构建AI智能体:五十三、反应式应急+深思式优化:反应速度与规划智慧的平衡
一、智能体的类型回顾
1. 反应式智能体
反应式智能体类似于生物的脊髓反射弧,这种智能体遵循经典的"感知-行动"模型,不包含复杂的内部状态表示,也不进行耗时的推理过程。其核心机制是基于预先编码的条件-动作规则,对环境刺激做出即时、确定的响应。
一个生动的例子是自动驾驶系统中的紧急制动模块:当毫米波雷达检测到前方突然出现的障碍物时,系统会立即触发制动指令,整个过程在毫秒级内完成,无需"思考"这个障碍物是什么、为什么会出现。
反应式智能体的优势在于其极致的响应速度、确定的系统行为和较低的计算资源需求,在应对突发、紧急或模式固定的任务时表现卓越。

2. 深思熟虑智能体
深思熟虑智能体更像人类的大脑皮层,负责复杂的认知活动,这类智能体采用"感知-推理-行动"的循环模式,它拥有丰富的内部世界模型,能够进行符号推理、目标分解和长远规划。
例如,一个围棋AI在落子前,会模拟未来几十步的可能走法,评估每个局面的优劣,最终选择胜率最高的策略。
深思熟虑智能体的核心优势在于强大的复杂问题求解能力、情境适应性和决策的深度,然而,这种深度思考需要消耗大量的计算资源和时间,在需要快速反应的场景中显得力不从心。
这两种类型的智能体看似对立,实则互补,正如生物同时拥有反射弧和大脑皮层一样,最先进的智能体系统正在探索将二者有机结合的路径。
二、智能体的融合架构
单一的范式无法应对真实世界的复杂性。最先进的智能体系统采用分层架构,将二者的优势结合起来。
1. 基础介绍
将反应式与深思熟虑智能体结合的核心思想是建立一种分层架构,这种架构模仿了人类处理问题的自然方式:简单、紧急的事务由下意识快速处理,复杂、重要的事务交由深思熟虑来决策。
在这种架构中,系统被划分为两个相对独立但又紧密协作的层次:位于底层的反应层和位于上层的深思层。
反应层由大量预先定义或学习得到的条件-动作规则组成,专门负责处理高频、紧急的常规任务,它的目标是"快",确保系统在面对危险或机会时能够第一时间作出反应,为整个系统提供基本的安全保障和实时响应能力。
深思层则包含世界模型、规划器和学习模块,负责处理复杂的目标分解、策略制定和经验学习。当环境相对稳定、任务复杂度超出反应层处理能力时,深思层就会被激活。它从宏观角度分析局势,制定长期规划,并将规划结果转化为反应层能够执行的具体策略或规则。
两个层次之间通过抑制/激活机制进行交互:反应层在遇到无法处理的复杂情况时向深思层发送求助信号;深思层在制定出新策略后,会将其编译成反应层能够理解的规则;在极端紧急情况下,反应层甚至能够暂时抑制深思层的控制权,优先确保系统安全。这种分工协作的架构,使得智能体既具备了应对突发情况的敏捷性,又拥有了解决复杂问题的深思能力。
2. 核心思想
总结以上信息,该架构采用分层协作的方式将智能体分为两层:
- 反应层: 位于底层,由if-then规则或简单策略网络构成,处理高频、紧急、确定的任务。
- 深思层: 位于上层,包含世界模型和规划器,处理低频、复杂、需要策略的任务。
3. 工作流程
两层之间通过清晰的接口进行协作,其工作流程如下图所示:
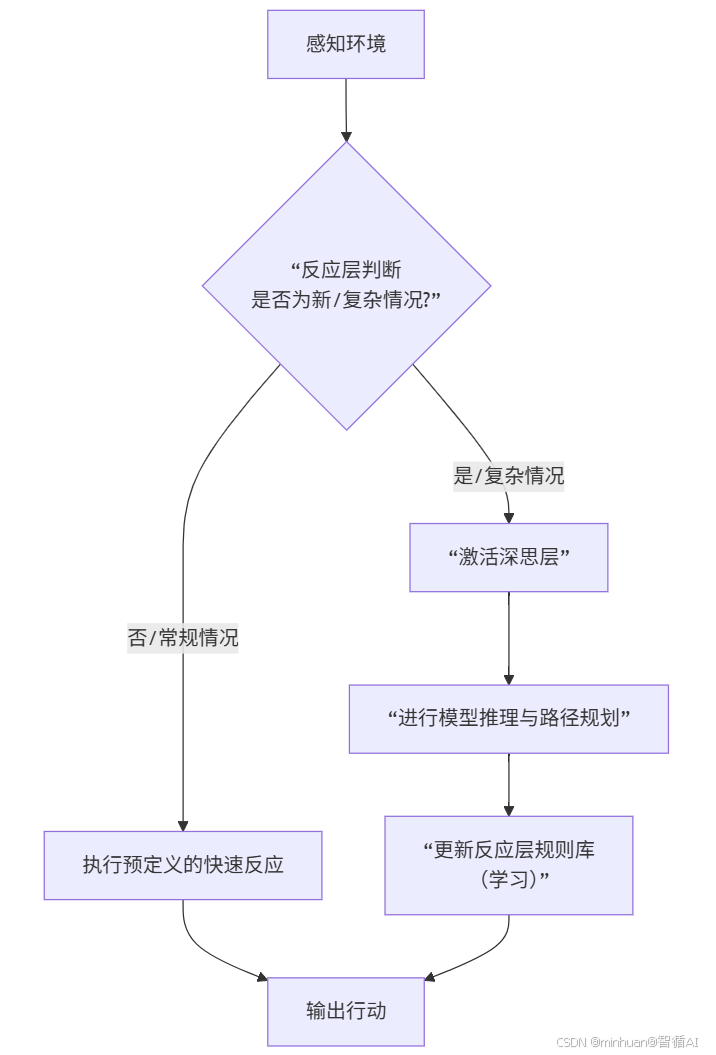
流程说明:
第一步:感知环境
智能体通过传感器收集环境数据,包括自身状态(位置、电量)、环境信息(障碍物、目标点)和任务状态。这是决策的原始输入,相当于人的感官系统。d
第二步: 反应层判断(决策枢纽)
反应层基于预设规则库进行快速模式匹配:
- 常规情况:环境状态能直接匹配到现有的“条件-动作”规则
- 复杂情况:遇到规则库中没有答案的新场景或需要多步推理的任务
这个判断过程极快,确保了系统的基本响应能力。
第三步:双路径处理
路径A:常规快速响应
当识别为常规情况时,反应层直接执行预定义动作,如避障、返回充电等。这个过程类似条件反射,速度快、功耗低、可靠性高。
路径B:复杂问题深思
遇到复杂情况时激活深思层,进行:
- 世界模型分析
- 路径规划与推理
- 多目标权衡决策
这个过程较慢但决策质量高,能解决策略性问题。
第四步:学习与进化(核心优势)
深思层成功解决新问题后,会将解决方案提炼为新的“条件-动作”规则,更新到反应层规则库中。这意味着:
- 系统具备学习能力
- 相同问题再次出现时可快速响应
- 智能体随经验积累不断进化
第五步:输出行动
最终通过执行器将决策转化为实际行动,完成一个决策循环。
流程总结:该流程实现了反应速度与决策质量的平衡,并通过学习机制使系统能够持续优化,是构建自适应智能系统的比较有效的方式。
4. 交互机制
- 自下而上触发: 反应层作为第一道关口,当它遇到其规则库无法处理的新情况或复杂情况时,会向深思层发送一个“求助”信号。
- 自上而下指导: 深思层被激活后,会进行思考并制定一个行动计划或策略。这个计划会被“编译”成一系列反应层能够理解的子目标或新规则,下发给反应层去执行。
- 学习与优化: 深思层通过这次经历,可以更新其世界模型。同时,它生成的新规则可以被反应层吸收,使得下次再遇到同样情况时,反应层能够直接处理,无需再次惊动深思层,从而实现系统性能的持续进化。
5. 完整架构
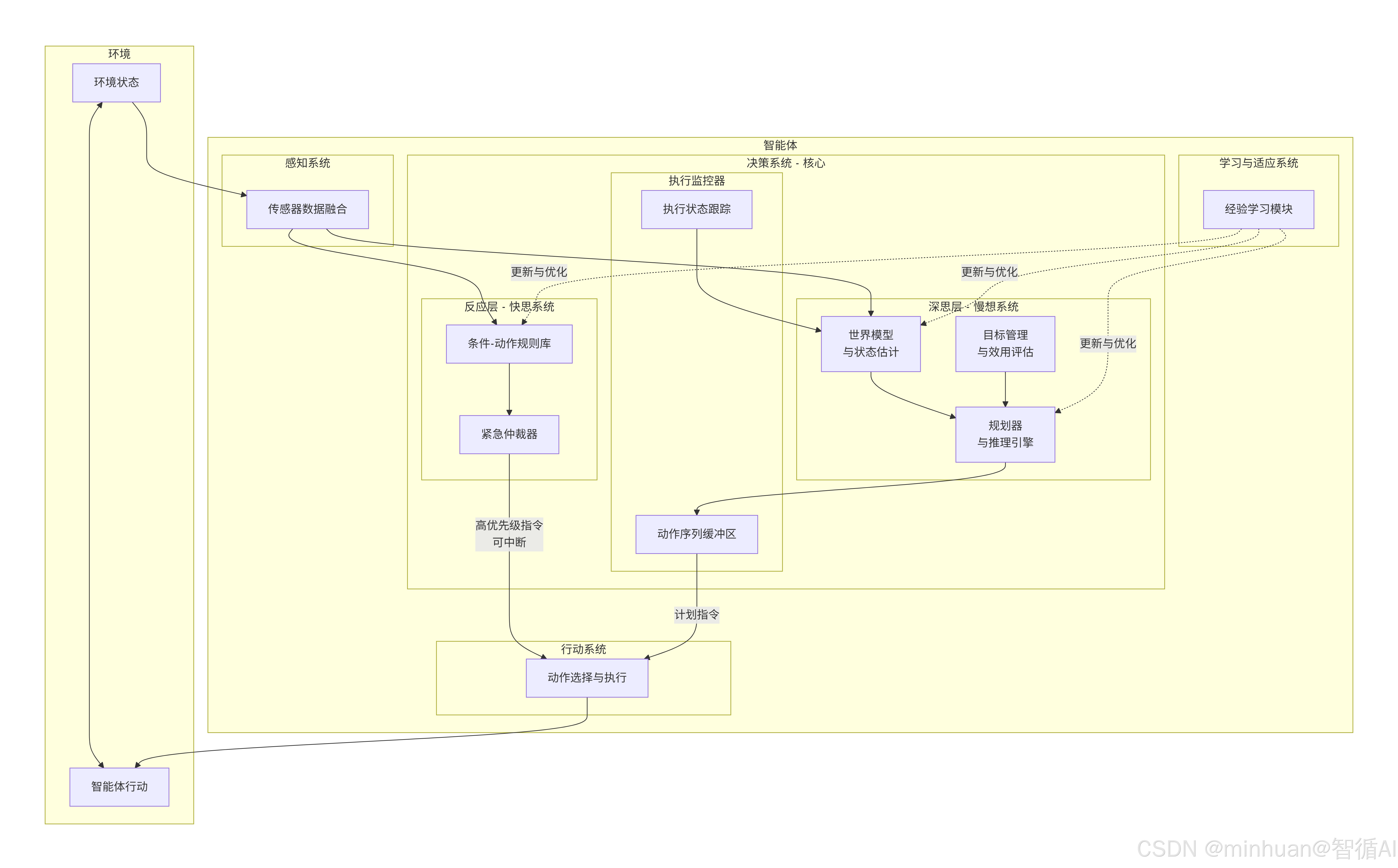
5.1 感知系统
这是智能体与环境的接口,负责将物理世界的信号转化为内部可处理的数据。
- 功能:接收来自各种传感器(如摄像头、激光雷达、红外、编码器等)的原始数据。
- 关键技术:传感器数据融合。它不是简单传递数据,而是将多源、可能相互冲突或冗余的数据进行整合、滤波和校准,形成一个统一、一致、可靠的环境状态描述。例如,结合GPS(绝对位置但不精确)和轮式里程计(相对位置精确但会漂移)来得到一个更可靠的定位信息。
- 输出:一份结构化的“感知报告”,为后续决策提供事实基础。
5.2 决策系统(核心)
这是智能体的“大脑”,采用分层设计,以平衡响应速度与决策深度。
5.2.1 反应层 - 快思系统
- 定位:智能体的“脊髓反射”,处理紧急和常规事务。
- 工作机制:内部维护一个条件-动作规则库。它持续扫描感知数据,一旦匹配到某条规则的条件(如 IF 障碍物距离 < 0.5米),则立即触发对应的动作(THEN 紧急停止)。
- 核心特点:
- 无状态性:决策不依赖历史信息或复杂模型,仅基于当前输入。
- 高优先级:通过紧急仲裁器,其指令可以立即中断深思层正在执行的计划,确保安全。
- 速度快、可靠性高:适用于避障、电量告警、系统保护等场景。
5.2.2 深思层 - 慢想系统
- 定位:智能体的“大脑皮层”,负责战略规划和复杂决策。
- 组成模块:
- 世界模型与状态估计:维护一个动态的内部环境模型。它不仅存储当前状态,还预测状态变化(如“执行动作A后,我可能到达位置B”)。它利用感知数据和执行反馈来持续修正这个模型,使其更精确。
- 规划器与推理引擎:这是深思层的核心计算单元。给定目标(来自目标管理)和当前世界模型,它通过搜索算法(如A*)、任务规划(如HTN)或逻辑推理,生成一系列能达到目标的最优行动序列。
- 目标管理与效用评估:定义和权衡智能体的任务。当多个目标冲突时(如“快速完成任务” vs “节省电量”),效用评估模块会根据预设的权重或学习到的价值,做出最优折衷。
5.2.3 执行监控器
- 定位:深思层与执行器之间的“桥梁”和“监工”。
- 功能:
- 动作序列缓冲区:存储深思层生成的行动计划,并按序提交给执行系统。
- 执行状态跟踪:监控计划的执行情况,对比预期状态与实际状态。如果发现重大偏差(如某个动作执行失败,或因环境变化导致计划失效),它会向深思层发出重新规划的请求。
5.3 行动系统
- 功能:将决策系统输出的抽象指令(如“向左转30度”)转化为具体的、底层硬件可以执行的控制信号(如“给左轮电机发送特定PWM波”)。
- 关键技术:运动控制、逆运动学解算等,确保动作的精确和稳定。
5.4 学习与适应系统
这是使智能体从“机器”走向“智能”的关键模块。
- 功能:通过分析历史数据(感知、决策、行动结果)来优化智能体自身的性能。
- 学习回路:
- 经验积累:记录成功与失败的决策案例。
- 模式提炼:学习模块会分析这些案例。例如,深思层多次成功解决一种新型障碍后,学习模块可以将其提炼为一个新的规则(IF 遇到障碍物类型X THEN 执行策略Y)。
- 知识注入:将提炼出的新规则注入反应层的规则库,或用于优化深思层的世界模型和规划策略。
- 效果:实现“吃一堑,长一智”。智能体在面对相同或类似情况时,反应会更快、决策会更优,具备持续进化的能力。
5.5 架构优势
这种混合架构通过精心的层次划分和模块协作,实现了:
- 安全与敏捷:反应层保障了在动态环境中的基本生存能力。
- 效率与策略:深思层确保了长期任务的高效和策略性完成。
- 协调与连贯:执行监控器保证了两层决策的平滑衔接和计划的连贯执行。
- 进化与适应:学习系统使智能体能够从经验中学习,不断优化其行为。
三、智能体的对比
| 特性 | 反应式 | 深思熟虑式 | 混合式 |
| 响应速度 | 极快 | 慢 | 快慢结合,分层响应 |
| 决策质量 | 短视、本能 | 深远、战略 | 兼具战术与战略 |
| 资源消耗 | 低 | 高 | 动态分配,效率更高 |
| 环境适应性 | 弱 | 强 | 通过持续学习不断增强 |
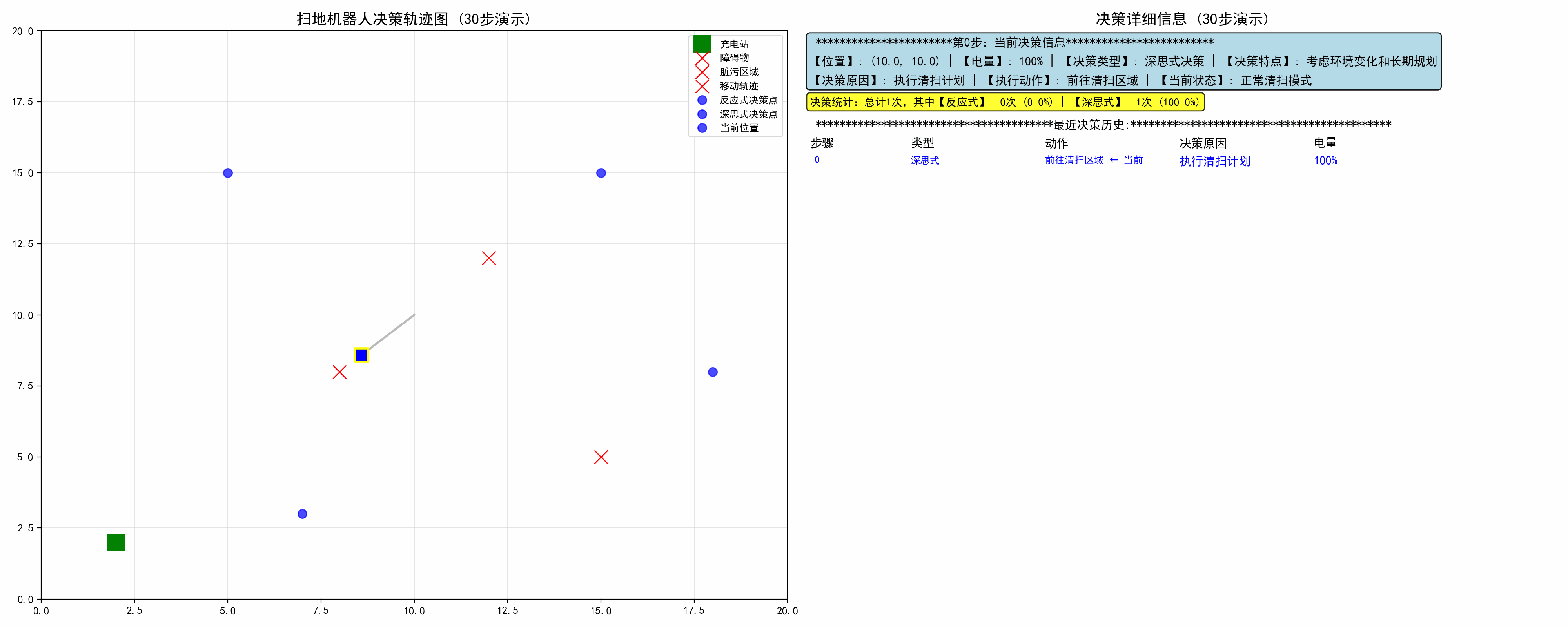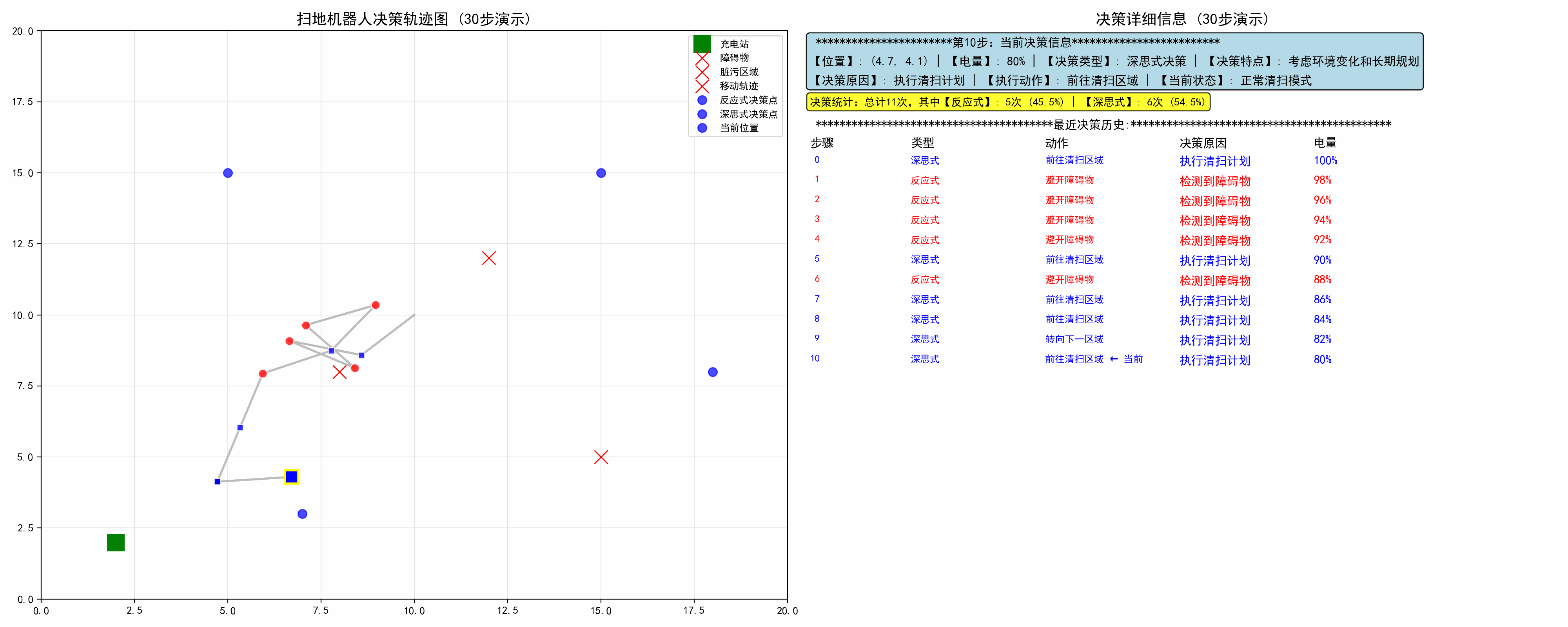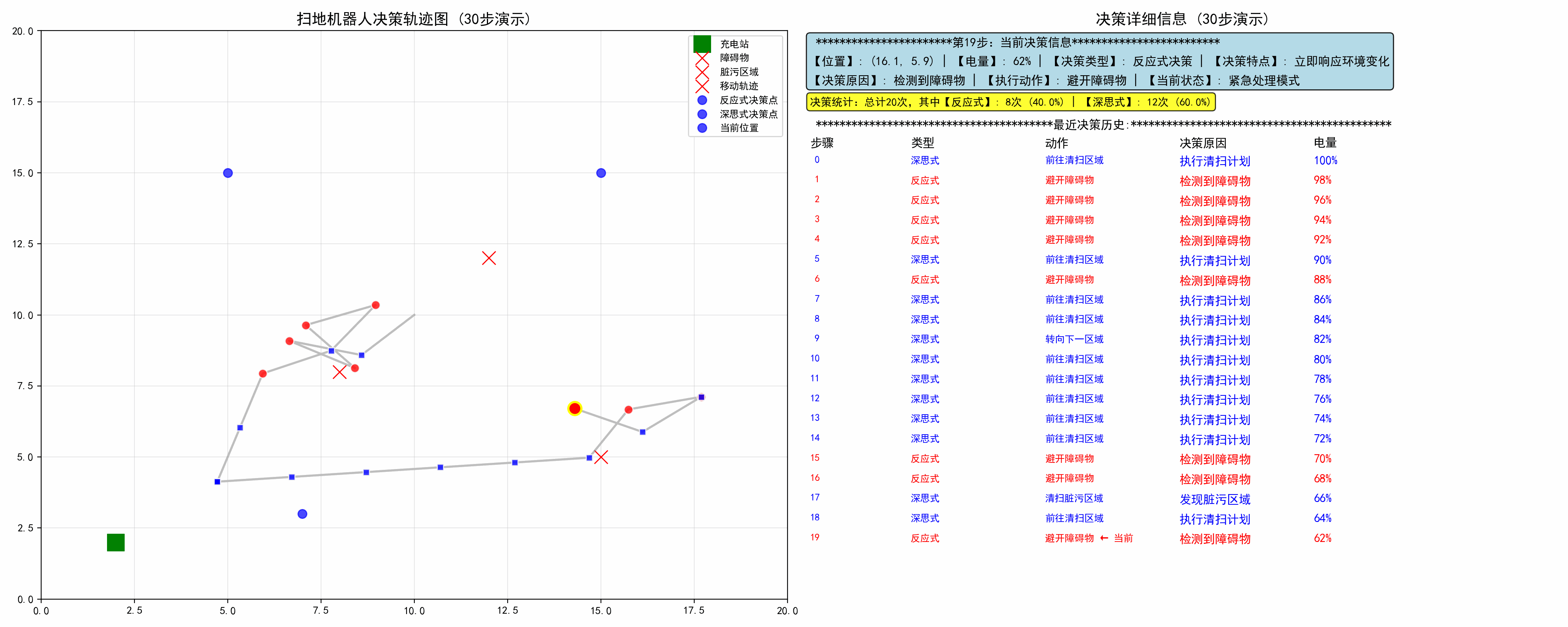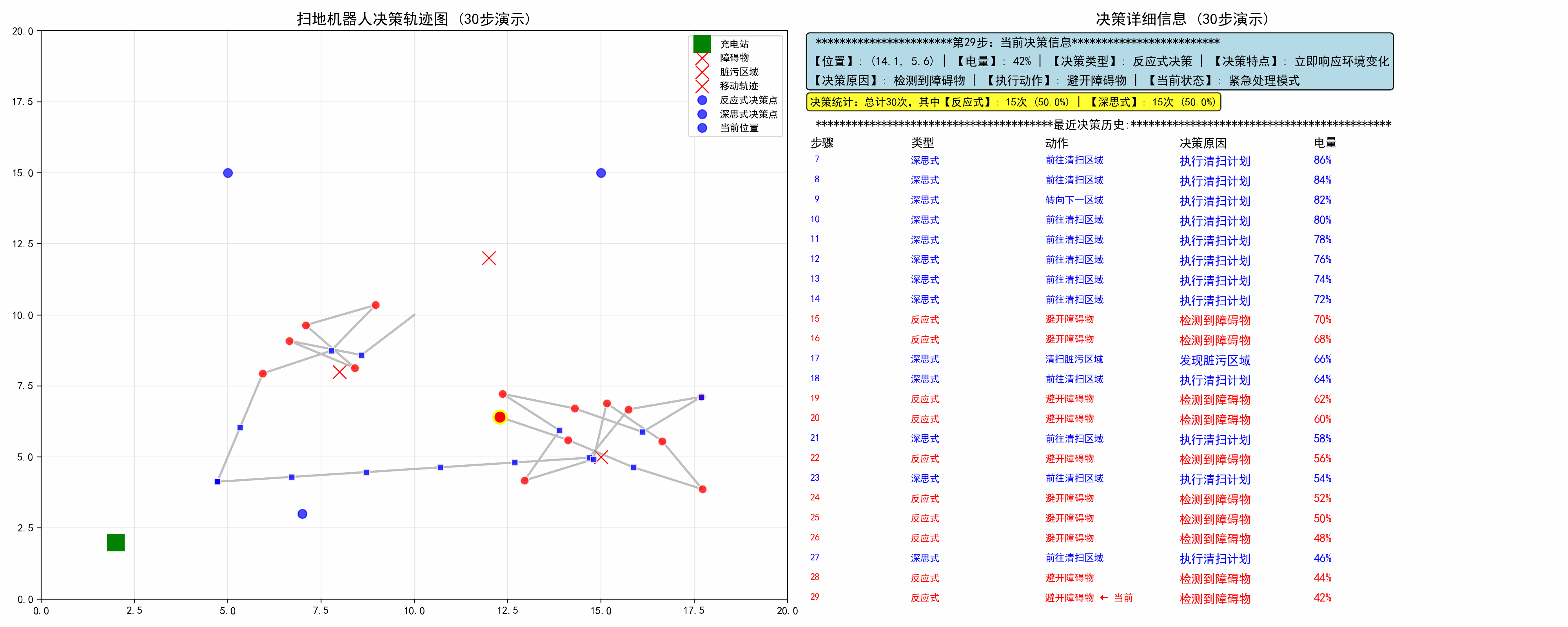
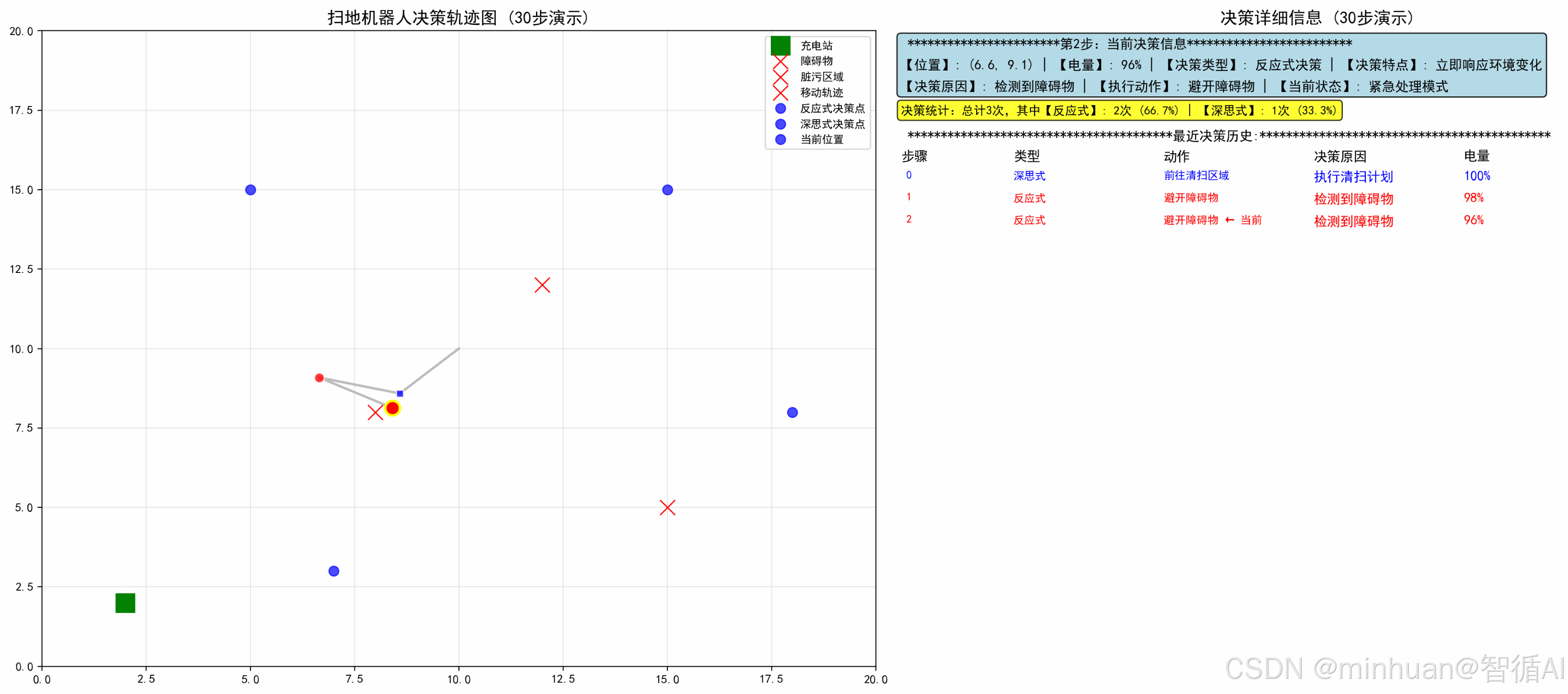
四、示例:扫地机器人的融合决策
示例实现了一个基于混合架构的扫地机器人智能决策系统,通过结合反应式决策和深思式决策两种模式,模拟了智能机器人在动态环境中的自主行为。系统包含完整的感知、决策、执行循环,并提供实时可视化。
- 示例运用混合决策架构,包括反应层处理紧急情况,保证生存和安全,同时深思层执行优化任务,提高效率,运用优先级仲裁,反应式可中断深思式决策
- 包含完整的状态管理:环境状态感知、内部状态维护、历史记录追踪
- 支持多层次可视化:实时环境地图、决策过程追踪、统计分析显示以及动画记录功能
1. 代码分解
1.1 导入库和基础设置
import matplotlib.pyplot as plt
import numpy as np
import random
import math
from matplotlib.animation import FuncAnimation, PillowWriter
import copyplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False功能说明:
- matplotlib:用于数据可视化和动画生成
- numpy:数学计算和数组操作
- random:生成随机数用于避障行为
- math:数学函数计算
- FuncAnimation, PillowWriter:GIF动画生成
- copy:深拷贝对象状态
- 中文字体设置:确保图表能正确显示中文
1.2 初始化方法
def __init__(self):self.position = [10, 10] # 初始位置self.battery = 100 # 初始电量self.step_count = 0 # 步数计数器self.is_charging = False # 充电状态# 环境设置self.room_size = 20self.charging_station = [2, 2]self.obstacles = [(8, 8), (12, 12), (15, 5)]self.dirty_spots = [(5, 15), (15, 15), (7, 3), (18, 8)]# 决策记录self.decision_history = []self.position_history = [self.position.copy()]# 路径规划self.cleaning_plan = []self.current_target_index = 0功能说明:
- 初始化机器人的所有状态变量
- 设置环境参数:房间大小、充电站、障碍物、脏污点位置
- 创建历史记录数据结构,用于追踪和分析决策过程
1.3 感知环境方法
def perceive_environment(self):sensor_data = {"battery_low": self.battery < 20,"near_obstacle": self.check_near_obstacle(),"at_charging_station": self.distance_to(self.charging_station) < 2,"on_dirty_spot": self.check_on_dirty_spot(),"near_boundary": self.check_near_boundary()}return sensor_data功能说明:
- 模拟机器人的传感器系统
- 检测5种关键环境状态:
- 低电量警告(<20%)
- 靠近障碍物
- 到达充电站
- 位于脏污点上
- 靠近边界
1.4 混合决策引擎(核心)
def make_decision(self, sensor_data):decision = {"step": self.step_count,"position": self.position.copy(),"type": "", "reason": "", "action": "", "battery": self.battery}# 反应式决策(高优先级)if sensor_data["battery_low"] and not self.is_charging:decision["type"] = "反应式"decision["reason"] = "电量低于20%"decision["action"] = self.return_to_charge()elif sensor_data["near_obstacle"]:decision["type"] = "反应式"decision["reason"] = "检测到障碍物"decision["action"] = self.avoid_obstacle()elif sensor_data["near_boundary"]:decision["type"] = "反应式"decision["reason"] = "靠近边界"decision["action"] = self.avoid_boundary()# 深思式决策(正常情况)else:decision["type"] = "深思式"# ... 具体深思式决策逻辑功能说明:
- 优先级仲裁机制:反应式决策优先于深思式决策
- 反应式决策:处理紧急情况(安全、生存相关)
- 深思式决策:执行优化任务(效率、规划相关)
- 记录完整的决策信息用于分析和可视化
1.5 反应式决策方法
def avoid_obstacle(self):# 随机方向避开障碍物angle = random.uniform(0, 2 * math.pi)move_x = math.cos(angle) * 2move_y = math.sin(angle) * 2self.position[0] += move_xself.position[1] += move_yself.keep_in_bounds()return "避开障碍物"特点:
- 快速响应,不进行复杂计算
- 使用随机方向避免陷入局部循环
- 立即执行,保证安全性
1.6 深思式决策方法
def follow_cleaning_plan(self):if not self.cleaning_plan:self.generate_cleaning_plan()if self.current_target_index < len(self.cleaning_plan):target = self.cleaning_plan[self.current_target_index]if self.distance_to(target) < 1:self.current_target_index += 1return "转向下一区域"return self.move_toward(target, "前往清扫区域")return "规划新路径"特点:
- 基于内部状态和计划
- 系统性执行任务
- 考虑长期目标
1.7 世界状态更新
def update_world(self, action):self.step_count += 1# 耗电逻辑if not self.is_charging:self.battery = max(0, self.battery - 2)# 充电逻辑if (self.distance_to(self.charging_station) < 2 and (self.battery < 30 or self.is_charging)):self.is_charging = Trueself.position_history.append(self.position.copy())功能说明:
- 更新步数计数器
- 模拟电量消耗和充电过程
- 记录位置历史用于轨迹绘制
1.8 双面板显示设计
def __init__(self, save_gif=False):self.fig, (self.ax1, self.ax2) = plt.subplots(1, 2, figsize=(20, 8))self.save_gif = save_gifself.robot_states = []布局说明:
- 左侧面板(ax1):环境地图和机器人轨迹
- 右侧面板(ax2):决策信息和历史记录
- GIF支持:可选保存运行动画
1.9 环境地图绘制
def setup_display(self, robot, decision):# 绘制静态环境元素self.ax1.plot(robot.charging_station[0], robot.charging_station[1], 'gs', markersize=15, label='充电站')# 绘制轨迹线positions = np.array(robot.position_history)if len(positions) > 1:self.ax1.plot(positions[:, 0], positions[:, 1], 'gray', alpha=0.5, linewidth=2)# 标记决策点(颜色编码)for i, decision_point in enumerate(robot.decision_history):if decision_point["type"] == "反应式":color = 'red' # 红色表示反应式marker = 'o'else:color = 'blue' # 蓝色表示深思式marker = 's'可视化特性:
- 颜色编码:红色=反应式,蓝色=深思式
- 轨迹追踪:显示完整移动路径
- 决策点标记:在轨迹上标记每个决策位置
1.10 决策信息显示
def display_colored_history(self, robot, current_decision):# 创建决策历史表格history_ax = self.ax2.inset_axes([0, 0.05, 0.9, 0.5])# 表头:步骤、类型、动作、决策原因、电量history_ax.text(0, 1.525, "步骤", fontsize=11, fontweight='bold')# ... 其他表头# 数据行(颜色区分)for i, d in enumerate(robot.decision_history[-15:]):if d['type'] == "反应式":text_color = 'red'else:text_color = 'blue'信息展示:
- 结构化显示最近25条决策记录
- 实时统计两种决策类型的比例
- 突出显示当前决策步骤
1.11 动画生成系统
def update_display(self, robot, decision):if self.save_gif:# 保存机器人的深拷贝状态robot_copy = robot.deep_copy()self.robot_states.append({'robot': robot_copy,'decision': decision.copy()})功能说明:
- 状态保存:每一步保存机器人的完整状态深拷贝
- 帧重建:使用保存的状态重新绘制每一帧
- 动画合成:将所有帧合成为GIF文件
1.12 主流程演示
def run_demonstration(save_gif=False):robot = CleaningRobot()viz = RobotVisualization(save_gif=save_gif)# 运行30步演示for step in range(30):# 感知-决策-行动循环sensor_data = robot.perceive_environment()decision = robot.make_decision(sensor_data)viz.update_display(robot, decision)# 生成统计报告reactive_count = sum(1 for d in robot.decision_history if d['type'] == "反应式")deliberative_count = sum(1 for d in robot.decision_history if d['type'] == "深思式")演示流程:
- 初始化机器人和可视化系统
- 执行30次完整的感知-决策-行动循环
- 实时更新可视化显示
- 生成最终统计报告
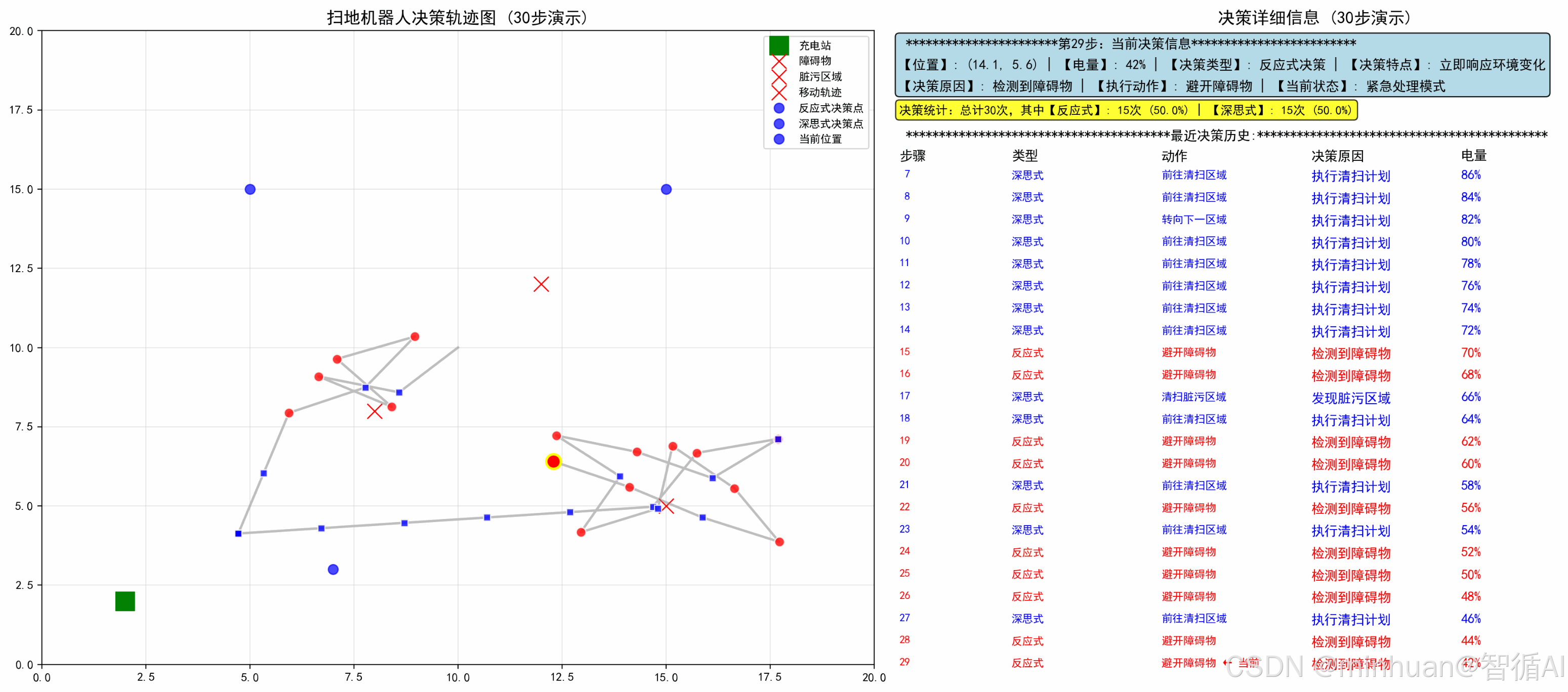
2. 输出结果
======================================================================
扫地机器人决策类型演示系统 (30步演示)
======================================================================
开始30步决策演示...
----------------------------------------------------------------------
步骤 0: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤 1: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤 2: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤 3: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤 4: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤 5: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤 6: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤 7: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤 8: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤 9: 🔵 深思式 | 执行清扫计划 | 转向下一区域
步骤10: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤11: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤12: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤13: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤14: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤15: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤16: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤17: 🔵 深思式 | 发现脏污区域 | 清扫脏污区域
步骤18: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤19: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤20: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤21: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤22: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤23: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤24: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤25: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤26: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤27: 🔵 深思式 | 执行清扫计划 | 前往清扫区域
步骤28: 🔴 反应式 | 检测到障碍物 | 避开障碍物
步骤29: 🔴 反应式 | 检测到障碍物 | 避开障碍物
======================================================================
演示统计报告 (30步)
======================================================================
总决策步数: 30
🔴 反应式决策: 15 次 (50.0%)
🔵 深思式决策: 15 次 (50.0%)
剩余脏污点: 3 个
最终电量: 40%
最终位置: (12.3, 6.4)
======================================================================
五、总结
将反应式与深思熟虑式智能体相结合,构建的分层混合架构,代表了当前复杂环境下AI系统设计的主流方向。它成功地将“快”与“慢”、“直觉”与“理性”统一在一个系统中。
混合式智能体的价值在于它告诉我们:真正的智能不是选择"快"还是"聪明",而是知道在什么情况下应该"快",在什么情况下应该"聪明",以及如何在这两种模式间无缝切换。这种情境感知的元决策能力,才是高级智能的真正体现。
随着人工智能技术的不断发展,混合式架构将继续演进,融入更多的学习能力和适应性,为构建真正智能、可靠、实用的自主系统提供坚实的技术基础。