大模型开发 - 02 Spring AI Concepts
文章目录
- Pre
- 引言
- 1. 模型(Models):AI 的“大脑”
- 2. 提示(Prompts):与 AI 对话的艺术
- 3. 提示模板(Prompt Templates):动态生成提示
- 4. 嵌入(Embeddings):语义的向量化表达
- 5. 令牌(Tokens):AI 的“计费单位”
- 6. 结构化输出(Structured Output)
- 7. 引入外部数据:三大策略
- (1)微调(Fine-tuning)
- (2)提示填充(Prompt Stuffing)→ 即 RAG
- (3)工具调用(Tool Calling)
- 8. 检索增强生成(RAG):让 AI “读”你的文档
- 阶段一:ETL 预处理
- 阶段二:问答时检索
- 9. 评估 AI 响应:确保输出质量
- 结语

Pre
大模型开发 - 01 Spring AI 核心特性一览
引言
在当今人工智能技术飞速发展的背景下,Spring AI 作为 Spring 生态系统对 AI 能力的官方集成,为 Java 开发者提供了一套简洁、高效且可扩展的 AI 应用开发框架。本文将深入解析 Spring AI 中的核心概念,帮助开发者理解其设计思想与实现原理,从而更高效地构建智能应用。
1. 模型(Models):AI 的“大脑”
AI 模型本质上是能够处理和生成信息的算法,它们通过在大规模数据集上学习模式与规律,模拟人类的认知能力,从而完成预测、文本生成、图像合成等任务。
Spring AI 当前支持以下几类输入/输出组合的模型:
- 文本 ↔ 文本(如 ChatGPT)
- 文本 ↔ 图像(如 Stable Diffusion)
- 音频 ↔ 文本(如语音识别)
- 文本 → 向量(即“嵌入”,Embeddings)
