【AI论文】多人纳什偏好优化
摘要:基于人类反馈的强化学习(RLHF)已成为使大语言模型(LLM)与人类偏好保持一致的标准范式。然而,基于布拉德利-特里(Bradley-Terry)假设的奖励型方法难以捕捉现实世界偏好中存在的非传递性和异质性特征。为解决这一问题,近期研究将偏好对齐重构为双人纳什博弈,催生了基于人类反馈的纳什学习(NLHF)方法。尽管这一视角催生了如INPO、ONPO和EGPO等具备强理论及实证保障的算法,但它们本质上仍局限于双人交互场景,导致“单一对手偏差”,无法全面捕捉现实偏好结构的复杂性。本研究提出多人纳什偏好优化(Multiplayer Nash Preference Optimization, MNPO)框架,将NLHF拓展至多人博弈场景。该框架将偏好对齐建模为n人博弈,其中每个策略在竞争对抗对手群体的同时,向参考模型进行正则化约束。我们的框架在多人场景中建立了定义明确的纳什均衡,并扩展了对偶间隙(duality gap)概念以量化近似质量。研究表明,MNPO继承了双人博弈方法的均衡保障,同时支持更丰富的竞争动态,并能更全面地覆盖多样化偏好结构。通过全面的实证评估,我们发现MNPO在指令遵循基准测试中持续优于现有NLHF基线,在标注者异质性和混合策略评估场景下实现了更优的偏好对齐质量。这些结果共同表明,MNPO为使大语言模型与复杂、非传递的人类偏好保持一致提供了一个有原则且可扩展的框架。代码已开源,详见:https://github.com/smiles724/MNPO。Huggingface链接:Paper page,论文链接:2509.23102
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理任务中的广泛应用,如何使这些模型更好地与人类偏好对齐成为了一个关键问题。
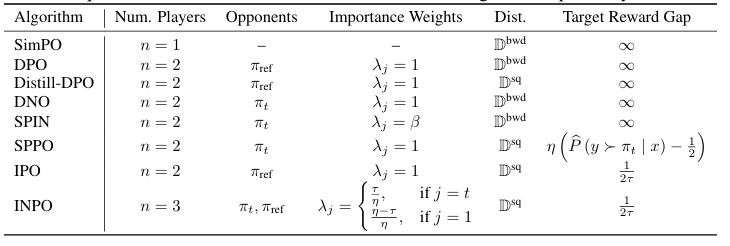
传统的强化学习从人类反馈中学习(RLHF)方法,主要依赖于基于Bradley-Terry模型的奖励函数来优化模型输出,这些方法假设人类偏好具有传递性,并且可以通过标量奖励函数来捕捉。然而,近期的研究表明,人类偏好往往表现出非传递性和异质性,这挑战了传统RLHF方法的假设。为了解决这一问题,近期的研究提出了将偏好优化视为两人纳什博弈的框架,即纳什学习从人类反馈中学习(NLHF)。尽管NLHF方法在理论和实践上都取得了一定的成功,但它们主要局限于两人互动场景,无法充分捕捉现实世界中复杂偏好结构的全部复杂性。
研究目的:
本研究旨在提出一种新的框架——多玩家纳什偏好优化(MNPO),将NLHF扩展到多玩家场景。MNPO通过将偏好优化视为一个n人博弈问题,每个策略在与对手群体竞争的同时向参考模型正则化,从而在多玩家环境中建立明确定义的纳什均衡。
本研究的主要目的包括:
- 扩展NLHF到多玩家场景:解决传统RLHF和NLHF方法在处理复杂、非传递性人类偏好时的局限性。
- 建立明确定义的纳什均衡:在多玩家环境中,MNPO框架能够找到稳定的策略组合,即纳什均衡,其中没有任何一个玩家可以通过单方面改变策略来提高自己的收益。
- 提高偏好对齐的质量:通过更丰富的竞争动态和多样化的偏好结构覆盖,MNPO旨在提高LLMs与复杂人类偏好的对齐质量。
研究方法
1. 理论框架构建:
MNPO框架将偏好优化视为一个n人博弈问题,其中每个策略(即LLM的输出)在与对手群体竞争的同时向参考模型正则化。
参考模型通常是一个经过监督微调的LLM,用于提供稳定的基准。MNPO通过引入时间依赖的对手选择机制(TD-MNPO),在每个训练迭代中动态地选择对手策略,从而增强训练的稳定性和鲁棒性。
2. 目标函数设计:
MNPO的目标函数设计考虑了多玩家博弈中的竞争与合作。
具体来说,每个策略的目标是最大化其相对于其他所有策略的平均偏好概率,同时通过KL散度正则化项保持与参考模型的接近。目标函数可以表示为:
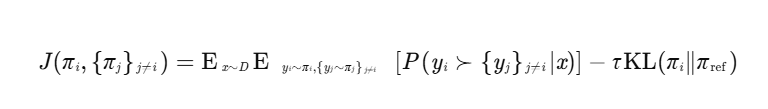
其中,![]() 表示在给定输入x的情况下,输出yi相对于其他所有输出{yj}j≠i的偏好概率;τ是正则化参数,用于控制策略与参考模型的偏离程度。
表示在给定输入x的情况下,输出yi相对于其他所有输出{yj}j≠i的偏好概率;τ是正则化参数,用于控制策略与参考模型的偏离程度。
3. 优化算法:
MNPO采用了一种基于乘法权重更新的优化算法,该算法在每个迭代步骤中根据当前策略与对手策略的偏好比较结果来更新策略权重。
具体来说,更新规则可以表示为:
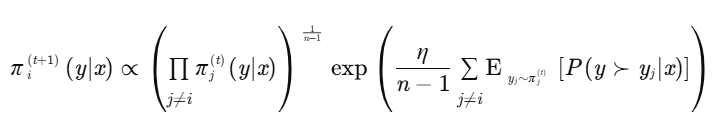
其中,η是学习率,控制更新步长。
该更新规则确保策略更新既考虑了对手策略的分布,又考虑了当前策略相对于对手策略的偏好优势。
4. 时间依赖的对手选择机制(TD-MNPO):
为了进一步提高训练的稳定性和鲁棒性,MNPO引入了时间依赖的对手选择机制。
在每个训练迭代中,MNPO从历史策略中选择一部分作为当前策略的对手,这些对手策略的权重随时间变化,从而在训练过程中动态地引入过去的知识。这种机制有助于防止模型在训练过程中陷入局部最优解,并提高模型的泛化能力。
研究结果
1. 指令跟随和偏好对齐性能:
在多个指令跟随和偏好对齐基准测试中,MNPO显著优于现有的NLHF基线方法。
例如,在MT-Bench、AlpacaEval2和Arena-Hard等基准测试中,MNPO生成的响应在长度控制的胜率(LC WR)和整体胜率(WR)方面均取得了显著提升。特别是在Arena-Hard基准测试中,MNPO的胜率比次优方法INPO提高了4.23个百分点,显示出其在处理复杂偏好结构时的优势。
2. 知识推理能力:
在多个知识推理基准测试中,MNPO同样表现出色。
例如,在GPQA、MMLU和ARC等基准测试中,MNPO的平均得分达到了71.08,超过了所有基线方法。这表明MNPO在保持与人类偏好对齐的同时,还能够有效地捕捉和利用知识信息进行推理。
3. 数学和编程能力:
在数学推理和编程基准测试中,MNPO也取得了优异成绩。
例如,在AIME-24基准测试中,MNPO是唯一能够实现非零性能的方法,而在HumanEval基准测试中,MNPO的得分也超过了所有其他方法。这些结果表明MNPO在处理复杂逻辑和编程任务时具有显著优势。
研究局限
1. 偏好数据的依赖:
MNPO的性能高度依赖于偏好数据的质量和多样性。
如果偏好数据存在偏差或不足,MNPO可能无法充分捕捉人类偏好的全部复杂性,从而影响模型的对齐质量。
2. 计算复杂度:
尽管MNPO通过引入多玩家博弈和动态对手选择机制提高了模型的鲁棒性和泛化能力,但这些改进也增加了计算复杂度。特别是在处理大规模数据集和复杂模型时,MNPO的训练过程可能变得非常耗时。
3. 纳什均衡的近似:
在实际应用中,MNPO找到的纳什均衡可能只是近似解,而非精确解。
这可能导致模型在某些情况下无法达到最优性能。此外,纳什均衡的近似质量也受到优化算法和超参数选择的影响。
未来研究方向
1. 提高偏好数据的多样性和质量:
未来的研究可以探索如何收集更丰富、更无偏的偏好数据,以提高MNPO模型的对齐质量。例如,可以通过众包、专家评审或主动学习等方式来获取高质量的偏好数据。
2. 优化计算效率:
针对MNPO计算复杂度高的问题,未来的研究可以探索更高效的优化算法和并行计算策略。
例如,可以通过模型剪枝、量化或分布式训练等方式来降低计算成本。
3. 探索更复杂的纳什均衡近似方法:
为了提高MNPO找到的纳什均衡的近似质量,未来的研究可以探索更复杂的优化算法和近似方法。
例如,可以通过引入更复杂的正则化项、使用更高级的优化算法或结合强化学习技术来改进纳什均衡的近似。
4. 扩展到其他应用场景:
除了指令跟随和偏好对齐任务外,MNPO还可以扩展到其他需要处理复杂偏好结构的应用场景中。
例如,在推荐系统、对话系统或自主驾驶等领域中,MNPO有望通过更好地捕捉用户偏好来提高系统性能。