论文速览:从ConvNeXt 到 ConvNeXt V2
论文链接:
[2201.03545] A ConvNet for the 2020s
[2301.00808] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
代码链接:ConvNeXt-V2/models/convnextv2_sparse.py at main · facebookresearch/ConvNeXt-V2
ConvNeXt v1
ConvNeXt 是一种现代化的纯卷积神经网络架构,通过融合视觉Transformer的设计理念和对传统卷积网络(如ResNet)的系统性改进,显著提升了视觉任务上的表现。
下图展示了从ResNet标准卷积网络到最终ConvNeXt的探索过程:
前景条表示ResNet-50/Swin-T FLOPs级别的模型准确率;灰色条表示ResNet-200/Swin-B级别的结果。带斜纹的条表示该改动未被采纳。
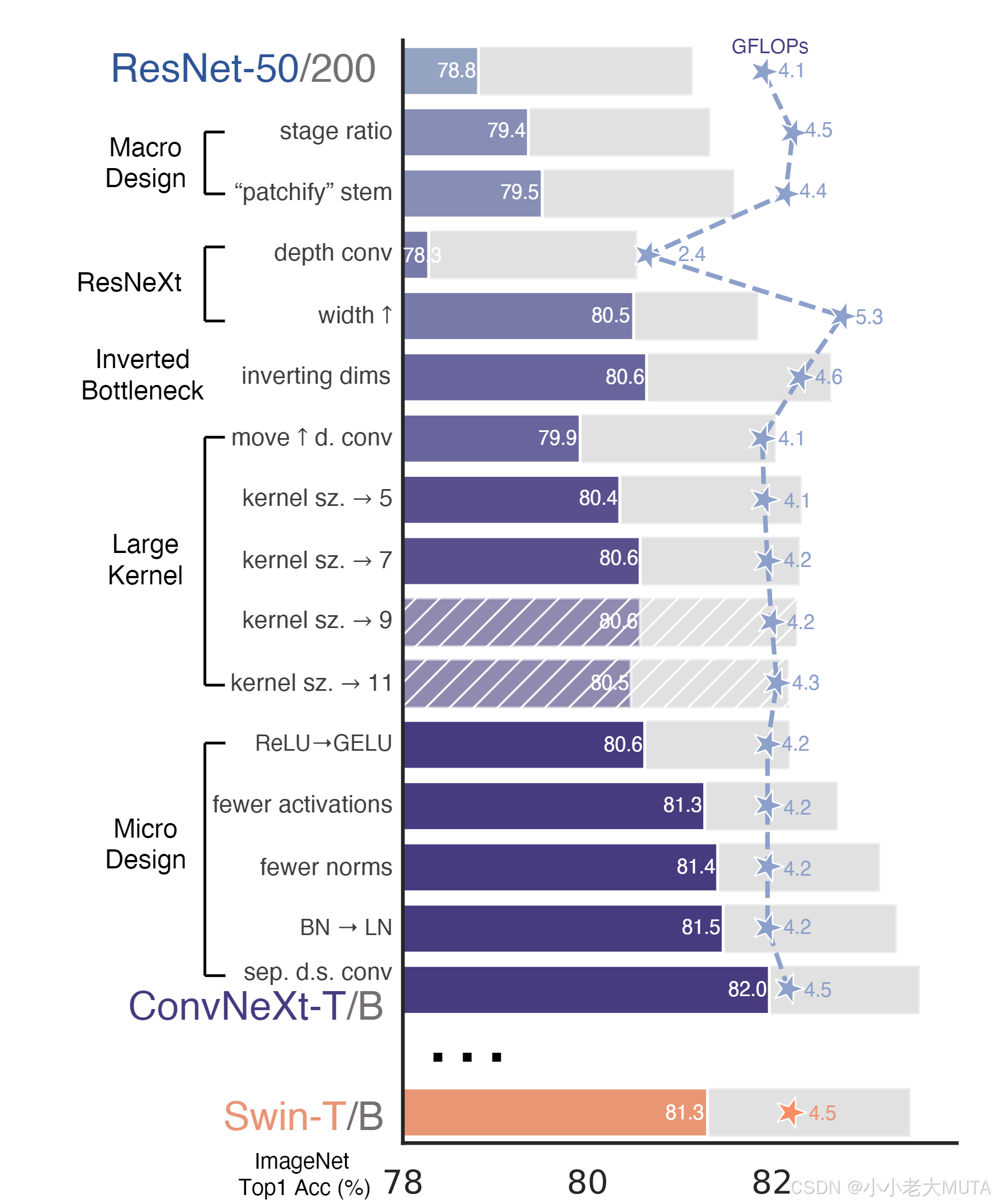
训练技巧
训练过程对最终性能也有重要影响。视觉Transformer不仅带来了新的模块和架构设计思路,还引入了不同的训练技巧(例如AdamW优化器)到视觉领域。这主要涉及优化策略及相关超参数设置。
- 训练轮数从ResNet原本的90个epoch延长到300个epoch;
- 使用AdamW优化器[46];
- 数据增强技术包括Mixup[90]、Cutmix[89]、RandAugment[14]、随机擦除[91];
- 以及包括随机深度[36]、标签平滑[69]在内的正则化策略。
仅凭改进后的训练配方,就将ResNet-50模型的性能从76.1%[1]提升到了78.8%(+2.7%),这表明传统卷积网络和视觉Transformer之间的性能差距有相当一部分其实是来源于训练技巧的不同。在整个“现代化”过程中,我们都将使用这一固定的训练配方和相同的超参数。关于ResNet-50规模的准确率,均为用三个不同随机种子训练后取平均。
1. 宏观设计
接下来分析Swin Transformer的宏观网络设计。Swin Transformer延续了卷积网络[28, 65]的多阶段设计思路,每个阶段的特征图分辨率都不同。这里有两个有趣的设计考量:阶段计算量分配比例(stage compute ratio)和“stem cell”结构。
1.1 调整阶段计算比例
ResNet各阶段的计算分配最初主要是经验性的。其中“res4”阶段占比较大,目的是兼容后续如目标检测等下游任务——检测头通常在14×14特征平面上运行。
