python全栈(基础篇)——day04:后端内容(字符编码+list与tuple+条件判断+实战演示+每日一题)
目录
字符编码
Python的字符串
ord()函数与chr()函数
encode()函数与decode()函数
小结
list与tuple
list(列表)
tuple(元组)
Python中list与tuple小结
list(列表)
tuple(元组)
list特有操作
添加元素
删除元素
修改元素
tuple特殊注意事项
单元素tuple定义
"可变"的tuple
使用建议
总结
条件判断
缩进部分
小结
条件判断部分
再议input
成员运算符
实战演练
题目1:字符编码转换器
题目2:学生成绩等级判断
题目3:购物车商品管理
题目4:元组操作演示
题目5:登录验证系统
每日一题
题目:学生信息管理系统
欢迎在评论区进行打卡留言,并分享学习经验,题目讲解以及分享更多内容,关注博主或者订阅专栏,可以第一时间看到博主发表的博文
字符编码
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode字符集应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是UCS-16编码,用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
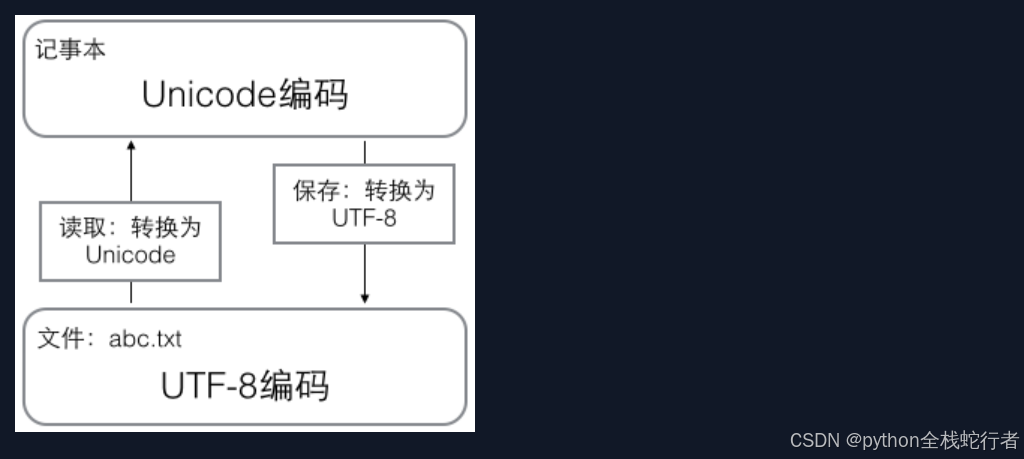
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Python的字符串
ord()函数与chr()函数
搞清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'如果知道字符的整数编码,还可以用十六进制这么写str:
>>> '\u4e2d\u6587'
'中文'两种写法完全是等价的。
encode()函数与decode()函数
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
小结
Python 3的字符串使用Unicode,直接支持多语言。
当str和bytes互相转换时,需要指定编码。最常用的编码是UTF-8。Python当然也支持其他编码方式,比如把Unicode编码成GB2312:
>>> '中文'.encode('gb2312')
b'\xd6\xd0\xce\xc4'但这种方式纯属自找麻烦,如果没有特殊业务要求,请牢记仅使用UTF-8编码。
格式化字符串的时候,可以用Python的交互式环境测试,方便快捷。
list与tuple
list(列表)
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']还有一种定义列表的方法叫做list():
>>> classmates = 'Michael', 'Bob', 'Tracy'
>>> classmates = list(classmates)
['Michael', 'Bob', 'Tracy']变量classmates就是一个list。用len()函数可以获得list元素的个数:
>>> len(classmates)
3用索引来访问list中每一个位置的元素,记得索引是从0开始的:
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
>>> classmates[3]
Traceback (most recent call last):File "<stdin>", line 1, in <module>
IndexError: list index out of range索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(classmates) - 1。
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1]
'Tracy'以此类推,可以获取倒数第2个、倒数第3个:
>>> classmates[-2]
'Bob'
>>> classmates[-3]
'Michael'
>>> classmates[-4]
Traceback (most recent call last):File "<stdin>", line 1, in <module>
IndexError: list index out of range当然,倒数第4个就越界了。
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']要删除list末尾的元素,用pop()方法:
>>> classmates.pop()
