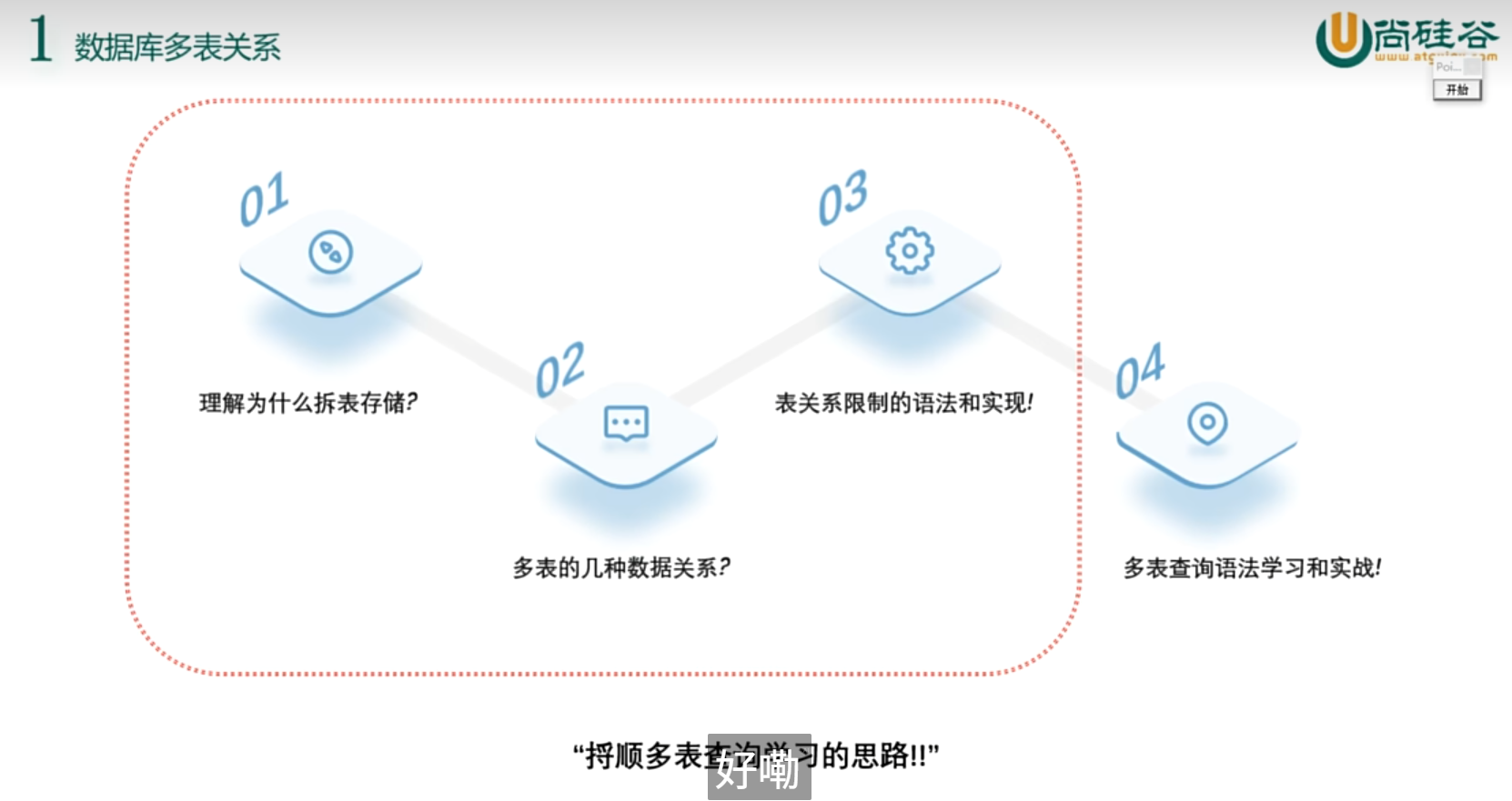
MySql速成笔记5(多表关系)

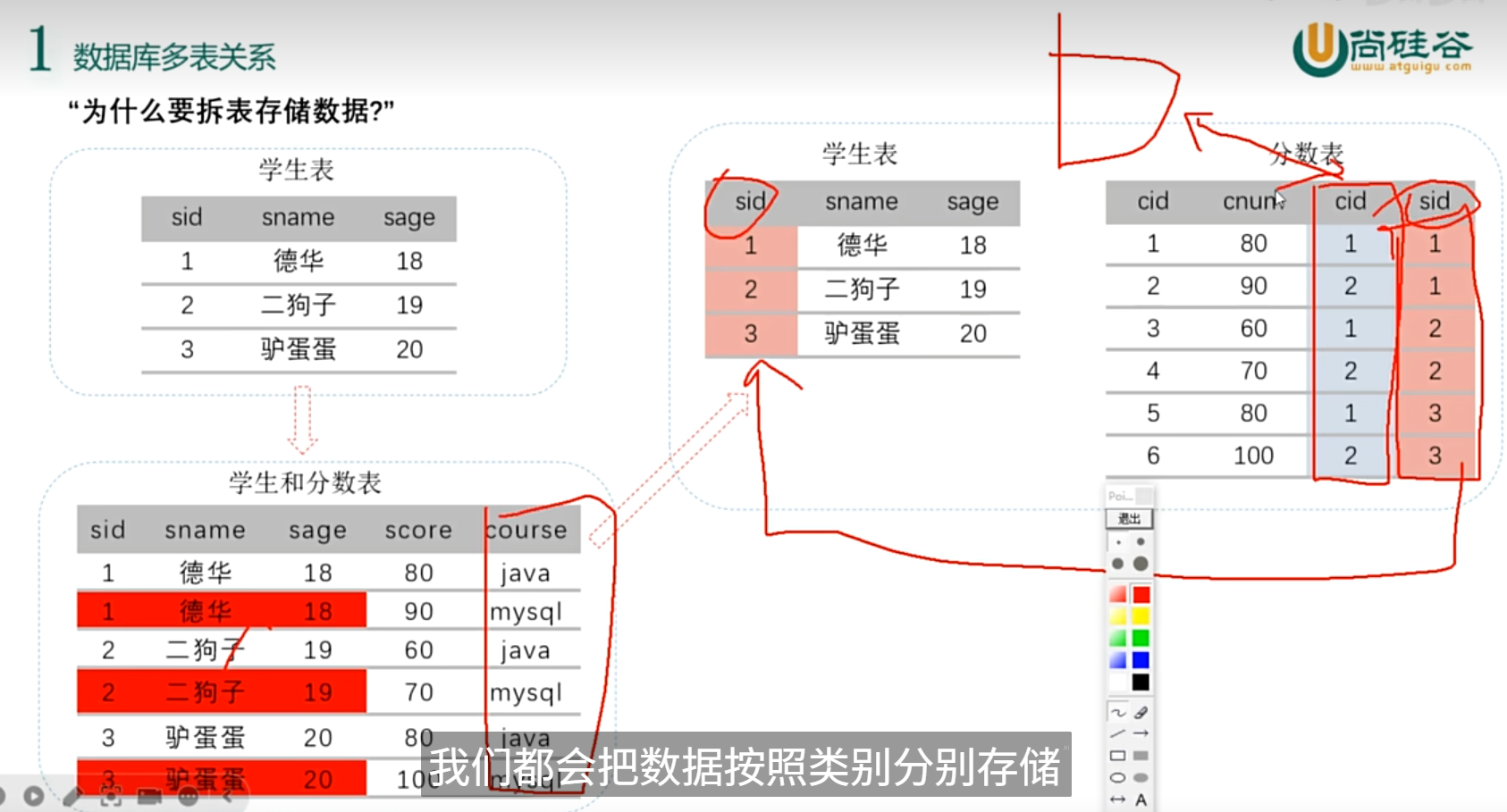
为什么要拆:解决数据冗余



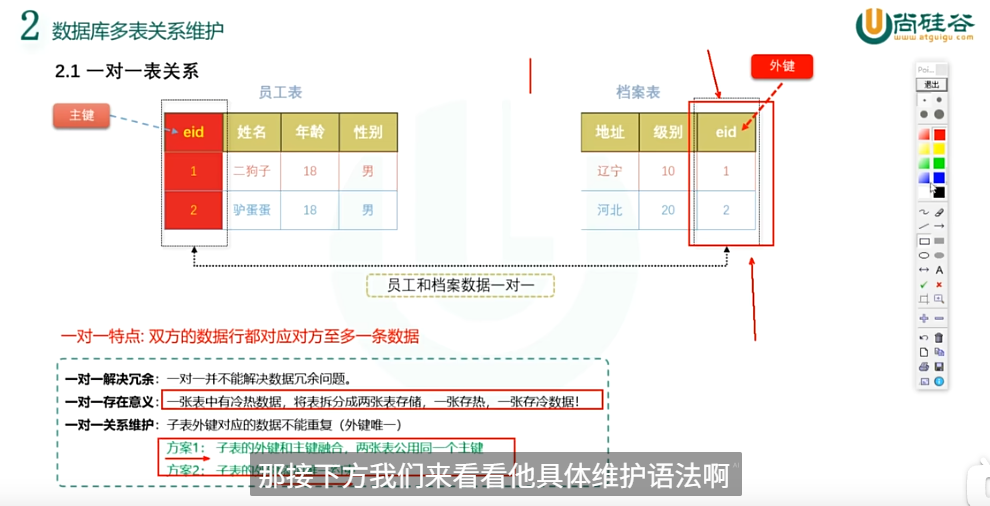
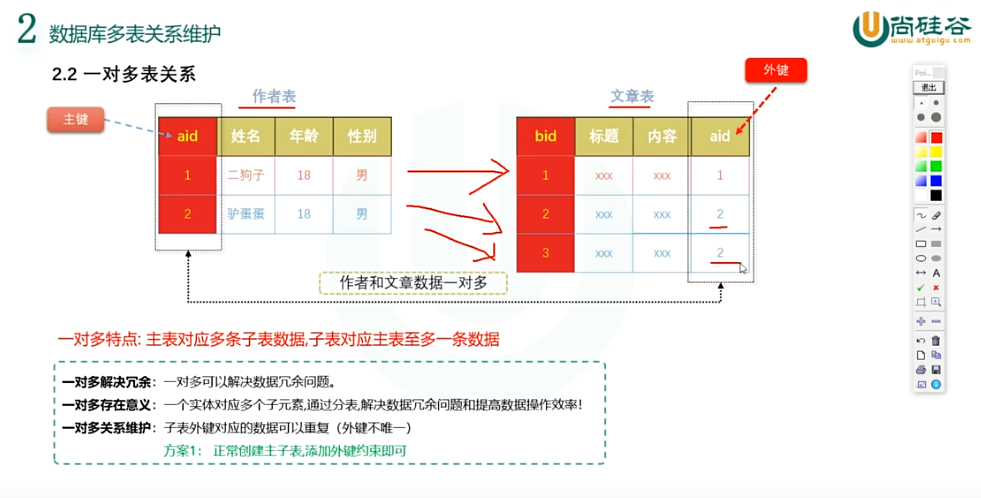
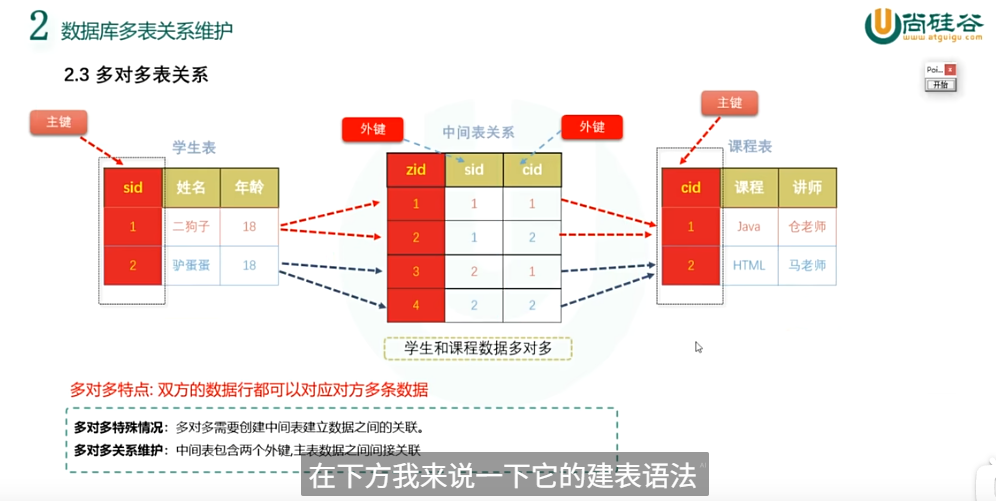
多表关系是双向查看的就是比如一对一指的是 对一对一 一对多指的是 对多对一 多对多指的是 对多对多



MySQL 中,即使查询时只读取部分字段(不涉及冗余信息),冗余数据仍可能影响查询效率,核心原因在于 冗余数据会增加 “数据存储和读取的额外开销”,这种开销与 “是否查询冗余字段” 无关。具体可以从以下几个角度理解:
1. 冗余数据增加表的物理存储量,导致 I/O 效率下降
- 表中冗余字段越多,每条记录的存储空间就越大(例如,一个表有 10 个必要字段 vs 50 个包含大量冗余的字段,单条记录大小可能相差数倍)。
- 当表的数据量增长到一定规模(比如千万级、亿级),总存储量会因冗余字段急剧膨胀(可能从 GB 级增至 TB 级)。
- MySQL 读取数据时,是以 数据页(Page,默认 16KB) 为单位从磁盘加载到内存的。冗余数据会导致:
- 每个数据页能存储的有效记录数减少(例如,原本 1 个页能存 100 条记录,冗余后只能存 20 条)。
- 查询时需要加载的页数增多,磁盘 I/O 次数增加(I/O 是数据库性能的主要瓶颈之一)。
- 即使只查询非冗余字段,也需要先把包含这些字段的整个数据页加载到内存,冗余数据会 “稀释” 有效数据的密度,间接增加 I/O 成本。
2. 索引效率受冗余数据影响
- 聚簇索引(主键索引):InnoDB 中,聚簇索引的叶子节点存储的是完整的行记录(包括所有字段,无论是否冗余)。如果表中存在大量冗余字段,聚簇索引的叶子节点会变得非常庞大,导致:
- 索引树的层级可能增加(需要更多次磁盘 I/O 才能定位到目标记录)。
- 缓存索引页的内存(Buffer Pool)利用率下降(同样的内存空间能缓存的有效索引记录更少)。
- 二级索引(非主键索引):虽然二级索引的叶子节点存储的是 “索引键 + 主键”,但回表查询(通过主键查聚簇索引获取完整记录)时,仍会受到聚簇索引庞大的影响(回表时加载的数据页更多)。
3. 数据更新和维护的额外开销
- 冗余数据往往需要保持 “一致性”(例如,用户表冗余了用户所属部门名称,当部门名称修改时,所有冗余了该名称的用户记录都需要更新)。
- 即使查询时不涉及冗余字段,更新冗余字段会导致:
- 更多的磁盘写入操作(修改冗余字段会触发整条记录的更新,包括聚簇索引和相关二级索引的维护)。
- 事务锁的范围可能扩大(更新记录时,锁的是整条记录,冗余字段越多,记录越大,锁的 “成本” 间接越高)。
- 这些更新开销会占用数据库资源,间接影响查询的响应速度(尤其是高并发场景)。
4. 统计信息偏差与执行计划低效
MySQL 的查询优化器依赖表的统计信息(如记录数、数据长度、索引分布等)来生成执行计划。
- 冗余数据会导致表的 “平均行长度” 增大,优化器可能误判查询成本(例如,认为全表扫描的代价更高,从而选择不合适的索引)。
- 极端情况下,冗余字段可能导致表的统计信息不准确,进一步影响优化器的决策,导致查询计划低效(例如,明明走索引更快,却选择了全表扫描)。
总结:冗余数据的影响与 “是否查询” 无关
冗余数据的核心问题是 “无意义地增加了数据的存储体积和处理复杂度”,这种影响是全局性的(涉及存储、I/O、索引、更新等多个环节),并非只在 “查询冗余字段时” 才体现。而分表(或规范化设计减少冗余)的作用,本质是通过缩小单表数据量、提高有效数据密度、降低 I/O 和索引开销,从根本上减少这些 “无意义的额外成本”,从而提升查询效率 —— 即使查询时只涉及部分字段,这种优化依然有效。