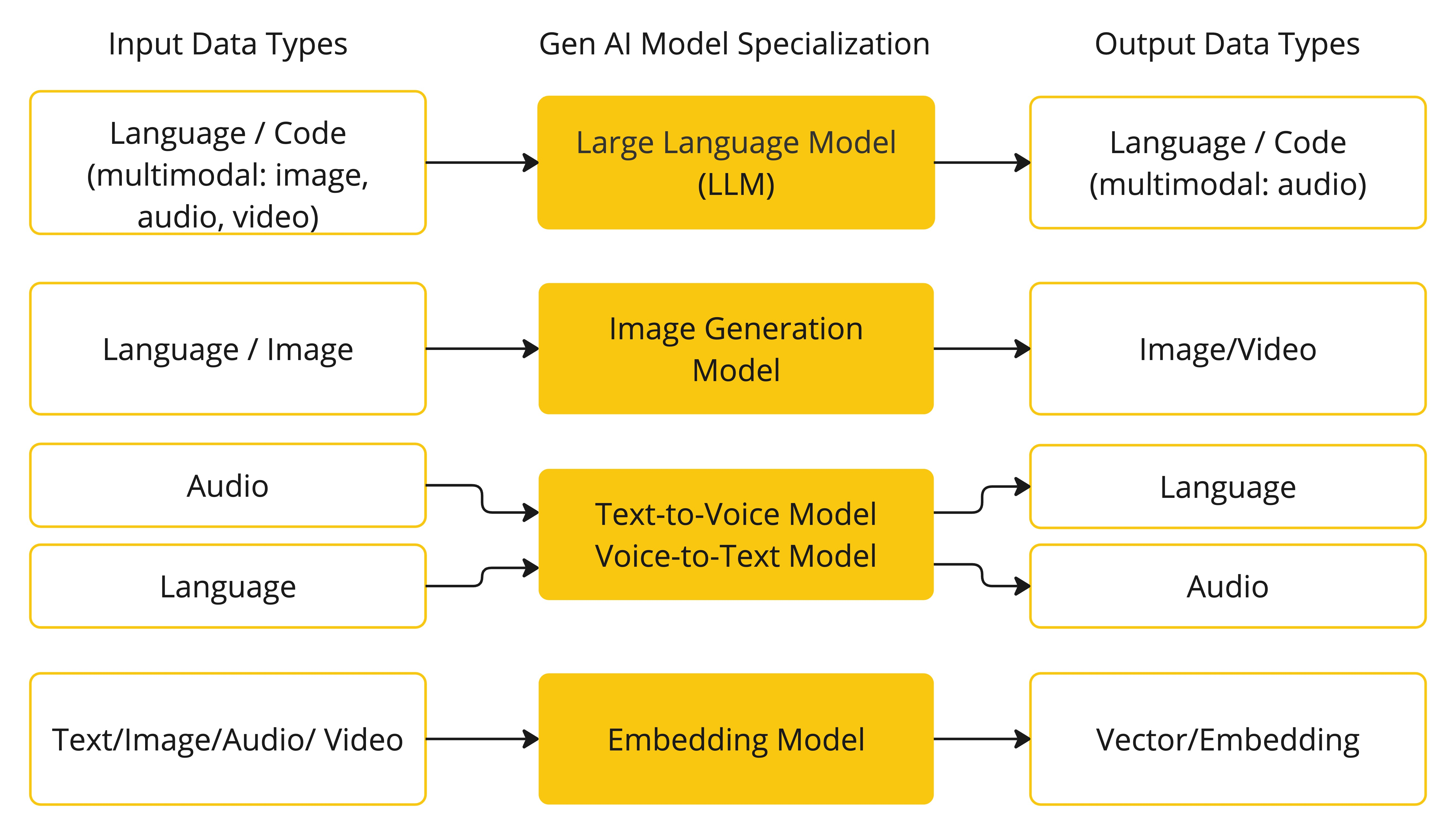
特别值得注意的是,像 GPT 这样的模型之所以强大,关键在于其 “预训练”(Pre-trained) 特性。这意味着开发者无需具备深厚的机器学习背景,也能直接利用这些通用模型构建应用,极大降低了 AI 技术的使用门槛。
2. 提示(Prompts):与 AI 对话的艺术
提示(Prompt)是引导 AI 模型生成特定输出的输入文本。在 ChatGPT 等现代大模型中,提示远不止是一段简单的字符串——它通常由多个带有“角色”的消息组成:
- system:设定模型行为准则与上下文(如“你是一个专业的法律顾问”)
- user:用户的真实提问
- assistant:模型的历史回复(用于多轮对话)
这种结构化的提示方式使得对话更自然、可控。而如何设计高效提示,已发展为一门独立学科——提示工程(Prompt Engineering)。
有趣的是,研究表明,像 “Take a deep breath and work on this step by step”(深呼吸,一步一步来)这样的提示语,竟能显著提升模型推理准确性。这说明与 AI 交流更像与人对话,而非编写 SQL 查询。
3. 提示模板(Prompt Templates):动态生成提示
在实际开发中,我们常需将用户输入动态插入提示中。Spring AI 借助开源库 StringTemplate 实现了提示模板功能,类似于 Spring MVC 中的“视图”(View)。
例如,定义一个模板:
Tell me a {adjective} joke about {content}.
通过传入 Map<String, Object>(如 {"adjective": "funny", "content": "Spring Boot"}),即可渲染出完整提示:
Tell me a funny joke about Spring Boot.
