深入浅出kafka:kafka演进以及核心功能介绍
文章目录
- 序言
- 入门:为什么消息队列是 “刚需”?
- 异步:提升接口性能
- 解耦:降低系统依赖
- 削峰:抵御瞬时流量冲击
- 阶段 1:最简单的队列(Kafka V1.0)—— 解决 “耦合与削峰”
- 阶段 2:引入 Topic(Kafka V2.0)—— 解决 “消息混放混乱”
- 阶段 3:引入 Consumer Group(Kafka V3.0)—— 解决 “多场景消费干扰”
- 阶段 4:引入 Partition(Kafka V4.0)—— 解决 “消费速度跟不上生产”
- 阶段 5:从单机到分布式 —— 解决 “存储与可靠性瓶颈”
- 单机 Kafka 的三大致命局限
- Broker 集群:突破单机的存储与并发瓶颈
- 消息从 “生产” 到 “持久化”:内存与磁盘的协同流程
- 副本(Replica):给数据 “买保险”,解决可靠性瓶颈
- 先看问题:Broker 宕机的后果
- 副本的核心设计:Leader-Follower 架构
- 故障转移实例:Broker 宕机后的恢复流程
- 极端情况与最终保障:acks 参数的关键作用
- Rebalance:消费者组的 “负载均衡” 机制与潜在陷阱
- 附:Kafka 真实命令实战
序言
在分布式系统学习中,很多人对 Kafka 的理解仅停留在 “用它发消息”,却忽略了每个功能背后 “解决具体问题” 的设计逻辑。事实上,Kafka 的核心架构是从最简单的队列开始,针对真实业务痛点一步步迭代而来的。本文将沿着这一演进路径,带你理解 Kafka “是什么”,更明白 “为什么这么设计”。
入门:为什么消息队列是 “刚需”?
消息队列(MQ)的核心价值体现在三个方面:异步、解耦、削峰。
异步:提升接口性能
- 业务场景:用户注册流程包含 “存数据库→发邮件→发短信”,同步执行时接口响应时间达 2 秒,用户体验差。
- 优化方案:通过 MQ 将 “发邮件、发短信” 异步化,注册接口只需完成数据库存储后立即返回,响应时间可缩短至毫秒级。
解耦:降低系统依赖
- 业务场景:订单系统需直接调用库存、物流系统的 API。若库存系统升级接口地址,订单系统必须同步修改;若物流系统临时故障,会导致下单流程失败。
- 优化方案:订单系统创建订单后,仅向 MQ 发送 “订单创建成功” 消息,无需等待其他系统;库存系统、物流系统通过订阅 MQ 消息独立处理业务(扣减库存、创建物流单)。这样各系统独立迭代,订单系统无需关注其他系统的接口细节。
削峰:抵御瞬时流量冲击
- 核心逻辑:将瞬间爆发的高请求导入 MQ 队列,后端系统按自身能力匀速消费,避免被压垮。
- 业务场景:瞬时 10 万用户抢购,后端订单系统每秒仅能处理 2000 请求。10 万请求直接打向后端,线程池、数据库连接池被耗尽,最终系统崩溃,秒杀活动失败。有 MQ后,10 万请求先进入 MQ 队列,MQ 轻松承接瞬时流量;后端按 2000 / 秒的速度从 MQ 拉取请求,未处理的请求在队列中排队;保证公平性(按顺序处理)和可控性(可临时降低拉取速度)。
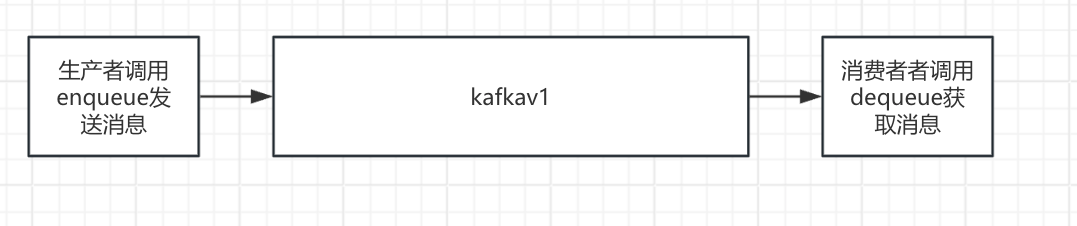
阶段 1:最简单的队列(Kafka V1.0)—— 解决 “耦合与削峰”
消息队列的底层是数据结构中的 “队列(Queue)”,遵循 “先进先出(FIFO)” 原则 —— 这是 Kafka 设计的起点。基础队列仅需实现两个核心动作:入队(生产者发送消息)和出队(消费者获取消息),以此解决简单场景的耦合与削峰问题。
代码实现
class Queue:def __init__(self):self.items = [] # 存储消息的列表self.front = 0 # 队首索引:标记已消费位置(避免删除列表头部,提升性能)def is_empty(self):"""判断队列是否为空"""return self.size() == 0def size(self):"""未消费消息数量 = 总长度 - 已消费索引"""return len(self.items) - self.frontdef enqueue(self, message):"""入队:生产者将消息加入队列尾部"""self.items.append(message)print(f"✅ 下单服务发消息:{message}(当前队列总消息数:{len(self.items)})")def dequeue(self):"""出队:消费者从队首获取消息"""if self.is_empty():print("❌ 队列已空,库存服务无消息可处理")return Nonemessage = self.items[self.front]self.front += 1 # 移动索引标记为已消费(不实际删除数据)print(f"🔍 库存服务处理消息:{message}(未消费消息数:{self.size()})")return message# 模拟真实业务流程
