MySQL笔记---索引
1. 索引的概念
在 MySQL 中,索引是一种特殊的数据结构,它与数据表关联,能帮助数据库高效查询数据,避免全表扫描(遍历所有记录),显著提升查询性能。
准确来说,索引是绑定到数据表的某一行或某几行的。
一个索引就是一个能通过键值快速查找目标的数据结构(例如红黑树、哈希表、B+树等),而为某一行建立索引,本质上就是以该行的值为键值建立一个用于查找的数据结构。
这样,在以该行为筛选条件查询记录时,查询速度就会有明显的提升。
1.1 索引的作用
- 加速查询:通过索引快速定位符合条件的记录(类似书籍的目录)。
- 优化排序 / 分组:若查询包含 ORDER BY 或 GROUP BY,合适的索引可避免额外排序操作。
- 约束作用:某些索引(如主键、唯一索引)可保证数据唯一性。
1.2 索引的类型
(1)按数据结构划分
- B + 树索引(最常用): MySQL 大多数存储引擎(如 InnoDB、MyISAM)默认使用 B + 树作为索引结构。
- 特点:有序性、平衡性,叶子节点存储数据(InnoDB 聚簇索引)或指针(MyISAM 非聚簇索引)。
- 适用场景:范围查询(>、<、BETWEEN)、精确匹配(=)、排序(ORDER BY)等。
- 哈希索引: 基于哈希表实现,适用于精确匹配(=),但不支持范围查询和排序。
- InnoDB 中仅 “自适应哈希索引”(自动为热点数据创建,不可手动干预)。
- 其他索引:
- 全文索引:用于文本内容的模糊查询(如 MATCH AGAINST),支持自然语言搜索。
- R-tree 索引:用于空间数据类型(如 GEOMETRY),较少使用。
(2)按功能划分
- 主键索引(PRIMARY KEY): 唯一标识一条记录,不允许 NULL,一张表只能有一个主键索引。 InnoDB 中,主键索引是聚簇索引(数据与索引存储在一起)。
- 唯一索引(UNIQUE): 确保索引列的值唯一,但允许 NULL(多个 NULL 不冲突),一张表可有多列唯一索引。
- 普通索引(INDEX): 无唯一性约束,仅用于加速查询,可创建在任意列。
- 联合索引(复合索引):
- 基于多列创建的索引(如 INDEX idx_name_age (name, age))。
- 遵循 “最左前缀原则”:查询条件需包含索引的最左列才能触发索引(如 WHERE name='xxx' 可命中,WHERE age=18 不可)。
1.3 索引的使用场景
- 适合创建索引的场景:
- 频繁用于 WHERE 条件、JOIN 关联、ORDER BY/GROUP BY 的列。
- 基数高(取值范围大、重复值少)的列(如身份证号),基数低的列(如性别)不适合。
- 字符串列可针对前缀创建索引(如 INDEX idx_title (title(10))),节省空间。
- 不适合创建索引的场景:
- 表数据量小(全表扫描速度可能更快)。
- 频繁更新的列(索引会增加更新成本)。
- 很少查询的列。
- 包含大量 NULL 的列(索引对 NULL 处理效率低)。
1.4 索引失效的常见情况
即使创建了索引,某些查询可能无法命中索引,导致全表扫描:
- 索引列参与计算或函数操作(如 WHERE YEAR(create_time) = 2023)。
- 使用 NOT、!=、<> 等否定操作符(可能失效,视情况而定)。
- 字符串不加引号(如 WHERE name=123,实际类型为字符串时会隐式转换)。
- 使用 OR 连接非索引列(如 WHERE idx_col=1 OR no_idx_col=2)。
- 违背联合索引的 “最左前缀原则”。 LIKE 以通配符开头(如 WHERE name LIKE '%abc')。
1.5 索引的代价
- 空间代价:索引会占用额外存储空间。
- 时间代价:插入、更新、删除数据时,需同步维护索引结构,降低写操作效率。
因此,索引并非越多越好,需根据业务查询特点 “按需创建”。
2. 索引的用法
2.1 查看索引
SHOW INDEX FROM table_name;mysql> SHOW INDEX FROM emp;
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| emp | 0 | PRIMARY | 1 | empno | A | 15 | NULL | NULL | | BTREE | | | YES | NULL |
| emp | 1 | fk_emp_mgr | 1 | mgr | A | 8 | NULL | NULL | YES | BTREE | | | YES | NULL |
| emp | 1 | fk_emp_dept | 1 | deptno | A | 5 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3 rows in set (0.02 sec)SHOW INDEX FROM table_name \G;mysql> SHOW INDEX FROM emp \G;
*************************** 1. row ***************************Table: emp -- 表名称Non_unique: 0Key_name: PRIMARY -- 键类型Seq_in_index: 1 -- 在复合索引中的位置Column_name: empno -- 绑定到的列Collation: ACardinality: 15Sub_part: NULLPacked: NULLNull: Index_type: BTREE -- 索引类型,这里的BTREE指B+树而非B树Comment:
Index_comment: Visible: YESExpression: NULL
