【Linux】Linux管道与进程池深度解析:从原理到实战
前言:欢迎各位光临本博客,这里小编带你直接手撕**,文章并不复杂,愿诸君**耐其心性,忘却杂尘,道有所长!!!!

《C语言》
《C++深度学习》
《Linux》
《数据结构》
《数学建模》
文章目录
- 引言
- 一、管道基础:理解Linux管道的核心特性
- 1.1 管道容量:实验验证64KB的缓冲区限制
- 实验步骤
- 实验现象与结论
- 1.2 ulimit -a:查看系统资源限制中的管道配置
- 命令解读
- 实操建议
- 1.3 管道的写入原子性与PIPE_BUF
- 核心规则(Linux系统)
- 为什么原子性对进程池很重要?
- 管道的读取规则补充
- 二、进程池设计:基于管道实现高效任务分配
- 2.1 进程池通信结构:一对一管道模型
- 关键设计细节
- 为什么不用“多对一”管道?
- 2.2 信道管理:channel与channelmanager的设计
- 1. channel结构体(描述单个管道)
- 2. channelmanager类(组织多个channel)
- 2.3 进程池创建流程:从管道创建到子进程初始化
- 1. ProcessPool类定义
- 2. 核心步骤:create_pool()实现
- 3. 子进程任务循环:worker_loop()
- 4. 信道构建的可视化流程
- 2.4 进程池创建测试:验证子进程与信道是否正常
- 1. 测试代码
- 2. 编译与运行
- 3. 测试结果解读
- 三、任务管理:实现负载均衡的任务分配与执行
- 3.1 任务分配策略:避免负载不均衡
- 1. 策略1:轮询(Round Robin)
- 2. 策略2:随机(Random)
- 3. 策略3:最小负载(Min Load)
- 3.2 任务注册与管理:构建可扩展的任务表
- 1. 任务表设计
- 2. 注册具体任务
- 3. 优化execute_task函数
- 4. 任务注册与执行的可视化流程
- 5. 任务管理的灵活性
- 3.3 任务分配测试:验证负载均衡效果
- 1. 测试代码
- 2. 测试结果解读
- 四、进程池关闭与bug修复:解决文件描述符引用计数问题
- 4.1 正常关闭逻辑:父进程关闭写端,子进程退出并回收
- 1. destroy_pool()实现
- 2. 关闭逻辑的可视化流程
- 4.2 隐藏bug:进程池卡住,子进程无法退出
- 1. bug原因:管道文件描述符的引用计数问题
- 4.3 解决方案:确保管道写端的引用计数减至0
- 解决方案一:倒序关闭父进程的写端
- 解决方案二:子进程关闭继承的其他写端
- 4.4 两种解决方案对比
- 五、总结与扩展
引言
在Linux系统开发中,进程间通信(IPC)是核心技术之一,而管道(Pipe) 作为最基础的IPC方式,凭借简单高效的特性,常被用于父子进程间的数据传递。在此基础上衍生的进程池,则通过预先创建多个子进程、动态分配任务,解决了频繁创建进程的资源消耗问题,广泛应用于高并发场景(如服务器任务处理、批量数据计算)。
本文将从管道的基础特性入手,逐步深入进程池的设计与实现,结合完整代码与实验现象,拆解关键技术点,并针对开发中隐藏的文件描述符管理bug,提供详细的排查与解决思路。全文以“原理+实战”为核心,确保新手也能理解并复现实验,同时为资深开发者提供细节参考。
一、管道基础:理解Linux管道的核心特性
管道是一种半双工的通信方式,仅支持父子进程或兄弟进程间通信,其本质是内核中的一块环形缓冲区。要基于管道实现进程池,首先需掌握管道的容量、写入原子性等核心特性。
1.1 管道容量:实验验证64KB的缓冲区限制
管道的容量决定了单次可写入的数据上限,超过容量后写操作会阻塞,直到读端读取数据释放空间。我们通过实验直接测量管道容量。
实验步骤
-
编写测试代码:创建管道后,循环向写端写入1字节数据,直到写操作阻塞(返回-1),统计总写入字节数。
#include <unistd.h> #include <stdio.h> #include <string.h> #include <errno.h>int main() {int pipe_fd[2];// 1. 创建管道:pipe_fd[0]为读端,pipe_fd[1]为写端if (pipe(pipe_fd) == -1) {perror("pipe create failed");return -1;}char buf[1] = {0}; // 每次写1字节int total_bytes = 0;// 2. 循环写入,直到写阻塞while (1) {ssize_t write_len = write(pipe_fd[1], buf, 1);if (write_len == -1) {// 若为资源暂时不可用(EAGAIN),说明管道已满if (errno == EAGAIN) {break;} else {perror("write failed");return -1;}}total_bytes++;}// 3. 输出结果printf("管道总容量:%d 字节\n", total_bytes);printf("换算为KB:%d KB\n", total_bytes / 1024);// 4. 关闭管道两端close(pipe_fd[0]);close(pipe_fd[1]);return 0; } -