if __name__ == '__main__':kafka_v1 = Queue()# 1. 秒杀场景:1秒内发3条消息(峰值流量)print("=== 秒杀开始:下单服务发消息 ===")kafka_v1.enqueue("下单消息1:用户A买iPhone 15(订单号:20240618001)")kafka_v1.enqueue("下单消息2:用户B买华为Mate 60(订单号:20240618002)")kafka_v1.enqueue("下单消息3:用户C买小米14(订单号:20240618003)")# 2. 库存服务按能力处理(每秒1条,避免被压垮)print("\n=== 库存服务处理消息(每秒1条) ===")import timekafka_v1.dequeue() # 处理消息1time.sleep(1) # 模拟处理耗时kafka_v1.dequeue() # 处理消息2time.sleep(1)kafka_v1.dequeue() # 处理消息3time.sleep(1)kafka_v1.dequeue() # 队列空,提示无消息
设计细节:
- 不直接删除已消费消息(避免列表头部删除的性能损耗),而是通过front索引标记已消费位置;
- 实际 Kafka 会定期清理过期消息(如配置 “保留 7 天”),防止存储爆炸。
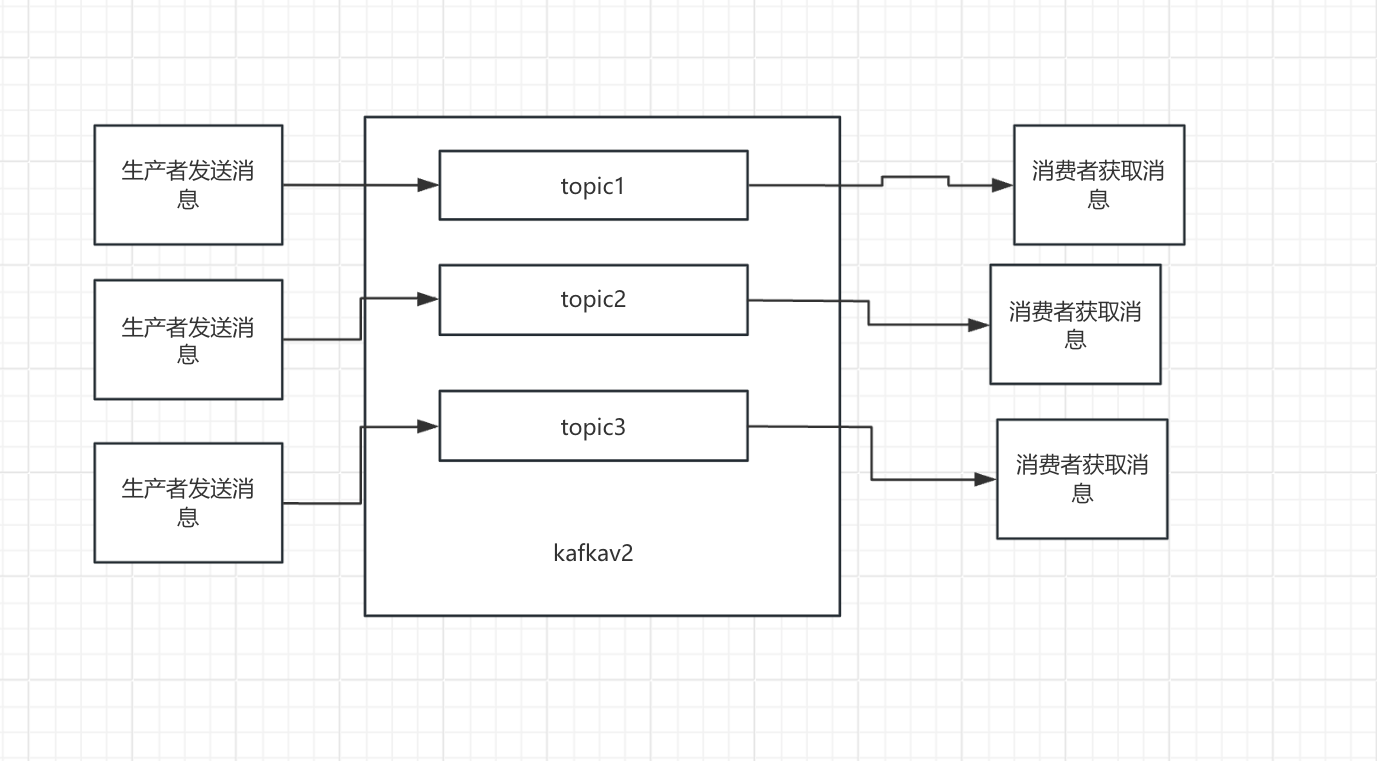
阶段 2:引入 Topic(Kafka V2.0)—— 解决 “消息混放混乱”
上面的简单队列有个致命问题:所有消息都挤在一个 “大通道” 里。
比如电商场景有三类核心消息:
- 订单消息(含 “商品 ID”“下单时间”)
- 支付消息(含 “交易流水号”“支付金额”)
- 物流消息(含 “快递单号”“收货地址”)
如果把这三类消息混在一个队列里,消费者(比如订单系统、财务系统、物流系统)每次取消息都要先 “过滤” 自己关心的类型,不仅浪费算力,还可能因消息格式不同导致解析错误(比如物流系统拿到支付消息,找不到 “快递单号” 字段)。
解决方案就是:按 “消息类型” 拆分通道 —— 这就是 Kafka 中的 Topic(主题)。
可以理解为:Topic 是 “消息的分类标签”,每个 Topic 对应一个独立的队列,不同类型的消息走不同的 Topic,从源头实现隔离。
代码实现
# 复用基础Queue类
class Queue:def __init__(self):self.items = []self.front = 0def is_empty(self): return self.size() == 0def size(self): return len(self.items) - self.frontdef enqueue(self, msg): self.items.append(msg); print(f"入队:{msg}")def dequeue(self):if self.is_empty(): return Nonemsg = self.items[self.front]; self.front +=1; return msgclass KafkaWithTopic:def __init__(self):# 核心:用字典存“Topic名称 → 对应的队列”self.topic_map = {}def create_topic(self, topic_name):"""创建Topic(避免重复创建)"""if topic_name in self.topic_map:print(f"⚠️ Topic「{topic_name}」已存在,无需重复创建")returnself.topic_map[topic_name] = Queue()print(f"✅ 成功创建Topic:{topic_name}")def send_message(self, topic_name, message):"""生产者发消息:指定Topic"""if topic_name not in self.topic_map:raise ValueError(f"❌ Topic「{topic_name}」不存在,请先创建")print(f"\n📤 生产者往「{topic_name}」发消息:")self.topic_map[topic_name].enqueue(message)def pull_message(self, topic_name, service_name):"""消费者取消息:指定Topic和服务名"""if