*************************** 2. row ***************************Table: empNon_unique: 1Key_name: fk_emp_mgrSeq_in_index: 1Column_name: mgrCollation: ACardinality: 8Sub_part: NULLPacked: NULLNull: YESIndex_type: BTREEComment:
Index_comment: Visible: YESExpression: NULL
*************************** 3. row ***************************Table: empNon_unique: 1Key_name: fk_emp_deptSeq_in_index: 1Column_name: deptnoCollation: ACardinality: 5Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment: Visible: YESExpression: NULL
3 rows in set (0.00 sec)2.2 主键索引
作为主键的列自带主键索引,无需用户显示创建。
2.3 唯一索引
同样地,唯一键自带唯一索引。
关于键的操作,请参考:https://the-old.blog.csdn.net/article/details/152162625?spm=1011.2415.3001.5331
在确保某列无重复数据的情况下,也可手动添加唯一索引:
CREATE UNIQUE INDEX idx_name ON table_name (column_name);2.4 普通索引
-- 创建表时定义索引
CREATE TABLE table_name (column_name 类型 [约束条件], INDEX idx_col (column_name)
);-- 添加普通索引
CREATE INDEX idx_name ON table_name (column_name);2.5 联合索引
-- 创建表时定义索引
CREATE TABLE table_name (column_name1 类型 [约束条件],column_name2 类型 [约束条件], INDEX idx_name (column_name1, column_name2)
);-- 添加联合索引
CREATE INDEX idx_name ON table_name (column_name1, column_name2);注意:只有在查询条件包含首列的情况下,联合索引才会被触发,这就是“最左前缀原则”。
