Python数据清洗实战指南
在数据分析的广阔领域中,数据清洗无疑是最为关键且基础的环节,堪称数据分析大厦的基石。原始数据通常犹如刚从矿山开采出来的矿石,蕴含着大量杂质,存在诸如缺失值、重复值、异常值以及数据格式不一致等诸多问题。这些问题若不加以妥善处理,就如同在不稳定的地基上建造高楼,后续的数据分析与建模工作将摇摇欲坠,得出的结论也可能误导决策。因此,数据清洗是确保数据分析准确性、可靠性与有效性的必经之路。
本文将借助 Python 强大的数据分析库以及内置的 SQLite 数据库,深入且全面地探索数据清洗的各个关键环节,并通过详细的代码示例及注释,帮助读者不仅掌握操作方法,更能理解背后的原理,从而在实际工作中灵活运用数据清洗技术。
二、数据清洗的关键流程与深度实践
(一)数据加载
数据加载是整个数据清洗流程的起点,它决定了我们后续处理的数据基础。Python 的sqlite3库为我们提供了与 SQLite 数据库进行交互的便捷接口,而pandas库则能够轻松地将数据库中的数据读取为易于操作的DataFrame格式。
import sqlite3
import pandas as pd# 连接到SQLite数据库
# 这里假设数据库文件名为example.db,如果该文件不存在,将会自动创建一个新的数据库
conn = sqlite3.connect('example.db')# 使用pandas从数据库中读取数据
# SELECT * FROM data_table表示选择data_table表中的所有列
query = "SELECT * FROM data_table"
data = pd.read_sql(query, conn)# 关闭数据库连接,避免资源浪费
conn.close()
(二)缺失值处理
缺失值是数据中较为常见的问题,它可能由多种原因导致,如数据采集过程中的失误、数据传输过程中的丢失等。处理缺失值的方式需要根据数据的特点和分析目的来选择,不同的处理方式可能会对数据分析结果产生显著影响。
1.缺失值检测
通过isnull()方法,我们能够敏锐地捕捉到数据中的缺失值。isnull()方法会对DataFrame中的每一个元素进行检查,如果元素值为缺失值(如NaN),则返回True,否则返回False。再借助sum()方法,我们可以对这些布尔值进行求和,从而清晰地统计出每列缺失值的具体数量。这就好比用一把精细的梳子,梳理数据中的每一个角落,找出那些缺失的部分并进行计数。
# 检测缺失值
missing_values = data.isnull().sum()
print(missing_values)
2.缺失值处理方法
删除缺失值:当缺失值在数据中所占比例较小,且缺失值的存在不会对整体数据结构和分析结果产生重大影响时,删除包含缺失值的行是一种简单直接的处理方式。就如同在一堆宝石中,少量有瑕疵的宝石可以直接剔除。dropna()方法提供了灵活的删除策略,how='any’表示只要该行有一个缺失值就删除,how='all’则表示整行全为缺失值才删除。
# 删除包含缺失值的行
# how='any'表示只要该行有一个缺失值就删除,how='all'则表示整行全为缺失值才删除
data = data.dropna(how='any')
填充缺失值:对于数值型数据,均值、中位数等统计量可以作为填补缺失值的依据。均值是所有数据的平均值,它反映了数据的平均水平,但容易受到极端值的影响;中位数则是将数据按大小顺序排列后位于中间位置的数值,更能抵御极端值的干扰。对于非数值型数据,众数是出现频率最高的类别,用众数填充缺失值是一种常见的方法。
# 用均值填充数值型数据的缺失值
numerical_columns = ['age','salary']
for col in numerical_columns:mean_value = data[col].mean()# fillna()方法将缺失值替换为均值data[col] = data[col].fillna(mean_value)# 用众数填充非数值型数据的缺失值
categorical_columns = ['name']
for col in categorical_columns:mode_value = data[col].mode()[0]data[col] = data[col].fillna(mode_value)
(三)重复值处理
重复值就像是数据中的 “双胞胎”,它们的存在会干扰数据分析的准确性,增加数据处理的冗余度,因此需要及时识别并清理。
重复值检测
duplicated()方法就像一面 “照妖镜”,能够精准地识别出数据中的重复行。它会对DataFrame中的每一行进行比较,判断是否与之前出现的行完全相同。sum()方法则进一步对这些重复行的判断结果进行求和,让我们清晰地了解到重复行的数量。
# 检测重复值
duplicate_rows = data.duplicated()
duplicate_count = duplicate_rows.sum()
print(f"重复行数量: {duplicate_count}")
重复值删除
drop_duplicates()方法可以帮助我们像 “剪刀” 一样,干净利落地删除重复行。keep='first’表示保留第一次出现的行,删除其他重复行;keep='last’则相反,保留最后一次出现的行,删除其他重复行;keep=False表示删除所有重复行,只保留唯一的行。
# 删除重复行
# keep='first'表示保留第一次出现的行,删除其他重复行;keep='last'则相反;keep=False表示删除所有重复行
data = data.drop_duplicates(keep='first')
(四)异常值处理
异常值是数据中那些与众不同的 “特殊个体”,它们可能是由于数据录入错误、测量误差或者真实存在的极端情况导致的。异常值的存在可能会对数据分析结果产生较大影响,因此需要仔细甄别并妥善处理。
异常值检测:以age列为例,四分位数间距(IQR)方法是一种常用且有效的检测异常值的手段。它通过计算数据的四分位数,将数据划分为四个部分,从而确定数据的分布范围,进而找出可能的异常值。
