Linux系统--文件系统--动静态库
深入理解 Linux 系统下的动静态库
一、 动静态库是什么?
库(Library)本质上是一种可执行代码的二进制形式,它可以被操作系统载入内存执行。
举个不严谨的例子,我们写的代码像是一辆含有说明书的没有车轮或者轮胎的赛车,说明书中清楚的说明了我们的车这场比赛需要使用到哪种轮胎,是全热熔的还是半热熔的,是软胎还是硬胎,还是雨胎……,库就是一个巨大的轮胎供应商,比如倍耐力,其中啥轮胎都有……
如果想让我们写的程序(赛车🏎)真正跑起来,我们需要将轮胎供应商中合适我们赛车的轮胎装上。
库就是一个轮胎供应商,需要使用的时候,我们就可以直接拿来使用。从而省去我们自己造轮胎的时间。
其中我们和轮胎供应商的合作方式分为两种方式:静态链接 和 动态链接
轮胎供应商有两间子公司,分别接待不同的业务:
一间是:静态库,负责对接静态链接
一间是:动态库,负责对接动态链接
- 静态库(Static Library):在编译链接期,直接将库的代码全部“复制”到最终的可执行程序中。因此,最终生成的可执行文件可以独立运行,不再需要依赖外部的库文件。在 Linux 中,静态库通常以
.a(Archive)作为后缀。
当我们和静态库合作的时候,静态库会在我们准备比赛期间(编译链接期间),就把轮胎送到我们的车间,然后我们就立马把轮胎装到车上。这个时候我们的车就已经可以下赛道了。
- 动态库(Shared Library / Dynamic Library):在编译链接期,只在最终的可执行程序中记录下库的名字、符号表等少量信息。在程序运行时,由操作系统的动态链接器(
ld-linux.so)负责将所需的动态库加载到内存并与程序链接。Linux 中动态库的后缀通常是.so(Shared Object)。
当我们和动态库合作的时候,在准备比赛期间(编译链接期间)我们会记录下和我们合作的动态库的名字,以及少量相关信息,等到比赛日到的时候,会有专门的人(操作系统的动态链接器)把我们需要的轮胎送到我们车间,并将轮胎装车。
我们平时有使用过动静态库吗?
当然有!我们几乎无法编写一个不使用任何库的 C/C++ 程序。最经典的例子就是 printf和 scanf函数,它们都来自 C 标准库。你可以通过下面的命令验证。
能有什么办法知道一个可执行程序链接了什么库嘛?
使用 ldd命令。它会列出指定可执行文件所依赖的所有动态库。
$ ldd /bin/lslinux-vdso.so.1 (0x00007ffd47bdf000)libcap.so.2 => /lib/x86_64-linux-gnu/libcap.so.2 (0x00007f87a75e0000)libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f87a73be000)/lib64/ld-linux-x86-64.so.2 (0x00007f87a7630000)
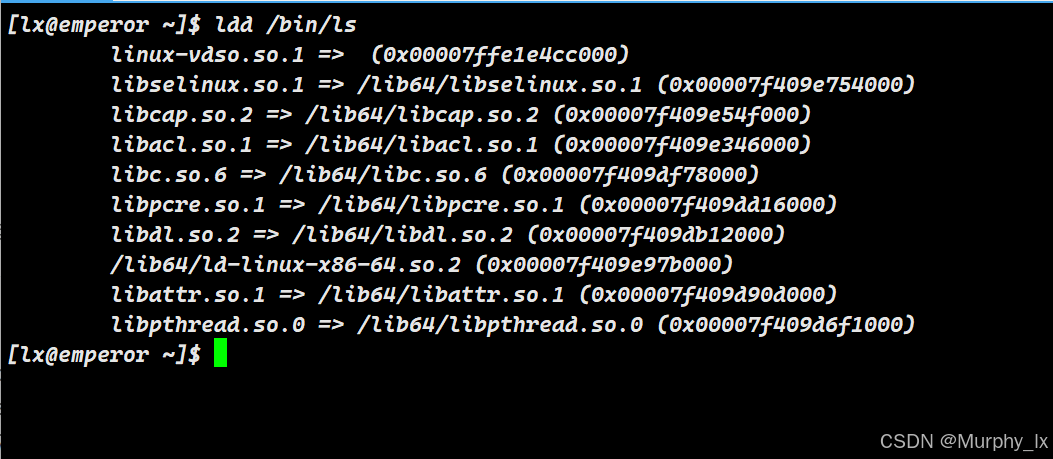
从输出可以看到 ls命令依赖于 libc.so.6(C 标准库)等。
系统默认安装什么库?
系统默认安装的是动态库。如果需要使用静态库需要自己手动下载安装静态库。
系统优先链接动态库还是静态库?
系统默认优先链接动态库。这是因为动态库的诸多优点(后面会详述),比如节省磁盘和内存空间、便于更新。
-
编译链接默认使用哪一种库?
当你在命令行使用
gcc main.c -o app时,gcc会默认动态链接 C 标准库(libc.so)。如果你想强制使用静态库,需要显式指定-static选项,例如gcc main.c -o app_static -static。生成的app_static文件会非常大,因为它包含了所有依赖的静态库代码。
如何知道一个库的真实名称是什么?
Linux 下的库遵循一个命名规则:动态库lib<name>.so.<version> 或 静态库 lib<name>.a。
掐头去尾就是name了。
注意:
- 如果我们同时提供动态库和静态库,gcc/g++默认使用的是动态库。
- 如果我们一定要使用静态链接,那么在保证静态库存在的情况下,我们必须显式指定
-static选项。 - 如果我们程序中某个功能的实现需要使用到库,而我们只给这个功能提供了静态库,那么程序在编译链接也就只能在这个功能上选择静态库进行静态链接了。但是程序并不一定全部都是用静态链接。
假设你程序中有3个功能,一个是add,一个是sub,一个是printf。add这个功能你给程序准备了一个动态库,并且你的系统中的C语言标准库也是动态库,唯独这个sub功能,你没有找到动态库可以使用,所以你就只提供了一个静态库。
那么在程序编译链接的时候,由于sub功能的那个库只有静态库,实在没得选,就只能静态链接了,但是add和printf都有动态库提供,那程序链接的时候,肯定都是选择的动态链接。
这就好像当你有新鲜现杀的牛羊狗肉吃的时候,肯定选择新鲜的。当只有预制菜给你吃的时候,那你也没办法,为了活命,你也只能吃预制菜。我想已经解释很清楚了。
- 如果我们只提供了动态库,没有提供静态库,那么默认是只能动态链接的,如果你强制显式指定
-static选项,强行静态链接,那么就会发生链接报错。
系统就会觉得,当你面前有新鲜美味的饭菜的时候,你还要哭爹喊娘的想吃预制菜,系统会觉得你脑子瓦特了,是病,得治。
二、 为什么要有“库”这个概念?
- 代码复用(Reusability):避免重复造轮子。将常用的、经过严格测试的代码(如数学函数、加密算法)打包成库,供所有开发者使用,提高了开发效率和质量。
- 模块化开发(Modularization):将程序划分为多个模块,分别编译成库,使得项目结构清晰,易于管理和协作。
- 便于更新和维护(Easy Update & Maintenance):
- 静态库:更新库需要重新编译整个程序。
- 动态库:更新库时,只需替换
.so文件并重启程序(有时甚至无需重启,如dlopen),所有使用该库的程序都会自动受益,极大简化了部署和修复漏洞的过程。
- 节省资源(Resource Saving):
- 磁盘空间:多个程序共享一个动态库的物理文件。
- 内存:操作系统的一份动态库代码可以被多个正在运行的程序进程共享,只需映射到各自的内存空间即可。
- 保护源代码:当你不想暴露自己的代码给别人的时候,你就可以将已经编译好的程序连同头文件打包发给别人,别人可以直接调用其中的接口,直接使用,而不需要知道源码是什么。
三、 静态库的制作与使用
如何制作一个静态库?
假设我们有两个源文件:add.c和 sub.c,以及对应的头文件 math.h。
//math.h
#pragma once//加法
int add(int x , int y);//减法
int sub(int x , int y);
------------------------------------------------
//add.c
#include "math.h"int add(int x,int y)
{return x + y;
}
------------------------------------------------
//sub.c
#include "math.h"int sub(int x, int y)
{return y - x;
}
------------------------------------------------
//main.c
#include <stdio.h>
#include "math.h"int main()
{int a1 = 1;int b1 = 2;int c1 = 0;c1 = add(a1, b1);int a2 = 3;int b2 = 4;int c2 = 0;c2 = sub(a2, b2);printf("a1 = %d , b1 = %d\n", a1, b1);printf("a1 + b1 = %d\n", c1);printf("a2 = %d , b2 = %d\n", a2, b2);printf("b2 - a2 = %d\n", c2);return 0;
}# 1. 将源文件编译成目标文件(.o)
$ gcc -c add.c sub.c# 2. 使用 ar(archive) 命令将目标文件打包成静态库(.a)
# 参数 r:替换/插入文件到归档文件
# 参数 c:创建归档文件
# 参数 s:创建索引,等同于ranlib命令
$ ar -rcs libmymath.a add.o sub.o# 现在你得到了 libmymath.a
libmymath.a : add.o sub.oar -rcs libmymath.a add.o sub.oadd.o:add.cgcc -c add.csub.o:sub.cgcc -c sub.c.PHONY:clean
clean:rm -f *.o *.a app
如何使用一个静态库?