原因我们会在下文介绍。
2.6 删除索引
DROP INDEX idx_name ON table_name;3. 索引底层原理
MySQL 索引的底层原理核心围绕数据结构和存储引擎的实现逻辑展开,其中最关键的是 B + 树(大多数存储引擎的默认选择)。
3.1 为什么选择 B + 树作为主流索引结构
索引的核心目标是减少磁盘 IO 次数(因为磁盘 IO 速度远慢于内存操作)。MySQL 中数据和索引都存储在磁盘上,索引需要通过高效的结构快速定位数据位置,减少磁盘访问次数。
磁盘读写数据的基本单位为一个扇区(512B),操作系统读写数据的基本单位为一个数据块(8个扇区,即4KB),而MySQL读写数据的基本单位为一个页面(Page,16KB)。
经过前面的介绍,我们当然不会选择哈希表作为索引的主流选择。所以剩下来的选择就是“树”。
而无论采用何种数据结构,我们都不能保证一次查询所涉及到的所有结点都在一个页面内。每次查询经过的结点越多,涉及到的页面也就越多,磁盘IO次数也就越多。
因此,我们需要的一定是一个矮胖的多叉树,这样才能减少结点的访问次数。
对比其他数据结构的缺陷:
- 二叉树:可能退化为链表(如有序数据插入时),查询效率暴跌(O (n))。
- 红黑树(平衡二叉树):树高随数据量增长较快(百万级数据树高约 20),磁盘 IO 次数多。
- B 树:非叶子节点也存储数据,导致单次 IO 加载的节点数据量少,树高更高,范围查询效率低。
而B + 树完美解决了这些问题,成为 MySQL(InnoDB、MyISAM 等)的首选:
- 结构特点: 是一种多路平衡查找树,所有数据都存储在叶子节点,且叶子节点之间通过双向链表连接;非叶子节点仅存储索引键(作为 “目录”),不存实际数据。
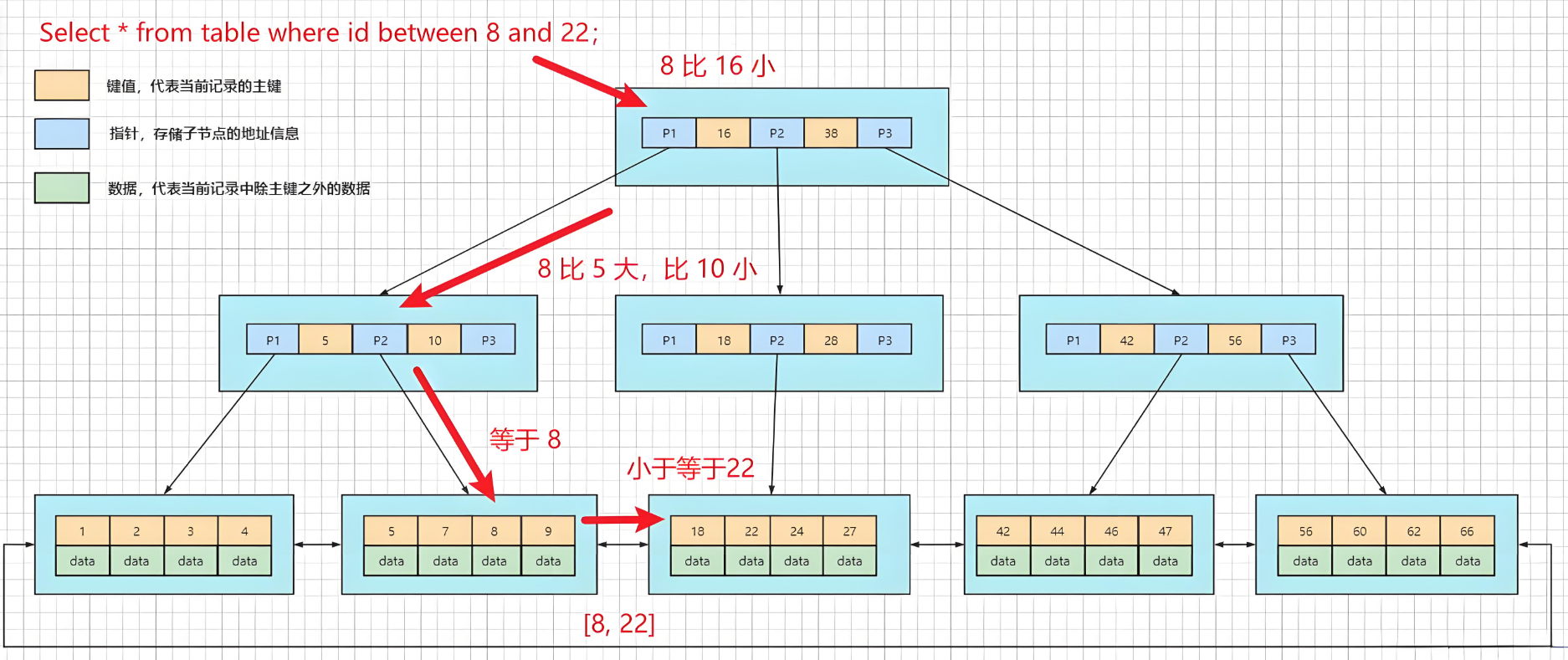
- 优势:
- 树高低:多路分支(如每个节点可存 1000 个索引键,3 层即可存 10 亿数据),减少磁盘 IO 次数(通常 3-4 次 IO 即可定位数据)。
- 范围查询高效:叶子节点链表有序,范围查询(如BETWEEN、ORDER BY)可直接通过链表遍历,无需回溯上层节点。
- IO 效率高:非叶子节点仅存索引键,单次磁盘 IO 可加载更多索引键,减少查询时的 IO 次数。
3.2 结点与页
B + 树的每个节点(包括根节点、非叶子节点、叶子节点)的大小会被设计为接近一个页的大小(16KB)。因此,每个节点会被完整地存储在一个单独的页中:
- 非叶子节点:存储索引键和指向子节点的指针(每个指针指向另一个页,即子节点);
- 叶子节点:存储索引键和数据(InnoDB 聚簇索引的叶子节点存完整数据行,二级索引存主键;MyISAM 存数据行物理地址)。