topic_name not in self.topic_map:raise ValueError(f"❌ Topic「{topic_name}」不存在")queue = self.topic_map[topic_name]msg = queue.dequeue()if not msg:print(f"📥 {service_name}从「{topic_name}」取消息:无未消费消息")return Noneprint(f"📥 {service_name}从「{topic_name}」取消息:{msg}")return msg# 模拟电商多服务场景
if __name__ == '__main__':kafka_v2 = KafkaWithTopic()# 1. 创建3个Topic(对应三类消息)print("=== 第一步:创建Topic ===")kafka_v2.create_topic("order-topic") # 订单消息Topickafka_v2.create_topic("payment-topic") # 支付消息Topickafka_v2.create_topic("logistics-topic")# 物流消息Topic# 2. 生产者发消息(不同消息走不同Topic)print("\n=== 第二步:生产者发消息 ===")kafka_v2.send_message("order-topic", '{"order_id":"20240618001","goods_id":"iPhone15","buyer":"用户A"}')kafka_v2.send_message("payment-topic", '{"payment_id":"P20240618001","order_id":"20240618001","amount":5999}')kafka_v2.send_message("logistics-topic", '{"logistics_id":"L20240618001","order_id":"20240618001","express":"顺丰"}')# 3. 不同服务取消息(只取自己关心的Topic)print("\n=== 第三步:各服务取消息 ===")kafka_v2.pull_message("order-topic", "库存服务") # 库存服务取订单消息kafka_v2.pull_message("payment-topic", "财务服务") # 财务服务取支付消息kafka_v2.pull_message("logistics-topic", "物流服务")# 物流服务取物流消息# 错误场景演示print("\n=== 错误场景演示 ===")wrong_msg = kafka_v2.pull_message("payment-topic", "库存服务")if wrong_msg:import jsontry:msg_dict = json.loads(wrong_msg)print(f"库存服务解析消息:需要goods_id,实际拿到{msg_dict.keys()} → 解析失败!")except:pass
其他:若某服务需多类消息(如 “订单详情服务” 需订单 + 支付 + 物流信息),可同时订阅多个 Topic,按order_id关联整合 —— 这就是 Kafka 的 “多 Topic 订阅” 特性。
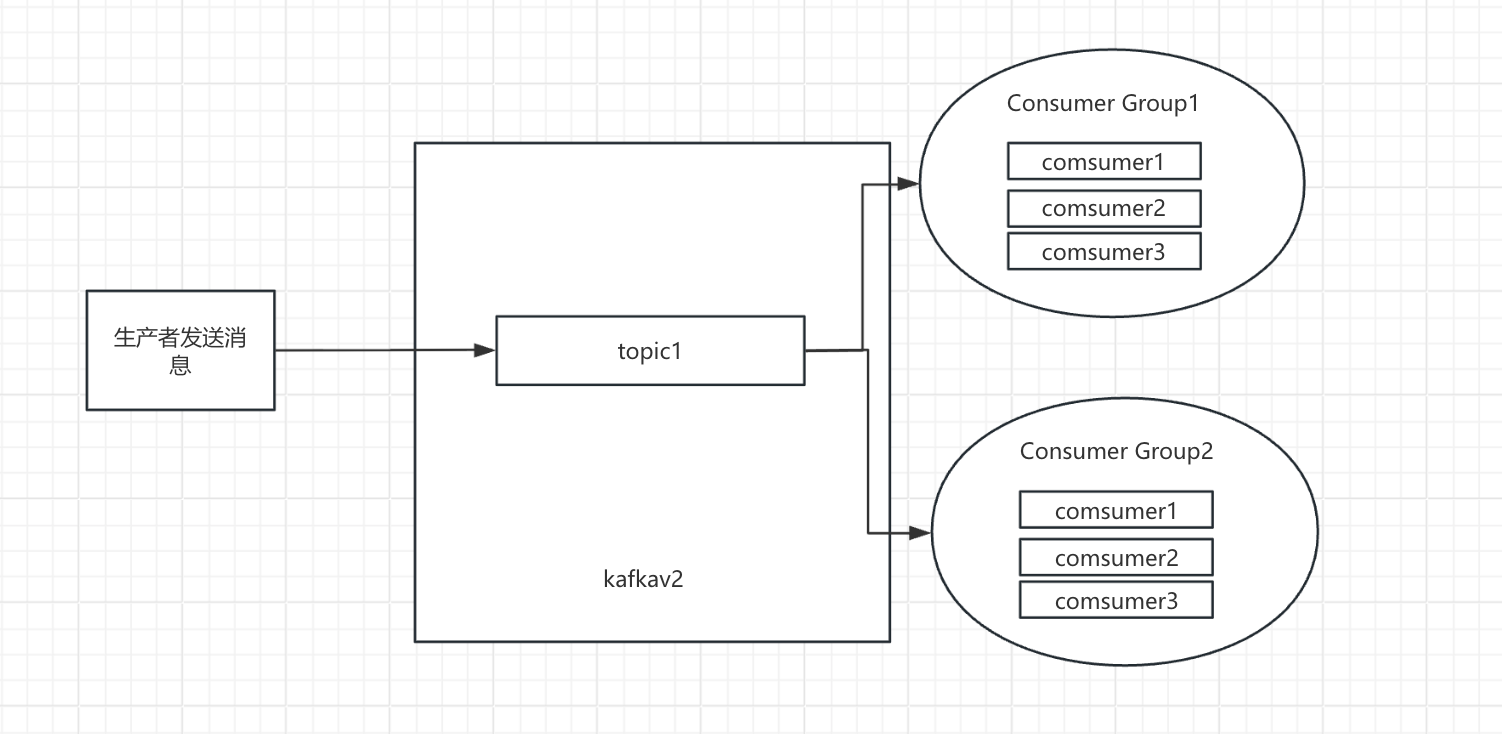
阶段 3:引入 Consumer Group(Kafka V3.0)—— 解决 “多场景消费干扰”
有了 Topic 后,新的问题又出现了:同一个 Topic 的消息,可能需要被多个独立场景消费。
比如 “order-create”(订单创建)Topic 的消息:
- 场景 1:支付系统需要消费它,生成支付链接;
- 场景 2:物流系统需要消费它,提前分配仓库;
- 场景 3:数据分析系统需要消费它,统计下单量。
如果这三个场景共用一个 “消费进度”(比如支付系统消费到第 100 条消息,物流系统也只能从第 101 条开始),一旦支付系统故障卡住,物流系统和数据分析系统也会跟着 “断粮”—— 这显然不合理。
解决方案就是:按 “消费场景” 分组 —— 这就是 Kafka 中的 Consumer Group(消费组)。
核心逻辑:
每个消费组有自己独立的 “消费进度(Offset)”—— 哪怕消费同一个 Topic,A 组消费到第 100 条,B 组可以消费到第 200 条,互不干扰;
消费者必须属于某个消费组,一个消费组可以有多个消费者(后续用于并行消费)。
Offset 是什么?
Offset 是 “下一条待消费消息的索引”,消息 1 的索引是 0,消息 2 是 1,以此类推。消费组刚创建时,Offset=0(从第一条开始),消费完消息 1 后,Offset 更新为 1(下次消费消息 2),数据分析服务重置 Offset=0,即可重新消费所有消息 —— 这就是 “消息回溯”,Kafka 的核心能力之一。
代码实现
class Queue:def __init__(self):self.items = []self.front = 0def is_empty(self): return self.size() == 0def size(self): return len(self.items) - self.frontdef enqueue(self, msg): self.items.append(msg)def dequeue(self, offset):"""按指定Offset取消息(支持重置进度)"""if offset >= len(self.items): return Nonereturn self.items[offset]class KafkaWithGroup:def __init__(self):# 核心结构:{Topic: {消费组: {队列: Queue, 当前Offset: int}}}self.topic_group_map = {}def create_topic(self, topic_name):if topic_name not in self.topic_group_map:self.topic_group_map[topic_name] = {}print(f"✅ 创建Topic:{topic_name}")def create_consumer_group(self, topic_name, group_name):"""为Topic创建消费组(初始化队列和Offset=0)"""self.create_topic(topic_name) # 没有Topic就先创建if group_name in self.topic_group_map[topic_name]:print(f"⚠️ 消费组「{group_name}」已存在于「{topic_name}」")return# 每个消费组有自己的队列(存全量消息)和Offset(初始0)self.topic_group_map[topic_name][group_name] = {"queue": Queue(),"offset": 0}print(f"✅ 为「{topic_name}」创建消费组:{group_name}")def send(self, topic_name, msg):"""发消息:广播给Topic下所有消费组的队列"""if topic_name not in self.topic_group_map:raise ValueError(f"❌ Topic「{topic_name}」不存在")for group_info in self.topic_group_map[topic_name].values():group_info["queue"].enqueue(msg)print(f"\n📤 往「{topic_name}」发消息:{msg}")def pull(self, topic_name, group_name, service_name, reset_offset=None):"""拉消息:按消费组的Offset,支持重置进度"""if topic_name not in self.topic_group_map or group_name not in self.topic_group_map[topic_name]:raise ValueError(f"❌ Topic「{topic_name}」或消费组「{group_name}」不存在")group_info = self.topic_group_map[topic_name][group_name]# 重置Offset(如数据分析服务跑批时重置为0)if reset_offset is not None:group_info["offset"] = reset_offsetprint(f"🔄 消费组「{group_name}」Offset重置为:{reset_offset}")current_offset = group_info["offset"]queue = group_info["queue"]msg = queue.dequeue(current_offset)if not msg:print(f"📥 {service_name}(组「{group_name}」):无未消费消息(当前Offset:{current_offset})")return None# 更新消费组的Offset(下次从current_offset+1开始)group_info["offset"] = current_offset + 1print(f"📥 {service_name}(组「{group_name}」):消费消息「{msg}」(Offset:{current_offset}→{group_info['offset']})")return msg# 模拟多场景消费
if __name__ == '__main__':kafka_v3 = KafkaWithGroup()topic = "order-topic"# 1. 创建两个消费组(对应两个场景)print("=== 第一步:创建消费组 ===")kafka_v3.create_consumer_group(topic, "inventory-group") # 库存服务组(实时消费)kafka_v3.create_consumer_group(topic, "analysis-group") # 数据分析组(跑批)# 2. 白天:生产者发5条订单消息print("\n=== 第二步:白天发消息 ===")for i in range(5):msg = f"订单消息{i+1}:用户{chr(65+i)}下单(订单号:2024061800{i+1})"kafka_v3.send(topic, msg)# 3. 库存服务实时消费(进度推进到5)print("\n=== 第三步:库存服务实时消费 ===")for _ in range(6): # 消费6次,最后一次无消息kafka_v3.pull(topic, "inventory-group", "库存服务")# 4. 凌晨:数据分析服务跑批(重新消费所有5条消息)print("\n=== 第四步:数据分析服务跑批 ===")kafka_v3.pull(topic, "analysis-group", "数据分析服务", reset_offset=0) # 重置Offset=0for _ in range(5): # 消费5条消息(全量)kafka_v3.pull(topic, "analysis-group", "数据分析服务")# 5. 故障场景:库存服务组故障,不影响分析组print("\n=== 第五步:故障场景演示 ===")print("❌ 库存服务组数据库故障,暂停消费(Offset停在5)")# 分析组继续消费(假设又发了1条新消息)kafka_v3.send(topic, "订单消息6:用户F下单(订单号:20240618006)")kafka_v3.pull(topic, "analysis-group", "数据分析服务") # 正常消费消息6
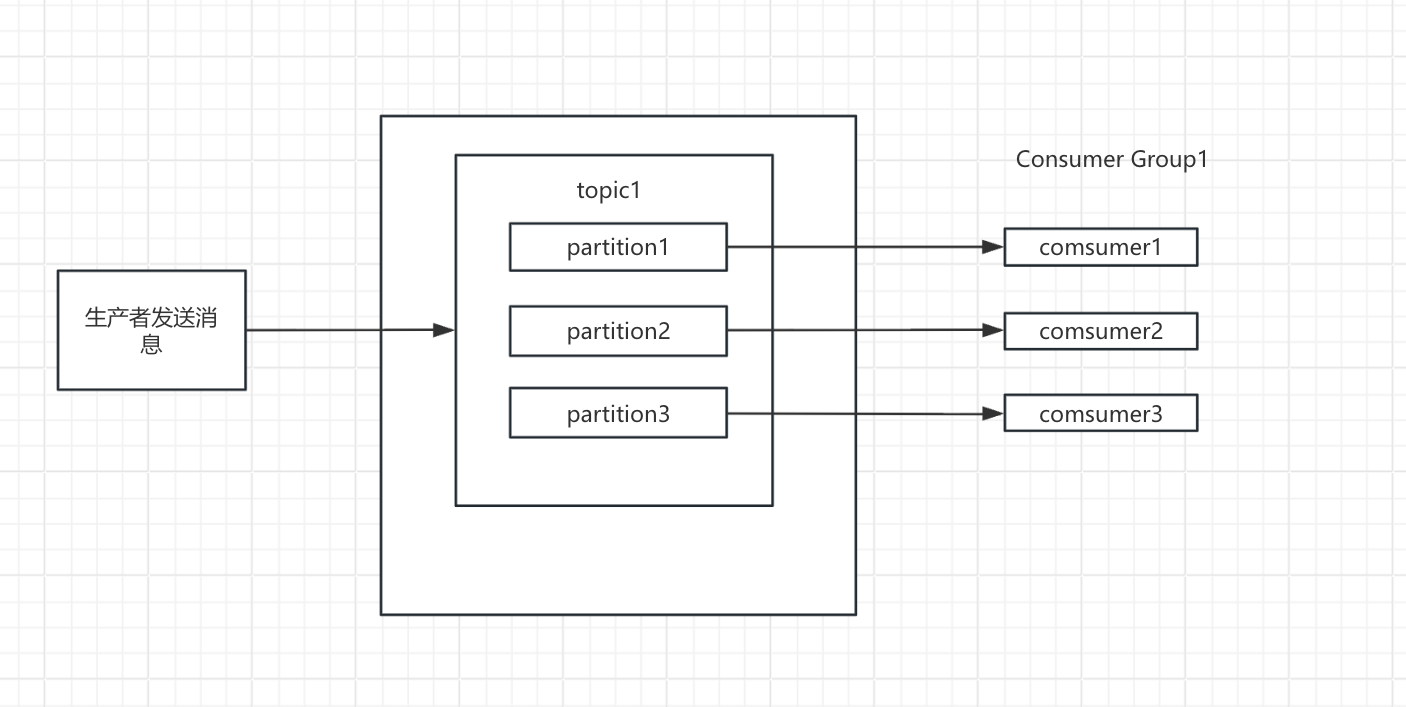
阶段 4:引入 Partition(Kafka V4.0)—— 解决 “消费速度跟不上生产”
到这里,单机 Kafka 的功能已经比较完善,但还有一个性能瓶颈:并发量不足。
假设一个场景:
生产者每秒往 “order-create” Topic 发 10 万条消息,单个消费者每秒最多处理 1 万条消息,即使给 “payment-group” 消费组加 10 个消费者,由于 Topic 只有一个队列,消费者们还是得 “抢着取消息”(同一时间只有一个消费者能取到消息),总消费速度还是 1 万条 / 秒 —— 远低于生产速度,导致消息积压(队列越堆越长,最终内存溢出)。
解决方案就是:拆分队列 —— 这就是 Kafka 中的 Partition(分区)。
核心逻辑:
一个 Topic 可以拆分为多个 Partition(比如 10 个),每个 Partition 是一个独立的子队列。生产者发消息时,会按规则(哈希 / 轮询)将消息分配到不同 Partition,消费组的消费者可以 “分工”:一个消费者负责一个或多个 Partition 的消费,实现 “并行消费”,总消费速度 = 单个消费者速度 × 消费者数量(前提是 Partition 数量 ≥ 消费者数量)。
代码实现
class Partition:"""分区:独立的子队列,带自己的Offset"""def __init__(self):self.messages = [] # 分区存储的消息self.offset = 0 # 该分区的消费Offsetdef add_msg(self, msg):self.messages.append(msg)def get_msg(self):if self.offset >= len(self.messages):return Nonemsg = self.messages[self.offset]self.offset += 1return msgdef get_size(self):return len(self.messages) - self.offsetclass KafkaWithPartition:def __init__(self):# 核心结构:{Topic: {消费组: [Partition1, Partition2, ...]}}self.topic_group_partitions = {}def create_topic(self, topic_name, partition_num=1):"""创建Topic,指定分区数(默认1)"""if topic_name in self.topic_group_partitions:print(f"⚠️ Topic「{topic_name}」已存在")returnif partition_num < 1:raise ValueError("❌ 分区数必须≥1")self.topic_group_partitions[topic_name] = {}print(f"✅ 创建Topic「{topic_name}」,分区数:{partition_num}")def create_group(self, topic_name, group_name):"""为Topic创建消费组,初始化对应数量的Partition"""if topic_name not in self.topic_group_partitions:raise ValueError(f"❌ Topic「{topic_name}」不存在")# 拿到Topic的分区数(从已有的组取,没有则默认1)partition_num = 1if self.topic_group_partitions[topic_name]:sample_group = next(iter(self.topic_group_partitions[topic_name].values()))partition_num = len(sample_group)# 为消费组创建对应数量的Partitionself.topic_group_partitions[topic_name][group_name] = [Partition() for _ in range(partition_num)]print(f"✅ 为「{topic_name}」创建消费组「{group_name}」,分区数:{partition_num}")def send_msg(self, topic_name, msg, key=None):"""发消息:按key哈希分配到Partition(key为空则轮询)"""if topic_name not in self.topic_group_partitions:raise ValueError(f"❌ Topic「{topic_name}」不存在")if not self.topic_group_partitions[topic_name]:print(f"⚠️ Topic「{topic_name}」无消费组,消息「{msg}」丢弃")return# 拿到分区数sample_group = next(iter(self.topic_group_partitions[topic_name].values()))partition_num = len(sample_group)# 按key哈希分配分区(确保同一key的消息进同一分区)if key:partition_idx = hash(key) % partition_numelse:# 轮询分配(简化)global send_countsend_count = getattr(self, 'send_count', 0)partition_idx = send_count % partition_numself.send_count = send_count + 1# 把消息加入该Topic所有消费组的对应分区for group_partitions in self.topic_group_partitions[topic_name].values():group_partitions[partition_idx].add_msg(msg)print(f"📤 消息「{msg}」分配到「{topic_name}」分区{partition_idx}(key:{key})")def pull_msg(self, topic_name, group_name, consumer_id):"""拉消息:消费者按ID分配Partition(1个消费者对应1个分区)"""if topic_name not in self.topic_group_partitions or group_name not in self.topic_group_partitions[topic_name]:raise ValueError(f"❌ Topic或消费组不存在")group_partitions = self.topic_group_partitions[topic_name][group_name]partition_num = len(group_partitions)# 消费者ID对应分区索引(确保1个消费者只处理1个分区)partition_idx = consumer_id % partition_numpartition = group_partitions[partition_idx]msg = partition.get_msg()if not msg:print(f"📥 消费者{consumer_id}(组「{group_name}」):分区{partition_idx}无消息(未消费:{partition.get_size()})")return Noneprint(f"📥 消费者{consumer_id}(组「{group_name}」):分区{partition_idx}消费「{msg}」(未消费:{partition.get_size()})")return msg# 模拟秒杀并发场景
if __name__ == '__main__':kafka_v4 = KafkaWithPartition()topic = "order-topic"# 1. 创建Topic,指定10个分区(应对10万/秒生产速度)print("=== 第一步:创建Topic(10个分区) ===")kafka_v4.create_topic(topic, partition_num=10)# 2. 创建消费组(库存服务组)print("\n=== 第二步:创建消费组 ===")kafka_v4.create_group(topic, "inventory-group")# 3. 秒杀场景:生产者1秒发10条消息(模拟10万/秒)print("\n=== 第三步:生产者发10条消息 ===")for i in range(10):order_id = f"202406180{i+1}"msg = f"订单{order_id}:用户下单"kafka_v4.send_msg(topic, msg, key=order_id) # 按order_id哈希,同一订单进同一分区# 4. 无分区对比:1个消费者处理10条消息(需10秒)print("\n=== 对比1:无分区(1个消费者) ===")import timestart = time.time()for _ in range(10):kafka_v4.pull_msg(topic, "inventory-group", consumer_id=0)time.sleep(1) # 模拟每秒处理1条print(f"总耗时:{time.time() - start:.1f}秒(1个消费者,无分区)")# 5. 有分区:10个消费者并行处理(需1秒)print("\n=== 对比2:有分区(10个消费者) ===")# 重置消费组的Partition Offset(重新消费)for partition in kafka_v4.topic_group_partitions[topic]["inventory-group"]:partition.offset = 0start = time.time()# 10个消费者同时处理(模拟并行)for consumer_id in range(10):kafka_v4.pull_msg(topic, "inventory-group", consumer_id)print(f"总耗时:{time.time() - start:.1f}秒(10个消费者,10个分区)")
阶段 5:从单机到分布式 —— 解决 “存储与可靠性瓶颈”
单机 Kafka 的三大致命局限
单机 Kafka(即 “1 个 Broker” 部署)仅适用于小规模场景,当面对海量数据(如电商日志、实时业务消息)时,会直接撞上以下三大瓶颈:
-
存储量严重不足
单机的硬盘容量是固定的,无法支撑大规模数据的长期存储。以某电商平台 “用户行为日志” Topic 为例,每日产生数据量500GB,数据保留周期30 天,总需存储量:500GB / 天 × 30 天 = 15TB,单机硬盘上限:通常为 2TB~4TB(主流服务器配置),显然,15TB 的需求远超单机存储上限,直接导致数据无法完整保留。 -
数据无备份,单点故障即数据全丢
单机架构下,数据仅存储在单台服务器的磁盘中,一旦发生硬件故障(如断电、硬盘损坏)或进程崩溃,未消费的消息会直接丢失。例如:某支付系统依赖 Kafka 传递 “订单创建” 消息,若单机 Kafka 突然断电,未消费的 10 万条订单消息会全部丢失,直接导致业务对账异常。 -
并发上限被锁死,消息积压成灾
单机的 CPU、内存、网络资源有限,导致 Kafka 的读写并发能力存在硬上限:单机 Kafka 最大支持约 20 万条 / 秒的读写吞吐量,若试图通过增加 Partition 数量提升并发(每个 Partition 需独立线程与缓存),会快速耗尽单机资源(如 CPU 占用率飙升至 100%),反而导致服务不可用。当业务并发超过单机上限时,消息会大量积压在生产者端,最终引发业务超时、数据延迟等问题。
Broker 集群:突破单机的存储与并发瓶颈
为解决单机的 “存储不足” 与 “并发受限” 问题,Kafka 引入Broker 集群—— 由多台服务器(每台运行 1 个 Broker 进程)组成分布式集群,通过 “分区分散存储” 与 “压力分担” 实现线性扩展。
- 核心概念:Broker 与集群架构
- Broker:单台服务器上运行的 Kafka 进程,是 Kafka 的 “工作节点”(单机 Kafka 即 “1 个 Broker”);
- Broker 集群:由 N 台 Broker 组成(生产环境通常为 3 台、5 台或更多,奇数台便于后续选举),所有 Broker 共享 Topic 的元数据(如 - Partition 分布、Leader 位置)。
- 两大核心能力:解决单机瓶颈
- 分区分散存储:突破存储上限:Kafka 将 Topic 的所有 Partition均匀分配到不同 Broker,避免单台 Broker 存储过载。例如:
某 Topic 配置 100 个 Partition,部署在 5 个 Broker 的集群中,每个 Broker 仅存储 20 个 Partition(100÷5),单机存储压力直接降低为原来的 1/5,若需扩展存储,只需新增 Broker,Kafka 会自动将部分 Partition 迁移到新节点,实现 “扩容不中断业务”。 - 并发压力分担:突破吞吐上限:Broker 集群会将读写请求分散到所有节点,实现吞吐量的线性扩展,单机 Broker 的吞吐量为 20 万条 / 秒,5 个 Broker 组成的集群,理论吞吐量可达 20 万条 / 秒 × 5 = 100 万条 / 秒。
- 分区分散存储:突破存储上限:Kafka 将 Topic 的所有 Partition均匀分配到不同 Broker,避免单台 Broker 存储过载。例如:
消息从 “生产” 到 “持久化”:内存与磁盘的协同流程
在理解 “可靠性” 之前,需先明确:Kafka 的消息并非直接写入磁盘,而是通过 “内存缓冲→页缓存→磁盘持久化” 的三步流程,在 “性能” 与 “可靠性” 间取得平衡。我们以 “用户发送一条订单消息” 为例,拆解完整流转逻辑:
第一步:生产者内存缓冲区 —— 攒批发送,提升吞吐
业务系统调用 Kafka 生产者发送消息时,消息不会直接发往 Broker,而是先进入生产者的内存缓冲区(由buffer.memory配置控制,默认 32MB)。
-
核心逻辑:缓冲区按 “目标 Partition” 分组,将同一 Partition 的消息攒成 “消息批次(Batch)”,满足以下任一条件时触发发送:
- 批次大小达到batch.size(默认 16KB);
- 等待时间达到linger.ms(默认 0ms,即 “有消息就发”,生产环境常调整为 5~10ms 以增加批次大小)。
-
作用:避免单条消息频繁发送导致的 “网络请求风暴”,通过 “批量发送” 降低网络 IO 次数,提升吞吐量。
第二步:Broker 内存页缓存 —— 快速响应,加速写入
生产者将 “消息批次” 发送到 Broker 后,Broker不会直接写入磁盘,而是先写入内存页缓存(Page Cache) —— 这是操作系统为磁盘文件分配的内存缓存。
- 核心设计:Kafka 不自己管理内存,而是直接复用操作系统的页缓存,避免手动管理内存导致的 JVM GC 频繁(若 Kafka 自己维护缓存,大内存下 GC 可能耗时数秒,导致服务卡顿)。
- 作用:内存写入速度比磁盘快 100~1000 倍,先写页缓存能让 Broker 快速向生产者返回 “发送成功” 响应,显著提升写入性能。
第三步:Broker 磁盘日志文件 —— 持久化兜底,确保不丢
消息写入页缓存后,Kafka 通过异步刷盘机制,将页缓存中的消息批量写入磁盘的日志文件(Log File),完成最终持久化。刷盘由两个参数控制(默认 “按消息数 + 按时间” 双触发,避免单一条件导致的延迟或频繁刷盘):
- log.flush.interval.messages:页缓存中积累的消息数达到该值(默认 10000 条),触发刷盘;
- log.flush.interval.ms:页缓存中消息的停留时间达到该值(默认 5000ms),触发刷盘。
副本(Replica):给数据 “买保险”,解决可靠性瓶颈
Broker 集群解决了 “存储” 与 “并发” 问题,但未解决 “单点故障”—— 若某台 Broker 宕机,其存储的 Partition 会无法访问,且未刷盘的页缓存数据会丢失。此时,副本(Replica)机制成为 Kafka 可靠性的核心保障。
先看问题:Broker 宕机的后果
若未开启副本,当一台 Broker 突然宕机(如断电),会引发两大问题:
- 生产者消息丢失:生产者无法向该 Broker 上的 Partition 发送消息,消息会暂存于生产者内存缓冲区;若缓冲区满(达到buffer.memory阈值),生产者会根据max.block.ms(默认 60000ms)阻塞请求,超时后抛出TimeoutException,未发送的消息会丢失。
- Broker 数据丢失:该 Broker 页缓存中未刷盘的消息会直接丢失,即使已刷盘的 Partition,也因 Broker 宕机无法访问,导致业务中断。
副本的核心设计:Leader-Follower 架构
为解决上述问题,Kafka 为每个 Partition 配置1 个 Leader 副本 + N 个 Follower 副本(生产环境通常配置 N=2,即 1 主 2 从),核心逻辑如下:
- Leader 副本:唯一对外提供读写服务的副本,所有生产者的写入、消费者的读取都直接与 Leader 交互
- Follower 副本:仅负责从 Leader 同步数据(按 Offset 顺序拉取消息),不对外提供服务;
- ISR 列表:即 “同步完成的 Follower 副本列表”(In-Sync Replicas),只有 Follower 的消息同步进度与 Leader 的差距在阈值内(由replica.lag.time.max.ms控制,默认 30000ms),才会被纳入 ISR 列表