这种方式极大提升了提示的可维护性与复用性。
4. 嵌入(Embeddings):语义的向量化表达
嵌入(Embedding)是将文本、图像等内容转换为高维浮点数向量的技术。这些向量能捕捉语义信息:语义越相近的内容,其向量在空间中的距离越近。
例如,在一个语义空间中,“猫”和“狗”的向量距离,会比“猫”和“汽车”更近。
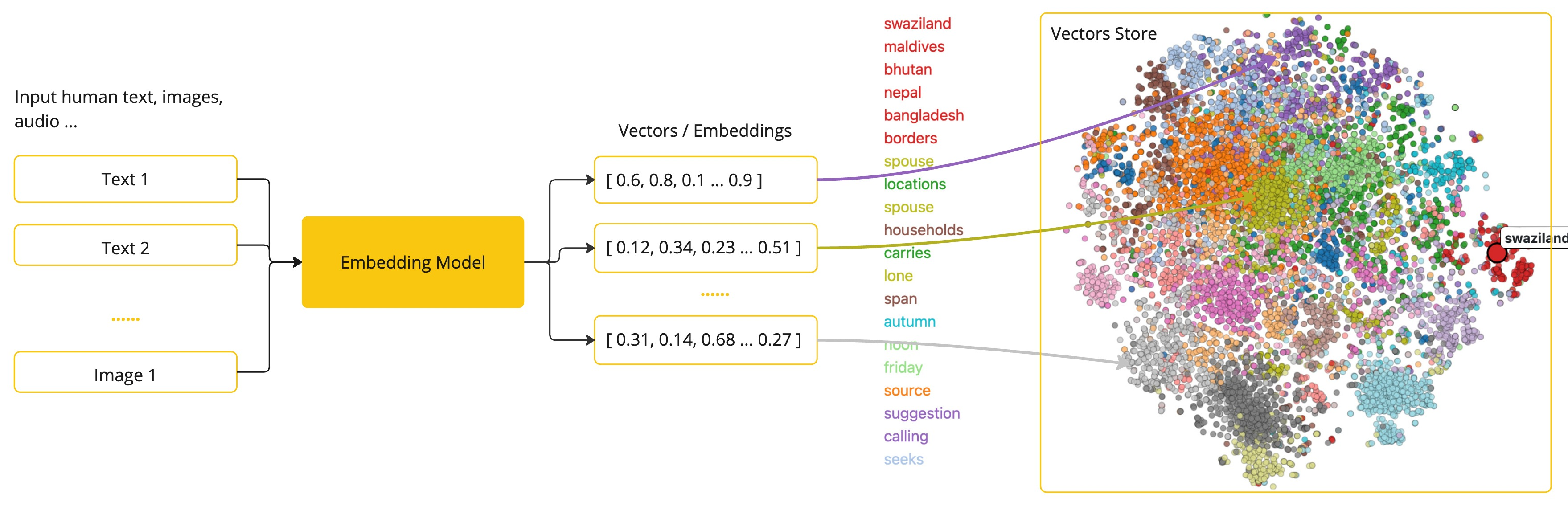
Spring AI 对嵌入的支持,为 检索增强生成(RAG) 等高级应用场景奠定了基础。开发者无需深究背后的数学原理,只需理解:嵌入 = 语义的数字指纹。
5. 令牌(Tokens):AI 的“计费单位”
AI 模型以 令牌(Token) 为基本处理单元。在英文中,1 个 token 大约等于 0.75 个单词。例如,莎士比亚全集约 90 万词,对应约 120 万 tokens。

关键点:
- Tokens = 成本:API 调用费用通常按输入+输出的总 token 数计费。
- 上下文窗口限制:模型一次能处理的 token 数有限。例如:
- GPT-3.5:4K tokens
- GPT-4:8K / 16K / 32K
- Claude:100K
- 最新研究模型:高达 1M tokens
Spring AI 提供了分块(chunking)策略,帮助开发者自动将长文本切分,适配模型上下文限制。
6. 结构化输出(Structured Output)
尽管我们可以要求模型“返回 JSON”,但其输出本质上仍是 字符串,而非真正的 JSON 对象。这导致解析不可靠,尤其在生产环境中。
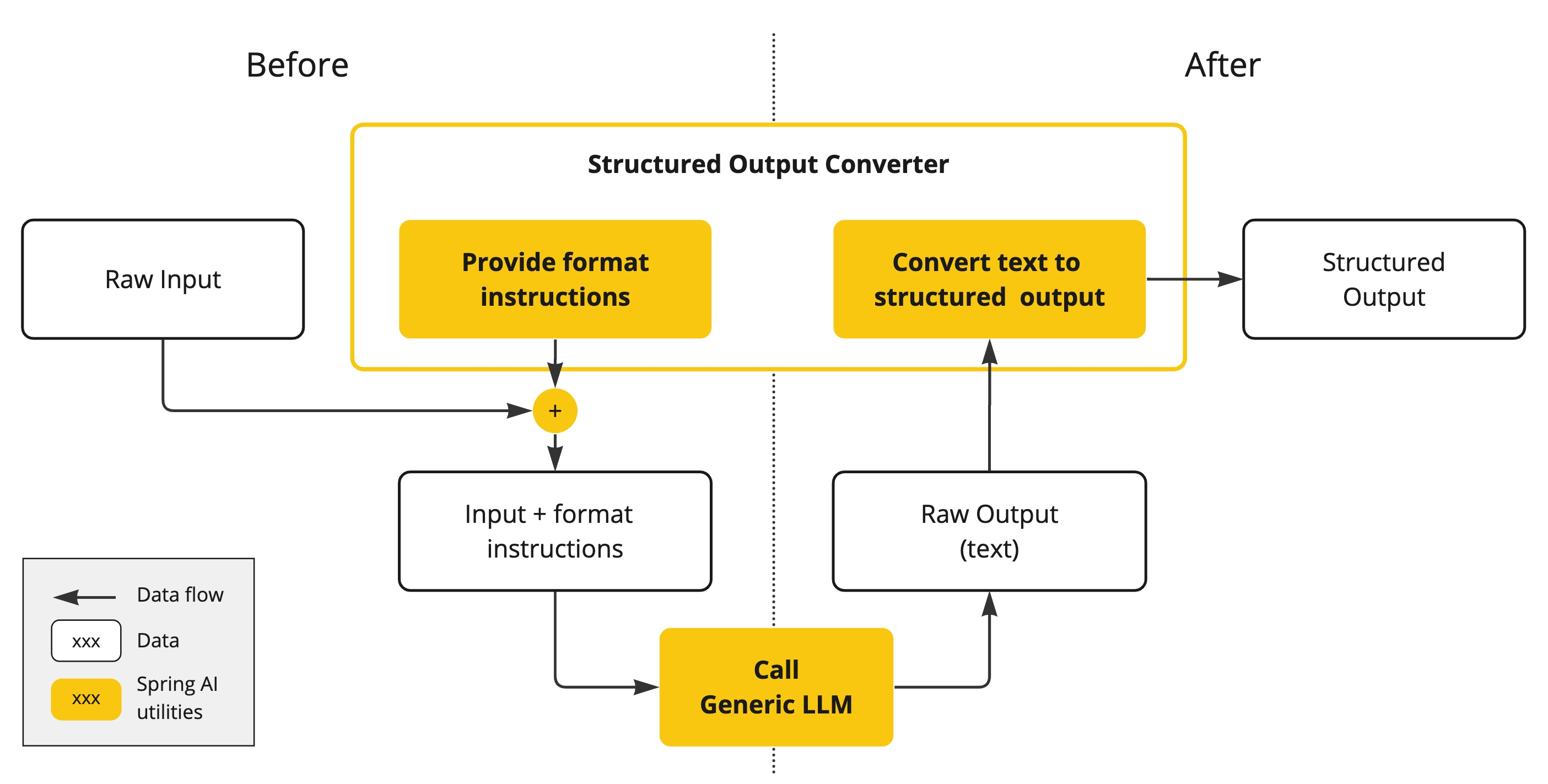
Spring AI 通过 结构化输出转换器(Structured Output Converter) 解决此问题:
- 使用精心设计的提示引导模型输出规范格式