Swin-T遵循了类似原则,但各阶段计算比例为1:1:3:1。对于更大的Swin Transformer,其比例为1:1:9:1。
参考该设计,我们将ResNet-50各阶段的模块数从(3, 4, 6, 3)调整为(3, 3, 9, 3),也使FLOPs与Swin-T保持一致。
这一步将模型准确率从78.8%提升到79.4%。值得注意的是,关于计算分配的研究[53, 54]已相当深入,可能还存在更优的设计。从这里开始,我们采用此阶段计算比例。
1.2 调整stem为“Patchify”
stem cell结构关心的是网络输入端如何处理原始图像。由于自然图像本身存在较多冗余,卷积网络和视觉Transformer都会在开头快速下采样,将输入图像缩小到合适的特征图大小。
标准ResNet的stem为一个7×7的卷积层,步幅为2,后跟max pooling,实现了4倍下采样。
Vision Transformer通常采用更激进的“patchify”策略作为stem,即较大的卷积核(如14或16),无重叠。Swin Transformer的patchify层patch size为4,以适应其多阶段设计。
我们用一个4×4、步幅为4的卷积层替换ResNet风格的stem结构,准确率从79.4%提升到79.5%。这表明ResNet的stem cell可以使用类似ViT的简单“patchify”层替换,性能基本相当。接下来我们将采用“patchify stem”(4×4无重叠卷积)结构。
1.3 ResNeXt化
尝试引入ResNeXt[87]的思想,其FLOPs与准确率的权衡优于普通ResNet。其核心是分组卷积:卷积核被分为若干组。ResNeXt的原则是“多组、扩宽度”。在瓶颈结构的3×3卷积层采用分组卷积。这样显著降低了FLOPs,因此可以通过加宽网络来弥补容量损失。
在本研究中我们使用深度可分离卷积(depthwise convolution),它是分组卷积的一种特例,组数等于通道数。Depthwise卷积被MobileNet[34]和Xception[11]等模型普及。
需要注意的是,depthwise卷积与自注意力机制中的加权求和操作类似,都是在每个通道上单独混合空间信息。Depthwise卷积和1×1卷积的结合实现了空间与通道混合分离,这与视觉Transformer只在空间或通道维度混合信息的特性一致。