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']还有一个删除的方法是remove(),在括号里面填入指定的值就可以用来删除对应的元素:
>>> classmates.remove('Bob')
>>> classmates
['Michael', 'Tracy']要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
>>> classmates[1] = 'Sarah'
>>> classmates
['Michael', 'Sarah', 'Tracy']list里面的元素的数据类型也可以不同,比如:
>>> L = ['Apple', 123, True]list元素也可以是另一个list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4要注意s只有4个元素,其中s[2]又是一个list,如果拆开写就更容易理解了:
>>> p = ['asp', 'php']
>>> s = ['python', 'java', p, 'scheme']要拿到'php'可以写p[1]或者s[2][1],因此s可以看成是一个二维数组,类似的还有三维、四维……数组,不过很少用到。
如果一个list中一个元素也没有,就是一个空的list,它的长度为0:
>>> L = []
>>> len(L)
0tuple(元组)
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Michael', 'Bob', 'Tracy')现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
>>> t = (1, 2)
>>> t
(1, 2)如果要定义一个空的tuple,可以写成():
>>> t = ()
>>> t
()但是,要定义一个只有1个元素的tuple,如果你这么定义:
>>> t = (1)
>>> t
1定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
最后来看一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])这个tuple定义的时候有3个元素,分别是'a','b'和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?
别急,我们先看看定义的时候tuple包含的3个元素:
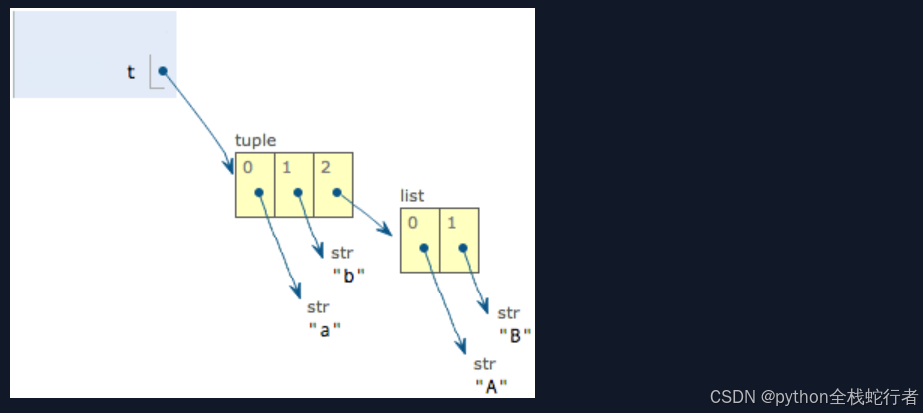
当我们把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:
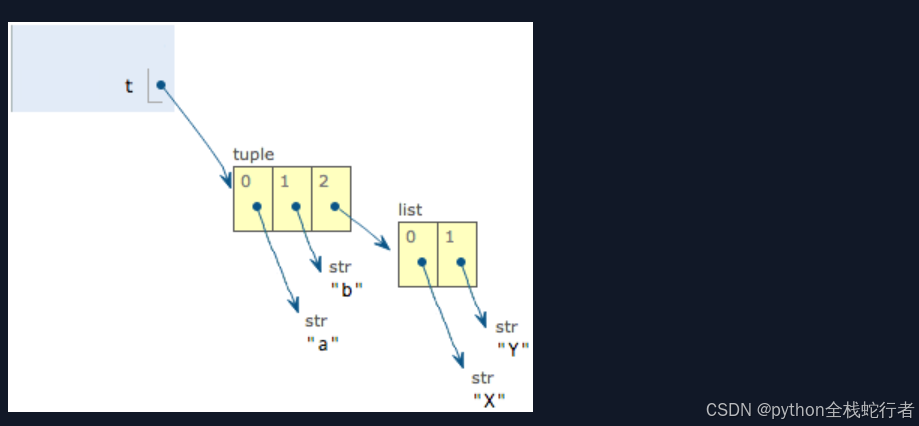
表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
Python中list与tuple小结
list(列表)
-
有序可变集合,可随时添加、删除和修改元素
-
定义方式:
[元素1, 元素2, ...]或list(可迭代对象) -
示例:
classmates = ['Michael', 'Bob', 'Tracy']
tuple(元组)
-
有序不可变集合,一旦初始化就不能修改
-
定义方式:
(元素1, 元素2, ...) -
示例:
classmates = ('Michael', 'Bob', 'Tracy')
主要区别
| 特性 | list | tuple |
|---|---|---|
| 可变性 | 可变 | 不可变 |
| 定义符号 | [] | () |
| 性能 | 稍慢 | 稍快 |
| 安全性 | 较低 | 较高 |
| 使用场景 | 需要修改的数据 | 常量数据 |
共同操作
访问元素
-
索引访问:
[0],[1],[-1](支持负数索引) -
长度获取:
len() -
切片操作(未在原文提及但常用)
注意事项
-
索引从0开始
-
索引越界会报
IndexError -
最后一个元素索引为
len()-1
list特有操作
添加元素
-
append(element)- 追加到末尾 -
insert(index, element)- 插入到指定位置
删除元素
-
pop()- 删除末尾元素 -
pop(index)- 删除指定位置元素 -
remove(value)- 删除指定值元素
修改元素
-
直接赋值:
list[index] = new_value
tuple特殊注意事项
单元素tuple定义
t = (1) # 这不是tuple,是数字1
t = (1,) # 这才是单元素tuple"可变"的tuple
t = ('a', 'b', ['A', 'B'])