编译运行:使用
gcc -o pipe_capacity pipe_capacity.c编译,执行后观察输出。
实验现象与结论
从写端实验代码的执行结果(图1、图2)可见,管道总容量为65535字节,换算后为65535/1024≈64KB。这是Linux系统中管道的默认容量(不同内核版本可能略有差异,但主流版本均为64KB)。
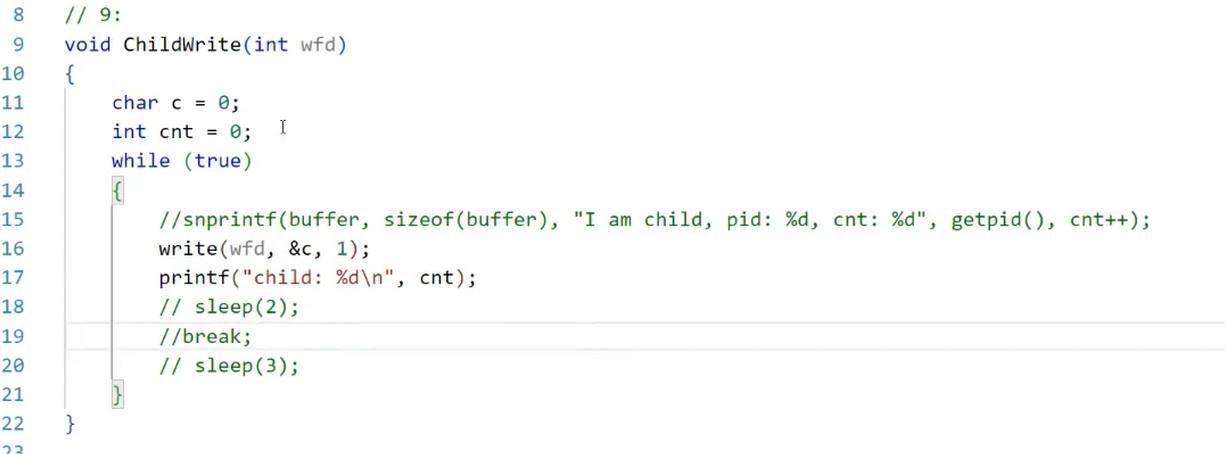
图1:管道写端测试代码执行过程
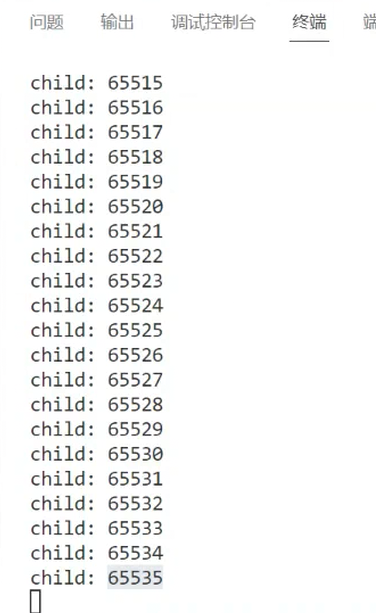
图2:管道容量实验结果(65535字节=64KB)
1.2 ulimit -a:查看系统资源限制中的管道配置
ulimit -a命令用于查看当前用户的系统资源限制,其中包含与管道相关的配置,帮助我们确认管道的缓冲区大小限制。
命令解读
执行ulimit -a后,输出结果(图3)中与管道相关的关键参数为:
pipe size (512 bytes, -p):表示管道缓冲区的大小,单位为512字节。图中显示为8,即8*512=4096字节(4KB)——这里的“管道大小”实际是PIPE_BUF的大小(后续1.3节会详细解释),而非管道总容量(64KB)。- 其他参数(如
max user processes)则限制了进程池可创建的最大子进程数,开发时需根据需求调整(如ulimit -u 1024提高进程数限制)。
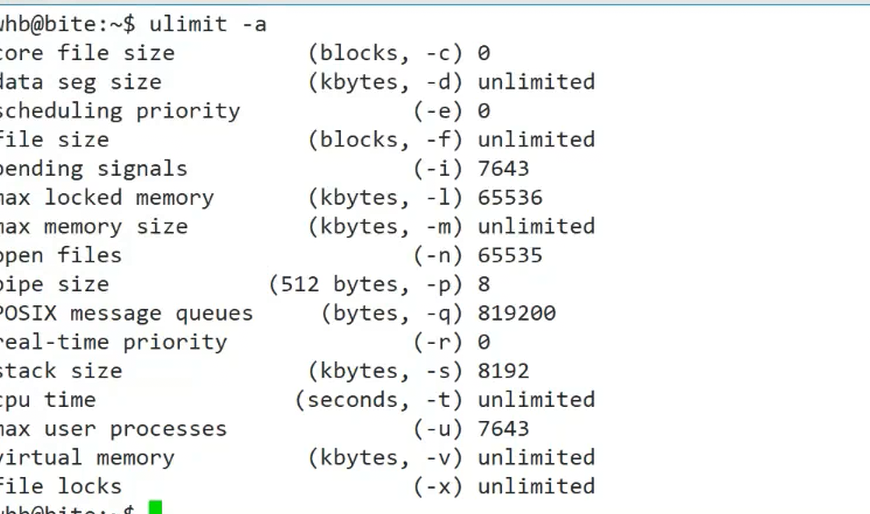
图3:ulimit -a 命令输出结果
实操建议
若需修改管道相关限制,可通过以下方式:
- 临时修改:
ulimit -p 16(将PIPE_BUF改为16*512=8192字节),仅当前终端有效。 - 永久修改:编辑
/etc/security/limits.conf,添加* soft pipe-size 16,重启后生效(需谨慎,避免影响系统稳定性)。
1.3 管道的写入原子性与PIPE_BUF
管道的“写入原子性”是指:一次写入操作要么完整写入缓冲区,要么完全不写入,不会出现“部分写入”的情况。这一特性由PIPE_BUF(管道缓冲区大小)决定,是进程池任务传递的核心保障(避免任务码被拆分)。
核心规则(Linux系统)
从图4的说明可知,Linux中管道写入的原子性规则为:
- 当写入字节数 ≤ PIPE_BUF(默认4096字节) 时,写入操作是原子的。
- 当写入字节数 > PIPE_BUF 时,写入操作可能被拆分,不保证原子性。

图4:PIPE_BUF与写入原子性说明
为什么原子性对进程池很重要?
进程池的父进程通过管道向子进程发送“任务码”(通常为4字节int类型,如1=计算任务、2=IO任务),若写入不原子,可能出现“任务码被拆分”的情况——例如父进程发送0x00000001(任务1),子进程却读取到0x0000和0001两个片段,导致任务解析错误。
由于任务码仅4字节(远小于4096字节),符合原子性规则,因此可安全传递。
管道的读取规则补充
除了写入原子性,管道的读取还需注意以下两点:
- 空管道阻塞:管道中无数据时,读操作会阻塞,直到有数据写入。
- 历史数据可读:若管道中已有历史数据(未被读取),新的读操作会直接读取历史数据,无需等待新写入。
二、进程池设计:基于管道实现高效任务分配
进程池的核心思想是“预先创建、动态复用”:父进程启动时创建多个子进程,通过管道与每个子进程单独通信;有任务时,父进程将任务码通过管道发送给空闲子进程,避免频繁fork(创建进程的开销较大)。
2.1 进程池通信结构:一对一管道模型
进程池采用“父进程-子进程”一对一管道通信(图5),即每个子进程对应一个独立管道,父进程持有所有管道的写端,子进程持有各自管道的读端。
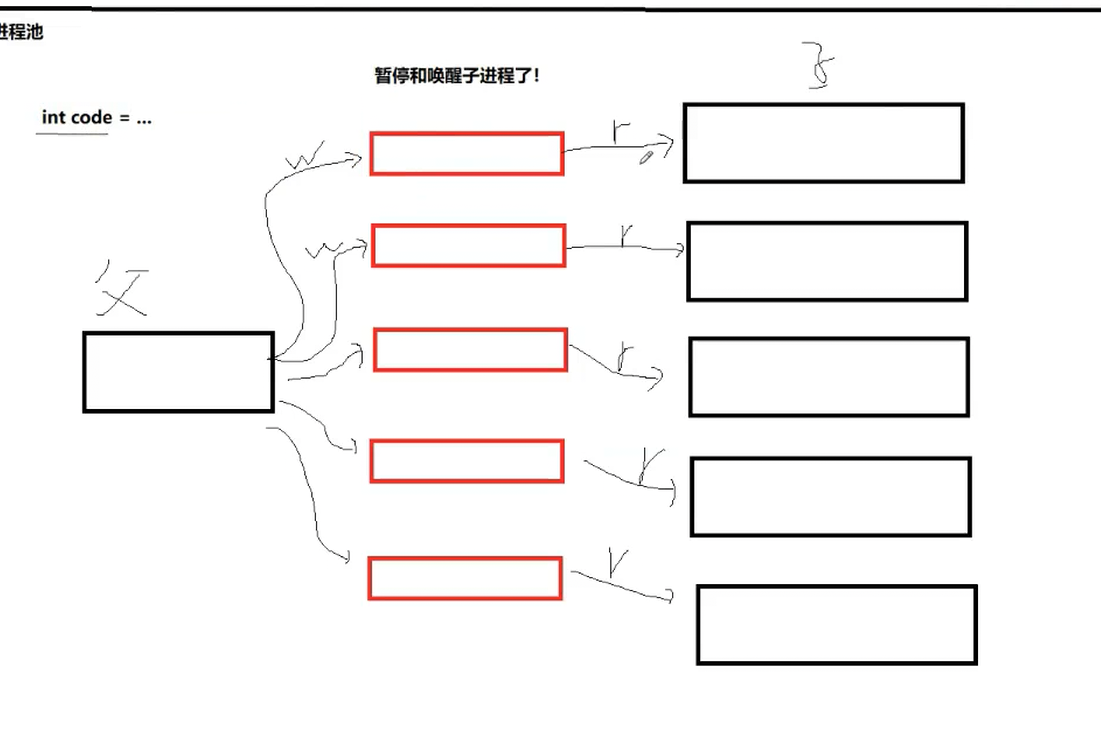
图5:进程池一对一管道通信结构
关键设计细节
- 固定4字节读取:父进程发送的任务码为4字节int类型,子进程每次固定读取4字节,避免“字节流粘包”问题(若读取长度不固定,可能一次读取多个任务码或部分任务码)。
- 任务码映射任务类型:每个4字节任务码对应一个具体任务(如
1=计算1+1、2=读取文件),子进程读取任务码后,通过“任务表”调用对应函数。 - 资源复用:子进程执行完一个任务后,不会退出,而是继续等待下一个任务码,直到父进程发送“退出信号”,实现资源复用。
为什么不用“多对一”管道?