引入depthwise卷积有效降低了网络FLOPs,但也会降低准确率。按照ResNeXt的策略,我们将网络宽度扩展到与Swin-T一致(从64增加到96通道),这样性能提升到80.5%,FLOPs增加到5.3G。我们将继续采用ResNeXt的设计。
2. 倒置Bottleneck
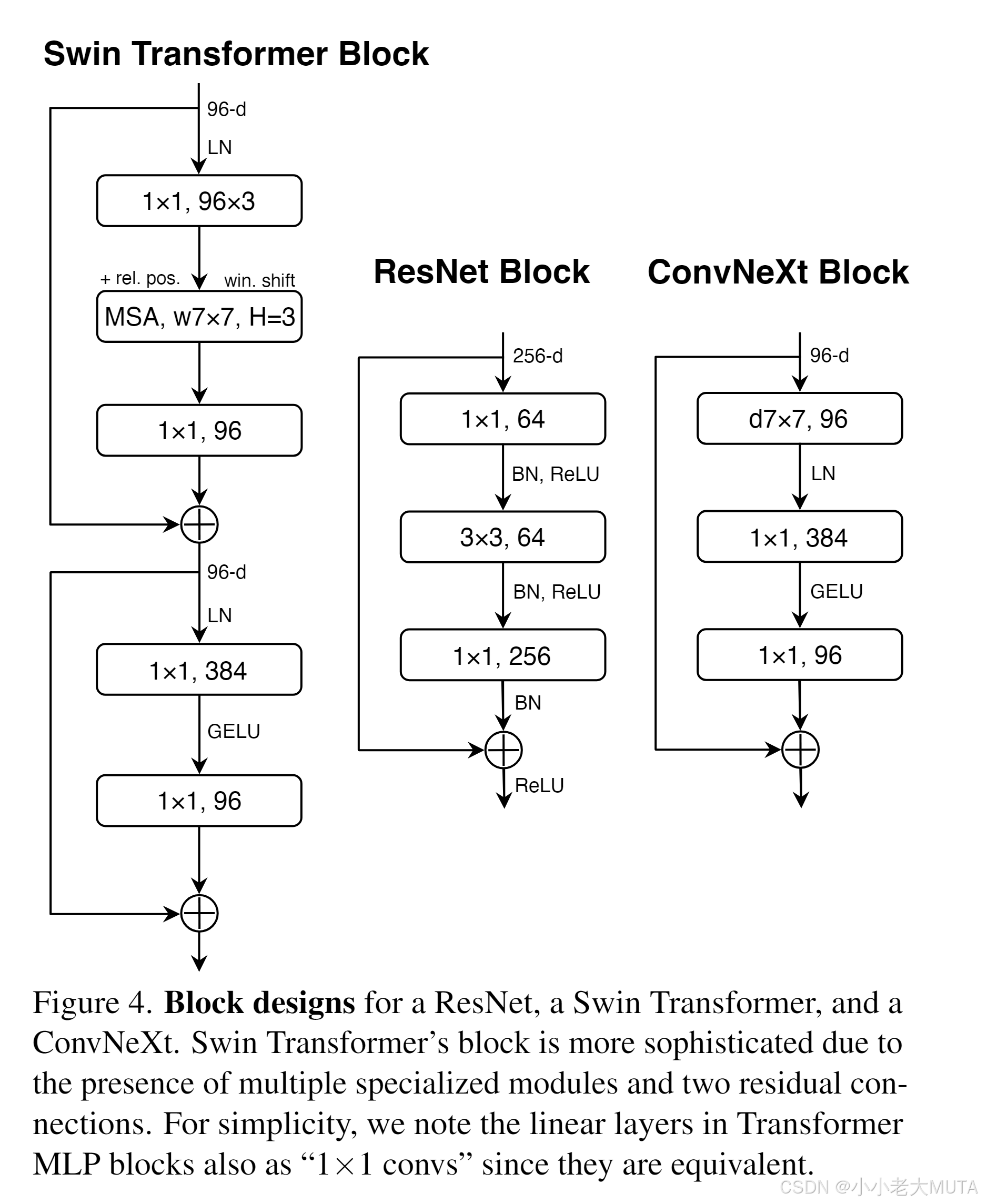
每个Transformer模块中的一个重要设计是倒置瓶颈结构,即MLP模块的隐藏层维度是输入维度的四倍(见图4)。有趣的是,这种Transformer的设计与ConvNet中采用扩展比例为4的倒置瓶颈结构相呼应。这个想法最初由MobileNetV2 [61] 推广,随后在多个先进的卷积网络架构中被广泛采用 [70, 71]。
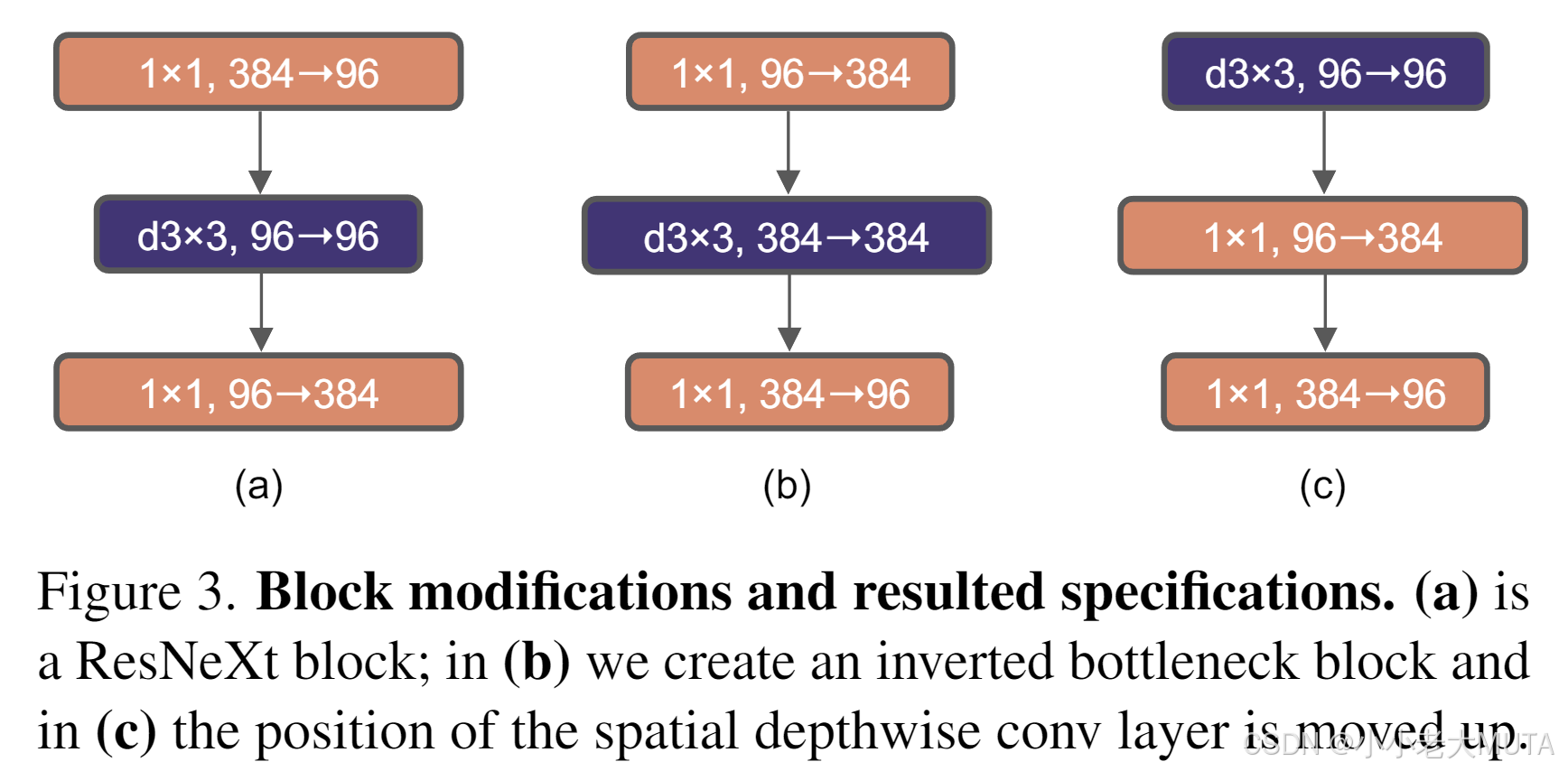
在这里,我们对倒置瓶颈结构进行了探索。图3(a)到(b)展示了相应的结构配置。
尽管这种改动使得深度可分离卷积层的FLOPs有所增加,但由于在下采样残差块中的shortcut 1×1卷积层FLOPs大幅减少,整体网络的FLOPs降至4.6G。有趣的是,这项改动使性能略有提升(从80.5%提升到80.6%)。在ResNet-200 / Swin-B规模下,这一步带来更显著的提升(从81.9%提升到82.6%),同时FLOPs也有所减少。因此,接下来我们将采用倒置瓶颈结构。
3. 大卷积核尺寸
视觉Transformer最显著的特点之一是其非局部自注意力机制,使每一层都具备全局感受野。
虽然过去卷积网络中也曾使用过大卷积核[40, 68],但广泛使用且被VGGNet[65]推广的黄金准则是堆叠小卷积核(3×3)层,这种设计在现代GPU上有高效的硬件实现[41]。尽管Swin Transformer将局部窗口重新引入自注意力模块,窗口大小至少为7×7,远大于ResNe(X)t的3×3卷积核尺寸。这里我们重新审视卷积网络中大卷积核的应用。
3.1 将深度可分离卷积层上移
探索大卷积核的一个前提是将深度可分离卷积层的位置上移(图3(b)到(c))。这一设计在Transformer中同样明显:多头自注意力(MSA)模块置于MLP层之前。由于我们采用倒置瓶颈结构,这也是自然的设计选择——复杂且计算效率较低的模块(MSA、大卷积核卷积)通道数较少,而高效且密集的1×1卷积层承担主要计算。该中间步骤将FLOPs降低至4.1G,但性能暂时下降至79.9%。
3.2 增大卷积核尺寸
