京东Java后台开发面试题及参考答案(下)
Java 中有哪些基本数据类型?一个 char 类型可以存储汉字吗?
Java 中的数据类型分为基本数据类型和引用数据类型,其中基本数据类型是直接存储数据值的,而非对象引用。Java 共有 8 种基本数据类型,可分为四大类:
整数类型:用于存储整数,包括 byte、short、int、long。
- byte:8 位,范围 -128~127,默认值 0,适用于节省内存的场景(如处理文件流)。
- short:16 位,范围 -32768~32767,默认值 0,适用于中等长度的整数存储。
- int:32 位,范围 -2³¹~2³¹-1,默认值 0,是最常用的整数类型,如循环计数器、数组索引等。
- long:64 位,范围 -2⁶³~2⁶³-1,默认值 0L,用于存储大整数,定义时需在数值后加 L 或 l(如 100L)。
浮点类型:用于存储小数,包括 float、double。
- float:32 位单精度浮点,范围约 ±3.4×10³⁸,默认值 0.0f,定义时需加 f 或 F(如 3.14f),精度较低,适用于内存紧张场景。
- double:64 位双精度浮点,范围约 ±1.8×10³⁰⁸,默认值 0.0d,是默认的浮点类型(如 3.14 无需后缀),精度更高,适用于科学计算。
字符类型:char,16 位,用于存储单个字符,范围 0~65535,默认值 '\u0000'(空字符)。Java 中 char 采用 Unicode 编码,可表示包括英文字母、数字、符号、汉字等在内的字符。
布尔类型:boolean,用于表示真(true)或假(false),默认值 false,无明确位数定义,通常用于条件判断。
关于 “一个 char 类型是否可以存储汉字”,答案是可以。原因是 Java 中的 char 基于 Unicode 编码,而 Unicode 包含了几乎所有语言的字符(包括汉字),每个汉字在 Unicode 中都有对应的编码值(如 “中” 的 Unicode 编码是 \u4e2d),且编码值在 0~65535 范围内,因此一个 char 类型足以存储单个汉字。
面试关键点:需准确区分基本类型与引用类型(如 String 是引用类型),明确各类型的位数和范围,理解 char 的 Unicode 特性。加分点:提及基本类型的包装类(如 Integer、Character),以及自动装箱 / 拆箱机制(如 int 与 Integer 的自动转换)。记忆法:采用 “分类记忆法”—— 将 8 种类型按 “整数(4 种)、浮点(2 种)、字符(1 种)、布尔(1 种)” 分类,结合各自的位数和用途辅助记忆,如 “整数从短到长:byte (8)→short (16)→int (32)→long (64)”。
面向对象的三大特性是什么?
面向对象编程(OOP)的三大特性是封装、继承和多态,它们是面向对象设计的核心思想,旨在提高代码的复用性、可维护性和扩展性。
封装封装是指将对象的属性(数据)和方法(操作)捆绑在一起,隐藏内部实现细节,仅通过公开的接口与外部交互。其核心是 “信息隐藏”,通过访问修饰符(private、default、protected、public)控制成员的访问权限:
- private:仅当前类可见,完全隐藏内部细节(如对象的私有属性)。
- default(缺省):仅同一包内可见。
- protected:同一包内或子类可见。
- public:全局可见,作为对外接口。例如,一个 Person 类可将 name、age 设为 private,通过 public 的 get/set 方法供外部访问,避免直接修改属性导致的数据混乱。封装的作用是降低耦合度,保障数据安全性,便于后续维护。
继承继承是指子类(派生类)通过 extends 关键字继承父类(基类)的属性和方法,从而实现代码复用。子类可直接使用父类的非私有成员,并可新增自己的属性 / 方法或重写父类方法。特点包括:
- 单继承:Java 中类只能直接继承一个父类(避免多继承的菱形问题),但可通过接口实现多继承效果。
- 传递性:子类继承父类,同时也继承父类的父类(如类 C 继承 B,B 继承 A,则 C 间接继承 A)。例如,Animal 类作为父类定义 eat () 方法,Dog 类继承 Animal 后可直接使用 eat (),并新增 bark () 方法,体现了 “is-a” 的关系(Dog is a Animal)。继承的作用是减少代码冗余,建立类之间的层次关系。
多态多态是指同一行为(方法调用)在不同对象上有不同的实现效果,即 “一个接口,多种实现”。其实现依赖两个条件:
- 继承或实现:子类继承父类,或类实现接口。
- 方法重写:子类重写父类的方法(或实现接口的抽象方法)。
- 父类引用指向子类对象:如 Animal dog = new Dog (),此时调用 dog.eat () 会执行 Dog 类的 eat () 实现。多态的作用是提高代码的灵活性和扩展性,例如通过父类引用统一管理不同子类对象,新增子类时无需修改原有代码(符合开闭原则)。此外,方法重载(同一类中方法名相同、参数不同)也是多态的一种体现(编译时多态)。
面试关键点:需明确三大特性的定义、实现方式及作用,区分方法重写与重载,理解多态的运行时动态绑定机制。加分点:结合设计模式(如工厂模式利用多态)或实际场景(如用继承实现类的层次设计)说明特性的应用。记忆法:采用 “逻辑关联记忆法”—— 封装是基础(隐藏细节),继承是手段(复用代码),多态是目的(灵活扩展),三者递进关联,共同支撑面向对象的设计思想。
父类的 private 修饰的成员变量和方法,子类可以继承吗?
父类中被 private 修饰的成员变量和方法,子类不能继承。这是由 private 修饰符的访问权限规则决定的:private 成员仅在当前类内部可见,对其他类(包括子类)完全隐藏,子类无法直接访问或拥有这些成员。
从继承的本质来看,继承的核心是子类获取父类的非私有成员(属性和方法),从而实现代码复用。但 private 成员因访问权限限制,无法被子类继承,具体表现为:
子类无法直接访问:子类中不能直接调用父类的 private 方法,也不能直接访问父类的 private 变量。例如:
class Parent {private int num = 10;private void print() {System.out.println("Parent's print");} } class Child extends Parent {public void test() {System.out.println(num); // 编译错误:无法访问父类的private变量print(); // 编译错误:无法访问父类的private方法} }子类不能重写父类的 private 方法:重写的前提是子类可见父类的方法(如 protected 或 public),而 private 方法对子类不可见,因此不存在重写的可能。即使子类定义了与父类 private 方法同名同参数的方法,也视为子类的新方法,而非重写。
通过父类的非私有方法间接访问:若父类提供了 public 或 protected 的方法来访问其 private 成员,子类可通过调用这些方法间接使用父类的 private 成员。例如:
class Parent {private int num = 10;public int getNum() { // 父类提供public方法访问private变量return num;} } class Child extends Parent {public void test() {System.out.println(getNum()); // 合法:通过父类的public方法间接访问} }这种情况下,子类并非继承了父类的 private 成员,而是借助父类的公开接口间接使用,本质上 private 成员仍属于父类,子类并未拥有。
需要注意的是,部分开发者可能混淆 “继承” 与 “访问” 的概念:继承强调子类是否拥有父类的成员,而访问强调子类能否直接使用这些成员。private 成员因完全隐藏,子类既不拥有(不继承),也无法直接访问。
面试关键点:明确 private 修饰符的访问权限规则,区分 “继承” 与 “访问” 的差异,说明子类间接使用父类 private 成员的方式。加分点:对比 protected 修饰符(子类可见,可继承),进一步说明访问修饰符对继承的影响。记忆法:采用 “权限决定论”——private 的核心是 “私有”,即仅限当前类使用,子类因权限不足无法继承,可简化记忆为 “私有成员,子类无份”。
接口和抽象类的区别是什么?
接口(interface)和抽象类(abstract class)是 Java 中实现抽象编程的两种重要方式,二者均包含抽象方法(未实现的方法),但在定义、功能和使用场景上有显著区别,具体如下:
| 对比维度 | 接口(interface) | 抽象类(abstract class) |
|---|---|---|
| 定义关键字 | 使用 interface 关键字定义 | 使用 abstract class 关键字定义 |
| 继承 / 实现方式 | 类通过 implements 关键字实现接口 | 类通过 extends 关键字继承抽象类 |
| 继承数量 | 一个类可实现多个接口(多实现) | 一个类只能继承一个抽象类(单继承) |
| 抽象方法 | Java 8 前:所有方法默认是 public abstract(必须抽象);Java 8 及后:可包含 default 方法(有实现)和 static 方法(有实现),但抽象方法仍需子类实现 | 可包含抽象方法(需用 abstract 修饰)和具体方法(有实现),抽象方法数量无限制 |
| 成员变量 | 只能是 public static final(常量),必须初始化 | 可包含各种修饰符的成员变量(private、protected、public 等),可被继承和修改 |
| 构造方法 | 无构造方法 | 有构造方法(供子类调用) |
| 静态成员 | 可包含 static 方法和 static 变量(常量) | 可包含 static 方法、static 变量(非 final) |
| 设计目的 | 定义规范(“做什么”),体现 “has-a” 关系(类具备接口的能力) | 作为模板(“是什么”+“怎么做”),体现 “is-a” 关系(子类是父类的一种) |
| 使用场景 | 多实现需求、定义跨类的通用功能(如 Comparable 接口) | 类间存在继承关系、需要复用代码(如抽象类提供通用实现) |
具体差异补充:
- 方法实现:接口在 Java 8 前完全是抽象的,Java 8 引入 default 方法允许接口提供默认实现(子类可重写),Java 9 进一步支持 private 方法(仅接口内部使用);抽象类可自由混合抽象方法和具体方法,更适合提供部分实现。
- 多继承支持:接口的多实现机制弥补了 Java 类单继承的限制,例如一个类可同时实现 Runnable 和 Serializable 接口,兼具多线程和序列化能力。
- 设计理念:接口侧重 “行为规范”,如 List 接口定义了 add ()、get () 等方法,具体实现交给 ArrayList、LinkedList 等类;抽象类侧重 “模板设计”,如 InputStream 抽象类提供了 read () 抽象方法,同时实现了 close () 等通用方法,子类只需关注 read () 的具体实现。
面试关键点:需从定义、继承方式、方法 / 变量修饰符、设计目的等多维度对比,提及 Java 8+ 对接口的增强(default 方法),结合使用场景说明二者的选择依据。加分点:举例说明实际应用(如 Collection 是接口,AbstractCollection 是抽象类),分析为何 Java 设计为类单继承而接口多实现。记忆法:采用 “角色定位记忆法”—— 接口是 “规则制定者”(只定标准,可多遵守),抽象类是 “模板提供者”(既有标准也有示例,只能单继承),通过角色差异区分二者特性。
静态类和静态内部类的区别是什么?
在 Java 中,“静态类” 这一说法并不严谨,因为顶级类(独立定义的类)不能被 static 修饰,static 只能用于修饰内部类(嵌套在其他类中的类),即 “静态内部类”。因此,通常讨论的 “静态类” 实际指 “静态内部类”,而与其对比的是 “非静态内部类”(普通内部类)。二者的区别主要体现在定义、实例化、访问权限等方面:
定义方式
- 静态内部类:在内部类前加 static 修饰,定义在外部类的成员位置。
class Outer {static class StaticInner { // 静态内部类// 成员} } - 非静态内部类:无 static 修饰,同样定义在外部类的成员位置。
class Outer {class NonStaticInner { // 非静态内部类// 成员} }
- 静态内部类:在内部类前加 static 修饰,定义在外部类的成员位置。
实例化依赖
- 静态内部类:实例化不依赖外部类的实例,可直接通过 “外部类。静态内部类” 的方式创建对象。
Outer.StaticInner staticInner = new Outer.StaticInner(); - 非静态内部类:实例化必须依赖外部类的实例,需先创建外部类对象,再通过外部类对象创建内部类对象。
Outer outer = new Outer(); Outer.NonStaticInner nonStaticInner = outer.new NonStaticInner();
- 静态内部类:实例化不依赖外部类的实例,可直接通过 “外部类。静态内部类” 的方式创建对象。
访问外部类成员的权限
- 静态内部类:只能直接访问外部类的静态成员(静态变量、静态方法),无法直接访问外部类的非静态成员(需通过外部类实例访问)。
class Outer {static int staticNum = 10;int nonStaticNum = 20;static class StaticInner {void test() {System.out.println(staticNum); // 合法:访问外部类静态成员// System.out.println(nonStaticNum); // 编译错误:无法直接访问非静态成员Outer outer = new Outer();System.out.println(outer.nonStaticNum); // 合法:通过外部类实例访问}} } - 非静态内部类:可直接访问外部类的所有成员(静态和非静态),因为其内部持有外部类的引用(Outer.this)。
class Outer {static int staticNum = 10;int nonStaticNum = 20;class NonStaticInner {void test() {System.out.println(staticNum); // 合法System.out.println(nonStaticNum); // 合法}} }
- 静态内部类:只能直接访问外部类的静态成员(静态变量、静态方法),无法直接访问外部类的非静态成员(需通过外部类实例访问)。
是否持有外部类引用
- 静态内部类:不持有外部类的实例引用,独立性更强,类似于一个独立的类,只是定义在外部类内部。
- 非静态内部类:隐式持有外部类的实例引用,因此可能导致内存泄漏(如内部类对象生命周期长于外部类对象时,外部类对象无法被回收)。
使用场景
- 静态内部类:当内部类与外部类的非静态成员无关,仅需依赖外部类的静态资源,或需作为独立组件被外部使用时(如工具类中的辅助类),适合用静态内部类。例如,HashMap 中的 Node 静态内部类,用于存储键值对,不依赖 HashMap 的非静态成员。
- 非静态内部类:当内部类需要频繁访问外部类的非静态成员,或与外部类存在强关联(如 “部分 - 整体” 关系)时,适合用非静态内部类。例如,LinkedList 中的 Node 非静态内部类,需要访问链表的头节点、尾节点等非静态成员。
面试关键点:明确 Java 中无顶级静态类,区分静态内部类与非静态内部类的实例化方式、成员访问权限及持有外部类引用的差异,结合使用场景说明选择依据。加分点:提及静态内部类可避免内存泄漏(因不持有外部类引用),非静态内部类在匿名内部类中的应用(如事件监听器)。记忆法:采用 “依赖关系记忆法”—— 静态内部类 “独立”(不依赖外部类实例,只访静态),非静态内部类 “依赖”(依赖外部类实例,全访问),通过 “独立 vs 依赖” 的核心差异记忆其他特性。
String、StringBuilder、StringBuffer 的区别是什么?
String、StringBuilder、StringBuffer 是 Java 中处理字符串的三个核心类,它们的主要区别体现在可变性、线程安全性和性能上,具体如下:
可变性
- String:不可变(Immutable)。其底层是一个被 final 修饰的 char 数组(JDK 9 及以上改为 byte 数组),任何修改 String 的操作(如拼接、替换)都会创建新的 String 对象,原对象不会被改变。例如:
String s = "a"; s += "b"; // 实际创建了新的 String 对象"ab",原对象"a"仍存在 - StringBuilder 和 StringBuffer:可变(Mutable)。它们的底层数组未被 final 修饰,修改操作(如 append、insert)直接在原有数组上进行,不会创建新对象(当数组容量不足时会扩容,但仍为同一对象)。
- String:不可变(Immutable)。其底层是一个被 final 修饰的 char 数组(JDK 9 及以上改为 byte 数组),任何修改 String 的操作(如拼接、替换)都会创建新的 String 对象,原对象不会被改变。例如:
线程安全性
- String:由于不可变,天然线程安全。多个线程同时访问一个 String 对象时,不会因修改导致数据不一致(因为无法修改)。
- StringBuffer:线程安全。其所有方法都被 synchronized 修饰,确保多线程环境下的操作原子性。
- StringBuilder:非线程安全。方法未加同步锁,多线程并发修改可能导致数据错误,但单线程下性能更优。
性能
- 由于 String 的不可变性,频繁修改字符串(如循环拼接)会产生大量临时对象,导致 GC 压力增大,性能最差。
- StringBuffer 因同步锁开销,性能低于 StringBuilder。
- StringBuilder 无同步开销,单线程下修改字符串的性能最佳。
使用场景
- String:适用于字符串内容不频繁修改的场景(如常量定义、少量拼接)。
- StringBuffer:适用于多线程环境下需频繁修改字符串的场景(如日志拼接)。
- StringBuilder:适用于单线程环境下需频繁修改字符串的场景(如动态拼接 SQL 语句)。
面试关键点:需明确可变性的底层原因(数组是否被 final 修饰)、线程安全性的实现方式(是否有 synchronized),以及不同场景下的选择依据。加分点:提及 JDK 9 对 String 底层实现的优化(char 数组改为 byte 数组 + 编码标识,节省空间),或 String.intern () 方法与常量池的关系。记忆法:采用 “特性关联记忆法”——“String 不可变,安全但低效;Buffer 可变且安全,性能中等;Builder 可变不安全,性能最优”,通过 “可变 / 不可变” 和 “安全 / 不安全” 的组合快速区分。
一个包含 default 分支且没有 break 的 switch 语句,给定具体 case 条件,问输出结果是什么?
switch 语句是 Java 中用于多分支判断的结构,其执行逻辑依赖于 case 后的常量匹配和 break 语句的控制。当包含 default 分支且没有 break 时,输出结果由 “case 穿透” 机制决定,具体规则如下:
执行流程
- 首先匹配 case 后的常量值,找到第一个匹配的 case 分支后,从该分支开始执行代码。
- 若分支中没有 break 语句,会继续执行后续所有分支(包括 default),直到遇到 break 或语句结束,即 “case 穿透”。
- default 分支用于匹配所有未被 case 覆盖的情况,其位置不影响执行顺序(可在任意位置),但只有当所有 case 都不匹配时才会执行。
示例分析假设有如下代码:
int num = 2; switch (num) {case 1:System.out.println("Case 1");case 2:System.out.println("Case 2");case 3:System.out.println("Case 3");default:System.out.println("Default"); }执行结果为:
Case 2 Case 3 Default原因:num=2 匹配 case 2,执行其打印语句;因无 break,继续穿透到 case 3 并执行,再穿透到 default 执行,直到语句结束。
若 num=4(无匹配 case):
int num = 4; switch (num) {case 1:System.out.println("Case 1");break;case 2:System.out.println("Case 2");default:System.out.println("Default");case 3:System.out.println("Case 3"); }执行结果为:
Default Case 3原因:num=4 无匹配 case,执行 default;因无 break,继续穿透到 case 3 执行。
关键规则
- 匹配优先:先执行匹配的 case,再按顺序穿透,default 仅在无匹配 case 时触发。
- 穿透无差别:无论后续是 case 还是 default,只要无 break 就持续执行。
- break 作用:终止当前 switch 语句,阻止穿透。
面试关键点:需掌握 case 穿透的触发条件(无 break),明确 default 的执行时机,能根据输入值推导输出结果。加分点:提及 JDK 7+ 中 switch 支持 String 和枚举类型,以及 JDK 14 引入的 switch 表达式(可返回值,避免穿透问题)。记忆法:采用 “流程口诀法”——“匹配 case 就执行,无 break 则继续行,直到 break 或结束,default 无匹配才运行”,通过口诀简化执行逻辑的记忆。
给定一个 try-catch-finally 代码块(需补充具体逻辑,如 try 中 return、finally 中修改值),问最终返回结果是什么?
try-catch-finally 是 Java 中处理异常的核心结构,其中 finally 块通常用于释放资源,且无论 try 或 catch 中是否有 return,finally 块都会执行(除非遇到 System.exit (0) 等终止虚拟机的操作)。当 try 中包含 return、finally 中修改值时,最终返回结果取决于修改的是基本类型还是引用类型,具体规则如下:
基本类型变量若 try 中返回基本类型(如 int、boolean),finally 中修改该变量不会影响返回值。因为 return 会先计算并保存返回值,再执行 finally,finally 中的修改仅作用于局部变量,不改变已保存的返回值。
示例代码:
public static int testBasic() {int num = 10;try {return num; // 保存返回值10} catch (Exception e) {return 0;} finally {num = 20; // 修改局部变量,不影响已保存的返回值} } // 调用testBasic(),返回结果为10引用类型变量若 try 中返回引用类型(如对象),finally 中修改对象的成员变量会影响返回值,因为引用指向的对象地址未变,修改的是对象内部数据;但如果在 finally 中重新赋值引用(指向新对象),则不影响返回值(原对象地址已被保存)。
示例代码:
class Data {int value;Data(int v) { this.value = v; } }public static Data testReference() {Data data = new Data(10);try {return data; // 保存对象引用(指向value=10的Data)} catch (Exception e) {return null;} finally {data.value = 20; // 修改对象成员,影响返回结果// data = new Data(30); // 重新赋值引用,不影响返回结果(仍返回原对象)} } // 调用testReference(),返回的Data对象value为20finally 中包含 return若 finally 中存在 return,会覆盖 try 或 catch 中的 return,成为最终返回值(不推荐此写法,易导致逻辑混乱)。
示例代码:
public static int testFinallyReturn() {try {return 10;} finally {return 20; // 覆盖try的return,最终返回20} }
面试关键点:需明确 finally 的执行时机(在 return 前),区分基本类型和引用类型在修改时对返回值的影响,理解 “返回值保存机制”(基本类型保存值,引用类型保存地址)。加分点:说明 finally 不执行的特殊情况(如虚拟机终止),或分析该机制在资源释放(如关闭流)中的应用。记忆法:采用 “保存不变原则”——“基本类型存值,finally 修改值不变;引用类型存地址,改内容则变,改地址不变”,通过 “保存内容” 的差异记忆结果。
请手写多态的示例代码,并说明多态的实现原理。
多态是面向对象的核心特性之一,指 “同一行为在不同对象上有不同实现”,其实现需满足三个条件:继承(或实现接口)、方法重写、父类引用指向子类对象。
多态示例代码
// 1. 定义父类(抽象类或接口)
abstract class Animal {// 抽象方法(需被子类重写)public abstract void eat();// 普通方法public void sleep() {System.out.println("动物睡觉");}
}// 2. 定义子类,继承父类并重写抽象方法
class Dog extends Animal {@Overridepublic void eat() {System.out.println("狗吃骨头");}// 子类特有方法public void bark() {System.out.println("狗叫");}
}class Cat extends Animal {@Overridepublic void eat() {System.out.println("猫吃鱼");}
}// 3. 测试类,体现多态
public class PolymorphismDemo {public static void main(String[] args) {// 父类引用指向子类对象(多态的核心体现)Animal animal1 = new Dog();Animal animal2 = new Cat();// 调用重写的方法,实际执行子类的实现animal1.eat(); // 输出:狗吃骨头animal2.eat(); // 输出:猫吃鱼// 调用父类的普通方法(未被重写)animal1.sleep(); // 输出:动物睡觉// 父类引用不能直接调用子类特有方法(需强制类型转换)if (animal1 instanceof Dog) {Dog dog = (Dog) animal1;dog.bark(); // 输出:狗叫}}
}
多态的实现原理
多态的实现依赖于 Java 的 “动态绑定”(又称运行时绑定)机制,具体过程如下:
编译时检查编译阶段,编译器仅根据父类(或接口)的类型检查方法是否存在,不关心实际对象类型。例如
animal1.eat()会检查 Animal 类是否有 eat () 方法,若没有则编译报错。运行时绑定运行阶段,JVM 会根据对象的实际类型(而非引用类型)调用对应的方法。其底层通过 “方法表” 实现:
- 每个类加载时,JVM 会为其生成一个方法表,记录该类的所有方法及对应的实现地址。
- 子类的方法表会继承父类的方法表,若子类重写了父类方法,会用子类的方法地址覆盖父类的对应条目。
- 调用方法时,JVM 先获取对象的实际类型,查找其方法表,找到对应方法地址并执行。
例如,
animal1实际是 Dog 对象,JVM 查找 Dog 的方法表,发现 eat () 对应的是 Dog 类的实现,因此执行 “狗吃骨头”。类型转换与 instanceof父类引用不能直接调用子类特有方法,需通过强制类型转换(向下转型)实现,转型前通常用 instanceof 检查类型,避免 ClassCastException。
面试关键点:需掌握多态的三个实现条件,理解动态绑定的过程(编译看父类,运行看子类),能正确编写多态代码并解释执行结果。加分点:提及静态方法、final 方法、private 方法不支持多态(它们是静态绑定,编译时确定调用版本),或结合设计模式(如工厂模式)说明多态的实际应用。记忆法:采用 “口诀记忆法”——“父类引用子类对象,编译看左(父类),运行看右(子类),方法表来定实现”,通过口诀简化动态绑定机制的记忆。
Java 中软引用、弱引用、虚引用的概念及区别是什么?强引用的特点是什么?
Java 中的引用类型分为强引用、软引用、弱引用、虚引用四种,它们的主要区别在于对象被垃圾回收(GC)时的回收时机和用途,具体如下:
1. 强引用(Strong Reference)
强引用是最常见的引用类型,即通过 Object obj = new Object() 定义的引用。其特点为:
- 回收特性:只要强引用存在,即使内存不足(OOM),GC 也不会回收被引用的对象。
- 使用场景:日常开发中默认使用的引用类型,用于表示对象的正常关联关系(如对象的成员变量、局部变量)。
- 示例:
Object strongRef = new Object(); // 强引用 strongRef = null; // 断开强引用,对象可能被GC回收(需满足其他回收条件)
2. 软引用(Soft Reference)
软引用通过 SoftReference 类实现,用于描述 “有用但非必需” 的对象。其特点为:
- 回收特性:当内存充足时,GC 不回收软引用关联的对象;当内存不足时,GC 会回收该对象。
- 使用场景:适用于缓存场景(如图片缓存、数据缓存),在内存紧张时释放缓存,避免 OOM。
- 示例:
Object obj = new Object(); SoftReference<Object> softRef = new SoftReference<>(obj); obj = null; // 断开强引用,保留软引用 // 内存不足时,obj可能被GC回收,此时softRef.get()返回null
3. 弱引用(Weak Reference)
弱引用通过 WeakReference 类实现,用于描述 “非必需” 的对象。其特点为:
- 回收特性:无论内存是否充足,只要发生 GC,弱引用关联的对象都会被回收(回收优先级高于软引用)。
- 使用场景:适用于临时关联关系(如缓存中生命周期较短的对象),或避免内存泄漏(如 WeakHashMap 中键为弱引用,键被回收后条目自动移除)。
- 示例:
Object obj = new Object(); WeakReference<Object> weakRef = new WeakReference<>(obj); obj = null; // 断开强引用 System.gc(); // 触发GC,obj会被回收,weakRef.get()返回null
4. 虚引用(Phantom Reference)
虚引用通过 PhantomReference 类实现,是最弱的引用类型,又称 “幽灵引用”。其特点为:
- 回收特性:无法通过虚引用获取对象(
get()始终返回 null),对象被回收时,虚引用会被加入关联的引用队列,用于跟踪对象回收时机。 - 使用场景:仅用于在对象被回收时收到通知,通常用于资源清理(如释放直接内存)。
- 示例:
ReferenceQueue<Object> queue = new ReferenceQueue<>(); Object obj = new Object(); PhantomReference<Object> phantomRef = new PhantomReference<>(obj, queue); obj = null; // GC回收obj后,phantomRef会被加入queue,可通过queue.poll()获取
四类引用的核心区别
| 引用类型 | 回收时机 | 是否可通过引用获取对象 | 主要用途 |
|---|---|---|---|
| 强引用 | 永不回收(除非断开引用) | 是 | 正常对象关联 |
| 软引用 | 内存不足时回收 | 是(回收前) | 缓存(内存敏感型) |
| 弱引用 | GC 时立即回收 | 是(回收前) | 临时关联、避免内存泄漏 |
| 虚引用 | GC 时回收 | 否 | 跟踪对象回收、资源清理 |
面试关键点:需明确四类引用的回收时机和用途,尤其是软引用与弱引用的区别,以及虚引用的特殊作用(无法获取对象,仅用于跟踪回收)。加分点:结合 JVM 垃圾回收机制(如可达性分析)说明引用类型如何影响对象的存活判定,或举例 WeakHashMap 的实现原理。记忆法:采用 “强度 - 回收时机” 关联法 ——“强引用不回收,软引用缺内存回收,弱引用 GC 就回收,虚引用只跟踪回收”,通过强度递减顺序记忆回收特性。
HashMap 的数据结构是怎样的?如何解决哈希冲突?
HashMap 的数据结构在 JDK 1.7 和 JDK 1.8 中有显著差异,核心是通过 “数组 + 链表 / 红黑树” 的组合实现高效存储,其设计目标是平衡查询速度与空间利用率。
一、HashMap 的数据结构(分 JDK 版本)
JDK 1.7 数据结构:数组 + 链表
- 数组(哈希桶):作为底层基础存储结构,数组元素是
Entry节点(存储 key、value、hash 值、下一个节点引用),数组长度默认是 16(2 的幂次),称为 “初始容量”。数组的索引通过 key 的哈希值计算得出,每个索引位置对应一个 “哈希桶”,用于存放可能冲突的节点。 - 链表:当多个 key 计算出相同的数组索引时(即哈希冲突),这些节点会以链表形式存储在同一个哈希桶中,链表的每个节点通过 “next” 引用连接,形成链式结构。此时查询需遍历链表,效率随链表长度增加而下降。
- 数组(哈希桶):作为底层基础存储结构,数组元素是
JDK 1.8 数据结构:数组 + 链表 + 红黑树
- 保留了 “数组 + 链表” 的基础结构,但新增了红黑树优化:当链表长度超过 8,且数组长度大于等于 64 时,链表会自动转换为红黑树(一种自平衡二叉查找树);若后续链表长度减少到 6 以下,红黑树会转回链表。
- 红黑树的引入将查询时间复杂度从链表的 O (n) 降至 O (logn),解决了 JDK 1.7 中链表过长导致的性能问题。
- 节点结构变化:JDK 1.8 用
Node类替代Entry,红黑树节点则用TreeNode类(继承Node),新增了红黑树相关的属性(如 parent、left、right、color 等)。
二、哈希冲突的解决方法
HashMap 核心采用 链地址法(拉链法) 解决哈希冲突,即冲突的节点通过链表 / 红黑树串联在同一哈希桶中。此外,还通过以下设计减少冲突概率:
优化哈希函数:
- 计算 key 的哈希值时,先调用
key.hashCode()获取原始哈希值(int 类型,32 位),再通过 “扰动函数” 优化:JDK 1.8 中使用(h = key.hashCode()) ^ (h >>> 16),将哈希值的高 16 位与低 16 位异或,目的是让高 16 位的特征参与索引计算,减少因哈希值低位重复导致的冲突(尤其当数组长度较小时,仅用低位计算索引)。
- 计算 key 的哈希值时,先调用
合理的数组容量与扩容机制:
- 数组容量默认是 2 的幂次(如 16、32),计算索引时用
(n - 1) & hash(n 为数组容量)。当 n 是 2 的幂次时,n-1 的二进制是 “全 1”(如 n=16 时,n-1=15,二进制 1111),此时(n-1)&hash能充分利用 hash 值的每一位,避免因二进制位存在 0 导致的索引重复,进一步减少冲突。
- 数组容量默认是 2 的幂次(如 16、32),计算索引时用
红黑树替代长链表:
- JDK 1.8 中,当链表长度超过 8 且数组长度≥64 时,链表转为红黑树,既解决了链表查询效率低的问题,也避免了冲突节点过度聚集。
关键补充与代码示例
- 节点存储示例(简化):
// JDK 1.8 Node 节点结构 static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next; // 链表节点引用// 构造函数、getter/setter 等 } // 红黑树节点(继承 Node) static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父节点TreeNode<K,V> left; // 左子节点TreeNode<K,V> right; // 右子节点boolean red; // 节点颜色// 红黑树相关方法 }
面试关键点:需明确 JDK 1.7 与 1.8 的数据结构差异、红黑树的树化条件、链地址法的原理;加分点:提及扰动函数的作用、数组容量为 2 的幂次对索引计算的影响;记忆法:采用 “版本 - 结构 - 优化” 关联法 ——“1.7 数组 + 链表,1.8 加红黑树;冲突用拉链,树化阈值 8,容量够 64”,通过版本对应结构,核心逻辑串联记忆。
HashMap 的初始容量是多少?负载因子是多少?为什么初始容量和扩容时要选择 2 的幂次?
HashMap 的初始容量、负载因子是影响其性能的核心参数,而 “选择 2 的幂次” 是基于哈希索引计算的效率与散列均匀性设计的,具体细节如下:
一、初始容量与负载因子的默认值
初始容量:指 HashMap 刚创建时,底层数组(哈希桶)的默认长度。JDK 1.7 和 JDK 1.8 中,默认初始容量均为 16(源码中定义为
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;,即 2^4)。- 若通过构造函数手动指定初始容量(如
new HashMap<>(20)),HashMap 不会直接使用该值,而是通过tableSizeFor(int cap)方法调整为 “大于等于指定值的最近的 2 的幂次”(例如指定 20 时,调整为 32)。
- 若通过构造函数手动指定初始容量(如
负载因子:指 HashMap 触发扩容的 “阈值比例”,即 扩容阈值 = 数组容量 × 负载因子。JDK 中默认负载因子为 0.75(源码定义
static final float DEFAULT_LOAD_FACTOR = 0.75f;)。- 负载因子的作用是平衡 “空间利用率” 与 “查询效率”:
- 若负载因子过小(如 0.5),扩容阈值低,数组会频繁扩容,导致空间浪费(大量哈希桶为空);
- 若负载因子过大(如 1.0),扩容阈值高,哈希桶中链表 / 红黑树过长,查询效率下降(冲突概率增加);
- 0.75 是 Oracle 团队通过统计得出的最优值,能在空间与时间成本间取得平衡。
- 负载因子的作用是平衡 “空间利用率” 与 “查询效率”:
二、为什么初始容量和扩容时要选择 2 的幂次?
HashMap 中,key 的索引计算依赖公式 index = (n - 1) & hash(n 为数组容量,hash 为 key 的优化后哈希值)。选择 2 的幂次,核心是让该公式的计算更高效、散列更均匀,具体原因如下:
保证 (n-1) 的二进制为 “全 1”,提升散列均匀性当 n 是 2 的幂次时(如 n=16=2^4),n-1 的二进制是 “全 1”(16-1=15,二进制
1111)。此时(n-1) & hash本质是 “截取 hash 值的低 k 位”(k 为 2 的幂次的指数,如 n=16 时 k=4),能充分利用 hash 值的每一位特征,避免因二进制位存在 0 导致的索引重复。- 反例:若 n 不是 2 的幂次(如 n=15),n-1=14,二进制
1110,此时(n-1)&hash的结果中,最低位永远是 0,导致所有索引都为偶数,哈希桶分布极度不均匀,冲突概率骤增。
- 反例:若 n 不是 2 的幂次(如 n=15),n-1=14,二进制
索引计算更高效(位运算 vs 取模)若不使用 2 的幂次,索引计算需用
hash % n(取模运算),但位运算(n-1)&hash的执行效率远高于取模运算(CPU 处理位运算更快)。而当 n 是 2 的幂次时,(n-1)&hash与hash % n的结果完全一致,既保证了正确性,又提升了性能。扩容时节点迁移更高效(避免重新计算 hash)HashMap 扩容时,新容量是原容量的 2 倍(仍为 2 的幂次)。此时,原数组中某个节点的新索引只有两种可能:
- 与原索引相同(hash 值的第 k 位为 0,k 为原容量的指数);
- 原索引 + 原容量(hash 值的第 k 位为 1)。这种迁移逻辑无需重新计算每个节点的 hash 值,仅需判断 hash 值的某一位即可,大幅提升扩容效率(JDK 1.8 已优化迁移逻辑,避免 JDK 1.7 的死循环问题)。
关键补充与代码示例
tableSizeFor方法(调整容量为 2 的幂次):static final int tableSizeFor(int cap) {int n = cap - 1; // 避免 cap 本身是 2 的幂次时,结果翻倍n |= n >>> 1; // 右移1位,或运算,填充高位1n |= n >>> 2; // 右移2位,继续填充n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
面试关键点:默认初始容量 16、负载因子 0.75 的含义,(n-1)&hash 的作用,tableSizeFor 方法的功能;加分点:解释负载因子 0.75 的设计逻辑,或扩容时节点迁移的高效性;记忆法:采用 “参数 - 作用 - 逻辑” 口诀 ——“初始 16 载 0.75,2 次幂因 n-1 全 1;位运算快散列匀,扩容迁移不用重算 hash”,通过口诀串联核心逻辑。
HashMap 的 put 操作流程是什么?查询操作的时间复杂度是多少?最差情况下为什么是 O (n)?
HashMap 的 put 操作是其核心功能,流程需兼顾哈希计算、冲突处理、扩容与树化;查询操作的时间复杂度则与数据结构(链表 / 红黑树)直接相关,最差情况的 O (n) 需结合 JDK 版本差异分析。
一、HashMap 的 put 操作流程(以 JDK 1.8 为例)
put 操作的核心是 “计算索引→处理冲突→插入节点→判断扩容”,具体步骤如下:
判断底层数组是否为空,为空则初始化若 HashMap 刚创建,底层数组(
table)为 null,需调用resize()方法初始化数组,设置初始容量(默认 16)和扩容阈值(16×0.75=12)。计算 key 的哈希值与数组索引
- 调用
key.hashCode()获取原始哈希值,再通过扰动函数(h = key.hashCode()) ^ (h >>> 16)优化哈希值,减少冲突; - 用
(n - 1) & hash计算索引i(n 为数组容量),确定节点应存入的哈希桶位置。
- 调用
判断索引 i 处是否有节点,分情况处理
- 情况 1:i 处为空:直接创建
Node节点(存储 key、value、hash、next),存入table[i],无需处理冲突。 - 情况 2:i 处有节点(存在冲突):a. 取出
table[i]处的头节点first,判断first的 key 与当前 key 是否 “相等”(需同时满足first.hash == hash且(first.key == key || key.equals(first.key))):若相等,说明是重复 key,用当前 value 覆盖first.value,并返回旧 value。b. 若 key 不相等,判断first是红黑树节点(TreeNode)还是链表节点:- 若是红黑树节点:调用
putTreeVal()方法,按红黑树规则插入新节点(保证树的平衡)。 - 若是链表节点:遍历链表,直到找到 key 相等的节点(覆盖 value)或遍历到链表末尾(插入新节点到链表尾部,JDK 1.8 为尾插,1.7 为头插)。c. 插入链表节点后,判断链表长度是否超过 8:若超过,调用
treeifyBin()方法尝试将链表转为红黑树;但需先判断数组长度是否≥64,若数组长度不足 64,会先触发resize()扩容,而非直接树化(避免数组过小导致红黑树浪费空间)。
- 若是红黑树节点:调用
- 情况 1:i 处为空:直接创建
判断是否需要扩容插入节点后,将 HashMap 的元素个数
size加 1,若size超过扩容阈值(数组容量 × 负载因子),调用resize()方法扩容(新容量为原容量的 2 倍,新阈值为新容量 ×0.75)。返回结果若插入的是新 key,返回 null;若覆盖了旧 key,返回旧 value。
二、查询操作的时间复杂度与最差情况 O (n) 的原因
查询操作流程查询的核心是 “定位哈希桶→遍历节点找匹配 key”:
- 计算 key 的哈希值与索引
i; - 若
table[i]为空,返回 null; - 若
table[i]有节点,先判断头节点 key 是否匹配,匹配则返回 value; - 不匹配则遍历链表或红黑树,找到 key 匹配的节点返回 value,无匹配则返回 null。
- 计算 key 的哈希值与索引
时间复杂度
- 理想情况:哈希散列均匀,每个哈希桶中只有 1 个节点(无冲突),查询仅需通过数组索引定位,时间复杂度为 O(1)。
- 一般情况:部分哈希桶存在链表或红黑树,链表查询时间复杂度为 O (k)(k 为链表长度),红黑树查询为 O (logk),整体接近 O (1)。
- 最差情况:所有节点都聚集在同一个哈希桶中,此时数据结构退化为链表(未树化),查询需遍历整个链表,时间复杂度为 O(n)。
最差情况 O (n) 的原因
- JDK 1.7:无红黑树优化,若哈希函数设计不合理(如所有 key 的 hash 值相同),会导致所有节点存入同一个哈希桶,形成超长链表,查询需遍历链表,时间复杂度 O (n)。
- JDK 1.8:虽有红黑树优化,但树化需满足 “链表长度≥8 且数组长度≥64”。若数组长度不足 64(如初始容量 16),即使链表长度超过 8,也会先扩容而非树化;若扩容后仍因哈希冲突导致链表过长(如哈希函数失效),或数组长度始终不足 64,链表无法树化,查询仍会退化为 O (n)。
关键补充与代码示例
put核心流程简化代码:public V put(K key, V value) {return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 步骤1:初始化数组if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 步骤2:索引i处为空,直接插入if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// 步骤3:key重复,覆盖valueif (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))e = p;// 步骤3:红黑树插入else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 步骤3:链表插入else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 链表长度≥8,尝试树化if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}// 找到重复key,跳出循环覆盖if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // 覆盖旧valueV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;// 步骤4:判断扩容if (++size > threshold)resize();afterNodeInsertion(evict);return null; }
面试关键点:JDK 1.8 put 的完整流程(初始化、索引计算、冲突处理、树化、扩容),查询时间复杂度的变化,最差 O (n) 的场景;加分点:对比 JDK 1.7 与 1.8 put 的差异(头插 vs 尾插、有无红黑树);记忆法:采用 “流程步骤口诀”——“判空初始化,算 hash 找索引;空桶直接插,冲突分情况;key 重复覆盖,树 / 链分别插;链长超 8 树化,size 超阈扩容”,查询复杂度 “理想 O (1),最差链表 O (n)”。
HashMap 为什么线程不安全?在多线程环境下可能出现哪些问题(如死循环、数据覆盖)?
HashMap 设计之初未考虑线程安全,底层数据结构(数组、链表、红黑树)的操作无同步机制,导致多线程并发访问时会出现数据一致性问题。其线程不安全的根源与具体问题需结合 JDK 版本差异分析。
一、HashMap 线程不安全的核心原因
HashMap 线程不安全的本质是 “并发操作缺乏同步控制”,具体体现在以下两点:
- 无锁设计:HashMap 的所有方法(
put、get、resize等)均未加synchronized锁或使用 CAS 原子操作,多线程可同时修改底层数据结构(如数组、链表节点)。 - 数据结构的可变性:HashMap 的底层数组会扩容,链表会插入 / 删除节点,红黑树会旋转平衡,这些操作均为 “非原子操作”(需多步完成)。若多线程同时执行这些操作,会导致中间状态被破坏,引发数据异常。
二、多线程环境下的典型问题
不同 JDK 版本中,HashMap 并发问题的表现不同,JDK 1.7 问题更严重(死循环),JDK 1.8 优化了部分问题,但仍存在数据覆盖等风险。
问题 1:JDK 1.7 的死循环(扩容时链表反转导致)JDK 1.7 中,
resize()扩容时通过transfer()方法迁移节点,采用 “头插法”(新节点插入链表头部),多线程并发扩容时会导致链表形成循环,进而引发死循环(查询时无限遍历)。- 具体过程:a. 线程 A 和线程 B 同时执行
resize(),均读取原数组中某链表(如key1→key2→null);b. 线程 A 先迁移节点,用头插法将链表反转(key2→key1→null),但未完成数组赋值;c. 线程 B 继续迁移同一链表,读取到线程 A 反转后的中间状态(如key1的 next 指向key2,key2的 next 仍指向key1),最终形成key1↔key2的循环链表;d. 后续查询该链表时,会无限遍历循环节点,导致 CPU 占用率飙升至 100%。 - JDK 1.8 已解决此问题:扩容时改用 “尾插法”,迁移节点时保持链表原有顺序,避免反转,从根源上杜绝死循环。
- 具体过程:a. 线程 A 和线程 B 同时执行
问题 2:数据覆盖(多线程并发 put 导致)这是 JDK 1.7 和 1.8 共有的问题,当多线程同时向同一哈希桶插入节点时,会因 “判断空桶” 与 “插入节点” 的非原子性导致数据覆盖。
- 具体过程:a. 线程 A 和线程 B 同时计算出相同的索引
i,且table[i]为空;b. 线程 A 先判断table[i] == null,准备插入节点,但未执行赋值操作;c. 线程 B 也判断table[i] == null(此时线程 A 尚未插入),执行插入操作,将节点存入table[i];d. 线程 A 继续执行,覆盖线程 B 插入的节点,导致线程 B 的数据丢失。 - 即使 JDK 1.8 有红黑树优化,仍无法避免此问题:红黑树的插入是多步操作(如旋转、变色),多线程并发插入时仍可能覆盖节点。
- 具体过程:a. 线程 A 和线程 B 同时计算出相同的索引
问题 3:数据不一致(size 计数错误、节点丢失)
- size 计数错误:HashMap 的
size变量用于记录元素个数,多线程并发put时,size++是 “读取 - 修改 - 写入” 的非原子操作,会导致计数不准(如线程 A 和 B 同时读取 size=10,均执行 size++,最终 size=11 而非 12)。 - 节点丢失:JDK 1.7 头插法迁移节点时,多线程可能覆盖
next引用,导致部分节点丢失(如线程 A 修改节点的 next 指向,线程 B 读取到旧的 next 引用,遗漏节点)。
- size 计数错误:HashMap 的
关键补充与代码示例
- JDK 1.7
transfer()方法(头插法导致死循环的核心):void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) { // 遍历原数组while (null != e) {Entry<K,V> next = e.next; // 线程A可能在此处暂停,线程B修改nextif (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i]; // 头插法:新节点的next指向原桶的头节点newTable[i] = e; // 将新节点设为桶的头节点e = next;}} }
面试关键点:JDK 1.7 死循环的原因(头插法 + 并发扩容)、数据覆盖的本质(非原子操作)、JDK 1.8 的优化与残留问题;加分点:提及线程安全的替代方案(如 ConcurrentHashMap,JDK 1.7 用分段锁,1.8 用 CAS+synchronized 实现高效并发);记忆法:采用 “版本 - 问题 - 原因” 关联法 ——“1.7 死循环(头插扩容),1.8 无死循但仍覆盖;核心无同步,非原子操作引问题”,通过版本差异记忆问题场景。
HashMap 可以存储 null 键和 null 值吗?
HashMap 可以存储 null 键和 null 值,这是其与其他 Map 实现(如 Hashtable、ConcurrentHashMap)的显著区别之一。HashMap 对 null 键和 null 值有专门的处理逻辑,确保存储与查询的正确性,具体细节如下:
一、HashMap 存储 null 键的逻辑
HashMap 允许存在一个 null 键(因为 Map 接口要求 key 唯一),其处理逻辑围绕 “哈希值计算” 与 “索引定位” 展开:
null 键的哈希值固定为 0HashMap 计算 key 的哈希值时,会先判断 key 是否为 null:若为 null,直接返回哈希值 0(源码中
hash()方法逻辑:static final int hash(Object key) { return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); })。null 键的索引固定为 0索引计算依赖公式
(n - 1) & hash,由于 null 键的 hash=0,无论数组容量 n 是多少(只要是 2 的幂次),(n-1) & 0的结果始终为 0。因此,null 键永远存储在底层数组的 0 号哈希桶中。null 键的唯一性保证若多次调用
put(null, value),后续的 null 键会覆盖前一次的 value(符合 Map 中 key 唯一的规则)。例如:HashMap<String, String> map = new HashMap<>(); map.put(null, "first"); map.put(null, "second"); // 覆盖前一个null键的value System.out.println(map.get(null)); // 输出:second
二、HashMap 存储 null 值的逻辑
HashMap 允许存储多个 null 值(只要对应的 key 不重复),对 null 值无特殊限制,仅需遵循 “key 唯一” 的规则:
null 值无需特殊哈希计算存储 null 值时,key 仍需正常计算哈希值(若 key 非 null),null 值仅作为节点的
value属性存储,不影响索引定位。例如:map.put("a", null); // key="a",hash计算后存入对应索引 map.put("b", null); // key="b",存入另一索引,允许value为null System.out.println(map.get("a")); // 输出:null System.out.println(map.get("b")); // 输出:nullnull 值的查询与删除查询 null 值时,通过 key 正常定位索引,若节点的 value 为 null,直接返回 null;删除时也通过 key 定位,与非 null 值的删除逻辑一致。需注意:
map.get(key) == null有两种可能 ——key 不存在,或 key 存在但 value 为 null,可通过map.containsKey(key)区分。
三、与其他 Map 实现的对比(为何 Hashtable 不能存 null 键值)
需特别注意,HashMap 的 “允许 null 键值” 并非所有 Map 都支持,最典型的对比是 Hashtable:
| Map 实现 | 是否允许 null 键 | 是否允许 null 值 | 原因分析 |
|---|---|---|---|
| HashMap | 是(仅一个) | 是(多个) | 专门处理 null 键的哈希值(0),无 null 校验逻辑 |
| Hashtable | 否 | 否 | put 方法中会主动校验 key 和 value,若为 null 则抛 NullPointerException |
| ConcurrentHashMap(JDK1.8+) | 否 | 否 | 为保证并发安全性,避免 null 键值导致的逻辑歧义(如无法区分 “key 不存在” 与 “value 为 null”) |
- Hashtable 源码中
put方法的 null 校验:public synchronized V put(K key, V value) {// 若value为null,抛异常if (value == null) {throw new NullPointerException();}// 若key为null,调用key.hashCode()时抛NullPointerExceptionEntry<?,?> tab[] = table;int hash = key.hashCode();// ...后续逻辑 }
关键补充与注意事项
- null 键的存储限制:HashMap 仅允许一个 null 键,因为 Map 接口要求 key 唯一,多次 put null 键会覆盖 value;
- 线程安全场景的风险:若在多线程环境下存储 null 键值,仍可能出现数据覆盖(如前一题所述),需使用
ConcurrentHashMap(但它不支持 null 键值); - 查询时的歧义处理:当
map.get(key) == null时,需调用map.containsKey(key)判断 key 是否存在,避免误判(例如 key 存在但 value 为 null,与 key 不存在的结果相同)。
面试关键点:HashMap 允许 null 键(一个,存 0 号桶)和 null 值(多个),与 Hashtable/ConcurrentHashMap 的区别,get(null) == null 的歧义处理;加分点:解释 null 键的哈希值与索引计算逻辑,或 Hashtable 禁止 null 的源码依据;记忆法:采用 “对比记忆法”——“HashMap:null 键一个(0 号桶),null 值随便存;Hashtable:键值都不准存 null;ConcurrentHashMap:同 Hashtable”,通过对比快速区分不同 Map 的规则。
HashMap 中链表为什么要转为红黑树?为什么链表查询慢?转为红黑树的条件是什么?
HashMap 中链表转为红黑树是 JDK 1.8 的重要优化,核心目的是解决链表过长导致的查询性能下降问题。这一设计需结合链表与红黑树的特性、查询效率差异及实际场景中的冲突概率综合分析。
一、链表为什么要转为红黑树?
链表是一种线性数据结构,其查询性能随长度增加而显著下降。当 HashMap 中某个哈希桶的链表过长时(如超过 8 个节点),查询操作需要遍历链表,时间复杂度为 O(n);而红黑树是一种自平衡二叉查找树,查询、插入、删除的时间复杂度均为 O(logn),能大幅提升操作效率。具体来说,当哈希函数不够理想或数据分布不均时,部分哈希桶会聚集大量节点,形成超长链表。例如,若一个哈希桶有 100 个节点,链表查询需平均遍历 50 次,而红黑树仅需约 7 次(log2(100)≈7),性能提升明显。因此,JDK 1.8 引入红黑树,将链表的线性查询优化为树的对数级查询,平衡了 HashMap 在极端情况下的性能。
二、链表查询慢的原因
链表查询慢的本质是其“线性存储”与“顺序访问”特性:
- 内存不连续:链表的节点在内存中随机分布,无法像数组那样通过索引直接定位,每次访问下一个节点需通过“next”引用跳转,增加了内存访问开销。
- 顺序遍历:查询时需从链表头节点开始,逐个比较节点的 key 与目标 key,直到找到匹配节点或遍历结束。若目标节点在链表尾部,需遍历所有前置节点,时间成本随链表长度线性增长。
- 无索引支持:链表没有索引机制,无法通过二分法等优化查询,必须依赖顺序扫描,这是其查询性能低于树结构的核心原因。
三、转为红黑树的条件
JDK 1.8 中,链表转为红黑树(树化)需同时满足两个条件,缺一不可:
- 链表长度 ≥ 8:当哈希桶中链表的节点数量超过 8 时,触发树化检查。这一阈值基于泊松分布设计——根据统计,链表长度为 8 的概率约为 0.00000006(几乎不可能),说明此时哈希冲突已非常严重,需通过红黑树优化。
- 数组长度 ≥ 64:若数组长度不足 64,即使链表长度 ≥ 8,也不会直接树化,而是先触发扩容(数组长度翻倍)。这是因为数组长度较小时(如 16),哈希桶数量少,冲突概率高,扩容能通过增加哈希桶数量分散节点,比树化更节省空间(红黑树节点占用内存比链表节点多)。
当树化后,若后续节点被删除,导致链表长度减少到 6 以下(收缩阈值),红黑树会自动转回链表(反树化),以平衡空间与性能。
关键补充与代码示例
- 树化相关常量(源码定义):
static final int TREEIFY_THRESHOLD = 8; // 树化阈值 static final int UNTREEIFY_THRESHOLD = 6; // 反树化阈值 static final int MIN_TREEIFY_CAPACITY = 64; // 最小树化容量 - 树化核心逻辑(
treeifyBin方法简化):final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// 若数组长度 < 64,先扩容而非树化if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (n - 1) & hash]) != null) {// 链表转为红黑树TreeNode<K,V> hd = null, tl = null;do {TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)hd.treeify(tab); // 调整为红黑树结构} }
面试关键点:树化的核心目的(优化查询性能)、链表查询慢的本质(线性遍历)、树化的两个条件及设计原因;加分点:解释阈值 8 与 6 的设计逻辑(避免频繁树化与反树化的抖动)、泊松分布在阈值设定中的作用;记忆法:采用“条件-目的”口诀——“链长超8且数组≥64,转红黑树提效率;链表慢因顺序找,树查快在log级”,通过条件与性能差异串联记忆。
HashMap 链表插入方式为什么是尾插(JDK 1.8 及以后)?之前头插的问题是什么?
HashMap 中链表的插入方式在 JDK 1.7 和 JDK 1.8 有显著差异:JDK 1.7 采用“头插法”,JDK 1.8 改为“尾插法”。这一变化的核心是解决头插法在多线程环境下的致命问题(死循环、节点丢失),同时优化链表的稳定性。
一、JDK 1.8 采用尾插法的原因
尾插法是指新节点插入到链表的尾部(最后一个节点之后),其核心优势是避免多线程扩容时的链表循环,同时保证链表顺序与插入顺序一致。
避免死循环:JDK 1.7 的头插法在扩容时会导致链表反转(新节点插入头部),多线程并发扩容时易形成循环链表(详见第14题)。而尾插法在扩容迁移节点时,会按原链表的顺序将节点插入新链表的尾部,保持链表顺序不变,从根源上杜绝了因反转导致的循环问题。
保证链表顺序稳定:尾插法使节点的插入顺序与链表中的存储顺序一致(先插入的节点在链表前,后插入的在链表后),而头插法会导致后插入的节点在链表前(顺序反转)。顺序稳定有助于在调试或遍历链表时更直观地理解数据插入过程。
配合红黑树优化:JDK 1.8 引入红黑树后,链表转红黑树时需要遍历链表节点。尾插法保证的链表顺序与插入顺序一致,便于在树化过程中保持节点间的逻辑关系,减少树化时的调整成本。
二、JDK 1.7 头插法的问题
头插法是指新节点插入到链表的头部(取代原头节点成为新头),在单线程下可正常工作,但在多线程并发场景(尤其是扩容时)会引发严重问题:
死循环(最致命问题):JDK 1.7 扩容时通过
transfer方法迁移节点,采用头插法导致链表反转。多线程并发扩容时,线程 A 可能在迁移过程中暂停,线程 B 完成迁移并修改节点的next引用,当线程 A 恢复后,会读取到被线程 B 修改的中间状态,最终形成循环链表。后续查询该链表时,会陷入无限循环,导致 CPU 占用率飙升至 100%。- 简化示例:原链表
A→B→null,线程 A 迁移时先处理 A,A 的 next 指向 null;线程 B 同时迁移,处理 B 时将 B 的 next 指向 A(头插),再处理 A 时将 A 的 next 指向 B,形成A↔B循环。
- 简化示例:原链表
节点丢失:头插法在多线程插入节点时,可能覆盖已有节点的
next引用,导致部分节点丢失。例如,线程 A 准备将节点 C 插入链表头部(C.next = A),但未完成赋值;线程 B 将节点 D 插入头部(D.next = A,链表变为 D→A);线程 A 继续执行,将 C 设为头节点(C.next = A),导致 D 节点被丢失(链表变为 C→A)。扩容后节点顺序混乱:头插法在扩容时反转链表顺序,导致节点的存储顺序与插入顺序完全相反,增加了调试和理解的难度,尤其在需要按插入顺序处理数据的场景中不友好。
三、尾插法的实现逻辑
JDK 1.8 中,尾插法通过遍历链表找到尾部节点,再将新节点插入尾部,核心代码如下:
// 链表插入逻辑(JDK 1.8 putVal 方法片段)
else { // 链表节点处理for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) { // 遍历到链表尾部p.next = newNode(hash, key, value, null); // 尾插新节点// 检查是否需要树化if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}// 找到重复key,跳出循环覆盖valueif (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))break;p = e; // 移动到下一个节点}
}
扩容时,尾插法同样保持原链表顺序,迁移节点时按原顺序插入新链表尾部,避免反转:
// 扩容迁移节点(JDK 1.8 resize 方法片段)
Node<K,V> loHead = null, loTail = null; // 原索引节点
Node<K,V> hiHead = null, hiTail = null; // 新索引节点
Node<K,V> next;
do {next = e.next;if ((e.hash & oldCap) == 0) { // 原索引if (loTail == null)loHead = e;elseloTail.next = e; // 尾插loTail = e;} else { // 新索引if (hiTail == null)hiHead = e;elsehiTail.next = e; // 尾插hiTail = e;}
} while ((e = next) != null);
面试关键点:尾插法解决的核心问题(死循环、节点丢失)、头插法在多线程下的风险、尾插法的实现逻辑;加分点:对比 JDK 1.7 与 1.8 扩容迁移的差异,解释尾插法对红黑树优化的辅助作用;记忆法:采用“问题-方案”关联法——“1.7头插易死循环(扩容反转),1.8尾插保顺序(避免循环);头插多线程丢节点,尾插遍历到尾才插入”,通过问题与解决方案的对应记忆。
ConcurrentHashMap 的底层实现原理是什么?它是如何保证线程安全的(JDK 1.7 分段锁、JDK 1.8 CAS+ synchronized)?
ConcurrentHashMap 是 Java 并发包中线程安全的哈希表实现,专为高并发场景设计。其底层实现和线程安全机制在 JDK 1.7 和 JDK 1.8 有显著优化,核心目标是在保证线程安全的同时提升并发效率。
一、JDK 1.7 底层实现与线程安全机制(分段锁)
底层数据结构:JDK 1.7 的 ConcurrentHashMap 采用“Segment 数组 + HashEntry 数组 + 链表”的三层结构:
- Segment 数组:Segment 是一个继承自 ReentrantLock 的内部类,相当于“分段锁”,每个 Segment 独立加锁,互不干扰。默认有 16 个 Segment(可通过构造函数修改,必须是 2 的幂次)。
- HashEntry 数组:每个 Segment 内部包含一个 HashEntry 数组(哈希桶),用于存储键值对,数组元素是链表节点(HashEntry),节点的 key 和 value 被
volatile修饰,保证可见性。 - 链表:当哈希冲突时,节点以链表形式存储在同一 HashEntry 数组索引下。
线程安全机制(分段锁):核心是“锁分段技术”,即把整个哈希表分为多个 Segment,每个 Segment 独立加锁:
- 执行
put、remove等写操作时,仅锁定当前 key 所在的 Segment,其他 Segment 仍可被其他线程访问,降低锁竞争。 - 执行
get等读操作时,无需加锁,通过volatile修饰的 HashEntry 节点保证数据可见性(读操作无锁,效率高)。 - 锁的粒度是 Segment,而非整个哈希表,理论上支持 16 个线程同时写入不同的 Segment(并发度为 16)。
- 执行
二、JDK 1.8 底层实现与线程安全机制(CAS + synchronized)
JDK 1.8 摒弃了 Segment 分段锁,改用更高效的“Node 数组 + 链表/红黑树 + CAS + synchronized”实现,性能大幅提升。
底层数据结构:与 JDK 1.8 HashMap 类似,采用“Node 数组 + 链表/红黑树”:
- Node 数组:底层是 Node 类型的数组(哈希桶),Node 的 key、value 和 next 均被
volatile修饰,保证可见性。 - 链表/红黑树:哈希冲突时,节点先以链表存储;当链表长度≥8 且数组长度≥64 时,转为红黑树(与 HashMap 树化条件一致),提升查询效率。
- 新增
TreeBin节点:封装红黑树,作为红黑树的根节点,统一管理树的结构调整。
- Node 数组:底层是 Node 类型的数组(哈希桶),Node 的 key、value 和 next 均被
线程安全机制(CAS + synchronized):取消分段锁后,通过更细粒度的同步机制保证线程安全:
- CAS 操作:用于无锁化的节点插入(如初始化哈希桶、头节点插入)。例如,通过
CASTabAt方法原子性地设置数组索引处的节点,避免加锁。 - synchronized 锁定头节点:当需要插入或修改节点时,仅对当前哈希桶的链表/红黑树的头节点加
synchronized锁,而非整个数组或分段。这使得不同哈希桶的操作可并行执行,锁竞争范围更小。 - volatile 保证可见性:Node 的 value 和 next 被
volatile修饰,确保一个线程修改后,其他线程能立即看到最新值,避免脏读。 - 扩容时的并发处理:扩容过程中,多个线程可协同迁移节点(通过
sizeCtl变量控制),避免单线程扩容的性能瓶颈。
- CAS 操作:用于无锁化的节点插入(如初始化哈希桶、头节点插入)。例如,通过
三、JDK 1.7 与 JDK 1.8 实现的核心差异
| 对比维度 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | Segment 数组 + HashEntry 数组 + 链表 | Node 数组 + 链表/红黑树 |
| 锁机制 | 分段锁(ReentrantLock) | CAS + synchronized(锁定头节点) |
| 并发度 | 由 Segment 数量决定(默认 16) | 理论上与哈希桶数量一致(更细粒度) |
| 读操作是否加锁 | 不加锁(volatile 保证可见性) | 不加锁(volatile 保证可见性) |
| 扩容效率 | 单 Segment 独立扩容,效率较低 | 多线程协同扩容,效率更高 |
| 红黑树支持 | 不支持(仅链表) | 支持(链表过长时转为红黑树) |
关键补充与代码示例
- JDK 1.8 中
put方法的同步逻辑(简化):final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable(); // CAS 初始化数组else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// CAS 插入头节点,无锁if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))break;}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f); // 协助扩容else {V oldVal = null;// 锁定头节点 f,处理链表/红黑树插入synchronized (f) {if (tabAt(tab, i) == f) {// 链表插入或红黑树插入逻辑// ...}}// 检查是否需要树化if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null; }
面试关键点:JDK 1.7 分段锁的设计与并发度,JDK 1.8 CAS + synchronized 的实现逻辑,两者的性能差异;加分点:解释为什么 JDK 1.8 放弃分段锁(锁粒度更细、减少内存开销、提升并发效率),或 sizeCtl 变量在扩容中的作用;记忆法:采用“版本-结构-锁”口诀——“1.7分段锁(Segment数组),1.8 CAS加sync(锁头节点);分段并发限16,1.8更细效率提”,通过版本对应核心实现记忆。
Hashtable 的底层数据结构是什么?为什么它是线程安全的?与 HashMap 的区别有哪些?
Hashtable 是 Java 早期的线程安全哈希表实现,与 HashMap 同属 Map 接口,但在数据结构、线程安全性及功能特性上有显著差异。理解其设计有助于更清晰地把握 Java 集合框架的演进。
一、Hashtable 的底层数据结构
Hashtable 的底层数据结构相对简单,且在 JDK 版本迭代中未引入红黑树优化,始终为“数组 + 链表”:
- 数组:作为哈希桶的基础存储结构,数组元素是
Entry节点(存储 key、value、hash 值、next 引用),初始容量默认是 11(非 2 的幂次)。 - 链表:当哈希冲突时,冲突的节点以链表形式存储在同一数组索引下(拉链法解决冲突)。与 HashMap 不同,Hashtable 未引入红黑树优化,即使链表过长,查询时间复杂度仍为 O(n)。
其索引计算方式也与 HashMap 不同:先通过 key.hashCode() 获取哈希值,再用 (hash & 0x7FFFFFFF) % table.length 计算索引(0x7FFFFFFF 确保哈希值为正数,避免负索引)。由于初始容量 11 不是 2 的幂次,无法使用 (n-1)&hash 位运算,只能通过取模计算,效率略低。
二、Hashtable 线程安全的原因
Hashtable 的线程安全是通过“方法级同步锁”实现的:其所有涉及修改或访问数据的方法(如 put、get、remove、size 等)均被 synchronized 修饰,保证同一时刻只有一个线程能执行这些方法。
例如,put 方法的源码:
public synchronized V put(K key, V value) {// 禁止 null 键和 null 值if (value == null) {throw new NullPointerException();}// 查找是否存在重复 key,存在则覆盖Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;@SuppressWarnings("unchecked")Entry<K,V> entry = (Entry<K,V>)tab[index];for (; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value;return old;}}// 插入新节点(头插法)addEntry(hash, key, value, index);return null;
}
由于 synchronized 修饰在方法上,锁的粒度是整个 Hashtable 对象,任何线程访问 Hashtable 的同步方法时,都需获取对象锁,因此能保证线程安全。但这也导致其并发性能较差——多线程即使操作不同的哈希桶,也需竞争同一把锁,效率低下。
三、Hashtable 与 HashMap 的核心区别
| 对比维度 | Hashtable | HashMap |
|---|---|---|
| 线程安全性 | 线程安全(方法加 synchronized) | 线程不安全(无同步机制) |
| null 键值支持 | 不允许 null 键和 null 值(抛异常) | 允许 1 个 null 键和多个 null 值 |
| 数据结构 | 数组 + 链表(无红黑树) | JDK 1.7:数组+链表;JDK 1.8:数组+链表/红黑树 |
| 初始容量与扩容 | 初始容量 11,扩容后为 2n+1 | 初始容量 16(2 的幂次),扩容后为 2n |
| 索引计算方式 | (hash & 0x7FFFFFFF) % 容量(取模) | (容量-1) & hash(位运算,容量为 2 的幂次) |
| 父类 | 继承 Dictionary 类 | 继承 AbstractMap 类 |
| 迭代器类型 | 枚举(Enumeration)和迭代器,枚举不支持快速失败 | 仅迭代器,支持快速失败(modCount 检测) |
| 并发场景适用性 | 低(锁粒度大,效率低) | 不适用(需手动同步或用 ConcurrentHashMap) |
关键补充
- 快速失败机制:HashMap 的迭代器通过
modCount变量检测并发修改(如迭代时其他线程修改 map),若检测到则抛ConcurrentModificationException;Hashtable 的迭代器也支持快速失败,但枚举(Enumeration)不支持。 - 替代方案:Hashtable 因并发效率低,已被 ConcurrentHashMap 取代,后者在保证线程安全的同时,通过更细粒度的锁机制(分段锁或 CAS + synchronized)大幅提升并发性能。
面试关键点:Hashtable 的数据结构(数组+链表)、线程安全的实现(synchronized 方法)、与 HashMap 在 null 支持、扩容、线程安全等方面的差异;加分点:分析 Hashtable 效率低的原因(锁粒度大),或解释为何不允许 null 键值(源码校验逻辑);记忆法:采用“对比记忆法”——“Hashtable:安全但慢(全表锁),禁 null,数组+链表,容量11;HashMap:不安全但快,允 null,1.8 有红黑树,容量16”,通过核心特性对比记忆。
ArrayList 和 LinkedList 的区别是什么?为什么 ArrayList 查询快、LinkedList 插入删除快?
ArrayList 和 LinkedList 是 Java 集合框架中最常用的 List 实现,二者在数据结构、性能特性和适用场景上有显著差异,核心区别源于底层存储结构的不同。
一、核心区别对比
| 对比维度 | ArrayList | LinkedList |
|---|---|---|
| 底层数据结构 | 动态数组(连续内存空间) | 双向链表(非连续内存,节点包含前后引用) |
| 随机访问(get) | 效率高,时间复杂度 O(1) | 效率低,时间复杂度 O(n) |
| 插入/删除(中间) | 效率低,时间复杂度 O(n)(需移动元素) | 效率高,时间复杂度 O(1)(仅修改指针) |
| 插入/删除(首尾) | 尾部插入高效(O(1),扩容时 O(n));头部插入 O(n) | 首尾插入均高效(O(1),修改首尾指针) |
| 内存占用 | 较少(仅存储元素,数组有扩容冗余) | 较多(每个节点需存储前后指针) |
| 扩容机制 | 容量不足时扩容(默认1.5倍) | 无扩容机制(节点动态创建) |
二、ArrayList 查询快的原因
ArrayList 底层基于动态数组实现,数组的元素在内存中连续存储,且每个元素的地址可通过“基地址 + 索引×元素大小”直接计算(随机访问特性)。当调用 get(int index) 方法时,只需通过索引校验(判断是否越界)后,直接返回数组对应位置的元素,无需遍历,时间复杂度为 O(1)。例如:
ArrayList<String> list = new ArrayList<>();
list.add("A");
list.add("B");
String value = list.get(1); // 直接访问数组索引1,效率极高
即使数组需要扩容(默认容量10,满后扩容为1.5倍),也仅影响插入性能,不影响查询——查询始终依赖索引的直接定位。
三、LinkedList 插入删除快的原因(针对中间位置)
LinkedList 底层是双向链表,每个节点(Node)包含三部分:元素值(item)、前驱节点引用(prev)、后继节点引用(next)。节点在内存中随机分布,无需连续空间。当在中间位置插入或删除节点时,只需修改目标节点前后节点的引用(指针),无需移动其他元素,时间复杂度为 O(1)(前提是已定位到目标节点)。例如,在节点 A 和节点 B 之间插入节点 C:
// 插入逻辑简化
C.prev = A;
C.next = B;
A.next = C;
B.prev = C;
而 ArrayList 在中间插入/删除时,需将目标位置后的所有元素整体后移或前移(如插入时 System.arraycopy 复制元素),元素越多,移动成本越高,时间复杂度为 O(n)。
注意:LinkedList 的插入删除效率优势仅体现在“已定位到目标节点”的场景。若需先通过索引定位节点(如 add(int index, E e)),则需从链表头或尾遍历到目标位置(时间复杂度 O(n)),整体效率可能低于 ArrayList(尤其当索引靠近中间时)。
四、适用场景总结
- ArrayList:适用于查询操作频繁,插入删除主要在尾部的场景(如用户列表展示、数据缓存)。
- LinkedList:适用于插入删除操作频繁且多在首尾的场景(如队列实现、链表式数据结构模拟)。
面试关键点:底层数据结构差异(数组 vs 链表)、随机访问特性对查询的影响、指针操作对插入删除的影响、不同位置操作的效率差异;加分点:提及 ArrayList 的扩容机制(ensureCapacityInternal 方法)、LinkedList 实现 Deque 接口可作为双端队列使用;记忆法:采用“结构决定性能”口诀——“ArrayList 数组存,查快增删(中间)慢;LinkedList 链表连,查慢增删(中间)快;首尾操作看细节,ArrayList 尾快头慢,LinkedList 首尾都快”。
项目中你用到了什么集合?请结合场景说明选择理由。
在实际项目中,集合的选择需结合业务场景的核心操作(查询、插入、删除、排序、并发等),以下是常见场景及对应的集合选择案例:
一、用户信息列表(查询频繁,偶有尾部插入)
场景:后台管理系统的用户列表,需频繁根据索引查询用户详情(如分页展示),新增用户时默认添加到列表尾部,极少在中间插入或删除。选择集合:ArrayList选择理由:
- ArrayList 基于动态数组,支持随机访问,
get(index)操作时间复杂度 O(1),能高效满足分页查询需求; - 尾部插入(
add(E e))无需移动元素,效率接近 O(1)(仅当容量不足时触发扩容,但可通过ensureCapacity预扩容优化); - 相比 LinkedList,内存占用更少(无指针开销),遍历(for循环)效率更高。
二、订单日志记录(尾部插入频繁,查询少)
场景:电商系统的订单日志,需不断在末尾追加新日志(每秒数十条),查询多为按时间范围遍历(极少随机访问),几乎不删除中间日志。选择集合:LinkedList选择理由:
- LinkedList 作为双向链表,尾部插入(
addLast(E e))仅需修改尾节点指针,时间复杂度 O(1),且无需扩容,适合高频尾部插入; - 虽然随机访问效率低,但场景中查询多为顺序遍历(迭代器遍历),LinkedList 的迭代效率与 ArrayList 接近;
- 相比 ArrayList,避免了扩容时的数组复制开销,适合数据量动态增长且未知上限的场景。
三、用户ID与信息映射(键值查询频繁)
场景:缓存用户信息(key为用户ID,value为用户对象),需频繁根据用户ID查询详情,偶尔更新用户信息,单线程环境。选择集合:HashMap选择理由:
- HashMap 基于哈希表,
get(key)操作平均时间复杂度 O(1),能高效通过用户ID定位信息; - 支持
put(key, value)覆盖更新,满足用户信息修改需求; - 相比 TreeMap,无需维护键的有序性,查询和插入效率更高,适合无排序需求的键值映射场景。
四、商品分类列表(需按名称排序)
场景:商品分类管理,需按分类名称升序展示,支持新增分类和按名称查询。选择集合:TreeMap选择理由:
- TreeMap 基于红黑树,能自动按键(分类名称)的自然顺序排序(或自定义比较器),无需额外排序操作;
- 支持
subMap、tailMap等范围查询方法,便于实现“查询名称大于‘手机’的分类”等需求; - 相比 HashMap + 手动排序,减少了排序的时间开销,且维护有序性的成本由红黑树自动承担。
五、并发场景下的商品库存列表(多线程读写)
场景:秒杀系统的商品库存列表,多线程同时读取库存(高频)和扣减库存(低频),需保证线程安全。选择集合:CopyOnWriteArrayList选择理由:
- CopyOnWriteArrayList 采用“写时复制”机制,读操作无锁(直接访问原数组),适合读多写少的并发场景,满足高频库存查询需求;
- 写操作(扣减库存)时复制新数组,避免多线程读写冲突,保证线程安全;
- 相比 Vector(全表锁),读操作无需等待,并发效率更高;相比 Collections.synchronizedList(同步代码块),减少了锁竞争。
面试关键点:结合场景明确核心操作(查询/插入/排序/并发),匹配集合的特性(效率/有序性/线程安全),体现对集合适用场景的理解;加分点:提及集合的优化细节(如 ArrayList 预扩容、HashMap 初始容量设置),或不同集合的性能对比数据;记忆法:采用“场景-核心操作-集合特性”关联法——“查多用ArrayList,尾插多用LinkedList,键值查用HashMap,有序用TreeMap,并发读写用CopyOnWrite”。
List 集合中有哪些线程安全的类?除了 Vector 和 Stack,JUC 包下还有哪些并发 List?
List 集合的线程安全类可分为传统同步类和 JUC(java.util.concurrent)包下的高效并发类,两者在实现机制和性能上有显著差异,适用于不同的并发场景。
一、传统的线程安全 List 类
VectorVector 是 Java 早期的线程安全 List 实现,底层基于动态数组(与 ArrayList 类似),其线程安全通过方法级 synchronized 锁保证:所有修改和访问方法(如
add、get、remove)均被synchronized修饰,确保同一时刻只有一个线程能执行这些方法。示例:public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true; }缺点:锁粒度大(整个 Vector 对象),多线程即使操作不同元素也需竞争同一把锁,并发效率低,适合低并发场景。
StackStack 继承自 Vector,是基于栈结构的线程安全集合(先进后出),其
push、pop、peek等方法同样被synchronized修饰,继承了 Vector 的线程安全机制和低效问题。由于功能单一且效率低,实际开发中多被Deque接口的实现类(如LinkedList)替代。
二、JUC 包下的并发 List
JUC 包提供了更高效的并发 List 实现,通过细粒度锁或无锁机制优化性能,适合高并发场景。
CopyOnWriteArrayList这是最常用的 JUC 并发 List,核心机制是“写时复制”:
- 读操作:直接访问底层数组(
volatile修饰),无锁,效率极高; - 写操作(
add、set、remove等):先复制一份新数组,在新数组上修改,再将底层数组引用指向新数组(通过ReentrantLock保证写操作原子性); - 线程安全保证:读操作无需等待,写操作互斥,避免了读写冲突。
示例(写操作简化逻辑):
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock(); // 写操作加锁try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1); // 复制新数组newElements[len] = e;setArray(newElements); // 指向新数组return true;} finally {lock.unlock();} }适用场景:读多写少(如配置列表、权限列表),写操作频率低但需线程安全。
- 读操作:直接访问底层数组(
ConcurrentLinkedQueue(伪 List,实现 Queue 接口)虽为队列(Queue),但可作为并发 List 使用(实现了
Iterable接口,支持遍历),底层基于无锁双向链表,通过 CAS 操作保证线程安全:- 所有操作(
add、poll、contains)均无锁,依赖 CAS 原子指令完成; - 适合高并发场景下的元素添加和移除,但随机访问(
get(index))效率低(需遍历)。
- 所有操作(
三、其他线程安全 List 的实现方式
除上述类外,还可通过工具类包装非线程安全 List 实现线程安全:
Collections.synchronizedList(List<T> list):返回一个同步代理类,所有方法通过同步代码块(锁对象为传入的 list)保证线程安全,性能与 Vector 接近(锁粒度大),适合简单场景。示例:List<String> syncList = Collections.synchronizedList(new ArrayList<>());
面试关键点:Vector/Stack 的同步机制(synchronized 方法)及其缺点,CopyOnWriteArrayList 的写时复制原理和适用场景,JUC 并发 List 与传统同步类的性能差异;加分点:解释 CopyOnWriteArrayList 的弱一致性(迭代器遍历的是旧数组),或 ConcurrentLinkedQueue 的 CAS 实现细节;记忆法:采用“类型-机制-场景”口诀——“传统 Vector/Stack,全表锁低效;JUC 有 CopyOnWrite,写复制读无锁,读多写少用;同步包装简单用,高并发选 JUC”。
什么是并发容器?除了 ConcurrentHashMap,JUC 包下还有哪些常用的并发容器(如 CopyOnWriteArrayList、BlockingQueue)?
并发容器是 Java 并发工具包(JUC)中为高并发场景设计的容器类,它们在保证线程安全的同时,通过优化同步机制(如细粒度锁、无锁化)提升并发效率,解决了传统同步容器(如 Hashtable、Vector)锁粒度大、性能低的问题。
一、并发容器的核心特性
- 线程安全:内部通过锁机制(如分段锁、synchronized)或无锁技术(CAS)保证多线程读写的安全性,无需外部同步。
- 高效并发:采用细粒度锁(锁定容器的部分区域)或读写分离(如写时复制),允许多线程同时访问不同区域,减少锁竞争。
- 功能适配:针对并发场景提供特有功能(如 BlockingQueue 的阻塞操作、ConcurrentMap 的原子性方法)。
二、JUC 包下常用的并发容器
除 ConcurrentHashMap(并发 Map)外,JUC 还提供了多种并发容器,按功能可分为 List、Set、Queue 等类别:
CopyOnWriteArrayList(并发 List)
- 原理:写时复制——读操作直接访问底层数组(无锁),写操作(add/set/remove)复制新数组并替换旧数组(通过 ReentrantLock 保证原子性)。
- 特点:读效率极高,写效率低(复制数组开销),迭代器弱一致性(不抛出 ConcurrentModificationException)。
- 适用场景:读多写少(如配置列表、日志记录)。
CopyOnWriteArraySet(并发 Set)
- 原理:基于 CopyOnWriteArrayList 实现(内部维护一个 CopyOnWriteArrayList,元素去重通过
addIfAbsent方法)。 - 特点:与 CopyOnWriteArrayList 特性一致,保证元素唯一,适合读多写少的去重场景。
- 原理:基于 CopyOnWriteArrayList 实现(内部维护一个 CopyOnWriteArrayList,元素去重通过
BlockingQueue(阻塞队列)专为生产者-消费者模式设计,提供阻塞插入(队列满时等待)和阻塞移除(队列空时等待)操作,常用实现类:
- ArrayBlockingQueue:基于数组的有界阻塞队列,通过 ReentrantLock 实现线程安全,支持公平/非公平锁。
- LinkedBlockingQueue:基于链表的可选有界阻塞队列,默认容量 Integer.MAX_VALUE,读写操作可使用不同锁(提高并发)。
- SynchronousQueue:无缓冲队列,生产者插入元素必须等待消费者取走(一对一传递),适合线程间直接通信。
- PriorityBlockingQueue:支持优先级的无界阻塞队列,元素需实现 Comparable 接口,按优先级排序。
ConcurrentLinkedQueue/ConcurrentLinkedDeque(并发队列/双端队列)
- 原理:基于无锁双向链表,通过 CAS 操作实现线程安全,无锁竞争。
- 特点:高并发场景下性能优异,不支持阻塞操作,适合非阻塞的高频读写场景(如任务队列)。
ConcurrentSkipListMap/ConcurrentSkipListSet(并发有序 Map/Set)
- 原理:基于跳表(SkipList)实现,一种有序的数据结构,查询效率 O(logn),支持范围查询。
- 特点:并发版的 TreeMap/TreeSet,无需加锁即可支持多线程并发操作,适合需要有序性的高并发场景。
三、并发容器与传统同步容器的对比
| 类型 | 传统同步容器(如 Vector、Hashtable) | JUC 并发容器(如 ConcurrentHashMap、CopyOnWriteArrayList) |
|---|---|---|
| 锁粒度 | 全表锁(锁定整个容器) | 细粒度锁(如分段锁、节点锁)或无锁(CAS、写时复制) |
| 并发效率 | 低(多线程竞争同一把锁) | 高(支持多线程并行操作不同区域) |
| 迭代安全性 | 快速失败(抛 ConcurrentModificationException) | 弱一致性(迭代旧数据,不抛异常) |
| 功能丰富度 | 仅基础容器功能 | 提供并发特有功能(如阻塞操作、原子性方法) |
面试关键点:并发容器的定义和核心特性,各常用并发容器的实现原理(如写时复制、CAS、阻塞队列)和适用场景,与传统同步容器的性能差异;加分点:结合具体场景说明容器选择(如生产者-消费者用 BlockingQueue,读多写少用 CopyOnWrite),或解释跳表相比红黑树在并发场景的优势;记忆法:采用“容器类型-核心原理-场景”口诀——“List 选 CopyOnWrite(写复制),Set 同源 CopyOnWriteSet;队列 Blocking 管阻塞,无锁队列 ConcurrentLinked;有序并发 SkipList,Map 首选 ConcurrentHashMap”。
Java 多线程的实现方法有哪些(如继承 Thread、实现 Runnable、Callable+Future、线程池)?
Java 多线程的实现方法围绕“线程创建”和“任务执行”展开,核心是将任务逻辑与线程生命周期管理分离,常见方法包括继承 Thread 类、实现 Runnable 接口、使用 Callable+Future 组合及线程池,每种方法有其适用场景和优缺点。
一、继承 Thread 类
这是最基础的多线程实现方式,通过继承 Thread 类并重写 run 方法定义线程任务。
实现步骤:
- 定义类继承 Thread 类;
- 重写
run方法(线程执行的任务逻辑); - 创建子类实例,调用
start()方法启动线程(而非直接调用run,否则为普通方法调用)。
代码示例:
class MyThread extends Thread {@Overridepublic void run() {for (int i = 0; i < 5; i++) {System.out.println("Thread-" + Thread.currentThread().getId() + ": " + i);}} }public class ThreadDemo {public static void main(String[] args) {MyThread thread = new MyThread();thread.start(); // 启动线程,JVM调用run方法} }优缺点:
- 优点:实现简单,可直接通过
this访问线程对象; - 缺点:Java 单继承限制(子类无法再继承其他类),任务逻辑与线程生命周期耦合,不适合多个线程共享任务的场景。
- 优点:实现简单,可直接通过
二、实现 Runnable 接口
Runnable 接口仅定义 run 方法(无返回值),通过实现该接口可将任务逻辑与线程分离,解决单继承限制。
实现步骤:
- 定义类实现 Runnable 接口,重写
run方法; - 创建 Runnable 实例,作为参数传入 Thread 构造器;
- 调用 Thread 实例的
start()方法启动线程。
- 定义类实现 Runnable 接口,重写
代码示例:
class MyRunnable implements Runnable {@Overridepublic void run() {for (int i = 0; i < 5; i++) {System.out.println("Runnable-" + Thread.currentThread().getId() + ": " + i);}} }public class RunnableDemo {public static void main(String[] args) {Runnable task = new MyRunnable();new Thread(task).start(); // 线程与任务分离new Thread(task).start(); // 多个线程共享同一任务} }优缺点:
- 优点:避免单继承限制,支持多个线程共享同一任务(适合资源共享场景,如卖票系统);
- 缺点:
run方法无返回值,无法获取任务执行结果。
三、实现 Callable 接口 + Future
Callable 接口与 Runnable 类似,但 call 方法有返回值且可抛出异常,结合 Future 可获取任务执行结果。
实现步骤:
- 定义类实现 Callable<T> 接口(T 为返回值类型),重写
call方法; - 创建 Callable 实例,包装为 FutureTask 实例(FutureTask 实现了 Runnable 和 Future 接口);
- 将 FutureTask 传入 Thread 构造器,调用
start()启动线程; - 通过 FutureTask 的
get()方法获取返回值(会阻塞直到任务完成)。
- 定义类实现 Callable<T> 接口(T 为返回值类型),重写
代码示例:
import java.util.concurrent.Callable; import java.util.concurrent.FutureTask;class MyCallable implements Callable<Integer> {@Overridepublic Integer call() throws Exception {int sum = 0;for (int i = 1; i <= 10; i++) {sum += i;}return sum; // 返回计算结果} }public class CallableDemo {public static void main(String[] args) throws Exception {Callable<Integer> task = new MyCallable();FutureTask<Integer> futureTask = new FutureTask<>(task);new Thread(futureTask).start();System.out.println("计算结果:" + futureTask.get()); // 获取返回值,可能阻塞} }优缺点:
- 优点:有返回值,可处理异常,适合需要任务结果的场景;
- 缺点:
get()方法可能阻塞,需合理处理超时(get(long timeout, TimeUnit unit))。
四、线程池(Executor 框架)
线程池通过复用线程减少创建/销毁线程的开销,是生产环境中推荐的多线程实现方式,核心接口为 ExecutorService。
常用线程池:
Executors.newFixedThreadPool(n):固定大小线程池,重用 n 个线程;Executors.newCachedThreadPool():缓存线程池,线程数动态调整(适合短期任务);Executors.newSingleThreadExecutor():单线程池,任务按顺序执行;ThreadPoolExecutor:自定义线程池(推荐,可灵活配置核心线程数、最大线程数、拒绝策略等)。
代码示例(自定义线程池):
import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit;public class ThreadPoolDemo {public static void main(String[] args) {// 核心线程数2,最大线程数4,队列容量2,空闲线程存活时间10秒ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 10, TimeUnit.SECONDS,new ArrayBlockingQueue<>(2),new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略);for (int i = 0; i < 5; i++) {executor.submit(() -> { // 提交任务System.out.println("Thread-" + Thread.currentThread().getId() + " 执行任务");});}executor.shutdown(); // 关闭线程池} }优缺点:
- 优点:控制线程数量(避免资源耗尽),复用线程(减少开销),提供任务队列和拒绝策略,适合高并发场景;
- 缺点:需合理配置参数(如核心线程数、队列大小),否则可能导致性能问题。
面试关键点:四种实现方法的代码示例、优缺点及适用场景,线程池的优势(资源复用、控制并发数),Callable 与 Runnable 的核心区别(返回值、异常);加分点:解释 start() 与 run() 的区别(start() 启动新线程,run() 仅执行方法),或 ThreadPoolExecutor 的核心参数含义;记忆法:采用“方法-特点-场景”口诀——“继承 Thread 简但单继承;实现 Runnable 解耦可共享;Callable+Future 有返回;线程池高效控并发,生产首选”。
你在项目中是如何使用多线程的?为什么要使用多线程?
在实际项目中,多线程的使用需结合业务场景的性能瓶颈与并发需求,核心目标是提升系统吞吐量、减少响应时间。以下是具体应用场景及使用原因:
一、项目中多线程的典型应用场景
异步处理非核心流程电商系统的订单提交场景中,用户支付成功后需完成订单入库(核心流程),同时需触发短信通知、积分更新、物流创建等非核心流程。若同步执行这些操作,会延长订单提交的响应时间(用户需等待所有流程完成)。解决方案:使用线程池异步处理非核心流程。订单入库后,将短信、积分等任务提交至线程池,主线程直接返回“订单提交成功”,非核心流程在后台并行执行。代码示例(线程池配置与使用):
// 配置线程池(核心线程5,最大线程10,适用于轻量级异步任务) private static final ExecutorService ASYNC_POOL = new ThreadPoolExecutor(5, 10, 60L, TimeUnit.SECONDS,new LinkedBlockingQueue<>(100),new ThreadFactory() {private final AtomicInteger count = new AtomicInteger(1);@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "order-async-" + count.getAndIncrement());}},new ThreadPoolExecutor.DiscardPolicy() // 任务满时丢弃(非核心任务可容忍) );// 订单提交后异步处理非核心流程 public void submitOrder(Order order) {// 1. 核心流程:订单入库(同步执行)orderMapper.insert(order);// 2. 异步处理非核心流程ASYNC_POOL.submit(() -> sendSms(order.getUserId())); // 短信通知ASYNC_POOL.submit(() -> updatePoints(order.getUserId(), order.getAmount())); // 积分更新 }并发处理批量任务数据迁移场景中,需将100万条历史数据从MySQL迁移至Elasticsearch。单线程逐条迁移需数小时,效率极低。解决方案:按数据ID分片,使用多线程并发迁移。例如,将数据分为10个区间,每个线程处理一个区间,利用多CPU核心并行执行,迁移时间缩短至原1/10左右。核心逻辑:通过线程池提交10个迁移任务,每个任务处理10万条数据,使用CountDownLatch等待所有任务完成后汇总结果。
服务器端处理多客户端请求即时通讯服务器需同时处理 thousands 级客户端的消息发送与接收。单线程无法应对高并发,会导致请求阻塞。解决方案:使用线程池管理客户端连接。服务器监听端口,每接收一个客户端Socket连接,就从线程池分配一个线程处理该连接的消息读写,避免为每个连接创建新线程(减少线程创建销毁开销)。
二、使用多线程的核心原因
提高CPU利用率现代CPU多为多核架构,单线程只能利用一个核心,多线程可使多个核心同时工作。例如,数据迁移时,多线程可让不同核心分别处理数据读取、转换、写入,避免CPU空闲。
减少响应时间将耗时操作(如IO、网络请求)异步化,主线程无需等待,直接返回结果。例如,订单提交时,非核心流程异步执行,用户等待时间从500ms缩短至100ms。
提高系统吞吐量线程池通过复用线程减少创建/销毁线程的开销(线程创建需分配栈内存、注册系统资源),同时控制并发数(避免线程过多导致的上下文切换开销)。例如,线程池可稳定处理每秒1000次请求,而无限制创建线程可能因资源耗尽崩溃。
面试关键点:结合具体场景说明多线程的应用(异步处理、并发任务、请求处理),强调线程池的优势(资源复用、控制并发),解释多线程提升性能的原理(CPU利用率、响应时间、吞吐量);加分点:提及线程池参数的调优经验(如核心线程数根据CPU核心数设置),或避免线程安全问题的实践(如使用ConcurrentHashMap);记忆法:采用“场景-问题-方案”关联法——“异步处理非核心(减响应),并发任务分区间(提速度),服务端用线程池(扩吞吐);多线程利多核,提效率解阻塞”。
Java 在多线程下如何保持数据的一致性?
多线程环境下,数据一致性指多个线程对共享数据的操作结果符合预期,避免因并发读写导致的数据错乱(如脏读、不可重复读、幻读)。Java 提供了多种机制保证数据一致性,核心是通过同步或隔离控制共享数据的访问。
一、同步机制(控制并发访问顺序)
synchronized 关键字最基础的同步方式,通过“对象锁”保证同一时刻只有一个线程执行同步代码块/方法,实现互斥访问共享数据。
- 作用范围:同步方法(锁为当前对象)、静态同步方法(锁为类对象)、同步代码块(锁为指定对象)。
- 原理:编译后生成
monitorenter和monitorexit指令,线程进入同步块前需获取对象的内置锁(monitor),执行完毕释放锁,其他线程需等待。 - 适用场景:简单的互斥场景(如计数器、单例模式双重检查)。示例(保证计数器一致性):
public class Counter {private int count = 0;// 同步方法,锁为当前Counter实例public synchronized void increment() {count++; // 避免多线程同时执行++导致的计数错误}public synchronized int getCount() {return count;} }显式锁(Lock 接口)JDK 1.5 引入,比 synchronized 更灵活,支持中断、超时、公平锁等特性,代表实现为 ReentrantLock。
- 核心方法:
lock()(获取锁)、unlock()(释放锁,需在 finally 中调用)、tryLock(long timeout, TimeUnit unit)(超时获取锁)。 - 优势:可实现非阻塞获取锁(避免死等),支持公平锁(按请求顺序获取锁),适合复杂同步场景(如读写分离)。示例(公平锁保证有序访问):
public class FairCounter {private final Lock lock = new ReentrantLock(true); // 公平锁private int count = 0;public void increment() {lock.lock();try {count++;} finally {lock.unlock(); // 确保释放锁}} }- 核心方法:
二、可见性与原子性保证
volatile 关键字保证共享变量的可见性(一个线程修改后,其他线程立即可见),禁止指令重排序,但不保证原子性。
- 原理:通过内存屏障(Memory Barrier)实现,写操作后强制将变量刷新到主内存,读操作前从主内存加载最新值。
- 适用场景:状态标记(如停止线程的 flag)、单例模式的双重检查(防止指令重排序导致的空指针)。示例(线程停止标记):
public class VolatileDemo {private volatile boolean stop = false; // 可见性保证public void run() {while (!stop) { // 其他线程修改stop后,此处能立即感知// 执行任务}}public void stop() {stop = true; // 修改标记} }原子类(java.util.concurrent.atomic)基于 CAS(Compare-And-Swap)操作实现原子性,无需加锁,性能优于同步机制。
- 常用类:AtomicInteger(原子整数)、AtomicReference(原子引用)、AtomicStampedReference(带版本号,解决ABA问题)。
- 原理:通过 Unsafe 类的 native 方法实现 CAS,比较内存值与预期值,一致则更新,否则重试(自旋)。示例(原子计数器):
public class AtomicCounter {private final AtomicInteger count = new AtomicInteger(0);public void increment() {count.incrementAndGet(); // 原子性++操作}public int getCount() {return count.get();} }
三、并发容器与线程隔离
并发容器专为多线程设计的容器,内部通过锁或 CAS 保证线程安全,避免手动同步。
- ConcurrentHashMap:分段锁(JDK 1.7)或 CAS+synchronized(JDK 1.8),支持高并发读写。
- CopyOnWriteArrayList:写时复制,读操作无锁,适合读多写少场景。
- BlockingQueue:阻塞队列,自带同步机制,适合生产者-消费者模式。
ThreadLocal通过线程隔离避免共享数据——为每个线程创建独立的变量副本,线程仅操作自己的副本,无需同步。
- 适用场景:存储线程私有信息(如数据库连接、用户会话)。
- 注意:需在 finally 中调用
remove()方法,避免线程池环境下的内存泄漏。示例(存储线程私有ID):
public class ThreadLocalDemo {private static final ThreadLocal<String> THREAD_ID = ThreadLocal.withInitial(() -> "default");public void setThreadId(String id) {THREAD_ID.set(id);}public String getThreadId() {return THREAD_ID.get();}public void clear() {THREAD_ID.remove(); // 清理副本} }
四、选择策略总结
| 场景需求 | 推荐方案 | 优势 |
|---|---|---|
| 简单互斥、低并发 | synchronized | 实现简单,JVM自动优化 |
| 复杂同步(中断、公平锁) | ReentrantLock | 灵活控制,支持高级特性 |
| 状态标记、可见性 | volatile | 轻量,无锁开销 |
| 原子性操作(计数、更新) | AtomicInteger 等原子类 | 无锁,高并发下性能优 |
| 高并发容器操作 | ConcurrentHashMap 等并发容器 | 内部优化,无需手动同步 |
| 线程私有数据 | ThreadLocal | 彻底避免共享,无锁竞争 |
面试关键点:同步机制(synchronized、Lock)、可见性与原子性(volatile、原子类)、并发容器与线程隔离的适用场景,各机制的原理与优缺点;加分点:解释 CAS 的 ABA 问题及解决方法(AtomicStampedReference),或 synchronized 与 Lock 的性能对比(JDK 1.6 后 synchronized 优化后性能接近);记忆法:采用“问题-方案”口诀——“互斥用 sync 或 Lock,可见性靠 volatile;原子操作找 atomic,容器并发用 JUC;线程私有 ThreadLocal,数据一致全靠它”。
多个客户端向服务器发送数据时,如何区分不同客户端并分别处理?
服务器处理多客户端并发请求时,核心是通过“客户端标识”唯一区分每个连接,并为每个客户端维护独立的处理逻辑和状态。具体实现依赖网络编程模型与会话管理机制,以下是关键技术与方案:
一、基于网络连接的客户端区分(底层标识)
TCP/IP 协议中,每个客户端与服务器的连接通过“四元组”(源IP、源端口、目标IP、目标端口)唯一标识,服务器可通过该标识区分不同客户端。
BIO 模型:为每个连接分配独立线程服务器通过
ServerSocket监听端口,每接收一个客户端Socket连接,就创建一个线程(或从线程池获取)处理该连接。线程与 Socket 一一绑定,通过 Socket 对象区分客户端。- 核心逻辑:
public class BioServer {private static final ExecutorService THREAD_POOL = Executors.newFixedThreadPool(10);public static void main(String[] args) throws IOException {ServerSocket serverSocket = new ServerSocket(8080);while (true) {Socket clientSocket = serverSocket.accept(); // 阻塞等待连接// 为每个客户端Socket分配线程处理THREAD_POOL.submit(new ClientHandler(clientSocket));}}static class ClientHandler implements Runnable {private final Socket clientSocket;public ClientHandler(Socket socket) {this.clientSocket = socket;}@Overridepublic void run() {// 通过clientSocket获取客户端标识(IP+端口)String clientId = clientSocket.getInetAddress().getHostAddress() + ":" + clientSocket.getPort();System.out.println("处理客户端:" + clientId + " 的数据");// 读取数据、处理、响应...}} } - 区分方式:线程通过持有的
clientSocket对象获取客户端 IP 和端口(clientSocket.getInetAddress()、clientSocket.getPort()),作为临时标识。
- 核心逻辑:
NIO 模型:通过 Channel 与 SelectionKey 区分NIO 采用多路复用器(Selector)管理多个客户端连接,每个连接对应一个
SocketChannel和SelectionKey(绑定 Channel 与感兴趣的事件)。- 核心逻辑:服务器通过
SelectionKey.attachment()方法为每个连接附加客户端信息(如标识、状态),处理时通过SelectionKey获取对应客户端数据。 - 优势:单线程(或少量线程)处理多连接,减少线程资源消耗,适合高并发场景。
- 核心逻辑:服务器通过
二、基于应用层的客户端标识(业务标识)
底层网络标识(IP+端口)可能变化(如客户端重启后端口改变),实际业务中需更稳定的标识(如用户ID、会话ID),通过应用层协议传递。
会话ID(Session ID)客户端首次连接时,服务器生成唯一会话ID(如UUID),通过响应返回给客户端;客户端后续请求需携带该ID,服务器通过ID区分客户端并关联状态(如用户信息、操作历史)。
- 实现方式:服务器用
Map<String, ClientSession>存储会话ID与客户端状态的映射,例如:// 服务器维护会话映射 private static final ConcurrentHashMap<String, ClientSession> SESSIONS = new ConcurrentHashMap<>();// 客户端首次连接时生成会话ID public String createSession(Socket socket) {String sessionId = UUID.randomUUID().toString();ClientSession session = new ClientSession(sessionId, socket, new Date());SESSIONS.put(sessionId, session);return sessionId; }// 处理客户端数据时,通过会话ID获取对应会话 public void handleData(String sessionId, byte[] data) {ClientSession session = SESSIONS.get(sessionId);if (session != null) {session.process(data); // 处理该客户端的数据} }
- 实现方式:服务器用
用户身份标识(如Token)需用户登录的系统中,客户端登录成功后获取Token(如JWT),后续请求携带Token,服务器通过Token解析出用户ID,区分不同用户(即使同一客户端切换用户,也能正确区分)。
- 优势:与用户身份强绑定,适合需要权限控制的场景(如电商后台、社交应用)。
三、客户端数据的分别处理策略
独立处理队列为每个客户端分配独立的任务队列,服务器线程池从对应队列中获取任务处理,避免不同客户端数据混杂。例如,使用
ConcurrentHashMap<String, BlockingQueue<Data>>存储客户端ID与队列的映射,保证数据按客户端有序处理。状态隔离每个客户端的处理逻辑和中间状态(如未完成的订单、缓存数据)独立存储(如通过 ThreadLocal 或会话对象),避免多客户端操作相互干扰。例如,银行转账时,客户端A的转账状态不会影响客户端B的操作。
并发控制对同一客户端的并发请求(如重复提交),通过锁机制(如
synchronized (sessionId.intern()))保证串行处理,避免数据不一致(如重复扣款)。
面试关键点:底层网络标识(四元组、Socket/Channel)与应用层标识(会话ID、Token)的区别,BIO/NIO 模型下的区分方式,客户端数据独立处理的策略(队列、状态隔离);加分点:提及分布式场景下的客户端标识(如结合IP+用户ID+设备ID),或高并发下会话管理的优化(如Redis存储会话);记忆法:采用“层次-标识-处理”口诀——“底层靠连接(Socket/Channel),应用用会话(ID/Token);分别处理靠队列,状态隔离保独立”。
线程间的通信方式有哪些?wait()、notify()、sleep()的区别是什么?
线程间通信指多个线程通过协作完成任务,核心是传递信号或共享数据;而 wait()、notify()、sleep() 是控制线程状态的关键方法,在通信中扮演重要角色,三者的区别体现在锁机制、使用场景等方面。
一、线程间的通信方式
共享内存(基于共享变量)多个线程访问同一共享变量,通过修改变量状态传递信息,需同步机制保证数据一致性。
- 示例:生产者线程修改共享队列(添加数据),消费者线程读取队列(获取数据),用 synchronized 或 Lock 保证队列操作的原子性。
// 共享队列作为通信媒介 private static final Queue<Integer> queue = new LinkedList<>(); private static final int CAPACITY = 10;// 生产者 class Producer implements Runnable {@Overridepublic void run() {synchronized (queue) {while (queue.size() == CAPACITY) {try { queue.wait(); } catch (InterruptedException e) {} // 队列满则等待}queue.add(1); // 生产数据queue.notify(); // 唤醒消费者}} }// 消费者 class Consumer implements Runnable {@Overridepublic void run() {synchronized (queue) {while (queue.isEmpty()) {try { queue.wait(); } catch (InterruptedException e) {} // 队列空则等待}queue.poll(); // 消费数据queue.notify(); // 唤醒生产者}} }消息传递(基于通信机制)线程通过明确的消息发送/接收机制通信,无需共享变量,降低同步复杂度。
- BlockingQueue:生产者-消费者模型的首选,队列自带阻塞特性(
put满时阻塞,take空时阻塞),无需手动 wait/notify。 - 管道流(PipedStream):线程间通过输入输出流传递数据,适合字节流通信(如
PipedInputStream与PipedOutputStream配对使用)。 - 同步工具类:
CountDownLatch(等待所有线程完成)、CyclicBarrier(线程到达屏障后一起执行)、Semaphore(控制并发数)。
- BlockingQueue:生产者-消费者模型的首选,队列自带阻塞特性(
ThreadLocal(线程隔离通信)严格来说是线程私有数据存储,通过为每个线程创建变量副本,避免线程间共享,间接实现“线程间无干扰”的通信隔离(如存储线程上下文信息)。
二、wait()、notify()、sleep()的区别
| 对比维度 | wait() | notify() | sleep(long) |
|---|---|---|---|
| 所属类 | Object 类(所有对象都有) | Object 类 | Thread 类 |
| 作用 | 使当前线程释放锁并进入等待状态 | 唤醒一个等待该对象锁的线程 | 使当前线程暂停执行指定时间 |
| 锁机制 | 必须在同步块/方法中使用,会释放对象锁 | 必须在同步块/方法中使用,不释放锁(唤醒后线程需竞争锁) | 可在任何地方使用,不释放锁(抱着锁休眠) |
| 唤醒方式 | 需被其他线程 notify()/notifyAll() 唤醒 | 主动唤醒等待线程 | 时间到自动唤醒,或被 interrupt() 中断 |
| 异常处理 | 必须捕获 InterruptedException | 无需捕获异常 | 必须捕获 InterruptedException |
| 使用场景 | 线程间协作(如等待资源就绪) | 线程间协作(如资源就绪后通知) | 暂停执行(如模拟延迟) |
三、关键细节与使用注意
- wait() 与 notify() 的协作条件
- 必须在同步块/方法中使用(持有对象锁),否则抛
IllegalMonitorStateException。 - 等待与唤醒必须针对同一对象锁(如线程A在
lock对象上 wait(),需线程B在lock对象上 notify() 才能唤醒)。 - 建议用
while循环判断等待条件(而非if),避免虚假唤醒(线程被唤醒但条件未满足):synchronized (lock) {while (conditionNotMet) { // 用while循环检查条件lock.wait();}// 处理逻辑 }
- 必须在同步块/方法中使用(持有对象锁),否则抛
Volatile 关键字有原子性吗?它的作用是什么(保证可见性、禁止指令重排序)?适用场景有哪些?
Volatile 是 Java 中用于修饰变量的关键字,其核心特性是保证共享变量的可见性和禁止指令重排序,但不具备原子性。理解这一特性及其适用场景,是掌握多线程并发编程的基础。
一、Volatile 不具备原子性
原子性指操作不可分割(要么全部执行,要么不执行)。Volatile 修饰的变量无法保证复合操作的原子性,例如 i++ 操作(包含读取、加1、写入三个步骤),多线程并发执行时会出现数据不一致。
示例(Volatile 无法保证原子性):
public class VolatileAtomicDemo {private static volatile int count = 0;public static void main(String[] args) throws InterruptedException {Runnable task = () -> {for (int i = 0; i < 1000; i++) {count++; // 非原子操作,多线程下会出错}};Thread t1 = new Thread(task);Thread t2 = new Thread(task);t1.start();t2.start();t1.join();t2.join();System.out.println("count = " + count); // 结果可能小于2000}
}
上述代码中,两个线程各执行 1000 次 count++,预期结果为 2000,但实际常小于 2000。原因是 count++ 非原子操作:线程 A 读取 count=100 后,线程 B 可能也读取到 100 并完成加1(写入 101),线程 A 继续加1后也写入 101,导致两次操作只累加1次。
二、Volatile 的核心作用
保证可见性可见性指当一个线程修改了 Volatile 变量的值,其他线程能立即看到最新值。
- 原理:通过内存屏障实现。写操作时,JVM 会强制将变量从工作内存刷新到主内存;读操作时,会从主内存重新加载变量到工作内存,避免线程读取到本地缓存的旧值。
- 对比:非 Volatile 变量的修改可能仅停留在线程的工作内存,其他线程无法感知,导致“脏读”。
禁止指令重排序指令重排序是 JVM 为优化性能对指令执行顺序的调整(不影响单线程结果,但可能破坏多线程语义)。Volatile 通过内存屏障禁止特定类型的重排序:
- 写屏障:保证 Volatile 变量的写操作后,后续指令不会被重排序到写操作之前;
- 读屏障:保证 Volatile 变量的读操作前,之前的指令不会被重排序到读操作之后。
- 示例:单例模式的双重检查锁中,
instance需用 Volatile 修饰,避免指令重排序导致的“半初始化”问题(对象未完全初始化就被其他线程获取)。
三、Volatile 的适用场景
状态标记量用于控制线程的启动/停止、暂停/继续等状态切换,例如:
public class VolatileFlagDemo {private volatile boolean isRunning = true;public void start() {new Thread(() -> {while (isRunning) { // 可见性保证:主线程修改后立即感知// 执行任务}}).start();}public void stop() {isRunning = false; // 主线程修改状态} }此处 Volatile 确保主线程修改
isRunning后,子线程能立即退出循环。单例模式的双重检查锁防止指令重排序导致的未初始化对象被引用:
public class Singleton {private static volatile Singleton instance; // 必须用Volatileprivate Singleton() {}public static Singleton getInstance() {if (instance == null) { // 第一次检查synchronized (Singleton.class) {if (instance == null) { // 第二次检查instance = new Singleton(); // 禁止重排序}}}return instance;} }new Singleton()可分解为“分配内存→初始化对象→引用指向内存”,若发生重排序(分配内存→引用指向内存→初始化对象),其他线程可能获取到未初始化的instance,Volatile 可禁止这种重排序。双重校验的变量变量的读写操作是单一的赋值或获取(非复合操作),且无需依赖其他变量的状态,例如配置参数的实时更新。
面试关键点:Volatile 不保证原子性的原因,可见性(内存屏障)和禁止重排序的实现,三大适用场景(状态标记、单例双重检查、简单变量);加分点:结合 JMM(Java 内存模型)解释可见性,或分析 volatile 与原子类的配合使用(如用 AtomicInteger 解决 i++ 原子性问题);记忆法:采用“特性-场景”口诀——“Volatile 无原子,可见重排止;状态标记单例用,简单变量才合适”。
Volatile 和 Synchronized 的区别是什么?
Volatile 和 Synchronized 是 Java 多线程编程中保证并发安全的重要机制,但两者在作用范围、功能特性和适用场景上有显著差异,理解这些差异是正确选择并发控制手段的关键。
一、核心区别对比
| 对比维度 | Volatile | Synchronized |
|---|---|---|
| 作用对象 | 只能修饰变量(实例变量、静态变量) | 可修饰方法(实例方法、静态方法)或代码块(指定锁对象) |
| 原子性保证 | 不保证(仅保证单次读写可见,复合操作如 i++ 仍会出错) | 保证(同步块/方法内的操作视为原子整体) |
| 可见性保证 | 保证(通过内存屏障刷新主内存) | 保证(释放锁时刷新主内存,获取锁时加载最新值) |
| 重排序禁止 | 保证(通过内存屏障禁止特定重排序) | 保证(同步块内的指令不会与块外指令重排序) |
| 锁机制 | 无锁(轻量级,仅内存屏障开销) | 有锁(对象锁/类锁,可能涉及上下文切换) |
| 适用场景 | 简单状态标记、单例双重检查等 | 复杂同步逻辑(如计数器、资源竞争) |
| 性能开销 | 低(仅内存屏障) | 中高(JDK 1.6 后优化,偏向锁/轻量级锁开销低) |
| 阻塞特性 | 非阻塞(线程不会等待) | 阻塞(未获取锁的线程会进入等待状态) |
二、详细差异解析
原子性保证的差异Volatile 仅保证变量的单次读写操作可见,但无法保证复合操作的原子性(如
i++、i = j + 1)。例如,两个线程同时执行i++时,可能因读取到相同的旧值导致结果错误。Synchronized 则通过排他锁保证同步块/方法内的所有操作是原子的——同一时刻只有一个线程执行同步代码,避免了并发修改的冲突。例如:// Synchronized 保证原子性 private int count = 0; public synchronized void increment() {count++; // 复合操作在同步方法内变为原子操作 }锁机制与性能的差异Volatile 是“无锁”机制,仅通过内存屏障确保可见性和禁止重排序,无需线程阻塞或唤醒,开销极低,适合高频读写的简单变量。Synchronized 是“有锁”机制,JDK 1.6 前依赖操作系统的互斥量(重量级锁),开销大;JDK 1.6 后引入锁升级(偏向锁→轻量级锁→重量级锁),大部分场景下性能接近 Volatile,但仍高于 Volatile 的内存屏障开销。
适用场景的差异Volatile 适合“读多写少”且操作简单的场景,如:
- 线程状态标记(如停止线程的
isRunning变量); - 单例模式的双重检查锁(防止指令重排序)。Synchronized 适合“读写频繁”或有复杂操作的场景,如:
- 计数器(
increment、decrement等复合操作); - 资源竞争(如多线程操作同一队列、集合)。
- 线程状态标记(如停止线程的
与线程调度的交互差异Volatile 不影响线程调度,线程执行时不会因 Volatile 变量而阻塞或等待。Synchronized 会影响线程调度:未获取锁的线程会被阻塞并放入等待队列,直到锁释放后被唤醒,可能导致上下文切换(保存/恢复线程状态),这是其开销高于 Volatile 的主要原因。
三、协同使用案例
Volatile 和 Synchronized 并非互斥,可协同使用以优化性能。例如,用 Volatile 修饰共享变量的状态,用 Synchronized 处理状态变更的复合操作:
public class协同Demo {private volatile boolean isReady = false; // 状态标记(Volatile保证可见)private int data;// 写线程:用Synchronized保证数据设置的原子性public synchronized void setData(int value) {data = value;isReady = true; // 状态变更,Volatile保证读线程可见}// 读线程:无需同步,直接读取Volatile变量public void process() {while (!isReady) {// 等待数据准备}System.out.println("数据:" + data); // 因isReady可见,data也可见(happen-before)}
}
此处 isReady 用 Volatile 保证可见性,setData 用 Synchronized 保证 data 赋值与 isReady 状态变更的原子性,既保证安全又减少同步开销。
面试关键点:原子性保证的差异(Volatile 无,Synchronized 有)、锁机制(无锁 vs 有锁)、适用场景(简单状态 vs 复杂操作),以及两者的协同使用;加分点:结合 JDK 版本说明 Synchronized 的性能优化(锁升级),或分析 happen-before 规则在两者中的体现;记忆法:采用“功能-场景”对比口诀——“Volatile 轻量无原子,管可见止重排,状态标记单例爱;Synchronized 重有原子,管同步保整体,复杂操作它来理”。
Synchronized 有几种用法?它锁的是什么(对象锁、类锁)?如何加锁才能使锁生效?其底层实现原理是什么(对象头 Mark Word、监视器锁、锁升级过程)?
Synchronized 是 Java 中最基础的同步机制,通过排他锁保证多线程对共享资源的有序访问。其用法、锁对象、生效条件及底层实现是理解并发安全的核心。
一、Synchronized 的三种用法
修饰实例方法锁对象为当前实例(
this),即多个线程访问同一实例的同步方法时会竞争同一把锁,访问不同实例的同步方法则无竞争。示例:public class SyncDemo {// 锁为当前SyncDemo实例(this)public synchronized void instanceMethod() {// 同步逻辑} }// 测试:同一实例竞争锁,不同实例不竞争 SyncDemo demo1 = new SyncDemo(); SyncDemo demo2 = new SyncDemo(); new Thread(demo1::instanceMethod).start(); // 线程1 new Thread(demo1::instanceMethod).start(); // 线程2(竞争锁) new Thread(demo2::instanceMethod).start(); // 线程3(不竞争)修饰静态方法锁对象为当前类的 Class 对象(如
SyncDemo.class),所有实例共享这把锁,无论访问哪个实例的静态同步方法,都会竞争同一把锁。示例:public class SyncDemo {// 锁为SyncDemo.classpublic static synchronized void staticMethod() {// 同步逻辑} }// 测试:所有实例共享类锁 SyncDemo demo1 = new SyncDemo(); SyncDemo demo2 = new SyncDemo(); new Thread(demo1::staticMethod).start(); // 线程1 new Thread(demo2::staticMethod).start(); // 线程2(竞争锁)修饰同步代码块锁对象为括号中指定的对象(可为实例对象、Class 对象或
this),灵活性最高,可缩小同步范围以减少锁竞争。示例:public class SyncDemo {private final Object lock = new Object(); // 自定义锁对象public void blockMethod() {// 锁为lock对象synchronized (lock) {// 同步逻辑}}public void thisBlockMethod() {// 锁为当前实例(this),等价于实例方法同步synchronized (this) {// 同步逻辑}}public void classBlockMethod() {// 锁为SyncDemo.class,等价于静态方法同步synchronized (SyncDemo.class) {// 同步逻辑}} }
二、锁的类型与生效条件
Synchronized 的锁分为对象锁和类锁:
- 对象锁:锁对象为实例对象(
this或自定义实例),控制同一实例的并发访问; - 类锁:锁对象为 Class 对象,控制所有实例对静态资源的并发访问。
锁生效的核心条件:多个线程必须竞争同一把锁。若线程持有的锁对象不同(如不同实例的对象锁、对象锁与类锁),则不会产生竞争,同步机制失效。例如:
- 线程 A 访问实例方法(对象锁
this),线程 B 访问静态方法(类锁X.class):无竞争,同步失效; - 线程 A 和线程 B 访问同一实例的同步方法:竞争同一对象锁,同步生效。
三、底层实现原理
对象头与 Mark WordJava 对象在内存中由“对象头”“实例数据”“对齐填充”组成,其中对象头的
Mark Word是 Synchronized 实现锁的关键——存储锁状态、持有锁的线程 ID 等信息。Mark Word的结构随锁状态变化(32位JVM示例):- 无锁状态:存储对象哈希码、分代年龄;
- 偏向锁:存储偏向线程 ID、偏向时间戳、分代年龄;
- 轻量级锁:存储指向线程栈中锁记录的指针;
- 重量级锁:存储指向监视器锁(monitor)的指针。
监视器锁(monitor)Synchronized 的底层依赖监视器锁(monitor),本质是依赖操作系统的互斥量(mutex)实现。
- 每个对象都关联一个 monitor(可理解为锁的持有者),线程进入同步块前需获取 monitor 的所有权(
monitorenter指令),退出时释放(monitorexit指令); - 若 monitor 已被其他线程持有,当前线程会进入阻塞状态,直到 monitor 被释放。
- 每个对象都关联一个 monitor(可理解为锁的持有者),线程进入同步块前需获取 monitor 的所有权(
锁升级过程(JDK 1.6 优化)为减少锁开销,JDK 1.6 引入锁升级机制,锁状态从低开销向高开销逐步升级(不可逆):
- 无锁:对象刚创建,未被任何线程锁定;
- 偏向锁:同一线程多次获取锁时,只需在
Mark Word记录线程 ID,无需竞争(适用于单线程场景); - 轻量级锁:多线程交替获取锁时,线程通过 CAS 尝试将
Mark Word替换为指向自身锁记录的指针,失败则自旋重试(避免阻塞,适用于短时间竞争); - 重量级锁:多线程激烈竞争,自旋失败后,线程阻塞并进入等待队列,依赖 OS 调度(适用于长时间竞争)。
面试关键点:Synchronized 的三种用法及对应的锁对象(实例/Class/自定义对象),锁生效的条件(竞争同一把锁),底层的 Mark Word、monitor 及锁升级过程;加分点:解释偏向锁的撤销条件(其他线程竞争时)、轻量级锁的自旋次数(JVM 自适应),或 synchronized 与 ReentrantLock 的性能对比;记忆法:采用“用法-锁对象-升级”口诀——“同步方法锁实例(静态锁类),代码块锁指定;同一锁才生效,升级无偏轻到重”。
Java 中有哪些锁(如偏向锁、轻量级锁、重量级锁、可重入锁、公平锁、非公平锁)?
Java 中的锁根据实现机制、功能特性和适用场景可分为多种类型,每种锁有其独特的设计目标和使用方式。理解这些锁的分类与特性,有助于在并发场景中选择合适的同步方案。
一、按锁状态升级划分(基于 Synchronized)
偏向锁
- 定义:当一个线程多次获取同一把锁时,锁会“偏向”该线程,无需每次竞争,只需在对象头 Mark Word 中记录线程 ID。
- 特点:开销极低(仅首次获取时需 CAS 操作),适用于单线程重复获取锁的场景(如单线程操作集合)。
- 升级条件:当其他线程尝试获取锁时,偏向锁会撤销并升级为轻量级锁。
轻量级锁
- 定义:多线程交替获取锁时,线程通过 CAS 操作将对象头 Mark Word 替换为指向自身栈帧中“锁记录”的指针,失败则自旋重试。
- 特点:无阻塞开销(自旋消耗 CPU),适用于短时间、低竞争场景(如简单计数器)。
- 升级条件:自旋次数超过阈值(JVM 自适应调整)或多线程同时竞争,升级为重量级锁。
重量级锁
- 定义:依赖操作系统的互斥量(mutex)实现,未获取锁的线程会被阻塞并放入等待队列,由 OS 调度唤醒。
- 特点:开销高(上下文切换),适用于长时间、高竞争场景(如复杂业务逻辑同步)。
二、按锁的可重入性划分
可重入锁
- 定义:线程获取锁后,可再次获取同一把锁而不被阻塞(锁计数器递增,释放时递减至0才真正释放)。
- 实现:Synchronized 和 ReentrantLock 均为可重入锁。
- 作用:避免嵌套同步导致的死锁,例如:
public synchronized void methodA() {methodB(); // 同一线程调用同步方法B,可重入不阻塞 } public synchronized void methodB() {// 逻辑 }
不可重入锁
- 定义:线程获取锁后,再次获取同一把锁会被阻塞(无计数器机制)。
- 特点:实现简单,但易导致死锁,Java 标准库中无默认实现,需自定义(如早期的自旋锁)。
三、按锁的公平性划分
公平锁
- 定义:线程获取锁的顺序与请求顺序一致(FIFO),先请求的线程先获取锁。
- 实现:ReentrantLock 可通过构造器
new ReentrantLock(true)创建公平锁。 - 特点:避免线程饥饿,但性能较低(需维护等待队列),适用于对公平性要求高的场景(如资源调度)。
非公平锁
- 定义:线程获取锁的顺序与请求顺序无关,新请求的线程可能“插队”获取锁(刚释放的锁可能被新线程获取,而非等待最久的线程)。
- 实现:Synchronized 默认为非公平锁,ReentrantLock 默认为非公平锁(
new ReentrantLock(false))。 - 特点:性能高(减少线程切换),但可能导致部分线程长期等待,适用于对性能要求高的场景。
四、其他常见锁类型
乐观锁
- 定义:假设并发操作不会冲突,仅在提交时通过版本号或 CAS 验证是否有冲突,冲突则重试。
- 实现:Atomic 原子类(CAS)、数据库乐观锁(版本字段)。
- 特点:无锁阻塞,适用于读多写少场景(如缓存更新)。
悲观锁
- 定义:假设并发操作必然冲突,获取资源时先加锁,阻止其他线程访问。
- 实现:Synchronized、ReentrantLock、数据库行锁。
- 特点:安全性高,但性能较低,适用于写多读少场景(如库存扣减)。
自旋锁
- 定义:线程获取锁失败时,不立即阻塞,而是循环重试(自旋),直到获取锁或自旋结束。
- 实现:轻量级锁的自旋逻辑、Unsafe 类的 CAS 操作。
- 特点:减少上下文切换,适用于锁持有时间短的场景(如原子类操作)。
读写锁
- 定义:区分读操作和写操作,允许多个线程同时读,仅允许一个线程写(写时阻塞读写)。
- 实现:ReentrantReadWriteLock(读锁共享,写锁排他)。
- 特点:提升读多写少场景的并发效率(如缓存读写)。
面试关键点:各类锁的定义、实现(如 Synchronized 对应偏向/轻量/重量级锁)、特点及适用场景,可重入锁与公平锁的实际意义;加分点:分析不同锁的性能对比(如乐观锁 vs 悲观锁的适用场景),或读写锁的升降级规则(ReentrantReadWriteLock 不支持写锁降级为读锁);记忆法:采用“分类-核心特点”口诀——“状态升级偏轻量,重入避免死锁忙;公平非公平看顺序,乐观悲观读写分”。
什么是锁粗化?什么是锁消除?
在 Java 并发编程中,锁粗化和锁消除是 JVM 对 Synchronized 锁的两种重要优化手段,目的是在保证线程安全的前提下,减少锁操作的开销,提升程序性能。两者从不同维度优化锁的使用:锁粗化解决“细粒度锁频繁切换”的问题,锁消除解决“不必要锁存在”的问题。
一、锁粗化(Lock Coarsening)
定义锁粗化指 JVM 将多个连续的、细粒度的锁操作(如多次获取和释放同一把锁)合并成一个粗粒度的锁操作(一次获取锁,执行所有逻辑后再释放),减少锁的获取和释放次数,降低上下文切换开销。
核心场景当代码中存在“循环内多次同步”或“连续多次同步同一对象”时,细粒度锁会导致线程频繁获取和释放锁,每次锁操作都有内存屏障和线程调度的潜在开销。JVM 会自动检测这种场景,将锁范围扩大,覆盖所有连续的同步逻辑。
示例与优化效果未优化前(细粒度锁):
public void fineGrainedLock() {for (int i = 0; i < 1000; i++) {synchronized (this) { // 循环内多次获取/释放锁,开销大doSomething();}} }JVM 优化后(锁粗化):
public void coarseGrainedLock() {synchronized (this) { // 一次获取锁,覆盖整个循环for (int i = 0; i < 1000; i++) {doSomething();}} }优化前需执行 1000 次锁获取和释放,优化后仅需 1 次,大幅减少锁操作开销。
手动优化与 JVM 自动优化开发者也可手动进行锁粗化(如将锁移到循环外),但 JVM 会在运行时(尤其是 JIT 编译阶段)智能判断:若连续锁操作的间隔短、逻辑关联紧密,会自动合并;若间隔长或逻辑无关,则不合并(避免锁竞争加剧)。
二、锁消除(Lock Elimination)
定义锁消除指 JVM 在 JIT 编译阶段,检测到某些锁操作是“不必要的”(如锁保护的对象仅在当前线程可见,无并发访问可能),从而自动移除这些锁操作,完全消除锁开销。
核心场景最典型的场景是“局部对象的同步操作”:当同步的对象是方法内的局部变量,且该对象未被传递到其他线程(无逃逸),则不存在并发访问风险,此时的锁是多余的,JVM 会将其消除。
示例与优化效果未优化前(多余锁):
public void unnecessaryLock() {StringBuffer sb = new StringBuffer(); // 局部变量,无逃逸for (int i = 0; i < 100; i++) {sb.append(i); // StringBuffer 的 append 方法是同步的(Synchronized 修饰)}System.out.println(sb.toString()); }上述代码中,
StringBuffer是局部变量,仅在当前线程内使用,无其他线程访问,append方法的同步锁完全多余。JVM 优化后,会移除append方法的锁操作,等价于使用非同步的StringBuilder,性能大幅提升。实现原理锁消除依赖 JVM 的“逃逸分析”(Escape Analysis)技术:
- 逃逸分析判断对象是否“逃逸”(是否被传递到方法外或其他线程);
- 若对象无逃逸(仅线程内可见),则同步锁失去意义,JIT 编译时会移除锁相关指令(如
monitorenter、monitorexit)。
三、两种优化的核心价值与注意事项
| 优化类型 | 核心解决问题 | 优势 | 注意事项 |
|---|---|---|---|
| 锁粗化 | 细粒度锁导致的频繁锁切换 | 减少锁操作次数,降低调度开销 | 避免过度粗化(锁范围过大导致竞争加剧) |
| 锁消除 | 不必要锁导致的无意义开销 | 完全消除冗余锁,提升执行效率 | 依赖逃逸分析,需确保对象无逃逸 |
面试关键点:锁粗化的“合并连续锁”逻辑、锁消除的“逃逸分析+移除冗余锁”原理,结合 StringBuffer 局部使用的例子说明锁消除;加分点:提及 JIT 编译在优化中的作用,或手动优化与 JVM 自动优化的配合(如避免手动写细粒度锁,依赖 JVM 粗化);记忆法:采用“问题-方案”口诀——“锁粗化:多锁合并成一锁,减少切换开销少;锁消除:逃逸分析判无险,多余锁移除性能高”。
Synchronized 和 ReentrantLock 的区别是什么?
Synchronized 和 ReentrantLock 是 Java 中两种核心的同步机制,均能保证线程安全,但在实现层面、功能特性和使用场景上有显著差异。ReentrantLock 作为 JDK 1.5 引入的 API 级锁,弥补了 Synchronized 的部分功能缺陷,提供更灵活的同步控制。
一、核心区别对比
| 对比维度 | Synchronized | ReentrantLock |
|---|---|---|
| 锁实现层面 | JVM 层面(底层依赖对象头 Mark Word 和监视器锁) | JDK API 层面(基于 AQS 框架实现) |
| 可重入性 | 支持(隐式,JVM 自动维护锁计数器) | 支持(显式,通过 AQS 的 state 变量计数) |
| 公平性 | 仅支持非公平锁(默认,无法配置) | 支持公平锁和非公平锁(构造器参数指定) |
| 锁释放机制 | 自动释放(同步块/方法执行完或抛异常时) | 手动释放(必须在 finally 中调用 unlock(),否则死锁) |
| 中断支持 | 不支持(线程获取锁时无法被中断,只能死等) | 支持(lockInterruptibly() 方法,可中断等待锁的线程) |
| 条件变量(Condition) | 不支持(仅依赖 Object 的 wait/notify,全量唤醒) | 支持(newCondition() 创建多个 Condition,可精准唤醒指定线程) |
| 锁状态查询 | 不支持(无法判断线程是否持有锁) | 支持(isHeldByCurrentThread()、getHoldCount() 等方法) |
| 性能(JDK 1.6+) | 与 ReentrantLock 接近(JVM 优化后,偏向锁/轻量级锁开销低) | 略高(API 调用开销,但功能更灵活) |
| 使用复杂度 | 简单(无需手动管理锁释放,不易出错) | 复杂(需手动释放,遗漏会导致死锁) |
二、详细差异解析
锁实现与释放机制
- Synchronized 是 JVM 原生支持的锁,无需手动释放:同步块执行完毕或抛出异常时,JVM 会自动释放锁,避免开发者遗漏导致的死锁风险;
- ReentrantLock 是 API 级锁,依赖
lock()获取锁、unlock()释放锁,且unlock()必须在finally中调用(否则线程异常退出时锁无法释放,导致其他线程永久阻塞)。示例:// ReentrantLock 必须手动释放锁 ReentrantLock lock = new ReentrantLock(); try {lock.lock(); // 获取锁// 同步逻辑 } finally {lock.unlock(); // 确保释放锁 }
公平性与中断支持
- Synchronized 仅支持非公平锁:新线程可能“插队”获取刚释放的锁,导致等待久的线程饥饿,但性能较高;
- ReentrantLock 可通过
new ReentrantLock(true)创建公平锁,按线程请求顺序分配锁,避免饥饿;同时支持中断(lockInterruptibly()),例如:// 中断等待锁的线程 Thread t1 = new Thread(() -> {try {lock.lockInterruptibly(); // 可被中断} catch (InterruptedException e) {System.out.println("线程被中断,放弃获取锁");return;}try { /* 逻辑 */ } finally { lock.unlock(); } }); t1.start(); t1.interrupt(); // 中断线程 t1 的锁等待
条件变量(Condition)
- Synchronized 仅能通过
Object.wait()/notify()唤醒线程,notify()会唤醒所有等待线程,无法精准控制,可能导致“惊群效应”; - ReentrantLock 的 Condition 可创建多个等待队列,实现精准唤醒。例如生产者-消费者模型中,分别唤醒生产者和消费者:
ReentrantLock lock = new ReentrantLock(); Condition producerCond = lock.newCondition(); // 生产者条件 Condition consumerCond = lock.newCondition(); // 消费者条件// 消费者等待 consumerCond.await(); // 生产者唤醒消费者 consumerCond.signal();
- Synchronized 仅能通过
三、适用场景选择
- 优先选 Synchronized:简单同步场景(如单例、计数器),无需复杂功能,追求代码简洁性,避免手动释放锁的风险;
- 优先选 ReentrantLock:需要公平锁、中断支持、精准唤醒(Condition)或锁状态查询的场景(如复杂的并发控制、自定义同步工具)。
面试关键点:锁实现层面、公平性、中断支持、Condition 的差异,结合示例说明 ReentrantLock 的灵活用法;加分点:提及 ReentrantLock 的可扩展性(如基于 AQS 自定义同步逻辑),或 JDK 1.6 后 Synchronized 的优化(偏向锁、轻量级锁)对性能的影响;记忆法:采用“特性-场景”口诀——“Sync 自动 JVM 管,简单场景不用管;Reentrant 手动 API,公平中断 Condition,复杂场景它来担”。
ReentrantLock 的实现原理是什么?如何实现一个可重入锁?
ReentrantLock 是 Java 中基于 AQS(AbstractQueuedSynchronizer,抽象队列同步器)实现的可重入独占锁,其核心是通过 AQS 的状态变量(state)管理锁的持有与释放,通过 CLH 队列(双向链表)管理阻塞线程,确保线程安全与可重入性。
一、ReentrantLock 的实现原理
ReentrantLock 的实现完全依赖 AQS 框架,AQS 是 JUC 包中同步工具的基础,提供“状态管理”和“线程排队”两大核心能力。
AQS 的核心组件
- 状态变量(state):int 类型,用于记录锁的持有状态。对于 ReentrantLock:
- state = 0:锁未被持有;
- state > 0:锁已被持有,state 的值等于“当前线程重入的次数”(可重入性的关键)。
- CLH 队列:双向链表结构,用于存储等待获取锁的线程。每个节点代表一个等待线程,包含“前驱节点”“后继节点”“等待状态”等信息,实现线程的有序排队与唤醒。
- 独占线程(exclusiveOwnerThread):AQS 的父类 AbstractOwnableSynchronizer 中的变量,记录当前持有独占锁的线程(判断可重入的关键)。
- 状态变量(state):int 类型,用于记录锁的持有状态。对于 ReentrantLock:
锁的获取流程(
lock()方法)ReentrantLock 分为公平锁和非公平锁,核心逻辑在tryAcquire(int arg)方法(AQS 的模板方法,由 ReentrantLock 实现):- 步骤1:判断 state 是否为 0(锁未被持有):
- 非公平锁:直接通过 CAS 尝试将 state 从 0 改为 1,成功则将 exclusiveOwnerThread 设为当前线程,获取锁;
- 公平锁:先判断 CLH 队列是否有前驱线程,若无再 CAS 修改 state(确保按请求顺序获取)。
- 步骤2:若 state > 0(锁已被持有):
- 判断当前线程是否为 exclusiveOwnerThread(持有锁的线程):若是,将 state 加 1(重入),获取锁;若不是,当前线程进入 CLH 队列阻塞。
- 步骤1:判断 state 是否为 0(锁未被持有):
锁的释放流程(
unlock()方法)核心逻辑在tryRelease(int arg)方法:- 步骤1:将 state 减 1(每次释放对应一次重入);
- 步骤2:判断 state 是否为 0:
- 若是,将 exclusiveOwnerThread 设为 null(释放锁),并唤醒 CLH 队列的首节点线程;
- 若不是,仅释放一次重入,锁仍被当前线程持有。
二、手动实现一个可重入锁
基于 AQS 框架实现可重入锁(简化版),需重写 AQS 的 tryAcquire 和 tryRelease 方法,实现可重入逻辑:
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Lock;// 自定义可重入锁
public class MyReentrantLock implements Lock {// 基于 AQS 实现同步逻辑private final Sync sync = new Sync();// AQS 子类,实现独占锁逻辑private static class Sync extends AbstractQueuedSynchronizer {// 尝试获取锁(arg=1,每次获取加1)@Overrideprotected boolean tryAcquire(int arg) {// 1. 获取当前线程Thread current = Thread.currentThread();// 2. 获取当前状态int c = getState();if (c == 0) { // 锁未被持有// CAS 尝试将 state 从 0 改为 1if (compareAndSetState(0, arg)) {setExclusiveOwnerThread(current); // 标记当前线程为持有者return true;}} else if (current == getExclusiveOwnerThread()) { // 锁已被当前线程持有(重入)int nextc = c + arg; // 重入次数加1if (nextc < 0) { // 防止溢出(理论上不会发生)throw new Error("Maximum lock count exceeded");}setState(nextc); // 无需 CAS,当前线程已持有锁,线程安全return true;}// 锁被其他线程持有,获取失败return false;}// 尝试释放锁(arg=1,每次释放减1)@Overrideprotected boolean tryRelease(int arg) {// 1. 释放前必须持有锁if (Thread.currentThread() != getExclusiveOwnerThread()) {throw new IllegalMonitorStateException();}int c = getState() - arg; // 重入次数减1boolean free = false;if (c == 0) { // 完全释放锁(重入次数为0)free = true;setExclusiveOwnerThread(null); // 清空持有者}setState(c); // 更新状态return free; // 返回是否完全释放}// 判断当前线程是否持有锁protected boolean isHeldExclusively() {return getExclusiveOwnerThread() == Thread.currentThread();}}// 实现 Lock 接口方法@Overridepublic void lock() {sync.acquire(1); // 调用 AQS 的 acquire 方法,触发 tryAcquire}@Overridepublic void unlock() {sync.release(1); // 调用 AQS 的 release 方法,触发 tryRelease}// 其他 Lock 方法(略,按需实现)@Override public void lockInterruptibly() throws InterruptedException { sync.acquireInterruptibly(1); }@Override public boolean tryLock() { return sync.tryAcquire(1); }@Override public boolean tryLock(long time, TimeUnit unit) throws InterruptedException { return sync.tryAcquireNanos(1, unit.toNanos(time)); }@Override public Condition newCondition() { return null; }
}
实现关键点:
tryAcquire中判断“锁未持有则 CAS 获取”“锁已被当前线程持有则重入”;tryRelease中减少 state,仅当 state 为 0 时完全释放锁;- 依赖 AQS 的
compareAndSetState保证原子性,setExclusiveOwnerThread标记持有者。
面试关键点:ReentrantLock 基于 AQS 的实现(state 管理重入、CLH 队列管理阻塞),手动实现可重入锁的核心逻辑(tryAcquire/tryRelease);加分点:解释 AQS 的模板方法模式(acquire/release 是模板,tryAcquire/tryRelease 是钩子),或 ReentrantLock 公平锁与非公平锁的 tryAcquire 差异;记忆法:采用“核心组件-流程”口诀——“Reentrant 靠 AQS,state 计数重入次;获取锁:CAS 改 state,重入加次不竞争;释放锁:减次到 0 才释放,CLH 队列唤醒线程”。
ThreadLocal 的作用是什么?它的底层实现原理是什么?使用时需要注意什么(如内存泄漏问题)?
ThreadLocal 是 Java 中用于实现“线程私有变量”的工具类,其核心作用是为每个线程创建独立的变量副本,避免多线程共享变量导致的并发安全问题。它在实际开发中广泛用于存储线程上下文信息(如用户会话、数据库连接),但需注意内存泄漏风险。
一、ThreadLocal 的作用
ThreadLocal 的核心价值是“线程隔离”,即每个线程访问 ThreadLocal 变量时,操作的是自己的专属副本,而非共享变量。具体作用场景包括:
存储线程上下文信息例如 Web 开发中,将用户登录信息(如 User 对象)存入 ThreadLocal,在整个请求处理链路(Controller、Service、DAO)中,无需通过参数传递即可直接获取,简化代码逻辑:
public class UserContext {// 定义 ThreadLocal 变量,存储 User 副本private static final ThreadLocal<User> USER_THREAD_LOCAL = new ThreadLocal<>();// 存入用户信息public static void setUser(User user) {USER_THREAD_LOCAL.set(user);}// 获取当前线程的用户信息public static User getUser() {return USER_THREAD_LOCAL.get();}// 清理用户信息(关键,避免内存泄漏)public static void removeUser() {USER_THREAD_LOCAL.remove();} }// Controller 中存入 @GetMapping("/login") public void login(User user) {UserContext.setUser(user);userService.process(); // 调用 Service }// Service 中获取 @Service public class UserService {public void process() {User currentUser = UserContext.getUser(); // 直接获取,无需参数传递// 业务逻辑} }避免共享变量并发问题例如多线程操作 SimpleDateFormat(非线程安全)时,每个线程通过 ThreadLocal 持有自己的 SimpleDateFormat 副本,避免并发格式化错误:
public class DateFormatUtil {private static final ThreadLocal<SimpleDateFormat> DATE_FORMAT = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd"));public static String format(Date date) {return DATE_FORMAT.get().format(date); // 每个线程使用自己的副本} }
二、ThreadLocal 的底层实现原理
ThreadLocal 的底层实现依赖 Thread 类的 ThreadLocalMap 成员变量,核心结构可概括为“Thread → ThreadLocalMap → Entry → 变量副本”:
核心数据结构
- Thread 类:每个 Thread 实例内部维护一个
ThreadLocalMap类型的变量threadLocals(初始为 null),用于存储该线程的所有 ThreadLocal 变量副本; - ThreadLocalMap:ThreadLocal 的静态内部类,本质是一个自定义哈希表(类似 HashMap),用于存储 ThreadLocal 与变量副本的映射关系。其 key 是 ThreadLocal 实例,value 是线程私有变量副本;
- Entry 类:ThreadLocalMap 的静态内部类,继承自
WeakReference<ThreadLocal<?>>,即 key(ThreadLocal 实例)是弱引用,value 是强引用。弱引用的设计是为了在 ThreadLocal 实例不再被使用时,能被 GC 回收。
- Thread 类:每个 Thread 实例内部维护一个
核心方法实现
set(T value)方法:- 获取当前线程的 ThreadLocalMap;
- 若 Map 不存在,创建新的 ThreadLocalMap 并绑定到当前线程;
- 若 Map 存在,以当前 ThreadLocal 为 key,存入 value(覆盖已有值);
get()方法:- 获取当前线程的 ThreadLocalMap;
- 若 Map 存在且包含当前 ThreadLocal 的 Entry,返回 value;
- 若 Map 不存在或无 Entry,调用
initialValue()初始化 value(默认返回 null,可通过ThreadLocal.withInitial()自定义),并存入 Map;
remove()方法:- 获取当前线程的 ThreadLocalMap;
- 若 Map 存在,删除当前 ThreadLocal 对应的 Entry,释放 value 引用。
三、使用时的注意事项(内存泄漏问题)
ThreadLocal 的内存泄漏是最核心的风险,其根源是“Entry 的 key 是弱引用,value 是强引用”:
内存泄漏的原因
- 当 ThreadLocal 实例不再被外部强引用(如
threadLocal = null),GC 会回收 key(弱引用),但 value 仍被 Entry 强引用,且 Entry 被 ThreadLocalMap 引用,ThreadLocalMap 被 Thread 引用; - 若 Thread 未结束(如线程池中的核心线程),value 会一直被强引用,无法被 GC 回收,最终导致内存泄漏。
- 当 ThreadLocal 实例不再被外部强引用(如
避免内存泄漏的解决方案
- 必须在 finally 中调用
remove()方法:无论业务逻辑是否正常执行,都要在使用完 ThreadLocal 后清理 value,切断强引用链。例如 Web 开发中,在拦截器的afterCompletion方法中调用remove():public class UserInterceptor implements HandlerInterceptor {@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) {UserContext.removeUser(); // 确保清理,避免内存泄漏} } - 避免使用 ThreadLocal 存储大对象:若大对象未被及时 remove,内存泄漏的影响会更严重;
- 线程池场景需特别注意:线程池中的线程会复用,若前一个任务未清理 ThreadLocal,后一个任务可能获取到脏数据,同时导致内存泄漏。
- 必须在 finally 中调用
面试关键点:ThreadLocal 的线程隔离作用,底层的 Thread → ThreadLocalMap → Entry 结构,内存泄漏的原因与 remove() 的必要性;加分点:解释弱引用 key 的设计目的(避免 ThreadLocal 实例无法被回收),或 ThreadLocalMap 的哈希冲突解决方式(线性探测,而非链表);记忆法:采用“结构-风险-方案”口诀——“ThreadLocal 线程私,Thread 里面 Map 存;key 弱引用怕漏 value,finally remove 要记准”。
你用过哪些线程池?newFixedThreadPool的工作队列使用的是什么(LinkedBlockingQueue)?线程池中的线程用完后如何回收?
在实际项目中,线程池的选择需结合业务的并发量、任务类型(CPU 密集/IO 密集)和资源限制,常用的线程池包括 JDK 预定义的线程池和自定义 ThreadPoolExecutor。newFixedThreadPool 作为预定义线程池的典型代表,其工作队列和线程回收机制有明确的设计逻辑。
一、项目中常用的线程池
newFixedThreadPool(固定大小线程池)
- 核心特性:核心线程数 = 最大线程数(参数指定,如 10),无超时时间(核心线程默认不回收),工作队列是无界的 LinkedBlockingQueue;
- 适用场景:任务数量稳定、执行时间较长的 IO 密集型任务(如数据库查询、HTTP 调用),例如订单处理、消息推送。
- 风险点:无界队列可能导致任务堆积,最终引发 OOM(内存溢出),需谨慎使用。
newCachedThreadPool(缓存线程池)
- 核心特性:核心线程数 = 0,最大线程数 = Integer.MAX_VALUE,非核心线程空闲超时时间 = 60 秒,工作队列是 SynchronousQueue(无缓冲,直接传递任务);
- 适用场景:任务数量波动大、执行时间短的轻量级任务(如临时数据处理、日志收集),例如用户行为日志异步写入。
- 风险点:最大线程数无界,高并发下可能创建过多线程,导致 CPU 占用率飙升或 OOM。
newSingleThreadExecutor(单线程池)
- 核心特性:核心线程数 = 最大线程数 = 1,无超时时间,工作队列是 LinkedBlockingQueue;
- 适用场景:需保证任务顺序执行的场景(如数据库表数据同步、单线程消费消息队列),例如按顺序处理用户的充值记录。
ThreadPoolExecutor(自定义线程池)
- 核心特性:可灵活配置核心线程数、最大线程数、超时时间、工作队列和拒绝策略,是生产环境的首选(避免预定义线程池的无界风险);
- 配置示例(IO 密集型任务,核心线程数 = CPU 核心数 × 2,最大线程数 = CPU 核心数 × 4):
// CPU 核心数 int cpuCore = Runtime.getRuntime().availableProcessors(); // 自定义线程池 ThreadPoolExecutor executor = new ThreadPoolExecutor(cpuCore * 2, // 核心线程数cpuCore * 4, // 最大线程数60, // 非核心线程空闲超时时间TimeUnit.SECONDS,new ArrayBlockingQueue<>(100), // 有界队列,避免OOMnew ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略:调用者执行 ); - 适用场景:几乎所有生产环境场景,尤其是对资源控制要求高的高并发业务(如秒杀、电商下单)。
二、newFixedThreadPool 的工作队列
newFixedThreadPool 的工作队列是 LinkedBlockingQueue(无界阻塞队列,默认容量为 Integer.MAX_VALUE),其核心特性:
- 无界特性:队列可无限存储任务,无需担心队列满导致的任务拒绝,但风险是任务堆积过多时会占用大量内存,最终引发 OOM;
- 阻塞特性:当线程池中的线程都在忙碌时,新任务会进入队列阻塞等待,直到有线程空闲;
- 源码验证:newFixedThreadPool 的实现如下,明确使用 LinkedBlockingQueue:
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()); // 无界队列 }
三、线程池中的线程回收机制
线程池的线程回收主要依赖“核心线程与非核心线程的区分”和“空闲超时时间(keepAliveTime)”,具体逻辑如下:
核心线程与非核心线程的区别
- 核心线程:线程池的常驻线程,默认情况下(
allowCoreThreadTimeOut = false),即使空闲也不会被回收,始终保持存活,等待新任务; - 非核心线程:线程池在核心线程不够用、队列满时创建的临时线程,空闲时间超过
keepAliveTime后会被回收。
- 核心线程:线程池的常驻线程,默认情况下(
线程回收的触发条件
- 非核心线程回收:当非核心线程执行完任务后,会从工作队列中获取新任务;若队列无任务,线程会进入空闲状态,空闲时间达到
keepAliveTime时,线程会被销毁(通过中断线程的park状态实现); - 核心线程回收:默认不回收,但若通过
executor.allowCoreThreadTimeOut(true)开启核心线程超时回收,核心线程空闲超过keepAliveTime后也会被回收; - 线程池关闭时的回收:调用
executor.shutdown()后,线程池不再接收新任务,待所有任务执行完后,所有线程会被回收;调用executor.shutdownNow()会立即中断所有线程并回收。
- 非核心线程回收:当非核心线程执行完任务后,会从工作队列中获取新任务;若队列无任务,线程会进入空闲状态,空闲时间达到
回收流程细节线程池中的每个线程(Worker 类实例)在执行完任务后,会进入循环获取任务的逻辑:
// Worker 类的 run 方法核心逻辑(简化) while (task != null || (task = getTask()) != null) {try {task.run(); // 执行任务} finally {task = null;} } // 若 getTask() 返回 null,线程退出循环,被回收其中
getTask()方法会判断线程是否为核心线程、是否超时:若为非核心线程且空闲超时,getTask()返回 null,线程退出并被回收。
面试关键点:常用线程池的特性与适用场景,newFixedThreadPool 的 LinkedBlockingQueue 特性,线程回收的核心条件(核心线程开关、非核心线程超时);加分点:分析 newFixedThreadPool 的 OOM 风险及解决方案(改用有界队列的自定义线程池),或线程池的 Worker 类实现细节;记忆法:采用“线程池-队列-回收”口诀——“Fixed 池用 LinkedQueue,核心线程默认不回收;非核心超时就销毁,allowCore设true全回收;自定义池最安全,有界队列控资源”。
线程池有哪些核心参数(核心线程数、最大线程数、空闲线程存活时间、工作队列、拒绝策略)?
线程池的核心参数决定了其并发能力、资源占用和任务处理策略,Java 中 ThreadPoolExecutor 的构造函数明确定义了 5 个核心参数,所有线程池(包括预定义的 newFixedThreadPool、newCachedThreadPool)均基于这些参数配置。理解每个参数的作用是合理设计线程池的关键。
一、五大核心参数的定义与作用
核心线程数(corePoolSize)
- 定义:线程池长期维持的最小线程数量,即使线程空闲也不会被回收(默认情况下,可通过
allowCoreThreadTimeOut(true)开启核心线程超时回收)。 - 作用:保证线程池有足够的线程处理日常任务,避免频繁创建 / 销毁线程的开销。
- 配置建议:
- CPU 密集型任务(如数据计算、排序):核心线程数 = CPU 核心数 + 1(减少线程切换,充分利用 CPU);
- IO 密集型任务(如数据库查询、HTTP 调用):核心线程数 = CPU 核心数 × 2(IO 等待时线程可空闲,多线程提高吞吐量)。
- 示例:CPU 核心数为 8 时,CPU 密集型设为 9,IO 密集型设为 16。
- 定义:线程池长期维持的最小线程数量,即使线程空闲也不会被回收(默认情况下,可通过
最大线程数(maximumPoolSize)
- 定义:线程池允许创建的最大线程数量,当核心线程满且工作队列满时,会创建非核心线程(数量 = 最大线程数 - 核心线程数)。
- 作用:控制线程池的最大并发能力,避免线程过多导致的 CPU 上下文切换和内存占用过高。
- 配置建议:需结合工作队列容量,确保 “最大线程数 + 队列容量” 能应对峰值任务量。IO 密集型任务可适当增大(如 CPU 核心数 × 4),CPU 密集型任务不宜过大(避免切换开销)。
空闲线程存活时间(keepAliveTime)与时间单位(TimeUnit)
- 定义:非核心线程空闲后,保持存活的最长时间;超过该时间,非核心线程会被销毁(释放资源)。
- 作用:平衡资源占用与响应速度 —— 空闲时回收冗余线程,避免内存浪费;有新任务时无需重新创建线程,快速响应。
- 配置建议:IO 密集型任务可设较长时间(如 60 秒,线程空闲时可能很快有新任务);短期轻量任务可设较短时间(如 10 秒,快速回收冗余线程)。
工作队列(BlockingQueue<Runnable>)
- 定义:用于存储待执行任务的阻塞队列,核心线程满时,新任务会先进入队列等待,而非直接创建非核心线程。
- 作用:缓冲任务,减少非核心线程的创建频率,同时避免任务丢失(队列满前)。
- 常见队列类型:
队列类型 特点 适用场景 ArrayBlockingQueue 有界,固定容量,FIFO 生产环境首选,避免任务堆积 OOM LinkedBlockingQueue 可选无界(默认)/ 有界,FIFO 预定义线程池(如 newFixedThreadPool),风险是无界队列 OOM SynchronousQueue 无缓冲,直接传递任务 newCachedThreadPool,适合短期任务 PriorityBlockingQueue 无界,按优先级排序 需按任务优先级执行的场景
拒绝策略(RejectedExecutionHandler)
- 定义:当线程池(核心线程满 + 队列满 + 非核心线程满)无法接收新任务时,触发的任务处理策略。
- 常见拒绝策略:
策略类型 行为 适用场景 AbortPolicy 抛 RejectedExecutionException 核心业务,任务不可丢失,需感知异常 CallerRunsPolicy 由提交任务的线程(如主线程)执行 非核心业务,允许任务延迟执行 DiscardPolicy 默默丢弃任务,无异常 不重要任务(如日志),可容忍丢失 DiscardOldestPolicy 丢弃队列最旧任务,加入新任务 新任务比旧任务优先级高的场景 自定义策略 自定义处理(如持久化任务到 DB) 任务不可丢失,需重试的场景
二、核心参数的协同工作示例
通过自定义 ThreadPoolExecutor 展示参数协同:
// CPU 核心数(假设为8)
int cpuCore = Runtime.getRuntime().availableProcessors();// 自定义线程池(IO 密集型任务配置)
ThreadPoolExecutor executor = new ThreadPoolExecutor(cpuCore * 2, // 核心线程数:16cpuCore * 4, // 最大线程数:3260, // 空闲存活时间:60秒TimeUnit.SECONDS,new ArrayBlockingQueue<>(1000), // 有界队列:容量1000new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略:调用者执行
);
- 当任务量较少时:16 个核心线程处理任务,队列空;
- 任务量增加:核心线程满,任务进入队列(最多存 1000 个);
- 任务量激增:队列满,创建非核心线程(最多 32 个);
- 任务量超 32 + 1000:触发拒绝策略,由提交任务的线程执行,避免任务丢失。
面试关键点:五大参数的定义、作用及配置依据(CPU/IO 密集型区别),工作队列与拒绝策略的类型,参数间的协同逻辑;加分点:结合业务场景给出具体配置示例(如秒杀系统的线程池配置),解释预定义线程池(如 newFixedThreadPool)的参数缺陷(无界队列);记忆法:采用 “参数 - 作用” 口诀 ——“核线保基础,最大控上限;空闲定回收,队列缓任务;拒绝处理满,配置看业务(CPU/IO)”。
一个用户向线程池请求线程后,线程池的处理过程是什么?如果使用无限队列(如 LinkedBlockingQueue)会出现什么问题?
线程池处理任务的过程遵循严格的优先级逻辑,核心是 “优先复用核心线程→缓冲队列→创建非核心线程→拒绝任务”,而无限队列的使用会打破这一逻辑,引发严重的资源风险。
一、线程池处理任务的完整流程
当用户通过 execute(Runnable task) 或 submit(Runnable task) 提交任务后,线程池按以下步骤处理:
判断核心线程池是否有空闲线程
- 若核心线程池中有空闲线程(未达到
corePoolSize或有核心线程空闲),直接分配一个核心线程执行任务; - 若核心线程池已满(所有核心线程均在执行任务),进入下一步。
- 若核心线程池中有空闲线程(未达到
判断工作队列是否已满
- 若工作队列未满(任务数 < 队列容量),将任务存入队列,等待核心线程空闲后从队列中获取任务执行;
- 若工作队列已满(任务数达到队列容量),进入下一步。
判断是否能创建非核心线程
- 若当前线程数 <
maximumPoolSize(未达到最大线程数),创建一个非核心线程执行任务; - 若当前线程数已达到
maximumPoolSize(核心 + 非核心线程满),进入下一步。
- 若当前线程数 <
触发拒绝策略线程池无法接收新任务,按预设的
RejectedExecutionHandler处理任务(如抛异常、丢弃任务、调用者执行)。
流程示例:以 corePoolSize=2、maximumPoolSize=4、队列容量=3 为例:
- 提交 2 个任务:核心线程 1、2 分别执行,队列空;
- 提交第 3~5 个任务:核心线程满,任务 3、4、5 存入队列;
- 提交第 6~7 个任务:队列满,创建非核心线程 3、4 执行,线程总数 4;
- 提交第 8 个任务:线程满 + 队列满,触发拒绝策略。
二、使用无限队列(如 LinkedBlockingQueue)的问题
LinkedBlockingQueue 是默认无界的队列(容量为 Integer.MAX_VALUE,约 21 亿),看似能无限缓冲任务,实则会引发致命问题:
任务堆积导致 OOM(内存溢出)无限队列没有容量限制,当任务提交速度远大于线程处理速度时(如每秒提交 1000 个任务,线程每秒仅处理 100 个),任务会持续堆积在队列中。每个任务(
Runnable)占用内存,堆积到一定数量后,JVM 堆内存耗尽,抛出OutOfMemoryError,导致应用崩溃。- 示例:电商秒杀场景中,瞬间提交 100 万订单任务,线程池每秒仅处理 1 万,队列快速堆积 99 万任务,每个任务占 1KB 内存,仅队列就占用 99MB,若持续提交,内存很快溢出。
非核心线程永远不会被创建线程池创建非核心线程的前提是 “工作队列满”,而无限队列永远不会满,导致
maximumPoolSize参数失效 —— 即使配置了最大线程数,也只会使用核心线程处理任务,非核心线程始终为 0。这会导致线程池的并发能力无法提升,任务处理速度始终受限于核心线程数,严重影响吞吐量。系统资源耗尽,响应缓慢任务堆积不仅占用堆内存,还可能引发连锁反应:
- 若任务涉及数据库连接、网络请求等资源,未执行的任务会持有资源(如数据库连接池耗尽),导致其他业务无法获取资源;
- JVM 频繁进行 GC(回收无用对象),GC 时间过长,导致应用响应时间延长,甚至出现 “STW(Stop The World)”,影响用户体验。
三、解决方案:使用有界队列
避免无限队列风险的核心是使用 有界队列(如 ArrayBlockingQueue),并合理配置队列容量:
- 队列容量需结合 “最大线程数” 和 “业务处理能力” 设计,确保 “最大线程数 + 队列容量” 能应对峰值任务量,同时避免内存溢出;
- 示例:
corePoolSize=16、maximumPoolSize=32、队列容量=1000,可处理的峰值任务量为 32 + 1000 = 1032,若超过则触发拒绝策略(如CallerRunsPolicy减缓提交速度)。
面试关键点:线程池处理任务的四步流程(核心线程→队列→非核心线程→拒绝),无限队列的 OOM 风险和参数失效问题,有界队列的解决方案;加分点:结合监控工具(如 JConsole)说明如何观察任务堆积,或给出具体的队列容量计算公式(如 “队列容量 = 峰值 QPS × 平均处理时间 - 核心线程数 × 平均处理时间”);记忆法:采用 “流程 - 风险” 口诀 ——“任务来了先找核(核心线程),核满入队等机会;队满再开非核心,全满拒绝不崩溃;无限队列是大坑,任务堆积 OOM 崩”。
什么是死锁?产生死锁的四个必要条件是什么?如何避免和解决死锁?
死锁是多线程并发中的致命问题,指两个或多个线程互相持有对方所需的资源,且均不释放,导致所有线程永久阻塞,无法继续执行。理解死锁的产生条件与解决方案,是保证并发程序稳定性的核心。
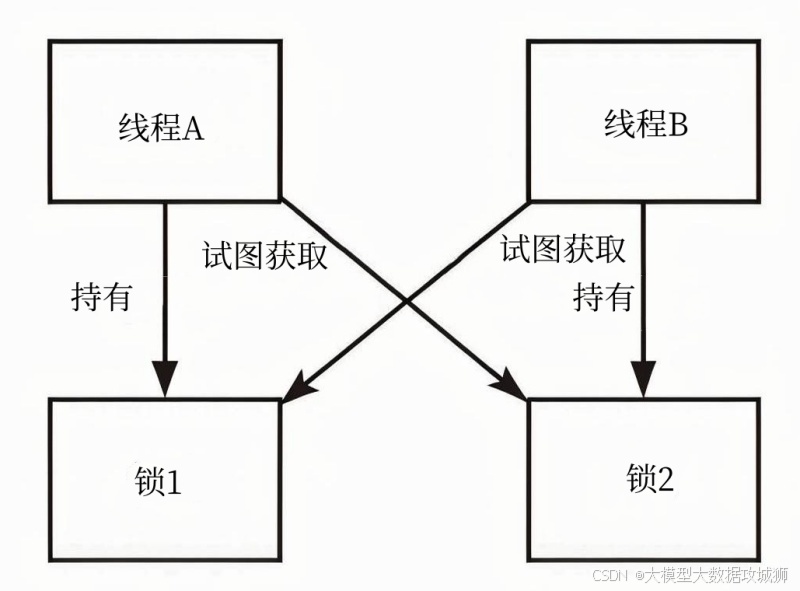
一、死锁的定义与示例
定义:多线程在竞争资源时,形成的一种 “循环等待” 状态 —— 线程 A 持有资源 X,等待资源 Y;线程 B 持有资源 Y,等待资源 X,两者均不释放已持有的资源,永远阻塞。
死锁示例代码(两个线程竞争两把锁):
public class DeadLockDemo {// 定义两把锁private static final Object LOCK_A = new Object();private static final Object LOCK_B = new Object();public static void main(String[] args) {// 线程1:先获取LOCK_A,再获取LOCK_Bnew Thread(() -> {synchronized (LOCK_A) {System.out.println("线程1持有LOCK_A,等待LOCK_B");try { Thread.sleep(100); } // 模拟持有LOCK_A后的业务逻辑catch (InterruptedException e) {}synchronized (LOCK_B) { // 等待线程2释放LOCK_BSystem.out.println("线程1获取LOCK_B,执行完成");}}}).start();// 线程2:先获取LOCK_B,再获取LOCK_Anew Thread(() -> {synchronized (LOCK_B) {System.out.println("线程2持有LOCK_B,等待LOCK_A");try { Thread.sleep(100); } // 模拟持有LOCK_B后的业务逻辑catch (InterruptedException e) {}synchronized (LOCK_A) { // 等待线程1释放LOCK_ASystem.out.println("线程2获取LOCK_A,执行完成");}}}).start();}
}
- 执行结果:线程 1 和线程 2 分别持有一把锁,等待对方的锁,永远无法继续执行,程序卡死。
二、产生死锁的四个必要条件
死锁的产生必须同时满足以下四个条件,缺一不可 —— 只要破坏任一条件,即可避免死锁:
| 必要条件 | 定义 |
|---|---|
| 互斥条件 | 资源具有排他性,同一时间只能被一个线程持有(如 Synchronized 锁、文件句柄) |
| 持有并等待条件 | 线程持有已获取的资源,同时等待其他线程持有的资源,且不释放已持有的资源 |
| 不可剥夺条件 | 线程已持有的资源,无法被其他线程强制剥夺,只能由线程自身主动释放 |
| 循环等待条件 | 多个线程形成 “循环等待链”,每个线程等待下一个线程持有的资源(如 A→B→C→A) |
三、死锁的避免与解决方法
核心思路是 “破坏死锁的任一必要条件”,常见方法如下:
破坏 “持有并等待” 条件
- 预分配资源:线程在执行前,一次性获取所有所需资源,若无法获取全部资源,则不获取任何资源,等待所有资源空闲后再尝试。
- 示例(优化死锁代码):
// 线程1和线程2均先尝试获取所有锁,再执行逻辑 new Thread(() -> {// 一次性获取LOCK_A和LOCK_B(顺序无关,只要统一)synchronized (LOCK_A) {synchronized (LOCK_B) {System.out.println("线程1获取所有锁,执行完成");}} }).start();
破坏 “循环等待” 条件
- 按固定顺序加锁:所有线程获取锁的顺序保持一致(如按锁的哈希值从小到大、按资源 ID 升序),避免形成循环等待链。
- 示例(优化死锁代码):
// 约定所有线程先获取LOCK_A,再获取LOCK_B(固定顺序) new Thread(() -> {synchronized (LOCK_A) { // 先加LOCK_ASystem.out.println("线程1持有LOCK_A,等待LOCK_B");synchronized (LOCK_B) { // 再加LOCK_BSystem.out.println("线程1执行完成");}} }).start();new Thread(() -> {synchronized (LOCK_A) { // 同样先加LOCK_A(而非先加LOCK_B)System.out.println("线程2持有LOCK_A,等待LOCK_B");synchronized (LOCK_B) {System.out.println("线程2执行完成");}} }).start(); - 此时线程 2 会等待线程 1 释放 LOCK_A,不会形成循环等待。
破坏 “不可剥夺” 条件
- 使用可超时的锁:通过
ReentrantLock.tryLock(long timeout, TimeUnit unit)尝试获取锁,若超时未获取,则主动释放已持有的锁,避免永久等待。 - 示例:
ReentrantLock lockA = new ReentrantLock(); ReentrantLock lockB = new ReentrantLock();new Thread(() -> {try {if (lockA.tryLock(100, TimeUnit.MILLISECONDS)) { // 超时100mstry {if (lockB.tryLock(100, TimeUnit.MILLISECONDS)) {try {System.out.println("线程1执行完成");} finally {lockB.unlock(); // 释放LOCK_B}}} finally {lockA.unlock(); // 释放LOCK_A}} else {System.out.println("线程1超时,放弃执行"); // 避免死锁}} catch (InterruptedException e) {} }).start();
- 使用可超时的锁:通过
死锁的解决(已发生死锁时)
- 定位死锁:使用 JDK 工具
jstack查看线程栈,分析哪个线程持有哪些锁、等待哪些锁。例如:- 执行
jps获取进程 ID; - 执行
jstack 进程ID,搜索 “deadlock” 关键字,找到死锁线程的锁信息。
- 执行
- 恢复措施:重启应用(简单直接,适合非核心服务),或通过代码预留 “逃生通道”(如定时线程检测死锁,中断死锁线程)。
- 定位死锁:使用 JDK 工具
面试关键点:死锁的定义与示例,四个必要条件的具体含义,破坏条件的具体方法(固定顺序加锁、可超时锁);加分点:演示如何用 jstack 定位死锁,或对比不同避免方法的适用场景(如预分配资源适合资源少的场景,固定顺序适合资源多的场景);记忆法:采用 “条件 - 破坏” 口诀 ——“死锁四条件:互斥持有等循环;破坏任一即可解:预分配、定顺序、超时锁、强剥夺”。
请解释 Java 并发包中的 CountDownLatch,说说它的作用和使用场景。
CountDownLatch 是 Java 并发包(java.util.concurrent)中基于 AQS(AbstractQueuedSynchronizer)实现的同步工具类,核心作用是 “让一个或多个线程等待其他多个线程完成操作后,再继续执行”,本质是 “倒计时器 + 等待机制”。
一、CountDownLatch 的核心原理
CountDownLatch 依赖 AQS 的状态变量 state 实现倒计时逻辑,核心机制如下:
初始化倒计时次数创建 CountDownLatch 实例时,传入倒计时次数
count(new CountDownLatch(int count)),AQS 的state变量会被初始化为count,代表需要等待的 “事件数量”。倒计时操作(
countDown()方法)当一个线程完成指定操作后,调用countDown()方法,AQS 的state会原子性减 1(通过tryReleaseShared(1)实现)。若state减至 0,AQS 会唤醒所有等待的线程;若state仍大于 0,无额外操作。等待操作(
await()方法)需要等待的线程调用await()方法后,会检查 AQS 的state是否为 0:- 若
state == 0:线程直接继续执行; - 若
state > 0:线程会进入 AQS 的 CLH 等待队列,阻塞等待,直到state减至 0 被唤醒。此外,await(long timeout, TimeUnit unit)方法支持超时等待 —— 若超时后state仍未为 0,线程会自动唤醒并返回false,避免永久阻塞。
- 若
二、CountDownLatch 的作用
CountDownLatch 的核心作用是 “协调多线程的执行顺序”,具体体现为两种场景:
主线程等待多个子线程完成主线程启动多个子线程后,需等待所有子线程执行完任务(如数据加载、文件处理),再汇总结果。例如:测试用例中,主线程等待 10 个测试线程执行完,再输出测试报告。
多个子线程等待主线程 “信号”多个子线程启动后,先阻塞等待主线程的 “开始信号”,待主线程准备就绪(如资源初始化完成),所有子线程同时开始执行。例如:并发测试中,100 个线程等待主线程发出 “开始” 指令,同时发起请求,模拟高并发。
三、CountDownLatch 的使用场景与代码示例
场景一:主线程等待多子线程完成需求:主线程启动 3 个数据加载线程,等待所有线程加载完成后,主线程汇总数据。代码示例:
import java.util.concurrent.CountDownLatch;public class CountDownLatchDemo1 {public static void main(String[] args) throws InterruptedException {// 初始化倒计时次数为3(对应3个数据加载线程)CountDownLatch latch = new CountDownLatch(3);// 启动3个数据加载线程for (int i = 1; i <= 3; i++) {int threadNum = i;new Thread(() -> {try {System.out.println("线程" + threadNum + "开始加载数据");Thread.sleep(1000); // 模拟数据加载耗时System.out.println("线程" + threadNum + "加载完成");} catch (InterruptedException e) {e.printStackTrace();} finally {latch.countDown(); // 倒计时减1(必须在finally中,避免异常未执行)}}).start();}// 主线程等待倒计时至0(所有线程加载完成)System.out.println("主线程等待所有线程加载数据...");latch.await();System.out.println("所有线程加载完成,主线程开始汇总数据");} }执行结果:主线程先打印 “等待”,3 个线程分别加载数据,全部完成后(
countDown3 次,state=0),主线程被唤醒,打印 “汇总数据”。场景二:多子线程等待主线程信号需求:5 个并发请求线程,等待主线程初始化完数据库连接后,同时发起请求。代码示例:
import java.util.concurrent.CountDownLatch;public class CountDownLatchDemo2 {public static void main(String[] args) throws InterruptedException {// 初始化倒计时次数为1(主线程的“初始化完成”信号)CountDownLatch latch = new CountDownLatch(1);// 启动5个请求线程for (int i = 1; i <= 5; i++) {int threadNum = i;new Thread(() -> {try {System.out.println("请求线程" + threadNum + "等待数据库初始化...");latch.await(); // 等待主线程信号System.out.println("请求线程" + threadNum + "发起请求");} catch (InterruptedException e) {e.printStackTrace();}}).start();}// 主线程初始化数据库(模拟耗时)System.out.println("主线程初始化数据库...");Thread.sleep(2000);System.out.println("主线程初始化完成,发送开始信号");latch.countDown(); // 倒计时减1至0,唤醒所有等待线程} }执行结果:5 个请求线程启动后立即阻塞等待,主线程初始化完成后
countDown(state=0),所有请求线程同时被唤醒,发起请求。
四、CountDownLatch 的关键注意事项
countDown()必须在 finally 中调用:避免线程因异常未执行countDown(),导致state无法减至 0,等待线程永久阻塞;- 一次性使用:CountDownLatch 的
state减至 0 后,无法重置,若需重复使用,需改用CyclicBarrier; - 与 CyclicBarrier 的区别:CountDownLatch 是 “单向倒计时”(主线程等子线程或反之),
CyclicBarrier是 “多线程互相等待”(所有线程到达屏障后一起继续),且支持重复使用。
面试关键点:CountDownLatch 的原理(AQS state 倒计时),两种核心使用场景(主线程等子线程、子线程等主线程),与 CyclicBarrier 的区别;加分点:解释 await() 的超时机制如何避免死锁,或结合实际项目场景(如分布式任务调度中的节点等待)说明使用;记忆法:采用 “功能 - 场景” 口诀 ——“CountDownLatch 倒计时,主线等子线程(汇总),子线程等主线(信号);countDown 减到 0,await 线程全唤醒,一次性使用要记清”。
多线程的同步和异步有什么区别?在项目中如何选择同步或异步处理?
多线程的同步与异步是两种核心的任务执行模式,其本质区别在于 “调用方是否等待任务完成”。在项目中选择哪种模式,需结合业务的核心需求(如可靠性、响应速度、资源占用)综合判断。
一、同步与异步的核心区别
同步与异步的区别体现在执行方式、返回时机、资源占用等多个维度,具体对比如下:
| 对比维度 | 同步(Synchronous) | 异步(Asynchronous) |
|---|---|---|
| 执行方式 | 调用方发起任务后,必须等待任务执行完成,才能继续执行后续逻辑 | 调用方发起任务后,无需等待任务完成,直接继续执行后续逻辑;任务在后台(如线程池)执行 |
| 返回时机 | 任务完成后,立即返回结果(或异常) | 任务发起时返回 “任务标识”(如 Future)或无返回;结果通过回调、轮询等方式获取 |
| 资源占用 | 调用方线程会阻塞等待,线程资源被占用(无法处理其他任务) | 调用方线程不阻塞,可处理其他任务;任务执行依赖独立线程(如线程池) |
| 可靠性 | 任务执行结果直接返回,调用方可立即感知成功 / 失败,便于重试 | 任务在后台执行,调用方需额外处理结果回调、失败重试(如任务丢失、超时) |
| 代码复杂度 | 逻辑线性,代码简单(顺序执行) | 逻辑非线性,需处理回调、线程安全、结果聚合,代码复杂度高 |
| 适用场景 | 核心流程、结果必须立即获取、依赖任务结果的场景 | 非核心流程、无需立即获取结果、追求高响应速度的场景 |
二、同步与异步的代码示例
通过 “订单支付” 场景对比两种模式:
同步处理示例订单支付后,同步执行 “订单入库”“库存扣减”“短信通知”,必须所有步骤完成后,才返回支付结果。
public class SyncDemo {// 订单入库(核心操作)private void saveOrder(Order order) {System.out.println("同步:订单入库");// 数据库操作}// 库存扣减(核心操作)private void deductStock(Order order) {System.out.println("同步:库存扣减");// 数据库操作}// 短信通知(非核心操作)private void sendSms(Order order) {System.out.println("同步:发送支付成功短信");// 调用短信接口(耗时1秒)}// 同步支付流程public String pay(Order order) {try {saveOrder(order); // 同步执行,等待完成deductStock(order); // 同步执行,等待完成sendSms(order); // 同步执行,等待完成(耗时1秒)return "支付成功";} catch (Exception e) {return "支付失败:" + e.getMessage();}}public static void main(String[] args) {SyncDemo demo = new SyncDemo();long start = System.currentTimeMillis();String result = demo.pay(new Order());long end = System.currentTimeMillis();System.out.println("结果:" + result + ",耗时:" + (end - start) + "ms");// 输出:耗时约1000ms(包含短信接口耗时)} }- 问题:短信通知(非核心)耗时 1 秒,导致支付响应时间延长,影响用户体验。
异步处理示例订单支付后,同步执行核心的 “订单入库”“库存扣减”,异步执行非核心的 “短信通知”(线程池处理),无需等待短信发送完成,直接返回支付结果。
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors;public class AsyncDemo {// 线程池(处理异步任务)private static final ExecutorService ASYNC_POOL = Executors.newFixedThreadPool(5);private void saveOrder(Order order) {System.out.println("同步:订单入库");}private void deductStock(Order order) {System.out.println("同步:库存扣减");}// 异步执行短信通知private void sendSmsAsync(Order order) {ASYNC_POOL.submit(() -> { // 提交到线程池,异步执行try {System.out.println("异步:发送支付成功短信");Thread.sleep(1000); // 模拟耗时} catch (InterruptedException e) {e.printStackTrace();// 失败重试逻辑(如重新提交任务)}});}// 异步支付流程public String pay(Order order) {try {saveOrder(order); // 同步执行核心操作deductStock(order); // 同步执行核心操作sendSmsAsync(order); // 异步执行非核心操作,无需等待return "支付成功";} catch (Exception e) {return "支付失败:" + e.getMessage();}}public static void main(String[] args) {AsyncDemo demo = new AsyncDemo();long start = System.currentTimeMillis();String result = demo.pay(new Order());long end = System.currentTimeMillis();System.out.println("结果:" + result + ",耗时:" + (end - start) + "ms");// 输出:耗时约10ms(仅核心操作耗时),短信在后台执行ASYNC_POOL.shutdown();} }- 优势:支付响应时间从 1000ms 缩短至 10ms,大幅提升用户体验;非核心任务在后台安全执行。
三、项目中同步与异步的选择策略
选择的核心是 “业务优先级 + 结果依赖性 + 响应速度要求”,具体规则如下:
选择同步处理的场景
- 核心业务流程:任务结果直接影响后续业务,必须确保成功执行且立即获取结果。例如:
- 订单支付中的 “订单入库”“库存扣减”(若失败,需立即返回支付失败,避免超卖);
- 用户登录中的 “密码验证”“会话创建”(需验证通过后,才能跳转首页)。
- 任务结果有依赖:后续任务需基于当前任务的结果执行。例如:
- 电商下单中,“计算订单金额”(需先获取商品价格、优惠券折扣,才能计算);
- 数据统计中,“汇总各部门数据”(需先获取每个部门的统计结果,才能汇总)。
- 核心业务流程:任务结果直接影响后续业务,必须确保成功执行且立即获取结果。例如:
选择异步处理的场景
- 非核心业务流程:任务失败不影响核心业务,无需立即获取结果。例如:
- 支付后的 “短信通知”“日志记录”“积分更新”(即使短信发送失败,用户支付已成功,可后续重试);
- 文章发布后的 “索引更新”“推荐算法触发”(文章已发布,索引可后台更新)。
- 追求高响应速度:需减少用户等待时间,提升体验。例如:
- 社交媒体的 “点赞” 功能(点击后立即返回成功,点赞数更新异步执行);
- 表单提交后的 “数据备份”(用户无需等待备份完成,直接跳转结果页)。
- 非核心业务流程:任务失败不影响核心业务,无需立即获取结果。例如:
混合策略(同步 + 异步)核心流程同步,非核心流程异步,是项目中最常用的模式。例如:
- 秒杀系统:同步执行 “库存扣减→订单创建”,异步执行 “订单确认短信→物流预创建”;
- 后台管理系统:同步执行 “数据提交→数据库保存”,异步执行 “数据导出→邮件发送”。
面试关键点:同步与异步的核心区别(是否等待),代码示例对比,选择策略(核心 / 非核心、结果依赖);加分点:提及异步处理的风险与解决方案(如任务丢失用消息队列、失败重试用定时任务),或结合分布式场景(如异步用 RocketMQ、同步用 Dubbo 同步调用);记忆法:采用 “场景 - 选择” 口诀 ——“核心流程要可靠,结果依赖必须同步;非核心流程求快速,无需等待就选异步;同步简单但耗时,异步复杂但高效”。
Java 类加载的过程分为几步?从.class 文件到生成实际对象需要哪些操作(加载、验证、准备、解析、初始化、实例化)?
Java 类加载是 JVM 将.class 文件加载到内存并转化为可执行代码的过程,是连接字节码与运行时对象的桥梁。从.class 文件到生成实际对象,需经历 “类加载(5 个阶段)” 和 “对象实例化” 两大环节,每个环节都有明确的职责。
一、类加载的五个核心阶段
类加载过程(也称为 “类的生命周期”)包括加载、验证、准备、解析、初始化五个阶段,这五个阶段按顺序执行(解析阶段可能与初始化阶段交叉进行,为 “动态绑定” 留有余地)。
加载(Loading)
- 核心操作:通过类的全限定名(如
com.example.User),将.class 文件的二进制字节流读取到内存,转化为方法区中的运行时数据结构(类元信息),并在堆中生成一个代表该类的java.lang.Class对象(作为方法区类元信息的访问入口)。 - 实现方式:由类加载器(如 Bootstrap ClassLoader、Application ClassLoader)完成,不同类加载器负责加载不同路径的类(如 Bootstrap 加载 JDK 核心类,Application 加载应用程序类)。
- 关键:二进制字节流的来源可以是.class 文件、网络(如 Applet)、数据库、动态生成(如代理类)等。
- 核心操作:通过类的全限定名(如
验证(Verification)
- 核心操作:确保加载的.class 文件字节流符合 JVM 规范,避免恶意或错误的字节流危害 JVM 安全。
- 主要验证内容:
- 文件格式验证:检查字节流是否符合.class 文件格式(如魔数 0xCAFEBABE、版本号兼容);
- 元数据验证:检查类的元数据(如类是否有父类、是否实现抽象方法);
- 字节码验证:检查方法体的字节码指令(如控制流是否合法、操作数栈类型是否匹配);
- 符号引用验证:检查常量池中的符号引用(如类、字段、方法的引用是否存在)。
准备(Preparation)
- 核心操作:为类的静态变量(
static修饰)分配内存,并设置默认初始值(零值),不执行代码中的赋值操作。 - 示例:
public class Test {private static int a = 10; // 准备阶段:a 分配内存,设为默认值 0(而非 10)private static final int b = 20; // final 静态变量:编译期已确定,准备阶段直接设为 20 } - 注意:静态常量(
static final)在编译期会被存入常量池,准备阶段直接赋值为目标值(而非零值)。
- 核心操作:为类的静态变量(
解析(Resolution)
- 核心操作:将常量池中的符号引用(如类名、方法名的字符串描述)转化为直接引用(如内存地址、偏移量),建立与实际类、字段、方法的关联。
- 解析对象:包括类或接口解析、字段解析、方法解析、接口方法解析。例如,将符号引用
Ljava/lang/String;解析为 String 类在方法区的内存地址。 - 动态性:解析通常在初始化前完成,但为支持 “动态绑定”(如多态),部分解析会延迟到初始化后(如调用重写方法时)。
初始化(Initialization)
- 核心操作:执行类的初始化逻辑,即执行类构造器
<clinit>()方法,包括静态变量的显式赋值和静态代码块的执行,按代码出现顺序执行。 <clinit>()特点:- 由编译器自动生成,合并静态变量赋值和静态代码块;
- 父类的
<clinit>()优先于子类执行(保证父类静态逻辑先完成); - 多个线程同时初始化一个类时,只有一个线程执行
<clinit>(),其他线程阻塞等待(保证初始化原子性)。
- 示例:
public class InitDemo {static {System.out.println("静态代码块1");}private static int x = 10; // 静态变量赋值static {System.out.println("静态代码块2,x=" + x);}// <clinit>() 执行顺序:静态代码块1 → x=10 → 静态代码块2 }
- 核心操作:执行类的初始化逻辑,即执行类构造器
二、从.class 文件到生成实际对象的完整流程
类加载完成后,需经过实例化才能生成对象,完整流程为:加载 → 验证 → 准备 → 解析 → 初始化 → 实例化
- 实例化(Instantiation):为对象分配内存、初始化实例变量、调用构造器(
<init>()方法)的过程,属于对象创建阶段,具体步骤:- 分配内存:在堆中为对象分配内存(大小在类加载完成后确定);
- 初始化实例变量:为实例变量设置默认零值(区别于静态变量的准备阶段);
- 执行构造器
<init>():由编译器生成,合并实例变量显式赋值、非静态代码块和构造方法逻辑,按顺序执行(先父类构造器,再子类构造器)。
面试关键点:类加载五阶段的具体操作(尤其是准备阶段的默认值与初始化阶段的显式赋值区别),从类加载到实例化的完整流程,<clinit>() 与 <init>() 的区别;加分点:提及动态解析(延迟解析)的场景,或类加载器在加载阶段的作用;记忆法:采用 “阶段 - 核心” 口诀 ——“加载读入.class,验证确保合规;准备静变赋零值,解析符号变地址;初始化执行<clinit>,实例化再调构造器”。
类初始化的过程是什么?哪些情况会触发类的初始化(如 new 对象、调用静态方法 / 属性、反射、子类初始化)?
类初始化是类加载过程的最后一个阶段,核心是执行类的初始化逻辑(静态变量赋值和静态代码块),而触发类初始化的场景有明确的规则,理解这些规则是掌握类加载机制的关键。
一、类初始化的过程
类初始化的核心是执行编译器自动生成的 <clinit>() 方法,该方法整合了类中所有静态变量的显式赋值语句和静态代码块,按代码在源码中的出现顺序执行。具体过程如下:
<clinit>()方法的生成编译器在编译阶段扫描类中的静态变量赋值(如static int a = 10;)和静态代码块(static {}),将它们按顺序合并为<clinit>()方法(无参数、无返回值)。例如:public class ClinitDemo {static int a;static { // 静态代码块1a = 20;System.out.println("静态块1:a=" + a);}static int b = 30; // 静态变量赋值static { // 静态代码块2System.out.println("静态块2:b=" + b);}// <clinit>() 执行顺序:a=20 → 打印静态块1 → b=30 → 打印静态块2 }执行后输出:
静态块1:a=20静态块2:b=30<clinit>()方法的执行规则- 父类优先:子类的
<clinit>()执行前,必须先执行父类的<clinit>()(保证父类静态逻辑先完成)。例如:父类Parent有静态代码块,子类Child初始化时,先执行Parent的<clinit>(),再执行Child的<clinit>()。 - 线程安全:多个线程同时初始化同一个类时,只有一个线程会执行
<clinit>(),其他线程阻塞等待,直到该线程执行完成(避免初始化冲突)。 - 可选性:若类中没有静态变量赋值和静态代码块,编译器不会生成
<clinit>()方法(初始化阶段无操作)。
- 父类优先:子类的
二、触发类初始化的六种场景
根据 Java 虚拟机规范,只有以下六种情况会触发类的初始化(称为 “主动引用”),其他情况(“被动引用”)不会触发:
创建类的实例(new 关键字)当通过
new关键字创建对象时,若类未初始化,会触发初始化。例如:public class InitTrigger {public static void main(String[] args) {new ClinitDemo(); // 触发 ClinitDemo 类的初始化} }调用类的静态方法调用类中被
static修饰的方法时,若类未初始化,会触发初始化。例如:public class ClinitDemo {public static void staticMethod() {System.out.println("静态方法");} } // 调用静态方法触发初始化 ClinitDemo.staticMethod();访问类的静态变量(非常量)读取或修改类中被
static修饰的变量(非final常量)时,若类未初始化,会触发初始化。例如:public class ClinitDemo {public static int staticVar = 10; // 静态变量(非常量) } // 访问静态变量触发初始化 System.out.println(ClinitDemo.staticVar);注意:访问
static final常量(编译期确定值)不会触发初始化,因为常量值已存入调用类的常量池(如public static final int CONST = 20;,访问ClinitDemo.CONST不触发初始化)。反射调用(如 Class.forName ())通过反射 API(如
Class.forName("com.example.ClinitDemo"))获取类对象时,若类未初始化,会触发初始化。例如:// 反射触发初始化 Class.forName("com.example.ClinitDemo");初始化子类时,父类未初始化子类初始化前,若父类未初始化,会先触发父类的初始化。例如:
class Parent {} class Child extends Parent {} // 初始化 Child 时,先初始化 Parent new Child();注意:子类访问父类的静态变量,仅触发父类初始化,不触发子类初始化(如
Child.parentStaticVar只初始化Parent)。JVM 启动时,执行主类(含 main 方法的类)JVM 启动时,会先初始化包含
main方法的主类。例如:public class MainClass {public static void main(String[] args) {} // 主类,启动时被初始化 }
三、不触发类初始化的场景(被动引用)
除上述六种情况外,其他引用类的方式均为 “被动引用”,不会触发初始化:
- 访问类的
static final常量(编译期确定值); - 通过数组定义引用类(如
ClinitDemo[] arr = new ClinitDemo[10];,仅创建数组对象,不初始化ClinitDemo); - 子类引用父类的静态变量(仅初始化父类)。
面试关键点:类初始化的核心是 <clinit>() 方法的执行,六种主动引用场景(尤其是 new、静态方法 / 变量、反射、子类初始化),被动引用的区别;加分点:解释 <clinit>() 与实例构造器 <init>() 的区别(前者静态逻辑,后者实例逻辑),或多线程初始化的线程安全机制;记忆法:采用 “触发场景” 口诀 ——“new 对象、调静态(方法 / 变量),反射、子类初始化;主类启动必初始化,这六种情况要记牢”。
什么是双亲委派模型?双亲委派模型的工作过程是什么?有什么作用?类加载的语法检查在哪个阶段(验证阶段)?
双亲委派模型是 Java 类加载器的核心设计模式,通过层级化的类加载器结构,保证类加载的安全性和唯一性。理解其工作过程与作用,是掌握类加载机制的核心。
一、什么是双亲委派模型
双亲委派模型(Parents Delegation Model)是指:当一个类加载器需要加载某个类时,它不会先自己尝试加载,而是先委托给父类加载器加载;只有当父类加载器无法加载该类时(即父类加载器的搜索范围中不存在该类),子类加载器才会尝试自己加载。
Java 中的类加载器按层级分为四类,形成双亲委派的层级结构:
| 类加载器类型 | 作用范围 | 父加载器 |
|---|---|---|
| Bootstrap ClassLoader(启动类加载器) | 加载 JDK 核心类库(如 rt.jar 中的 java.lang.*) | 无(顶层,用 C++ 实现) |
| Extension ClassLoader(扩展类加载器) | 加载 JDK 扩展类库(如 jre/lib/ext 目录下的类) | Bootstrap ClassLoader |
| Application ClassLoader(应用程序类加载器) | 加载应用程序类路径(classpath)下的类 | Extension ClassLoader |
| 自定义类加载器 | 加载自定义路径下的类(如加密的.class 文件) | 通常为 Application ClassLoader |
二、双亲委派模型的工作过程
类加载的具体流程遵循 “先父后子” 的委托逻辑,以加载 com.example.User 类为例:
当前类加载器委托父类加载器假设由应用程序类加载器(Application ClassLoader)触发加载,它不会直接加载,而是先委托给父类加载器 —— 扩展类加载器(Extension ClassLoader)。
父类加载器继续向上委托扩展类加载器收到委托后,同样不自己加载,继续委托给其父类加载器 —— 启动类加载器(Bootstrap ClassLoader)。
顶层加载器尝试加载启动类加载器检查自己的加载范围(JDK 核心类库),若
com.example.User不在核心类库中(通常如此),则无法加载,将结果返回给扩展类加载器。父类加载器尝试加载扩展类加载器收到 “无法加载” 的结果后,检查自己的加载范围(扩展类库),若
com.example.User不在扩展类库中,同样无法加载,返回给应用程序类加载器。当前类加载器自己加载应用程序类加载器收到结果后,检查自己的加载范围(
classpath),若找到com.example.User.class,则加载该类;若未找到,抛出ClassNotFoundException。
三、双亲委派模型的作用
双亲委派模型的核心价值是保证类加载的安全性和唯一性,具体体现在以下两点:
避免类的重复加载同一类(全限定名相同)由同一个类加载器加载,确保内存中只有一个类的实例。例如,
java.lang.String类无论被哪个类加载器触发加载,最终都会委托给启动类加载器加载,避免多个类加载器加载出多个不同的String类(导致类型不兼容)。保护核心类库的安全防止恶意代码篡改核心类库。例如,若自定义一个
java.lang.String类,试图替换 JDK 中的String类,由于双亲委派机制,该类会被委托给启动类加载器加载,而启动类加载器只会加载核心类库中的String类,自定义的String类不会被加载,避免核心类被篡改。
四、类加载的语法检查在哪个阶段
类加载的语法检查发生在验证阶段(Verification),这是类加载过程的第二个阶段。
验证阶段的核心任务是确保加载的 .class 文件字节流符合 Java 虚拟机规范,避免恶意或错误的字节流危害 JVM 安全。其中,语法检查主要体现在两个方面:
- 文件格式验证:检查字节流是否符合
.class文件的格式规范(如魔数0xCAFEBABE、版本号是否兼容 JVM 版本); - 字节码验证:检查方法体中的字节码指令是否符合语法规则(如控制流是否合法、操作数栈与指令是否匹配、类型转换是否有效)。
通过语法检查,JVM 可在类加载阶段拦截大部分无效或恶意的字节码,保证后续执行的安全性。
面试关键点:双亲委派模型的定义、四层类加载器结构、“先父后子” 的工作流程,两大核心作用(去重、安全),语法检查在验证阶段;加分点:说明如何打破双亲委派模型(如重写 loadClass 方法,典型案例:Tomcat 的类加载器),或验证阶段的其他检查内容(元数据验证、符号引用验证);记忆法:采用 “流程 - 作用” 口诀 ——“双亲委派先找父,父能加载不用子;保证类唯一,核心类安全;语法检查在验证,字节流合规才放行”。
JVM 的运行时数据区分为哪几部分?哪些是线程共享的(方法区、堆)?哪些是线程私有(虚拟机栈、本地方法栈、程序计数器)?
JVM 的运行时数据区是 Java 程序运行时内存分配和管理的核心区域,其结构划分直接影响程序的性能与稳定性。根据《Java 虚拟机规范》,运行时数据区分为五个部分,按 “线程共享” 和 “线程私有” 可明确区分其特性。
一、运行时数据区的五部分组成
JVM 运行时数据区包括程序计数器、虚拟机栈、本地方法栈、堆、方法区五个部分,每个部分有明确的功能和生命周期:
程序计数器(Program Counter Register)
- 定义:一块较小的内存空间,可看作当前线程执行字节码的 “行号指示器”,记录当前线程正在执行的字节码指令地址(若执行 native 方法,计数器值为 undefined)。
- 特性:
- 线程私有:每个线程都有独立的程序计数器,互不影响(线程切换时需保存和恢复计数器值);
- 无 OOM:是唯一不会抛出
OutOfMemoryError的区域,内存大小在编译期确定。
虚拟机栈(VM Stack)
- 定义:线程运行时创建的栈结构,用于存储栈帧(Stack Frame),每个方法调用对应一个栈帧入栈,方法执行完对应栈帧出栈。
- 栈帧组成:
- 局部变量表(存储方法参数和局部变量);
- 操作数栈(方法执行时的临时数据栈);
- 动态链接(指向常量池中该方法的符号引用);
- 方法返回地址(方法执行完后返回的位置)。
- 特性:
- 线程私有:每个线程的虚拟机栈独立,栈帧属于当前线程;
- 内存固定或动态扩展:若线程请求的栈深度超过虚拟机允许的深度,抛出
StackOverflowError;若栈扩展时无法申请到足够内存,抛出OutOfMemoryError。
本地方法栈(Native Method Stack)
- 定义:与虚拟机栈功能类似,但专门为执行 native 方法(如调用 C/C++ 代码)服务,存储 native 方法的执行状态。
- 特性:
- 线程私有:与虚拟机栈一样,每个线程有独立的本地方法栈;
- 异常类型:同样可能抛出
StackOverflowError(栈深度超限)和OutOfMemoryError(内存不足)。
- 实现差异:HotSpot 虚拟机将虚拟机栈和本地方法栈合并为同一结构,无需单独实现。
堆(Heap)
- 定义:JVM 中最大的内存区域,用于存储对象实例和数组(几乎所有的对象都在这里分配内存)。
- 特性:
- 线程共享:所有线程共享堆空间,对象实例的访问需考虑线程安全;
- 内存动态分配:堆内存可通过
-Xms(初始大小)和-Xmx(最大大小)参数配置,内存不足时抛出OutOfMemoryError; - 垃圾回收核心区域:堆是垃圾收集器(GC)的主要工作区域,通常按 “新生代”(Eden、Survivor)和 “老年代” 划分,优化垃圾回收效率。
方法区(Method Area)
- 定义:存储类的元数据信息,包括类的结构信息(如字段、方法、接口)、常量池、静态变量、即时编译(JIT)后的代码等。
- 特性:
- 线程共享:所有线程共享方法区,类元信息被所有线程共享访问;
- 内存回收:主要回收废弃的常量和无用的类(满足类卸载条件),回收效率较低;
- 实现差异:JDK 1.7 及之前称为 “永久代”(在堆中),JDK 1.8 及之后改为 “元空间”(使用本地内存),内存不足时抛出
OutOfMemoryError: Metaspace。
二、线程共享与线程私有区域的对比
| 分类 | 包含区域 | 核心特点 | 生命周期 |
|---|---|---|---|
| 线程共享 | 堆、方法区(元空间) | 所有线程可访问,需考虑线程安全;内存较大 | 随 JVM 启动而创建,随 JVM 退出而销毁 |
| 线程私有 | 程序计数器、虚拟机栈、本地方法栈 | 每个线程独立拥有,无需考虑线程安全;内存较小 | 随线程创建而创建,随线程结束而销毁 |
面试关键点:运行时数据区的五部分组成,各区域的功能与特性,线程共享(堆、方法区)与私有(程序计数器、虚拟机栈、本地方法栈)的划分,常见异常类型;加分点:说明堆的分代模型(新生代、老年代),或方法区从永久代到元空间的演变原因(避免永久代 OOM、更好利用本地内存);记忆法:采用 “区域 - 归属” 口诀 ——“程序栈、本地栈、计数器,线程私有各顾各;堆和方法区共享用,所有线程可访问”。
本地方法区(JDK 1.8 后为元空间)中存放的是什么内容(类元信息、常量、静态变量、即时编译后的代码)?
JDK 1.8 后,本地方法区的实现从 “永久代” 改为 “元空间”(Metaspace),虽然存储位置从堆内存调整为本地内存,但其核心存储内容未发生根本变化,主要用于存放类的元数据及相关信息,是类加载后在内存中的 “数据字典”。
一、元空间(Metaspace)的核心存储内容
元空间是方法区的实现,主要存储以下四类内容,这些内容是类加载后对字节码信息的结构化映射:
类的元信息(Class Metadata)这是元空间最核心的内容,包括类的结构定义和描述信息,是 JVM 识别和使用类的基础:
- 类的基本信息:类的全限定名(如
com.example.User)、父类的全限定名、实现的接口列表、访问修饰符(public、abstract、final等); - 字段信息:类中所有字段的名称、类型、访问修饰符(
public、private等)、是否为静态(static)、是否为常量(final)等; - 方法信息:类中所有方法的名称、返回值类型、参数列表、访问修饰符、异常列表、方法体的字节码指令(存储在常量池或方法属性中);
- 其他元数据:类的版本号、常量池引用、注解信息、内部类列表等。
例如,
User类编译后,元空间中会存储其字段(id、name)、方法(getId()、setName())的定义,以及它继承自Object类的信息。- 类的基本信息:类的全限定名(如
运行时常量池(Runtime Constant Pool)运行时常量池是方法区的一部分,由类的常量池(.class 文件中的
constant_pool表)在类加载时转化而来,存储以下内容:- 字面量:字符串(如
"hello")、基本类型常量(如10、true)、被声明为final的静态变量(编译期确定值); - 符号引用:类和接口的全限定名、字段的名称和描述符、方法的名称和描述符(在解析阶段会转化为直接引用);
- 动态常量:JDK 1.7 后支持的动态生成的常量(如
invokedynamic指令相关的常量)。
例如,
String s = "hello";中,"hello"会被存储在运行时常量池中,多个引用指向同一常量(字符串常量池的实现基础)。- 字面量:字符串(如
静态变量(JDK 1.8 前)
- JDK 1.7 及之前:静态变量(
static修饰)存储在永久代(方法区的旧实现)中,与类的元信息存放在一起; - JDK 1.8 及之后:静态变量被移至堆内存中,作为类对象(
java.lang.Class实例)的一部分存储,元空间中不再存放静态变量。
这一变化的原因是:将静态变量移至堆,可利用堆的垃圾回收机制更灵活地管理静态变量的生命周期,避免永久代内存不足导致的 OOM。
- JDK 1.7 及之前:静态变量(
即时编译(JIT)后的代码JVM 的即时编译器(如 HotSpot 的 C1、C2 编译器)会将热点代码(频繁执行的方法或循环)从字节码编译为本地机器码,这些编译后的机器码也会存储在元空间中,以提升代码执行效率。
例如,一个被频繁调用的
calculate()方法,JIT 编译后的机器码会存放在元空间,后续调用直接执行机器码,无需再次解释字节码。
二、元空间与永久代的核心区别
JDK 1.8 用元空间替代永久代,主要差异体现在存储位置和内存管理上:
| 特性 | 永久代(JDK 1.7 及之前) | 元空间(JDK 1.8 及之后) |
|---|---|---|
| 存储位置 | 堆内存的一部分(受 -Xmx 限制) | 本地内存(不受 -Xmx 限制,受系统内存限制) |
| 内存大小 | 需通过 -XX:PermSize 和 -XX:MaxPermSize 配置 | 默认无上限(可通过 -XX:MaxMetaspaceSize 限制) |
| 静态变量存储 | 存储在永久代中 | 存储在堆中(类对象的一部分) |
| OOM 风险 | 易因永久代大小不足导致 OutOfMemoryError: PermGen space | 若元空间无限增长,可能导致系统内存耗尽,需手动限制大小 |
面试关键点:元空间存储的四类核心内容(类元信息、运行时常量池、JIT 编译代码,注意静态变量在 JDK 1.8 后的位置变化),元空间与永久代的区别;加分点:说明元空间的内存回收机制(主要回收无用类和废弃常量),或配置元空间大小的 JVM 参数(-XX:MetaspaceSize、-XX:MaxMetaspaceSize);记忆法:采用 “内容 - 特点” 口诀 ——“元空间存类信息,常量池、JIT 码;静态变量堆中去,本地内存是新家”。
什么是 Java 内存模型(JMM)?它主要解决什么问题(多线程可见性、原子性、有序性)?
Java 内存模型(JMM,Java Memory Model)并非物理内存的实际结构,而是 JVM 定义的一套抽象规范,用于协调多线程对共享内存的访问规则,保证多线程环境下程序的正确性。其核心目标是解决多线程并发时因“CPU 缓存、指令重排序”导致的内存可见性、原子性、有序性问题,让开发者无需关注底层硬件细节,即可编写安全的并发代码。
一、Java 内存模型(JMM)的核心定义
JMM 定义了“线程”与“主内存”“工作内存”之间的交互规则:
- 主内存:所有线程共享的内存区域,存储共享变量(实例变量、静态变量),对应物理内存中的一部分;
- 工作内存:每个线程独有的内存区域,存储线程私有变量(局部变量、方法参数)及共享变量的副本,对应 CPU 的高速缓存;
- 交互规则:线程对共享变量的读写必须通过“工作内存→主内存”的交互完成,不能直接操作主内存:
- 线程读取共享变量时,需从主内存加载变量到工作内存,形成副本;
- 线程修改共享变量时,需先修改工作内存中的副本,再刷新到主内存;
- 不同线程的工作内存相互隔离,线程间的变量传递需通过主内存间接完成。
例如,线程 A 修改共享变量 count,线程 B 读取 count 的流程:线程 A 工作内存:count=1 → 刷新到主内存(count=1) → 线程 B 工作内存加载(count=1)若缺少 JMM 规范,线程 A 修改后可能未刷新到主内存,导致线程 B 读取到旧值,引发并发错误。
二、JMM 主要解决的三大并发问题
多线程并发时,因 CPU 缓存(导致可见性问题)、指令重排序(导致有序性问题)、线程切换(导致原子性问题),会破坏程序的正确性,JMM 通过规范和工具(如 volatile、锁)解决这些问题。
可见性问题
- 定义:一个线程修改了共享变量的值,其他线程无法立即看到最新值,导致“脏读”。
- 原因:线程修改共享变量后,工作内存中的副本未及时刷新到主内存;其他线程读取时,仍加载主内存中的旧值到工作内存。
- JMM 解决方案:通过内存屏障强制刷新主内存。例如
volatile修饰的变量,写操作后会触发“写屏障”,将副本刷新到主内存;读操作前会触发“读屏障”,从主内存重新加载变量,保证可见性。 - 示例:
public class VisibilityDemo {private volatile boolean flag = false; // volatile 保证可见性public void setFlag() {flag = true; // 写屏障:立即刷新到主内存}public void checkFlag() {while (!flag) { // 读屏障:每次从主内存加载// 若 flag 无 volatile,线程可能一直循环(看不到 true)}System.out.println("flag 已变为 true");} }
原子性问题
- 定义:一个或多个操作组成的“不可分割”的整体,要么全部执行,要么全部不执行,中间不会被线程切换打断。
- 原因:线程执行时会被 CPU 分时调度,若操作未完成就切换线程,可能导致数据不一致(如
i++包含“读-改-写”三步,中间切换线程会出错)。 - JMM 解决方案:通过锁机制或原子类保证原子性。例如
synchronized或ReentrantLock会将同步块内的操作视为原子整体;AtomicInteger基于 CAS 实现原子操作。 - 示例:
public class AtomicityDemo {private AtomicInteger count = new AtomicInteger(0);public void increment() {count.incrementAndGet(); // 原子操作,避免 i++ 的并发问题} }
有序性问题
- 定义:程序执行顺序与代码编写顺序不一致,因 JVM 为优化性能会对指令重排序(单线程下不影响结果,多线程下可能破坏逻辑)。
- 原因:指令重排序可能导致“依赖”的操作顺序颠倒。例如
int a = 1; int b = a + 2;,重排序后若先执行b = a + 2(此时a未赋值),会导致b错误。 - JMM 解决方案:通过内存屏障禁止关键指令重排序,或通过
happens-before规则定义操作间的有序性。例如volatile禁止变量读写与其他指令重排序;synchronized保证同步块内的指令不会与块外指令重排序。 - 典型场景:单例模式的双重检查锁,
instance需用volatile修饰,禁止“对象创建”与“引用赋值”的重排序,避免线程获取到未初始化的对象。
三、JMM 的核心保障:happens-before 规则
为简化并发编程,JMM 定义了 happens-before 规则(无需显式使用 volatile 或锁,即可保证有序性和可见性),核心规则包括:
- 程序顺序规则:同一线程内,代码按编写顺序执行,前面的操作
happens-before后面的操作; - 锁规则:解锁操作
happens-before后续对同一锁的加锁操作; volatile规则:volatile变量的写操作happens-before后续的读操作;- 线程启动规则:
Thread.start()happens-before线程内的所有操作。
例如,线程 A 解锁后,线程 B 加锁获取同一把锁,线程 A 解锁前的操作结果,线程 B 一定能看到(符合锁规则)。
面试关键点:JMM 的规范本质(非物理结构),三大并发问题(可见性、原子性、有序性)的定义、原因及 JMM 解决方案,happens-before 核心规则;加分点:结合 volatile、锁的底层实现(内存屏障)解释 JMM 的具体保障;记忆法:采用“规范-问题-方案”口诀——“JMM 是规范,协调线程存;解三性:可见靠屏障,原子用锁类,有序禁重排,规则帮保障”。
讲一下垃圾收集机制(GC)的作用?常见的垃圾回收算法有哪些(标记 - 清除、标记 - 复制、标记 - 整理)?各算法的优缺点对比是什么?
垃圾收集机制(GC,Garbage Collection)是 JVM 自动管理内存的核心机制,负责识别并回收堆中“无用对象”(不再被引用的对象)的内存,避免内存泄漏和内存溢出(OOM),减轻开发者手动管理内存的负担。其核心流程包括“识别垃圾”“回收垃圾”“内存整理”三步,其中“回收垃圾”依赖不同的垃圾回收算法实现。
一、垃圾收集机制(GC)的核心作用
- 自动识别垃圾对象通过“可达性分析”判断对象是否为垃圾:以“GC Roots”(如线程栈引用、静态变量引用、本地方法栈引用)为起点,遍历对象引用链,若对象无法被 GC Roots 访问,则判定为垃圾对象(需回收)。
- 回收垃圾内存释放垃圾对象占用的堆内存,将内存重新分配给新对象,避免内存资源浪费。
- 优化内存布局部分算法在回收垃圾后会整理内存碎片,减少内存碎片化,保证大对象能顺利分配内存(碎片化严重时,即使总内存充足,也可能因无连续内存无法分配大对象)。
- 保障程序稳定运行自动回收内存避免了开发者手动释放内存的疏漏(如忘记
free或delete),减少内存泄漏风险,降低 OOM 概率。
二、常见的垃圾回收算法
垃圾回收算法的核心目标是“高效回收内存”“减少停顿时间”“避免内存碎片”,不同算法因设计思路不同,适用于不同的堆区域(新生代、老年代),常见算法包括标记-清除、标记-复制、标记-整理。
标记-清除算法(Mark-Sweep)
- 核心原理:分“标记”和“清除”两步:
- 标记阶段:从 GC Roots 出发,遍历所有对象,标记出非垃圾对象(可达对象);
- 清除阶段:遍历堆内存,回收未被标记的垃圾对象,释放内存(仅记录空闲内存地址,不移动对象)。
- 优点:实现简单,无需移动对象,回收速度快(尤其适合对象存活率高的场景)。
- 缺点:
- 内存碎片化严重:回收后产生大量不连续的空闲内存块,后续分配大对象时,即使总空闲内存充足,也可能因无连续块导致分配失败;
- 标记和清除效率低:需遍历整个堆两次(标记一次、清除一次),堆内存越大,耗时越长。
- 适用场景:老年代(对象存活率高,移动对象开销大,碎片化可通过其他机制缓解)。
- 核心原理:分“标记”和“清除”两步:
标记-复制算法(Mark-Copy)
- 核心原理:将堆内存划分为两个大小相等的区域(如新生代的 Eden 区和 Survivor 区,比例通常为 8:1):
- 标记阶段:仅在“活动区”(如 Eden 区)标记可达对象;
- 复制阶段:将活动区的可达对象复制到“空闲区”(如 Survivor 区),按顺序排列(无碎片);
- 切换阶段:清空活动区,将空闲区设为新的活动区,原活动区设为空闲区。
- 优点:
- 无内存碎片化:复制后对象按顺序排列,空闲内存连续,便于大对象分配;
- 回收效率高:仅标记和复制可达对象,无需遍历整个堆(尤其适合对象存活率低的场景)。
- 缺点:
- 内存利用率低:需预留一半空闲区,实际可用内存仅为总内存的 50%(新生代通过“Eden+2个Survivor”优化,利用率提升至 90%);
- 复制开销大:若对象存活率高(如老年代),需复制大量对象,耗时较长。
- 适用场景:新生代(对象存活率低,大部分对象创建后很快成为垃圾,复制开销小)。
- 核心原理:将堆内存划分为两个大小相等的区域(如新生代的 Eden 区和 Survivor 区,比例通常为 8:1):
标记-整理算法(Mark-Compact)
- 核心原理:结合标记-清除和标记-复制的优点,分“标记”“整理”“清除”三步:
- 标记阶段:与标记-清除一致,标记可达对象;
- 整理阶段:将所有可达对象向堆内存的一端移动,按顺序排列;
- 清除阶段:回收对象移动后另一端的所有垃圾内存(释放连续的大块内存)。
- 优点:
- 无内存碎片化:整理后空闲内存连续,解决标记-清除的碎片化问题;
- 内存利用率高:无需预留空闲区,全部内存可利用(解决标记-复制的利用率问题)。
- 缺点:
- 移动对象开销大:整理阶段需移动所有可达对象,还需更新对象的引用地址(避免引用失效),耗时较长,导致 GC 停顿时间增加;
- 实现复杂:需处理对象移动后的引用更新逻辑。
- 适用场景:老年代(对象存活率高,移动开销虽大,但可避免碎片化和低利用率问题)。
- 核心原理:结合标记-清除和标记-复制的优点,分“标记”“整理”“清除”三步:
三、三种算法的优缺点对比
| 算法 | 优点 | 缺点 | 适用区域 |
|---|---|---|---|
| 标记-清除 | 实现简单,无需移动对象 | 内存碎片化严重,标记/清除效率低 | 老年代 |
| 标记-复制 | 无碎片化,回收效率高(低存活率场景) | 内存利用率低,复制开销大(高存活率场景) | 新生代 |
| 标记-整理 | 无碎片化,内存利用率高 | 移动对象开销大,实现复杂 | 老年代 |
面试关键点:GC 的核心作用(识别垃圾、回收内存、整理布局),三种算法的原理、优缺点及适用区域,新生代与老年代选择不同算法的原因;加分点:解释新生代“Eden+2 Survivor”的标记-复制优化(提升内存利用率),或 G1 回收器对三种算法的融合;记忆法:采用“算法-特点-适用”口诀——“标记清除简无移,碎片多老年代去;标记复制无碎片,利用率低新生代;标记整理无碎片,移动开销老年代”。
讲一下常见的垃圾回收器(如 Serial、Parallel Scavenge、Parallel Old、CMS、G1、ZGC)?各回收器的特点和适用场景是什么?
垃圾回收器(Garbage Collector)是 GC 算法的具体实现,JVM 提供了多种回收器,每种回收器针对不同的性能目标(吞吐量、低停顿、低延迟)设计,适用于不同的业务场景(客户端、服务端、大内存场景)。常见回收器按“分代回收”或“不分代回收”可分为传统回收器(Serial、Parallel 系列、CMS)和现代回收器(G1、ZGC)。
一、常见垃圾回收器的特点与适用场景
Serial 回收器(串行回收器)
- 核心特点:
- 单线程回收:仅使用一个线程执行 GC 操作,回收期间暂停所有用户线程(STW,Stop The World);
- 分代回收:仅用于新生代,采用“标记-复制”算法;
- 实现简单,内存开销小:无需多线程同步,适合内存较小的场景。
- 优缺点:
- 优点:单线程无同步开销,GC 效率高(客户端场景下停顿时间短);
- 缺点:STW 时间长(堆内存越大,停顿越久),不适合多 CPU、大内存的服务端场景。
- 适用场景:客户端应用(如桌面软件、小型工具),或内存较小的嵌入式系统;JVM 客户端模式(默认)下的新生代回收器。
- 启用参数:
-XX:+UseSerialGC(新生代 Serial + 老年代 Serial Old)。
- 核心特点:
Parallel Scavenge 回收器(并行回收器)
- 核心特点:
- 多线程回收:使用多个 CPU 核心并行执行 GC,减少 STW 时间(比 Serial 快数倍);
- 分代回收:仅用于新生代,采用“标记-复制”算法;
- 追求吞吐量:吞吐量 = 用户线程执行时间 /(用户线程时间 + GC 时间),默认吞吐量目标为 99%(即 GC 时间不超过 1%)。
- 优缺点:
- 优点:多线程提升回收效率,高吞吐量适合后台计算场景;
- 缺点:STW 时间仍随堆内存增大而增加,无法满足低停顿需求(如实时服务)。
- 适用场景:服务端后台应用(如数据计算、报表生成),注重吞吐量而非低停顿;JVM 服务端模式下的默认新生代回收器。
- 启用参数:
-XX:+UseParallelGC(新生代 Parallel Scavenge + 老年代 Serial Old)。
- 核心特点:
Parallel Old 回收器
- 核心特点:
- 多线程回收:老年代专用回收器,与 Parallel Scavenge 搭配使用,组成“新生代并行+老年代并行”的全并行回收组合;
- 分代回收:用于老年代,采用“标记-整理”算法;
- 追求吞吐量:延续 Parallel Scavenge 的吞吐量目标,适合对吞吐量要求高的全链路场景。
- 优缺点:
- 优点:全并行回收提升整体吞吐量,比老年代 Serial Old 快得多;
- 缺点:STW 时间仍较长(老年代对象多,整理开销大)。
- 适用场景:与 Parallel Scavenge 搭配,用于高吞吐量的服务端应用(如电商后台订单处理,非实时交互场景)。
- 启用参数:
-XX:+UseParallelOldGC(新生代 Parallel Scavenge + 老年代 Parallel Old)。
- 核心特点:
CMS 回收器(Concurrent Mark Sweep,并发标记清除)
- 核心特点:
- 低停顿优先:通过“并发标记”减少 STW 时间(仅初始标记和重新标记阶段短暂 STW,并发标记和清除阶段与用户线程并行);
- 分代回收:仅用于老年代,采用“标记-清除”算法;
- 多线程并发:标记和清除阶段使用多个线程与用户线程并行执行。
- 核心流程(四阶段):
- 初始标记(STW):标记 GC Roots 直接引用的对象(毫秒级停顿);
- 并发标记:与用户线程并行,遍历引用链标记所有可达对象(无 STW);
- 重新标记(STW):修正并发标记期间因用户线程修改导致的标记偏差(毫秒级停顿);
- 并发清除:与用户线程并行,回收未标记的垃圾对象(无 STW)。
- 优缺点:
- 优点:STW 时间极短(通常几十毫秒),适合低停顿需求的实时服务;
- 缺点:
- 内存碎片化:采用标记-清除算法,长期运行易产生碎片,需定期执行 Full GC 整理内存;
- CPU 资源占用高:并发阶段需占用部分 CPU 核心,可能影响用户线程性能;
- 浮动垃圾:并发清除阶段产生的新垃圾(浮动垃圾)无法回收,需预留内存容纳。
- 适用场景:低停顿需求的服务端应用(如电商秒杀、金融交易),对响应时间敏感的场景。
- 启用参数:
-XX:+UseConcMarkSweepGC(新生代 ParNew + 老年代 CMS)。
- 核心特点:
G1 回收器(Garbage-First)
- 核心特点:
- 区域化分代:将堆内存划分为多个大小相等的“Region”(默认 1MB~32MB),每个 Region 可动态标记为新生代(Eden/Survivor)或老年代,打破传统分代边界;
- 低停顿+高吞吐量:通过“优先回收垃圾比例高的 Region”(Garbage-First)减少 STW 时间,同时兼顾吞吐量;
- 混合回收:支持新生代回收(Young GC)和老年代混合回收(Mixed GC),避免全堆 Full GC(仅在极端情况下触发);
- 采用“标记-复制”+“标记-整理”算法:回收 Region 时用标记-复制(无碎片),全局整理时用标记-整理。
- 优缺点:
- 优点:支持大堆(几十 GB~几百 GB),STW 时间可控(通过
-XX:MaxGCPauseMillis设定目标停顿时间),无明显碎片化; - 缺点:Region 管理复杂,内存开销比 CMS 高,小堆场景下性能不如 Parallel 系列。
- 优点:支持大堆(几十 GB~几百 GB),STW 时间可控(通过
- 适用场景:大内存、低停顿需求的服务端应用(如大型互联网服务、分布式系统),JDK 9 及之后的默认回收器。
- 启用参数:
-XX:+UseG1GC(默认 JDK 9+),-XX:MaxGCPauseMillis=200(目标停顿时间 200ms)。
- 核心特点:
ZGC 回收器(Z Garbage Collector)
- 核心特点:
- 超低延迟:STW 时间控制在亚毫秒级(通常 <1ms),几乎无感知;
- 不分代回收:无需分代,支持超大堆(TB 级内存),适合内存密集型应用;
- 并发回收:所有阶段(标记、清理、整理)均与用户线程并行,仅初始标记和最终标记有极短 STW;
- 基于“颜色指针”和“读屏障”技术:通过指针标记对象状态,避免传统回收器的引用更新开销,支持并发整理。
- 优缺点:
- 优点:TB 级大堆支持,亚毫秒级延迟,CPU 利用率高;
- 缺点:JDK 11 才引入(实验性),JDK 15 正式转正,兼容性需验证,小堆场景下性能无明显优势。
- 适用场景:超大内存、超低延迟需求的场景(如实时数据分析、高频交易系统)。
- 启用参数:
-XX:+UseZGC(JDK 11+,需指定大堆内存,如-Xmx100G)。
- 核心特点:
二、常见回收器的核心对比
| 回收器 | 线程模型 | 分代支持 | 算法 | 核心目标 | 适用场景 | JDK 支持 |
|---|---|---|---|---|---|---|
| Serial | 单线程 | 新生代 | 标记-复制 | 简单高效 | 客户端、嵌入式 | JDK 1+ |
| Parallel Scavenge | 多线程 | 新生代 | 标记-复制 | 高吞吐量 | 服务端后台计算 | JDK 1.4+ |
| Parallel Old | 多线程 | 老年代 | 标记-整理 | 高吞吐量 | 服务端后台计算 | JDK 1.6+ |
| CMS | 多线程 | 老年代 | 标记-清除 | 低停顿 | 实时服务(秒杀、交易) | JDK 1.5+(JDK 14 废弃) |
| G1 | 多线程 | 区域化分代 | 标记-复制/整理 | 低停顿+吞吐量 | 大堆服务端应用 | JDK 7+(默认 9+) |
| ZGC | 多线程 | 不分代 | 颜色指针+读屏障 | 超低延迟 | 超大堆、实时系统 | JDK 11+(正式 15+) |
面试关键点:各回收器的线程模型(单线程/多线程)、分代支持、核心算法、性能目标(吞吐量/低停顿/低延迟)及适用场景,G1 和 ZGC 的创新技术(区域化、颜色指针);加分点:解释 CMS 被废弃的原因(内存碎片化、CPU 占用高),G1 如何通过 Region 实现低停顿,ZGC 亚毫秒延迟的技术原理;记忆法:采用“回收器-特点-场景”口诀——“Serial 单线程客户端,Parallel 追吞吐;CMS 低停顿,G1 区域化大堆;ZGC 亚毫秒,TB 内存无压力”。