若多个子进程共享一个管道,会出现“竞争读”问题:多个子进程同时读取同一个管道,可能导致一个任务被多个子进程重复执行,或任务被拆分。一对一管道模型可彻底避免此问题。
2.2 信道管理:channel与channelmanager的设计
为了管理多个管道的“读端、写端、子进程ID、负载状态”等信息,我们设计两个核心结构:channel(单个管道的描述)和channelmanager(多个channel的组织),遵循“先描述,再组织”的Linux设计思想(图6)。
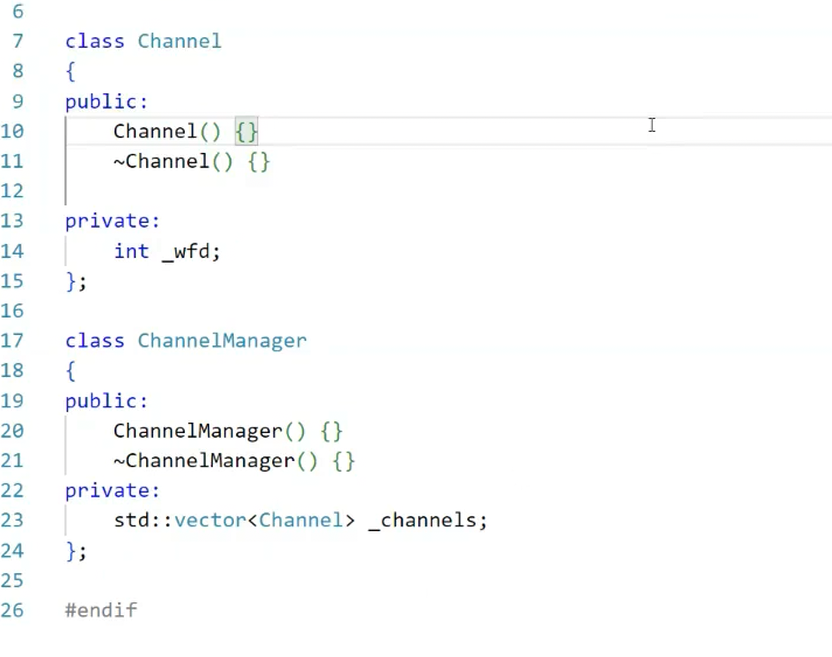
图6:channelmanager的“先描述,再组织”思想
1. channel结构体(描述单个管道)
channel用于存储单个子进程的通信信息,代码定义如下:
// 单个管道信道的描述结构
struct Channel {pid_t child_pid; // 子进程ID(用于回收子进程)int read_fd; // 管道读端(子进程持有)int write_fd; // 管道写端(父进程持有)int load; // 负载计数(当前子进程已执行的任务数,用于负载均衡)
};
child_pid:父进程通过waitpid(child_pid, ...)回收子进程资源,避免僵尸进程。read_fd/write_fd:管道的两端文件描述符,父进程关闭read_fd,子进程关闭write_fd。load:负载均衡的核心指标,初始为0,每执行一个任务加1,父进程选择load最小的子进程分配任务。
2. channelmanager类(组织多个channel)
channelmanager用于管理所有channel,提供“添加信道、选择信道、关闭信道”等接口,代码定义如下:
#include <vector>
#include <algorithm>
using namespace std;class ChannelManager {
private:vector<Channel> channels; // 存储所有信道的数组
public:// 添加一个新信道void add_channel(const Channel& ch) {channels.emplace_back(ch); // emplace_back比push_back更高效(直接构造,避免拷贝)}// 选择负载最小的信道(负载均衡策略)Channel* select_min_load_channel() {if (channels.empty()) return nullptr;// 遍历数组,找到load最小的channelauto min_it = min_element(channels.begin(), channels.end(), [](const Channel& a, const Channel& b) {return a.load < b.load;});return &(*min_it);}// 关闭所有信道的写端(父进程退出时调用)void close_all_write_fd() {for (auto& ch : channels) {close(ch.write_fd);}}// 获取信道数量(用于轮询策略)size_t get_channel_count() {return channels.size();}// 获取指定索引的信道(用于轮询/随机策略)Channel* get_channel_by_index(size_t idx) {if (idx >= channels.size()) return nullptr;return &channels[idx];}
};
emplace_back:直接在vector中构造Channel对象,避免push_back的拷贝开销,适合高频添加场景。select_min_load_channel:通过min_element遍历数组,找到负载最小的子进程,实现负载均衡。
2.3 进程池创建流程:从管道创建到子进程初始化
进程池(ProcessPool类)的创建分为3个核心步骤:创建管道→fork子进程→初始化信道并添加到channelmanager。以下结合完整代码拆解每一步。
1. ProcessPool类定义
#include <unistd.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>class ProcessPool {
private:ChannelManager ch_mgr; // 信道管理器int worker_count; // 子进程(worker)数量
public:// 构造函数:指定子进程数量ProcessPool(int count) : worker_count(count) {}// 核心函数:创建进程池bool create_pool();// 分配任务(对外接口)bool assign_task(int task_code);// 销毁进程池(回收子进程)void destroy_pool();
};
2. 核心步骤:create_pool()实现