在完成上述准备后,采用更大卷积核的好处显著。我们实验了3、5、7、9、11等多种核尺寸,性能从79.9%(3×3)提升至80.6%(7×7),而网络FLOPs变化不大。此外,我们观察到性能提升在7×7处达到饱和点。我们在大容量模型中也验证了这一现象:ResNet-200规模模型在核尺寸超过7×7时无进一步提升。后续我们将在每个块中使用7×7深度可分离卷积。
此时,我们完成了对网络宏观架构的研究。令人惊讶的是,视觉Transformer中的许多设计选择都可以映射到卷积网络中。
4. 微观设计
在层级上对激活函数和归一化层的具体选择进行研究。
4.1 用GELU替代ReLU
NLP和视觉架构在激活函数选择上有所不同。虽然多种激活函数被提出,卷积网络依然大量采用简单高效的ReLU[49]。原始Transformer论文[77]中也使用ReLU。而Gaussian Error Linear Unit(GELU)[32],可视为ReLU的平滑版本,被先进Transformer模型如Google的BERT[18]、OpenAI的GPT-2[52]及ViT所采用。我们发现ConvNet中ReLU可被GELU替换,准确率保持不变(80.6%)。
4.2 减少激活函数数量
Transformer和ResNet块的一个细微区别是Transformer中激活函数较少。
以Transformer块为例,关键、查询、值线性嵌入层,投影层以及MLP中两层线性层,只有MLP中有一个激活函数。相比之下,卷积网络通常在每层卷积后都加激活函数,包括1×1卷积。
我们尝试采用相同策略,即如图4所示,除两1×1卷积层之间保留一个GELU外,去除其他所有GELU层,模仿Transformer风格。此改动使性能提升0.7%,达到81.3%,几乎与Swin-T持平。此后,我们在每个块中使用单个GELU激活。
4.3 减少归一化层数量
Transformer块通常归一化层较少。我们移除两个BatchNorm(BN)层,仅保留1个位于1×1卷积层前的BN层,性能提升至81.4%,超过Swin-T的81.3%。值得注意的是,我们每块归一化层比Transformer还少,经验表明在块开始处增加BN层不会带来性能提升。
4.4 用LayerNorm替代BatchNorm
BatchNorm[38]是卷积网络中核心组件,提升收敛速度并减少过拟合,但存在一些细节问题可能对性能不利[84]。尽管有多种替代归一化技术[60, 75, 83],BN仍是视觉任务中的主流选择。另一方面,较简单的Layer Normalization(LN)[5]被Transformer广泛采用,在多个应用场景表现良好。直接将LN替换ResNet中的BN通常效果不佳[83]。在进行架构和训练策略修改后,我们重新尝试用LN替代BN,发现模型训练过程正常且性能略有提升,准确率达81.5%。因此,我们将在每个残差块中使用一个LayerNorm作为归一化层。
