生成对抗网络(GANs)深度解析:从原理、变体到前沿应用
前言
自2014年由Ian Goodfellow及其同事首次提出以来,生成对抗网络(Generative Adversarial Networks, GANs)已成为深度学习领域最引人注目和最具革命性的思想之一。它通过一个巧妙的“对抗”框架,使得模型能够学习并生成与真实数据分布极为相似的全新数据,尤其在图像生成领域取得了惊人的成果。GANs不仅推动了人工智能在创造性任务上的发展,也为无监督学习开辟了新的道路。
本文将全面深入地探讨GANs的核心原理、数学基础、关键架构、训练中的挑战,并介绍其重要的变体和广泛的应用场景,旨在为读者提供一份详尽而深入的GANs学习指南。
一、 GANs的核心思想:一场“伪造者”与“鉴赏家”的博弈
GANs的精髓在于其“对抗性训练”机制。我们可以通过一个生动的类比来理解这个过程:
- 生成器(Generator, G):扮演一个“艺术伪造者”的角色。它的目标是学习创作出能够以假乱真的艺术品(例如,画作)。它从一堆随机的、无意义的噪声(通常是一个来自特定分布的向量)开始,通过神经网络的学习,将其转换为一件“伪造”的作品。
- 判别器(Discriminator, D):扮演一个“艺术鉴赏家”的角色。它的任务是尽可能准确地判断一件作品是来自真实艺术家(真实数据集)的真品,还是由伪造者(生成器)创作的赝品。它本质上是一个二元分类器。
这场博弈的训练过程如下:
- 初始阶段:生成器(G)完全是随机的,它生成的作品杂乱无章,判别器(D)可以轻而易举地识别出这些是赝品。
- 判别器的学习:判别器会同时看到真实的作品和生成器生成的赝品,并被告知哪些是真、哪些是假。它通过学习,不断提升自己鉴别真伪的能力。
- 生成器的学习:生成器将自己生成的赝品交给判别器进行评判。它根据判别器的反馈(例如,判别器认为其作品是假的概率有多高)来调整自己的“创作技巧”。生成器的目标是“欺骗”判别器,让判别器相信它生成的作品是真实的。
- 循环对抗:这个过程不断迭代。判别器因为看到了越来越逼真的赝品而变得越来越挑剔;生成器为了欺骗更挑剔的判别器而努力提升自己的创作水平。
最终,理想情况下,这场博弈会达到一个“纳什均衡”点:生成器创作出的作品已经达到了以假乱真的地步,使得判别器无法分辨真伪,只能做出随机猜测(即判断为真的概率为50%)。此时,我们便认为生成器已经成功地学习到了真实数据的分布。
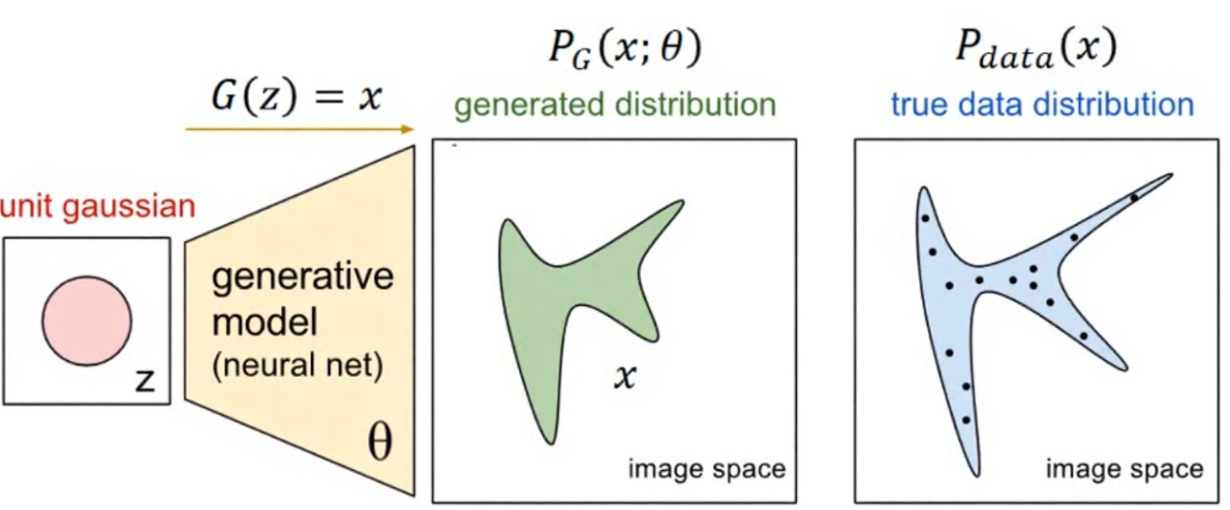
二、 数学原理:极小化极大博弈(Minimax Game)
GANs的对抗过程可以用一个优美的数学公式来描述,即一个极小化极大博弈(Minimax Game)的目标函数 V(D, G):
minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_{z}(z)}[\log(1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
让我们来分解这个公式:
- x∼pdata(x)x \sim p_{\text{data}}(x)x∼pdata(x):表示样本 xxx 来自于真实数据分布。
- z∼pz(z)z \sim p_{z}(z)z∼pz(z):表示噪声向量 zzz 来自于一个先验的噪声分布(如高斯分布)。
- G(z)G(z)G(z):生成器网络,输入噪声 zzz 并输出一个生成样本。
- D(x)D(x)D(x):判别器网络,输入一个样本 xxx 并输出其为真实样本的概率(一个0到1之间的标量)。
对于判别器D:
它的目标是最大化 V(D, G)。
- Ex∼pdata(x)[logD(x)]\mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)]Ex∼pdata(x)[logD(x)]:当输入是真实数据 xxx 时,D希望 D(x)D(x)D(x) 尽可能接近1,这样 logD(x)\log D(x)logD(x) 就最大化了。
- Ez∼pz(z)[log(1−D(G(z)))]\mathbb{E}_{z \sim p_{z}(z)}[\log(1 - D(G(z)))]Ez∼pz(z)[log(1−D(G(z)))]:当输入是生成数据 G(z)G(z)G(z) 时,D希望 D(G(z))D(G(z))D(G(z)) 尽可能接近0,这样 1−D(G(z))1 - D(G(z))1−D(G(z)) 接近1,log(1−D(G(z)))\log(1 - D(G(z)))log(1−D(G(z))) 也随之最大化。
对于生成器G:
它的目标是最小化 V(D, G)。
- 生成器G无法影响第一项 Ex∼pdata(x)[logD(x)]\mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)]Ex∼pdata(x)[logD(x)],因为它不涉及G。