假设主程序为 main.c,它 #include "math.h"。
# gcc main.c -o app -I [头文件路径] -L [库文件路径] -l [库名]
# -I ./:指定头文件搜索路径为当前目录
# -L ./:指定库文件搜索路径为当前目录
# -l mymath:链接名为 libmymath.a 的库(注意:-l 会自动加上 lib 前缀和 .a 后缀)
$ gcc main.c -o app -I ./ -L ./ -l mymath
此时,app已经将 add和 sub函数的代码完全“复制”到了自身,可以独立运行。这个时候(链接完成的时候)就算你把静态库libmymath.a删除了,你的程序依旧是可以独立运行的。
也可使用make指令一步到位://Makefile如下:
app:libmymath.agcc main.c -o app -I ./ -L ./ -l mymathlibmymath.a : add.o sub.oar -rcs libmymath.a add.o sub.oadd.o:add.cgcc -c add.csub.o:sub.cgcc -c sub.c.PHONY:clean
clean:rm -f *.o *.a app静态链接的本质
静态链接的本质是:在程序编译链接的最后阶段,将外部库的目标代码“复制”到最终的可执行文件中,并完成所有符号的解析和重定位,从而生成一个完全自给自足、不依赖任何外部库的独立二进制实体。
我们可以将这个本质拆解为三个核心过程来理解:
1. 空间与内容的复制(The “Copy”)
这是最直观的一层理解。
- 输入:你的程序的目标文件(
main.o) + 一个或多个静态库文件(libmymath.a,它实际上是add.o和sub.o的打包集合)。 - 过程:链接器(
ld)并不是把整个libmymath.a都塞进可执行文件。它会进行一个称为 “归档文件提取(Archive Extraction)” 的过程。链接器扫描你的main.o中未解析的符号(比如add),然后到提供的静态库中逐个查找哪个目标文件(add.o)定义了该符号。一旦找到,就将那个特定的目标文件(add.o)从库中提取出来,合并到最终的可执行文件中。 - 结果:最终生成的
app文件,其二进制内容中包含了main函数的代码,也包含了add和sub函数的代码。它们被物理地、永久地整合在了一起。这就是为什么静态链接的程序更大的原因——它把需要的“工具”都自己带上了。
比喻:就像你要写一份报告(可执行程序),需要引用一本教科书(静态库)里的一个章节。静态链接的做法是:把那个章节完整地复印下来,然后装订到你的报告末尾。这样,你的报告就自成一体,不再需要那本教科书了。
2. 符号解析与地址分配(The “Resolution”)
这是逻辑层面最核心的一步。仅仅把代码复制过来是远远不够的,必须让所有部分能正确地协同工作。
- 符号解析(Symbol Resolution):
- 在编译
main.c成main.o时,编译器遇到add(5, 3)这一行,它并不知道add函数在哪。它只是在main.o的符号表中留下一个记录:“这里需要一个叫add的符号,地址待定(Undefined)”。 - 同样,在编译
add.c成add.o时,编译器会在add.o的符号表中记录:“我这里定义了一个叫add的符号”。 - 链接器的核心工作之一就是充当“月老”,将
main.o中对add的引用(Reference),与add.o中对add的定义(Definition) 绑定起来。这个过程就是符号解析。
- 在编译
- 地址与空间分配(Address & Space Allocation):
- 链接器会将所有输入的目标文件(
main.o,add.o,sub.o,以及像crt1.o这样的启动文件)合并到一起。 - 它会根据每个目标文件中的段(Section)(如
.text代码段,.data数据段),将它们分类并聚合到可执行文件的对应段中。 - 最关键的是:链接器会开始为这个聚合后的“大程序”分配运行时的虚拟内存地址。例如,它决定
main函数的代码放在虚拟地址0x400500开始的地方,add函数的代码放在0x400600开始的地方。
- 链接器会将所有输入的目标文件(
3. 重定位(Relocation)—— 静态链接的灵魂
这是将“复制”和“解析”落到实处的关键一步,是静态链接技术实现的基石。
- 问题来源:在第二步分配地址之前,每个目标文件都是在不知道自己最终会被放在哪的情况下编译的。比如,在
add.o中,add函数自己的代码和其内部跳转指令使用的都是相对于本文件开头的偏移地址(例如,从add.o的.text段开头向后偏移 16 字节)。这些地址在合并到大程序后肯定是错的。 - 重定位的过程:
- 链接器已经知道了所有段最终的虚拟内存起始地址。
- 链接器会查看每个目标文件中的 “重定位表”(Relocation Table)。这个表专门记录了哪些指令和数据在将来需要被修正(哪些地方用了尚未确定的地址)。
- 链接器根据之前分配的地址,计算出一个绝对地址。例如,计算出
add函数的绝对入口地址就是0x400600。 - 然后,链接器找到
main.o中调用add函数的那条call指令的位置,将这条指令的操作数(原本可能是个无效的占位符)修改(重定位) 为正确的绝对地址0x400600。
- 结果:经过重定位后,可执行文件中所有的内部函数调用、全局变量访问使用的都是正确的、最终的虚拟内存地址。此时,这个可执行文件就是一个所有部分都紧密结合的有机整体。
比喻(接上文):在你把教科书的章节复印到报告中后,你发现原文里有一句“详情请见本章第5节”,但这个“第5节”指的是在原书中的位置。你需要把这个引用重定位成在你报告中的新页码,比如“详见本报告第23页”。
总结与核心思想
| 特性 | 静态链接 |
|---|---|
| 时机 | 编译链接期(compile-time) |
| 行为 | 复制库代码 + 解析符号 + 重定位地址 |
| 结果 | 生成一个完整独立的可执行文件,不依赖任何外部库文件 |
| 优点 | 移植简单,性能稍好(无运行时链接开销) |
| 缺点 | 浪费磁盘和内存空间,更新库需要重新编译整个程序 |
核心思想:静态链接是一个 “预绑定”(Pre-binding) 的过程。它在程序运行之前,就提前解决了所有外部依赖问题,把所有不确定的、需要查找的东西都变成了确定的、内部的地址。这牺牲了空间灵活性,换来了部署的简单性和时间的确定性。
四、 动态库的制作与使用
如何制作一个动态库?
同样使用 add.c, sub.c, math.h。
# 1. 编译目标文件,需要添加 -fPIC 选项
# -fPIC (Position Independent Code):生成与位置无关的代码,这是动态库的关键特性
$ gcc -c -fPIC add.c sub.c# 2. 使用 gcc -shared 生成动态库
$ gcc -shared -o libmymath.so add.o sub.o# 现在你得到了 libmymath.so
如何使用一个动态库?
编译链接时的命令和静态库完全一样。(就算你当前目录中有静态库,gcc默认选择的是动态链接)
# gcc main.c -o app -I [头文件路径] -L [库文件路径] -l [库名]
# -I ./:指定头文件搜索路径为当前目录
# -L ./:指定库文件搜索路径为当前目录
# -l mymath:链接名为 libmymath.a 的库(注意:-l 会自动加上 lib 前缀和 .a 后缀)
$ gcc main.c -o app -I ./ -L ./ -l mymath
也可以使用Makefile:
app:libmymath.sogcc main.c -o app -I ./ -L ./ -l mymathlibmymath.so:add.o sub.ogcc -shared -o libmymath.so add.o sub.oadd.o:add.cgcc -c -fPIC add.csub.o:sub.cgcc -c -fPIC sub.c.PHONY:clean
clean:rm -f *.o *.so *.a app动态链接的本质
动态链接的本质是:将链接过程拆分成两部分,在编译链接时仅建立“契约”,而将符号地址的最终绑定推迟到程序运行时(或加载时)完成。 这是一种“推迟决策(Delayed Decision)”的策略,核心思想是按需链接。
这种“推迟”带来了巨大的灵活性,是解决静态链接诸多痛点的关键。
为什么要有这两个步骤?(设计动机)
静态链接在程序运行前就确定了一切,这导致:
- 浪费空间:同一个库(如
libc.so)的代码被复制到每个使用它的程序中,磁盘和内存中存在多份 相同 的副本。 - 难以更新:修复库的一个小bug,需要所有依赖它的程序重新编译链接。
动态链接通过“分两步走”完美解决了这些问题:
- 编译链接时(第一步):只确认库的接口(有哪些函数、变量)是否存在、是否兼容,并将这种依赖关系记录在可执行文件中。不复制代码。
- 运行时(第二步):在程序被加载到内存准备执行前,由操作系统的动态链接器(
ld-linux.so) 负责找到所需的库,并将其映射到进程的地址空间,然后才完成最终的地址解析和重定位。多个进程可以共享内存中的同一份库代码。
比喻:这就像订酒店。
- 静态链接:直接买下一栋别墅(把库代码复制过来)。稳定,但贵且不灵活。
- 动态链接:
- 第一步(编译时):签合同,确认酒店有房、房型符合要求(检查符号是否存在)。
- 第二步(运行时):实际入住时,酒店前台(动态链接器)给你分配一个具体的房间号(函数地址)。
第一步:编译链接时 —— 建立“契约”
这个阶段发生在你使用 gcc命令进行编译链接的时候。
1. 目标:
- 验证所需的符号(函数、变量)在动态库中是否存在。
- 生成一个“不完整”的可执行文件,其中包含所有必要的依赖信息和待解析的符号表。
2. 关键过程:
- 符号解析(Symbol Resolution):编译器发现
main.c调用了add函数。它知道你通过-l mymath指定了库,于是去-L指定的路径查找libmymath.so。它检查libmymath.so的导出符号表,确认里面确实有add这个符号。注意:它只检查“有没有”,并不关心“在哪里”(地址是多少)。 - 记录依赖(Recording Dependencies):链接器不会将
add的代码复制到最终的可执行文件app中。它会在app的文件头中创建一个特殊的段(如.dynamic),里面清晰地记录:- “我这个程序运行需要
libmymath.so”。 - “我有一个名为
add的符号,需要由外部库提供”。
- “我这个程序运行需要
- 生成位置无关代码(PIC, Position-Independent Code):为了让后续的运行时链接能够正常工作,编译器会使用
-fPIC选项来生成与位置无关的代码。这意味着代码本身不包含任何绝对地址,所有的跳转和数据访问都通过全局偏移表(GOT) 等机制间接完成。这使得动态库可以被加载到进程地址空间的任意位置而无需修改其代码段。
输出结果:一个看起来“正常”但“无法独立运行”的可执行文件 app。如果你尝试运行它而系统找不到 libmymath.so,就会报错:cannot open shared object file。
第二步:运行时 —— 履行“契约”
这个阶段发生在你在命令行输入 ./app按下回车之后,到 main函数执行之前的极短时间内。
1. 目标:
- 将所需的动态库加载到内存。
- 完成所有推迟的地址解析和重定位工作,让程序能够正确执行。
2. 关键过程:
操作系统的加载器(Loader) 和动态链接器(Dynamic Linker, ld-linux.so.2) 协同工作:
- 程序加载:Shell 调用
execve()系统调用,操作系统加载器将app的代码段、数据段等映射到新创建进程的虚拟地址空间中。 - 发现依赖:加载器查看
app文件头中的.dynamic段,发现它依赖libmymath.so(还可能依赖libc.so等)。 - 加载库文件:动态链接器被启动。它根据一套复杂的规则(
LD_LIBRARY_PATH、/etc/ld.so.cache、默认库路径/lib、/usr/lib)去磁盘上寻找libmymath.so文件。 - 映射库:找到后,动态链接器将
libmymath.so的代码段映射到进程的地址空间。注意:这里是“映射”(Memory Mapping),不是“复制”! 操作系统通过精巧的页表机制,可以让多个进程的虚拟地址指向物理内存中的同一份libmymath.so代码副本,实现了内存共享。 - 重定位(运行时重定位):这是最核心的一步。现在库已经被加载到了一个具体的虚拟地址(例如
0x7f2a1b200000)。动态链接器开始进行最终的符号解析和重定位:- 它计算得出
add函数在内存中的绝对入口地址是0x7f2a1b200500。 - 它找到
app中所有调用add函数的地方(这些地方在编译时被预留为空白或占位符)。 - 它将
0x7f2a1b200500这个真实地址填回(修补) 到那些调用指令中。
- 它计算得出
- 执行:所有重定位完成后,控制权被交给
app的main函数,程序开始正常运行。
这个过程被称为 加载时链接(Load-time Linking)。
还有一种更极端的“推迟”:延迟绑定(Lazy Binding),即直到函数第一次被调用时才进行步骤5的重定位。这通过过程链接表(PLT)和全局偏移表(GOT)实现,进一步优化了启动速度。
编译时和运行时有什么关系?