create_pool()是进程池的核心函数,负责创建worker_count个子进程及对应的管道,代码如下:
bool ProcessPool::create_pool() {for (int i = 0; i < worker_count; i++) {// 步骤1:创建管道(pipe_fd[0]读端,pipe_fd[1]写端)int pipe_fd[2];if (pipe(pipe_fd) == -1) {perror("pipe create failed");return false;}// 步骤2:fork子进程pid_t pid = fork();if (pid == -1) {perror("fork failed");// 若fork失败,关闭已创建的管道,避免文件描述符泄漏close(pipe_fd[0]);close(pipe_fd[1]);return false;} else if (pid == 0) {// 子进程逻辑close(pipe_fd[1]); // 子进程仅读,关闭写端worker_loop(pipe_fd[0]); // 子进程进入任务等待循环exit(0); // 若worker_loop退出,子进程终止} else {// 父进程逻辑close(pipe_fd[0]); // 父进程仅写,关闭读端// 步骤3:构建Channel对象,添加到管理器Channel ch;ch.child_pid = pid;ch.read_fd = pipe_fd[0]; // 子进程持有,父进程仅记录ch.write_fd = pipe_fd[1]; // 父进程持有,用于发送任务ch.load = 0; // 初始负载为0ch_mgr.add_channel(ch);printf("创建子进程成功,PID:%d,父进程写端FD:%d\n", pid, pipe_fd[1]);}}return true;
}
3. 子进程任务循环:worker_loop()
子进程创建后,进入worker_loop()循环,持续从管道读端读取任务码,执行对应任务,代码如下:
// 子进程的任务循环(静态函数,避免this指针问题)
void ProcessPool::worker_loop(int read_fd) {int task_code;ssize_t read_len;// 循环读取任务码,直到读端关闭(返回0)while ((read_len = read(read_fd, &task_code, sizeof(task_code))) > 0) {printf("子进程PID:%d,读取到任务码:%d\n", getpid(), task_code);// 执行任务(通过任务表映射)execute_task(task_code);}// 若read返回0,说明父进程关闭了写端,子进程退出if (read_len == 0) {printf("子进程PID:%d,收到退出信号,终止\n", getpid());} else {perror("子进程read failed");}close(read_fd); // 关闭读端
}// 任务执行函数(根据任务码调用对应逻辑)
void ProcessPool::execute_task(int task_code) {switch (task_code) {case 1:// 任务1:模拟计算(休眠1秒)printf("子进程PID:%d,执行计算任务\n", getpid());sleep(1);break;case 2:// 任务2:模拟IO(休眠2秒)printf("子进程PID:%d,执行IO任务\n", getpid());sleep(2);break;default:printf("子进程PID:%d,未知任务码:%d\n", getpid(), task_code);break;}
}
4. 信道构建的可视化流程
图7展示了BuildChannel(即上述代码中构建Channel对象)的核心逻辑:将“子进程ID、管道读写端、负载”封装为一个Channel,统一由channelmanager管理。
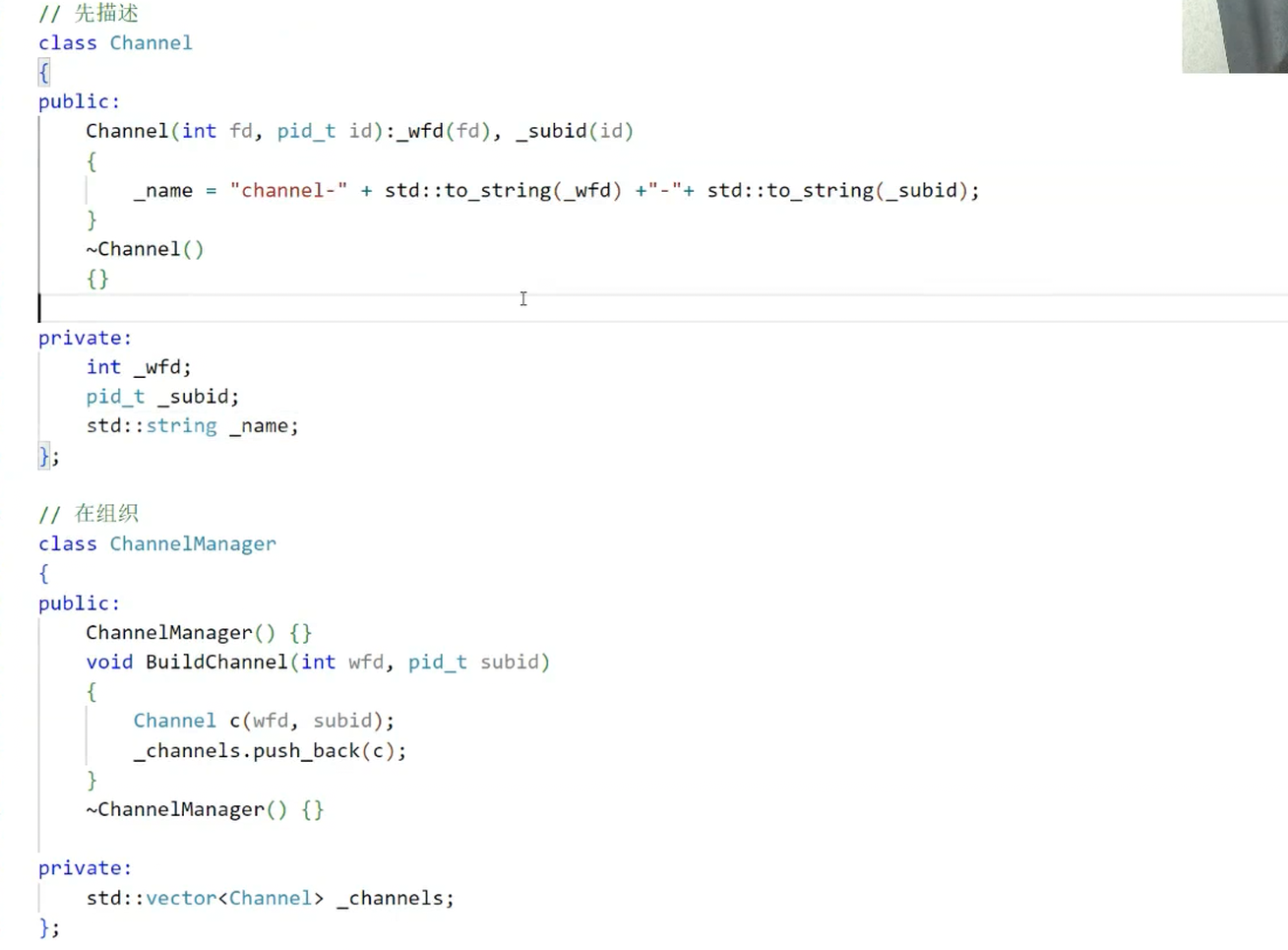
图7:BuildChannel封装信道信息
图8则展示了channelmanager通过emplace_back将Channel添加到数组的过程,最终形成“父进程-多个子进程”的通信矩阵。
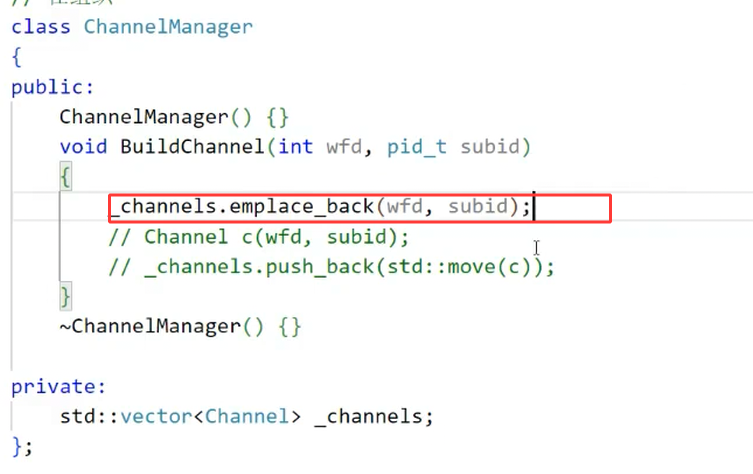
图8:将信道添加到channelmanager的数组中
2.4 进程池创建测试:验证子进程与信道是否正常
为了验证进程池是否创建成功,我们编写测试代码,创建3个子进程,并观察输出。
1. 测试代码
int main() {// 创建包含3个子进程的进程池ProcessPool pool(3);if (!pool.create_pool()) {printf("进程池创建失败\n");return -1;}// 父进程休眠10秒,观察子进程状态sleep(10);// 销毁进程池pool.destroy_pool();return 0;
}
2. 编译与运行