4.5 采用独立的下采样层
在ResNet中,空间下采样由各阶段起始的残差块实现,使用stride为2的3×3卷积(以及shortcut中的1×1卷积)。
在Swin Transformer中,下采样由阶段间额外的独立层完成。
我们尝试类似策略,采用stride为2的2×2卷积层做空间下采样。初次改动导致训练发散。进一步研究发现,在空间分辨率发生变化处添加归一化层(包括多个Swin Transformer中使用的LN层:下采样层前、stem后和最终全局平均池化后)有助于稳定训练。此时准确率提升至82.0%,显著超过Swin-T的81.3%。我们将采用独立的下采样层。
最终结构

ConvNeXt v2
视觉表征学习系统的性能主要受三个因素影响:所选神经网络架构、网络的训练方法以及用于训练的数据。
目前探索神经网络架构设计空间的最常见方法仍是基于ImageNet上的监督学习性能进行基准测试。
自监督方法(如MAE)主要在Transformer架构下取得成功,卷积网络(ConvNets)在掩码自监督预训练下效果不佳。
ConvNeXt V2通过将网络结构与自监督任务(如MAE)协同优化,解决卷积网络在掩码训练中性能提升受限的问题。
可以先看这篇博客对视觉自监督训练有个理解:《MAE: Masked Autoencoders Are Scalable Vision Learners》论文精读笔记_mae论文-CSDN博客
学习信号通过对原始输入图像随机掩码(掩码比例较高)产生,让模型根据可见部分预测缺失区域。框架如图2所示。
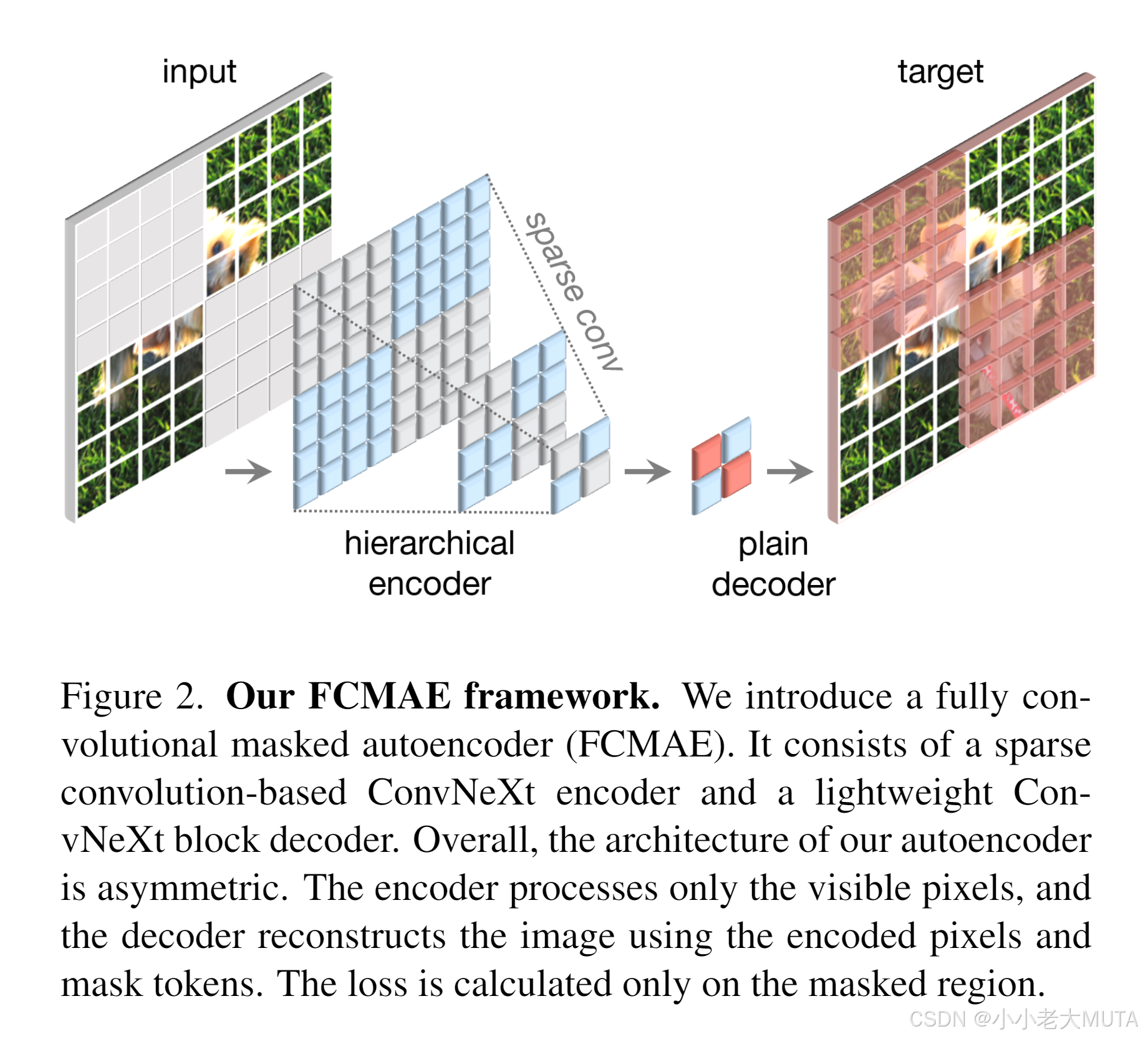
掩码策略
采用随机掩码策略,掩码比例为0.6。由于卷积模型采用分层设计,特征在不同阶段被下采样,掩码在最后一个阶段生成后,递归上采样到最细粒度。
具体实现中,我们随机移除原始输入图像中60%的32×32像素块。数据增强采用最小化策略,仅包含随机调整尺寸裁剪。
编码器设计
使用ConvNeXt[52]作为编码器。
掩码图像建模面临的一个挑战是防止模型学习捷径——即直接复制掩码区域的信息。Transformer模型中较容易通过只输入可见块来避免这一问题,但卷积网络必须保留二维图像结构,使得防止捷径更困难。一些简单方案通过在输入端引入可学习的掩码token[3,77],但这降低了预训练效率且训练和测试时不一致(测试时无掩码token),掩码比例高时问题尤为突出。