它们的关系是 “协作”与“契约” 的关系:
- 分工协作:
- 编译时 是 “准备阶段” 。它的工作是:“确认库存在,并告诉系统我运行时需要谁。”
- 运行时 是 “执行阶段” 。它的工作是:“根据编译时留下的信息,找到它们,并完成最后的拼图。”
- 两者缺一不可。没有编译时的记录,运行时不知道要加载什么。没有运行时的加载和重定位,编译时生成的程序只是一纸空文。
- 信息传递:
- 编译时生成的
.dynamic段 和 待重定位表,就是它传递给运行时动态链接器的“任务清单”和“工程图纸”。 - 运行时链接器严格遵循这张图纸来施工。
- 编译时生成的
- 二进制兼容性:
- 编译时建立的“契约”是基于符号的接口(函数名、参数类型、返回值类型)。只要运行时的动态库提供的接口与编译时期望的接口一致,程序就能正常工作。这就是二进制兼容性。
- 如果运行时提供的库版本接口变了(比如函数参数个数变了),即使库文件存在,也会在重定位时发生错误,导致程序无法运行。这就是“契约”被破坏了。
总结与核心思想
| 特性 | 动态链接 |
|---|---|
| 时机 | 两步走:编译链接期 + 程序运行时 |
| 行为 | 编译时:记录依赖,验证接口。 运行时:加载库,映射内存,完成重定位。 |
| 结果 | 生成一个依赖外部库的可执行文件。多个进程共享内存中的库代码。 |
| 优点 | 节省磁盘和内存空间,库更新方便(无需重编程序),支持插件架构。 |
| 缺点 | 性能有轻微损耗(运行时链接开销),部署稍复杂(需确保库存在)。 |
核心思想:“延迟绑定(Delayed Binding)”。通过将链接过程推迟到运行时,实现了极致的空间优化和部署灵活性。编译时和运行时的关系,如同建筑师和施工队的关系,一个出蓝图,一个按图索骥,最终共同完成一个可运行的进程。
运行时加载动态库:编译成功绝不等于运行成功
通过前面的学习,我们已经知道动态链接将链接过程拆分成了两个独立的阶段:编译链接时 和 程序运行时。理解这两个阶段的独立性和协作关系至关重要。
一、 编译链接时:建立“合约”与“清单”
当你执行 gcc main.c -o app -I ./ -L ./ -l mymath时,编译链接器(主要是 ld)会进行以下工作:
- 语法与语义检查:检查你的代码(
main.c)语法是否正确,并处理#include和#define等预处理指令。 - 符号解析(Symbol Resolution):发现你调用了
add函数,它会根据-l mymath和-L ./的指示,在指定目录下寻找libmymath.so(或.a)文件。 - 验证符号存在:检查找到的动态库的导出符号表,确认其中确实存在
add这个函数定义。此时,它只关心“有没有”,完全不关心这个函数未来的“内存地址”是多少。 - 生成“不完整”的可执行文件:编译器将你的
main函数编译成目标代码,但对于add函数的调用,它只是生成一个占位符或一个待重定位的条目。同时,它会在可执行文件app的头部(例如.dynamic段)清晰地记录下一份**“运行时依赖清单”**,写明:“我需要libmymath.so才能运行”。
这个阶段的核心任务是: 确认所有需要的“零件”(函数、变量)在库中都存在,并生成一份详细的“采购清单”(依赖关系)。只要零件齐全,清单无误,编译链接就会成功。
比喻:这就好比建筑师(编译器)完成了一份完美的飞机设计图(可执行文件
app),并列出所有所需外部供应商的名单(依赖清单),比如“需要XX公司提供发动机(libmymath.so)”。图纸本身没问题,所以设计阶段“成功”了。
二、 运行时:按“清单”采购并组装
当你运行 ./app时,一个全新的角色——操作系统的动态链接器(ld-linux.so)——登场了。它的工作完全独立于之前的编译器:
- 读取“清单”:动态链接器首先加载
app,并读取其头部的依赖清单,发现需要libmymath.so。 - 按图索骥:它根据一套固定的搜索规则(
LD_LIBRARY_PATH,/etc/ld.so.cache, 默认路径等)去磁盘上寻找libmymath.so这个文件。它绝不会因为app在当前目录,就自动去当前目录寻找,也不会理会你编译时使用的-L ./选项,因为这个选项是给编译链接器看的,与它无关。 - 加载与映射:找到库文件后,动态链接器将库的代码段和数据段映射到进程的虚拟地址空间中。注意,是“映射”而不是“复制”,这允许多个进程共享同一份物理内存中的库代码。
- 最终的重定位(运行时重定位):这是最关键的一步。现在库已经被加载到了内存中的一个具体地址(例如
0x7f2a1b200000)。动态链接器开始工作,计算得出add函数的绝对入口地址是0x7f2a1b200500,然后找到app中所有调用add的地方,将之前预留的占位符修补为这个真实的地址。 - 执行:所有地址修补完成后,控制权才交给
app的main函数,程序开始正式运行。
这个阶段的核心任务是: 在程序启动前,根据“采购清单”找到所有“零件”,并将它们安装到正确的位置上,最终完成整个系统的组装。任何一个零件找不到,组装都会失败。
比喻(接上文):现在要根据图纸造飞机了(运行