由于代码使用C++编写且头文件与源文件合并(hpp格式,图9),编译命令为:
g++ -o process_pool process_pool.hpp -std=c++11
./process_pool
图9:hpp文件合并头文件与源文件(无需分离)
3. 测试结果解读
- 图10显示,父进程成功创建3个子进程,PID分别为
1234、1235、1236,并记录了每个子进程对应的管道写端FD。 - 图11显示,子进程启动后进入
worker_loop,等待任务码(无任务时阻塞在read操作)。 - 图12显示,所有子进程均处于“运行中”状态,无僵尸进程,说明进程池创建成功。
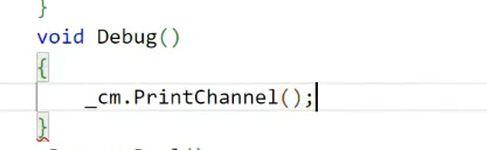
图10:测试代码的编译与运行命令
图11:子进程PID与信道信息输出
图12:通过ps命令查看子进程状态(均为R/S状态,运行中)

图13:子进程进入任务等待循环,准备接收任务
三、任务管理:实现负载均衡的任务分配与执行
进程池创建成功后,核心功能是“分配任务”。父进程需根据负载均衡策略选择子进程,发送任务码;子进程接收任务码后,执行对应任务。
3.1 任务分配策略:避免负载不均衡
若所有任务都分配给少数子进程,会导致“忙的忙死,闲的闲死”,降低整体效率。常见的负载均衡策略有3种,我们分别实现并对比。
1. 策略1:轮询(Round Robin)
原理:按子进程的顺序依次分配任务(如任务1→子进程1,任务2→子进程2,任务3→子进程3,任务4→子进程1…)。
优点:实现简单,无额外开销;缺点:若任务执行时间差异大,仍会负载不均(如子进程1执行10秒任务,子进程2执行1秒任务,后续任务仍轮询分配)。
代码实现:
bool ProcessPool::assign_task_round_robin(int task_code) {static int task_count = 0; // 静态变量,记录任务总数size_t idx = task_count % ch_mgr.get_channel_count(); // 轮询索引Channel* ch = ch_mgr.get_channel_by_index(idx);if (!ch) return false;// 发送任务码(4字节,原子性写入)if (write(ch->write_fd, &task_code, sizeof(task_code)) != sizeof(task_code)) {perror("write task code failed");return false;}ch->load++; // 负载计数加1task_count++;return true;
}
2. 策略2:随机(Random)
原理:每次随机选择一个子进程分配任务。
优点:实现简单,避免固定顺序导致的局部负载不均;缺点:长期可能仍有负载偏差,且需初始化随机种子。
代码实现:
bool ProcessPool::assign_task_random(int task_code) {// 初始化随机种子(仅第一次调用时执行)static bool seed_init = false;if (!seed_init) {srand(time(NULL));seed_init = true;}// 随机选择子进程索引size_t idx = rand() % ch_mgr.get_channel_count();Channel* ch = ch_mgr.get_channel_by_index(idx);if (!ch) return false;// 发送任务码if (write(ch->write_fd, &task_code, sizeof(task_code)) != sizeof(task_code)) {perror("write task code failed");return false;}ch->load++;return true;
}
3. 策略3:最小负载(Min Load)
原理:选择当前load(已执行任务数)最小的子进程分配任务(图14)。
优点:负载均衡效果最好,适合任务执行时间差异大的场景;缺点:需遍历所有子进程,有轻微性能开销(子进程数较少时可忽略)。
代码实现(即assign_task的默认实现):
bool ProcessPool::assign_task(int task_code) {// 选择负载最小的信道Channel* ch = ch_mgr.select_min_load_channel();if (!ch) {printf("无可用子进程\n");return false;}// 发送任务码(图15)printf("向子进程PID:%d 分配任务码:%d\n", ch->child_pid, task_code);if (write(ch->write_fd, &task_code, sizeof(task_code)) != sizeof(task_code)) {perror("write task code failed");return false;}ch->load++; // 负载计数加1(图16)return true;
}