- 故障转移:若 Leader 所在 Broker 宕机,Kafka 会从 ISR 列表中选举 1 个 Follower 升级为新 Leader,业务不中断、数据不丢失。
故障转移实例:Broker 宕机后的恢复流程
假设集群有 2 台 Broker(Broker1、Broker2),Partition1 的 Leader 在 Broker1,Follower 在 Broker2(已纳入 ISR 列表)。当 Broker1 突然崩溃,恢复流程分为三步:
(1)崩溃检测:感知 Broker 下线
- 心跳机制:每个 Broker 会定期向 ZooKeeper 发送心跳(默认每 3 秒);若 ZooKeeper 超过zookeeper.session.timeout.ms(默认 6 秒)未收到心跳,会将 Broker1 标记为 “下线”;
- Controller 感知:Kafka 集群会选举 1 个 Broker 作为 “Controller”(集群管理者),Controller 会监听 ZooKeeper 上的 Broker 状态变化,当发现 Broker1 下线后,立即触发后续处理。
(2)Leader 选举:从 ISR 中选新 Leader
Controller 会为 Partition1 执行 Leader 选举,核心规则是 “仅从 ISR 列表中选择”(确保新 Leader 数据完整),由于 Broker2 的 Follower 副本已同步完 Broker1 的所有消息(属于 ISR 列表),Controller 会将 Broker2 上的 Follower 副本升级为新 Leader,选举完成后,Controller 会将 “Partition1 的新 Leader 在 Broker2” 这一元数据,广播给所有 Broker、生产者与消费者。
(3)生产消费切换:业务无缝恢复
- 生产者切换:生产者发送消息前,会先发送 “Metadata 请求” 查询 Partition1 的 Leader 位置;得知新 Leader 在 Broker2 后,生产者会将缓冲区中积压的失败消息一并发送到 Broker2,避免消息丢失;
- 消费者切换:消费者同样通过 “Metadata 请求” 获取新 Leader 地址,切换到 Broker2 读取 Partition1 的消息;由于消费者会将 “已消费的 Offset” 提交到 Kafka 内部的__consumer_offsets主题(默认),若崩溃前已消费到 Offset=1000 并提交,重启后会从新 Leader 的 Offset=1001 继续消费,无重复、无遗漏。
整个故障转移过程耗时约 6 秒(与 ZooKeeper 心跳超时一致),业务几乎无感知。
极端情况与最终保障:acks 参数的关键作用
即使开启副本,仍存在一种极端情况导致数据丢失:Leader 收到消息后,未同步给 Follower 就突然宕机(如刚写入页缓存就断电)。此时,若生产者已收到 “发送成功” 的响应,会认为消息已持久化,但实际上 Follower 未同步该消息,新 Leader 上线后会丢失这部分数据。
- 问题根源:Kafka 默认的acks=1配置(即 “Leader 写入页缓存即返回成功”)是导致上述问题的根源 —— 此时 Leader 未等待 Follower 同步,就向生产者确认 “成功”,若 Leader 宕机,未同步的消息会丢失。
- 解决方案:设置 acks=-1(或 acks=all),将acks参数设置为-1(等价于all),可彻底避免该问题,核心逻辑是:
- 生产者确认条件:生产者发送的消息,必须被 Leader 副本 + 所有 ISR 列表中的 Follower 副本都 “写入页缓存” 后,才会收到 “发送成功” 的响应;
- 数据安全性:即使 Leader 宕机,ISR 中的 Follower 已同步完所有消息,新 Leader 上线后数据完整,无丢失风险。
以上述极端情况为例:
若设置acks=-1,Leader(Broker1)收到 Offset=1031-1050 的 20 条消息后,不会立即确认,需等待 Follower(Broker2)同步完这 20 条消息(Follower 的 Offset 也达到 1050),才向生产者返回 “成功”,此时即使 Broker1 突然断电,Broker2 的 Follower 已同步完 1050 条消息,升级为新 Leader 后,这 20 条消息不会丢失。
Rebalance:消费者组的 “负载均衡” 机制与潜在陷阱
在 Kafka 消费链路中,单个消费者的处理能力有限,因此引入消费者组(Consumer Group)—— 由多个消费者组成的集群,共同消费一个或多个 Topic 的所有 Partition(规则:每个 Partition 仅被组内一个消费者消费,避免重复消费)。而 Rebalance 是消费者组实现 “动态负载均衡” 的核心机制,但其频繁触发会成为业务消费的隐形杀手。
核心概念:消费者组与 Rebalance 的本质
- 消费者组(Consumer Group):一组协同工作的消费者,共享同一个group.id,共同承担 Topic 的消费任务。例如:某订单 Topic 有 10 个 Partition,由 3 个消费者组成的 group 消费,Kafka 会将 10 个 Partition 分配给 3 个消费者(如 4-3-3 的分配比例),每个消费者仅处理分配给自己的 Partition,一般情况下默认平均分配。
- Rebalance 定义:当消费者组内的 “消费关系” 发生变化时(如消费者数量增减、Partition 数量变化),Kafka 会重新计算 Partition 与消费者的分配关系,这个过程称为 Rebalance。其目的是确保 Partition 被均匀分配,避免部分消费者过载、部分空闲。
触发 Rebalance 的三大场景
Rebalance 并非随时发生,仅当以下 “消费关系变更” 事件触发时才会执行:
- 消费者数量变化
- 新消费者加入组(如扩容增加消费能力);
- 消费者主动退出(如正常关闭)或崩溃(如进程挂掉、网络断开)。
例:某日志消费组原有 2 个消费者,因消息积压新增 1 个消费者,触发 Rebalance 后 3 个消费者重新分配 Partition。
附:Kafka 真实命令实战
https://cloud.tencent.com/developer/article/2468202