【AI4S】DrugChat:迈向在药物分子图上实现类似ChatGPT的功能
DrugChat:迈向在药物分子图上实现类似ChatGPT的功能
- 引言
- 方法
- 图神经网络(GNN)
- 大型语言模型(LLM)
- 自适应器:连接的桥梁(对齐图文生成)
- 结果
- 实验
- 药物说明调优数据
- ChEMBL药物指令调优数据集
- PubChem药物说明调优数据集
- 创新点
- 计算化学前沿研究的需求
- 创新方法:LLM 与 GNN 的结合
- 讨论: DrugChat 潜力与挑战
一种类似ChatGPT的药物化合物系统,有望彻底改变制药研究领域——它不仅能加速药物发现进程,还能深化我们对构效关系的理解,指导先导化合物优化,助力药物再利用,降低研发失败率,并简化临床试验流程。在本工作中,我们首次尝试将类似ChatGPT的功能应用于药物分子图谱,开发出原型系统
DrugChat。DrugChat的工作方式与ChatGPT如出一辙:
用户上传化合物分子图,并针对该化合物提出各种问题;DrugChat则以多轮互动的方式逐一解答。
整个DrugChat系统由图神经网络(GNN)、大型语言模型(LLM)及一个适配器组成。其中,
GNN接收化合物分子图作为输入,学习并生成该图的特征表示;适配器则负责将GNN输出的图表示进一步转换为LLM能够理解的另一种形式;最后,LLM结合经适配器转换后的化合物表示,以及用户提出的相关问题,生成最终的答案。这些组件均采用
端到端的方式进行联合训练。为了训练DrugChat,我们收集了包含10,834种药物化合物和143,517组问答对的指令微调数据集。

论文地址:https://arxiv.org/pdf/2309.03907
引言
药物发现与开发的过程耗时且成本高昂,通常需要数年时间和数十亿美元,才能将一种新药推向市场(Avorn,2015)。这一过程涉及对广阔化学空间的探索与理解,以及分子结构与其生物活性之间复杂关系的深入剖析,即所谓的构效关系(SAR)(Idakwo等,2020)。然而,传统方法(Rycker等,2018)往往依赖繁琐的反复试验,导致后期失败率居高不下。尽管近年来计算化学和化学信息学领域取得了一些进展(Zeng等,2022),为这一难题带来了一定缓解,但目前仍迫切需要能够直观理解并从药物化合物分子图谱中复杂数据里挖掘出有意义洞察的工具。
本技术报告介绍了将类似ChatGPT的功能应用于药物分子图的概念,旨在彻底改变我们与这些复杂实体互动和理解的方式。通过将这些分子图转化为适合AI分析的形式,我们能够实现对化学空间的动态探索、高效预测化合物特性,并为药物设计与优化提供智能化建议。一个能够理解药物分子图并解答有关这些药物各类问题的类似ChatGPT的AI系统,有望从多个方面革新制药研究领域:
- 加速药物发现进程。一种类似ChatGPT的人工智能系统,能够通过根据化合物的结构,迅速洞察其潜在的治疗用途、副作用及禁忌症,从而大幅缩短药物发现初期阶段所需的时间。
- 预测药物相互作用。这种类似ChatGPT的人工智能系统还能预测新候选药物与现有药物之间可能发生的相互作用。它通过比对数千种已知物质的分子结构,识别出潜在的冲突或协同效应,帮助研究人员更准确地预判新药在实际应用中的表现。
- 解析构效关系(SAR)。构效关系是药物设计中极为关键的一环(Idakwo et al., 2020)。借助这种类似ChatGPT的人工智能系统,研究人员能更深入理解药物的化学结构与其生物活性之间的关联,同时预测哪些化学结构的微调可能进一步提升药物疗效,或有效降低不良反应。
- 指导先导化合物优化。在药物发现过程中,经过初步筛选后具有潜力的“先导化合物”(Hughes et al., 2011)通常需要进行优化,以提高其疗效、降低毒性,并改善药代动力学特性。而这种类似ChatGPT的人工智能系统能够针对这些参数提出结构修饰建议,为研究人员指明方向,从而节省宝贵的研发时间。
- 助力药物重定位。此外,这种人工智能系统还可支持药物重定位研究(Pushpakom et al., 2019)。通过分析现有药物的结构特性,它能快速锁定那些可能对原本未被开发用于治疗的疾病同样有效的候选药物,为已有药物注入新活力,同时为应对棘手疾病提供更高效的治疗方案。
- 降低失败率。当前,药物研发的失败率居高不下(Hughes et al., 2011),其中很大一部分原因在于开发后期才暴露出的意外毒性和疗效问题。而通过在早期阶段就提供更为精准的药物特性与效果预测,这种类似ChatGPT的人工智能系统有望显著减少这些代价高昂的后期失败案例。
- 简化临床试验。类似于ChatGPT的人工智能可以通过预测药物与其他药物或疾病之间的相互作用来帮助设计更有效的临床试验,从而使研究人员能够更有针对性地进行试验并招募适合的患者群体。
开发一种类似ChatGPT的药物分子图系统极具挑战性。
- 首先,主要难题之一在于分子图的表示方式。与具有明确顺序和结构的文本数据不同,分子图本质上是非序列化的,且极其复杂,没有清晰的起点或终点。因此,如何将这些分子图转化为GPT模型能够处理的格式,是至关重要的技术突破点。
- 其次,另一个重大挑战是如何捕捉并理解药物化合物中复杂的构效关系(SAR)。这类关系往往并非显而易见,可能涉及分子各部分之间微妙而复杂的相互作用。
- 此外,要训练这样的系统,还需要海量的分子结构数据集,以及与之相关的生物活性、副作用和其他特性信息。然而,由于许多此类信息属于专有范畴,加之化学空间本身的巨大多样性,构建或整合如此大规模的数据集本身便是一项极为艰巨的任务。