- G的目标是让第二项 Ez∼pz(z)[log(1−D(G(z)))]\mathbb{E}_{z \sim p_{z}(z)}[\log(1 - D(G(z)))]Ez∼pz(z)[log(1−D(G(z)))] 变小。它通过生成更逼真的样本 G(z)G(z)G(z) 来“欺骗”D,使得 D(G(z))D(G(z))D(G(z)) 尽可能接近1。当 D(G(z))D(G(z))D(G(z)) 趋近于1时,log(1−D(G(z)))\log(1 - D(G(z)))log(1−D(G(z))) 趋近于负无穷,从而使整个表达式最小化。
这个公式完美地体现了两者之间的对抗关系:D试图最大化其辨别能力,而G试图最小化D的辨别能力(即最大化D的错误率)。
三、 核心架构与代码实现
在实践中,生成器和判别器通常由深度神经网络构成,尤其在图像任务中,会使用卷积神经网络(CNNs)。
3.1 判别器(Discriminator)
判别器是一个典型的二元分类CNN。它接收一张图像作为输入,通过一系列卷积层、激活函数(通常是LeakyReLU以防止梯度消失)和池化层来提取特征,最终输出一个介于0和1之间的概率值,表示输入图像为“真实”的概率。
PyTorch 代码实现示例 (Discriminator):
import torch.nn as nnclass Discriminator(nn.Module):def __init__(self, img_channels, features_d):super(Discriminator, self).__init__()# 输入: N x img_channels x 64 x 64self.net = nn.Sequential(nn.Conv2d(img_channels, features_d, kernel_size=4, stride=2, padding=1), # 32x32nn.LeakyReLU(0.2),self._block(features_d, features_d * 2, 4, 2, 1), # 16x16self._block(features_d * 2, features_d * 4, 4, 2, 1), # 8x8self._block(features_d * 4, features_d * 8, 4, 2, 1), # 4x4# 最终输出一个概率值nn.Conv2d(features_d * 8, 1, kernel_size=4, stride=2, padding=0), # 1x1nn.Sigmoid(),)def _block(self, in_channels, out_channels, kernel_size, stride, padding):return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),nn.BatchNorm2d(out_channels),nn.LeakyReLU(0.2),)def forward(self, x):return self.net(x)
3.2 生成器(Generator)
生成器则执行相反的操作。它接收一个低维的随机噪声向量(latent vector),通过一系列转置卷积(Transposed Convolution)层进行上采样,逐步将噪声向量“解码”成一张高维度的图像。激活函数通常在隐藏层使用ReLU,在输出层使用Tanh(将像素值归一化到-1到1之间)。
PyTorch 代码实现示例 (Generator):
import torch.nn as nnclass Generator(nn.Module):def __init__(self, z_dim, img_channels, features_g):super(Generator, self).__init__()# 输入: N x z_dim x 1 x 1self.net = nn.Sequential(self._block(z_dim, features_g * 16, 4, 1, 0), # N x f_g*16 x 4 x 4self._block(features_g * 16, features_g * 8, 4, 2, 1), # 8x8self._block(features_g * 8, features_g * 4, 4, 2, 1), # 16x16self._block(features_g * 4, features_g * 2, 4, 2, 1), # 32x32# 最后的输出层nn.ConvTranspose2d(features_g * 2, img_channels, kernel_size=4, stride=2, padding=1),nn.Tanh(), # 将输出规范到 [-1, 1])def _block(self, in_channels, out_channels, kernel_size, stride, padding):return nn.Sequential(nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),)def forward(self, x):return self.net(x)