app)。采购员(动态链接器)拿着供应商名单(依赖清单)去市场(磁盘文件系统)采购。如果市场上找不到XX公司(找不到libmymath.so),即使图纸再完美,飞机也造不出来,项目(程序)就会运行时失败。
三、 核心结论:为何编译成功 ≠ 运行成功
正是因为这两个阶段的独立性,导致了以下情况:
- 场景一(编译成功,运行成功):编译时
-L ./指定了库路径,库存在;运行时,动态链接器通过LD_LIBRARY_PATH=./或其他配置也在同一路径找到了库。完美。 - 场景二(编译成功,运行失败):这就是你最常遇到的情况! 编译时
-L ./d7指定库在d7/目录,链接成功。但运行时,你没有为动态链接器提供任何指引,它无法在d7/目录找到库,因此报错cannot open shared object file。
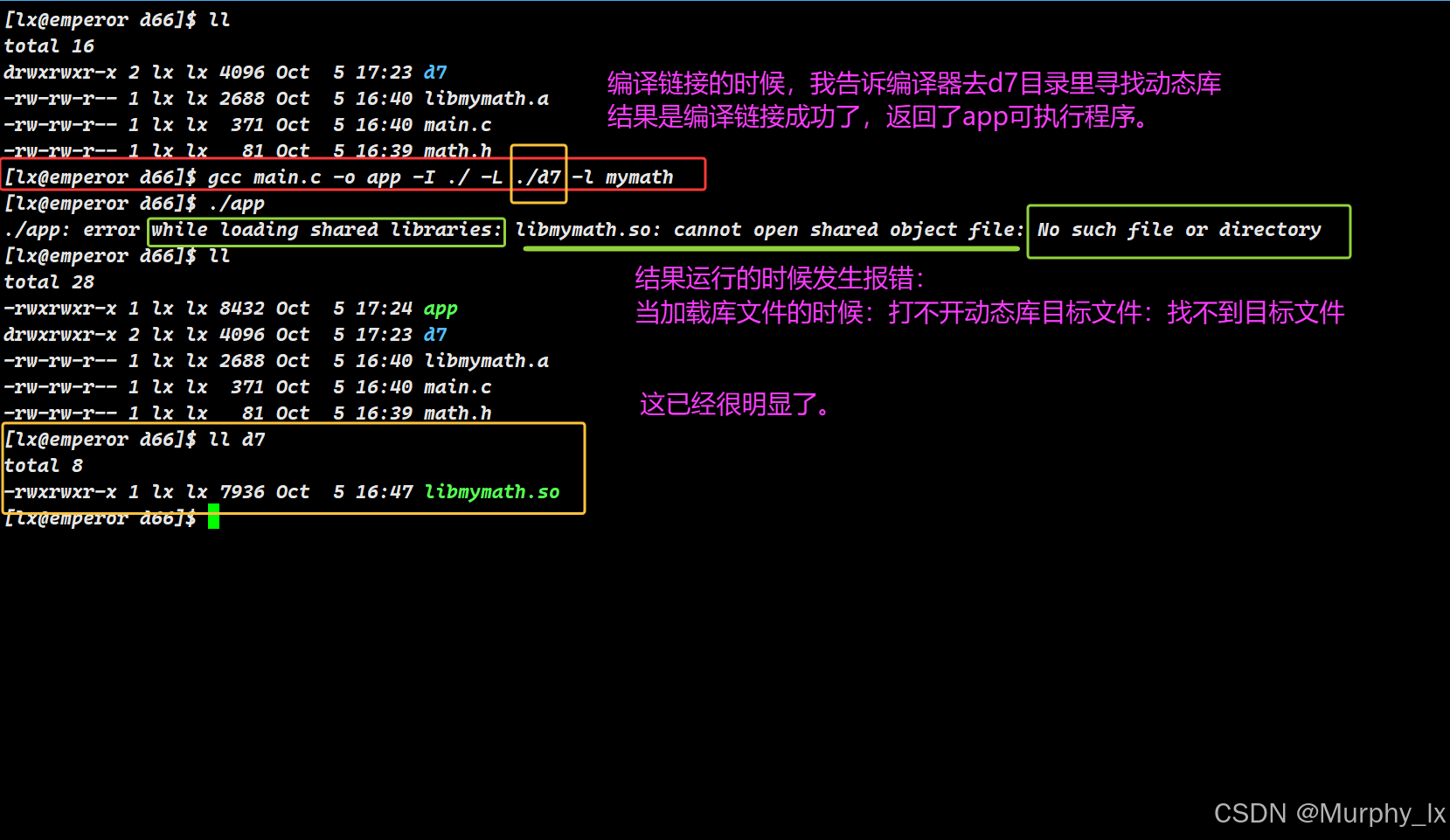
- 场景三(编译失败,运行无从谈起):编译时
-L指定的路径根本不存在libmymath.so,链接器直接报错cannot find -lmymath,根本无法生成app。
因此,你必须清晰地认识到:gcc命令的 -L选项仅服务于编译链接阶段,而 -l选项则同时服务于两个阶段(编译时确认存在,运行时记录名字)。确保编译成功,只是万里长征的第一步;为运行时动态链接器提供清晰的寻库路径,才是程序能够正常启动的关键。
这种设计带来了巨大的灵活性(易于更新库文件),但也增加了部署的复杂性。
接着我们来彻底梳理一下 Linux 系统中动态库的搜索规则。理解这个规则,是掌握程序部署和解决运行时库依赖问题的钥匙。
Linux 动态库搜索规则详解
动态链接器(ld-linux.so.2)的工作是:在程序运行时,找到它所需要的所有共享库。它遵循一套固定且具有明确优先级的搜索规则。这套规则的设计权衡了灵活性、效率与安全性。
一、 搜索规则的完整优先级顺序
动态链接器按以下顺序查找所需的共享库,一旦找到,便停止搜索:
-
可执行文件本身的
DT_RPATH条目(已废弃,但仍有优先级)- 是什么:这是一个被硬编码(Embedded) 在可执行文件中的库搜索路径列表。它在编译时通过链接器选项
-Wl,-rpath <path>指定。 - 优先级:最高。它会覆盖后续几乎所有设置。
- 现状:由于其行为过于“强硬”,现在已被
DT_RUNPATH取代。但在为兼容性,如果DT_RPATH存在,它依然有效。 - 示例:
# 编译时,将运行时库搜索路径硬编码为 /opt/mylibs gcc main.c -o app -L/opt/mylibs -lmylib -Wl,-rpath=/opt/mylibs# 使用 readelf 查看 readelf -d app | grep RPATH # 输出: 0x000000000000000f (RPATH) Library rpath: [/opt/mylibs]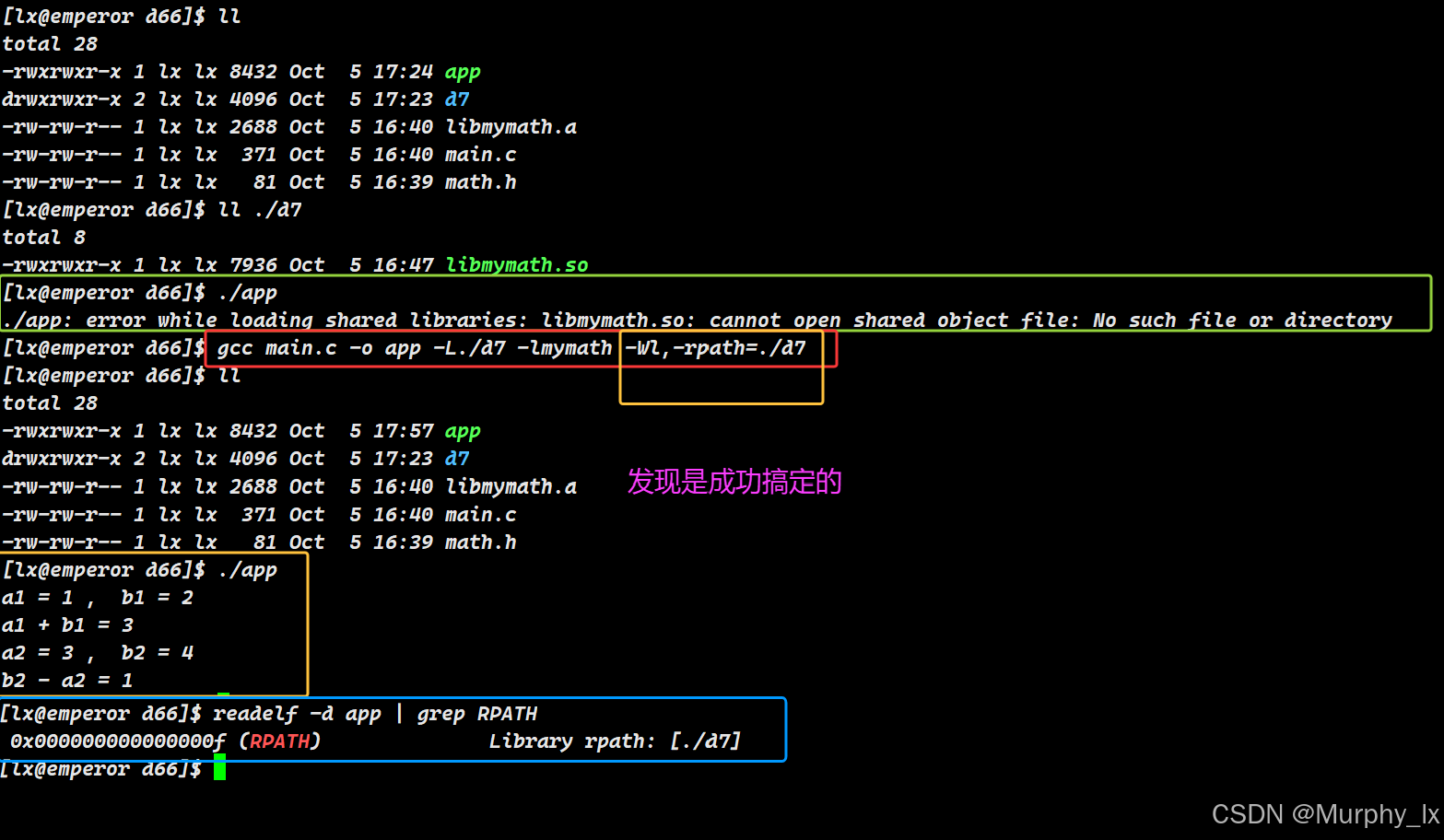
- 是什么:这是一个被硬编码(Embedded) 在可执行文件中的库搜索路径列表。它在编译时通过链接器选项
-
环境变量
LD_LIBRARY_PATH-
是什么:一个由用户定义的、用冒号分隔的目录列表。
-
如何使用:
export LD_LIBRARY_PATH=/some/path:/another/path -
优先级:很高。常用于开发和测试阶段,临时指定非标准路径的库。
-
注意:在生产环境中过度依赖它被认为是不好的做法,因为它会影响所有程序,可能引发意外行为。
-
DT_RPATH会覆盖LD_LIBRARY_PATH:如果可执行文件在编译时指定了DT_RPATH,那么动态链接器会优先使用DT_RPATH中的路径,而忽略LD_LIBRARY_PATH的设置。这是旧机制,行为较“强硬”。 -
DT_RUNPATH不会覆盖LD_LIBRARY_PATH:相反,LD_LIBRARY_PATH的优先级高于DT_RUNPATH。如果设置了LD_LIBRARY_PATH,动态链接器会先搜索它,然后再搜索DT_RUNPATH。这是新机制(DT_RUNPATH)的设计,为了提供更大的灵活性,允许用户在运行时通过环境变量覆盖编译时设置的路径。
-
-
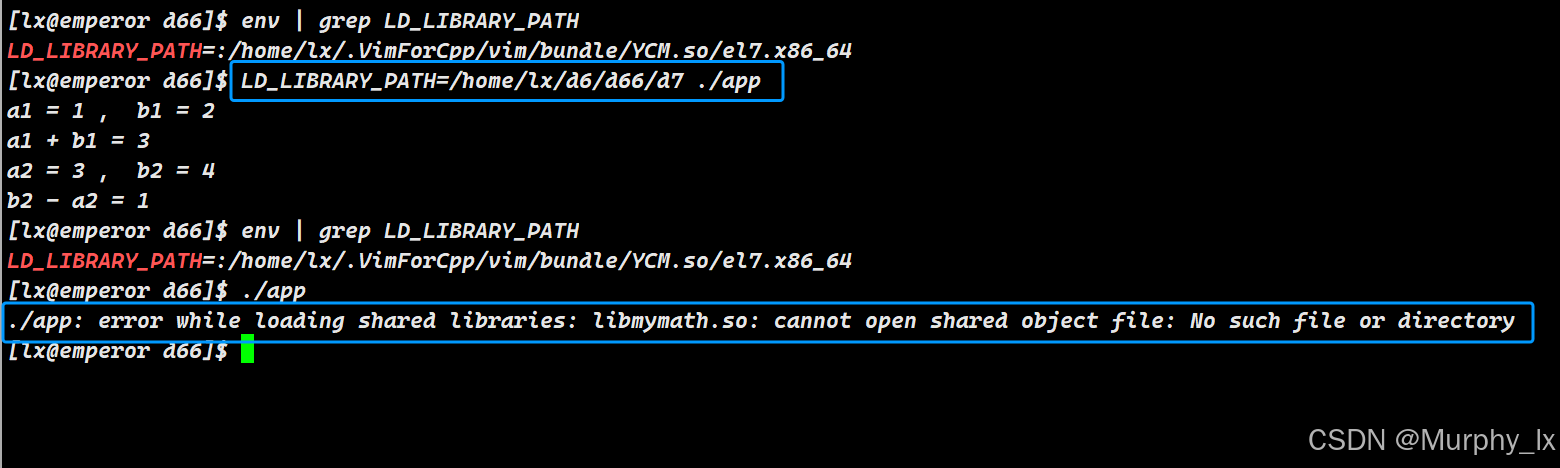
示例:
# 假设库文件在 /home/user/code/mylibs export LD_LIBRARY_PATH=/home/user/code/mylibs:$LD_LIBRARY_PATH ./app # 然后运行程序# 或者一行完成:定义临时环境变量并执行程序 LD_LIBRARY_PATH=/home/user/code/mylibs ./app- 两个指令的讲解:
export LD_LIBRARY_PATH=/home/user/code/mylibs:$LD_LIBRARY_PATH这句指令的作用是:将
/home/user/code/mylibs这个目录添加到LD_LIBRARY_PATH环境变量的最前面,并让这个设置在当前的 Shell 会话中永久生效。(这个设置只在当前的终端会话中有效。一旦你关闭这个终端窗口,或者重启电脑,这个设置就会丢失。)这是一种追加操作,而不是覆盖。如果你只写