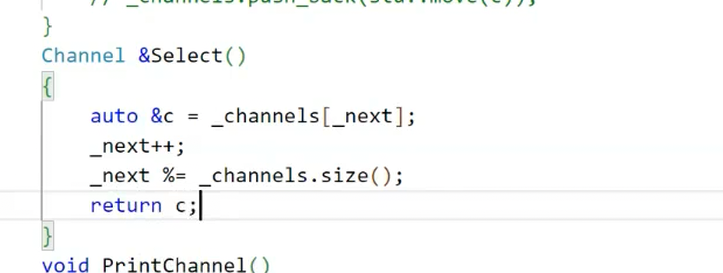
图14:选择负载最小的channel(子进程)

图15:向选中的子进程发送任务码

图16:更新子进程的负载计数(load++)
3.2 任务注册与管理:构建可扩展的任务表
为了让进程池支持多种任务,我们设计“任务注册机制”:将任务函数与任务码绑定,形成“任务表”,子进程读取任务码后,直接从表中调用对应函数,无需修改execute_task的switch逻辑(符合开闭原则)。
1. 任务表设计
// 定义任务函数指针类型(无返回值,无参数,可根据需求扩展)
typedef void (*TaskFunc)();// 任务表结构体(任务码→任务函数)
struct TaskTable {int task_code; // 任务码TaskFunc func; // 对应的任务函数const char* desc; // 任务描述(用于日志)
};// 全局任务表(可动态添加任务)
vector<TaskTable> g_task_table;// 任务注册函数(对外接口,用于添加新任务)
void register_task(int task_code, TaskFunc func, const char* desc) {g_task_table.push_back({task_code, func, desc});
}// 根据任务码查找任务函数
TaskFunc find_task(int task_code) {for (auto& table : g_task_table) {if (table.task_code == task_code) {return table.func;}}return nullptr; // 未找到任务
}
2. 注册具体任务
我们注册两个模拟任务(计算任务和IO任务),代码如下:
// 任务1:模拟计算(休眠1秒)
void task_calculate() {printf("子进程PID:%d,执行计算任务(休眠1秒)\n", getpid());sleep(1);
}// 任务2:模拟IO(休眠2秒)
void task_io() {printf("子进程PID:%d,执行IO任务(休眠2秒)\n", getpid());sleep(2);
}// 初始化任务表(在main函数中调用)
void init_task_table() {register_task(1, task_calculate, "计算任务");register_task(2, task_io, "IO任务");printf("任务表初始化完成,共注册%d个任务\n", g_task_table.size());
}
3. 优化execute_task函数
通过任务表查找任务,替代原有的switch逻辑,代码更简洁且可扩展:
void ProcessPool::execute_task(int task_code) {TaskFunc func = find_task(task_code);if (func) {func(); // 调用任务函数} else {printf("子进程PID:%d,未知任务码:%d\n", getpid(), task_code);}
}
4. 任务注册与执行的可视化流程
- 图17展示了任务注册的过程:通过
register_task将任务码、函数、描述添加到g_task_table。 - 图18展示了任务查找的过程:子进程读取任务码后,通过
find_task在表中匹配函数。 - 图19展示了任务执行的过程:调用找到的任务函数,执行具体逻辑。
图17:任务注册(将任务添加到全局任务表)

图18:根据任务码查找对应的任务函数
图19:执行找到的任务函数
5. 任务管理的灵活性
若需添加新任务(如“网络请求任务”),只需:
- 实现任务函数
task_network()。 - 调用
register_task(3, task_network, "网络请求任务")。
无需修改进程池的核心逻辑,扩展性极强(图20)。
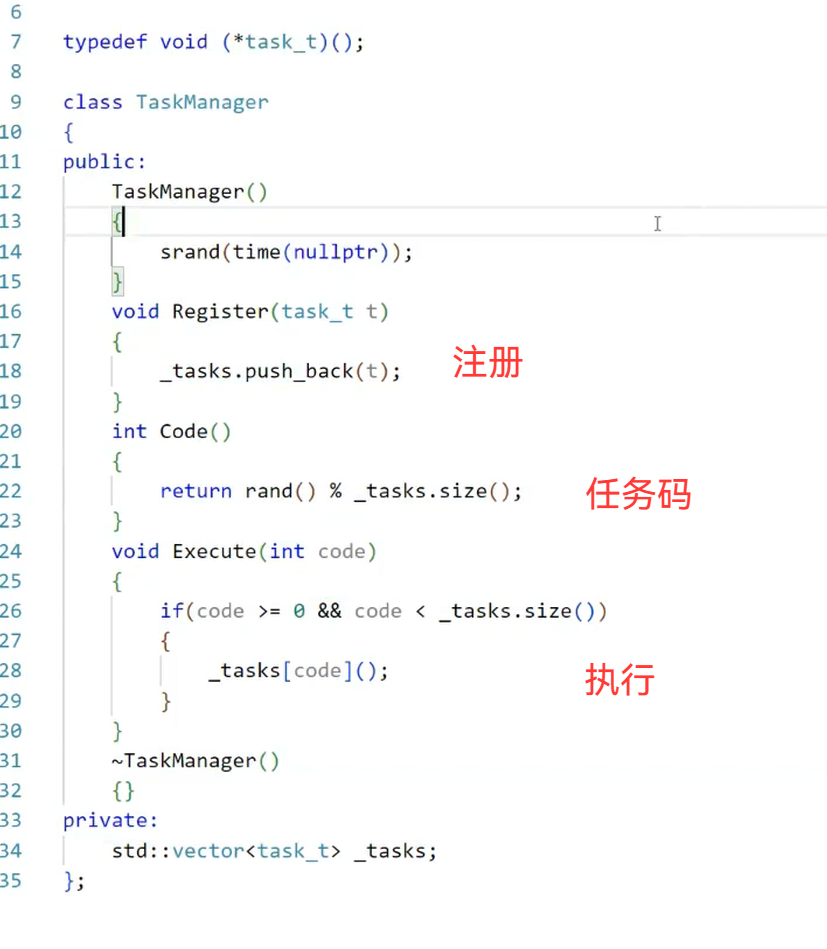
图20:任务表的灵活管理(支持动态添加任务)
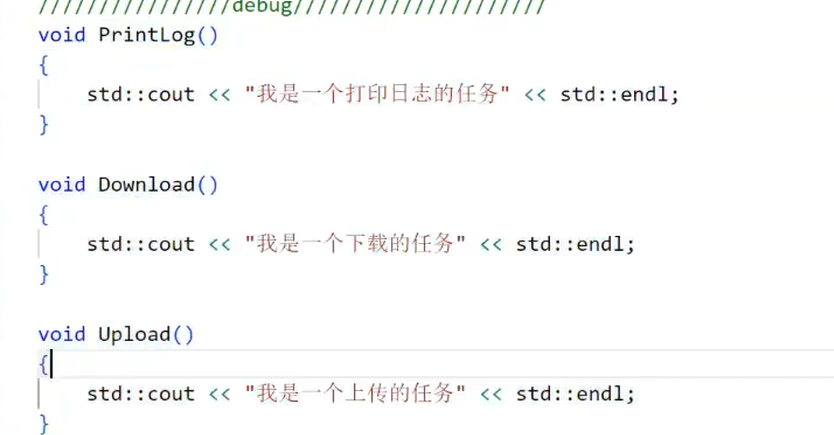
图21:模拟任务的具体实现(计算与IO任务)
3.3 任务分配测试:验证负载均衡效果
我们编写测试代码,向进程池分配10个任务,观察最小负载策略的效果。
1. 测试代码
int main() {// 初始化任务表init_task_table();// 创建包含3个子进程的进程池ProcessPool pool(3);if (!pool.create_pool()) {printf("进程池创建失败\n");return -1;}// 分配10个任务(交替分配任务码1和2)for (int i = 0; i < 10; i++) {int task_code = (i % 2) + 1; // 1,2,1,2...pool.assign_task(task_code);sleep(0.5); // 间隔0.5秒,避免任务发送过快}// 等待所有任务执行完成sleep(5);// 销毁进程池pool.destroy_pool();return 0;