Q1 = data['age'].quantile(0.25) # 计算第一四分位数,即25%分位数,意味着25%的数据小于该值
Q3 = data['age'].quantile(0.75) # 计算第三四分位数,即75%分位数,意味着75%的数据小于该值
IQR = Q3 - Q1 # 计算四分位数间距,它反映了数据中间50%部分的离散程度lower_bound = Q1 - 1.5 * IQR # 确定下限,一般认为低于此值的数据可能是异常值
upper_bound = Q3 + 1.5 * IQR # 确定上限,一般认为高于此值的数据可能是异常值outliers = data[(data['age'] < lower_bound) | (data['age'] > upper_bound)] # 找出异常值
print(outliers)
异常值处理:对于异常值,我们需要根据实际情况来决定处理方式。如果异常值是由于数据录入错误导致的,那么可以将其修正为合理值;如果是真实的极端情况,可能需要单独进行分析。这里我们采用一种简单的处理方式,将超出上限的值替换为上限值,低于下限的值替换为下限值。
data['age'] = data['age'].apply(lambda x: lower_bound if x < lower_bound else upper_bound if x > upper_bound else x)
(五)数据格式调整
数据格式的一致性是数据分析能够顺利进行的重要保障。如果数据格式混乱,就像拼图的碎片形状各异,难以拼凑完整。假设salary列的数据类型本应为整数,但当前为浮点数且包含小数部分,我们就需要对其进行类型转换。
# 将salary列转换为整数类型
# astype()方法用于数据类型转换,这里将'salary'列的数据转换为整数类型
data['salary'] = data['salary'].astype(int)
(六)数据逻辑错误检查与修正
除了上述常见问题,数据中还可能存在逻辑错误,这些错误可能不会像缺失值、重复值或异常值那样直观,但同样会影响数据分析的结果。例如年龄为负数、日期前后矛盾等情况。以年龄为例,假设年龄不能为负数,我们可进行如下检查与修正。
# 检查并修正年龄为负数的情况
data['age'] = data['age'].apply(lambda x: 0 if x < 0 else x)
(七)数据标准化与归一化在一些数据分析场景中,不同特征的数值范围可能差异很大。例如,薪资可能在几千到几十万,而年龄通常在几十岁以内。这种差异可能会影响到一些分析模型(如机器学习中的梯度下降算法)的性能,因为模型可能会过度关注数值较大的特征,而忽略数值较小的特征。此时,我们需要对数据进行标准化或归一化处理,使所有特征在同一尺度上。标准化(Z - score 标准化):标准化后的数据均值为 0,标准差为 1,能有效消除量纲的影响。它的计算公式为: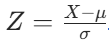
,其中X是原始数据,μ是数据的均值,
是数据的标准差。
from sklearn.preprocessing import StandardScaler# 对数值型列进行标准化
numerical_columns = ['age','salary']
scaler = StandardScaler()
data[numerical_columns] = scaler.fit_transform(data[numerical_columns])
归一化(Min - Max 归一化):将数据缩放到 [0, 1] 区间,保留数据的分布信息。它的计算公式为: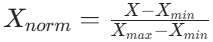
,其中X是原始数据,
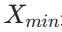 是数据中的最小值,
是数据中的最小值,
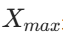 是数据中的最大值。
是数据中的最大值。
from sklearn.preprocessing import MinMaxScaler# 对数值型列进行归一化
numerical_columns = ['age','salary']
scaler = MinMaxScaler()
data[numerical_columns] = scaler.fit_transform(data[numerical_columns])
三、数据清洗后的数据保存
经过一系列精心的数据清洗操作后,我们得到了高质量的数据。为了方便后续的数据分析和使用,需要将这些处理后的数据妥善保存。借助pandas的to_sql()方法,我们能够将处理后的数据无缝保存回 SQLite 数据库。
# 连接到SQLite数据库
conn = sqlite3.connect('example.db')# 将处理后的数据写回数据库
# 'cleaned_data_table'为新表名,if_exists='replace'表示若表已存在则替换,index=False表示不保存索引
data.to_sql('cleaned_data_table', conn, if_exists='replace', index=False)# 关闭数据库连接
conn.close()
四、总结
数据清洗是一项细致而又关键的工作,贯穿于数据分析的始终。通过本文详细介绍的各个环节及丰富的代码示例,我们深入探索了如何从杂乱无章的原始数据中提炼出高质量的可用数据。从数据加载时的谨慎读取,到缺失值、重复值、异常值的细致处理,再到数据格式调整、逻辑错误修正以及标准化归一化的优化,每个步骤都紧密相连,不可或缺。
在实际应用中,面对不同类型的数据和复杂的业务场景,我们需要灵活运用这些方法,并不断积累经验,根据数据的特点和分析目的选择最合适的数据清洗策略。同时,我们还应该意识到数据清洗并非一蹴而就,可能需要反复进行,以确保数据分析的准确性与可靠性。希望读者通过本文的学习,能够在数据清洗的道路上稳步前行,为后续的数据分析工作筑牢坚实基础,从数据中挖掘出有价值的信息,为决策提供有力支持。