Redis和MySQL的数据同步
文章目录
- 概要
- 为什么要使用Redis缓存MySQl中的数据
- 数据同步问题
- 数据同步结构的设计
- 小结
概要
关于MySQl和Redis同步问题理解和解决
为什么要使用Redis缓存MySQl中的数据
在应用程序开发中,使用 Redis 缓存 MySQL 中的数据是一种常见且有效的优化策略,有以下几种原因:
1. 提升系统性能
快速读写: Redis 是基于内存的数据库,数据的读写操作速度极快,其读写性能远远超过基于磁盘的 MySQL 数据库。
减少数据处理时间: Redis 可以直接在内存中对数据进行处理,无需像 MySQL 那样进行复杂的 SQL 解析、查询优化和磁盘 I/O 操作。
2. 提高并发处理能力
缓解数据库压力: 在高并发场景下,大量的请求直接访问 MySQL 数据库可能会导致数据库负载过高,甚至出现数据库崩溃。而 Redis 可以作为一个缓存层,拦截大部分的读请求,大大减小了MySQL数据库的压力。
支持更多并发连接: Redis 可以轻松处理大量的并发连接,其单线程模型加上高效的 I/O 多路复用技术,使得它能够在短时间内处理大量请求。相比之下,MySQL 处理过多的并发连接时,性能会明显下降。
3.降低数据库成本
减少硬件资源需求: 由于 Redis 承担了大部分的读请求,MySQL 的访问频率降低,对 MySQL 服务器的硬件配置要求也可以相应降低。例如,原本需要配置高性能的服务器来满足大量并发查询的 MySQL 数据库,在使用 Redis 缓存后,可以降低服务器的 CPU、内存和磁盘配置,从而节省硬件采购成本。
延长数据库使用寿命: 减少了 MySQL 的读写操作次数,降低了磁盘的磨损和老化速度,延长了数据库服务器的使用寿命。同时,也减少了数据库维护和升级的频率,降低了维护成本。
4. 实现数据的持久化和备份
数据持久化: 虽然 Redis 是内存数据库,但它提供了多种数据持久化机制,如 RDB(Redis Database)和 AOF(Append Only File)。可以将 Redis 中的缓存数据定期保存到磁盘上,即使服务器重启,也可以快速恢复数据。例如,在一个金融系统中,将一些关键的交易数据缓存到 Redis 中,并通过持久化机制保存到磁盘,确保数据的安全性和可恢复性。
数据备份和恢复: Redis 的数据备份和恢复操作相对简单,而且备份文件体积较小,便于存储和管理。相比之下,MySQL 的备份和恢复过程较为复杂,尤其是对于大型数据库。使用 Redis 缓存数据可以在一定程度上减轻 MySQL 备份和恢复的压力。