LD_LIBRARY_PATH=/home/user/code/mylibs,那么LD_LIBRARY_PATH中原有的所有路径都会丢失,这可能会导致系统中的其他程序因为找不到它们需要的库而无法运行。通过...:$LD_LIBRARY_PATH的方式,你既添加了新路径,又保留了旧路径。搜索优先级:动态链接器在查找库文件时,会从左到右遍历
LD_LIBRARY_PATH中的路径。因为你把新路径/home/user/code/mylibs放在了最前面,所以程序会优先加载这个目录下的库文件。这对于覆盖系统默认的库版本(例如,用你自己编译的新版本库来测试程序)非常有用。LD_LIBRARY_PATH=: 这是要被赋值的环境变量名。/home/user/code/mylibs: 这是你想要新增的库文件搜索路径。:: 这是路径分隔符,用于分隔多个不同的路径。$LD_LIBRARY_PATH: 这是一个变量引用。$符号告诉 Shell 在这里插入LD_LIBRARY_PATH变量当前的值。
指令部分 作用 LD_LIBRARY_PATH=...定义动态链接库的搜索路径列表。 /home/user/code/mylibs新增的、优先级最高的搜索路径。 :路径分隔符。 $LD_LIBRARY_PATH引用并保留 LD_LIBRARY_PATH原有的值。export将修改后的变量导出为环境变量,使其能被所有子进程继承。
LD_LIBRARY_PATH=/home/user/code/mylibs ./app(命令级临时设置)这种写法是为单个命令临时修改环境变量。
-
执行流程:
- Shell 看到这个命令结构,它会先创建一个临时的、只用于执行
./app的环境。 - 在这个临时环境中,它将
LD_LIBRARY_PATH的值设置为/home/user/code/mylibs。 - Shell 使用这个临时环境来启动
./app进程。 ./app进程在运行时,会读到这个临时的LD_LIBRARY_PATH,并因此去/home/user/code/mylibs目录下寻找它需要的动态链接库(.so文件)。- 当
./app进程结束后,这个临时环境就被销毁了。
- Shell 看到这个命令结构,它会先创建一个临时的、只用于执行
-
对当前 Shell 的影响:完全没有影响。
如果你在执行完这行命令后,立即在同一个终端里输入
echo $LD_LIBRARY_PATH,你会发现它的值和执行命令之前完全一样,没有被改变。 -
优点:
- 干净、安全:不会污染当前 Shell 的环境。非常适合运行那些需要特定库版本或非标准库路径的程序,而又不想影响系统中其他程序的运行。
- 无需清理:命令一结束,环境自动恢复,不会留下任何痕迹。
-
适用场景:
- 运行一个需要特定动态库的第三方程序。
- 测试自己开发的程序,临时指定它加载你刚刚编译好的库文件,而不是系统中已安装的旧版本。
-
可执行文件本身的
DT_RUNPATH条目- 是什么:
DT_RPATH的现代继任者。在编译时通过链接器选项-Wl,--enable-new-dtags -Wl,-rpath=<path>指定。 - 优先级:低于
LD_LIBRARY_PATH。这是为了允许用户在运行时通过设置环境变量来覆盖开发者在编译时设置的路径,提供了更大的灵活性。 - 示例:
# 使用 --enable-new-dtags 生成 DT_RUNPATH 而不是 DT_RPATH gcc main.c -o app -L/opt/mylibs -lmylib -Wl,--enable-new-dtags -Wl,-rpath=/opt/mylibs# 使用 readelf 查看 readelf -d app | grep RUNPATH # 输出: 0x000000000000001d (RUNPATH) Library runpath: [/opt/mylibs]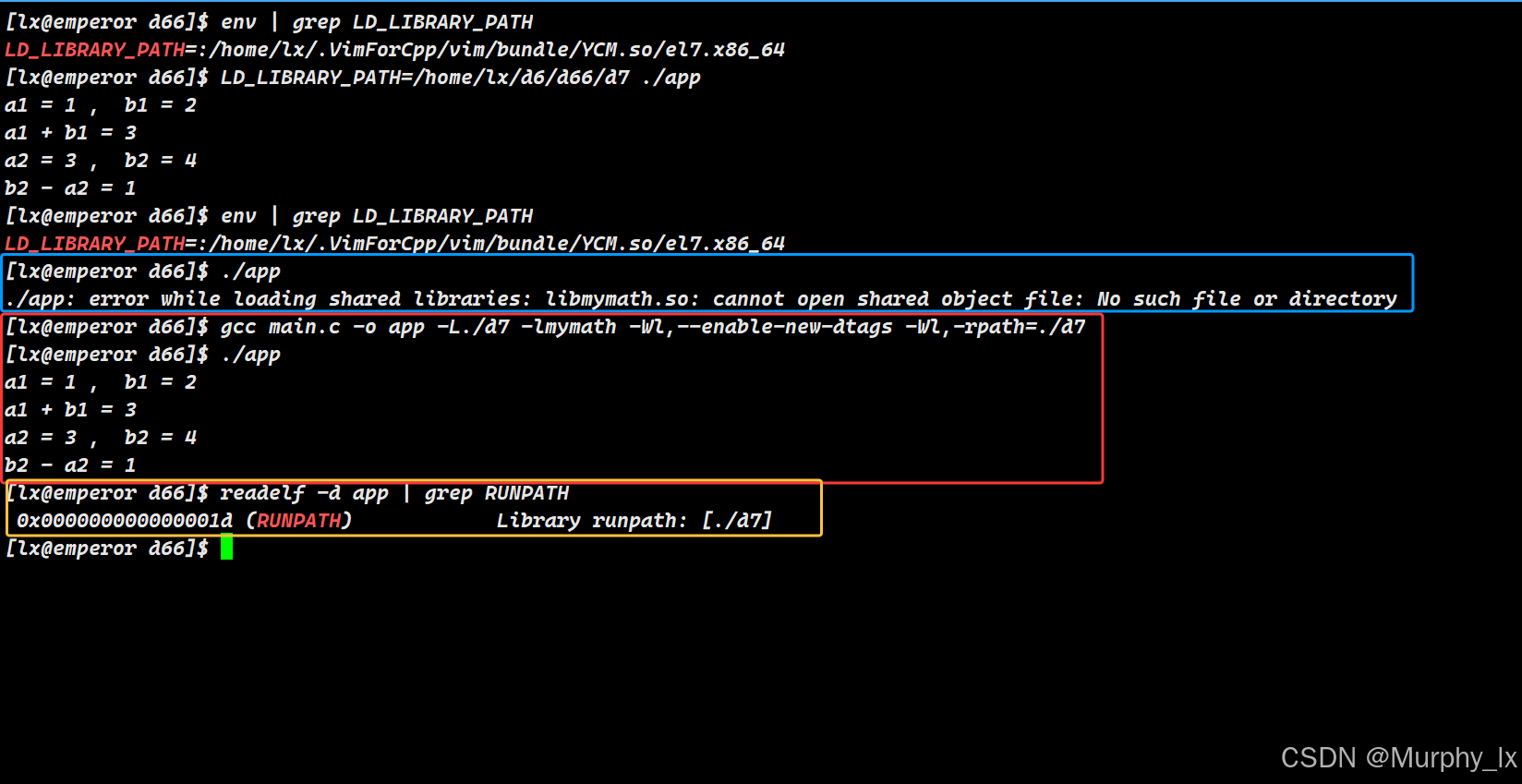
- 是什么:
-
缓存文件
/etc/ld.so.cache- 是什么:一个由
ldconfig工具生成的、经过优化的、二进制格式的缓存文件。它包含了在所有标准库目录及其配置目录中找到的库列表。 - 优先级:系统级优先级。这是系统库(如
libc.so,libpthread.so)被查找的主要方式。 - 如何更新:修改配置后,需要运行
sudo ldconfig来更新缓存。 - 示例:
# 1. 创建一个配置文件,指明你的库路径 echo '/usr/local/myapp/lib' | sudo tee /etc/ld.so.conf.d/myapp.conf# 2. 更新缓存,使配置生效 sudo ldconfig# 3. 验证缓存中是否有你的库(不一定需要库名完全匹配,主要是路径生效) ldconfig -p | grep /usr/local/myapp/lib # 或者直接运行你的app,应该可以找到了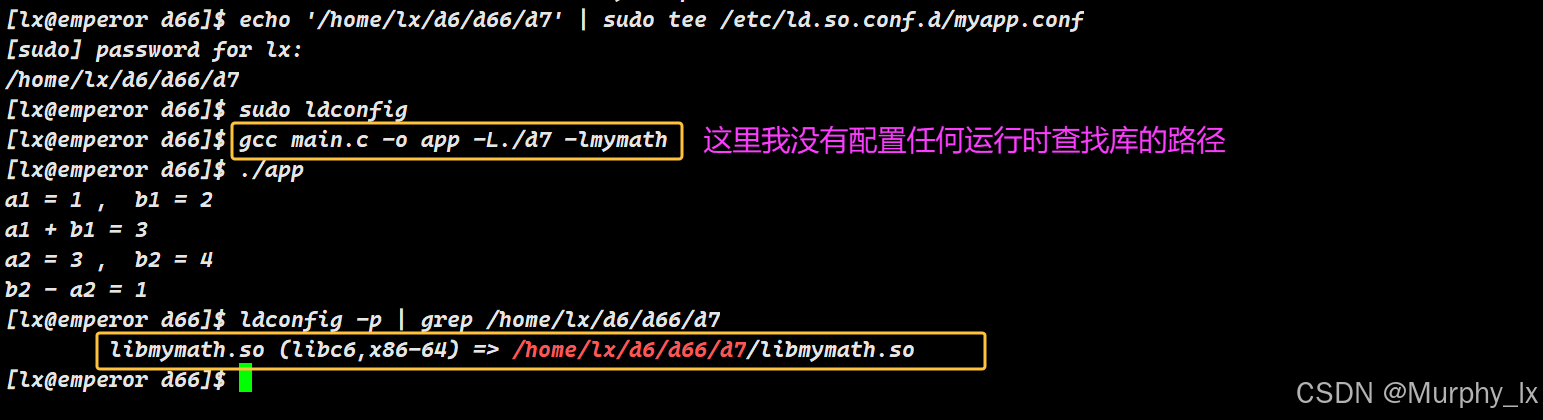
这种方法是Linux系统中指定自定义动态库搜索目录的首选和标准方法。
这种方法比设置
LD_LIBRARY_PATH环境变量更持久、更全局,比在系统目录创建软链接更规范、更易于管理。为什么这种方法更好?