在本技术报告中,我们首次尝试为药物分子图赋予类似ChatGPT的能力,开发出了一款名为DrugChat的原型系统。DrugChat的工作原理与ChatGPT类似:用户上传一个化合物分子图,并针对该化合物提出各种问题;DrugChat则会以多轮互动的方式,逐一解答这些问题。
DrugChat系统由一个图神经网络(GNN)(Hu等,2020)、一个大型语言模型(LLM)(Chiang等,2023)以及一个适配器组成。其中,GNN以化合物分子图为输入,学习该图的表示;适配器则将GNN生成的图表示转换为适合LLM处理的另一种表示形式;而LLM则以适配器转换后的化合物表示和用户针对该化合物提出的问题作为输入,生成最终的答案。这些组件均采用端到端的方式进行联合训练。为了训练DrugChat,我们收集了包含10,834种药物化合物及143,517组问答对的指令微调数据集。本文的主要贡献如下:
- 我们开发了DrugChat,这是一个原型系统,旨在实现类似ChatGPT在药物分子图上的功能。通过DrugChat,用户可以与系统互动,就药物化合物提出开放式问题,并获得详尽而富有信息的解答。
- 我们收集了包含10,834种药物化合物和143,517组问答对的指令微调数据集。这些数据集为训练适用于药物化合物的ChatGPT类模型提供了支持,并已公开发布。
- 据我们所知,DrugChat是首个将图数据与大规模语言模型(LLMs)相融合的系统,使用户能够围绕图结构展开互动式对话。我们的系统巧妙地将图神经网络与LLMs结合在一起,并且可轻松扩展,用于分析化合物分子图以外的其他类型图数据。
- 首先,DrugChat 系统在药物研发领域具有重要意义,比如加速药物发现。与 ChatGPT 类似,该系统能根据用户上传的化合物分子图进行多轮交互性回答,从而在早期阶段就能发现潜在有效的药物。
- 其次,该系统通过图神经网络(GNN)和大型语言模型(LLM)的结合,提升了我们对结构活性关系的理解。GNN 负责从化合物分子图中学习表示,然后通过适配器转换为 LLM 可以接受的形式,进一步生成答案。
- 此外,DrugChat 还能够辅助先导化合物优化,并助力药物再定位。通过对化合物的深入分析,该系统不仅能找到更有效的先导化合物,还能发现现有药物的新用途。
- 更值得一提的是,该系统有助于减少失败率和简化临床试验。作者收集了包含 10,834 种药物化合物和 143,517 个问题-答案对的数据集,并进行了端到端的训练,以确保系统的高准确性。
- 最后,所有这些组件都是端到端训练的,代码和数据已在 GitHub 上公开,这进一步提高了其应用的可行性和透明性。