- 自动将字符串解析为 Java 对象(如 POJO)
- 支持多轮交互以确保格式正确
这大大简化了 AI 输出与业务逻辑的集成。
7. 引入外部数据:三大策略
大模型的知识截止于训练数据(如 GPT-3.5 截至 2021 年 9 月),如何让其“知道”你的私有数据?Spring AI 支持三种方式:
(1)微调(Fine-tuning)
修改模型内部参数,成本高、技术门槛高,且部分模型不开放此功能。
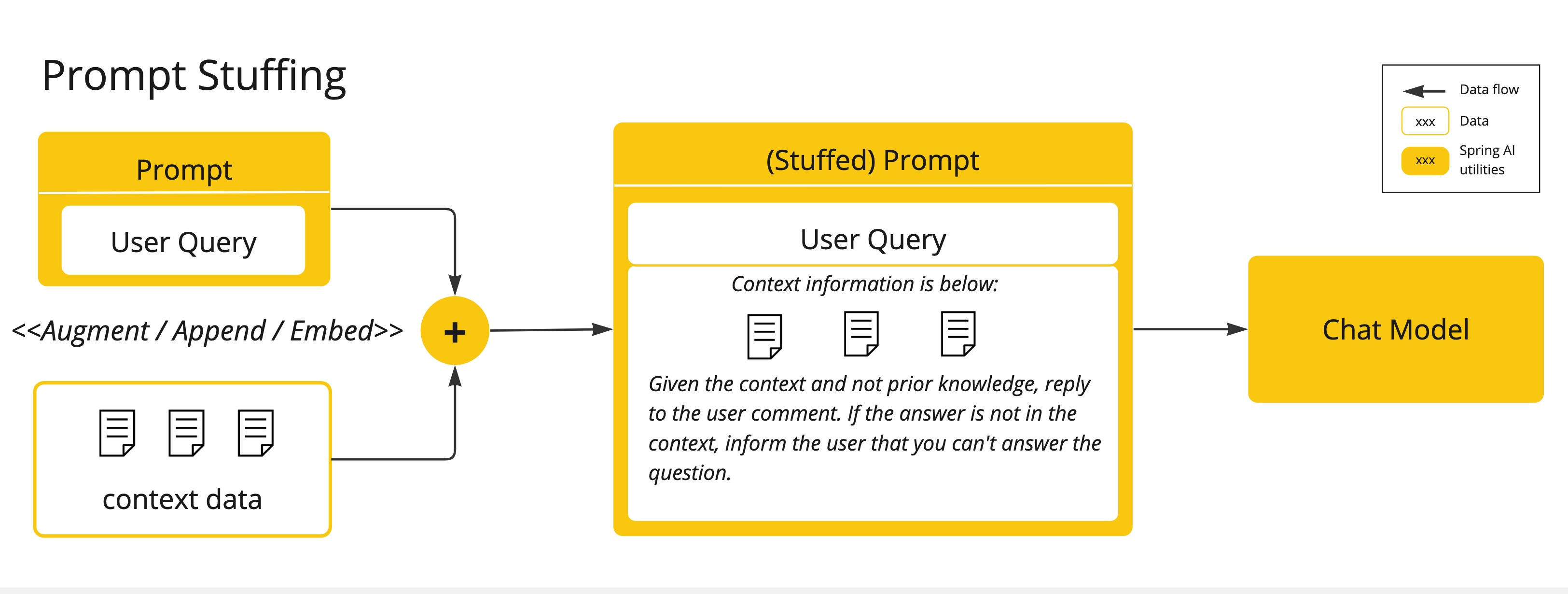
(2)提示填充(Prompt Stuffing)→ 即 RAG
将相关数据动态插入提示中。受限于 token 上限,需结合向量数据库检索最相关内容。
(3)工具调用(Tool Calling)
注册自定义服务(如数据库查询、API 调用),让模型在需要时主动调用。
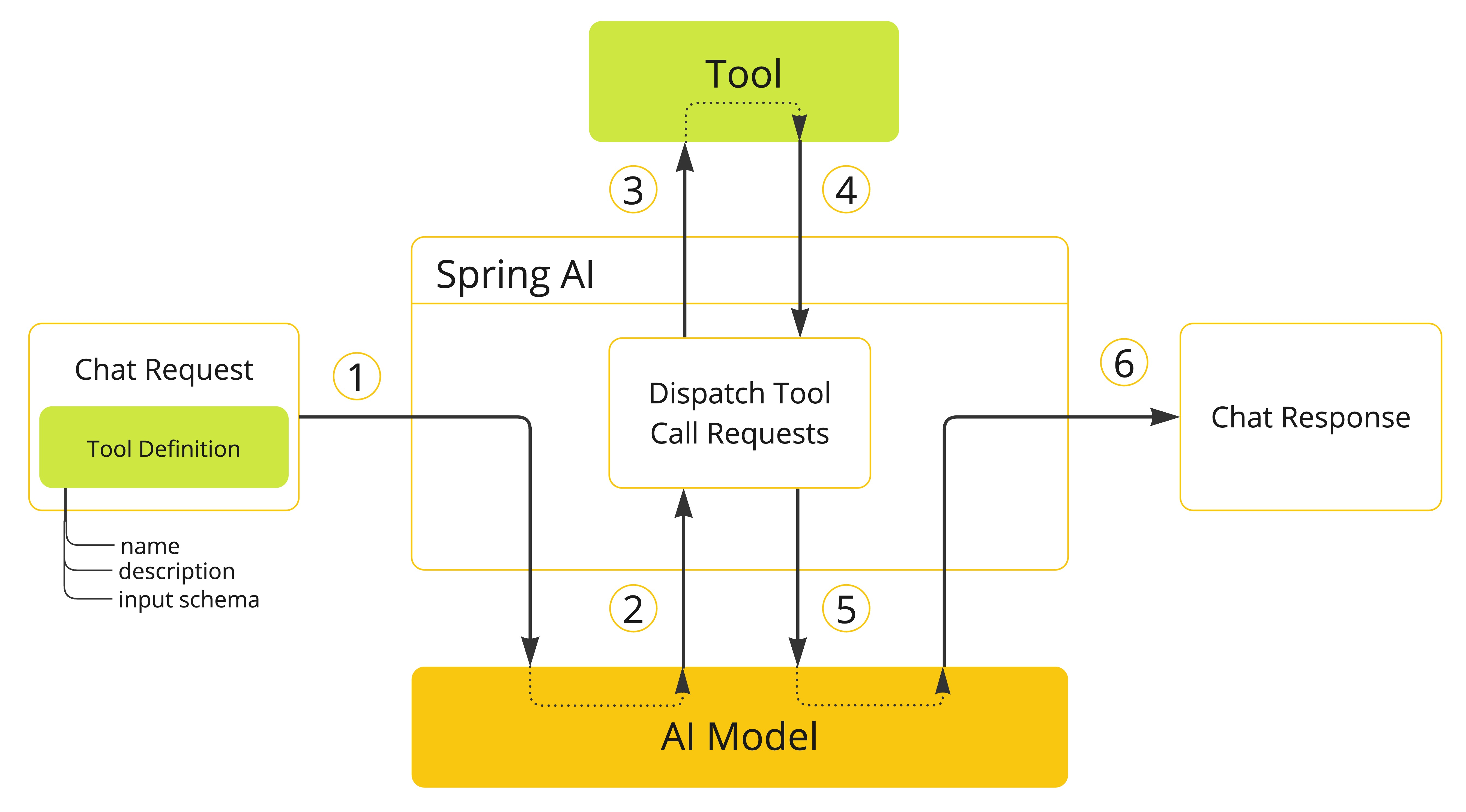