针对该问题,我们的新见解是将掩码图像视为“稀疏数据”,灵感来源于3D任务中稀疏点云学习[15,76]。我们的关键观察是掩码图像可表示为二维稀疏像素数组。基于此,合理引入稀疏卷积以辅助掩码自编码器预训练。
实践中,预训练时我们将编码器中的标准卷积层替换为子流形稀疏卷积,使模型仅对可见数据点进行计算[15,27,28]。微调阶段可将稀疏卷积层转换回标准卷积,无需额外处理。
另一种备选方案是在密集卷积操作前后施加二值掩码操作,数值效果等同稀疏卷积,理论计算更复杂,但对TPU等AI加速器更友好。
解码器设计
我们使用轻量级的单个ConvNeXt块作为解码器,形成整体非对称的编码器-解码器结构(编码器较重,解码器较轻)。
虽然有层次解码器[48,59]或Transformer解码器[21,31]等更复杂方案,但简化的单块ConvNeXt解码器在微调准确率表现良好,且大幅降低预训练时间(见表1)。解码器维度设为512。

重建目标
计算重建与目标图像的均方误差(MSE)。与MAE[31]类似,目标为原始输入的块级归一化图像,损失仅作用于掩码块。
FCMAE
将上述方案结合,提出完全卷积掩码自编码器(Fully Convolutional Masked AutoEncoder,FCMAE)。为验证该框架有效性,采用ConvNeXt-Base作为编码器,进行一系列消融实验。
文中侧重于端到端微调性能,因其在迁移学习中的实用价值,用以评估表征质量。预训练和微调均在ImageNet-1K(IN-1K)数据集上进行,分别训练800和100个epoch,报告单中心裁剪224×224图像的top-1验证准确率。实验细节见附录。
为探究稀疏卷积在FCMAE中的作用,首先考察其对掩码图像预训练期间表征质量的影响。实验证明,防止掩码区域的信息泄露至关重要,以获得良好结果。
| 是否使用稀疏卷积 | 预训练top-1准确率(%) |
|---|---|
| 不使用 | 79.3 |
| 使用 | 83.7 |
接下来,我们将自监督方法与监督学习进行对比。具体地,提供两个监督基线实验结果:采用相同训练策略的100个epoch基线及原ConvNeXt论文[52]中的300个epoch基线。结果表明,FCMAE预训练比随机初始化提供了更好的初始点(82.7 → 83.7),但尚未达到原监督训练的最佳性能。
| 训练方式 | top-1准确率(%) |
|---|---|
| 监督,100 epoch | 82.7 |
| 监督,300 epoch | 83.8 |