这种设计的核心目的是最大化单次磁盘 IO 的效率—— 一次 IO 就能加载整个节点的所有索引键和指针,避免因节点跨多个页导致的多次 IO。
实际中,节点可能不会完全填满页(例如新创建的索引、数据量较少时)。
但即便如此,节点仍会占用一个完整的页(剩余空间会空闲,或后续插入数据时填充)。
不会出现 “多个节点挤在一个页中” 的情况,因为这会导致读取一个节点时不得不加载其他无关节点的数据,浪费 IO 资源。
3.3 不同存储引擎的索引实现
MySQL 的索引实现与存储引擎强相关,最典型的是InnoDB和MyISAM。
3.3.1 InnoDB 的索引实现(聚簇索引 + 二级索引)
InnoDB 是 MySQL 默认存储引擎,其索引核心是聚簇索引(Clustered Index),即 “索引与数据存储在一起”。
- 聚簇索引(主键索引):
- 必须基于主键创建(若未显式定义主键,InnoDB 会隐式选择唯一非空列作为主键;若没有,则生成隐藏的 6 字节row_id作为主键)。
- 结构:B + 树的叶子节点直接存储完整的数据行(包括所有列的值)。
例:若表user的主键为id,则聚簇索引的叶子节点存储(id, name, age, ...)完整行数据。
- 二级索引(辅助索引 / 非主键索引): 基于非主键列创建的索引(如普通索引、唯一索引、联合索引等)。
- 结构:B + 树的叶子节点不存储完整数据行,而是存储主键值(聚簇索引的键)。
- 查询过程:通过二级索引查询时,需先定位到叶子节点获取主键值,再通过聚簇索引查询完整数据行,这个过程称为 “回表”。
例:若user表有name列的二级索引,查询WHERE name='Bob'时,先通过name索引找到主键id=15,再用id=15查聚簇索引得到完整数据。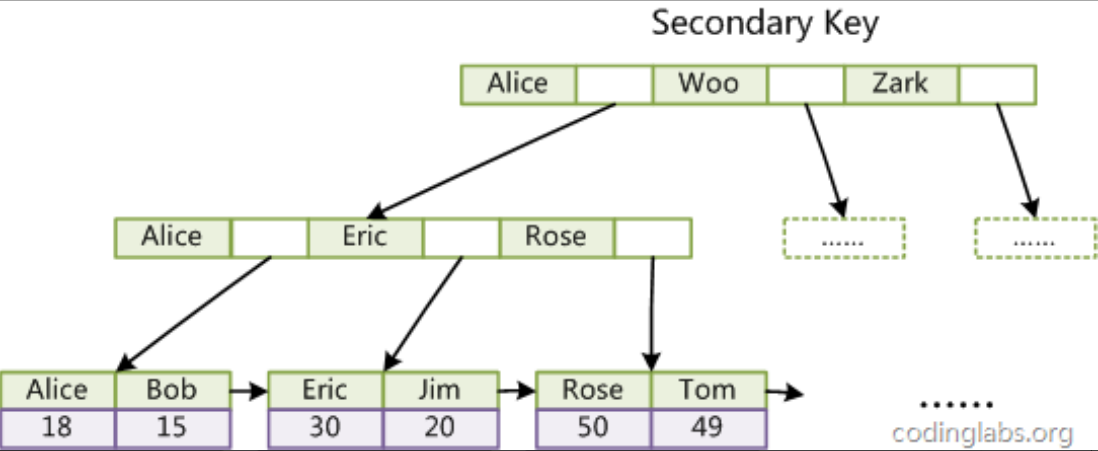
- 联合索引的底层: 基于多列创建的 B + 树,索引键按列顺序排序(如(name, age)联合索引,叶子节点按name先排序,name相同则按age排序)。这也是 “最左前缀原则” 的底层原因:只有从最左列开始匹配,才能沿 B + 树的有序结构定位。
3.3.2 MyISAM 的索引实现(非聚簇索引)
MyISAM 的索引与数据完全分离,所有索引(包括主键索引)都是非聚簇索引。
- 结构:
- 索引的 B + 树叶子节点存储的是数据行的物理地址(即数据在磁盘上的存储位置,类似文件指针)。
- 数据单独存储在数据文件中,与索引文件分离。
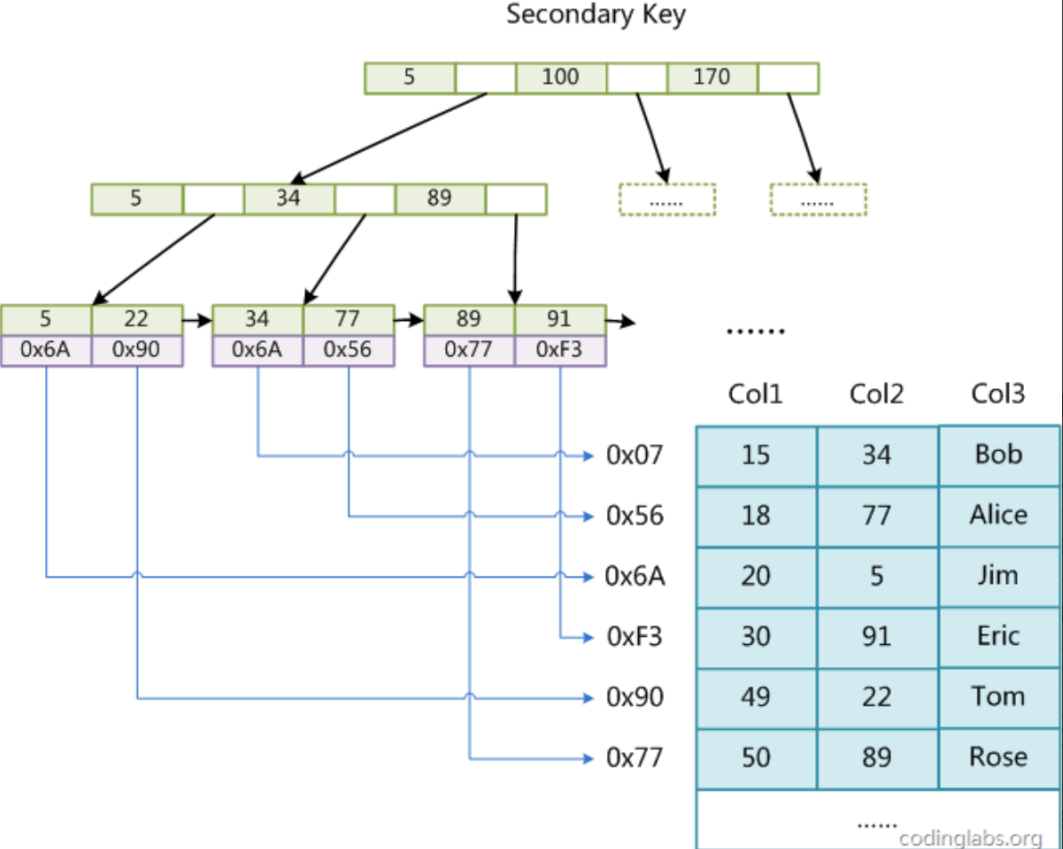
- 查询过程: 无论主键索引还是二级索引,找到叶子节点的物理地址后,直接通过地址访问数据文件获取完整行,无需回表(因为地址直接指向数据)。
- 缺点: 由于索引与数据分离,范围查询效率低于 InnoDB(InnoDB 的叶子节点链表更高效);且不支持事务和行级锁,现在已较少使用。