t[2][0] = 'X' # 可以修改tuple中的list元素解释:tuple的"不变"是指每个元素的指向不变,如果元素本身是可变对象,其内容可以改变。
使用建议
-
优先使用tuple:当数据不需要修改时,使用tuple更安全高效
-
需要修改时使用list:当需要频繁增删改元素时使用list
-
注意单元素tuple:定义时务必加逗号
-
嵌套结构:两者都可以嵌套使用,形成多维数据结构
总结
list和tuple都是Python中重要的有序集合类型,主要区别在于可变性。理解它们的特性和适用场景,能够帮助我们编写更高效、更安全的代码。list适合处理动态数据,tuple适合表示固定数据,在实际编程中应根据需求灵活选择。
条件判断
在将条件判断之前,还需要讲解一下缩进,要不然很多同学都不知道为什么条件判断的语法结构是这个样子
缩进部分
Python是一种计算机编程语言。计算机编程语言和我们日常使用的自然语言有所不同,最大的区别就是,自然语言在不同的语境下有不同的理解,而计算机要根据编程语言执行任务,就必须保证编程语言写出的程序决不能有歧义,所以,任何一种编程语言都有自己的一套语法,编译器或者解释器就是负责把符合语法的程序代码转换成CPU能够执行的机器码,然后执行。Python也不例外。
Python的语法比较简单,采用缩进方式,写出来的代码就像下面的样子:
# print absolute value of an integer:
a = 100
if a >= 0:print(a)
else:print(-a)以#开头的语句是注释,注释是给人看的,可以是任意内容,解释器会忽略掉注释。其他每一行都是一个语句,当语句以冒号:结尾时,缩进的语句视为代码块。
缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。按照约定俗成的惯例,应该始终坚持使用4个空格的缩进。
缩进的另一个好处是强迫你写出缩进较少的代码,你会倾向于把一段很长的代码拆分成若干函数,从而得到缩进较少的代码。
缩进的坏处就是“复制-粘贴”功能失效了,这是最坑爹的地方。当你重构代码时,粘贴过去的代码必须重新检查缩进是否正确。此外,IDE很难像格式化Java代码那样格式化Python代码。
最后,请务必注意,Python程序是大小写敏感的,如果写错了大小写,程序会报错。
小结
Python使用缩进来组织代码块,请务必遵守约定俗成的习惯,坚持使用4个空格的缩进;
在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格。
条件判断部分
计算机之所以能做很多自动化的任务,因为它可以自己做条件判断。
比如,输入用户年龄,根据年龄打印不同的内容,在Python程序中,用if语句实现:
age = 20
if age >= 18:print('your age is', age)print('adult')根据Python的缩进规则,如果if语句判断是True,就把缩进的两行print语句执行了,否则,什么也不做。
也可以给if添加一个else语句,意思是,如果if判断是False,不要执行if的内容,去把else执行了:
age = 3
if age >= 18:print('your age is', age)print('adult')
else:print('your age is', age)print('teenager')注意不要少写了冒号:。
当然上面的判断是很粗略的,完全可以用elif做更细致的判断:
age = 3
if age >= 18:print('adult')
elif age >= 6:print('teenager')
else:print('kid')elif是else if的缩写,完全可以有多个elif,所以if语句的完整形式就是:
if <条件判断1>:<执行1>
elif <条件判断2>:<执行2>
elif <条件判断3>:<执行3>
else:<执行4>if语句执行有个特点,它是从上往下判断,如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的elif和else,所以,请测试并解释为什么下面的程序打印的是teenager:
age = 20
if age >= 6:print('teenager')
elif age >= 18:print('adult')
else:print('kid')if判断条件还可以简写,比如写:
if x:print('True')只要x是非零数值、非空字符串、非空list等,就判断为True,否则为False。
再议input
最后看一个有问题的条件判断。很多同学会用input()读取用户的输入,这样可以自己输入,程序运行得更有意思:
birth = input('birth: ')
if birth < 2000:print('00前')
else:print('00后')输入1982,结果报错:
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: unorderable types: str() > int()这是因为input()返回的数据类型是str,str不能直接和整数比较,必须先把str转换成整数。Python提供了int()函数来完成这件事情:
s = input('birth: ')
birth = int(s)
if birth < 2000:print('00前')
else:print('00后')再次运行,就可以得到正确地结果。但是,如果输入abc呢?又会得到一个错误信息:
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'abc'
原来int()函数发现一个字符串并不是合法的数字时就会报错,程序就退出了。
如何检查并捕获程序运行期的错误呢?后面的错误和调试会讲到。
成员运算符
| 保留字 | 作用 |
|---|---|
| in | 在不在列表或者其他数据类型里面 |
| not in | 不在列表或者其他数据类型里面 |
# in 和 not in
fruits = ['apple', 'banana', 'orange']
print('apple' in fruits) # True
print('grape' not in fruits) # True
# 字符串检查
text = "Hello World"
print('Hello' in text) # True
print('hello' in text) # False实战演练
题目1:字符编码转换器
print("=== 字符编码转换器 ===")
# 字符转编码
char_input = input("请输入一个字符: ")
if len(char_input) == 1:code = ord(char_input)print(f"字符 '{char_input}' 的Unicode编码是: {code}")print(f"十六进制表示: {hex(code)}")
else:print("请输入单个字符")
print()
# 编码转字符
code_input = input("请输入一个Unicode编码(数字): ")
if code_input.isdigit():code_num = int(code_input)if 0 <= code_num <= 1114111:char_result = chr(code_num)print(f"编码 {code_num} 对应的字符是: '{char_result}'")else:print("编码超出有效范围(0-1114111)")
else:print("请输入有效的数字")题目2:学生成绩等级判断
print("=== 学生成绩等级判断 ===")
score_input = input("请输入学生成绩(0-100): ")
if score_input.replace('.', '').isdigit():score = float(score_input)if score < 0 or score > 100:print("成绩必须在0-100之间")elif score >= 90:print("等级: 优秀")print("评语: 表现非常出色!")elif score >= 80:print("等级: 良好")print("评语: 表现不错,继续努力!")elif score >= 70:print("等级: 中等")print("评语: 还有提升空间")elif score >= 60:print("等级: 及格")print("评语: 刚刚达标,需要加油")else:print("等级: 不及格")print("评语: 需要加倍努力")
else:print("请输入有效的数字成绩")题目3:购物车商品管理
print("=== 购物车商品管理 ===")
# 初始商品列表
cart = ['苹果', '香蕉', '牛奶']
print(f"当前购物车商品: {cart}")
# 添加商品
new_item = input("请输入要添加的商品: ")
if new_item.strip():cart.append(new_item)print(f"添加成功!当前购物车: {cart}")
else:print("商品名称不能为空")
# 删除商品
if len(cart) > 0:remove_choice = input("是否要删除最后一个商品?(y/n): ")if remove_choice.lower() == 'y':removed_item = cart.pop()print(f"已删除商品: {removed_item}")print(f"当前购物车: {cart}")
else:print("购物车已空,无法删除")