| FCMAE | 83.7 |
与基于Transformer的掩码图像建模近期成功形成鲜明对比[3,31,77],后者的预训练模型显著优于监督版本。
全局响应归一化
提出全局响应归一化(Global Response Normalization, GRN)以提升FCMAE预训练在ConvNeXt架构上的效果。先通过定性和定量的特征分析来说明提出该方法的动机。
特征塌缩
为了深入理解模型的学习行为,我们首先在特征空间进行定性分析。
通过可视化FCMAE预训练的ConvNeXt-Base模型的激活,我们注意到一种有趣的“特征塌缩”现象:许多特征图出现“死”或饱和状态,且不同通道间激活高度冗余。部分可视化结果见图3。此行为主要出现在ConvNeXt块中用于维度扩展的MLP层[52]。
图3 特征激活可视化。将每个特征通道的激活图以小方块形式进行展示。为了清晰起见,每个可视化图中展示64个通道。ConvNeXt V1模型存在特征塌缩问题,其表现为不同通道间存在大量冗余激活(即死神经元或饱和神经元)。

图解
ConvNeXt V1(左侧两列):可以看到很多小方格颜色非常相似或极暗,说明很多通道的激活非常低(“死神经元”),或者亮度很接近,说明多个通道表现重复(冗余)。这表明特征表达缺乏多样性,出现了明显的特征塌缩问题。
ConvNeXt V2(右侧两列):激活图颜色更加丰富多样,不同通道之间激活明显差异更大,说明特征表达更丰富、更有区分度,特征塌缩问题得到缓解。
特征余弦距离分析
为进一步验证该现象,我们进行了特征余弦距离的定量分析。设激活张量为 ,其中
表示第 i 个通道的特征图。我们将其重塑为 HW 维向量,计算所有通道间两两的平均余弦距离:
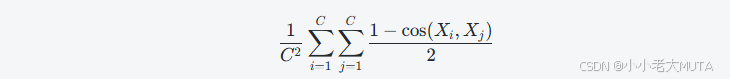
该数值越大代表特征越多样,越小则表示特征冗余。
随机选取ImageNet-1K验证集中1000张不同类别图片,提取不同模型各层的高维特征,包括FCMAE模型、ConvNeXt有监督模型[52]和MAE预训练的ViT模型[31],计算每层平均余弦距离。结果绘制于图4。
FCMAE预训练的ConvNeXt模型表现出明显的特征塌缩趋势,与激活图可视化一致。由此我们考虑通过增加特征多样性来防止特征塌缩。
图4 特征余弦距离分析。由于不同架构的总层数不同,我们将余弦距离值与归一化的层索引进行绘制。我们观察到,ConvNeXt V1 FCMAE预训练模型表现出严重的特征塌缩现象。监督训练模型在最后几层同样出现了特征多样性的下降。这种多样性下降很可能是由于采用了交叉熵损失,使模型更专注于区分类特征,同时抑制了其他特征。