Spring AI 通过 @Tool 注解极大简化了实现:
@Tool("获取当前天气")
public String getWeather(String city) {// 调用天气 API
}
模型可自动识别工具、传参、执行并整合结果。
8. 检索增强生成(RAG):让 AI “读”你的文档
RAG 是当前最实用的私有数据集成方案,其流程分为两阶段:
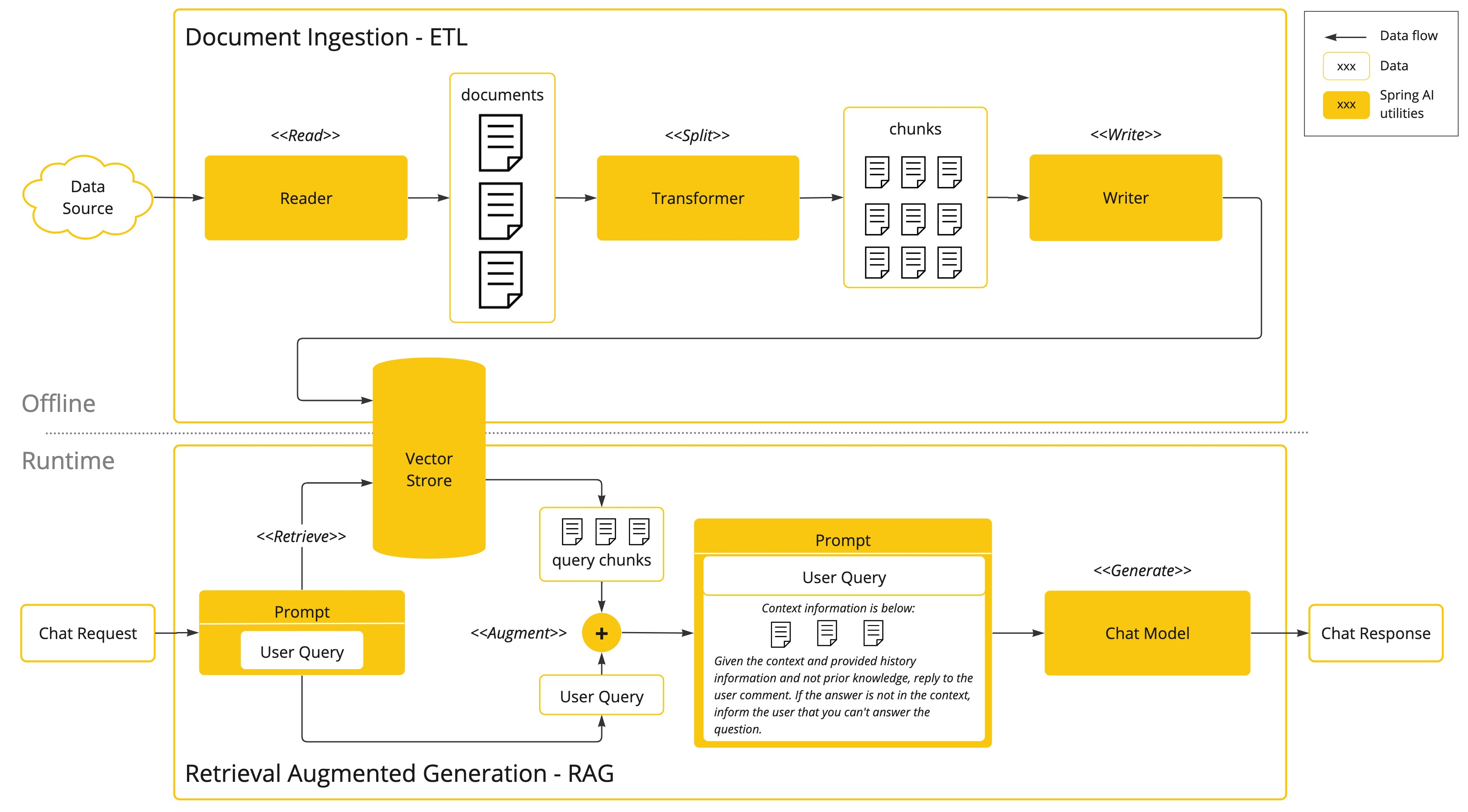
阶段一:ETL 预处理
- 提取:从 PDF、Word、数据库等源读取文档
- 切分:按语义边界(如段落、表格)分割文本,避免截断
- 嵌入:将每段文本转为向量
- 存储:写入向量数据库(如 Pinecone、Milvus)
阶段二:问答时检索
- 用户提问 → 转为向量
- 向量数据库检索最相似的文档片段
- 将问题 + 相关片段拼入提示,发送给大模型
- 模型基于上下文生成准确回答
Spring AI 提供了完整的 RAG 支持,包括 QuestionAnswerAdvisor 和向量存储集成。
9. 评估 AI 响应:确保输出质量
AI 输出是否准确、相关、连贯。 Spring AI 提供 Evaluator API,支持以下评估策略:
- 自我评估:让模型判断自身回答是否符合要求
- 基于向量检索的验证:比对回答与知识库内容的一致性
- 人工反馈闭环:结合业务指标持续优化提示
这为构建可靠、可信的 AI 应用提供了质量保障。
结语
Spring AI 不仅封装了大模型的复杂性,更通过模板、工具调用、RAG、评估等机制,为 Java 开发者提供了一套完整的 AI 应用开发范式。理解这些核心概念,是构建下一代智能应用的关键一步。
提示:AI 不是魔法,而是工程。最好的结果,往往来自对提示的精心设计、对数据的合理组织,以及对模型能力的清晰认知。
欢迎探索 Spring AI 官方文档,开启你的智能应用之旅!