数据同步问题
MySQL和Redis的数据同步问题是指在使用Redis作为MySQL的缓存时,如何保证两者之间数据的一致性和及时性。
产生的原因
读写操作的异步性: 在实际应用中,对数据的读写操作可能会在不同的时间发生,且操作对象可能不同。例如,当应用程序更新了MySQL中的数据,但由于某些原因没有及时更新Redis中的缓存数据,就会导致两者数据不一致。
并发操作: 在高并发场景下,多个客户端可能同时对MySQL和Redis进行读写操作,这增加了数据同步的复杂性。比如多个用户同时对同一商品的库存进行修改,可能会导致MySQL和Redis中的库存数据不一致。
常见场景
读操作场景: 当应用程序从Redis中读取数据时,如果Redis中的数据已经过期或者没有及时更新,而MySQL中的数据已经发生了变化,就会出现数据不一致的情况。例如,用户查询商品价格,Redis中缓存的价格是旧的,而MySQL中已经更新了价格。
写操作场景: 当应用程序向MySQL中写入新数据或者更新已有数据时,如果没有及时更新Redis中的缓存数据,也会导致数据不一致。比如管理员修改了商品的库存信息,MySQL中的库存已经更新,但Redis中的库存还是旧值。
带来的影响
数据不准确: 会导致应用程序展示给用户的数据不准确,影响用户体验。例如,在购物系统中,如果商品的价格在Redis和MySQL中不一致,导致用户看到的价格与实际购买价格不同,会引起用户的不满。
业务逻辑错误: 可能会导致业务逻辑出现错误。比如在库存管理系统中,如果Redis和MySQL中的库存数据不一致,可能会出现超卖的情况,给企业带来损失。
解决方法
缓存更新策略
先更新数据库,再更新缓存: 在更新MySQL数据后,紧接着更新Redis中的缓存数据。但这种方式可能会在高并发场景下出现问题,例如多个线程同时更新数据时,可能会导致缓存数据被覆盖。
先更新数据库,再删除缓存: 在更新MySQL数据后,删除Redis中的缓存数据,下次查询时再从数据库中读取数据并更新缓存。这种方式可以避免缓存更新时的并发问题,但可能会在缓存删除后到下次更新前出现短暂的数据不一致。
异步消息队列: 使用消息队列(如RabbitMQ、Kafka)来实现数据的异步同步。当MySQL数据发生变化时,发送消息到消息队列,由专门的消费者从消息队列中获取消息,并更新Redis中的缓存数据。这种方式可以提高系统的吞吐量和可靠性,但会增加系统的复杂度。