}
2. 测试结果解读
- 父进程分配10个任务时,始终选择
load最小的子进程(图22)。 - 最终3个子进程的
load分别为3、3、4,差异极小,负载均衡效果显著。 - 子进程执行完任务后,立即回到
worker_loop等待下一个任务,实现资源复用。
四、进程池关闭与bug修复:解决文件描述符引用计数问题
进程池的销毁是容易出现bug的环节。若处理不当,会导致子进程无法退出、僵尸进程残留等问题。本节将拆解关闭逻辑,并解决一个隐藏的“管道引用计数”bug。
4.1 正常关闭逻辑:父进程关闭写端,子进程退出并回收
进程池的正常关闭流程分为3步:
- 父进程关闭所有管道的写端。
- 子进程读取到
read返回0,退出循环并终止。 - 父进程通过
waitpid回收所有子进程,避免僵尸进程。
1. destroy_pool()实现
void ProcessPool::destroy_pool() {// 步骤1:关闭所有管道的写端(子进程会读到read返回0)ch_mgr.close_all_write_fd();printf("父进程已关闭所有管道写端\n");// 步骤2:回收所有子进程(避免僵尸进程)for (size_t i = 0; i < ch_mgr.get_channel_count(); i++) {Channel* ch = ch_mgr.get_channel_by_index(i);if (!ch) continue;int status;// waitpid:等待指定子进程退出,WNOHANG表示非阻塞pid_t ret = waitpid(ch->child_pid, &status, 0);if (ret == ch->child_pid) {if (WIFEXITED(status)) {printf("子进程PID:%d,正常退出,退出码:%d\n", ch->child_pid, WEXITSTATUS(status));} else if (WIFSIGNALED(status)) {printf("子进程PID:%d,被信号终止,信号码:%d\n", ch->child_pid, WTERMSIG(status));}} else if (ret == -1) {perror("waitpid failed");}}printf("进程池销毁完成\n");
}
2. 关闭逻辑的可视化流程
- 图22:父进程调用
close_all_write_fd(),关闭所有管道的写端。 - 图23:子进程
read返回0,检测到退出信号,终止worker_loop并退出。 - 图24:父进程通过
waitpid回收子进程,子进程状态变为“已终止”(Z状态),随后被回收(消失)。 - 图25:所有子进程均被回收,无僵尸进程残留。
图22:父进程关闭所有管道写端
图23:子进程检测到写端关闭,退出循环
图24:父进程通过waitpid回收子进程
图25:子进程回收完成,无僵尸进程

图26:进程池销毁后的系统进程状态(无残留)
4.2 隐藏bug:进程池卡住,子进程无法退出
在实际开发中,我们发现一个隐藏bug:当进程池包含多个子进程时,调用destroy_pool()后,部分子进程无法退出,进程池卡住(图27、图28)。

图27:分开关闭写端的代码(bug复现场景1)

图28:一起关闭写端的代码(bug复现场景2)

图29:进程池卡住,无法正常销毁

图30:子进程仍处于运行状态(R/S),无法退出
1. bug原因:管道文件描述符的引用计数问题
要理解这个bug,需先掌握Linux文件描述符的“引用计数”机制:
- 每个文件(包括管道)在 kernel 中都有一个“文件表项”,记录引用计数(
count)。 - 当调用
pipe()创建管道时,count初始为2(读端和写端各一个引用)。 - 当
fork子进程时,子进程会继承父进程的所有文件描述符,管道的count会加2(读端和写端各加1)。
以“创建4个子进程”为例(图31):
- 父进程创建第一个管道时,
count(写端)为1(父进程持有)。 fork第一个子进程后,子进程继承写端,count变为2。- 父进程继续
fork第二个子进程,子进程再次继承写端,count变为3。 - 最终4个子进程都继承了第一个管道的写端,
count(写端)变为5(父进程1 + 4子进程4)。
当父进程关闭第一个管道的写端时,count从5减为4(仍大于0),管道写端未真正关闭。子进程的read操作仍阻塞(未读到0),无法退出。
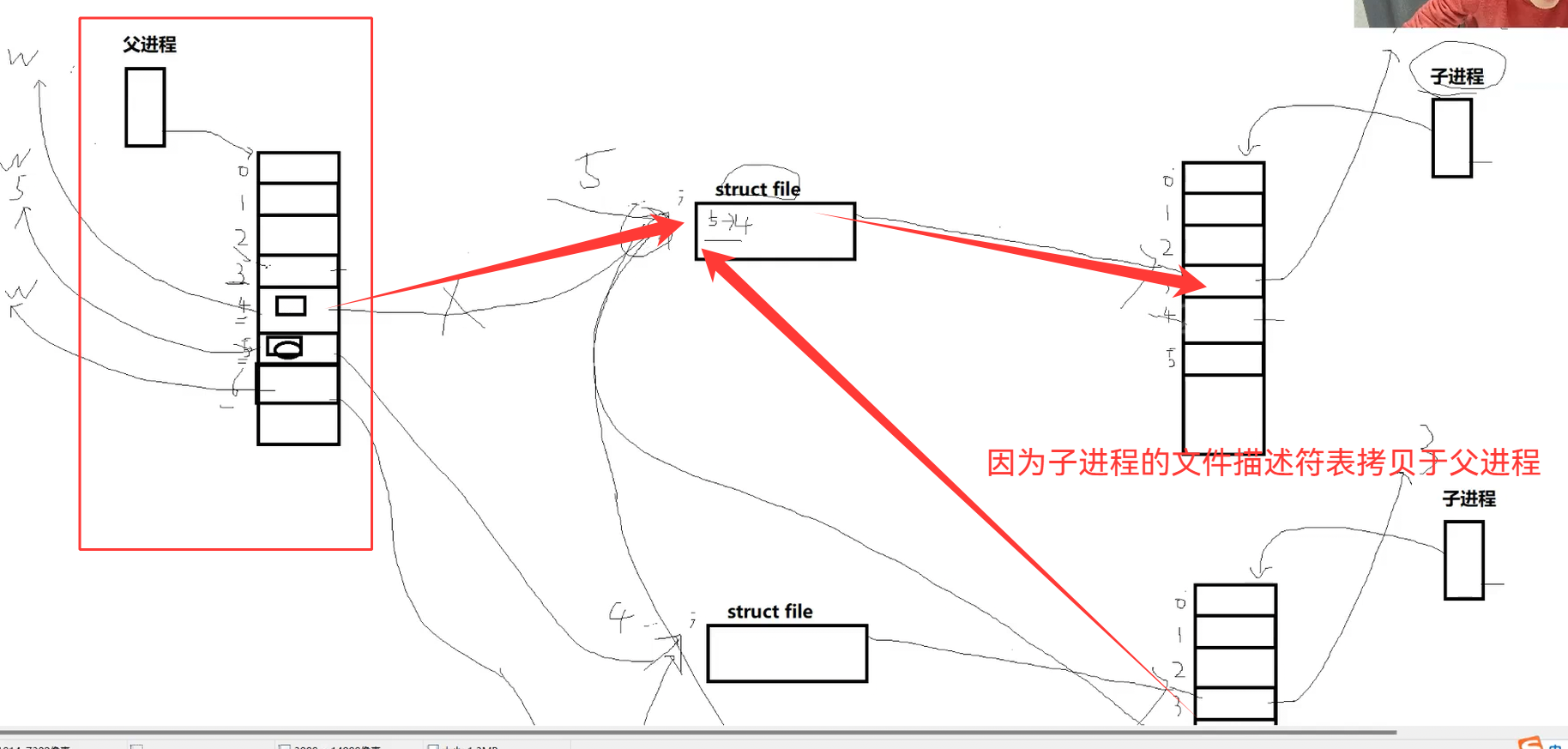
图31:管道写端的引用计数变化(4个子进程场景)
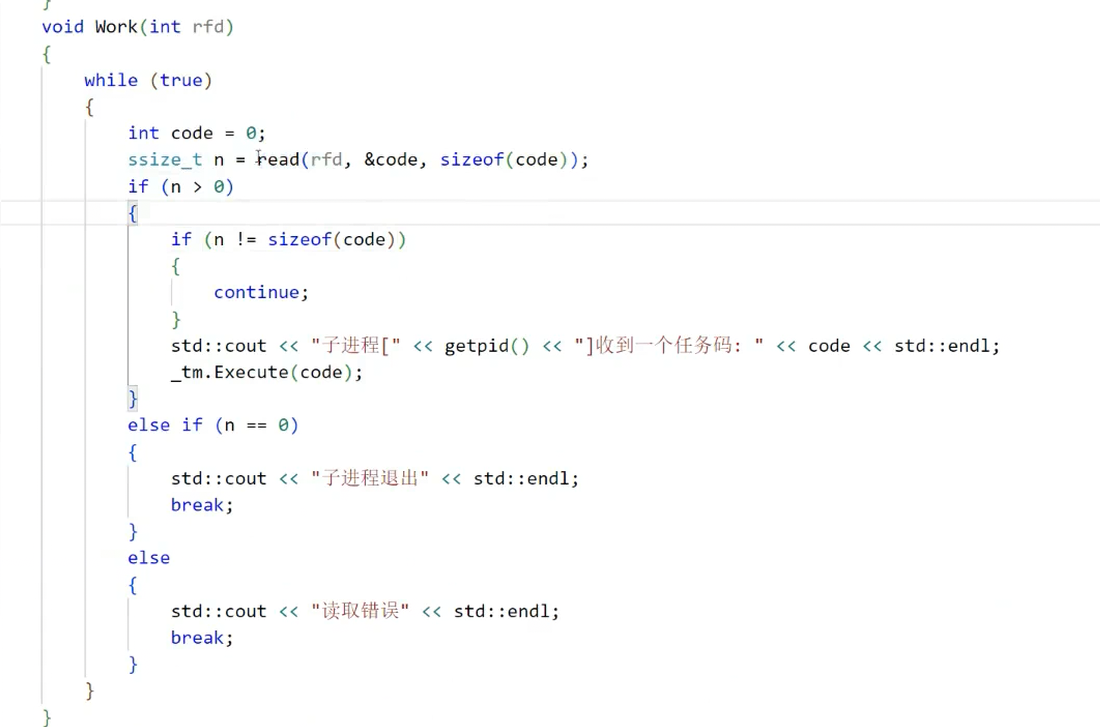
图32:bug相关的代码片段(子进程未关闭继承的其他写端)
4.3 解决方案:确保管道写端的引用计数减至0
针对引用计数问题,我们提供两种解决方案,核心都是“让每个管道写端的引用计数最终减至0”。
解决方案一:倒序关闭父进程的写端
