快速了解并使用pandas库
系列文章目录
Python 机器学习入门之pandas的使用
目录
系列文章目录
Python 机器学习入门之pandas的使用
文章目录
一、pandas是什么?
二、Pandas库
1.Series类型
1.1 Series类型的创建
1.2 Series类型的基本操作
2.DataFrame类型
2.1 DataFrame类型的创建
2.2 重新索引 (.reindex())
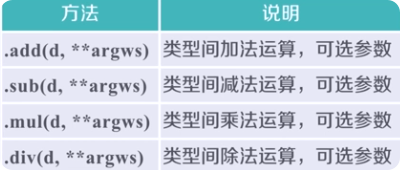
2.3 算数运算
2.3.1 相同维度间的运算
2.3.2 以方法的形式实现:
2.3.3 不同维度间的运算
2.4 比较运算
2.5 数据排序
2.6 统计分析
总结
一、pandas是什么?
pandas 是Python的第三方库,基于NumPy 的一种工具,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析,常与NumPy和Matplotlib一同使用。
import pandas as pdpandas提供了两个非常重要的数据结构,Series和DataFrame:
Series:一维数据结构,类似于列表(List),但拥有更强的功能,支持索引。 DataFrame:二维数据结构,类似于表格或数据库中的数据表,行和列都具有标签(索引)。
对NumPy有了解就会知道它也提供了一个数据结构表示:ndarray,两者的不同点在于NumPy更关注数据间的结构关系(以什么样的方式对数据组织和存取),而Pandas则更关注数据的应用(关注怎样有效提取并运算这些数据),我们可以通过索引快速定位并使用这些数据。
二、Pandas库
1.Series类型
1.1 Series类型的创建
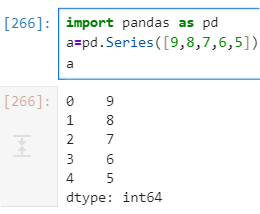
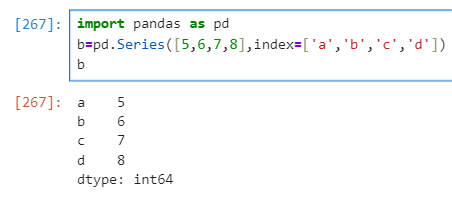
import pandas as pd a=pd.Series([9,8,7,6,5]) aimport pandas as pd b=pd.Series([5,6,7,8],index=['a','b','c','d']) b
可以发现当Series()内只有一维的时候索引下标默认是从0开始依次递增的,当有两维时列表的第二维表示的是对应的索引(‘index=’可以省略),另它的数据类型依然沿用NumPy中的数据类型。
当我们试图将某一个列表中的数据删除或添加就会出错(index和列表元素必须一样长),事实上在实际处理数据中缺少对应或对应缺失经常会发生,这里我们再说一下其他几种创建方式:
由标量值创建(只能有一个),index来表示Series的尺寸。
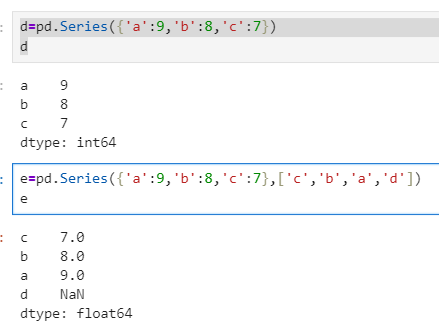
import pandas as pd b=pd.Series(5,['a','b','c','d']) #注意这里是一个标量值并非列表(没有括号) b由Python字典进行创建(别忘了是大括号),需要注意当后面没有指定index时索引下标按字典进行,如果有index列表则索引以index列表为准,此时会依照索引查看字典所对应的索引是否有数据,将属于和索引进行对应没有则为空。
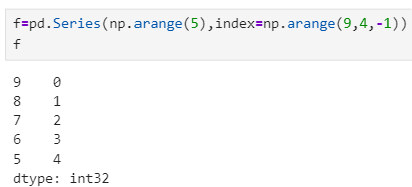
d=pd.Series({'a':9,'b':8,'c':7}) #注意这里一定要有大括号 d e=pd.Series({'a':9,'b':8,'c':7},['c','b','a','d']) e索引和数据都通过ndarray类型创建:
f=pd.Series(np.arange(5),index=np.arange(9,4,-1)) f
1.2 Series类型的基本操作
