一、环境准备
二、爬取思路
- JS动态渲染的数据是前后端分离的, 直接通过地址无法获取到具体的数据, 需要找到数据返回的api, 然后通过requests请求api拿到数据(一般为json数据), 最后进行解析获取想要的内容
- 在浏览器开发者模式中, 选中 网络 -> Fetch/XHR, 找到api, 如下图所示:
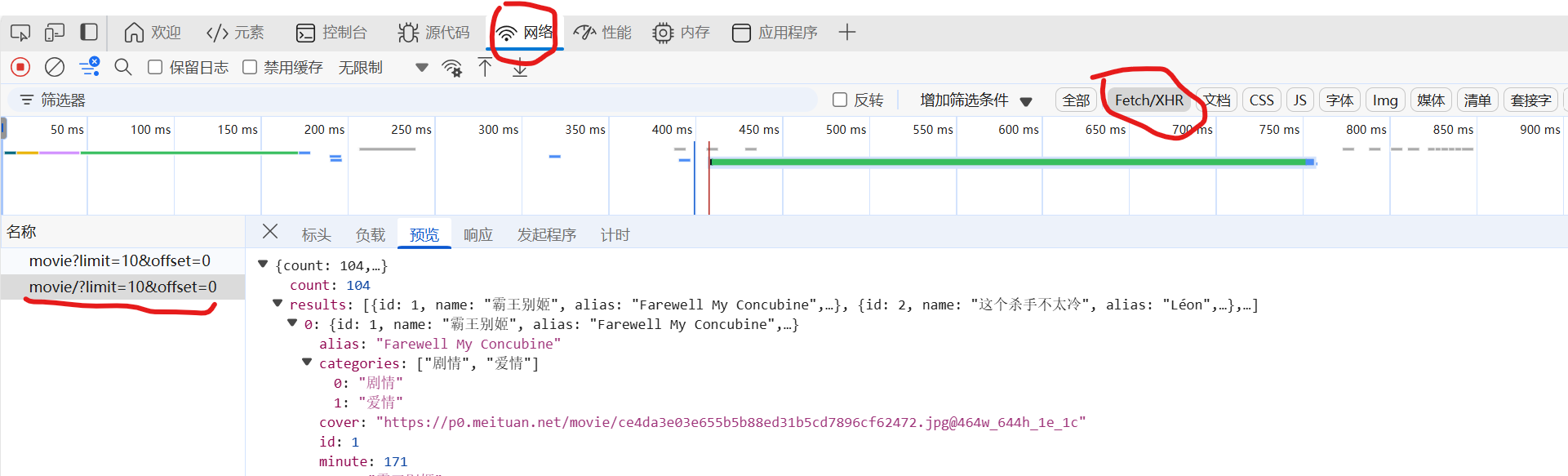
- 分析这个json结构, 解析出需要的内容
三、代码示例
import requests
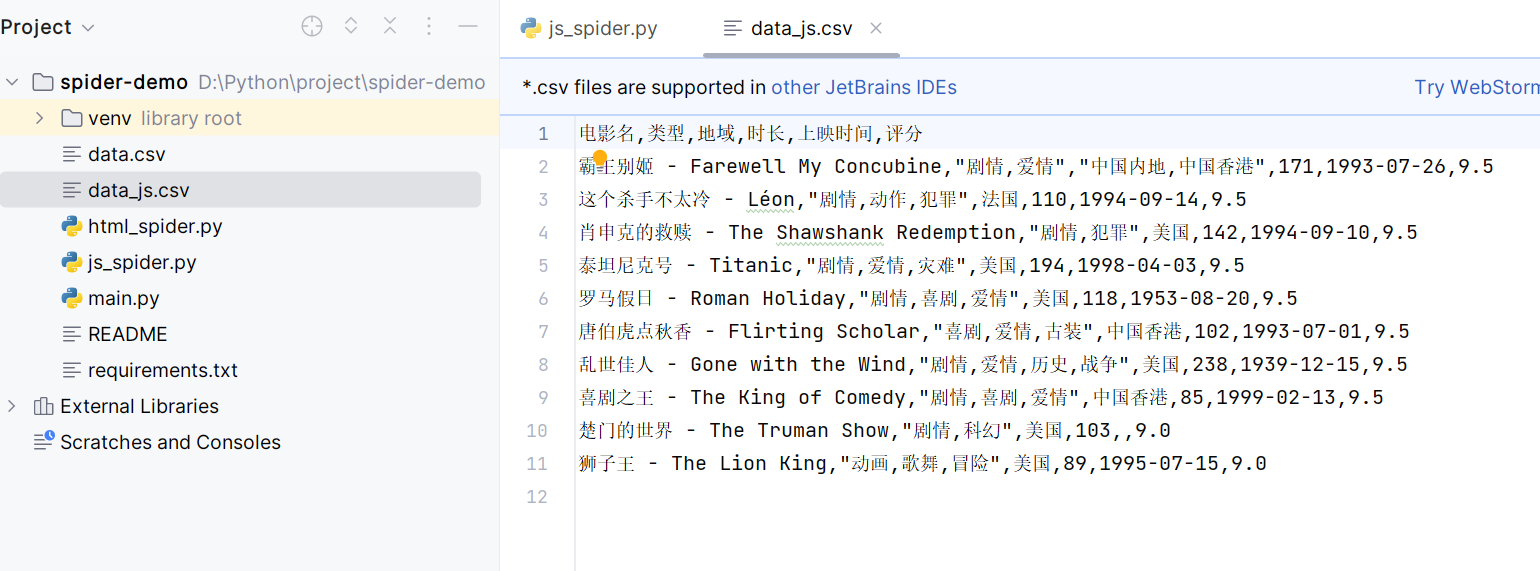
import pandas as pddef request(url):r = requests.get(url);return r.json();def parseJson(json_data):movie_list = []results = json_data['results']for result in results:movie_info = {'name': f"{result['name']} - {result['alias']}",'categories': ','.join(result['categories']),'location': ','