Spring AI alibaba 智能体理论
本文为个人学习笔记整理,仅供交流参考,非专业教学资料,内容请自行甄别。
文章目录
- 概述
- 一、CoT思维链
- 1.1、为什么要使用CoT思维链
- 1.2、CoT 的关键原理
- 1.3、CoT 的两种典型实现方式
- 1.4、CoT 的应用场景
- 1.5、CoT 与普通 AI 回答的核心区别
- 二、Agent Loop
- 三、ReAct模式
概述
AI 智能体是具备自主决策、环境交互与目标驱动能力的计算实体,AI智能体也称为Agent,这个单词原本的含义是代理,但是在不同的领域,它的含义也是不相同的。AI 智能体具有以下本质特征:
- 自主性:智能体无需外部实时干预,可依据内置规则、学习模型独立决策。例如自主导航机器人能基于环境感知数据规划路径,无需人工逐步指令。
- 交互性:它能与环境,如物理环境或数字环境,以及其他智能体进行双向互动。如物联网场景中,智能传感器与执行器组成的智能体网络,通过数据交互协同调控设备。
- 目标导向性:智能体围绕预设目标行动,如任务完成、资源优化等。强化学习智能体通过 “试错 - 奖励” 机制逼近目标,对话智能体以生成符合意图的回复为目标。
最初的AI应用,更加倾向于是聊天机器人,仅仅能根据预设和用户的问题作出回答,非常的死板。近年来逐步进化的AI应用,
能够根据用户提供的任务目标,对其进行分解,自主执行推理并且执行任务,调用工具,最终返回结果,这样的AI应用符合智能体的特性。
智能体实现的关键技术,主要包含了CoT思维链、Agent Loop、ReAct模式,下面是简单的介绍:
一、CoT思维链
CoT(Chain of Thought,思维链)是一种引导 AI 逐步拆解复杂问题、模拟人类逻辑推理过程的提示工程技术,核心是让 AI 不再直接输出答案,而是先 “展示” 思考步骤 —— 就像人解决数学题、逻辑题时会一步步写草稿一样,最终基于连贯的推理链得出结论。
它的本质是将 AI 的 “黑箱式推理” 转化为 “白箱式分步推理”,尤其适用于需要多步逻辑、数学计算、常识关联的复杂任务(如数学题、代码调试、逻辑分析等),能显著提升 AI 回答的准确性和可解释性。
1.1、为什么要使用CoT思维链
在没有 CoT 引导时,AI 面对复杂问题常出现 “跳跃式错误”—— 比如算数学题时省略关键步骤导致结果出错,或分析逻辑题时忽略中间条件导致结论偏差。而 CoT 通过 “强制分步推理” 解决了这两个核心痛点。
1.2、CoT 的关键原理
例如需要计算10的平方的平方,这道数学题,以人类的思维,应该是:
- 先计算10的平方,为100。
- 再计算100的平方,为10000。
CoT 的核心就是让 AI 复现这个过程:通过提示词引导 AI 拆解任务、分步骤推理,每一步都基于前一步的结论,最终推导到目标答案。其技术逻辑可概括为:
用户需求 → 提示AI“分步思考” → AI生成推理链(步骤1→步骤2→…→步骤N) → 基于推理链输出最终结果
1.3、CoT 的两种典型实现方式
Zero-Shot CoT(零样本思维链),Few-Shot CoT(少样本思维链)。
前者是无需给 AI 示例,只需在提示词中加入 “请分步思考”“先分析 XX,再计算 XX” 等引导语,直接让 AI 自主拆解步骤。(适用于问题逻辑相对清晰,AI 可通过自身知识库拆解步骤(如基础数学题、简单逻辑题)。)
而后者会先给 AI1-3 个 “问题 + 正确推理链” 的示例,让 AI 模仿示例的分步模式,再解决新问题(类似人类 “看例题学解题”,适用于问题逻辑复杂(如多变量数学题、代码调试、逻辑论证),需要示例引导 AI 理解推理框架。)。
1.4、CoT 的应用场景
CoT 的价值在 “复杂任务” 中最突出,典型应用包括:
- 数学与科学计算:如解方程、几何证明、物理公式推导(避免 AI 直接套公式出错);
- 逻辑分析与决策:如商业案例分析(“某公司利润下降,分析 3 个可能原因并给出对策”)、法律条款解读;
- 代码生成与调试:如 “写一个计算质数的 Python 函数”,AI 先拆解 “判断质数的逻辑→写循环→加边界条件”,再输出代码;
- 多步骤任务规划:如 “帮我规划‘从北京去上海出差 3 天’的行程”,AI 分步思考 “交通选择→住宿安排→每日行程匹配工作需求”。
1.5、CoT 与普通 AI 回答的核心区别
简单来说,普通 AI 回答是 “直接给结果”,CoT 是 “先给思考过程,再给结果”—— 这个过程差异带来了本质区别:
- 普通回答:AI 可能 “蒙对” 也可能 “蒙错”,用户无法判断其逻辑是否正确;
- CoT 回答:用户可通过推理链验证每一步的合理性,即使结果出错,也能快速定位是哪一步逻辑偏差(比如公式用错、条件漏看)。
在早期的Open Manus的源码中,有关于CoT的提示词:
You are an assistant focused on Chain of Thought reasoning. For each question, please follow these steps: 1. Break down the problem: Divide complex problems into smaller, more manageable parts
2. Think step by step: Think through each part in detail, showing your reasoning process
3. Synthesize conclusions: Integrate the thinking from each part into a complete solution
4. Provide an answer: Give a final concise answer Your response should follow this format:
Thinking: [Detailed thought process, including problem decomposition, reasoning for each step, and analysis]
Answer: [Final answer based on the thought process, clear and concise] Remember, the thinking process is more important than the final answer, as it demonstrates how you reached your conclusion.