通过上图我们可以发现,即使我们采用了自定义索引自动索引也并没有取消,我们依然可以用自动索引的下标访问元素,但是当我们想要同时使用两套索引的时候,默认使用的其实是自定义索引。
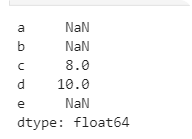
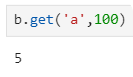
import pandas as pd b=pd.Series([5,6,7,8],['a','b','c','d']) b[0] 5 in b #支持in这个保留字 'a' in ba=pd.Series([1,2,3],['c','d','e']) a+bb.get('a',100) #获取'a'索引对应的值,若找不到就返回100
需要说明的是,这里的运算是基于索引的运算(先找到两者共同的索引然后是相同索引对应元素间的运算),而NumPy只关心数据的维度,是数据维度的运算(不找索引值)。
值得注意的是:Series()对象可以随时修改并即刻生效(上图所示),这为Series()的应用提供了很好的支持。
回过头来我们发现理解Series()关键在于理解带标签数组的含义。



2.DataFrame类型
2.1 DataFrame类型的创建
采用二维的ndarray创建:
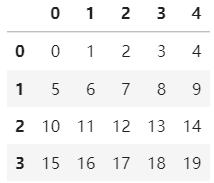
import pandas as pd import numpy as np d=pd.DataFrame(np.arange(10).reshape(2,5)) d
使用字典创建:
import pandas as pd dt={'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([9,8,7,6],index=['a','b','c','d'])} d=pd.DataFrame(dt) dpd.DataFrame(dt,index=['b','c','d'],columns=['two','three'])
我们发现我们采用three列索引,但这一列并没有值,数据根据行列索引自动补齐。
当我们index索引完全相同时,字典的索引创建就可以进行简化:
import pandas as pd dl={'one':[1,2,3,4],'two':[9,8,7,6]} d=pd.DataFrame(dl,index=['a','b','c','d']) d
2.2 重新索引 (.reindex())
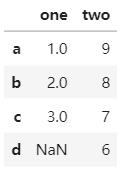
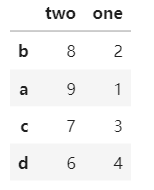
d=d.reindex(index=['b','a','c','d']) #行索引交换 dd=d.reindex(columns=['two','one']) #列交换 d
注意这里是d.reindex()非pd.reindex()同时要明确是是更改行还是列,两者的关键字不同。
我们来仔细分析一下上面是如何进行修改的:首先是将第二列的数据进行删除并将其赋值给了nc,然后又添加一行(表示添加c0到第五行)赋值给ni,最后将赋值后的行和列作为新的行和列,method='ffill'空缺的部分的值采用向前填充的方式。
可以发现上面的delete()也可以用来删除,两者有何不同?delete主要用于Index对象和Series对象,按位置(系统默认的从0开始的非自定义整数索引)删除元素,drop主要用于DataFrame和Series,按标签(自定义索引值)删除行或列。但我们发现上面DataFrame也用了delete,如果要按位置删除DataFrame的行或列,可以先使用iloc或index/columns属性来获取位置对应的标签,才能进行删除。
2.3 算数运算
2.3.1 相同维度间的运算
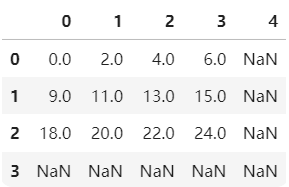