- 系统级生效:对所有用户、所有程序都有效。
- 持久性:重启后依然有效,不像
LD_LIBRARY_PATH是会话相关的。 - 规范性:这是Linux系统管理共享库的标准方式,软件包管理器(如
apt、yum)在安装库时也是采用这种方式。 - 易于管理:每个软件或项目可以有自己的配置文件(如
myapp.conf),要删除搜索路径时,只需删除对应的配置文件或其中的行,然后再次运行sudo ldconfig即可,非常清晰。
重要注意事项:
- 需要 root 权限:修改
/etc/ld.so.conf.d/目录下的文件和运行ldconfig都需要sudo。 - 文件格式:确保配置文件中每行只有一个路径,并且是绝对路径。
- 运行
ldconfig:这是必须的步骤,否则修改不会生效。
- 是什么:一个由
-
默认路径
- 是什么:最后保底的搜索位置。通常是:
/lib/usr/lib/usr/lib64/usr/local/lib(在某些发行版中需要额外配置)
- 优先级:最低。只有在以上所有位置都找不到时,才会检查这里。
- 示例:(简单粗暴的做法)
# 如果你有 root 权限,可以直接将库文件拷贝到默认路径 sudo cp libmylib.so /usr/lib64/ sudo ldconfig # 更新缓存,虽然很多系统也会扫描默认路径,但运行一下更保险 ./app # 现在应该可以正常运行了不过这个行为我们是不太推荐的。我们并不推荐将一些不成熟的库放在这些默认路径上。
- 是什么:最后保底的搜索位置。通常是:
-
在默认路径创建软链接指向库文件
在系统的默认库搜索路径(如 /usr/lib或 /lib)中为你自己的库文件创建一个软链接(Symbolic Link),是一种非常经典且有效的解决方法。
这种方法的核心思想是:“欺骗”动态链接器,让它以为你自定义的库已经安装在系统标准位置。
方法原理:
动态链接器会在默认路径(如 /usr/lib)中查找 libmylib.so。如果你在该目录下创建了一个软链接 libmylib.so,并指向你实际存放库的位置(例如 /home/user/myproject/libmylib.so),那么当链接器在 /usr/lib中找到这个“假的”库文件(软链接)时,会顺着链接找到真正的库文件并加载它。
具体示例:
假设你的工作目录和文件结构如下:
/home/user/myproject/
├── app # 你的可执行程序
├── libs/
│ └── libmylib.so # 你自己编译的动态库文件
└── src/└── ... # 源代码
你的程序 app依赖于 libmylib.so,并且你希望系统能找到它。
步骤 1:检查现状(确认找不到库)
首先,确认直接运行程序会失败。
cd /home/user/myproject
./app
预期输出:
./app: error while loading shared libraries: libmylib.so: cannot open shared object file: No such file or directory
步骤 2:创建软链接(需要 root 权限)
使用 ln -s命令创建软链接。语法是:sudo ln -s <目标文件真实路径> <软链接的放置路径>
# 在系统库目录 /usr/lib 中创建一个名为 libmylib.so 的软链接,
# 该链接指向你库文件的实际位置 /home/user/myproject/libs/libmylib.sosudo ln -s /home/user/myproject/libs/libmylib.so /usr/lib/libmylib.so
步骤 3:验证结果
现在再次运行你的程序,它应该可以成功了。
./app
# 程序正常启动,没有报错
额外验证:使用 ldd命令查看
运行 ldd app,你会看到输出发生了变化:
- 创建软链接前:
libmylib.so => not found - 创建软链接后:
libmylib.so => /usr/lib/libmylib.so (0x00007f...)- 虽然
ldd显示它找到的是/usr/lib/libmylib.so,但实际上/usr/lib/libmylib.so只是一个指针,系统最终加载的是/home/user/myproject/libs/libmylib.so。
- 虽然
方法的优缺点:
优点:
- 一劳永逸:创建一次软链接后,所有用户、所有依赖该库的程序都能找到它,无需再设置
LD_LIBRARY_PATH。 - 简单直观:操作非常容易理解和实施。
缺点和注意事项:
- 需要 root 权限:向
/usr/lib或/lib目录写入文件通常需要sudo。 - 可能造成命名冲突:如果你的库名
libmylib.so和系统已存在的库重名,将会引起严重冲突,可能导致系统软件无法运行。务必为你自己的库起一个独一无二的名字。 - 管理混乱:如果有很多自定义库,都在
/usr/lib下创建软链接会使该目录变得混乱,难以管理。删除项目后,别忘了回来删除软链接,否则会成为“僵尸链接”。 - 不符合标准规范:在标准实践中,更推荐的方式是将库文件直接安装到
/usr/local/lib,或者通过/etc/ld.so.conf.d/配置文件来添加搜索路径(上文)。
二、 周边重要内容
1. 配置文件:/etc/ld.so.conf和 /etc/ld.so.conf.d/
- 缓存文件
/etc/ld.so.cache的内容不是凭空产生的,它源于一个主配置文件/etc/ld.so.conf和/etc/ld.so.conf.d/目录下的所有.conf文件。 /etc/ld.so.conf:通常很简单,只包含一行include /etc/ld.so.conf.d/*.conf。/etc/ld.so.conf.d/:这是一个目录,里面可以存放多个.conf文件。每个文件包含一行或多行自定义的库搜索路径。- 例如:如果你安装了 Intel 的数学库,可能会有一个文件
/etc/ld.so.conf.d/intel-mkl.conf,其内容是/opt/intel/mkl/lib/intel64。 - 这是向系统添加全局库搜索路径的首选方法。添加后,记得运行
sudo ldconfig。
- 例如:如果你安装了 Intel 的数学库,可能会有一个文件
2. 如何检查和调试?
-
查看程序依赖:
lddldd /path/to/your/app它会列出程序依赖的所有共享库以及系统找到它们的位置。如果某个库显示
not found,就意味着动态链接器在运行时找不到它。 -
查看可执行文件内嵌的路径:
readelfreadelf -d /path/to/your/app | grep -E '(RPATH|RUNPATH)'这可以检查程序在编译时是否被嵌入了
DT_RPATH或DT_RUNPATH。 -
手动调用动态链接器进行调试:
ldd与LD_DEBUG-
ldd其实是一个脚本,它最终调用了LD_TRACE_LOADED_OBJECTS=1这个环境变量来模拟动态链接器的行为。 -
更强大的工具是
LD_DEBUG:LD_DEBUG=libs ./app这会输出极其详细的库搜索过程,显示链接器一步一步尝试了哪些路径,成功或失败的原因是什么。这对于诊断复杂的库问题非常有帮助。(
LD_DEBUG=help ./app可以查看所有调试选项)
-
3. 为什么默认不搜索当前目录(.)?
- 安全性(Security):这是一个非常重要的安全特性。如果恶意用户在某个目录放置了一个恶意的
libc.so.6,然后诱骗你运行该目录下的某个程序(如ls),动态链接器可能会加载这个恶意库,从而获得控制权。这被称为“LD_PRELOAD”攻击的一种变体。强制使用绝对路径或明确配置的路径,极大地增加了攻击难度。 - 明确性(Explicitness):Linux 哲学强调明确性。程序的行为不应该因为它被从哪个目录调用而改变。依赖当前目录会使程序的行为变得不可预测。
三、 总结与比喻
你可以将动态链接器想象成一个严格的快递员,他的任务是按清单(可执行文件中的依赖)取货(共享库)。
- 首先,他看发货人(开发者)是否在包裹上贴了“绝对指定取货点”的纸条(
DT_RPATH/DT_RUNPATH)。 - 如果没有,他会看收货人(用户)是否给了他一个临时的取货地址单(
LD_LIBRARY_PATH)。 - 如果还没有,他就会去查询公司的官方供应商数据库(
/etc/ld.so.cache),这里面记录了所有合作仓库的位置。 - 最后,如果官方数据库里也没有,他就会去公司的总仓库(
/lib,/usr/lib)碰碰运气。 - 他绝对不会因为当前正在你家门口,就顺便去你家隔壁的仓库看看。除非你明确告诉他那个地址(通过上述任何一种方式)。
最终建议:
- 开发测试:使用
LD_LIBRARY_PATH或-Wl,-rpath='$ORIGIN'($ORIGIN表示可执行文件所在目录)。 - 生产部署:将库安装到标准路径(如
/usr/local/lib)并通过/etc/ld.so.conf.d/配置,或者使用-Wl,-rpath指定一个固定的绝对路径(如/opt/myapp/lib)。
五、 动静态库的相同与不同
| 特性 | 静态库 (.a) | 动态库 (.so) |
|---|---|---|
| 链接时机 | 编译链接期 | 程序运行期 |
| 包含方式 | 代码被复制到可执行文件 | 库名被记录,代码由系统加载 |
| 文件大小 | 大(库代码+程序代码) | 小(仅程序代码) |
| 运行时依赖 | 无,可独立运行 | 有,需确保库存在 |
| 升级/部署 | 需重新编译整个程序 | 替换库文件即可,所有程序生效 |
| 内存使用 | 多份副本(不共享) | 一份副本,多进程共享 |
| 加载速度 | 快(已在内) | 稍慢(需要查找加载) |
它们之间最大的不同是哪里?
链接的时机和代码的存在形式。静态库是“空间换便利”,动态库是“依赖换资源”。
六、 理解虚拟编址&&动态库的加载
编址这个概念主要分为两层去理解:一种是物理编址(发生在硬件层面),一种是虚拟编址(发生在操作系统或者说是软件层面)。我简单说一下物理编址主要是干什么,我们今天的重点不是这个:
- 这是什么? 这是最底层、最基础的编址概念,发生在硬件层面。
- 谁负责? 由硬件设计者(如CPU和内存条制造商)决定。
- 如何工作? CPU的地址引脚会直接输出一个电信号到内存总线(Memory Bus)上。内存控制器看到这个地址,就能在物理内存条上找到对应的、唯一的存储单元(通常是一个字节)。
- 特点:
- 唯一性:每个物理存储单元都有一个独一无二的地址。
- 直接性:CPU发出的地址直接对应物理硬件位置。
- 从0开始:系统的物理地址空间通常从0开始编址。
这个层面的编址,是后续一切软件层面地址概念的物理基础。没有这个机制,计算机就无法正常工作。
接下来我们将给大家补充一点**虚拟编址(操作系统/软件层面)**的知识,这个有助于我们理解程序的加载。
首先呢,先有几个提问:
- 虚拟地址空间中分配的虚拟地址是怎么来的?每个程序具体大小,以及程序中的内容分布都不一样,系统是如何准确的把程序中的内容分配到虚拟地址空间中合适的区域的呢?
- 程序在运行之前,也就是编译链接完成的时候就已经存在有地址吗?虚拟地址空间是否会根据程序自身的地址来进行分配呢?
- 为什么需要这样做?这样做的意义是什么?对程序加载有什么帮助?
带着这些问题,我们走入虚拟编址的大门:
Linux 下编译时的虚拟编址操作
当你在 Linux 下使用 gcc编译一个程序时,编译器(更准确地说是链接器 ld)会执行一个关键操作:它会在一个预设的、固定的虚拟地址空间布局中,为程序的各个部分(代码、数据等)分配地址。
这个过程是怎样的?