总体而言,DrugChat 系统集多项功能于一身,具备强大的应用潜力,无疑将成为药物研发领域的一项革命性进展。
方法
图1提供了DrugChat的概览。它以化合物分子图为输入,允许用户针对该化合物提出多轮问题,并为每一个问题生成相应答案。DrugChat由一个图神经网络(GNN)、一个大型语言模型(LLM),以及连接GNN与LLM的适配器组成。其中,GNN负责学习化合物分子图的表示;而适配器(即一个线性变换矩阵)则将图表示转换为适合LLM使用的软提示向量。随后,LLM会结合用户问题和图提示向量,生成最终的答案。
在训练过程中,我们采用了来自(Hu et al., 2020)的预训练GNN,以及预训练的大型语言模型——Vicuna13b(Chiang et al., 2023)。值得注意的是,当训练DrugChat时,我们固定了GNN和LLM的权重参数,仅对适配器的权重进行更新。具体来说,给定指令调优数据中的某种药物及其相关问题后,首先将该药物的分子图送入GNN,生成对应的表示向量;接着,这一向量经由适配器转换为提示向量,再与用户问题一同输入LLM,从而得到最终答案。最后,系统会计算生成答案与真实答案之间的负对数似然损失,并通过最小化该损失来优化适配器的参数。接下来,我们将逐一介绍DrugChat中的各个组成部分。
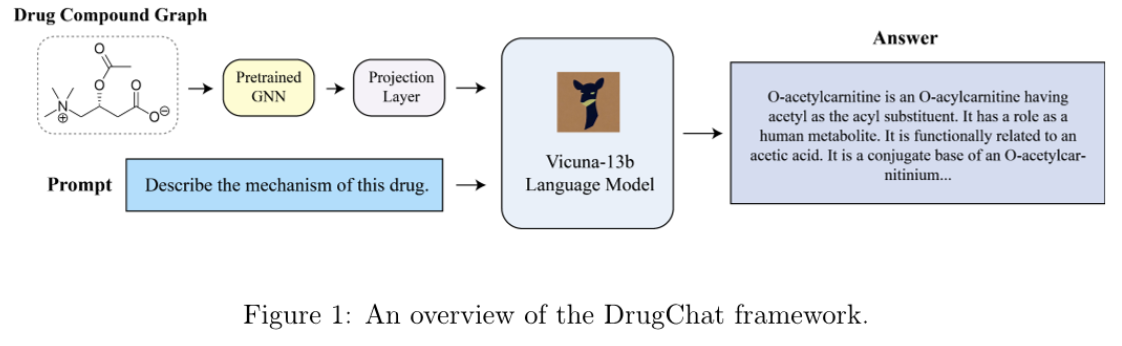
- 图神经网络(GNN)专门用于解析化合物分子图。
- 大型语言模型(LLM)负责生成用户问题的答案。
- 自适应器连接 GNN 和 LLM,并进行微调。
图神经网络(GNN)
GNN 是一种能够理解和分析化学结构的神经网络。它依据节点和边的特性,通过多层表示来更新每个节点,进而获取整个图的代表性向量。在这个过程中,GNN 使用了一系列数学函数和池化方法来整合所有节点的信息。换句话说,GNN 是解码化合物分子图的「大脑」。
图神经网络(GNN,Hu 等,2020)利用图结构和节点特征,为每个节点vvv学习多层表示向量,并为整个图GGG计算一个全局表示向量hGh_GhG。每节点的表示通过聚合其邻近节点的特征进行更新。在第kkk层,节点vvv的表示hvkh_v^khvk包含了来自vvv的kkk跳网络邻域内节点的信息。具体而言,hvkh_v^khvk的计算公式如下:
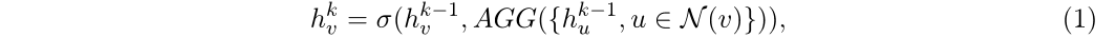
其中,AGGAGGAGG 表示一种聚合来自邻近节点信息的函数;σ\sigmaσ则是一种结合前一层节点特征与邻近节点信息的函数。N(v)N(v)N(v) 表示节点 vvv 的所有邻近节点。为了获取整个图 GGG 的表示向量,在第 KKK 层利用一个置换不变的池化函数 fff(例如取平均值),从所有节点特征中提取相关信息:
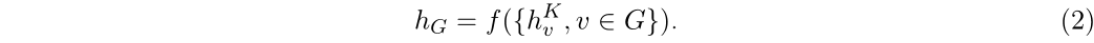
大型语言模型(LLM)
LLM 则是专门用于解析和回应用户问题的模型。通过 Transformer 架构和特定的概率计算,LLM 能够根据上下文生成准确的答案。在 DrugChat 中,作者使用了预训练的 Vicuna13b 模型,它能对化学分子和用户问题进行智能解读。
大型语言模型(LLMs)利用Transformer(Vaswani等,2017)的解码器来建模语言模型中第nnn个标记的条件概率pθ(ni∣n<i)p_{\theta}(n_i|n_{<i})pθ(ni∣n<i)。Transformer解码器首先对输入上下文标记应用一个多头自注意力机制块(Vaswani等,2017),随后通过一个位置全连接前馈网络计算输出标记的概率分布。给定标记的上下文向量后,token生成概率的计算公式如下:

其中,Ni−1=(n1,n2,...,ni−1)N_{i-1} = (n_1, n_2, ..., n_{i-1})Ni−1=(n1,n2,...,ni−1) 表示标记的上下文向量,mmm 指的是层数,WeW_eWe 表示token嵌入矩阵,WpW_pWp 则代表位置嵌入矩阵。
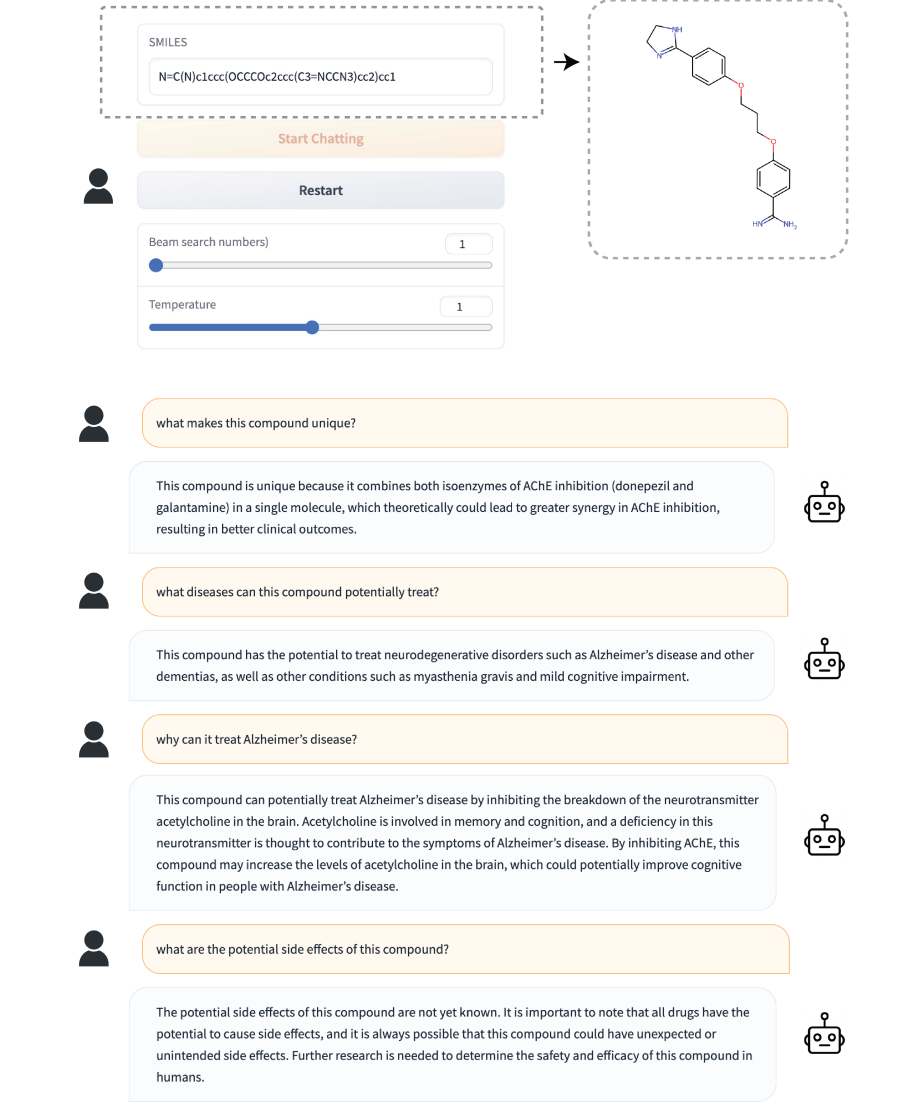
该图展示了 DrugChat 框架的实际应用示例:
自适应器:连接的桥梁(对齐图文生成)
自适应器的作用是将 GNN 生成的图表示向量转换成 LLM 可以理解的「软提示」向量。这个转换是通过一个线性变换矩阵来完成的。在训练 DrugChat 时,作者固定了 GNN 和 LLM 的权重参数,仅对自适应器进行了更新。
通过这三个组件的紧密协作,DrugChat 能够接收一个化合物分子图和用户的多轮问题,然后生成准确的答案。这不仅提高了化学分子结构解析的准确性,也极大地简化了用户与模型的交互过程。
总体来说,DrugChat 是一种高度集成和自适应的系统,能够将复杂的化学知识和自然语言处理技术无缝地结合在一起。
现阶段,我们为每一对训练图-文本数据生成一个prompt,使大语言模型能够根据药物化合物图生成描述。我们采用了一种遵循Vicuna-13b对话格式的提示模板:
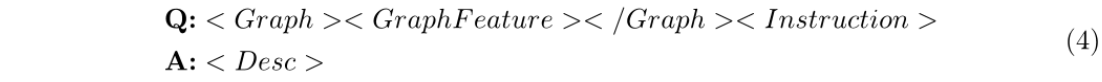
在这个提示中,<GraphFeature> 是一个软提示,用于表示由线性投影层编码的图结构特征。而<Instruction> 则是一条指令性语句,引导大模型生成关于该药物的描述,例如“描述这种药物的作用机制”。在训练阶段,<Desc> 会被填充来自人类专家的描述性文本,以训练线性投影层;而在测试阶段,<Desc> 保持为空,模型则需根据提供的药物结构自动生成相应的描述性文本。