分布式锁: 在高并发场景下,可以使用分布式锁(如Redis分布式锁、ZooKeeper分布式锁)来保证数据更新的原子性。例如,在更新MySQL和Redis数据时,先获取分布式锁,更新完成后释放锁,避免多个线程同时更新数据导致的数据不一致问题。
数据同步结构的设计
可以通过查询学生信息案例来理解
我们以先更新数据库,再更新缓存的方案实现数据同步结构的设计
普通的查询学生信息只会将学生的信息直接扔入redis缓存中,他们共用一个键值,当我们对MySQL数据库的数据进行修改后,不能对redis缓存中的单个学生信息进行准确修改,导致redis和MySQL中的数据不能同步。
普通
@Overridepublic List<Student> findAll2() {log.info("开始查询所有数据2");List<String> range = forList.range(ALL_STUDENT, 0, -1);if (range != null && !range.isEmpty()) {List<Student> all_student = new ArrayList<>();range.forEach(s -> {all_student.add(JSONArray.parseObject(s, Student.class));});return all_student;}List<Student> list = this.list();list.forEach(student -> {forList.rightPush(ALL_STUDENT, JSONArray.toJSONString(student));});return list;}
如下图所示redis缓存的学生信息所用的是同一个键值,这也就导致了他们一体化的特质,使得我们要修改某一个学生信息时不能精准修改,让人头疼。
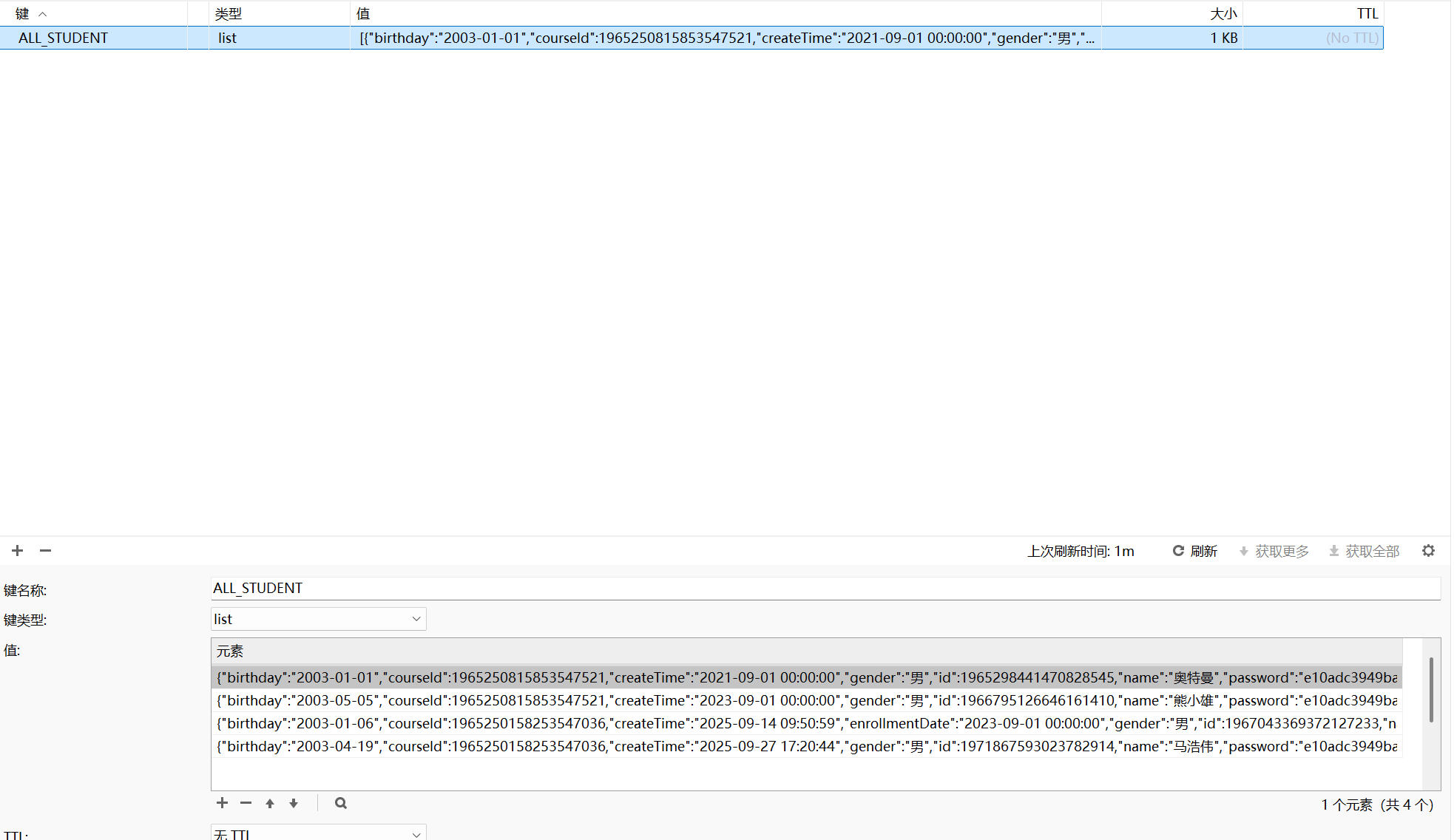
于是我们在查询学生信息的时候将查到的学生信息挨个放入redis缓存之前,先将他们的序号id记录在新的集合中,再将他们的数据保存在另外一个集合之中,以保留的id作为他们的键值,他们之间相互对应,在需要修改redis缓存中的学生信息时就能通过他们保留的id直接修改他们的信息
@Overridepublic List<Student> findAll3() {List<String> stringList = forList.range(ALL_STUDENT, 0, -1);if(stringList !