a=pd.DataFrame(np.arange(12).reshape(3,4)) a b=pd.DataFrame(np.arange(20).reshape(4,5)) b a+b
可以发现,当两组数据的维度不相同时,相同标签的数据进行运算,不同标签的数据补齐后运算,NaN与任何元素进行运算还是NaN。
2.3.2 以方法的形式实现:
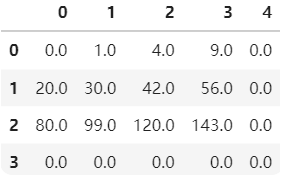
b.add(a,fill_value=100) a.mul(b,fill_value=0)
用方法实现的运算可以用指定数进行补齐然后进行运算(也仅限于方法才可以实现)。
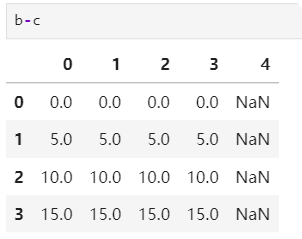
2.3.3 不同维度间的运算
b=pd.DataFrame(np.arange(20).reshape(4,5)) b c=pd.Series(np.arange(4)) c
可以发现:不同维度间的运算为广播运算,如果二维与一维的运算默认为轴1(行)运算,如果我一定要列广播运算怎么办呢?可以直接指定b.sub(c,axis=0)即可。
2.4 比较运算
这里需要注意:如果是相同维度,那么这两个相同维度的数据的轴长必须是相同的。
即使是不同维度的运算也必须保证轴长相同,比较运算不会进行补齐。
a=pd.DataFrame(np.arange(12).reshape(3,4)) a c=pd.Series(np.arange(4)) c a>c c>0
2.5 数据排序
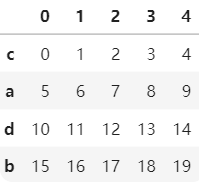
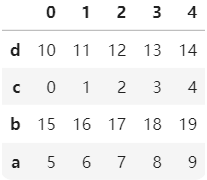
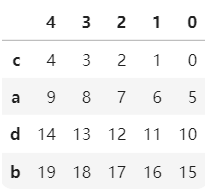
.sort_index()方法在指定轴上根据索引进行排序,默认升序。sort_index(axis=0,ascending=True/Flase)。
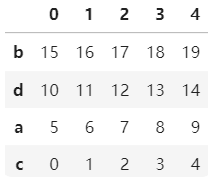
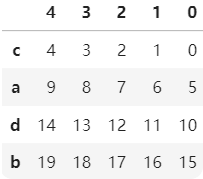
import pandas as pd import numpy as np b=pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b']) bb.sort_index() #纵轴升序 b.sort_index(ascending=False) #纵轴索引降序 b.sort_index(axis=1,ascending=False) #横轴索引升序 b.sort_index(axis=1,ascending=True) #横轴索引降序
c=b.sort_values(2,ascending=False) c c=b.sort_values('a',axis=1,ascending=False) c
by可以指定特定的行或列,axis指定是按行还是按列进行。ascending=False:表示降序排列。默认NaN放到排序的最后。
又是横轴又是纵轴我怎么记?其实大多数都是按照axis=0轴(纵轴)进行,因为毕竟要与一维同步。
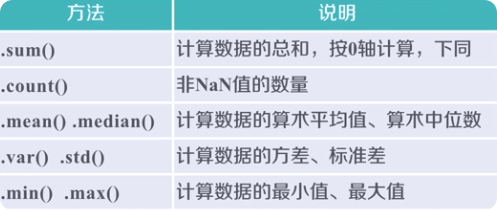
2.6 统计分析
包括但不限于上面的一些函数有很多,这里就不一一列举,记住常用的,不常用的遇到现查就可以了。





















总结
本文主要参考嵩天老师的相关课程并进行分析整理,主要介绍了Pandas的基本使用,当然Pandas还封装了许多用于数据分析的相关函数,包括上面所提到的一些函数的详细用法有些没有进一步展开,想做进一步了解市面上的资料很多,这里不过多赘述。如果觉得有些收获那就点个赞吧!