- 假设一个地址空间:链接器会假设每个程序都从一个特定的、固定的虚拟内存地址开始加载。例如,在 x86-64 Linux 系统上,默认的程序入口点(
_start)地址通常是0x400000,代码段(.text)紧随其后。 - 分配地址:基于这个假设,链接器会为每一条指令、每一个全局变量和函数分配一个具体的虚拟内存地址(Virtual Address)。
- 函数
main可能会被放在0x400500。 - 全局变量
global_var可能会被放在0x601020。 - 调用库函数
printf的指令会被编译成call 0x400710(这个地址是链接器为printf在程序空间中的“占位”地址准备的)。
- 函数
- 生成最终二进制文件:最终生成的可执行文件(如
ELF格式)中的地址,全部都是这种基于零地址偏移的虚拟地址。
一个简单的例子:
假设你有以下程序 simple.c:
#include <stdio.h>
int global_var = 42;int main() {printf("Hello, World!\n");return 0;
}
编译链接后,使用 objdump -d simple反汇编,你会看到类似这样的输出:
...
000000000040052d <main>:40052d: 55 push %rbp40052e: 48 89 e5 mov %rsp,%rbp400531: bf e0 05 40 00 mov $0x4005e0,%edi # 地址 0x4005e0 是字符串 "Hello, World!\n" 的地址400536: e8 d5 fe ff ff call 400410 <printf@plt> # 调用 printf,地址为 0x400410
...
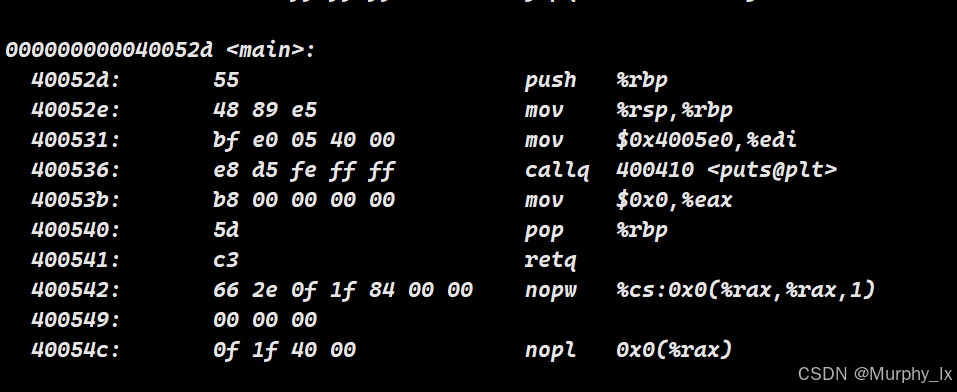
这里的 0x4005e0, 0x400410等都是虚拟地址。
为什么需要这样做?
直接在编译时使用虚拟地址,而不是等到运行时再分配,是出于以下几个核心原因:
- 效率(Efficiency):
- 如果所有地址在编译链接时就已确定,那么生成的可执行文件中,指令和数据的地址都是固定的偏移量。CPU 可以直接执行这些指令,无需在运行时进行复杂的、与位置无关的计算(尽管现代 PIC 技术部分解决了这个问题,但仍有开销)。这提高了代码的执行效率。
- 简化链接过程(Simplifies Linking):
- 当链接器将多个目标文件(
.o文件)合并成一个可执行文件时,它需要解决这些文件之间的相互引用。例如,一个目标文件中的函数调用另一个目标文件中的函数。如果有一个统一的虚拟地址空间作为框架,链接器就可以像玩拼图一样,将各个模块放到这个框架的预定位置,并轻松地修正这些交叉引用地址。如果没有这个预设框架,链接过程会变得极其复杂。
- 当链接器将多个目标文件(
- 为静态链接提供基础(Foundation for Static Linking):
- 对于静态链接,库的代码会被直接复制到最终的可执行文件中。编译时的虚拟编址使得链接器可以明确地将库代码“放置”在程序地址空间的特定区域,并确保所有对库函数的调用都被正确重定向到新的位置。
这样做的意义是什么?
这样做的意义极其深远,它是现代操作系统几乎所有高级内存管理特性的前提:
- 进程隔离(Process Isolation):
- 这是最重大的意义。每个进程都认为自己独享从
0到最大值的整个虚拟地址空间。进程 A 和进程 B 都可以在它们的虚拟地址0x400000存放代码,但这些地址通过操作系统的页表(Page Table) 映射到完全不同的物理内存地址上。一个进程无法访问甚至无法感知到另一个进程的内存内容,从而实现了天然的内存保护和隔离,极大地提升了系统的安全性和稳定性。
- 这是最重大的意义。每个进程都认为自己独享从
- 提供一致性视图(Consistent View):
- 它为程序员和编译器提供了一个稳定、可预测的内存布局模型。开发者无需关心程序具体会被加载到物理内存的哪个角落。他们只需要知道,代码从大概
0x400000开始,全局数据在0x600000附近,堆从某个地址向上增长,栈从某个地址向下增长。这种一致性极大地简化了软件开发。
- 它为程序员和编译器提供了一个稳定、可预测的内存布局模型。开发者无需关心程序具体会被加载到物理内存的哪个角落。他们只需要知道,代码从大概
- 简化调试(Simplifies Debugging):
- 调试器(如
gdb)看到的地址是虚拟地址。由于这个地址空间在每次运行时都是一致的(除非使用了特殊技术如 ASLR),开发者可以轻松地设置断点、检查变量,因为这些符号的地址每次运行都是相同的(例如,变量global_var总是在0x601020),极大地简化了调试过程。
- 调试器(如
对程序加载有什么帮助?
编译时使用虚拟地址非但没有让程序加载变复杂,反而在操作系统的帮助下,使其变得极其简单和灵活:
-
位置无关的加载(Position-Independent Loading):
-
这听起来可能有点矛盾,但正是关键所在。因为编译器使用了虚拟地址,操作系统加载器(Loader)完全不必关心这些地址具体是什么。加载器的任务变得非常机械:
a. 为新的进程创建一个独立的页表。
b. 读取可执行文件的各个段(Code, Data, BSS 等)。
c. 在物理内存中找一些空闲的页帧(Page Frames)。
d. 将程序的段映射到这些物理页上,并在页表中建立虚拟地址 → 物理地址的映射关系。
-
程序可以被加载到物理内存的任意位置,只要操作系统通过页表“欺骗”程序,让它以为自己就在
0x400000开始的地址上运行。这个过程就是重定位(Relocation) 的终极形式,由硬件(MMU)在运行时透明地完成。
-
-
共享库(Shared Libraries):
- 动态库(
.so文件)也是被编译器用虚拟地址编译的。当多个进程共享同一个动态库时,操作系统只需将同一份物理内存中的库代码映射到不同进程的虚拟地址空间中即可。虽然每个进程看到的库代码虚拟地址可能不同,但它们都指向相同的物理内存页,从而极大地节省了内存。编译时确定的地址使得运行时进行这种复杂的映射成为可能。
- 动态库(
-
延迟加载(Lazy Loading):
- 操作系统甚至可以更进一步,利用虚拟内存机制,只在程序真正访问某些代码或数据时,才将其从磁盘加载到物理内存中( Demand Paging )。编译时确定的虚拟地址为这种高效的资源利用策略提供了可能。
总结
编译器在编译时使用虚拟地址进行操作,是一种“先规划,后执行”的策略。
- 为什么需要:为了效率、简化链接和提供静态链接基础。
- 意义:实现了进程隔离、为开发者提供一致视图、简化调试,是现代操作系统内存管理的基石。
- 对加载的帮助:它使得操作系统加载器的工作变得简单、灵活和强大,支持位置无关加载、共享库和延迟加载等高级特性。
这种“编译时虚拟编址 + 运行时硬件重定位”的组合,完美地分离了编译时和运行时的关注点,是计算机科学中“抽象”和“虚拟化”思想的典范之作。它让程序员摆脱了物理内存管理的繁琐细节,让操作系统能够更高效、更安全地管理整个系统的资源。
回答问题:
问题一:虚拟地址空间中分配的虚拟地址是怎么来的?
答案是:这些虚拟地址是由编译器(和链接器)在编译链接阶段预先分配好的。
这个过程可以详细分解为:
- 链接脚本(Linker Script):这是幕后真正的“规划图”。GCC 工具链(特别是链接器
ld)内置了一个默认的链接脚本。这个脚本定义了整个进程虚拟地址空间的默认布局,例如:.text(代码段)从地址0x400000(32位系统)或0x400000(64位系统常见)开始。.data(已初始化数据段)和.bss(未初始化数据段)紧随其后。- 然后是堆(Heap)空间,向上增长。
- 栈(Stack)从用户空间的高地址(如
0x7ffffffff000)开始,向下增长。 - 共享库等会被映射到中间的特定区域。
- 编译器的角色:编译器将每个源文件(如
.c)编译成目标文件(.o)时,会生成代码和数据的雏形,并为它们分配相对于本文件开头的偏移地址。 - 链接器的角色:链接器接收所有目标文件和库,并以链接脚本为蓝图,将所有输入的目标文件的各个段(
.text,.data等)进行合并、归类,并最终在虚拟地址空间中为它们分配一个绝对的、固定的虚拟地址。
举个例子:
链接器会说:“好,现在所有目标文件的 .text段,你们就从 0x400000开始依次存放。main.o的 .text先来,占 0x400000到 0x4000FF;接着是 math.o的 .text,从 0x400100开始…”
所以,虚拟地址不是运行时随机产生的,而是链接器根据一套固定的规则预先计算和分配的。
问题二:每个程序具体大小,以及程序中的内容分布都不一样,系统是如何准确的把程序中的内容分配到虚拟地址空间中合适的区域的呢?
答案是:操作系统加载器(Loader)不关心程序“想”被放在哪里,它只关心程序“被规定”在哪里。它严格按照可执行文件中记录的信息进行映射。
这个过程的关键在于可执行文件(如ELF格式)的头部信息:
-
程序头表(Program Header Table):可执行文件中包含一个非常重要的结构,叫“程序头表”。它描述了如何将文件中的各个段(Segments)映射到进程的虚拟内存中。每个表项(Program Header)会明确告诉操作系统:
- 在文件中的偏移量(Offset):这段内容在磁盘上的可执行文件中的哪个位置。
- 应该放在虚拟内存的哪个地址(Virtual Address):这就是链接器预先分配好的虚拟地址,例如
0x400000。 - 需要多大的内存空间(Memory Size)。
- 访问权限(Flags):读(R)、写(W)、执行(X)。
-
加载器的操作:当你在 shell 中输入
./app时,操作系统的加载器(execve系统调用的一部分)会:-
读取程序头表。
-
为当前新创建的进程建立一个页表。
-
遍历程序头表,对于每一个需要加载的段(通常是类型为
PT_LOAD的段):a. 根据
Virtual Address,在进程的页表中预留出相应的虚拟地址范围。b. 找到一些空闲的物理页帧(Physical Page Frames)。
c. 建立虚拟地址 → 物理地址的映射关系,并将该段内容从磁盘文件读入对应的物理内存中。
-
这个映射过程就像是把幻灯片的每一张(文件的各个段)按照预先画好的编号(虚拟地址),精准地投影到屏幕(虚拟地址空间)的指定位置上。
-
因为所有程序都遵循同一个链接脚本约定的布局规则(代码段从 ~0x400000 开始,栈从高地址开始等),所以即使程序内容千差万别,它们的核心段在虚拟地址空间中的相对位置也是固定的。 操作系统只需要按部就班地根据文件头信息进行映射即可。
对两个核心问题的最终回答
程序在运行之前,也就是编译链接完成的时候就已经存在有地址吗?