=null && !stringList.isEmpty()){List<Student> all_student = new ArrayList<>();stringList.forEach(id -> {String json = forValue.get(id);Student student1 = JSONArray.parseObject(json, Student.class);all_student.add(student1);});return all_student;}List<Student> list = this.list();list.forEach(student -> {forList.rightPush(ALL_STUDENT,student.getId()+"");forValue.set(student.getId()+"", JSONArray.toJSONString(student));});return list;}
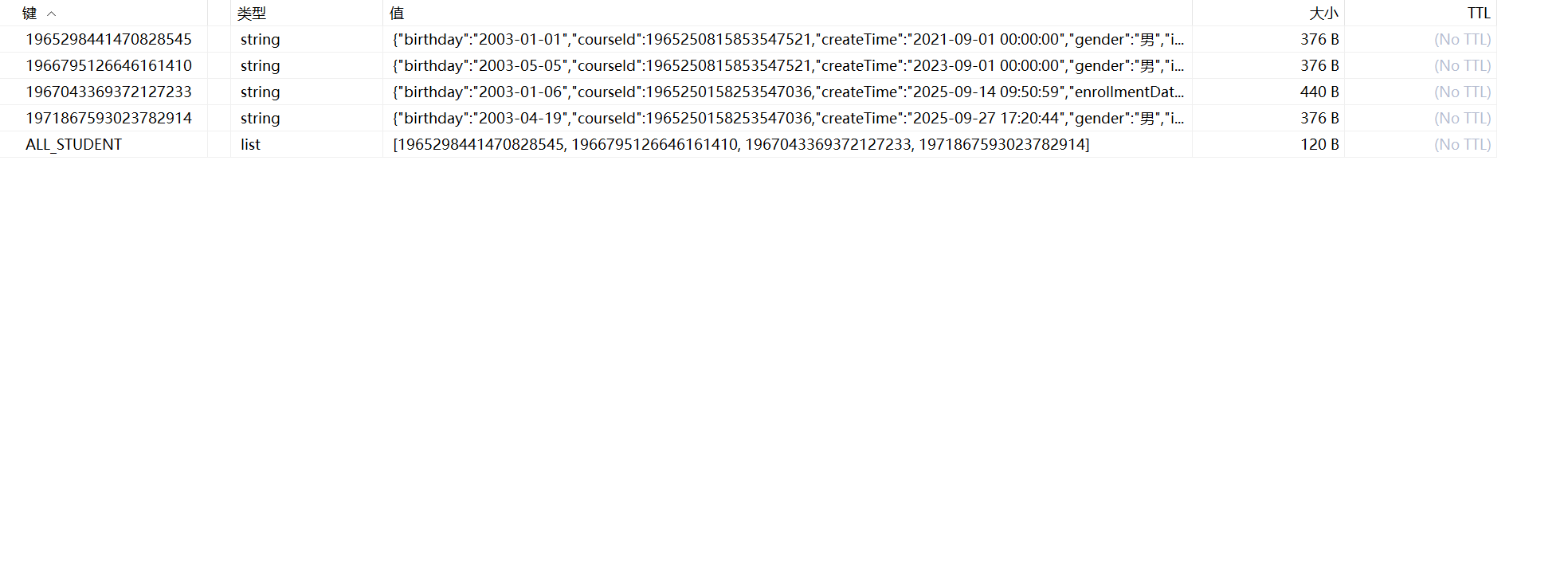
组合缓存策略:同时使用Redis的List和Value两种数据结构
List结构:存储学生ID列表,作为索引目录
Value结构:以学生ID为键,存储具体的学生对象数据
数据一致性保证:当缓存失效时,会重新从数据库加载数据并更新缓存
操作灵活性:这种设计便于单独更新或删除某个学生的数据
更新时:只需更新对应ID的Value数据
删除时:只需删除对应ID的Value数据,并从List中移除该ID
性能优化:通过Redis缓存减少数据库访问压力,提高查询效率
具体如下图所示
接下来再看一个写入的案例
比如我们现在要修改一个学生的信息,MySQL数据库会第一时间进行修改更新,接下来redis缓存就会通过这个学生它的id快速知道它的所在位置快速定位然后精确的进行修改,成功解决了redis和MySQL的同步问题
@Overridepublic int updateStudent(Student student) {boolean b = this.updateById(student);QueryWrapper<Student> queryWrapper = new QueryWrapper<>();queryWrapper.eq("id", student.getId());Student one = getOne(queryWrapper);forValue.set(one.getId()+"", JSONArray.toJSONString(one));return b ? 1 : 0;}小结
通过学习Redis和MySQL的数据同步问题及解决方案,深刻理解了数据一致性在分布式系统中的重要性。