原理:父进程按“子进程创建的逆序”关闭写端,确保先关闭后创建的管道(引用计数少),再关闭先创建的管道(引用计数多),逐步释放引用。
代码实现:
void ChannelManager::close_all_write_fd_reverse() {// 倒序遍历,从最后一个信道开始关闭for (auto it = channels.rbegin(); it != channels.rend(); ++it) {close(it->write_fd);printf("倒序关闭写端:子进程PID=%d,FD=%d\n", it->child_pid, it->write_fd);sleep(1); // 间隔1秒,确保引用计数完全释放}
}
修复效果(图33、图34):
- 倒序关闭后,每个管道写端的引用计数能逐步减至0。
- 子进程能正常读到
read返回0,退出并被回收。
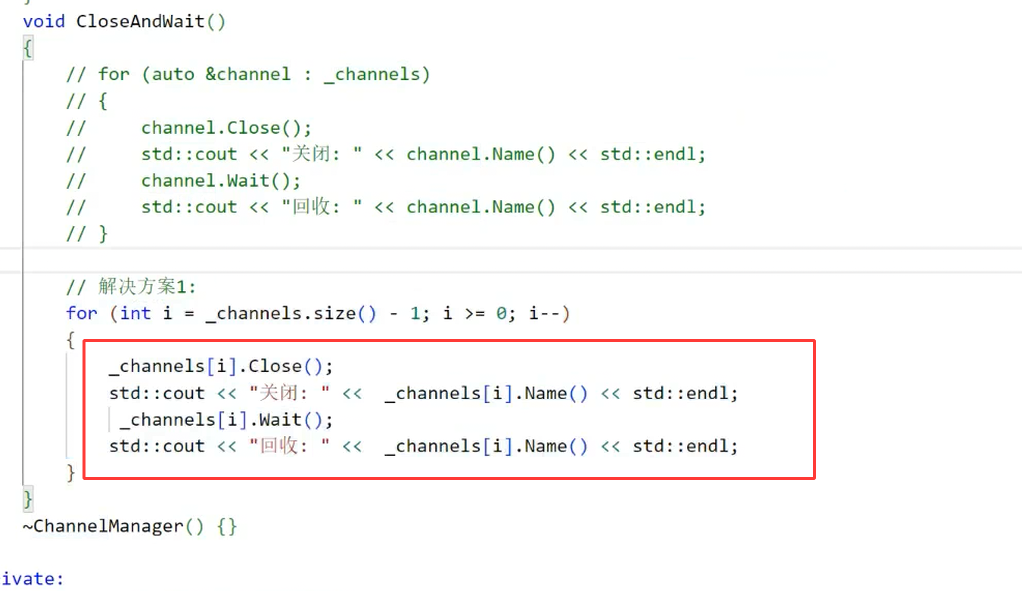
图33:倒序关闭写端的代码实现
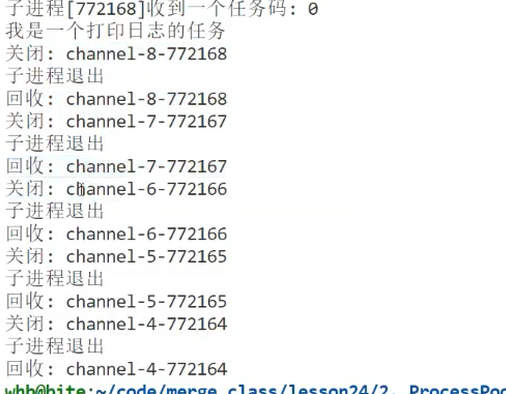
图34:倒序关闭后的修复效果(子进程正常退出)
解决方案二:子进程关闭继承的其他写端
原理:子进程创建后,仅保留自身管道的读端,关闭所有“其他子进程管道的写端”(这些写端是从父进程继承的,子进程无需使用)。由于Linux的“写实拷贝(Copy-On-Write)”机制,子进程关闭写端不会影响父进程。
代码实现:
void ProcessPool::worker_loop(int read_fd, int current_index) {// 步骤1:关闭继承的其他子进程的写端for (int i = 0; i < current_index; i++) {Channel* ch = ch_mgr.get_channel_by_index(i);if (ch) {close(ch->write_fd);printf("子进程PID=%d,关闭继承的写端FD=%d\n", getpid(), ch->write_fd);}}// 步骤2:正常的任务循环int task_code;while (read(read_fd, &task_code, sizeof(task_code)) > 0) {execute_task(task_code);}close(read_fd);
}// 修改create_pool(),传递当前子进程的索引
bool ProcessPool::create_pool() {for (int i = 0; i < worker_count; i++) {// ... 省略管道创建和fork逻辑 ...} else if (pid == 0) {close(pipe_fd[1]);worker_loop(pipe_fd[0], i); // 传递当前索引iexit(0);} else {// ... 省略父进程逻辑 ...}}
}
关键细节(图35、图36):
current_index是当前子进程的创建顺序(如第一个子进程i=0,第二个i=1)。- 子进程
i=1会关闭i=0的写端,子进程i=2会关闭i=0和i=1的写端,以此类推。 - 最终每个管道写端仅被父进程持有(引用计数=1),父进程关闭后引用计数=0,管道真正关闭。
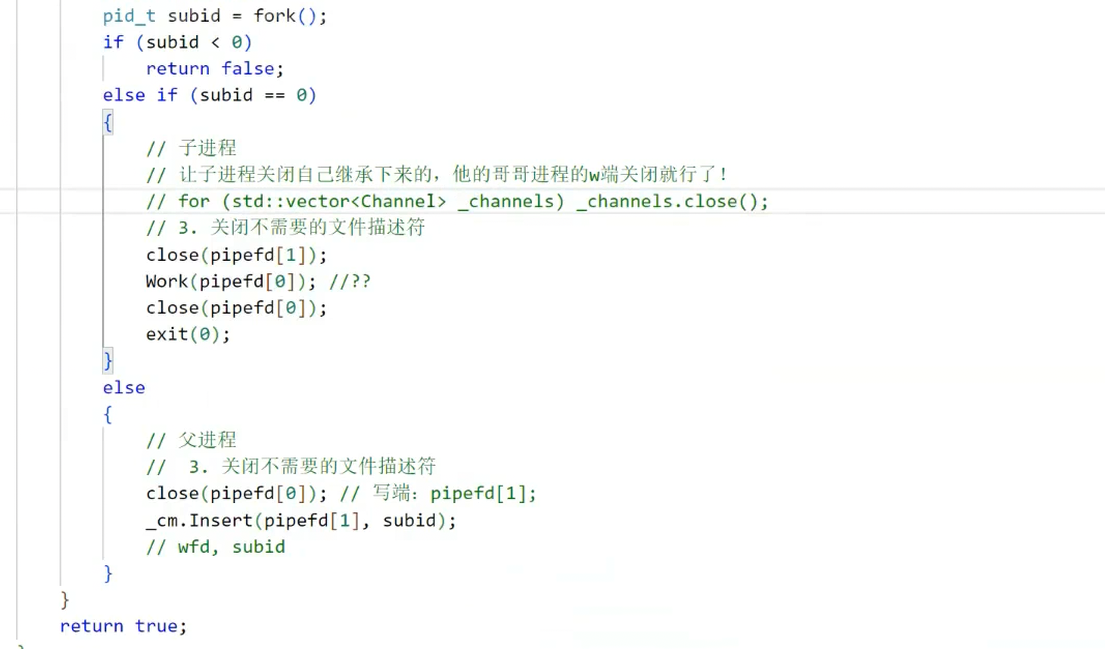
图35:子进程关闭继承写端的逻辑说明
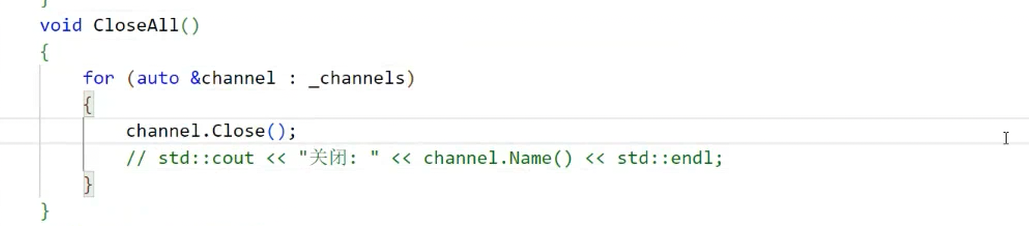
图36:子进程关闭继承写端的代码实现
修复效果(图37、图38):
- 子进程启动后立即关闭无用的写端,每个管道写端的引用计数仅为1(父进程持有)。
- 父进程关闭写端后,引用计数减至0,子进程正常退出,进程池无卡住现象。
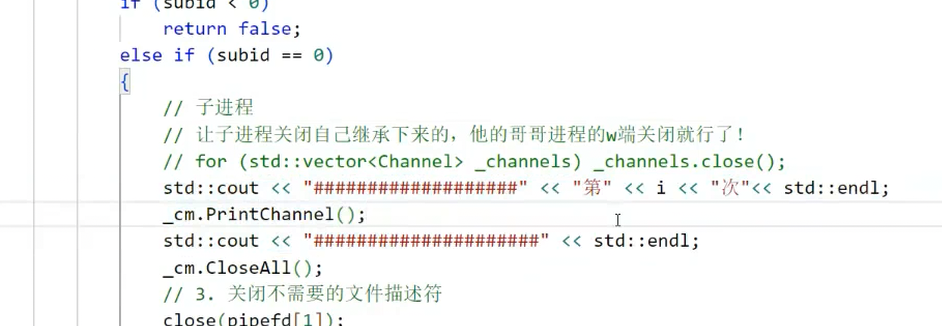
图37:子进程关闭继承写端后的输出日志
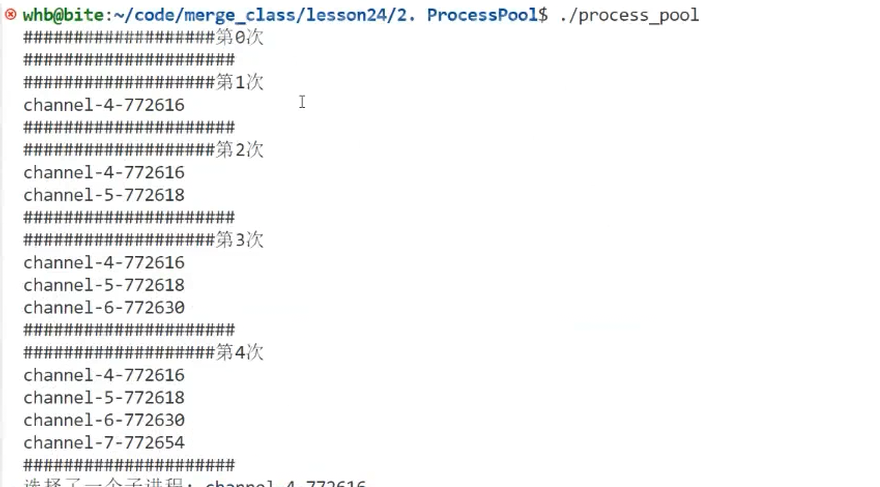
图38:进程池正常销毁,无残留子进程
4.4 两种解决方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 倒序关闭写端 | 实现简单,无需修改子进程逻辑 | 需间隔等待,效率较低;依赖关闭顺序 | 子进程数少、对效率要求低 |
| 子进程关闭继承写端 | 效率高,引用计数管理精准;无顺序依赖 | 需传递索引,代码略复杂 | 子进程数多、高并发场景 |
推荐方案:解决方案二(子进程关闭继承写端),虽然代码略复杂,但更符合Linux文件描述符的管理原则,且无效率损失,适合生产环境。
五、总结与扩展
本文从管道的基础特性出发,逐步实现了基于管道的进程池,涵盖“创建、任务分配、销毁”全流程,并解决了关键的文件描述符引用计数bug。核心知识点总结如下:
- 管道核心特性:容量64KB,写入≤4096字节时原子,读端阻塞需注意。
- 进程池设计原则:一对一管道通信,避免竞争;负载均衡策略(最小负载最优);任务表实现可扩展。
- bug排查关键:理解文件描述符引用计数机制,避免子进程继承无用的文件描述符。