从LLM角度学习和了解MoE架构
MoE是目前国内LLM采用的技术路线,Deepseek R1、Qwen3、GLM4都采用了MoE架构。
这里尝试理解什么是MoE,以及MoE有哪些优点和缺点,后续分析为什么这么多LLM采用MoE。
1 什么是MoE
MoE,全称为Mixed Expert Models,1991年论文Adaptive Mixture of Local Exports提出。
1.1 MoE示例
在相同计算资源和参数量条件下,MoE模型与Dense模型相比,训练速度更快。
也就是说,MoE由于训练效率的提升,可以是更大的模型。
比如Google Switch Transformer模型,大小是T5-XXL的15倍,相比T5-XXL模型快4倍达到固定困惑度PPL。
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) models defy this and instead select different parameters for each incoming example. The result is a sparsely-activated model—with an outrageous number of parameters—but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs, and training instability. We address these with the introduction of the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques mitigate the instabilities, and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5 Large (Raffel et al., 2019) to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the “Colossal Clean Crawled Corpus”, and achieve a 4x speedup over the T5-XXL model.
https://arxiv.org/pdf/2101.03961
在相同计算预算条件下,MoE可以显著扩大模型的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。
1.2 MoE架构
MoE基于Transformer架构,主要由两部分组成:稀疏MoE层、token路由。
稀疏 MoE 层,MoE 层包含若干“专家”(如 8 个),每个专家本身是一个独立的神经网络,用于代替经典Transformer模型的前馈网络 (FFN) 层。实际应用中,这些专家通常是更简单的FFN,也可以是其他网络。
token路由,用于决定哪些token激活哪个专家。如下图所示,token “More”可能激活第二个专家,而“Parameters” 被激活第一个专家。一个 token 甚至能激活多个专家。token路由是MoE的一个关键点,路由器包含学习参数,与网络其他部分一同进行训练。
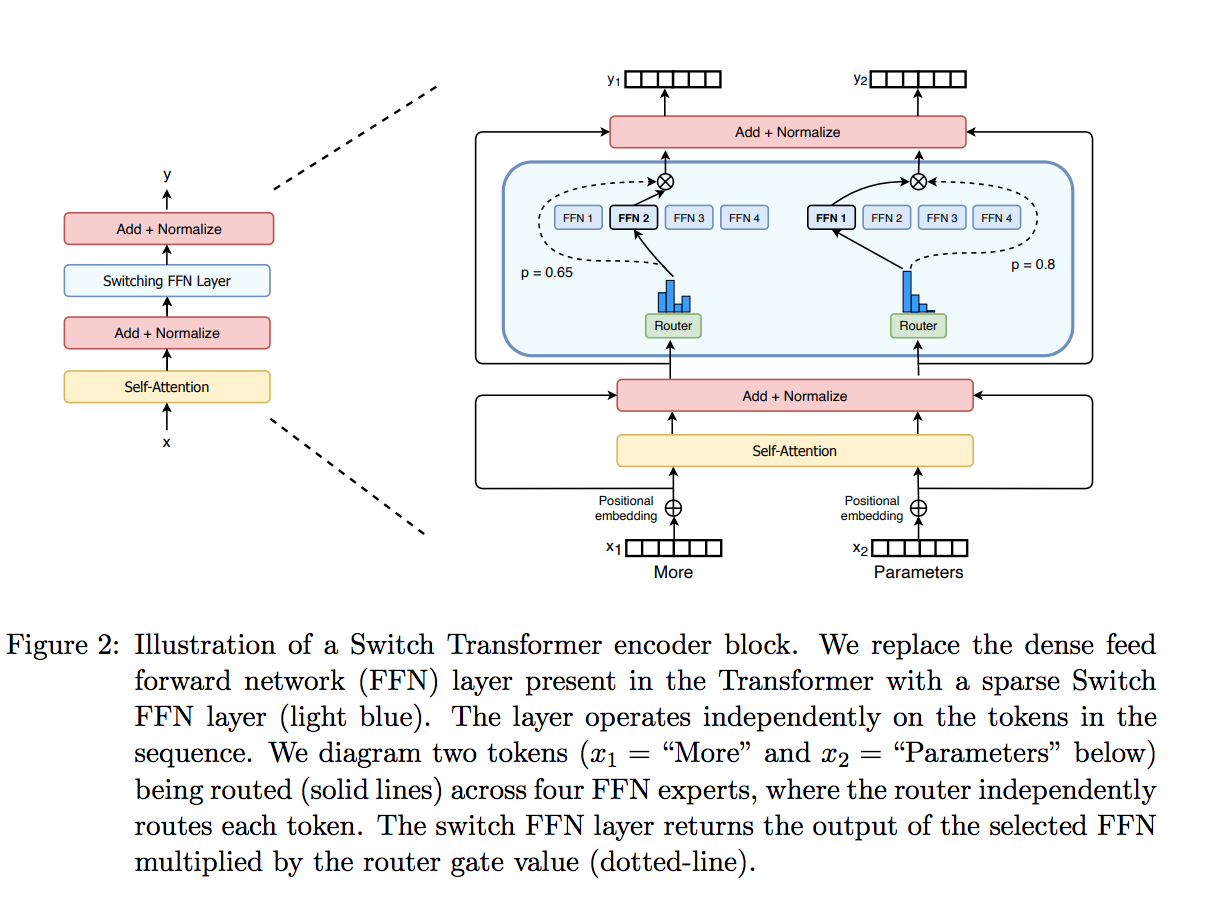
2 MoE优点
MoE与Dense模型相比,训练速度更快,可以训练更大的模型,如Google的Switch Transformer。
DeepSeek的16B MoE模型,仅消耗40%计算预算,就达到与LLaMA2 7B差不多的效果。
MoE优点总结如下:
1)训练速度更快,效果更好
2)推理成本低,只需要激活部分的参数参数运算
3)可以较容易扩展到更大的模型,计算预算不变,可以增加参数量。
4)多任务学习,如Switch Transformer在101种语言获得性能提升,具备较好的多任务学习能力。
3 MoE缺点
当然MoE也有缺点,总结如下
1)训练稳定性差,这与MoE的架构有关,在训练中可能会遇到稳定性问题。
2)通信开销大,MoE的专家路由机制,可能会增加通信成本,特别是在分布式训练环境中。
3)模型复杂,模型参数增加,嫌贵那贵的模型设计就会相对复杂,需要均衡和取舍。
4)下游任务容易过拟合,MoE由于其稀疏性,在微调时更容易过拟合,当然这不一定全是坏处,需要依据具体问题取舍和优化。
reference
---
Switch Transformers: Scaling to Trillion Parameter Models
https://arxiv.org/pdf/2101.03961
MoE(Mixture-of-Experts)大模型架构的优势是什么?为什么?
https://www.zhihu.com/tardis/bd/ans/3364787819
Adaptive Mixtures of Local Experts
https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf