6.基本查询
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
新增insert
insert into 表名 (列1,列2,...) values(值1,值2,...)
插入否则更新
场景:由于 主键 或者 唯一键 对应的值已经存在而导致插入失败
语法:INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...
- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
- 1 row affected: 表中没有冲突数据,数据被插入
- 2 row affected: 表中有冲突数据,并且数据已经被更新
ROW_COUNT(); // 获取受影响的行数
替换
语法:replace into 表名 (列1,列2,...) values(值1,值2,...)
- 主键 或者 唯一键 没有冲突,则直接插入;影响行数:1
- 主键 或者 唯一键 如果冲突,则删除后再插入;影响行数:2
查找select
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...全列查询:select * from 表名 ...
指定列查询:select 列1,列2,... from 表名
查询字段为表达式:select 表达式1,表达式2, ... from 表名
为查询列起别名:select 列 [as] xxx,表达式 [as] xxx from 表名
查询去重:select distinct 列,表达式,... from 表名 //注意:distinct 紧跟select后面

where字句
比较运算符:
特别地:
- is NULL 和 is not NULL 可以比较值是不是NULL。
- = 和NULL比较时,NULL和任何数比较都是NULL
- <=>安全等于比较,NULL<=>NULL结果是1(为真)
逻辑运算符:


结果排序
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
特别地:NULL 视为比任何值都小
为什么排序时可以用字段别名,where时不能用?
where比字段列表先执行,order by比字段列表后执行
select 语句执行顺序(暂时):
1)from 表名(先定位表)
2)where字句(定位筛选条件)
3)字段列表(确认字段)
4)排序(先有合适的数据,在排序)
5)分页limit

筛选分页结果
-- 起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
UPDATE
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...][LIMIT ...]
Delete
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
注意:删除整表操作要慎用!删除数据不会改变表结构,auto_increment 计数器不会被影响。
截断表
TRUNCATE [TABLE] table_name1)只能对整表操作,不能像 DELETE 一样针对部分数据操作;
2)实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事务,所以无法回滚
3)会重置 AUTO_INCREMENT 项
数据库有日志,记录历史sql语句 或者 数据本身(2进制),bin log默认关闭。
插入select结果案例:
删除表中的重复记录,重复记录只能出现一次
1)已知原表src,创建新表dst结构与src完全一致(create table 表名 like 存在表名;)2)去重查询语句是:select distinct * from 原表;
3)执行插入语句:insert into dst(新表)去重查询语句(select distinct * from 原表);
4)将原表src重命令成别的名字例如old,新表dst重命名为src
命名操作(rename 表名 to 新表名,表名 to 新表名)
为什么最后通过rename方式进行的?就是单纯想等一切都准备就绪了,然后统一放入,更新,生效
上传文件放临时目录原因:上传文件操作不是原子的,mv移动文件是原子的。
redis not only sql 内存级数据库。

聚合函数
NULL 不会计入结果
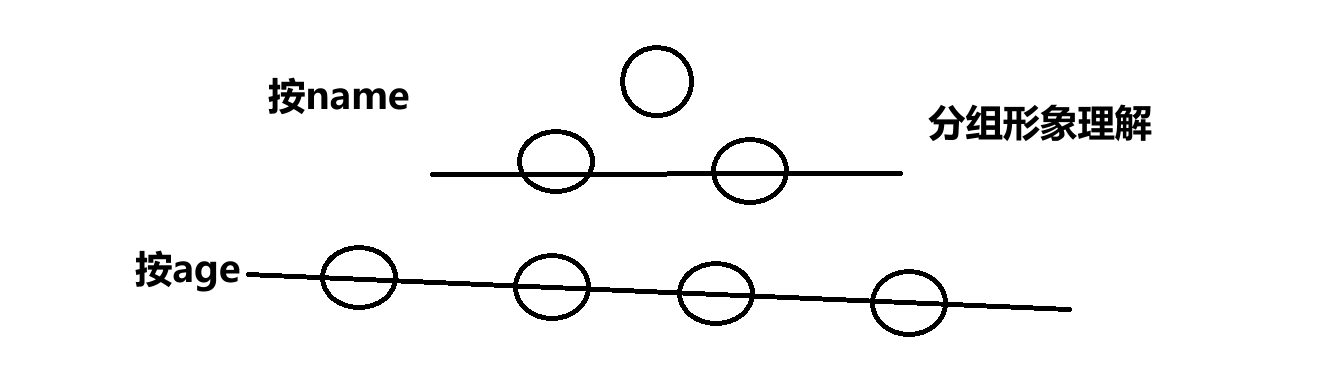
GROUP BY字句
select column1, column2, .. from table group by column;
group by搭配聚合函数进行使用,目的:为了更好的做 聚合统计。
group by本质:分组,同组内用作分组的字段值全部相同。再本质:分表,按照字段值的不同分成不同的子表(MySQL一切皆表)。
having:与group by搭配使用,用于分组后的条件筛选
where vs having
执行顺序:where 是在整个select语句的第2个执行,对任意列进行条件筛选;having是在执行完分组后,进行条件筛选。
select语句执行顺序:
1)from 表名,查询结果,...
2)where字句
3)group by 字段
4)select 字段,聚合函数结果,表达式
5)having 条件
6)order by 字段
7)limit xx,xx