答:是的,完全正确。 在编译链接完成后生成的可执行文件(如 ELF文件)中,代码、数据等的虚拟地址就已经被链接器确定并写死了。你可以用 objdump -d app或 readelf -S app等工具看到这些地址。
虚拟地址空间是否会根据程序自身的地址来进行分配呢?
答:是的,但需要精确理解这个过程。 操作系统加载器严格遵循可执行文件中预先定义好的地址信息来进行分配和映射。它不是主动地、智能地为程序分配合适的区域,而是被动地、机械地执行程序文件发出的“指令”(程序头表),将文件内容映射到程序“自己要求”的虚拟地址上。
总结一下:
你可以把编译链接过程想象成绘制一张建筑蓝图。
- 编译器/链接器 就是建筑师,他在蓝图(可执行文件)上规定好了:“客厅(.text段)必须盖在土地的东经100度(虚拟地址0x400000),卧室(.data段)紧挨着客厅…”。
- 操作系统加载器 就是施工队。它拿到蓝图后,不会质疑为什么客厅要盖在100度。它会严格按照蓝图,在虚拟地址空间这片“土地”上,从东经100度开始,把客厅(代码段)给“盖”(映射)起来。
这种“编译时预定地址 + 运行时按图映射”的机制,是实现进程隔离、内存保护以及运行一致性的基础。
动态库加载与多进程共享详解
一、 动态库的加载过程
动态库的加载是一个分为两步的“按需”过程,核心在于 “映射”而非“复制”。
第 1 步:编译时 - 建立依赖关系
编译器在链接时,不会将库代码复制到可执行文件中,而是:
-
记录下该程序需要哪些动态库(例如
libc.so.6,libmymath.so)。 -
在可执行文件中创建一个 “待办事项清单”(例如 ELF 文件中的
.dynamic段)。结果: 生成一个“不完整”的可执行文件,它知道自己需要什么,但不知道这些东西在哪。
第 2 步:运行时 - 加载与链接
当你运行程序时,操作系统的加载器(Loader) 和动态链接器(ld-linux.so) 开始工作:
- 加载主程序: 将可执行文件的代码段、数据段等映射到进程的虚拟地址空间。
- 解析依赖: 读取“待办事项清单”,发现需要
libmymath.so。 - 查找库文件: 动态链接器按照我们之前讨论的规则(
RPATH,LD_LIBRARY_PATH,/etc/ld.so.cache, 默认路径)在磁盘上找到libmymath.so文件。 - 映射库文件: 这是最关键的一步!动态链接器将
libmymath.so的代码段映射到进程的虚拟地址空间中。请注意:- 不是将整个文件读入内存!
- 而是建立一个内存映射(Memory Mapping),将库文件的一部分(主要是代码段和只读数据)直接映射到进程的虚拟内存区域。
- 此时,这些数据还停留在磁盘上,只是占用了进程的虚拟地址空间。
- 重定位: 修正程序中对动态库函数的所有引用,将其指向刚刚映射的虚拟地址。
- 执行: 控制权交给程序的
main函数,程序开始执行。
当程序执行到调用动态库中的函数时:
- 如果该代码页尚未被加载到物理内存,CPU 会产生一个缺页异常(Page Fault)。
- 操作系统捕获这个异常,然后从磁盘上的
libmymath.so文件中将对应的代码页加载到物理内存中。 - 然后恢复进程的执行。
- 这个过程就是 “按需调页(Demand Paging)” ,避免了程序启动时就加载所有无用代码的开销。
下图直观地展示了一个进程加载动态库的过程:
┌─────────────────────────────────────────────────┐│ 进程的虚拟地址空间 ││ ││ ┌─────────────────┐ ┌─────────────────┐ ││ │ app的 │ │ libmymath.so │ ││ │ 代码段 │ │ 的代码段 │ ││ │ (RX权限) │ │ (RX权限) │ ││ └─────────────────┘ └─────────────────┘ ││ ▲ ▲ ││ │ │ ││ └───────────┐ ┌───────────┘ ││ │ │ ││ 通过页表映射 │ │ 通过页表映射 ││ │ │ │└──────────────────────┼───┼───────────────────────┘│ │▼ ▼┌─────────────────────────────────────────────────┐│ 物理内存 (DRAM) ││ ││ ┌─────────────────┐ ┌─────────────────┐ ││ │ app代码的 │ │ libmymath.so │ ││ │ 物理页帧 │ │ 代码的物理 │ ││ │ │ │ 页帧 │ ││ └─────────────────┘ └─────────────────┘ ││ │└─────────────────────────────────────────────────┘▲ ▲│ ││ │┌──────────────────────┼───┼───────────────────────┐│ 磁盘 │ │ ││ │ │ ││ ┌─────────────────┐ │ │ ┌─────────────────┐ ││ │ app可执行文件 │ │ │ │ libmymath.so │ ││ │ │─┘ └─│ │ ││ └─────────────────┘ └─────────────────┘ ││ │└─────────────────────────────────────────────────┘
注:RX权限 = 可读(Read) + 可执行(eXecute)
二、 多进程共享同一个动态库的场景
这是动态库设计最精妙的地方,它通过共享物理内存页来极大地节省内存资源。
核心原理:
- 同一个动态库的代码段在内存中只有一份物理副本。
- 多个进程的虚拟地址空间都映射到这份相同的物理副本上。
- 每个进程都有自己的页表,操作系统通过修改不同进程的页表,让它们各自虚拟地址空间中的不同地址指向同一块物理内存。
工作流程:
- 第一个进程(Process A)加载
libmymath.so时,操作系统将库的代码段从磁盘读入物理内存。 - 第二个进程(Process B)启动,也需要
libmymath.so。 - 操作系统发现该库的代码段已经被加载到物理内存中。
- 操作系统不再从磁盘读取库文件,而是直接修改进程 B 的页表,将其虚拟地址空间中对应
libmymath.so的区域映射到与进程 A 相同的物理内存页。 - 从此,进程 A 和进程 B 共享
libmymath.so代码段的物理内存。CPU 在执行这两个进程时,会执行同一段物理内存中的指令。
下图展示了两个进程共享同一个动态库的场景:
Process A Virtual Space Process B Virtual Space┌───────────────────────┐ ┌───────────────────────┐│ │ │ ││ ┌─────────────────┐ │ │ ┌─────────────────┐ ││ │ libmymath.so │ │ │ │ libmymath.so │ ││ │ Code (VA_A) │ │ │ │ Code (VA_B) │ ││ └─────────────────┘ │ │ └─────────────────┘ ││ ▲ │ │ ▲ │└───────────│────────────┘ └───────────│────────────┘│ ││ (通过进程A的页表映射) │ (通过进程B的页表映射)│ │└───────────────┬────────────────┘▼┌─────────────────────────────────────────┐│ 物理内存 (DRAM) ││ ││ ┌─────────────────┐ ││ │ libmymath.so │ ││ │ Code (PA) │◄───────────┘│ └─────────────────┘│ │└─────────────────────────────────────────┘▲│┌───────────────┴────────────────┐│ 磁盘 ││ ┌─────────────────┐ ││ │ libmymath.so │ ││ │ 文件 (Disk) │ ││ └─────────────────┘ │└─────────────────────────────────┘
注:VA_A/VA_B = 进程A/B中的虚拟地址 (Virtual Address), PA = 物理地址 (Physical Address)
重要注意事项(写时复制 - Copy on Write):
- 代码段(只读) 可以完美共享,如上图所示。
- 对于动态库的数据段(如全局变量),每个进程都需要自己独立的副本。操作系统使用 “写时复制(COW)” 技术来实现:
- 最初,所有进程共享数据段的同一物理页(设置为只读)。
- 当任何一个进程试图写入这个共享数据段时,CPU 会触发一个权限异常。
- 操作系统捕获该异常,然后为该进程单独复制一份物理页作为其私有副本,并将其页表项改为指向新副本且具有可写权限。
- 这样,只有在真正需要的时候才会复制数据,最大限度地节省了内存。
总结与优势
通过这种映射和共享机制,动态库带来了巨大优势:
- 节省内存(Memory Saving):多个进程共享库代码的同一份物理内存,大大降低了系统总内存消耗。
- 节省磁盘(Disk Saving):磁盘上只需保存一份
.so文件,所有程序都使用它。 - 易于更新(Easy Update):更新库时,只需替换磁盘上的
.so文件。下次新进程启动时,会自动加载新版本。(正在运行的进程仍需重启才能使用新库)。 - 加载速度快(Faster Loading):部分得益于“按需调页”,进程启动时无需加载整个库。
七、 完整流程示例
静态库使用完整流程(示例)
-
准备文件:
math.h:int add(int a, int b); int sub(int a, int b);add.c:int add(int a, int b) { return a + b; }sub.c:int sub(int a, int b) { return a - b; }main.c:#include <stdio.h> #include "math.h"; int main() { printf("5+3=%d\n", add(5,3)); return 0; }
-
制作静态库:
$ gcc -c add.c sub.c $ ar -rcs libmymath.a add.o sub.o -
编译链接(使用静态库):
$ gcc main.c -o app_static -I ./ -L ./ -l mymath -
检查并运行:
$ ldd app_static # 会显示 "not a dynamic executable" 或 没有libmymath依赖 $ ./app_static 5+3=8此时,即使删除
libmymath.a,app_static也能正常运行。
动态库使用完整流程(示例)
-
制作动态库(使用上面相同的
.c和.h文件):$ gcc -c -fPIC add.c sub.c $ gcc -shared -o libmymath.so add.o sub.o -
编译链接(使用动态库):
$ gcc main.c -o app_dynamic -I ./ -L ./ -l mymath -
尝试运行(会失败):
$ ./app_dynamic ./app_dynamic: error while loading shared libraries: libmymath.so: cannot open shared object file: No such file or directory -
解决运行依赖(采用修改环境变量法):
$ export LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH $ ldd app_dynamic # 此时会发现 libmymath.so 被成功找到了 -> found at ./ $ ./app_dynamic 5+3=8 -
验证独立性:
此时删除或修改
libmymath.so,再次运行./app_dynamic,行为会随之改变或报错,证明它确实在运行时依赖这个外部文件。