# 修改商品
if len(cart) > 0:change_choice = input("是否要修改第一个商品?(y/n): ")if change_choice.lower() == 'y':new_name = input("请输入新的商品名称: ")if new_name.strip():old_name = cart[0]cart[0] = new_nameprint(f"已将 '{old_name}' 修改为 '{new_name}'")print(f"当前购物车: {cart}")else:print("商品名称不能为空")题目4:元组操作演示
print("=== 元组操作演示 ===")
# 创建元组
student_info = ('张三', 18, '计算机科学')
coordinates = (10.5, 20.3)
single_item = ('只有一个元素',)
print(f"学生信息元组: {student_info}")
print(f"坐标元组: {coordinates}")
print(f"单元素元组: {single_item}")
# 访问元组元素
print(f"学生姓名: {student_info[0]}")
print(f"学生年龄: {student_info[1]}")
print(f"最后一个元素: {student_info[-1]}")
# 元组解包
name, age, major = student_info
print(f"解包结果 - 姓名: {name}, 年龄: {age}, 专业: {major}")
# 尝试修改元组(会报错)
print("尝试修改元组...")
print("元组不能被修改!这是元组的重要特性")
# 包含列表的元组(列表内容可以修改)
mixed_tuple = ('不可变部分', [1, 2, 3])
print(f"混合元组: {mixed_tuple}")
mixed_tuple[1][0] = 99
print(f"修改列表元素后: {mixed_tuple}")
print("注意:元组中的列表元素可以被修改,但元组本身指向的列表不变")题目5:登录验证系统
print("=== 登录验证系统 ===")
# 预定义的用户列表
valid_users = ['admin', 'user1', 'guest']
valid_password = '123456'
username = input("请输入用户名: ")
password = input("请输入密码: ")
# 检查用户名是否存在
if username in valid_users:print("用户名存在")# 检查密码是否正确if password == valid_password:print("登录成功!")print("欢迎使用系统")else:print("密码错误!")print("请重新输入密码")else:print("用户名不存在!")print("可用的用户名:", valid_users)
# 额外检查
if username not in valid_users and password == valid_password:print("提示: 密码正确,但用户名不存在")
elif username in valid_users and password != valid_password:print("提示: 用户名存在,但密码错误")每日一题
题目:学生信息管理系统
题目描述:创建一个基础的学生信息管理系统,能够实现以下功能:
-
添加学生信息:输入学生姓名和成绩,将学生信息添加到系统中
-
查看学生信息:显示当前系统中所有学生的信息
-
成绩等级判断:根据学生成绩判断等级(优秀、良好、中等、及格、不及格)
-
系统统计:显示学生总数和平均分
具体要求:
-
使用列表存储学生信息,每个学生用元组表示(姓名,成绩)
-
使用条件判断实现成绩等级分类
-
使用成员运算符检查用户名是否存在
-
使用字符串方法验证输入的有效性
-
不使用函数、循环、字典等高级特性
示例输出:
=== 学生信息管理系统 ===
1. 添加学生信息
2. 查看学生信息
3. 成绩等级判断
4. 系统统计
5. 退出请选择功能(1-5): 1
请输入学生姓名: 张三
请输入学生成绩: 85
成功添加学生: 张三, 成绩: 85请选择功能(1-5): 3
请输入学生姓名: 张三
学生张三的成绩85,等级: 良好挑战要求:
-
添加输入验证,确保成绩是0-100之间的数字
-
实现简单的用户身份验证
-
统计优秀学生(成绩>=90)的数量
这个题目综合运用了今天学习的所有知识点:列表与元组操作、条件判断、成员运算符等,是一个很好的综合性练习。
欢迎在评论区进行打卡留言,并分享学习经验,题目讲解以及分享更多内容,关注博主或者订阅专栏,可以第一时间看到博主的发表博文,感谢大家支持,我们下期见!