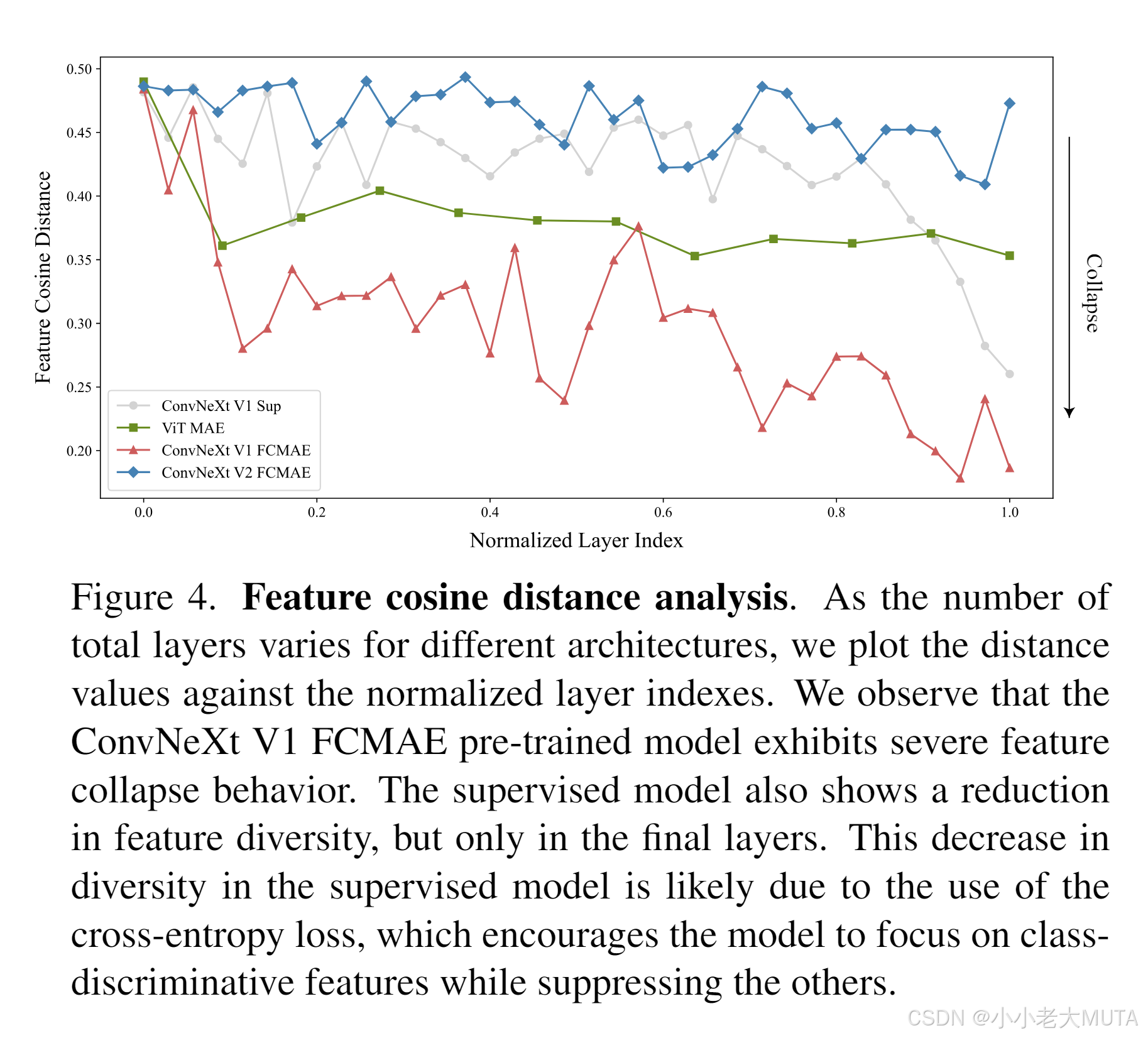
图解
这张图展示了不同模型在各层的“特征余弦距离”(即特征多样性)变化趋势。纵轴是特征余弦距离,横轴是归一化后的层索引(从网络的头部到尾部)。特征余弦距离越高,表示该层不同通道之间的特征越多样化;距离越低,表示特征越相近,甚至出现特征塌缩。图中的曲线分别代表不同模型和训练方式:
- ConvNeXt V1 Sup(灰色):监督训练的ConvNeXt V1模型,前面层特征多样性较高,后面层急剧下降,特征塌缩主要发生在最后几层。
- ViT MAE(蓝色):ViT自监督方法,整体特征多样性较高,塌缩较轻。
- ConvNeXt V1 FCMAE(红色):ConvNeXt V1 FCMAE自监督预训练模型,整体余弦距离很低,特征塌缩问题严重。
- ConvNeXt V2 FCMAE(绿色):ConvNeXt V2 FCMAE自监督预训练模型,特征多样性明显提升,特征塌缩得到了缓解。
ConvNeXt V2通过新的设计(如GRN层)显著缓解了特征塌缩,提升了特征表达多样性。
解决方法
大脑中存在多种机制促进神经元多样性,例如侧抑制(lateral inhibition)[6,30],它通过抑制邻近神经元响应,增强被激活神经元的对比度和选择性,并提升神经元群体响应的多样性。在深度学习中,这类侧抑制可通过响应归一化实现[45]。
本工作提出一种新的响应归一化层——全球响应归一化(GRN),旨在增强通道间的对比度和选择性。给定输入特征,GRN包含三步:
1. 全局特征聚合

2. 特征归一化

3. 特征校准


ConvNeXt v2结构
将GRN层融入原始ConvNeXt块,如图5所示。
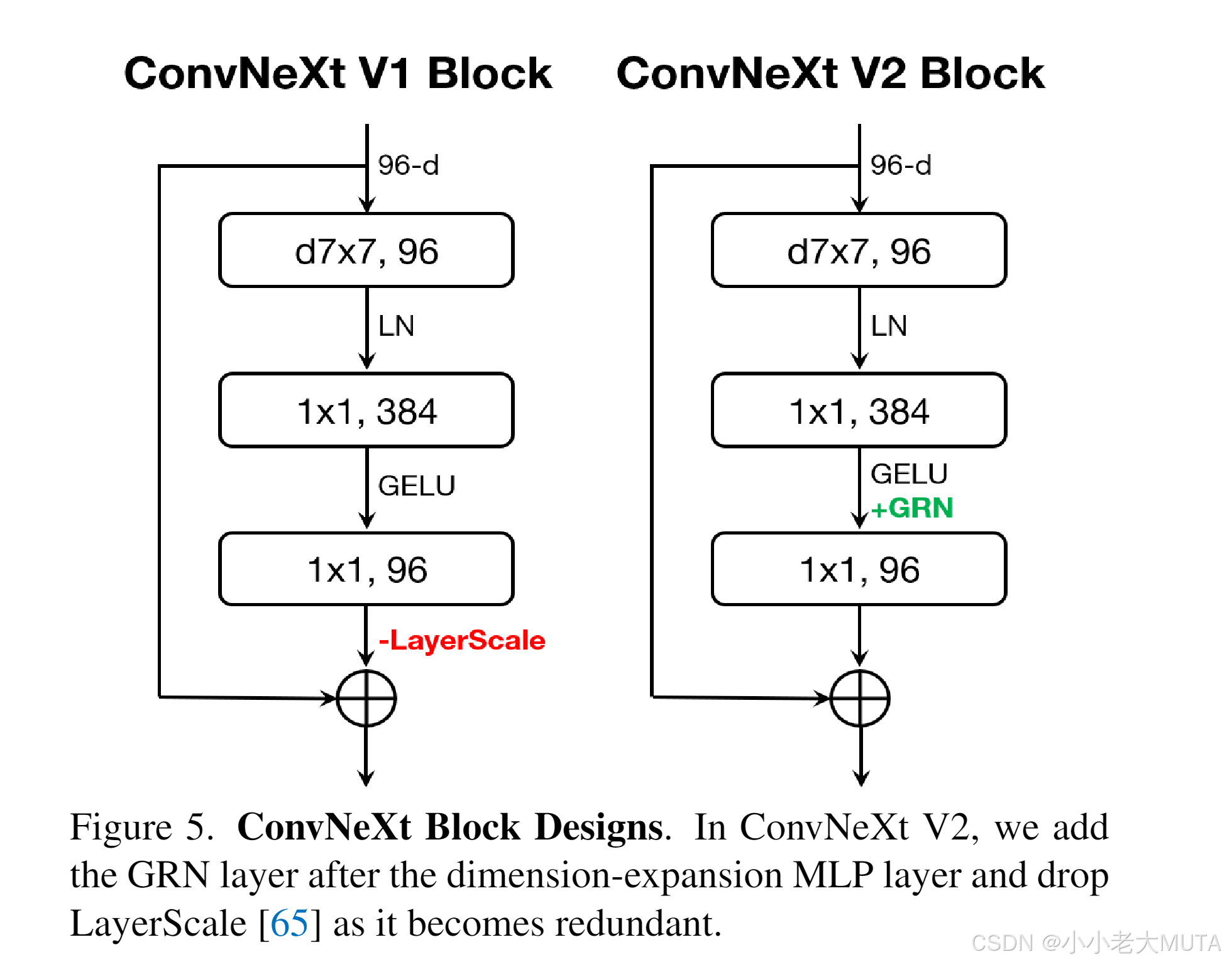
实验证明,加入GRN后LayerScale[65]变得多余,可被移除。
基于该新块设计,构建了多种不同规模的模型,统称为ConvNeXt V2系列,涵盖轻量级(如Atto[70])到高计算量(如Huge)模型,详细配置见附录。
使用FCMAE框架预训练ConvNeXt V2后,结合图3的可视化和图4的余弦距离分析,可见ConvNeXt V2有效缓解了特征塌缩问题,且余弦距离值持续保持较高,表明层间特征多样性得到维护。这种表现与MAE预训练的ViT模型类似[31]。整体来看,ConvNeXt V2的学习行为在类似掩码图像预训练框架下可与ViT相媲美。