结果
首先,DrugChat 框架是为了解决药物化合物的多元问题而设计的。该框架不仅能回答常规问题,还能进行复杂的多轮对话,如「这种化合物有何独特之处?」或「这种化合物可能治疗哪些疾病?」值得注意的是,这些问题并没有包含在训练数据中,显示了该模型的强大适应性。
其次,为了训练 DrugChat 模型,作者发展了 ChEMBL 药物数据集和 PubChem 药物数据集。这些专业数据集不仅提供了丰富的训练素材,还增强了模型的可靠性。
然而,DrugChat 的一个潜在局限性是语言生成的不准确性。由于集成了 LLM 模块,该框架有时可能生成不可信的药物描述,这会妨碍其在真实药物发现流程中的应用。如果 DrugChat 生成看似可信但实际不准确的文本描述,可能会误导人类决策者,导致不良后果。
最后,解决这一问题的未来发展方向包括使用更高质量的训练数据和实施有效的过滤策略。更先进的 GNN 编码器和 LLMs 也将在解决这一挑战中发挥关键作用。随着用户数量的增加,人类反馈也可以通过强化学习技术用于微调 DrugChat 模型(参考 Ouyang 等人,2022 年)。
通过以上信息,可以看出 DrugChat 框架虽有巨大潜力,但仍需进一步优化以应对挑战。
实验
药物说明调优数据
表1提供了数据集中药物数量和问题-答案对的数量。

ChEMBL药物指令调优数据集
在本节中,我们概述了构建ChEMBL药物指令微调数据集的过程。我们从ChEMBL网站获取了数据,该网站收录了共计2,354,965种化学化合物的信息。我们下载了截至2023年2月28日最新更新的SQLite格式数据转储文件。在整个数据集中,我们筛选出包含药物信息的14,816种化合物。随后,经过进一步过滤,剔除了描述性信息不足的药物,最终得到一个包含3,892种药物的数据集。
对于每种药物,我们首先收集了其SMILES字符串,用于表示分子结构。接着,我们获取了多种分子特征,包括完整的分子式,以及该化合物被归类为酸、碱或中性化合物的信息。此外,我们还收集了与药物相关的特定属性,例如作用机制和治疗用途。基于这些属性,我们手动设计了129,699组问答对。表2展示了ChEMBL药物指令微调数据集中一种示例药物的问答对。

PubChem药物说明调优数据集
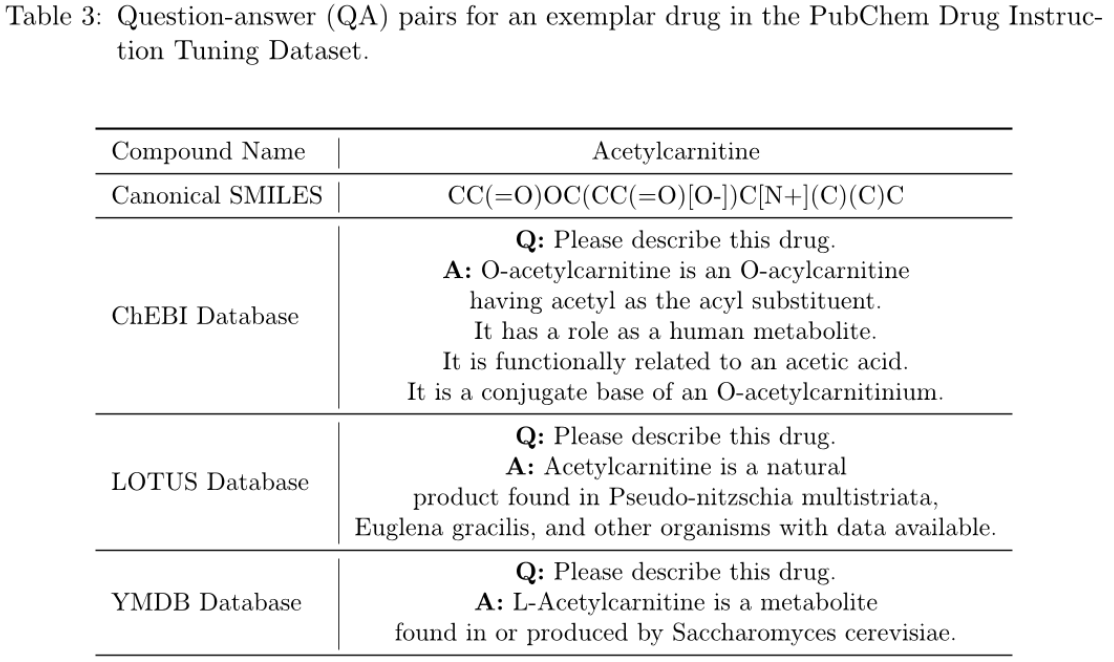
在本节中,我们概述了构建PubChem药物说明调优数据集的过程。数据来源于PubChem网站,该网站收录了66,469,244种化学化合物的信息。我们使用的是截至2023年5月9日最新更新的数据版本。在这批化合物中,有19,319种具备药物相关信息。经过筛选,剔除那些缺乏详细文本描述的药物后,最终保留了6,942种药物。
