AI大模型微调教程6
https://www.bilibili.com/video/BV1r9ieYhEuZ?spm_id_from=333.788.videopod.episodes&vd_source=3969f30b089463e19db0cc5e8fe4583a&p=22
1、目录

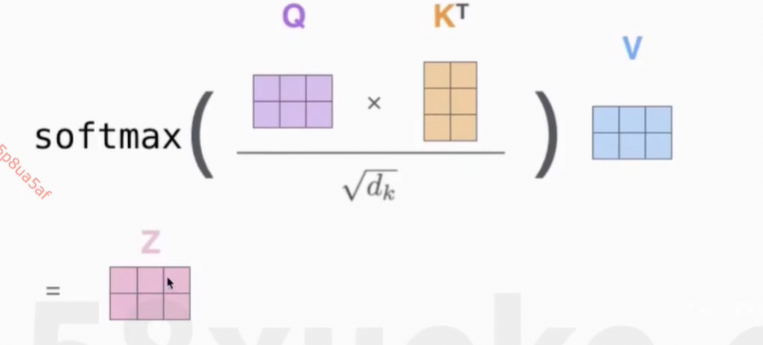
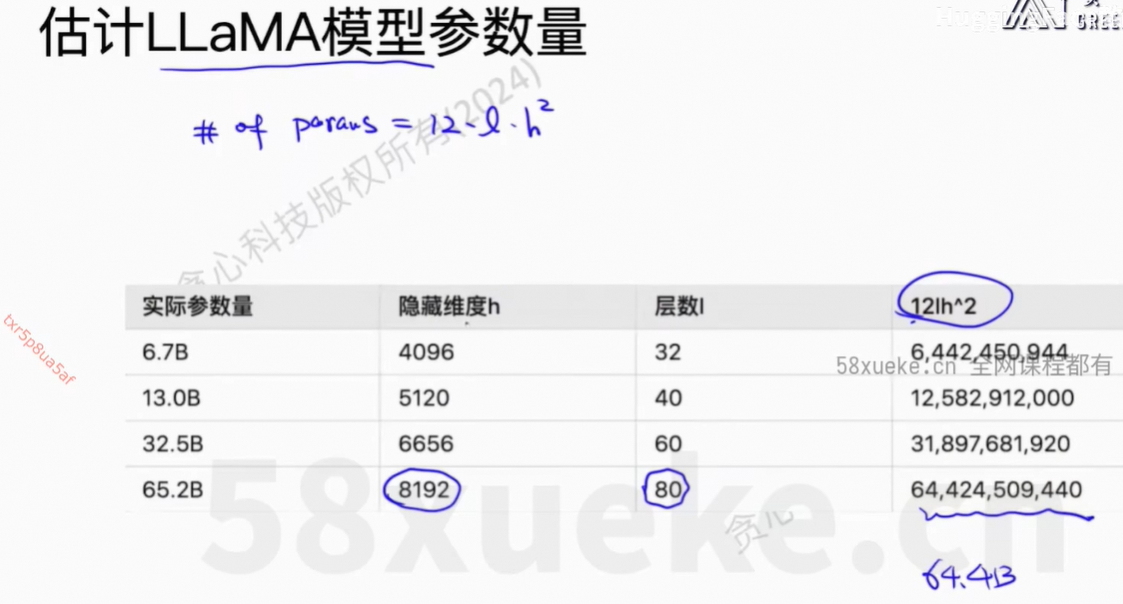
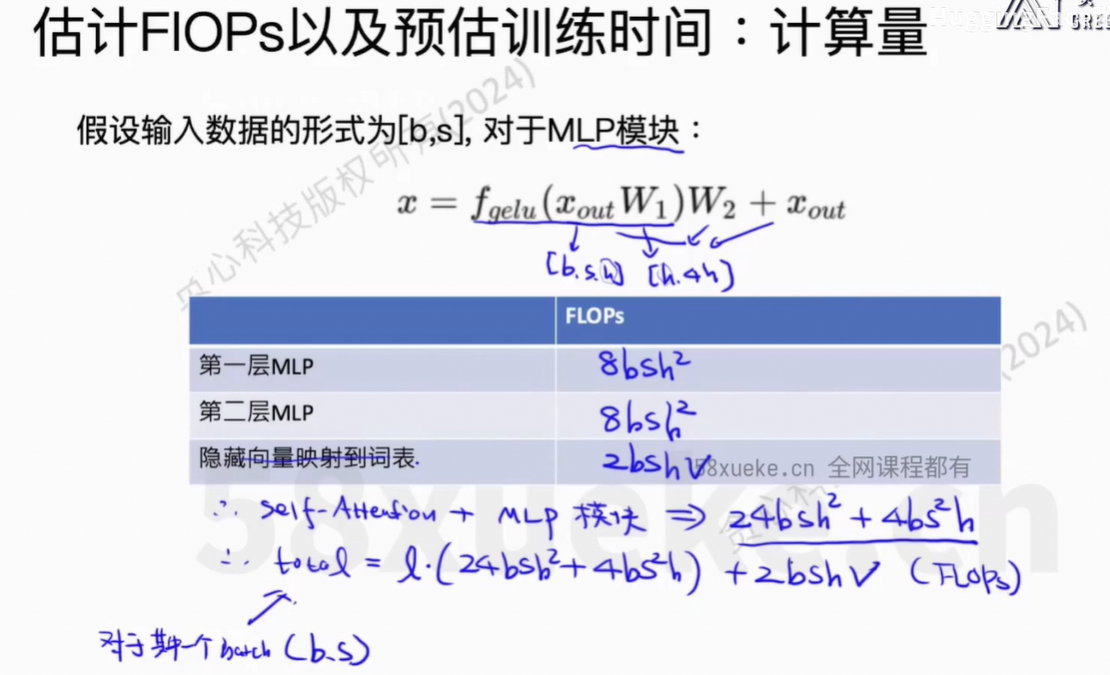
2、GPU时间计算






3、Distributed Computing
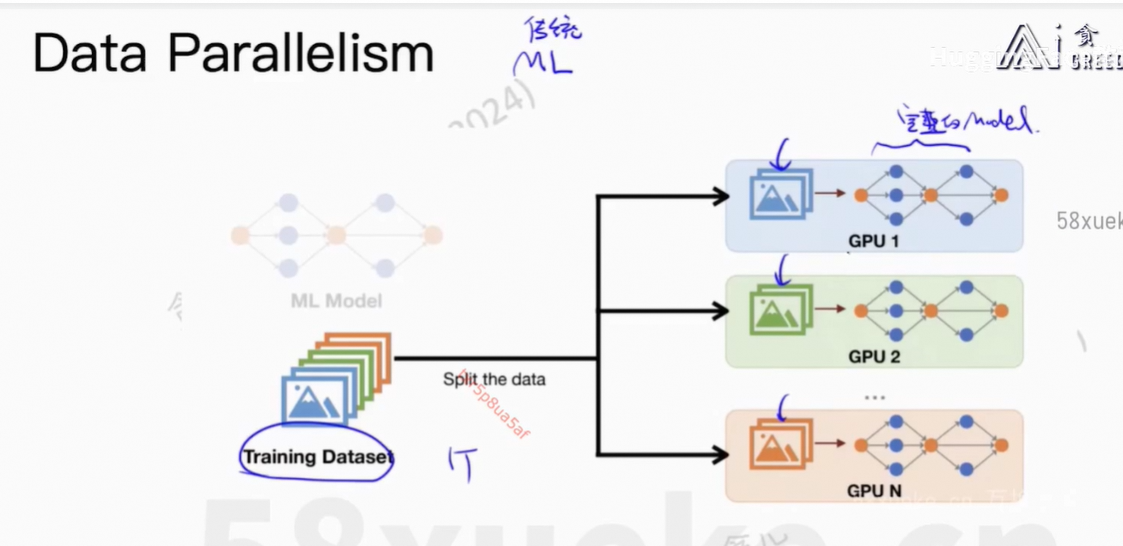
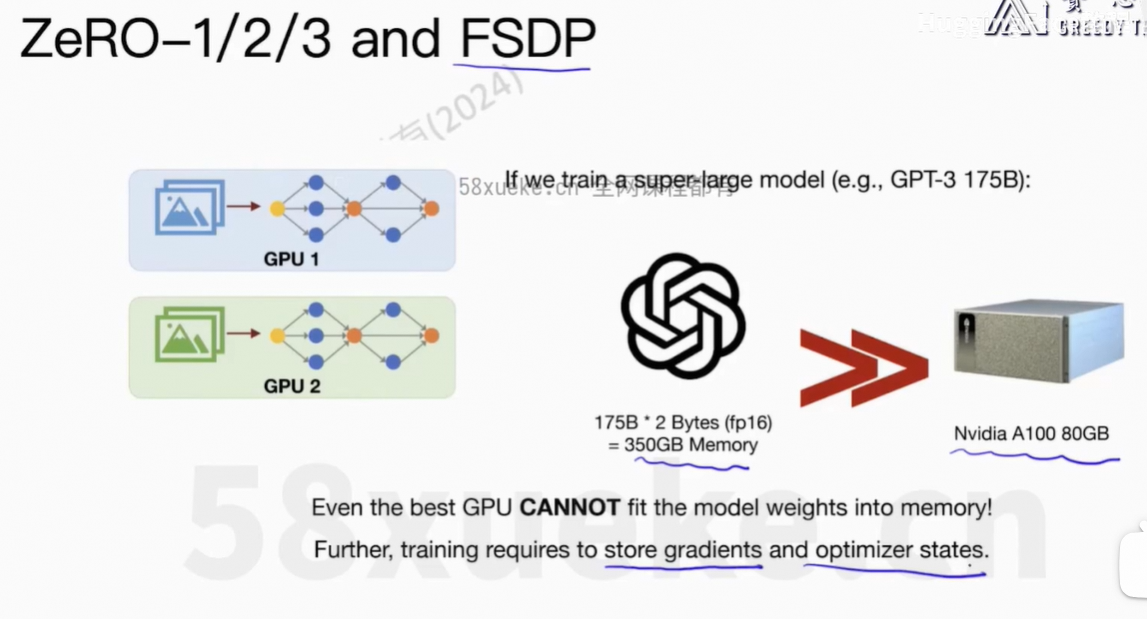
训练大模型的时候,没法在每张GPU上把完整的模型存下来,这个是有问题的。
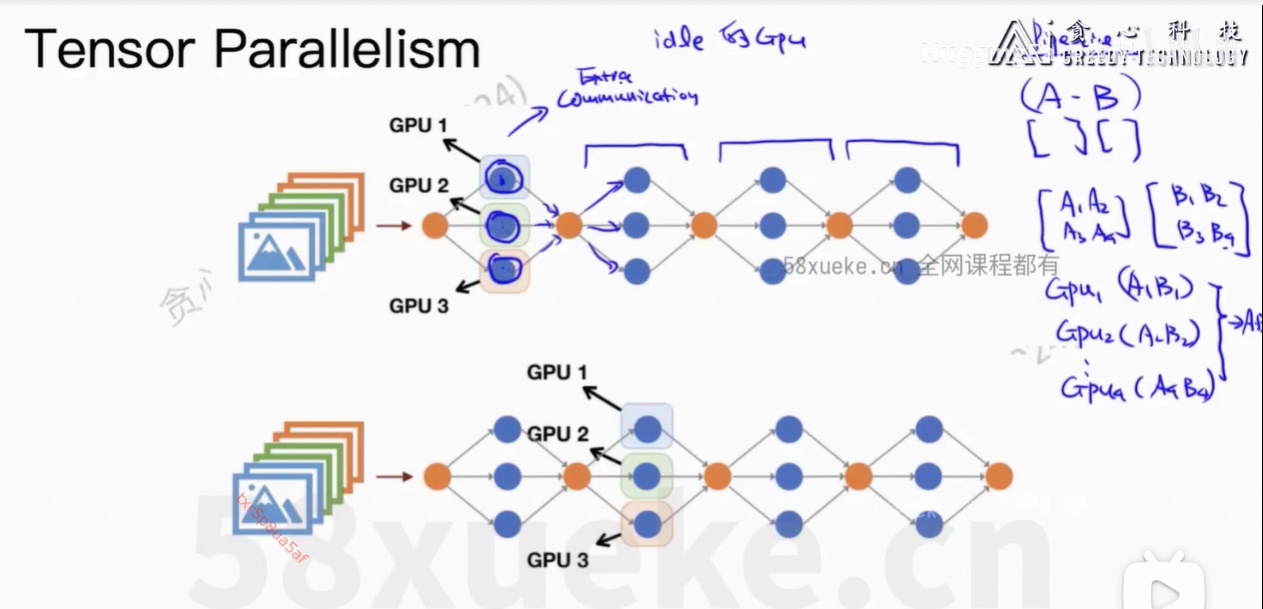
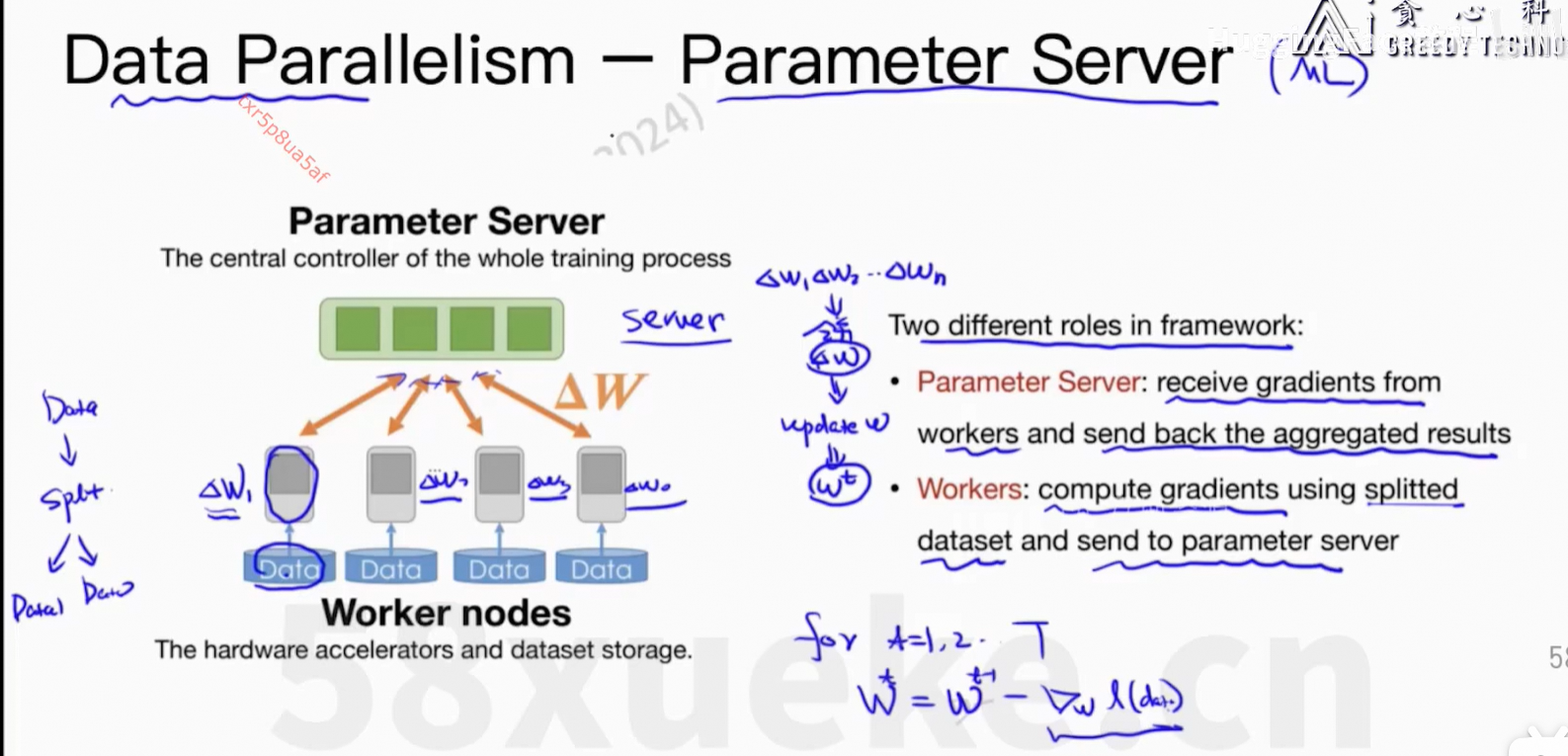
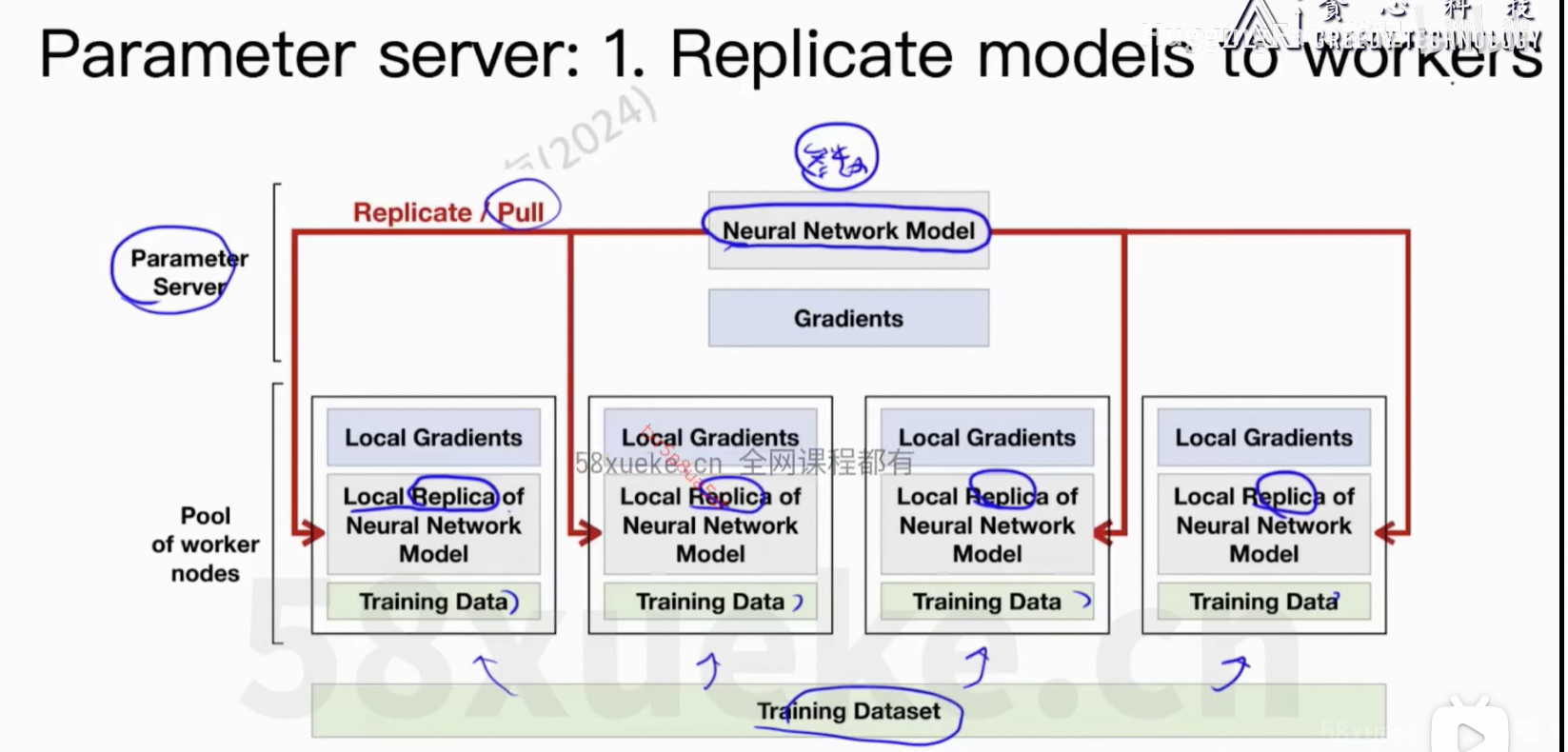
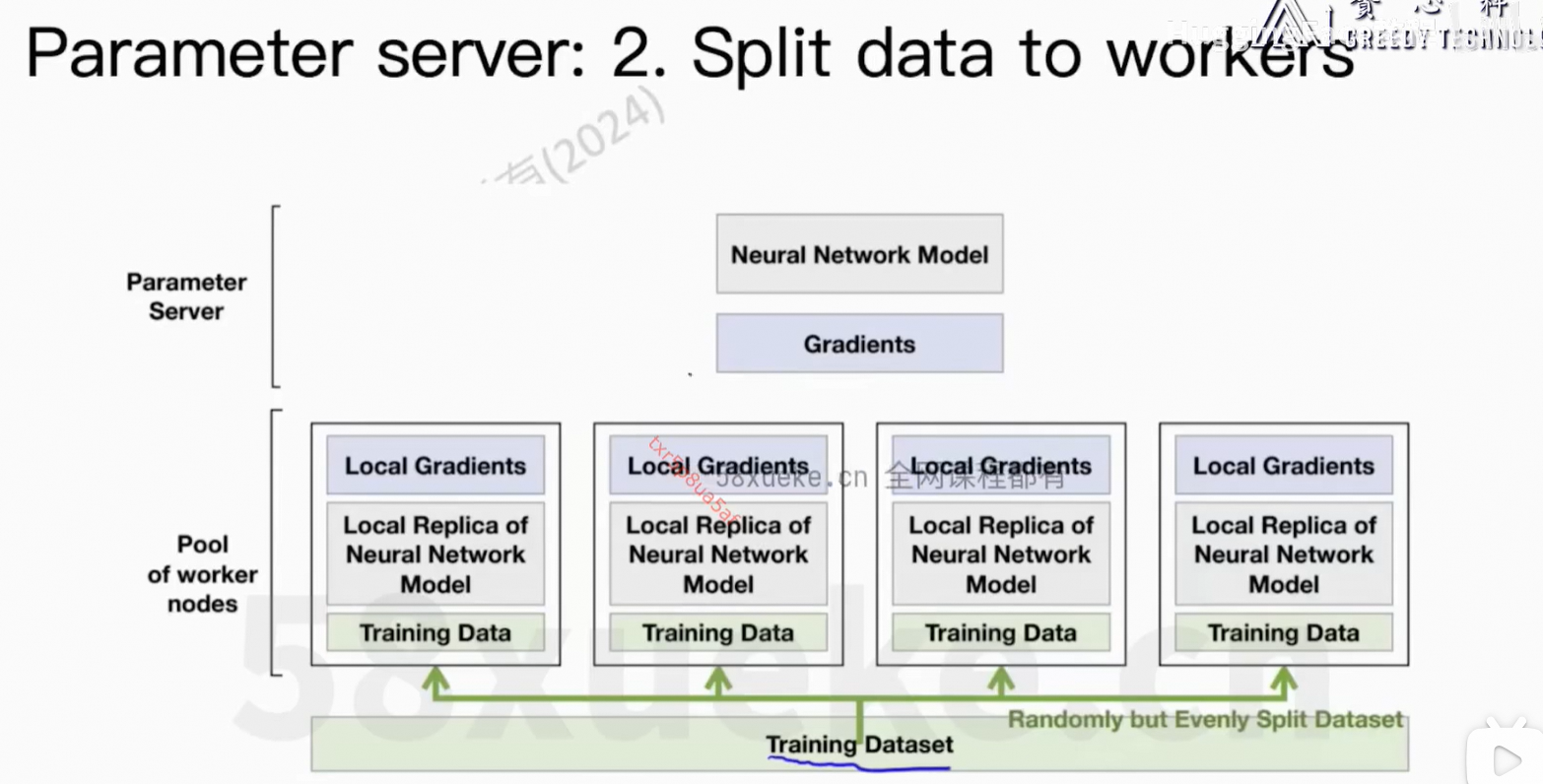
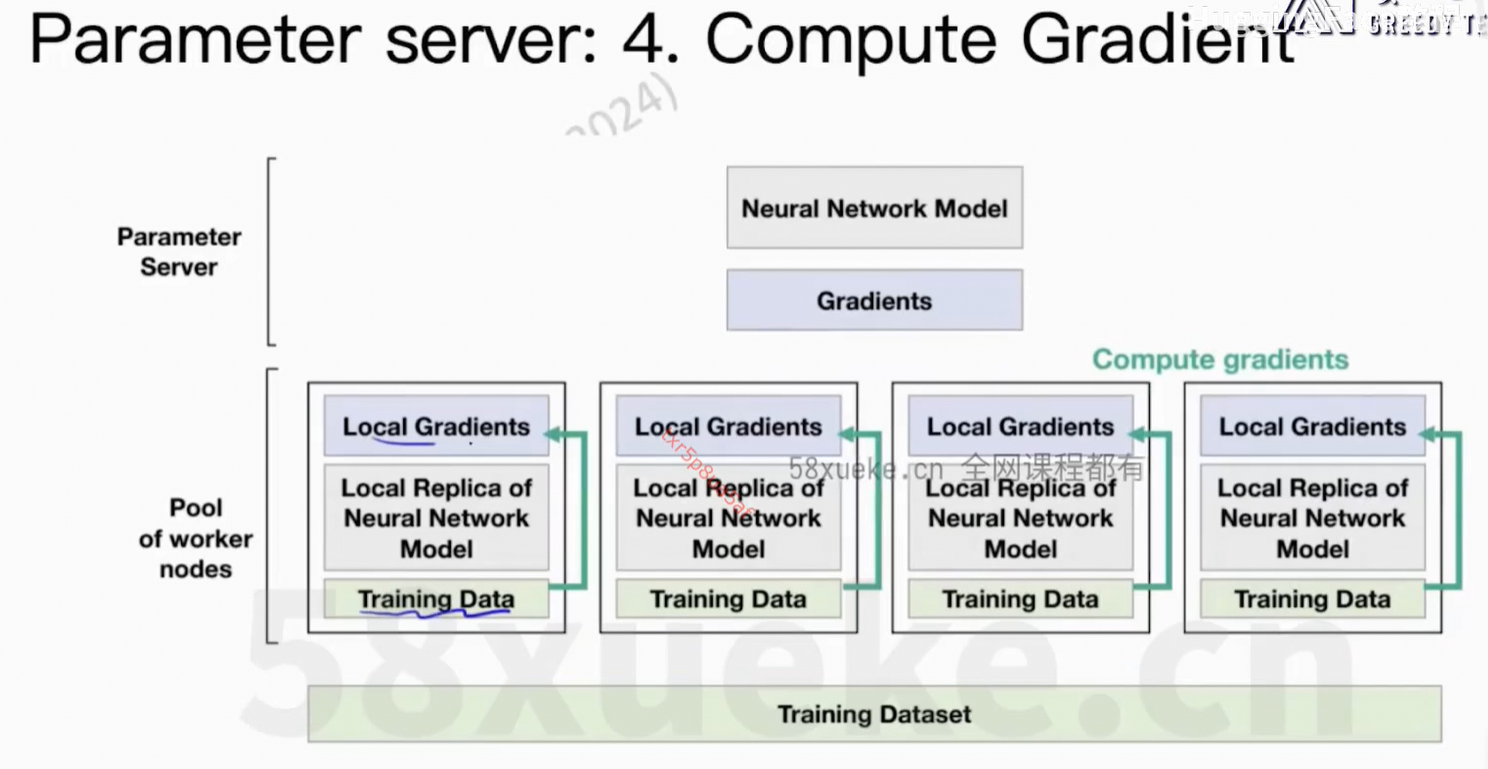
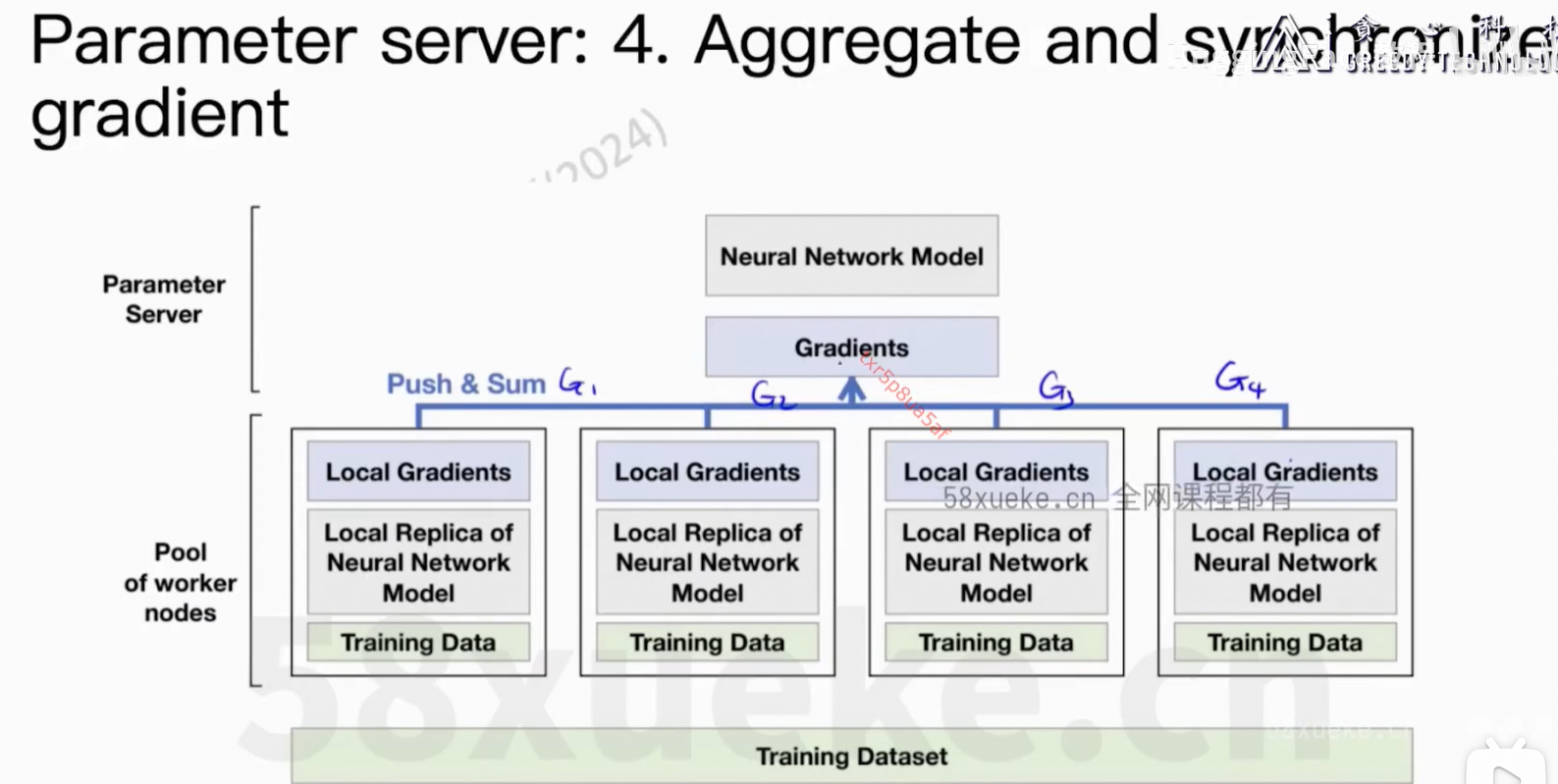
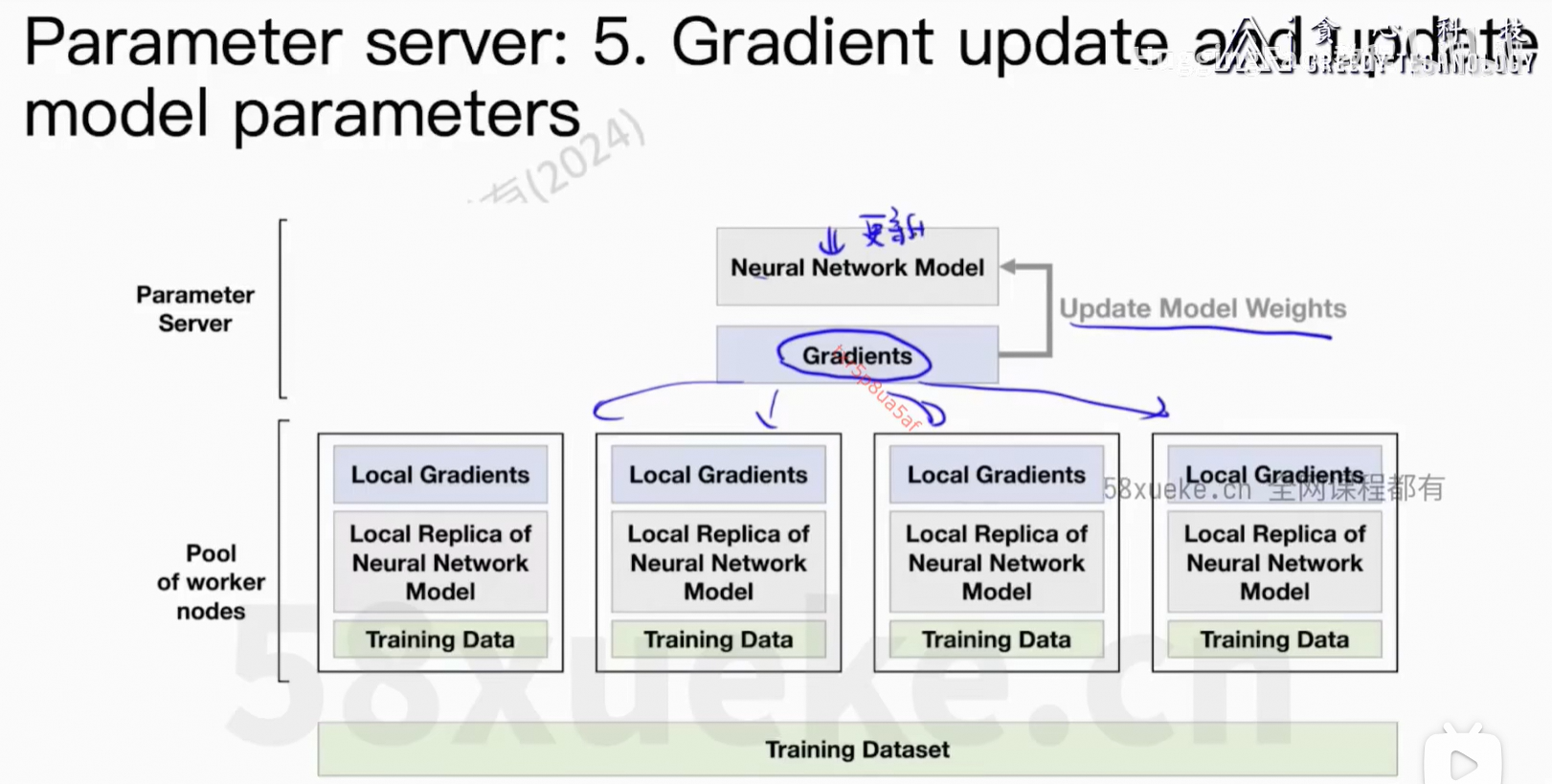
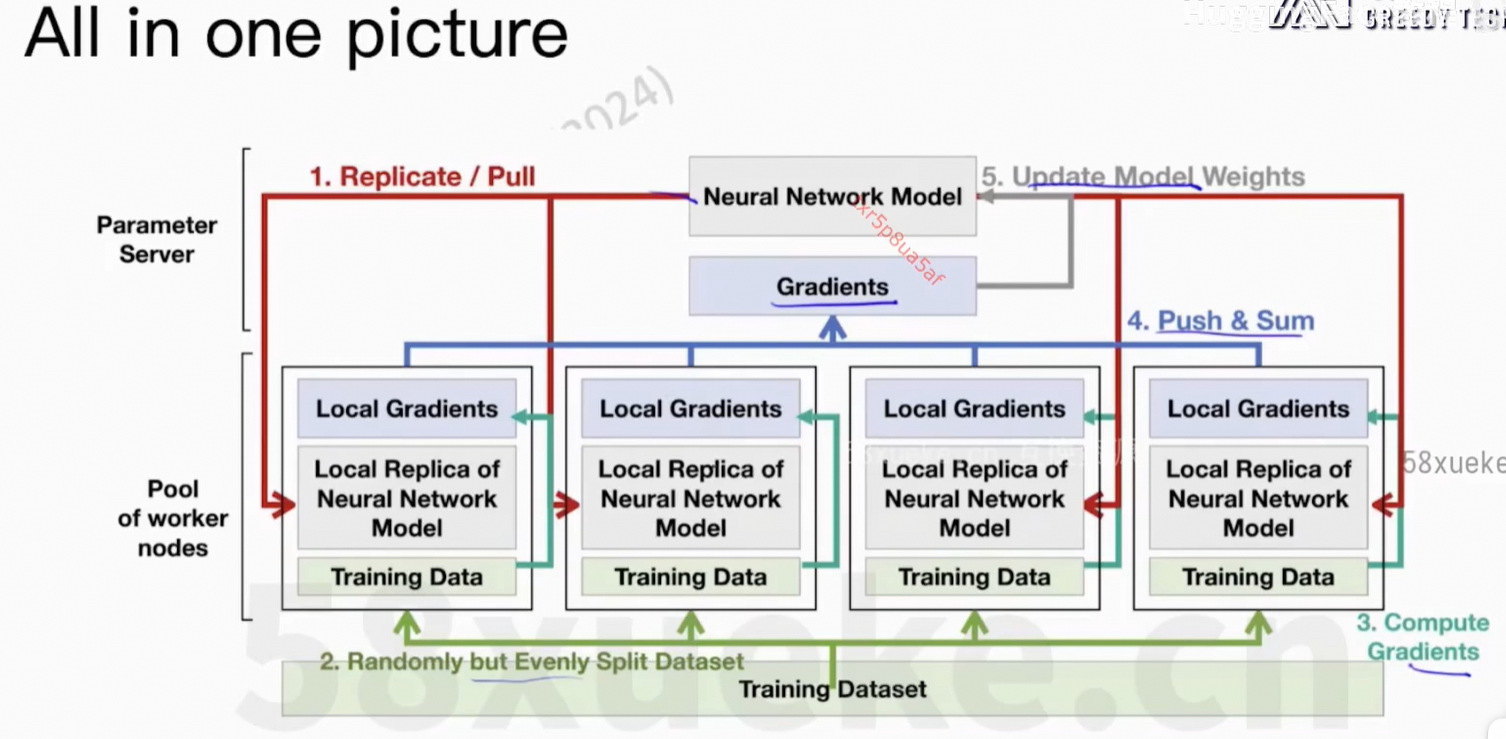


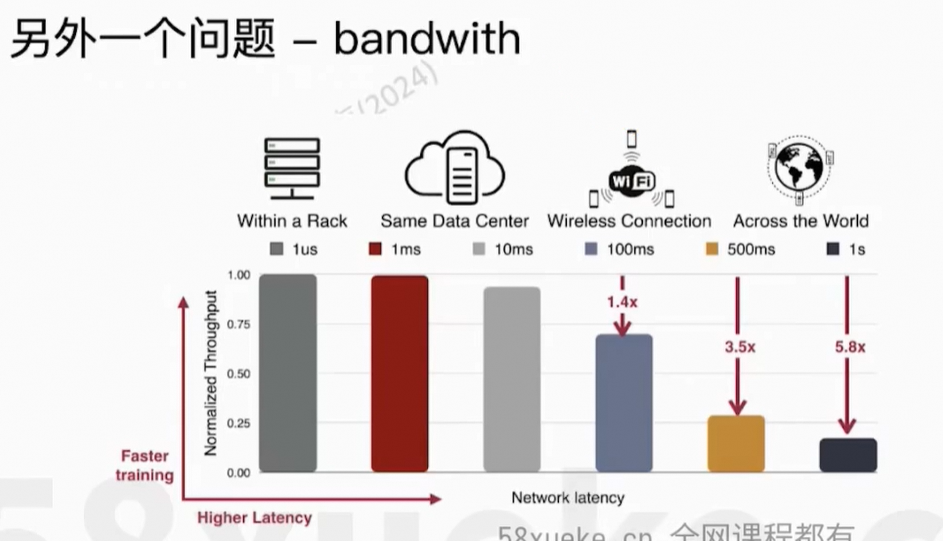
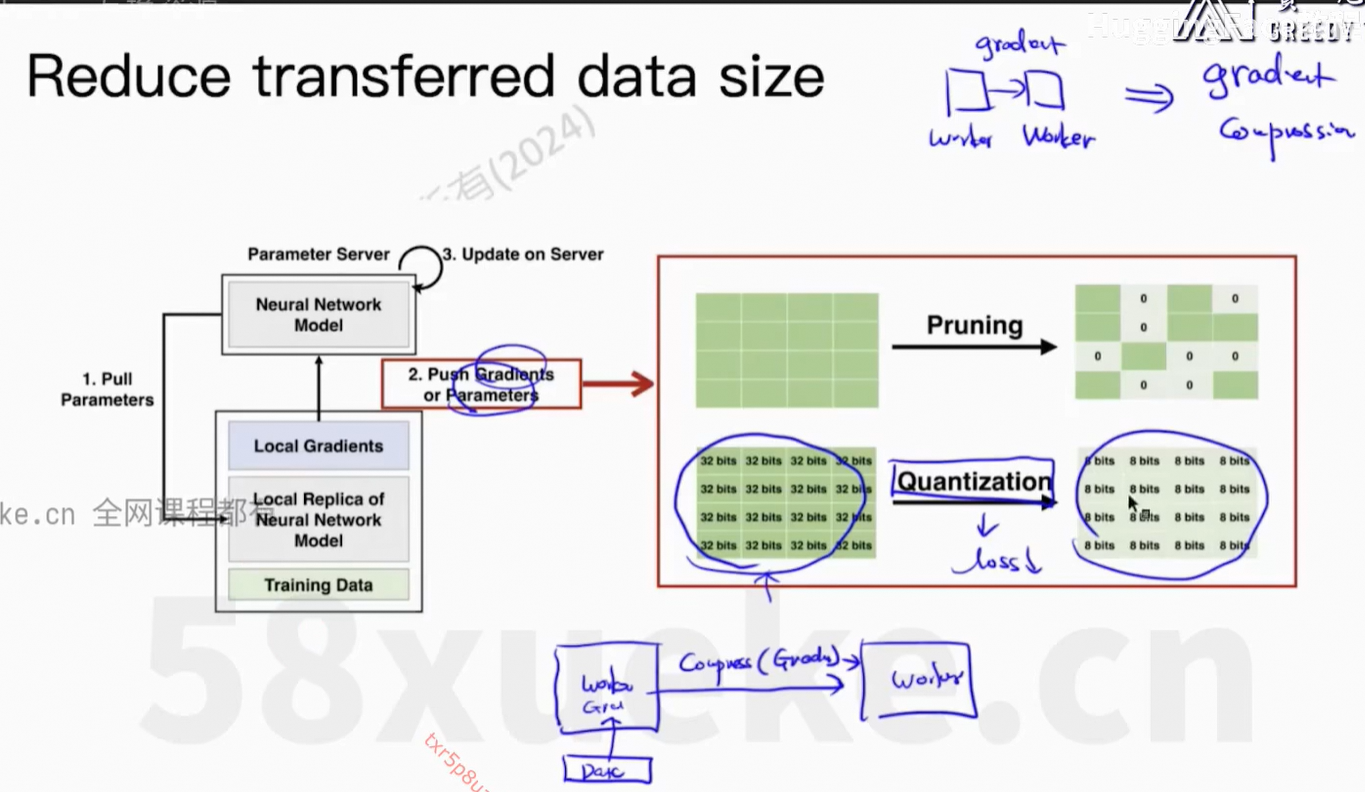
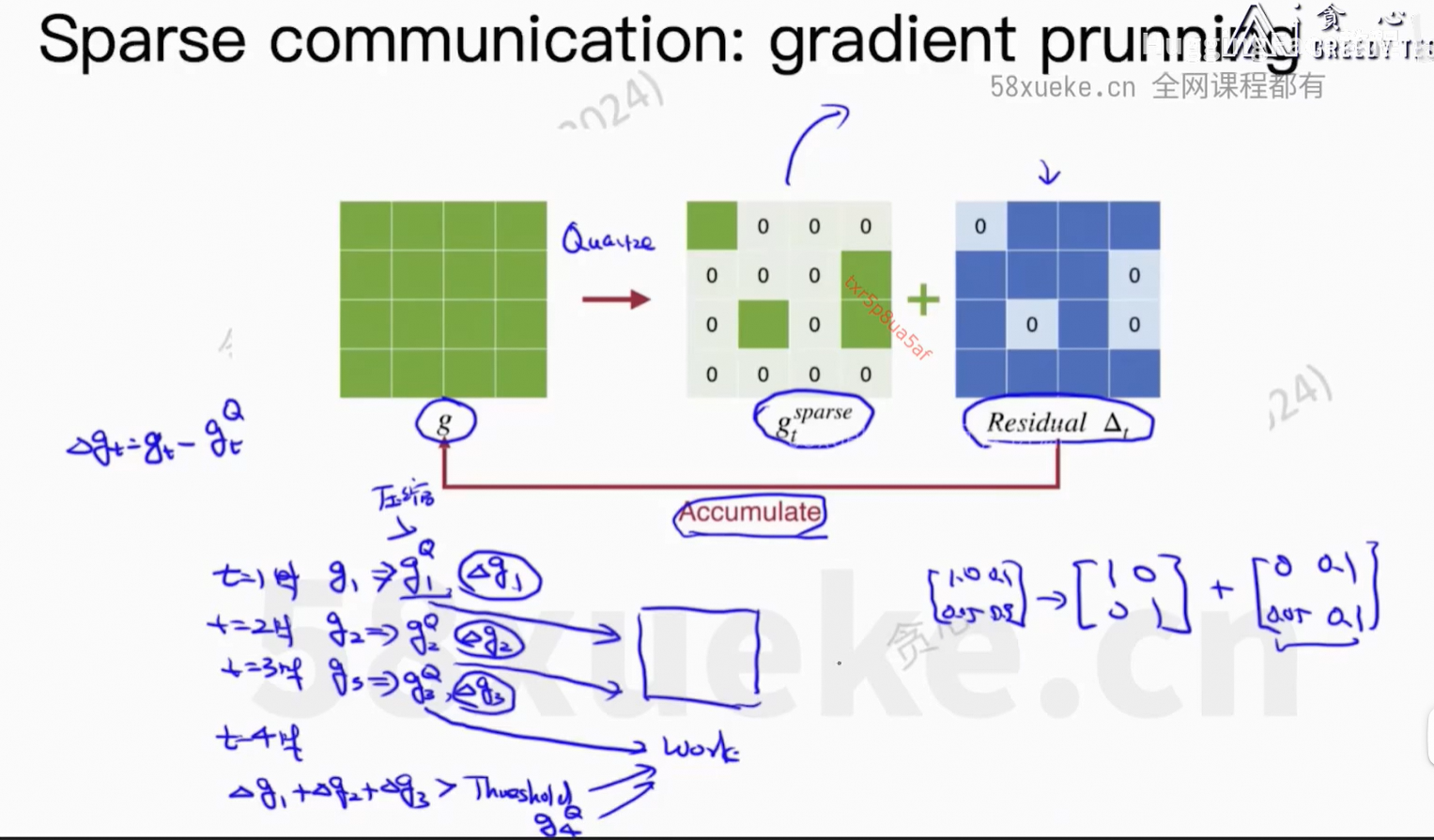
通信上的开销。
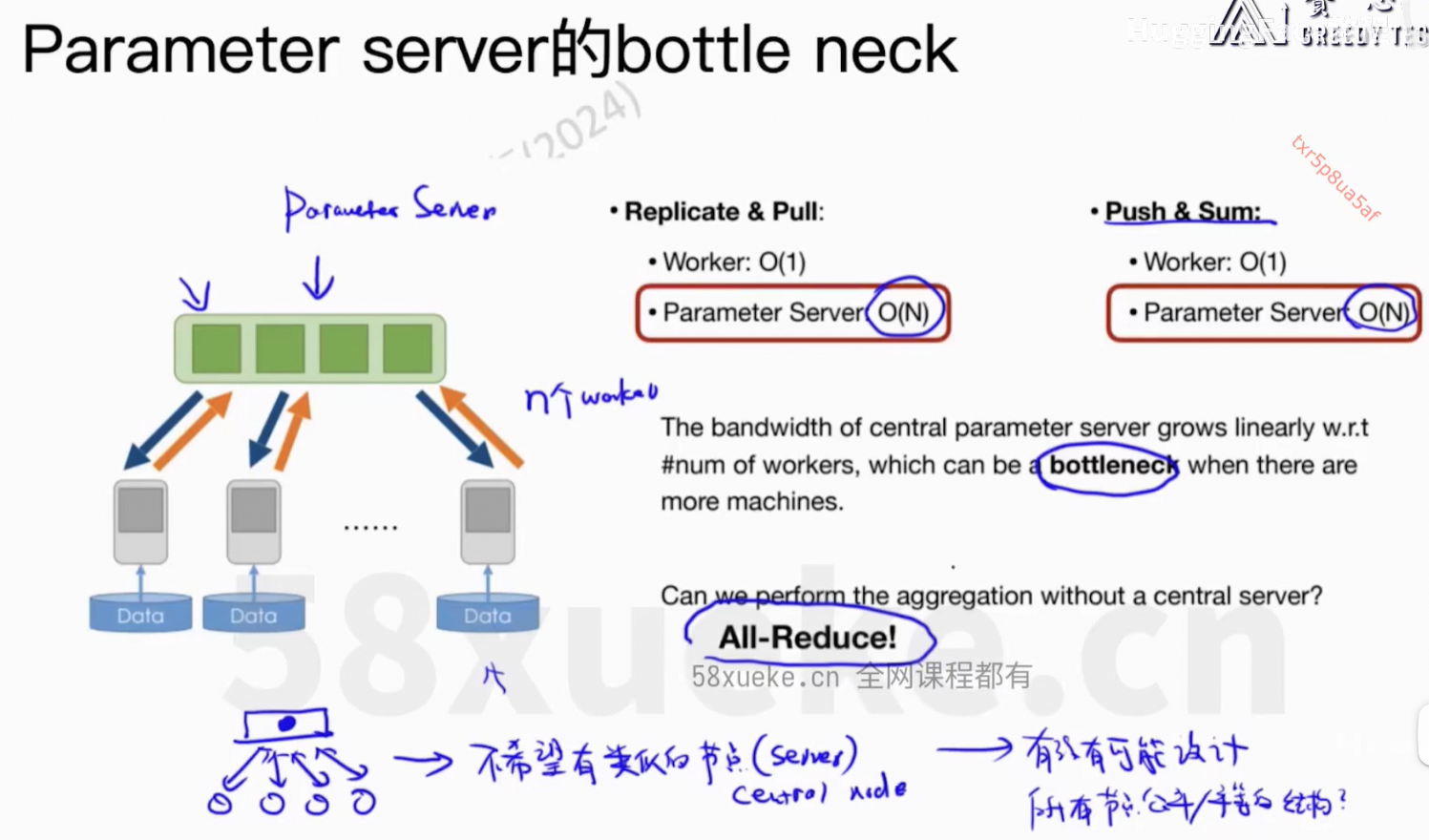
Parameter Server活太多成了瓶颈。
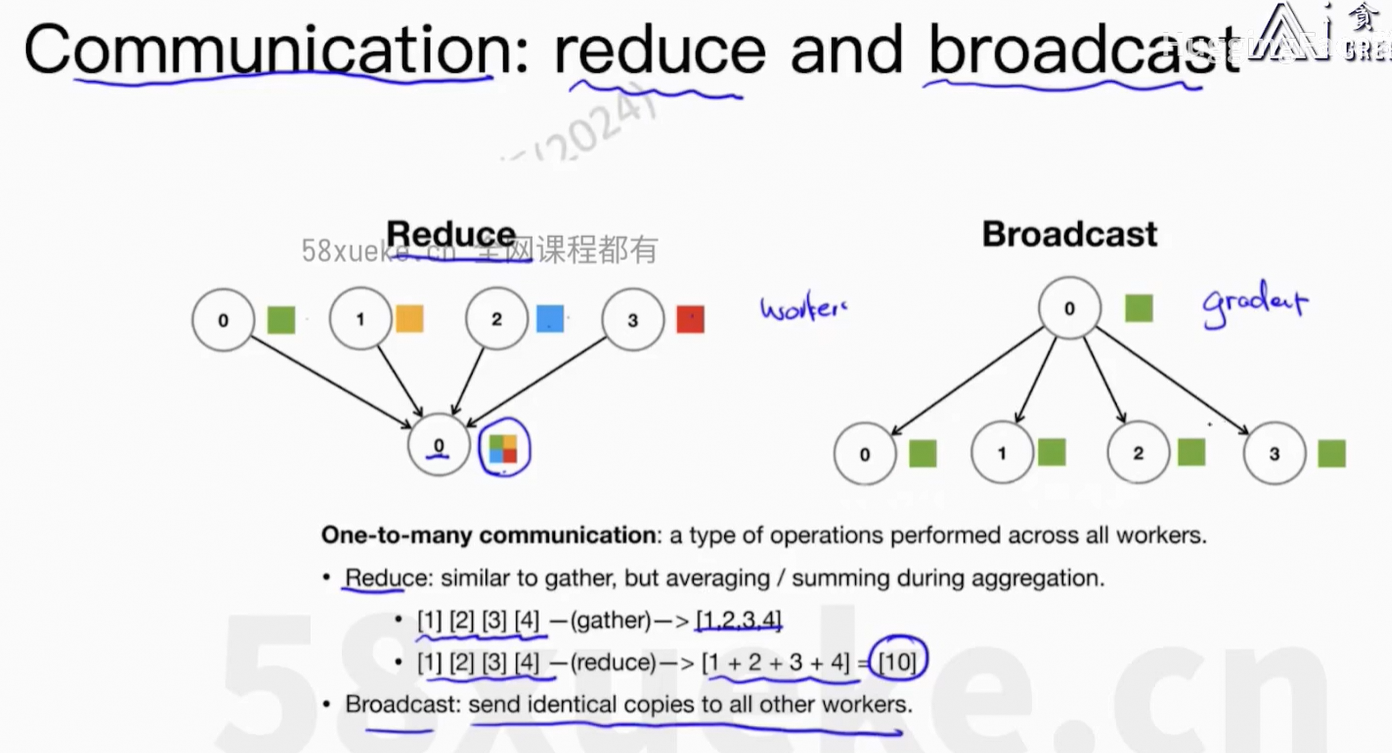
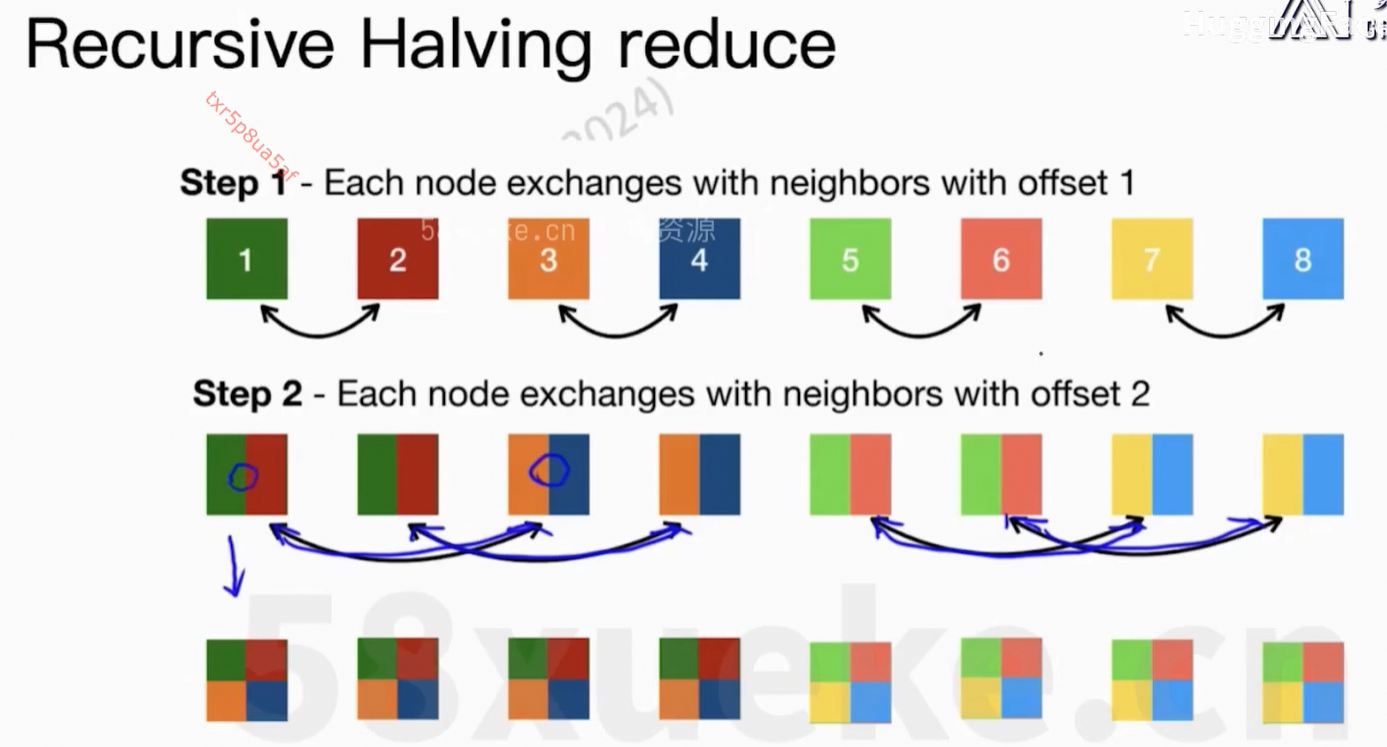
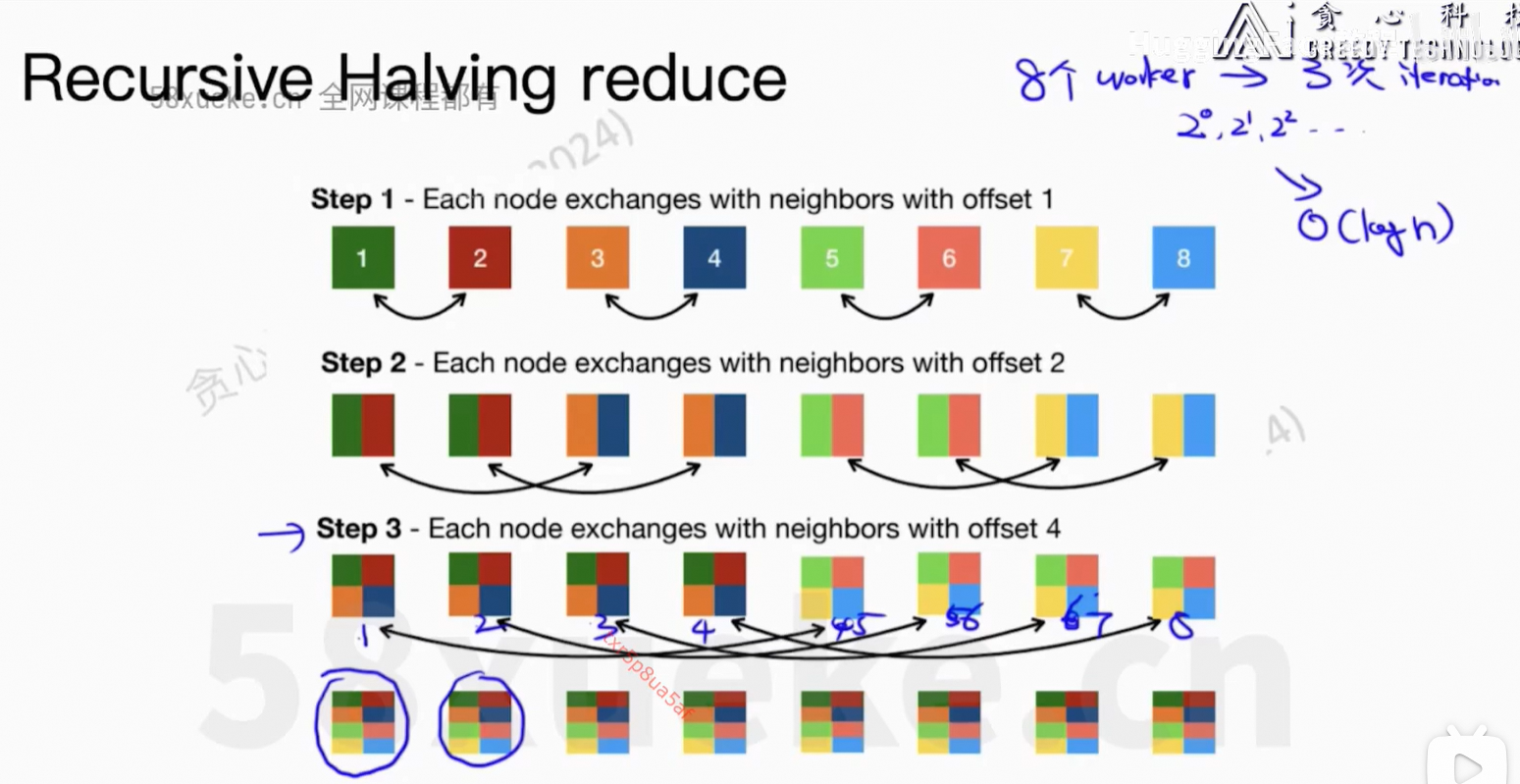
核心问题:每个worker上的信息可以同步到所有节点上。
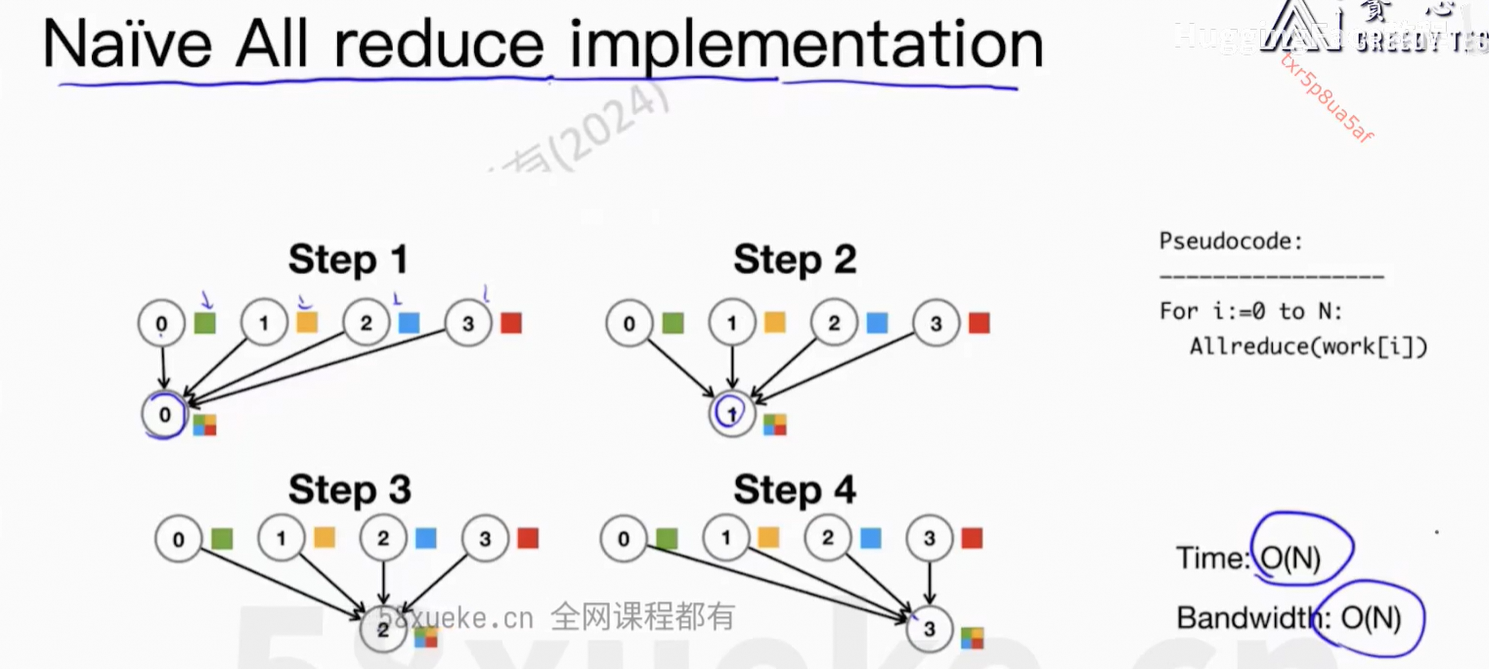
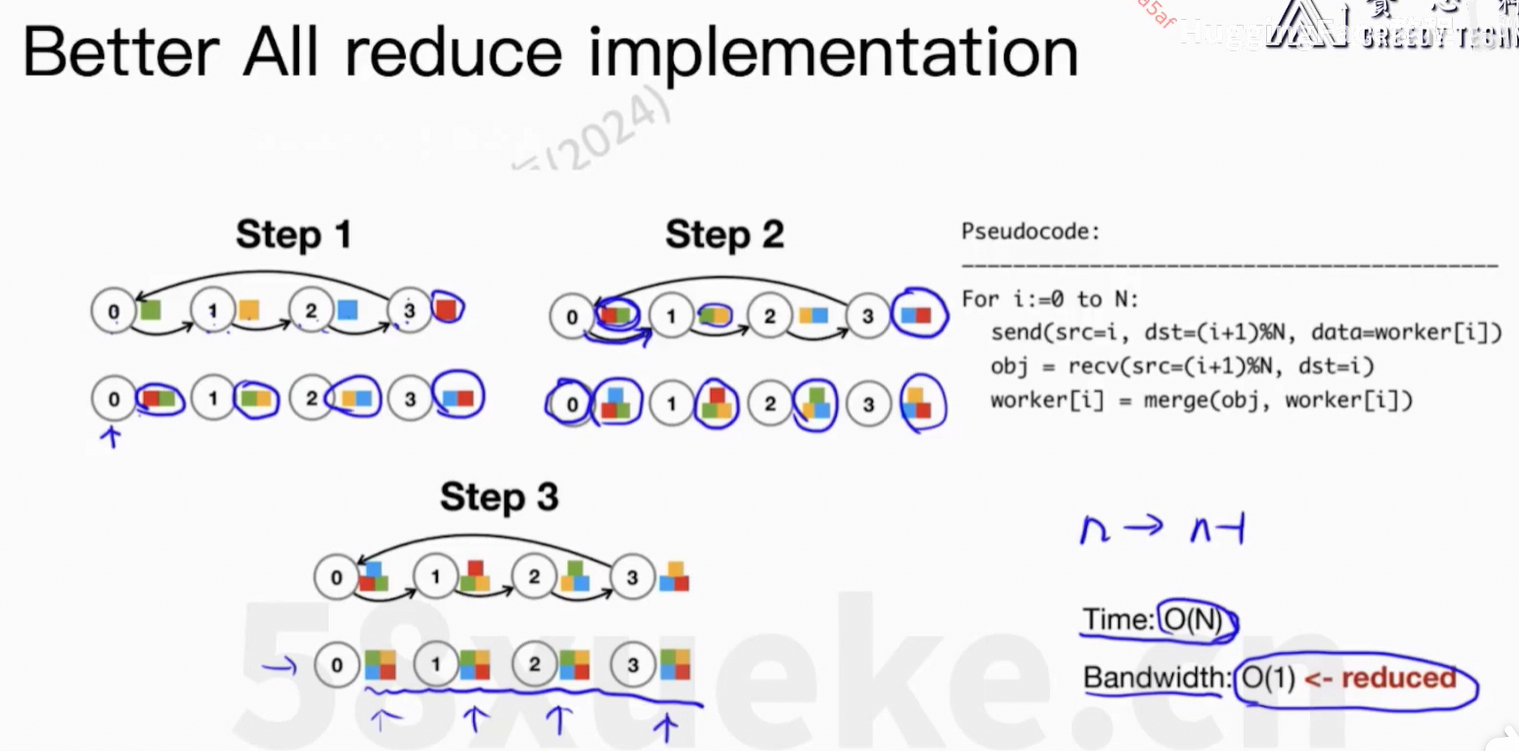
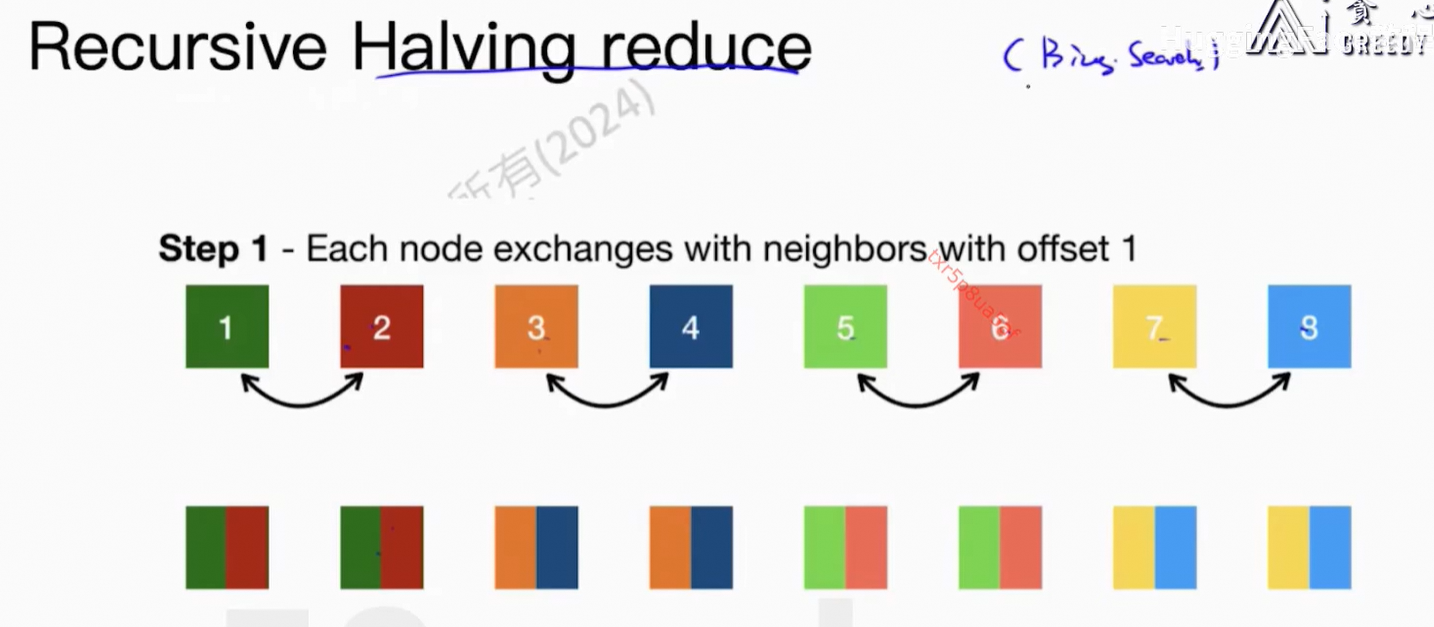
4、ZeRO-1/2/3 and FSDP

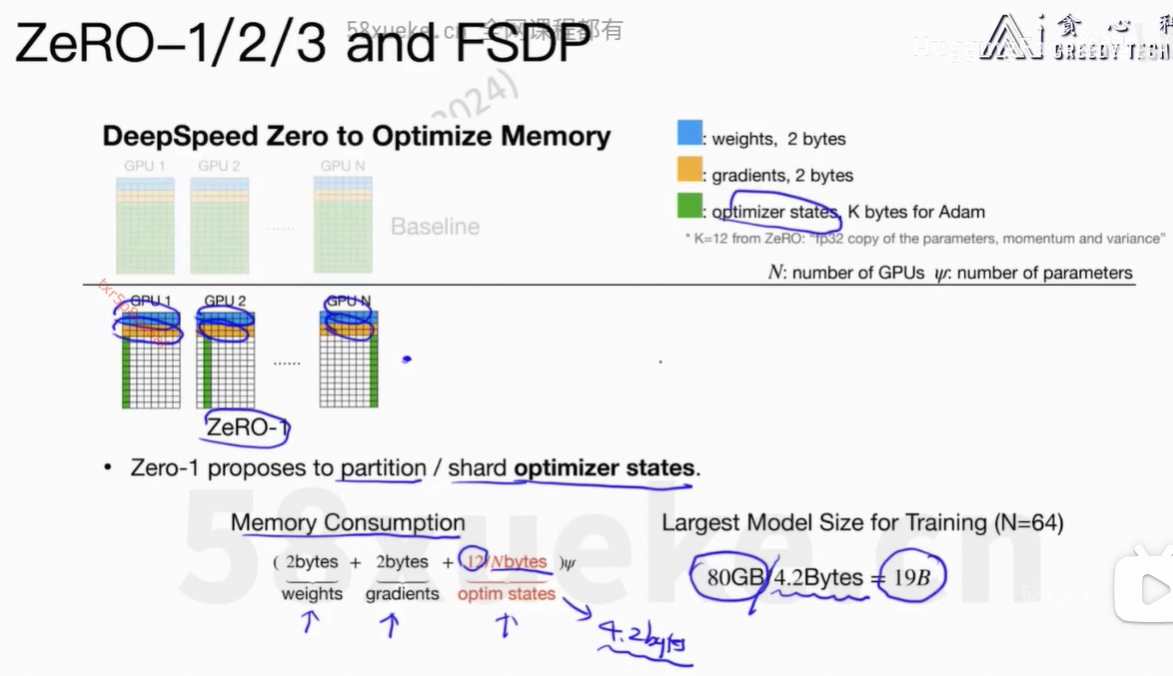
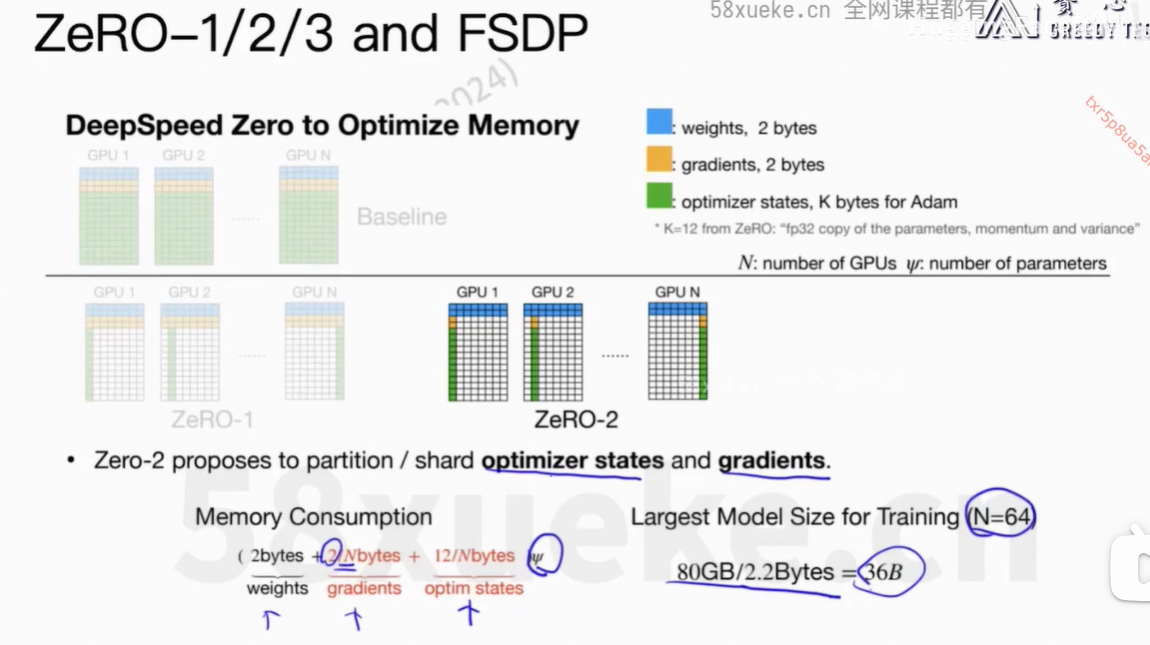

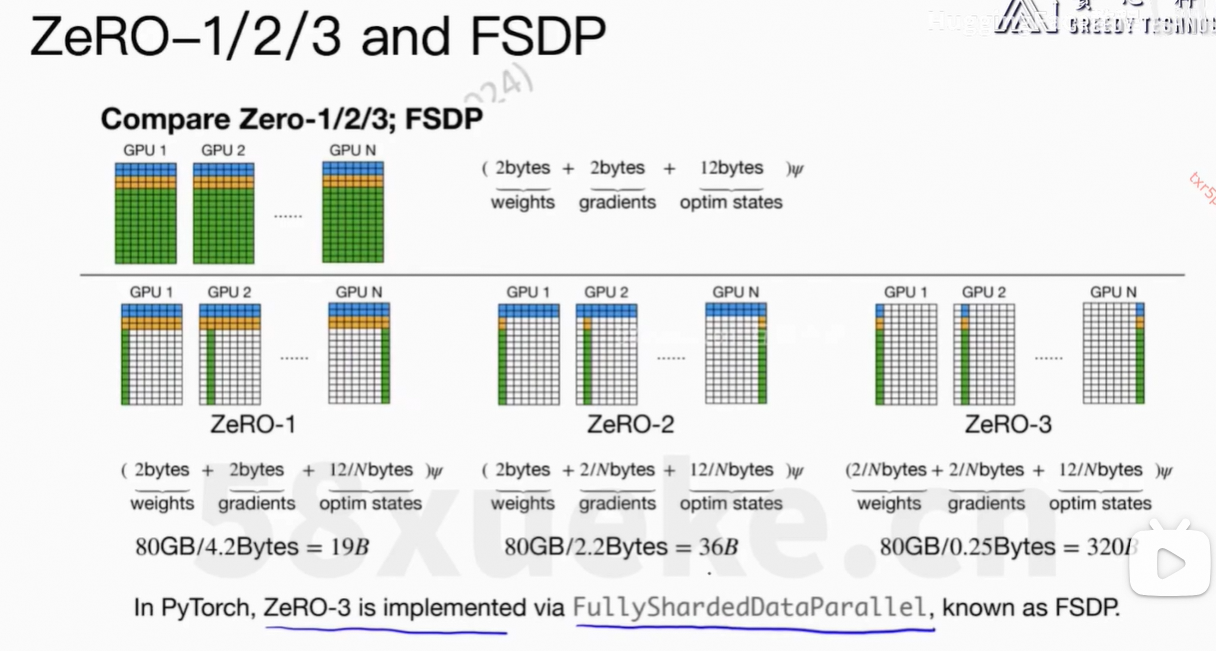
上面的逻辑在deepspeed的代码中。
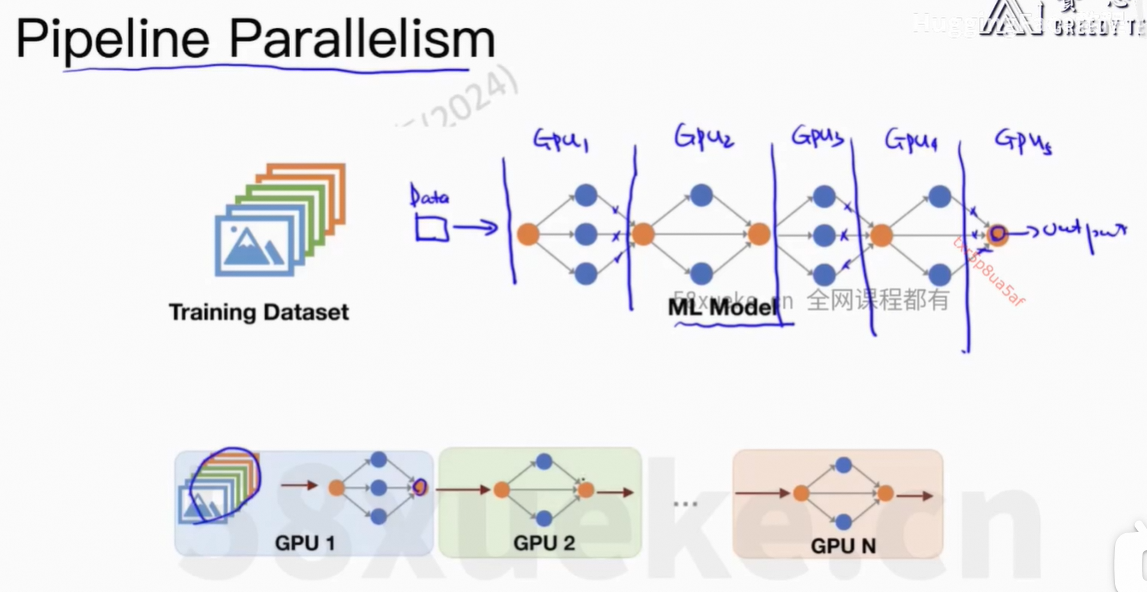
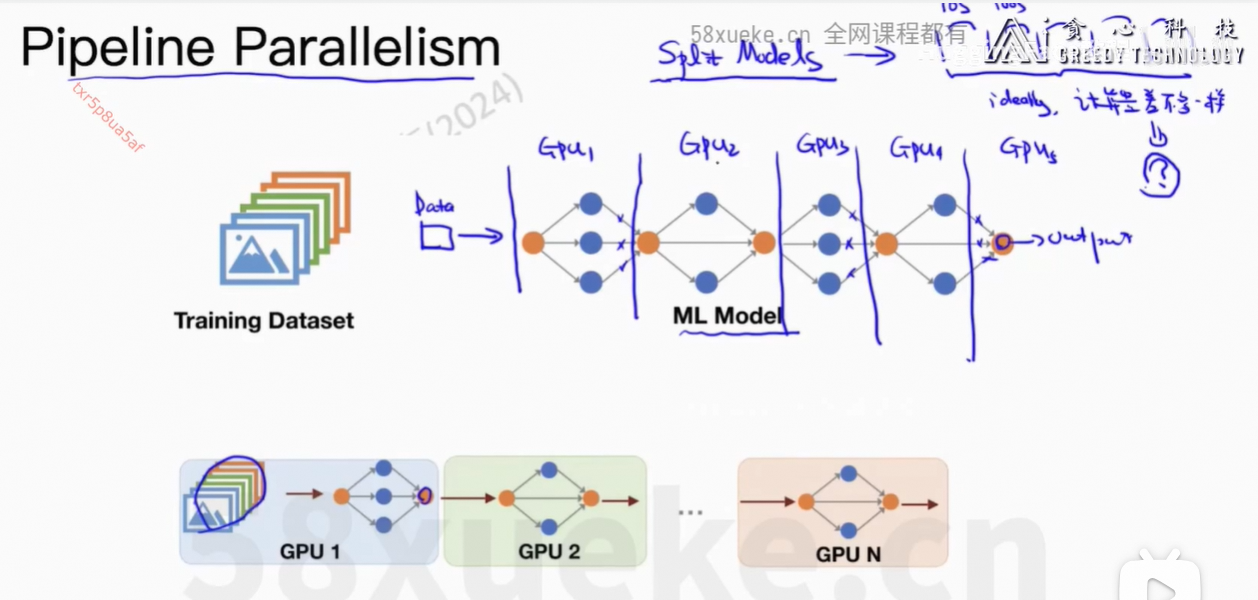
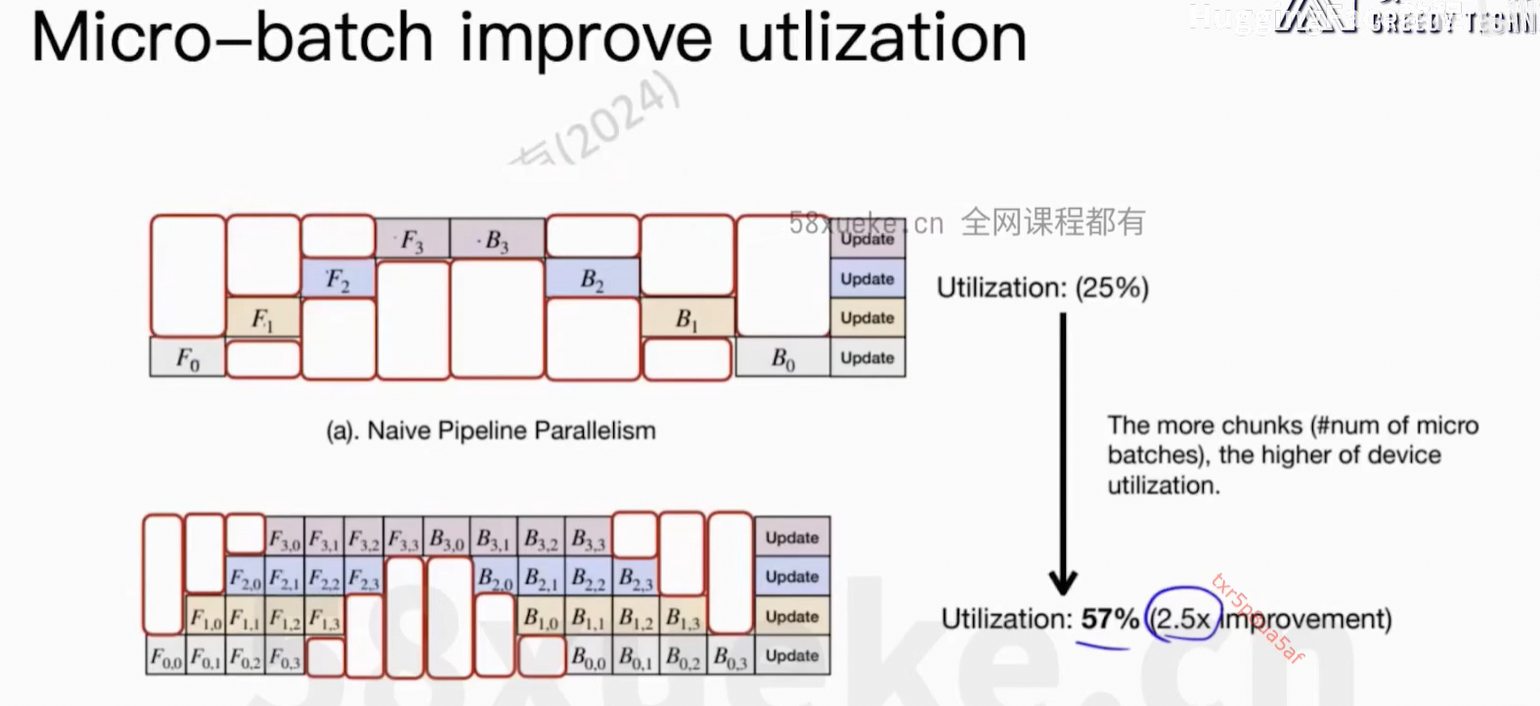
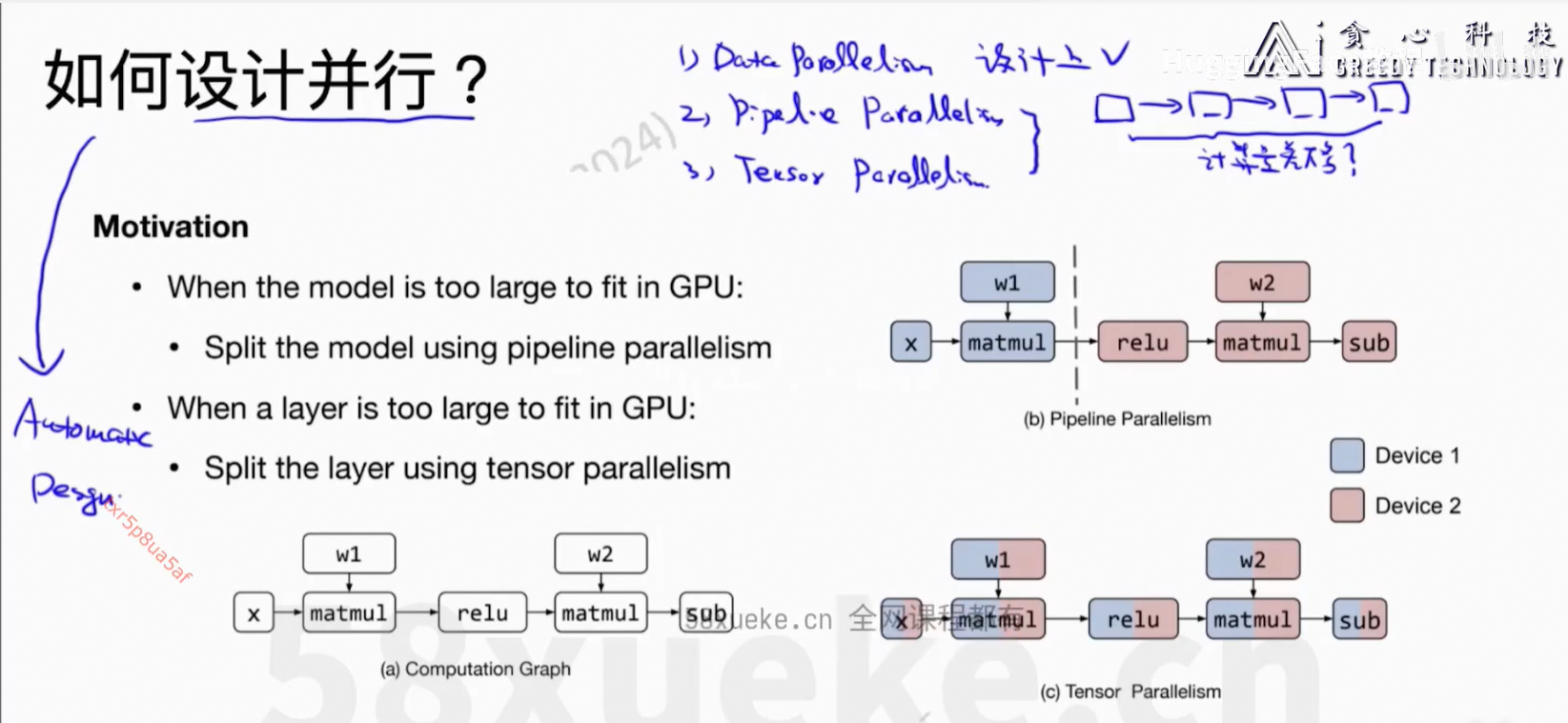
5、Pipeline并行
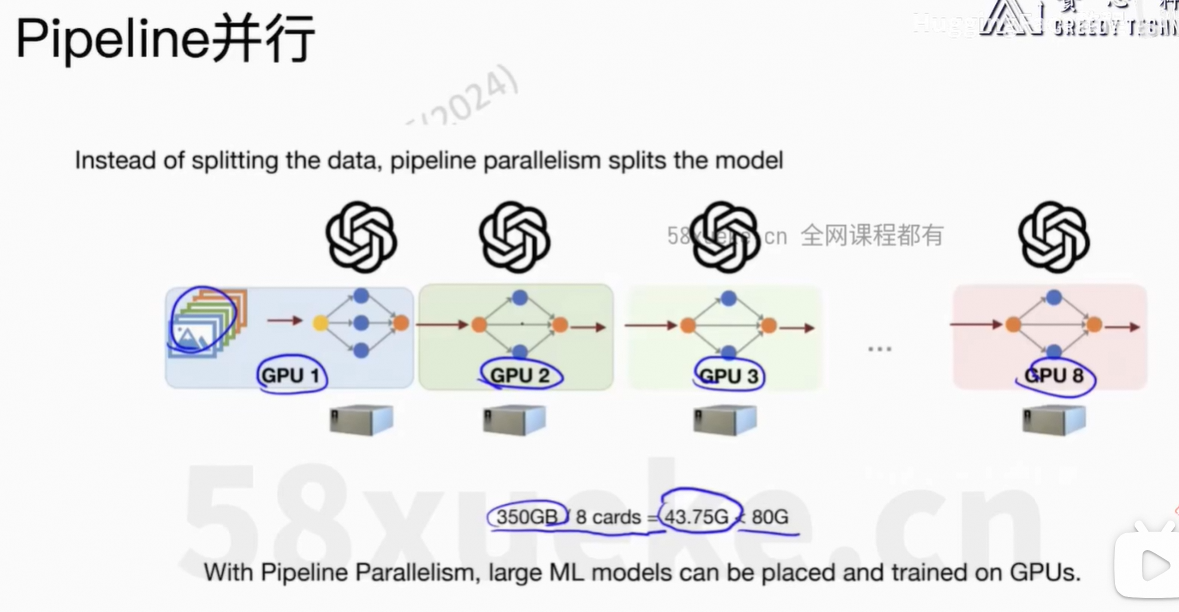
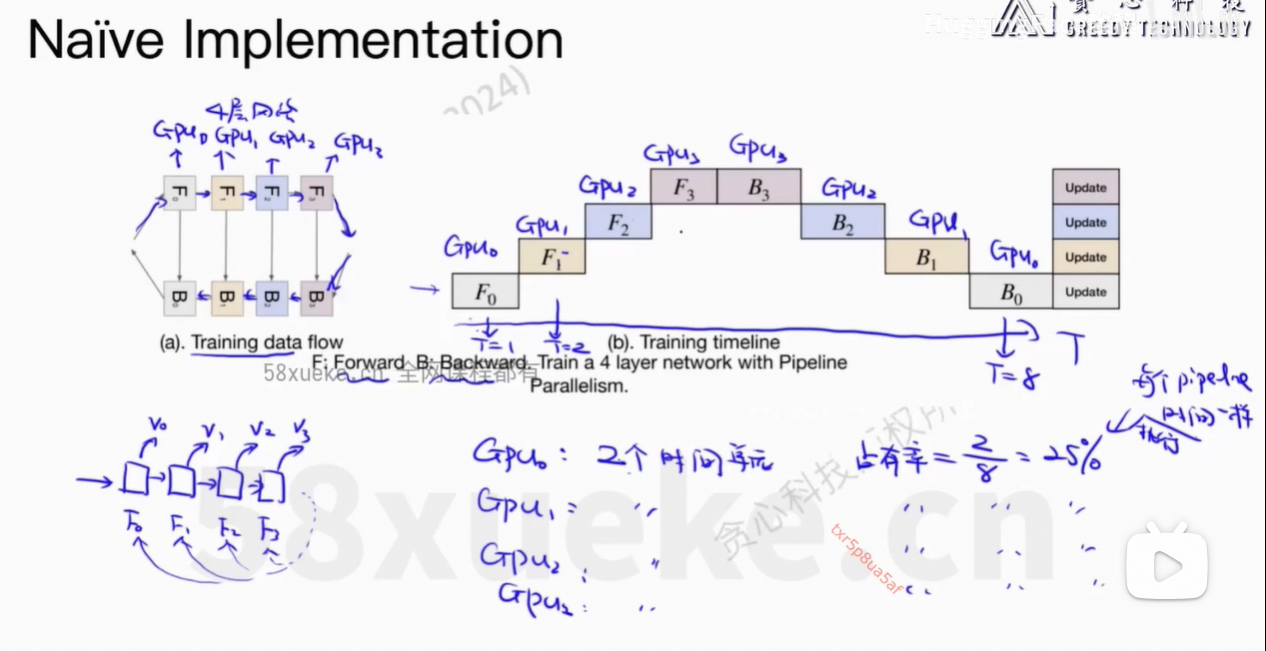
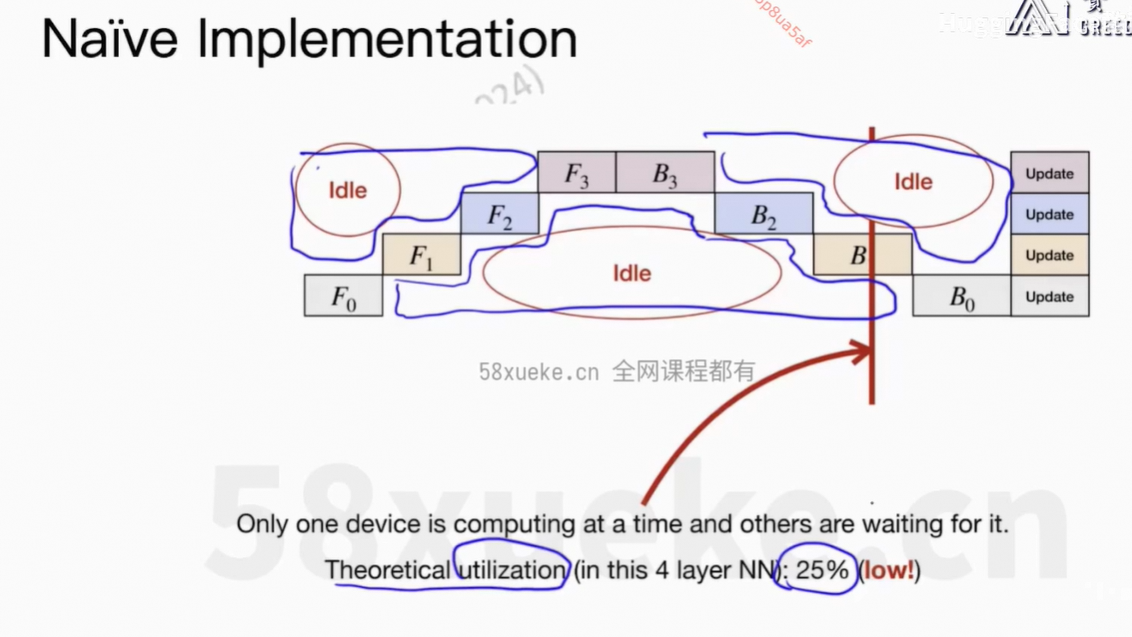

每个GPU只能运行一个任务。
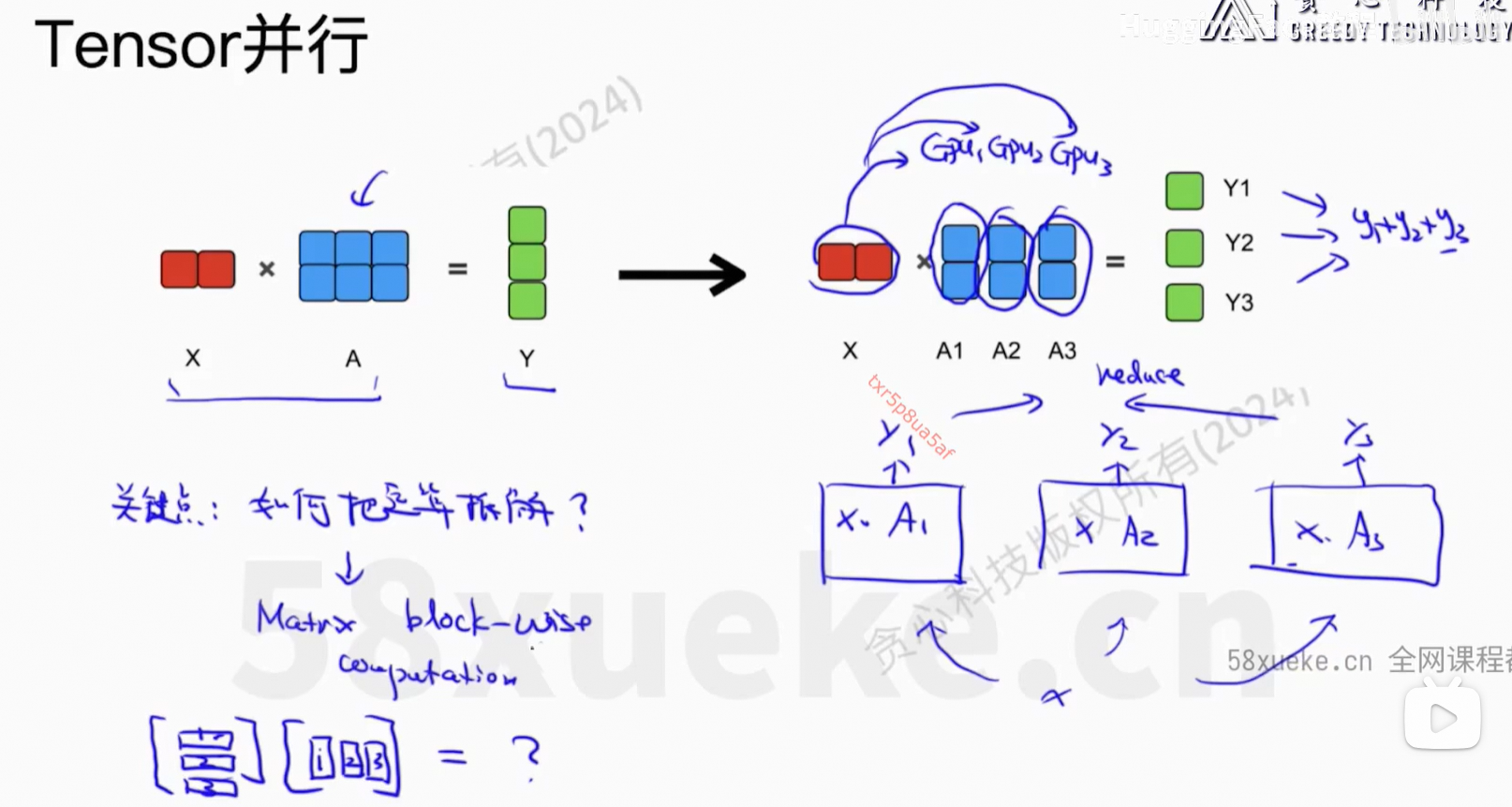
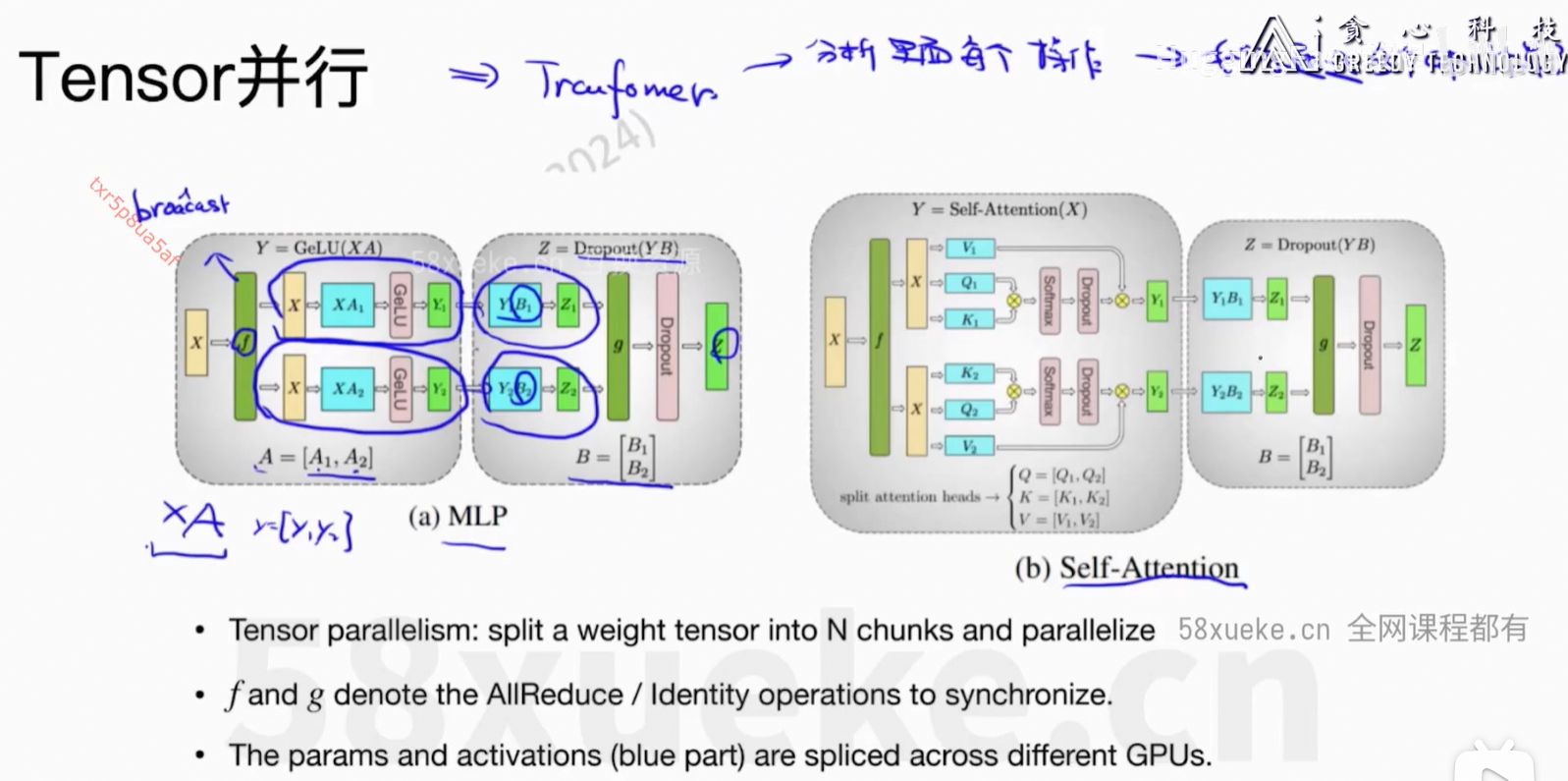
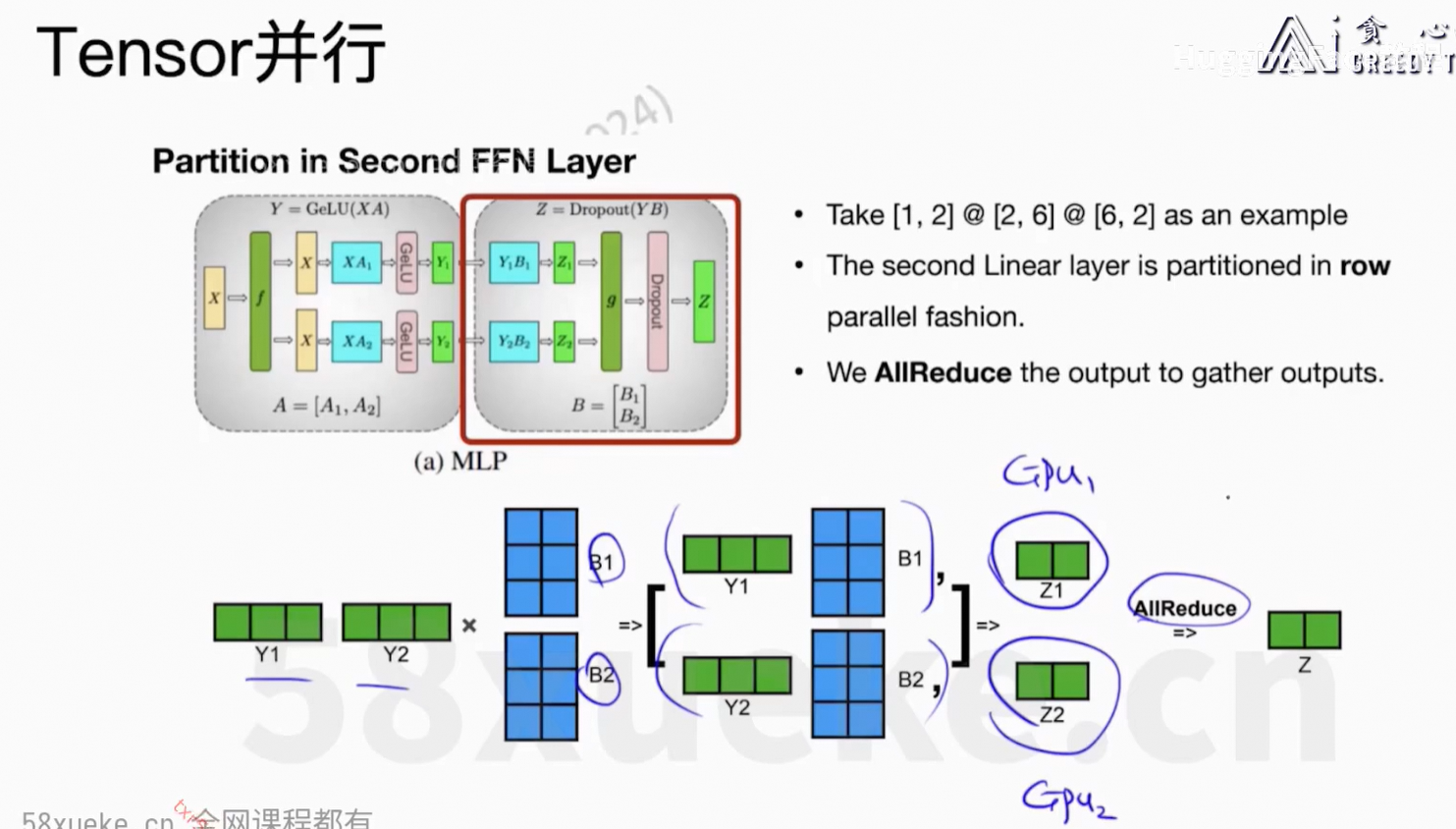
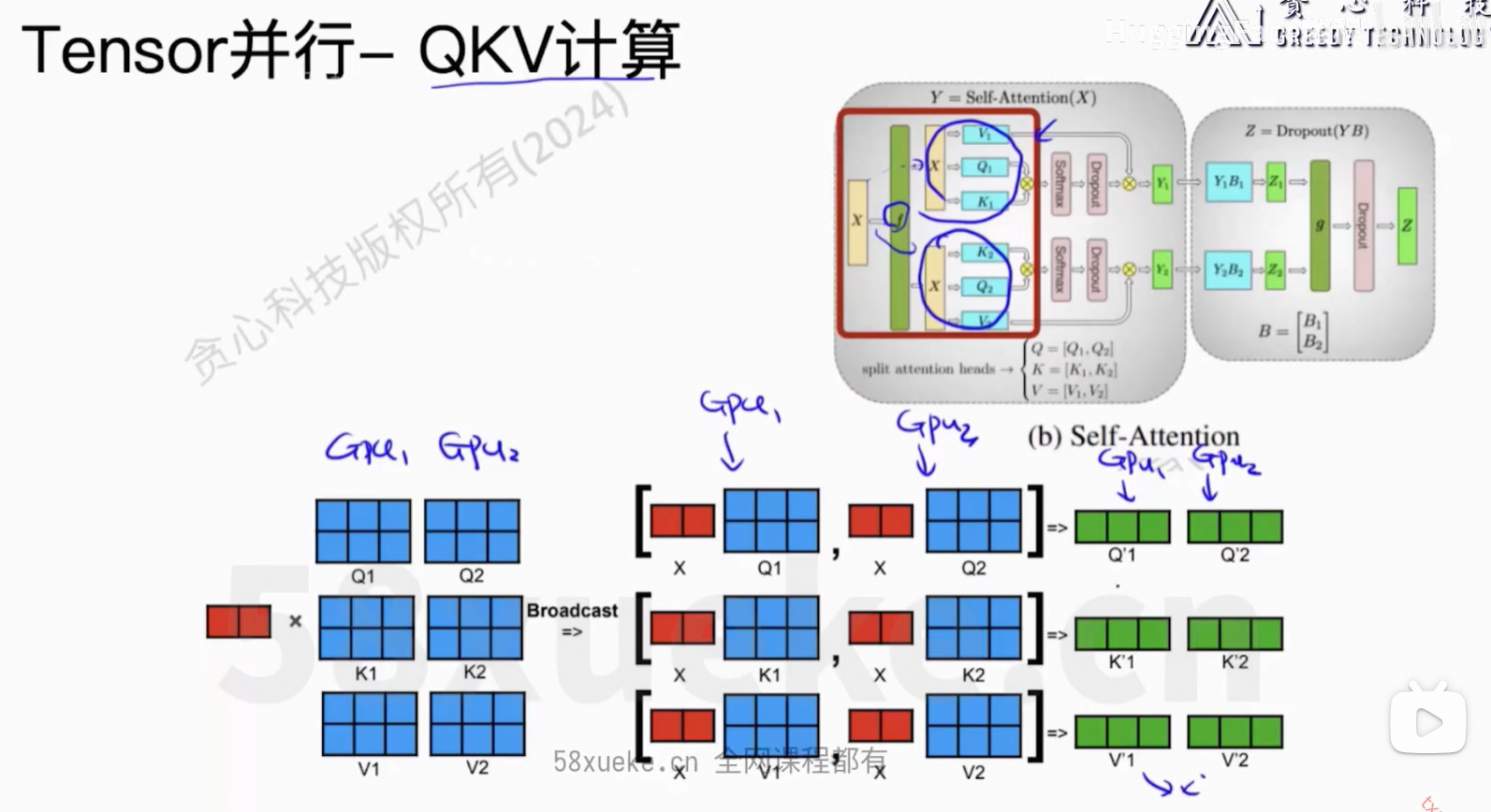
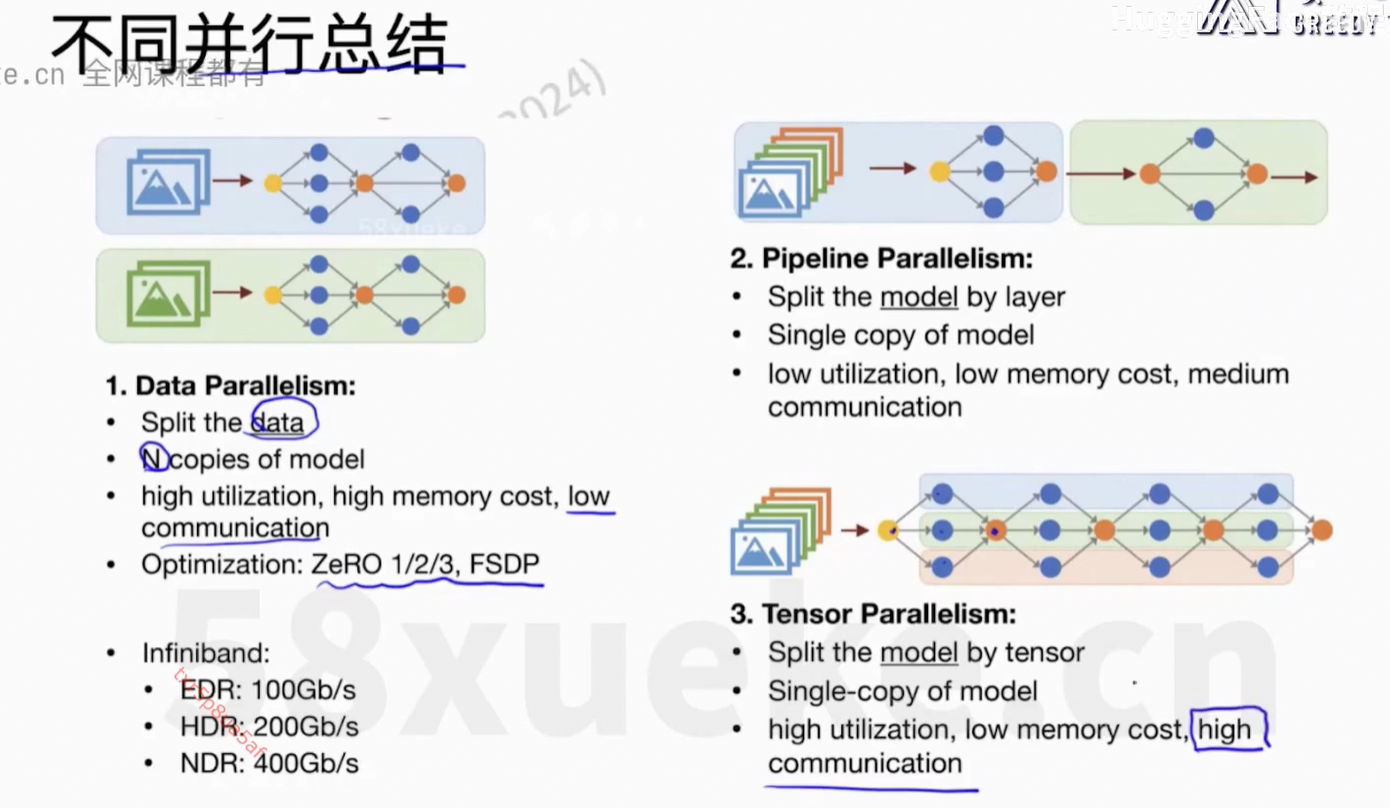
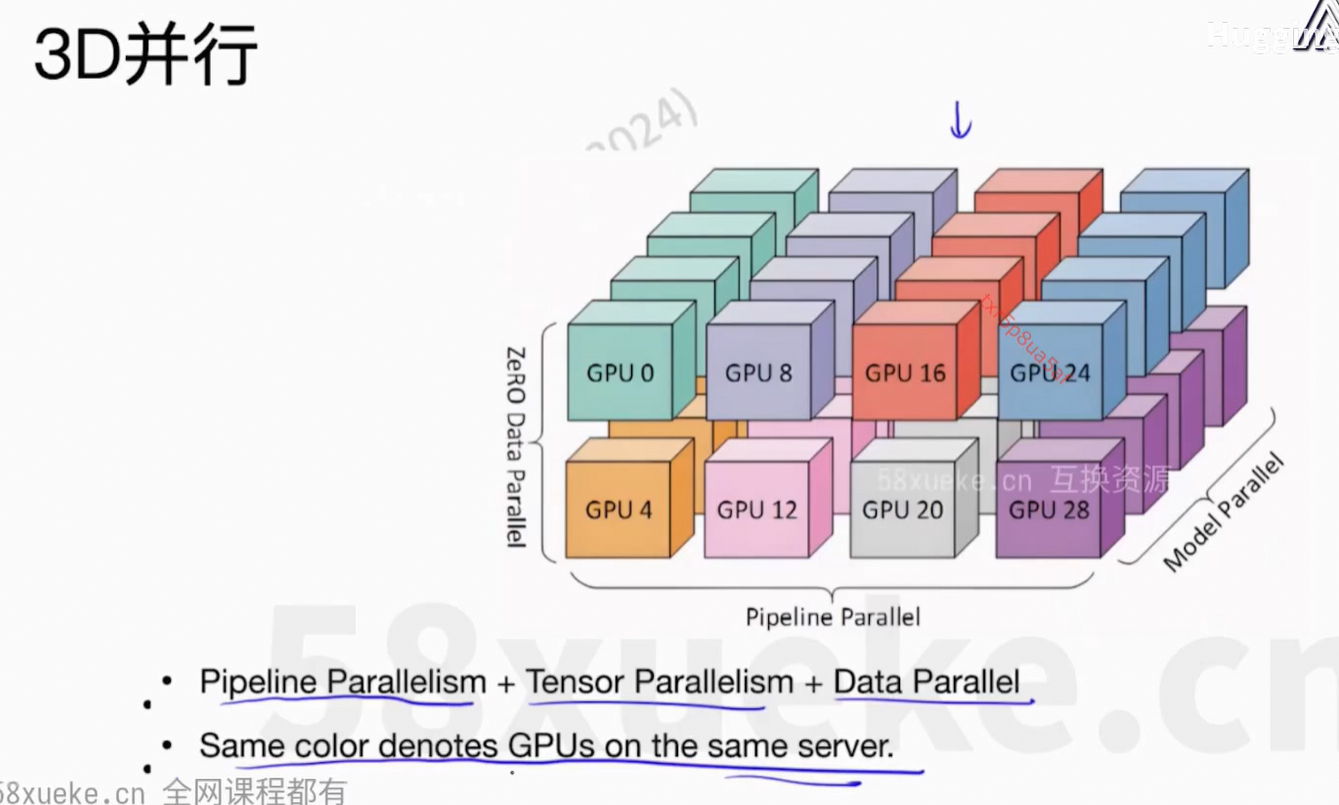
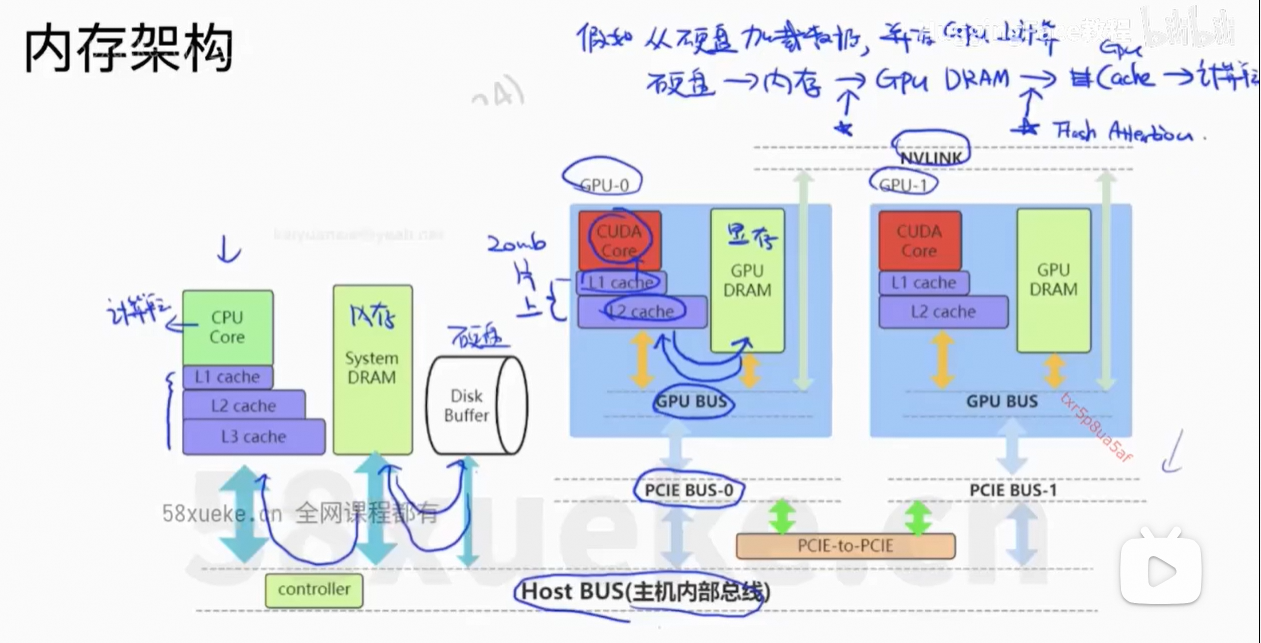
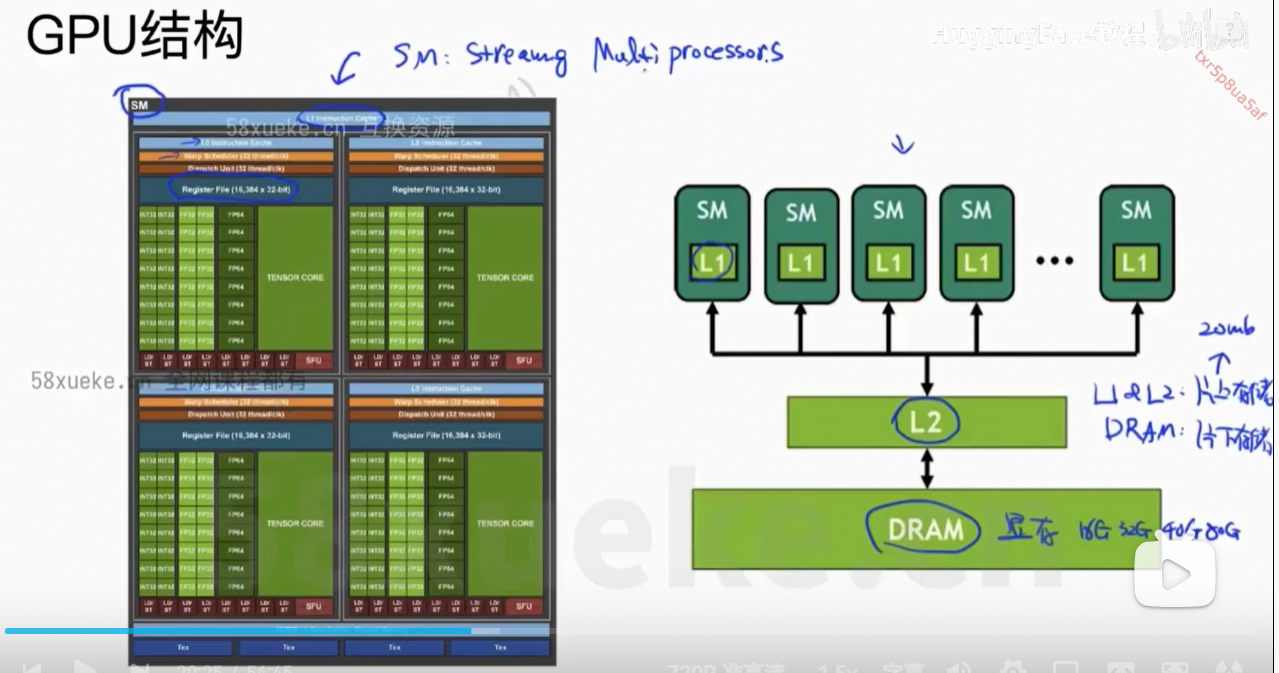
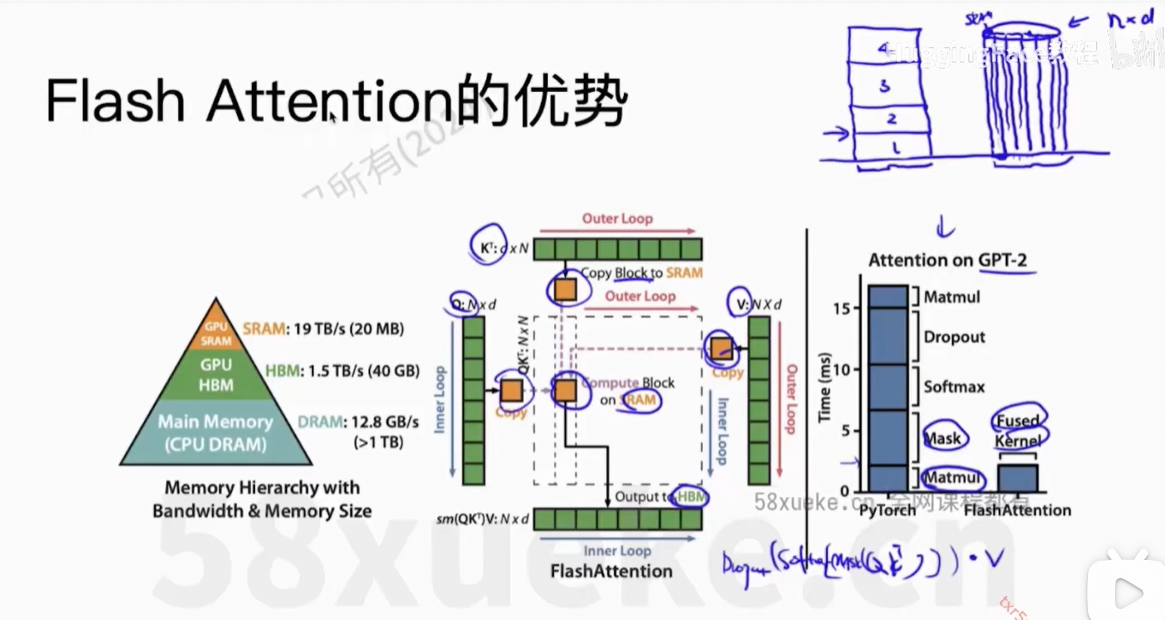
6、Flash Attention
Flash Attention: Fast and Memory-Efficient Exact Attention with IO-Awareness

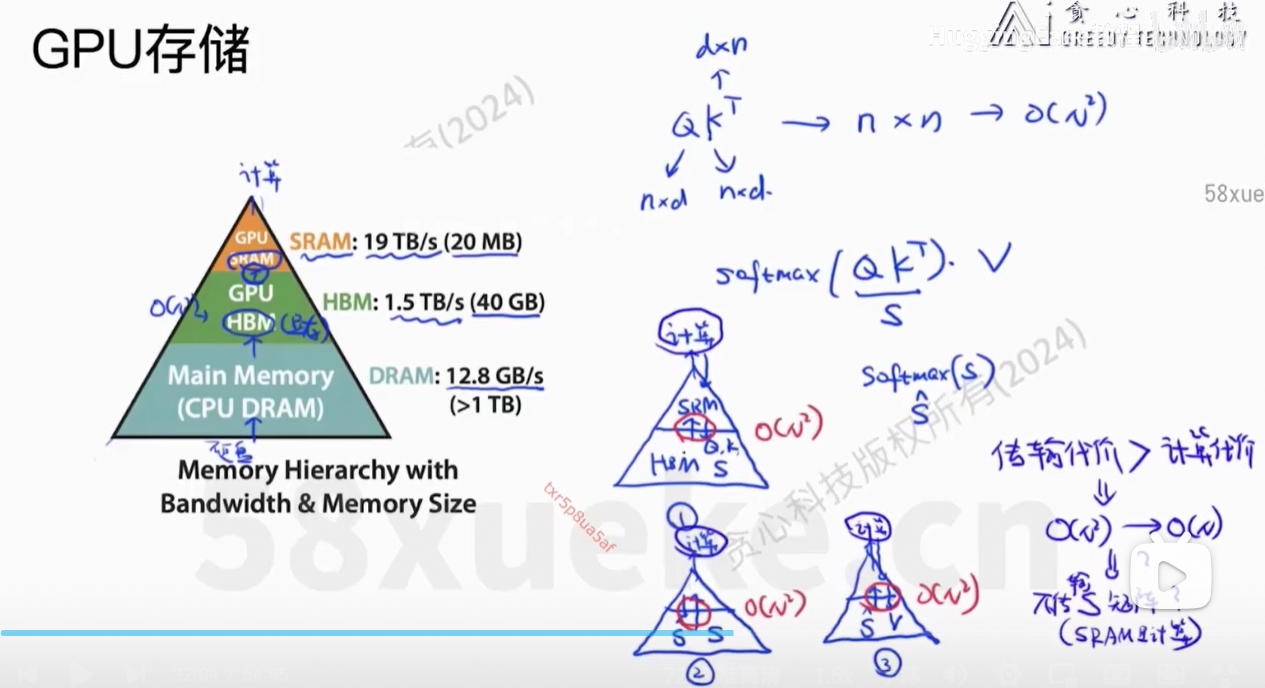
解决的问题:计算复杂度下降 + Memory复杂度下降,且是精确的计算
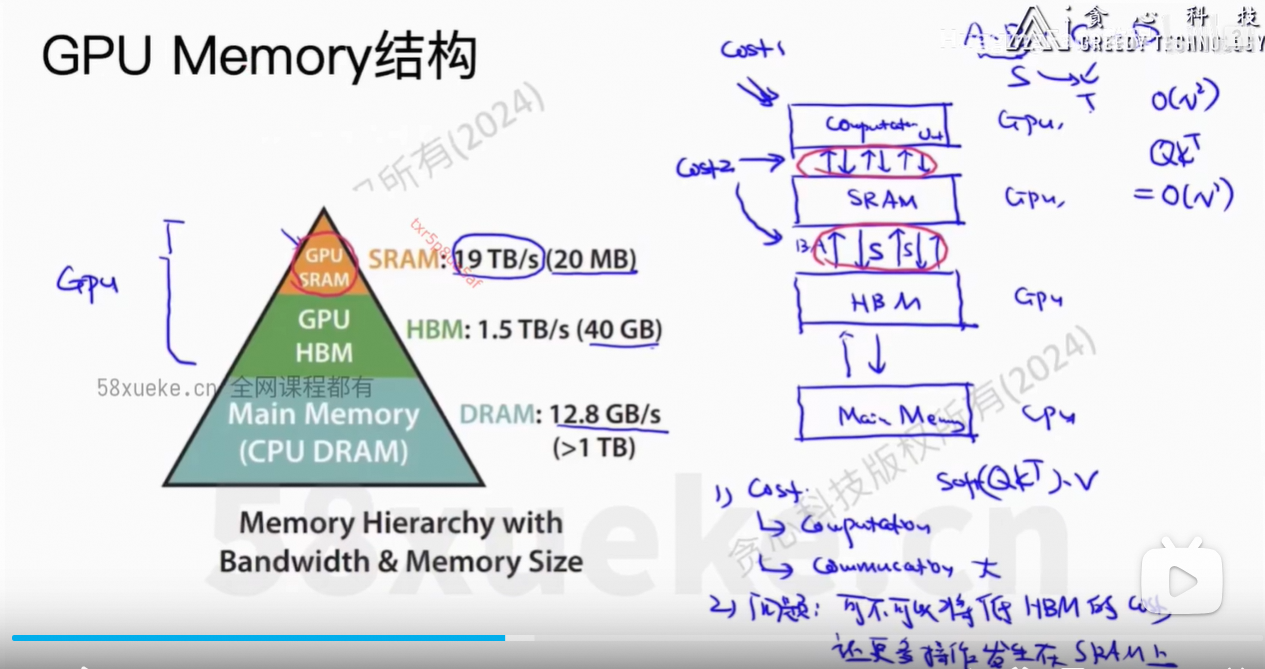

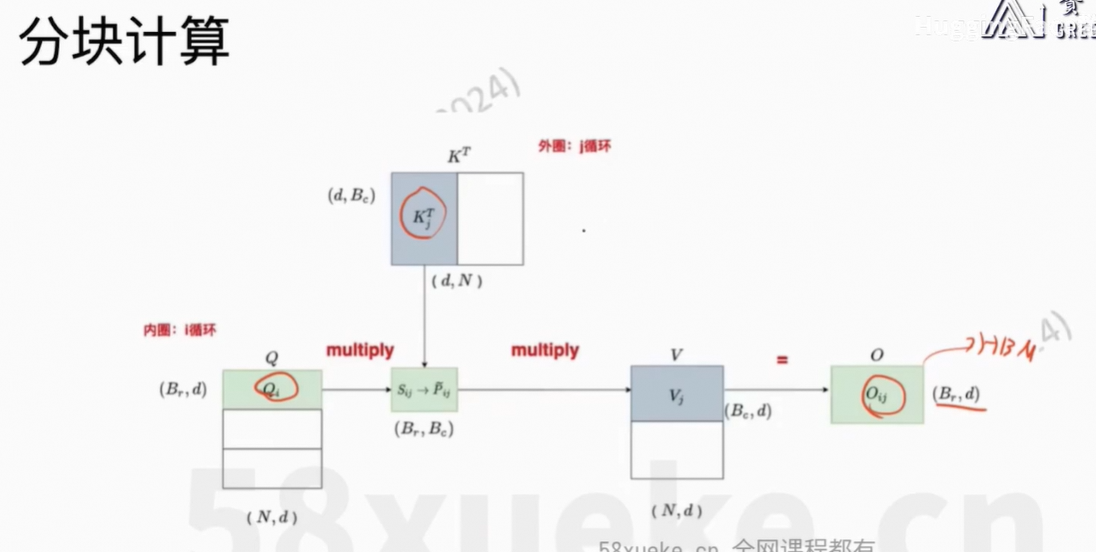
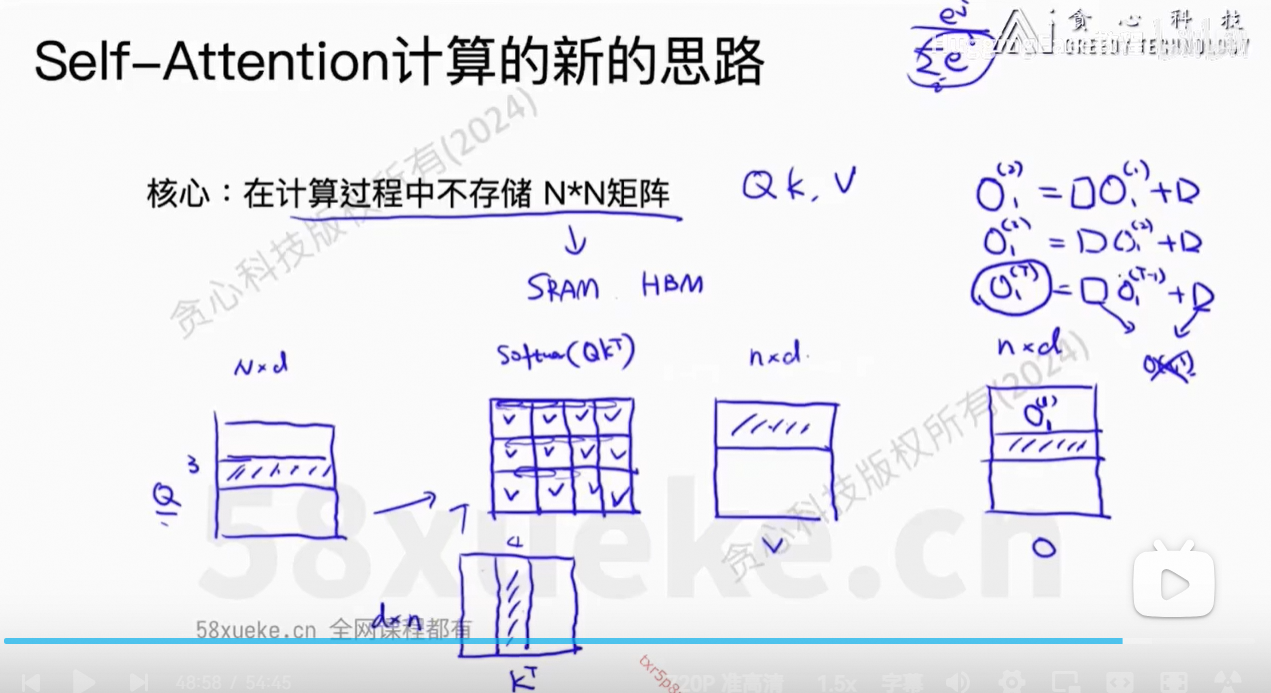
核心思想:将Q、K、V分块,然后每个小块放在SRAM中计算,最后reduce output得到最终结果。
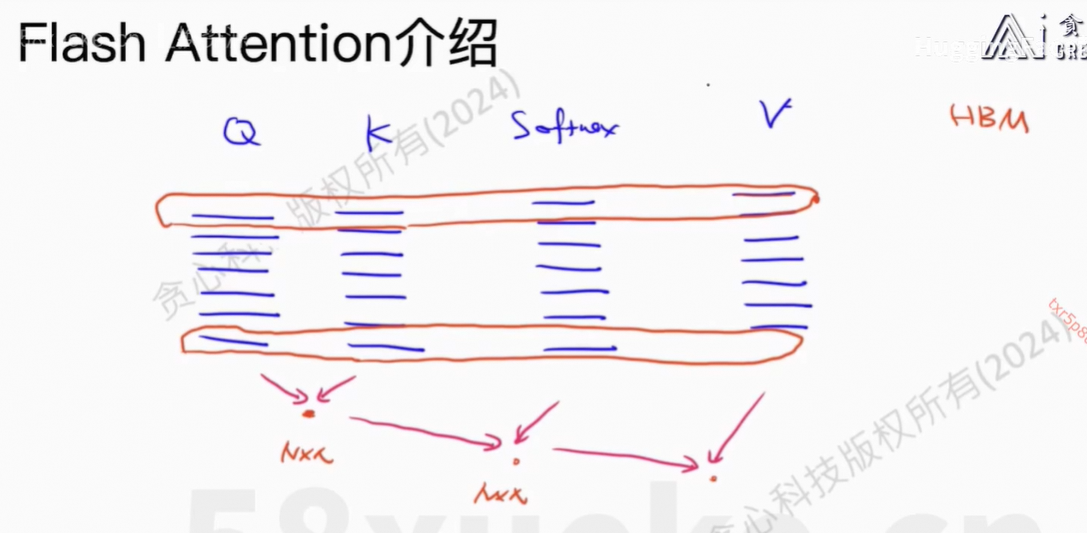
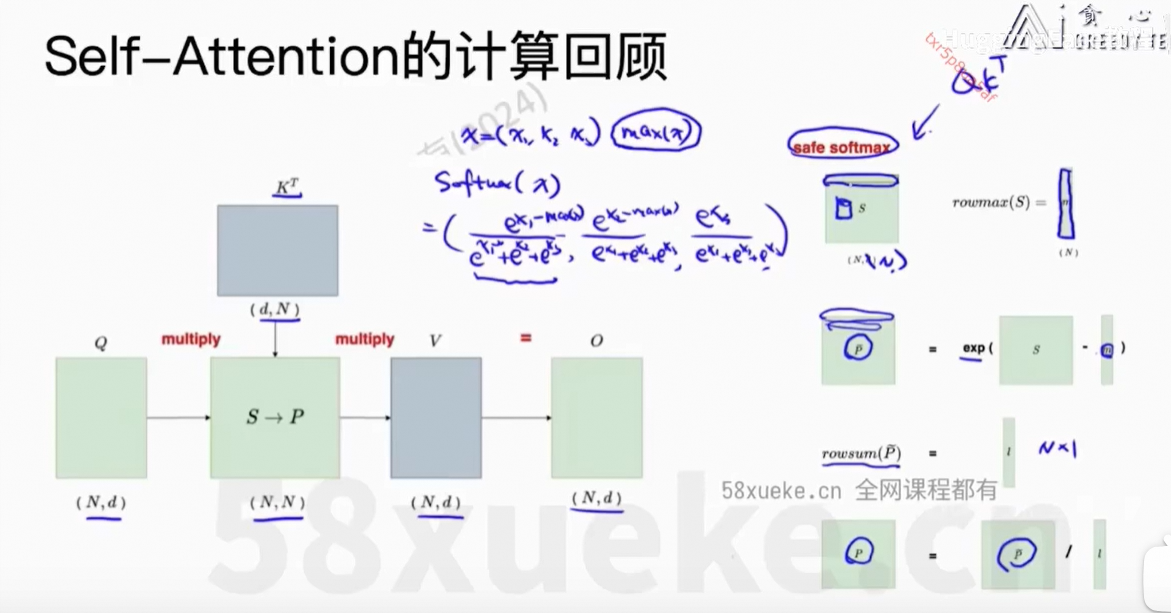
safe softmax:防止某个x过大导致float类型的计算溢出,溢出后会直接返回null。做法就是减去最大的x值即max值。
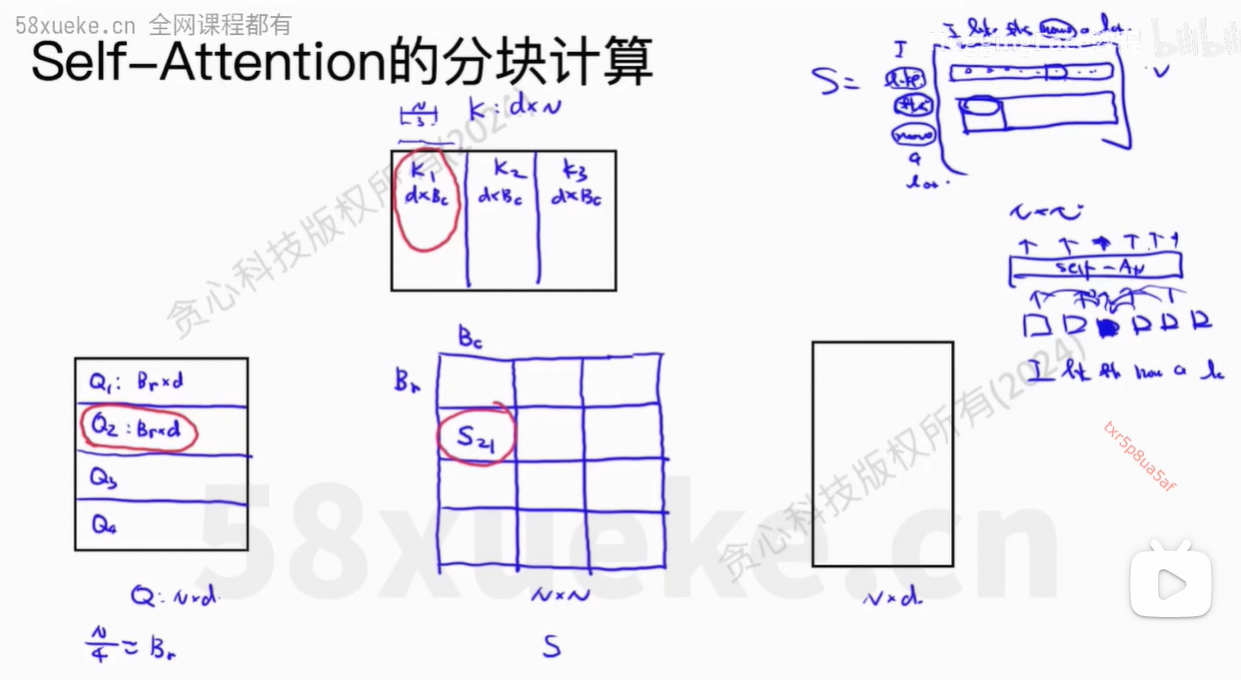
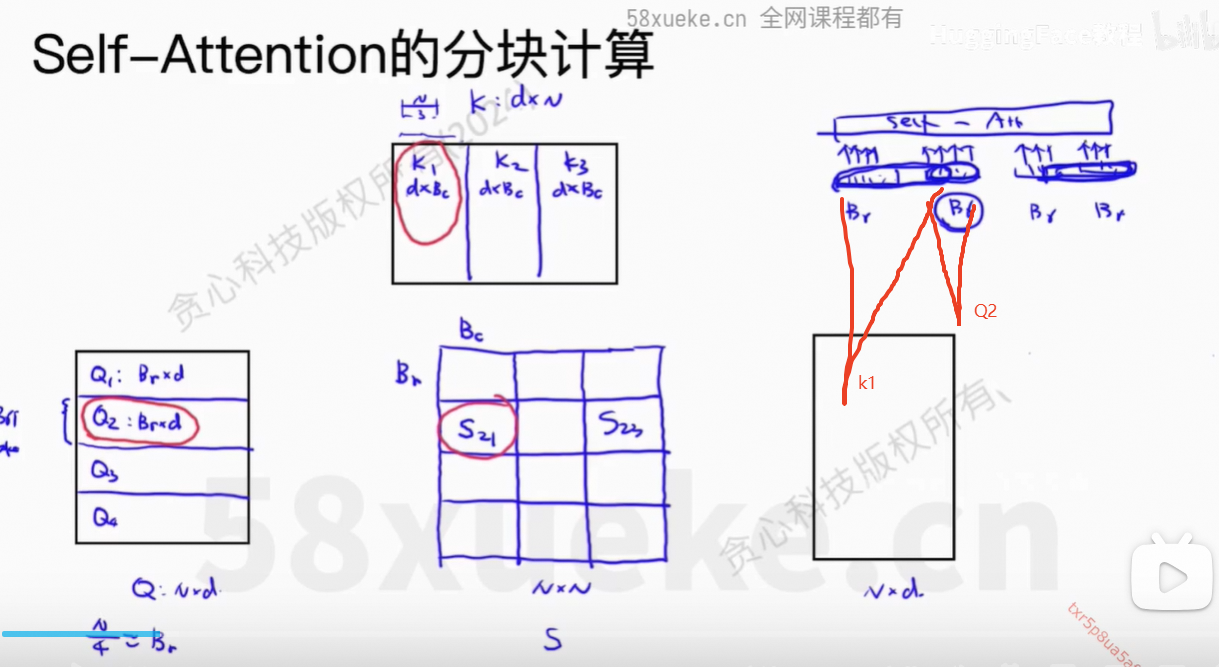
对于Block,是计算
对
的值。
包含了一部分token,
也包含了一部分的token。
当S中一行全部计算出来之后,就可以通过softmax计算权重值,再乘以V即可。
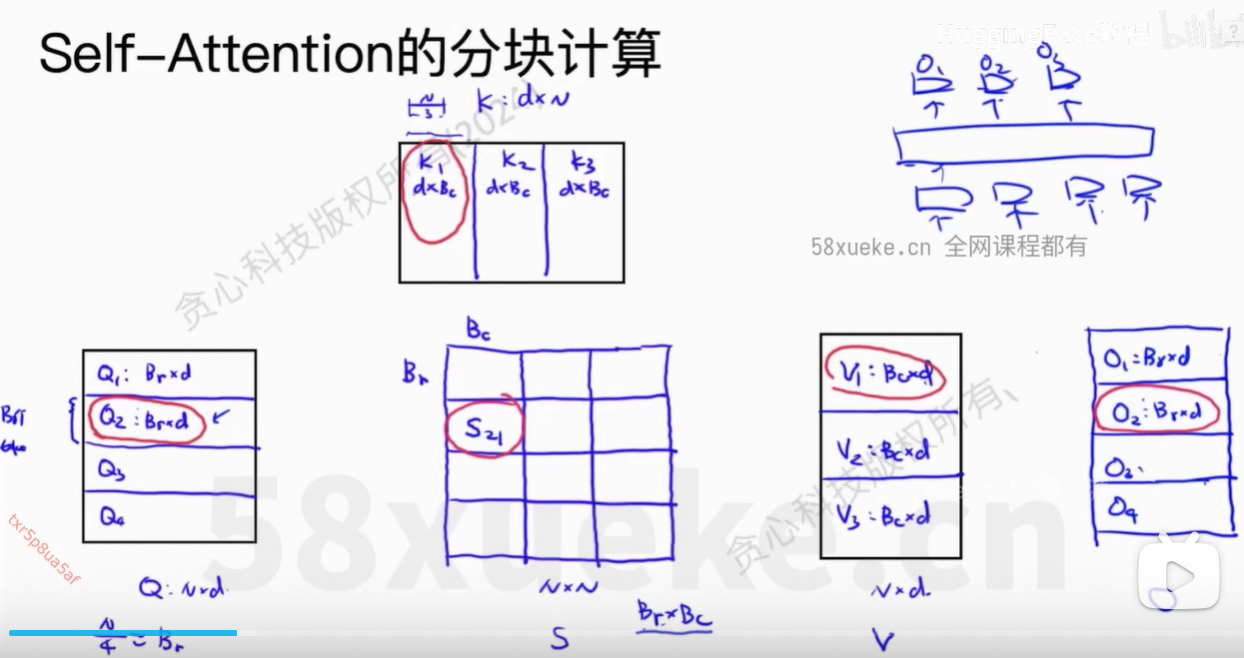
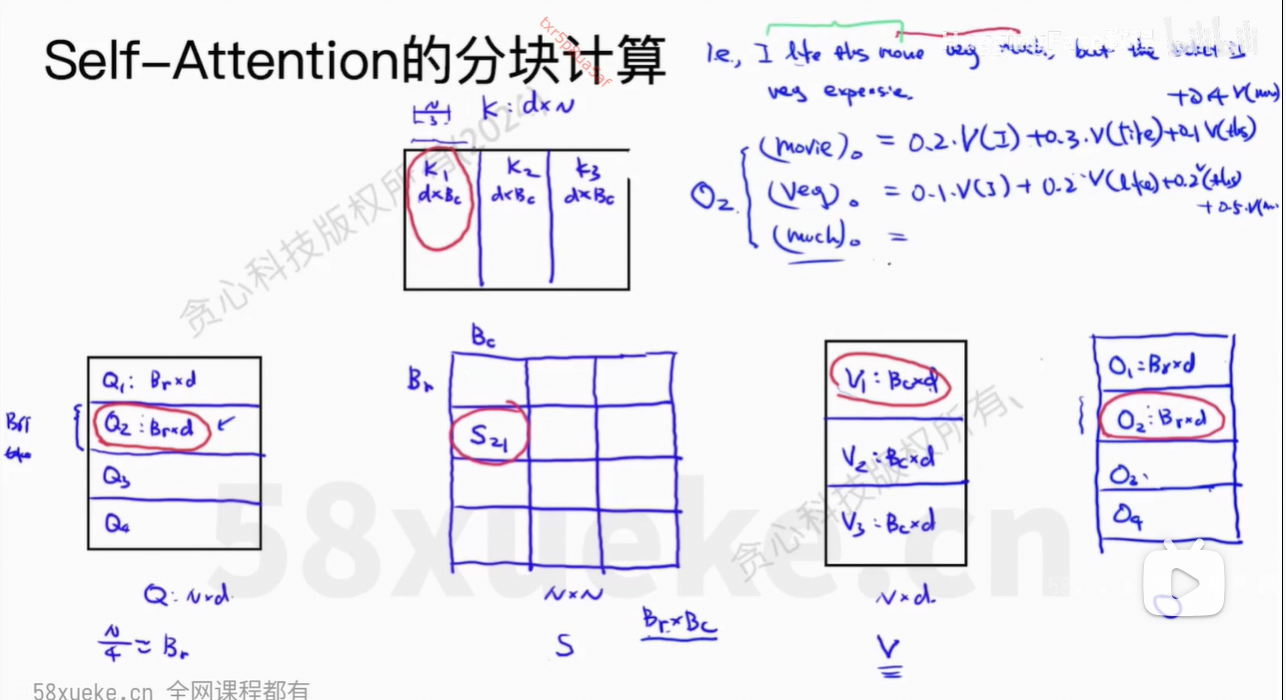
目前的O不是我们想要的值,因为权重只有部分的值,不全,所以最后得到的O2也是不正确的。
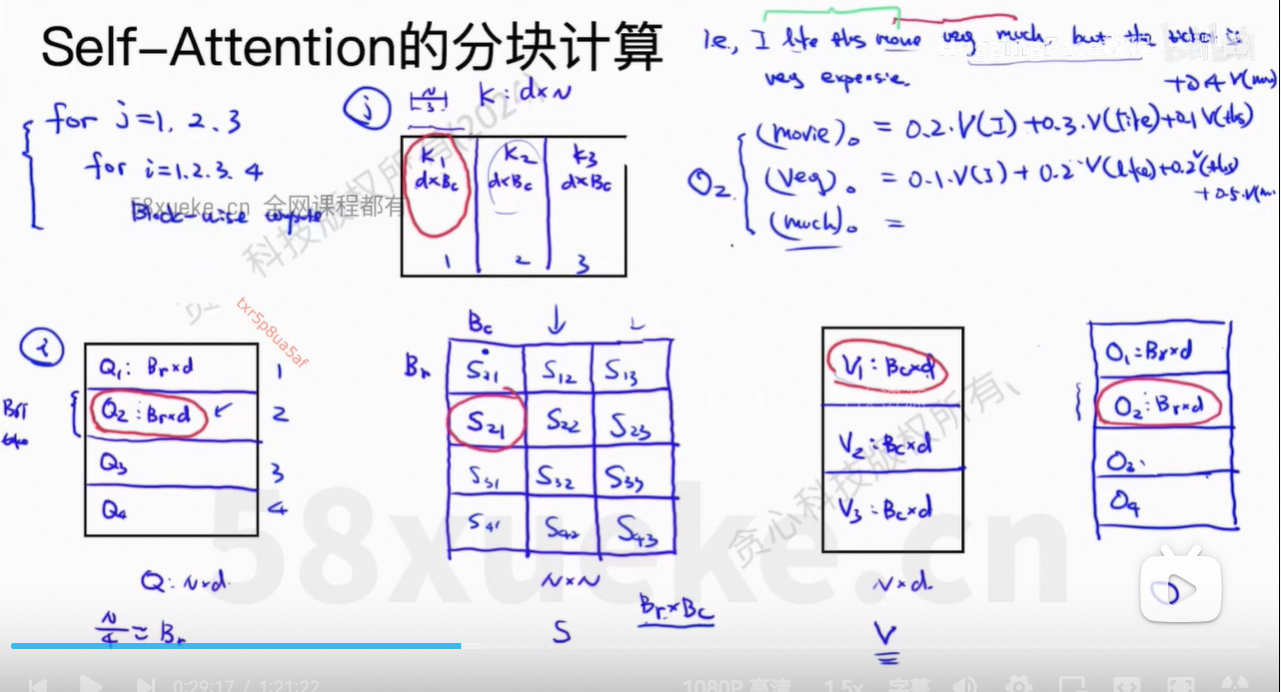

每次根据过去得到的m(x)和最新的x,更新m(x)的值即可。
我们不需要计算出完整的softmax的值,否则还是O(n2)的复杂度。



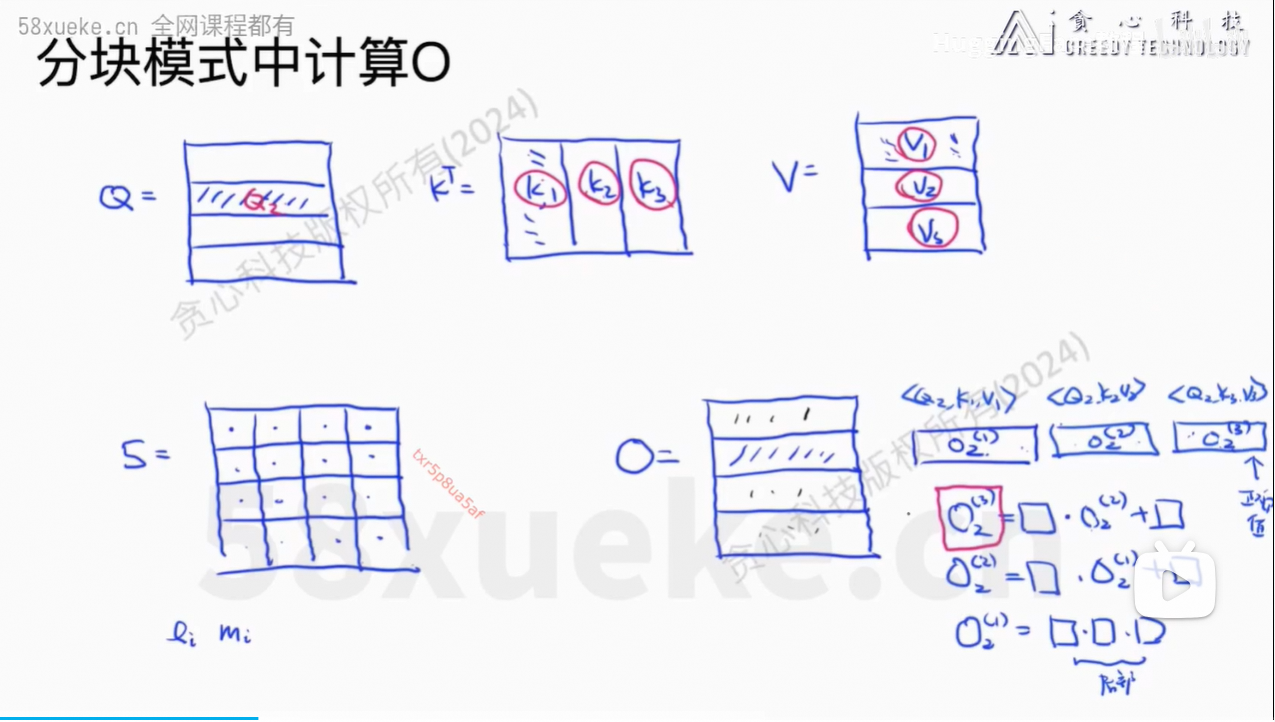

递归式方法求解。
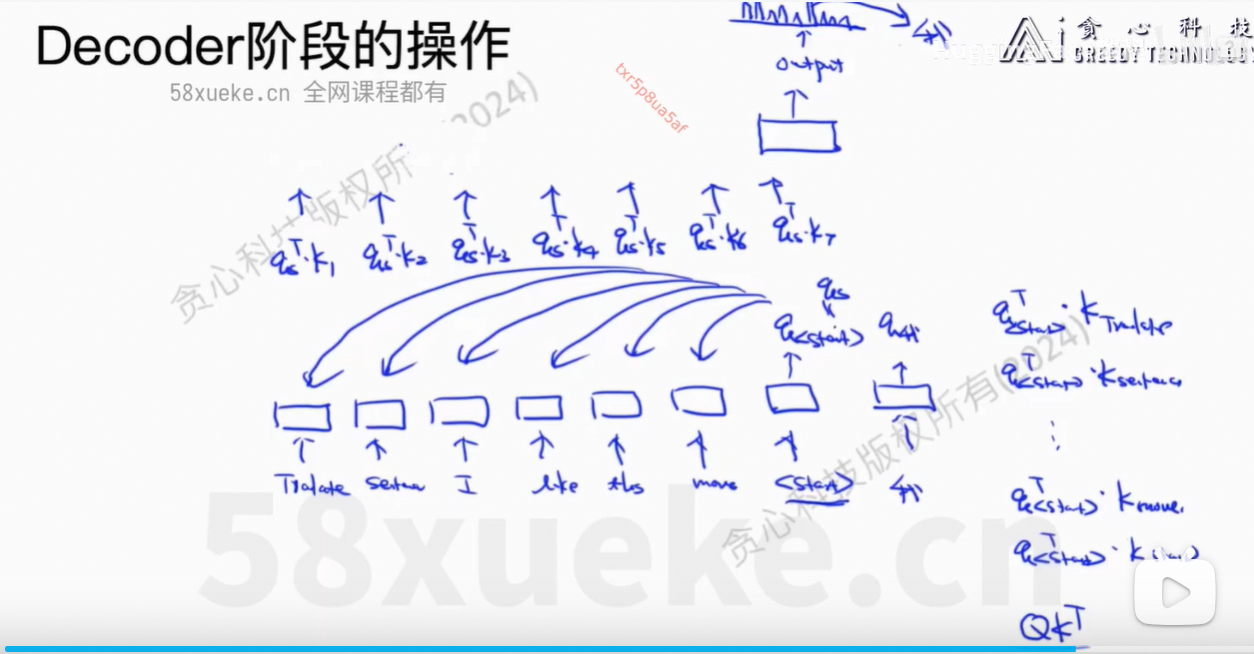
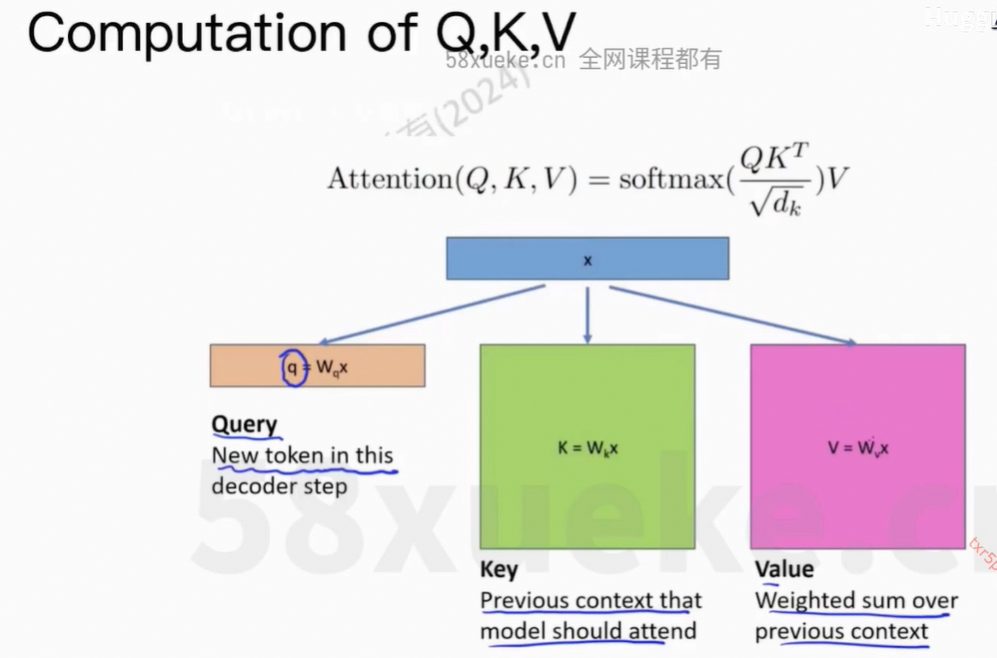
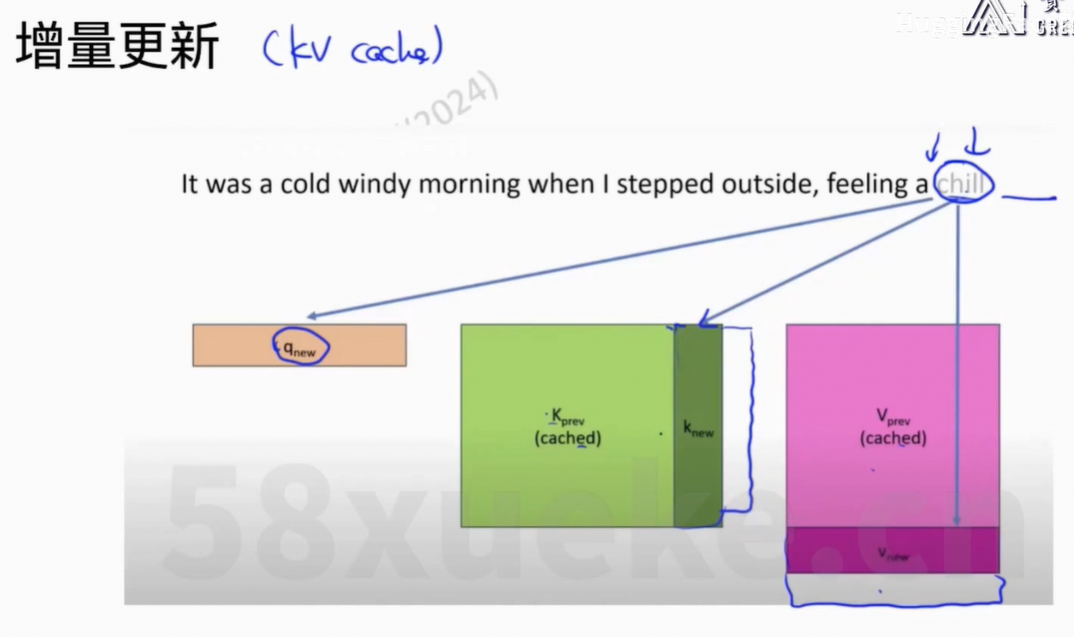
7、KV Cache
8、Mixture of Experts Model
可以理解为一种集成模型。
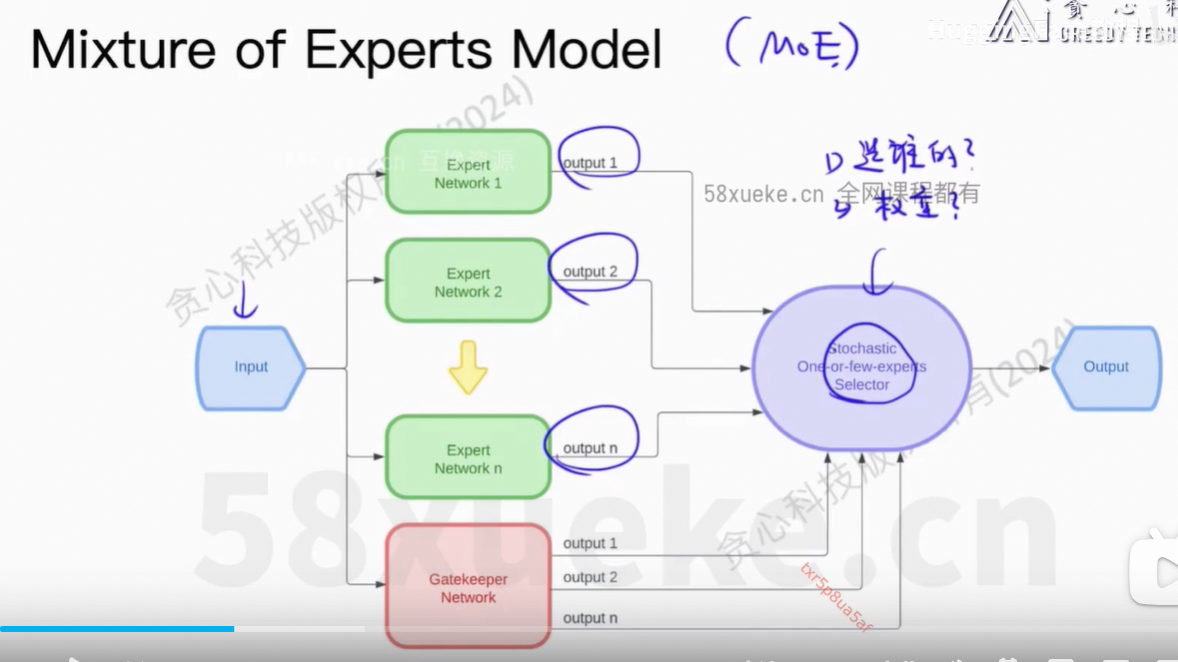
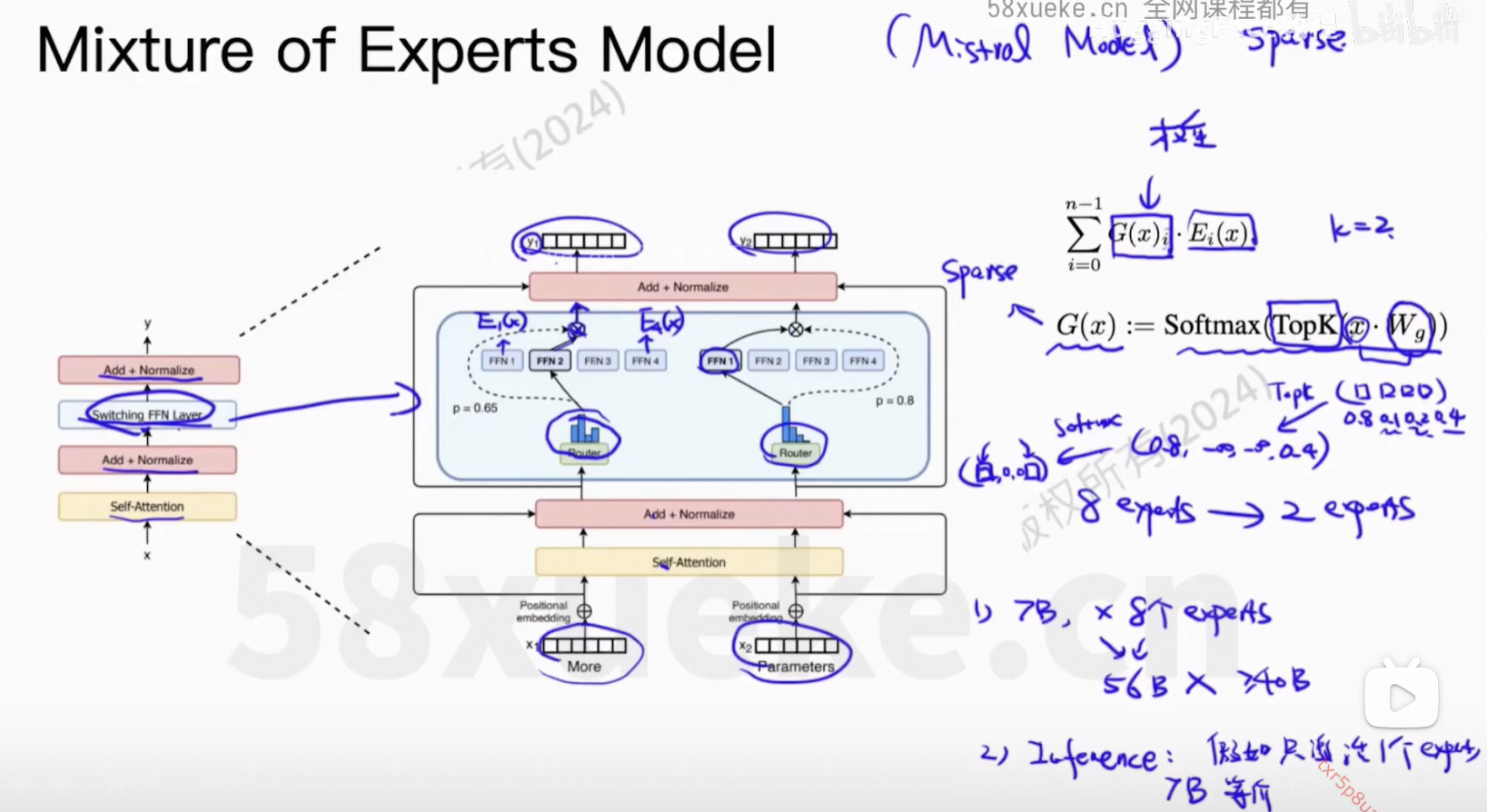
训练多个expert使得有差异化,最后推理时只激活部分FFN。如果只激活1个,那么和之前的性能是等价的。