二、Agent Loop
Agent Loop 是一种能让 AI 智能体持续运转的循环流程,其核心是通过反复的 “思考、行动和学习” 来实现复杂任务的处理。它能让智能体在没有用户输入干预的场景下,自主的执行推理和工具调用。
它的工作流程,类似于PDCA循环:
- 推理(Reason):智能体将原始任务分解为多个步骤,明确每一步要执行的操作,就像人类在解决复杂问题时会先分析问题,确定解题的步骤一样。
- 行动(Action):依据推理阶段的规划,智能体判断是否需要调用工具来执行任务,如果需要,则选择合适的工具并传入相应的参数。例如,在处理数据时,智能体可能会调用数据分析工具来对数据进行处理。
- 观察(Observation):智能体获取工具返回的结果,并对结果进行分析和评估,了解行动的效果如何。
- 循环:智能体重复执行推理、行动和观察这三个过程,直到达到终止条件,如任务完成、达到预设的时间限制或满足特定的结果要求等。
在Open Manus的源码中就有所体现。如果当前是空闲态,写入初始请求,把状态切为运行中,按步循环执行 step(),每一步检查是否“卡住”,达到步数上限就停,最后清理资源并返回步骤结果汇总:
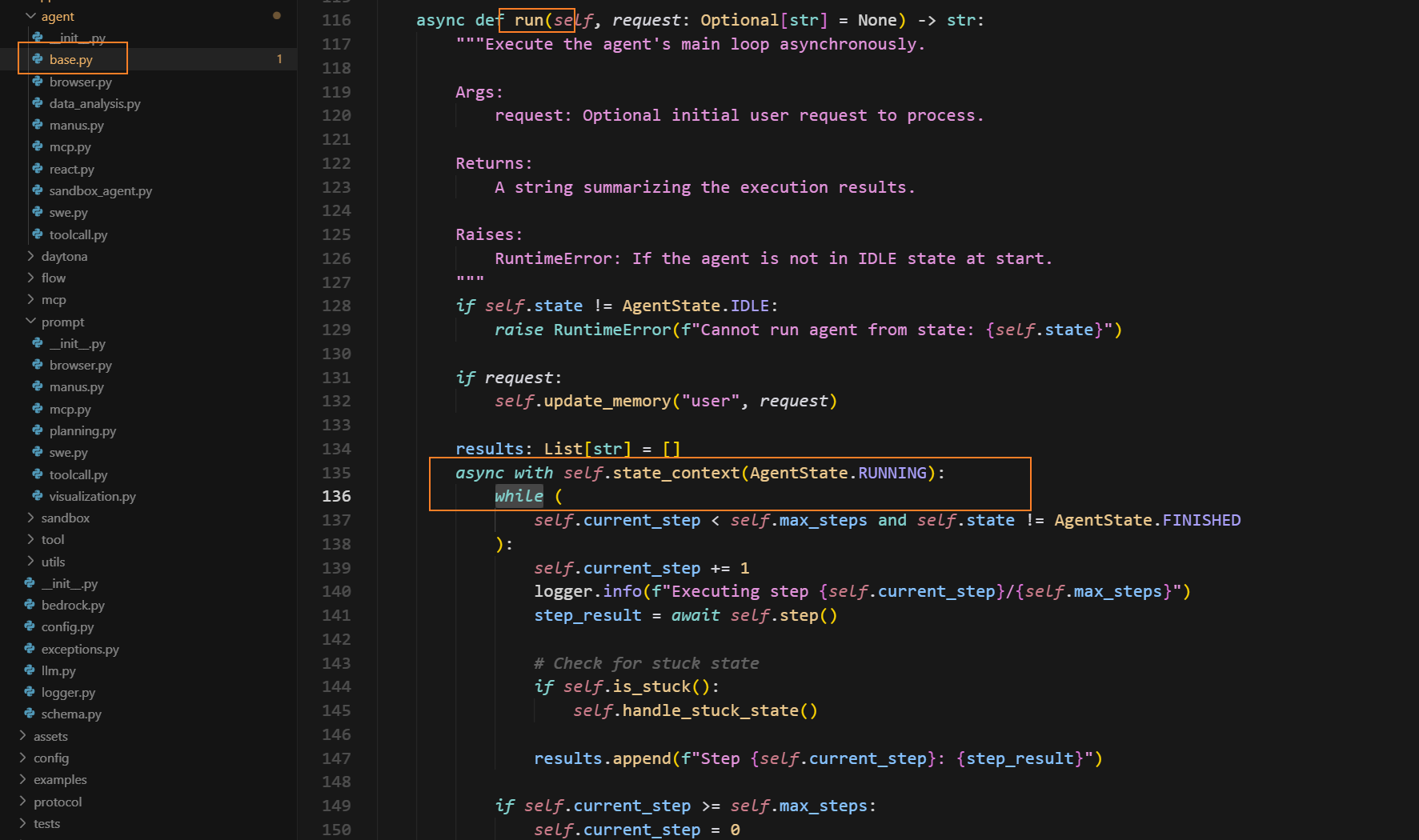
三、ReAct模式
ReAct 模式,即推理与行动模式,是一种结合了语言推理和实际行动的 AI 交互模式,旨在让智能体能够更灵活、智能地完成复杂任务。强调智能体在面对任务时,通过语言模型进行推理,明确需要采取的行动,并实际执行这些行动,然后根据行动的结果进一步推理和调整后续行动。它将推理过程和行动过程紧密结合,形成一个循环迭代的过程,以逐步接近任务的目标。Agent Loop是它的体现。
一个完整的AI智能体,除了大模型,还应该包含上下文记忆,RAG知识库,工具调用,并且结合上述的三大特性。