.join(result['regions']),'duration': result['minute'],'release_date': result['published_at'],'score': result['score']}movie_list.append(movie_info)return movie_listdef save(data):df = pd.DataFrame(data);df.columns = ['电影名', '类型', '地域', '时长', '上映时间', '评分'];df.to_csv("data_js.csv", index=False, encoding='utf-8-sig');if __name__ == '__main__':jsonData = request('https://spa1.scrape.center/api/movie/?limit=10&offset=0')print(f'获取jsonData成功..')movie_list = parseJson(jsonData);print('解析json成功..')save(movie_list)print('写入文件成功...')
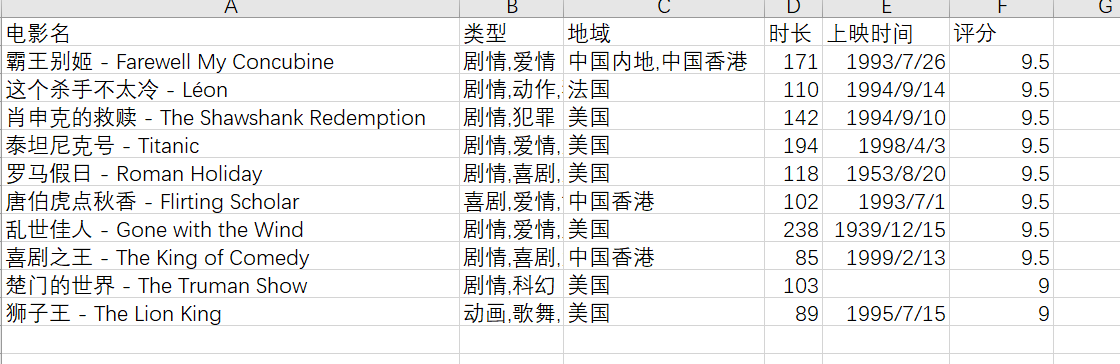
四、结果展示