从ChEBI、LOTUS和YMDB等数据库中,为每种药物收集了其SMILES字符串和描述信息。最终,共获得了13,818条化合物描述摘要,并精心整理了13,818组问答(QA)对。表3中提供了PubChem中一种示例药物的QA对。
创新点
计算化学前沿研究的需求
近年来,计算化学和化学信息学(参见 Zeng 等人,2022 年)的突破性进展虽然带来了一些喘息之机,但仍然存在对能够直观理解和从药物分子图的复杂数据中产生有意义见解的工具的迫切需求。这种需求催生了 DrugChat 的诞生,其目标是将 ChatGPT 的强大处理能力应用到药物分子图谱上,以革命性地改变作者与这些复杂体系的交互和理解方式。
创新方法:LLM 与 GNN 的结合
作者的方法取自用户问题和图提示向量作为输入,并生成一个答案。具体来说,作者采用了预训练的图神经网络(GNN,参见 Hu 等人,2020 年)以及预训练的 LLM—Vicuna13b(参见 Chiang 等人,2023 年)。这种结合的力量在于它能够更准确、更直观地解读和生成有关药物分子图的信息。
讨论: DrugChat 潜力与挑战
- DrugChat 框架设计用于解析和描述药物分子。
- 语言幻觉是主要限制因素,可能导致不可靠的分析。
- 未来工作将聚焦于优化数据和算法,以提升模型质量。
首先,作者推出了 DrugChat 框架,其目的是通过解析药物的分子结构来生成详细的药物描述和回答相关问题。通过使用 ChEMBL 药物数据集和 PubChem 药物数据集进行训练,这一框架展示了在药物复合物的对话分析方面的巨大潜力。
然而,DrugChat 面临一个主要的局限性,即「语言幻觉」。因为模型内嵌了一个 LLM 模块,它偶尔会产生不可信的药物描述和答案。这种现象不仅影响其在实际药物发现流程中的应用,而且还有可能误导决策者,甚至可能导致不良后果。
针对这一问题,未来的工作将集中在使用更高质量的训练数据和有效的过滤策略上。更先进的 GNN 编码器和 LLM 将在解决这一挑战中起到关键作用。随着用户数量的增加,人类反馈也可以通过强化学习技术用于微调DrugChat 模型。
通过这些逐步的优化,未来有望将 DrugChat 框架推向一个更高的实用性水平。
Liang Y, Zhang R, Zhang L, et al. DrugChat: towards enabling ChatGPT-like capabilities on drug molecule graphs[J]. arXiv preprint arXiv:2309.03907, 2023.