四、 GANs训练中的挑战与不稳定因素
尽管GANs的理论很优雅,但其训练过程却异常困难,常常面临以下问题:
-
模式崩溃(Mode Collapse):这是GANs最常见的问题之一。生成器可能发现只生成少数几种能够轻易欺骗判别器的样本就足够了,从而停止探索数据的其他模式。例如,在训练一个生成人脸的GAN时,模式崩溃可能导致生成器只会生成同一张或少数几张面孔,完全丧失了多样性。
-
梯度极高的置信度拒绝所有生成样本。这会导致判别器返回给生成器的梯度信号非常微弱(接近于0),使得生成器无法从中学到任何有用的信息来改进自己。
-
训练不收敛(Non-convergence):由于模型由两个独立更新的网络组成,它们之间的对抗动态可能导致参数振荡而不收敛。生成器和判别器可能在“猫鼠游戏”中不断循环,无法达到稳定的平衡点。
-
评估困难:如何客观地评价一个GAN的好坏?我们无法像监督学习那样使用准确率等指标。通常需要依赖主观的人类评估,或者使用一些代理指标,如Inception Score (IS)和Fréchet Inception Distance (FID),来衡量生成样本的质量和多样性。
五、 GANs的重要变体:演进与革新
为了解决上述挑战并扩展GANs的能力,研究人员提出了大量的变体模型。
-
DCGAN (Deep Convolutional GAN):第一个将卷积神经网络成功应用于GANs并提出了一套稳定训练的架构准则(如使用BatchNorm、LeakyReLU、用转置卷积上采样等),成为了后续许多研究的基石。
-
CGAN (Conditional GAN):通过向生成器和判别器同时提供一个额外的条件信息
y(如类别标签),使得GANs可以生成特定类别的数据。例如,我们可以指定模型生成一只“猫”或一辆“汽车”,极大地增强了GANs的可控性。 -
WGAN (Wasserstein GAN):通过引入Wasserstein距离作为损失函数,从理论上缓解了梯度消失问题,使得训练过程更加稳定。其核心思想是将判别器改造为一个“评论家”(Critic),输出一个实数评分而非概率,并通过梯度惩罚(WGAN-GP)等技术来保证模型的稳定。
-
StyleGAN系列:由NVIDIA提出的StyleGAN、StyleGAN2和StyleGAN3是目前图像生成领域的巅峰之作,能够生成极其逼真和高分辨率的人脸图像。其创新点在于引入了全新的生成器结构,将输入噪声映射到一个中间的潜在空间W,并通过自适应实例归一化(AdaIN)在不同尺度上控制图像的“风格”,实现了对生成图像特征(如发型、年龄、表情)前所未有的精细控制。
-
CycleGAN:解决了“非成对图像翻译”问题。例如,在没有成对的“马”和“斑马”照片的情况下,学习将马的图像转换成斑马的图像。它通过引入“循环一致性损失”(Cycle Consistency Loss)——将马变成斑马再变回马,应该与原始图像一致——来实现这一神奇效果。
六、 GANs的广泛应用
GANs的强大生成能力使其在各个领域都展现出巨大的应用潜力。
-
图像生成与艺术创作:
- 超高分辨率图像生成:生成不存在但高度逼真的人物、风景、物体图像。
- 艺术风格迁移:将一张照片的内容与一幅名画的风格相结合。
- AI艺术创作:生成全新的艺术作品,甚至在艺术品拍卖会上售出。
-
图像编辑与修复:
- 图像超分辨率:将低分辨率图像提升为高分辨率图像(如SRGAN)。
- 图像修复(Inpainting):智能地填充图像中缺失或损坏的部分。
- 人脸编辑:改变人脸的年龄、表情、发色等属性。
-
数据增强(Data Augmentation):
- 在数据稀疏的领域(如医疗影像分析),利用GANs生成大量合成数据来扩充训练集,从而提升下游分类或分割模型的性能。
-
跨领域转换:
- 图像到图像翻译:如将卫星图转换为地图、将草图转换为照片(pix2pix)。
- 文本到图像生成:根据一段文字描述生成对应的图像(如DALL-E、Stable Diffusion等模型的后端也借鉴了GAN的思想)。
-
时尚、娱乐与设计:
- 虚拟试衣:生成模特穿上不同服装的效果图。
- 游戏与电影制作:快速生成高质量的游戏场景、角色纹理等视觉资产。
- 工业设计:辅助生成新的产品设计原型。
七、 总结与展望
生成对抗网络(GANs)无疑是深度学习发展史上的一项重大突破。它通过一种优雅而强大的对抗性学习框架,赋予了机器前所未有的“创造力”。尽管其训练仍然充满挑战,但随着WGAN、StyleGAN等先进模型的不断涌现,GANs的稳定性和生成质量已经达到了令人惊叹的高度。
未来,我们有理由相信,随着理论和技术的进一步完善,GANs将在科学研究、内容创作、数据模拟等更多领域扮演关键角色。然而,与此同时,我们也必须正视其潜在的伦理风险,如“深度伪造”(Deepfakes)技术的滥用,并积极探索相应的监管与检测技术,确保这一强大的工具能够向着造福社会的方向发展。