Spark的Broadcast Join以及其它的Join策略
一、什么是Broadcast Join?
当有一张表较小时,我们通常选择 Broadcast Hash Join,这样可以避免 Shuffle 带来的开销,从而提高性能。比如事实表与维表进行JOIN时,由于维表的数据通常会很小,所以可以使用 BHJ 将维表进行 Broadcast。这样可以避免数据Shuffle(在 Spark 中 Shuffle 操作是很耗时的),从而提高 JOIN 的效率。
在进行Broadcast Join 之前,Spark 需要把处于 Executor 端的数据先发送到 Driver 端,然后Driver 端再把数据广播到 Executor 端。如果我们需要广播的数据比较多,会造成Driver 端出现OOM。具体如下图示:

一句话简单理解一下其原理:
- 小表广播:首先,Spark会将小表发送给driver,然后再广到集群中的每个工作节点。
- 大表分区:大表会被分区并分配到不同的工作节点。
- 本地Join操作:每个大表的工作节点接收到广播的小表后,都会在本地执行Join操作,这样大大减少了数据的网络传输。
条件与特点:
- 仅支持等值连接,join key 不需要排序
- 支持除了全外连接(full outer)之外的所有 join 类型
- 在 Driver 端缓存数据,所以当小表的数据量较大时,会出现 OOM 的情况
- 被广播的小表的数据量要小于 spark.sql.autoBroadcastJoinThreshold 值,默认是 10MB,但是被广播表的大小阈值不能超过 8GB,否则会报错。
- 基表不能被 broadcast,比如左连接时,只能将右表进行广播。
二、优化引擎如何判断需要走Broadcast Join?
在使用Hive SQL时,如果底层执行引擎是Spark,优化引擎会根据统计信息和查询计划来决定是否使用broadcast join。以下是优化引擎(特别是spark的catalyst优化器)判断是否使用broadcast join的一般步骤和考虑因素:
-
收集统计信息
为了进行优化,Hive会依赖表和列的统计信息,这些统计信息包括表的大小、行数、列的基数等,Hive通过以下几种方式收集统计信息:
ANALYZE TABLE语句:显示运行ANALYZE TABLE命令来收集表的统计信息
自动统计,某些i情况下适用 -
Hive逻辑计划的生成
Hive解析Hive SQL查询并生成初始的逻辑执行计划,这个执行计划包含了所有需要执行的操作步骤,但还没有进行任何优化。 -
基于规则的优化(RBO)
初始的逻辑计划会经过基于规则的优化,进行一些基本的转换和简化。例如,常见的优化包括:谓词下推、列裁剪等等。 -
基于代价的优化(CBO)
在代价优化阶段,hive的优化器会使用统计信息来评估不同执行计划的成本。
hive通过以下步骤来决定是否使用broadcast join:- 评估表的大小:优化器会检查连接操作中表的大小,如果表足够小,可以考虑将其广播到所有节点。
- 计算Join成本:优化器会比较不同Join策略的代价(广播、Shuffle Hash Join、Sort Merge Join)
- 选择最优策略:如果broadcast join的代价低于其他join策略并且满足内存限制,优化器会选择broadcast join
-
当使用spark作为执行引擎时,hive的逻辑计划会被转换成spark的物理计划,catalyst优化器将进一步优化执行计划,将小表标记为广播表。
三、还有哪些Join策略?
3.1 Shuffle Hash Join
首先,对于两张参与join的表,分别按照join key进行重分区,该过程会涉及shuffle,其目的是将相同Join Key的数据发送到同一个分区,方便分区内进行Join。
其次,对于每个Shuffle之后的分区,会将小表的分区数据构建成一个hash table,然后根据join key与大表的分区数据进行匹配。
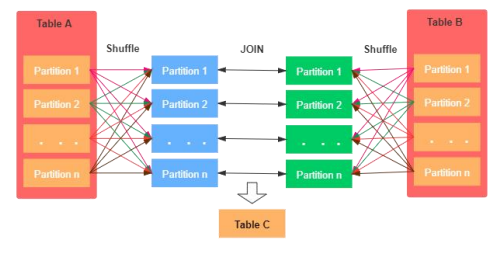
shuffle hash join主要包括两个阶段:
- Shuffle 阶段:两张大表根据Join Key进行Shuffle重分区
- merge 阶段:对来自不同表的分区进行Join,通过遍历元素,连接具有相同Join Key的值的行来合并数据集。
条件与特点:
- 仅支持等值连接,join key 不需要排序
- 支持所有的 join 类型(3.1.0之前不支持full outer join)
- 需要对小表构建 Hash table,属于内存密集型的操作,如果构建侧数据比较大,可能会造成 OOM
- 将参数 spark.sql.join.prefersortmergeJoin (default true)置为false
3.2 Sort Merge Join
Spark默认的Join方式,非常常见。
一般在两个大表进行Join时。使用该方式。Sort merge join可以减少集群中的数据传输,该方式不会先加载所有数据到内存,然后进行hash join,但是在join之前需要对join key进行排序:

Sort merge join主要包括三个阶段:
- shuffle 阶段:两张大表根据join key进行shuffle重分区
- sort 阶段:每个分区内的数据进行排序(原因就是,这种情况下的右表比较大,无法完全的放入到内存中(放不下的数据需要spill到磁盘中),所以进行排序)
- merge阶段:对来自不同表的排序好的分区进行join,通过遍历元素,连接具有相同的key值的行来合并数据集(因为是遍历的,所以不需要在内存中构建哈希表)
条件与特点:
- 仅支持等值连接
- 支持所有 join 类型
- Join Keys 是排序的
- 参数 spark.sql.join.prefersortmergeJoin (默认 true)设定为true
解释一下为什么不需要构建哈希表
因为两个序列都是有序的,从头遍历,碰到key相同的就输出;如果不同,左边小就继续取左边,反之取右边。可以看出,无论分区有多大,Sort Merge Join都不用把某一侧的数据全部加载到内存中,而是即用即取即丢,从而大大提升了大数据量下SQL Join的稳定性(如果使用广播或者Shuffle Hash Join,万一数据量膨胀,非常容易出现OOM问题,Sort Merge Join对内存的要求小很多,所以基本不会出现OOM问题,Join稳定性得到保证)。

3.3 Cartesian Join
在日志里看到这种join的时候,大概率是写出bug了。
因为这种join,类似于参与join的表没有指定join key,这个join得到的结果其实就是两张表的笛卡尔积。
条件:
- 仅支持内连接
- 支持等值和不等值连接
- 开启参数 spark.sql.crossJoin.enabled=true
3.4 Broadcast Nested Loop Join(BNLJ)
兜底策略。
该方式是在没有合适的 JOIN 机制可供选择时,最终会选择该种join 策略。优先级为:Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > cartesian Join >Broadcast Nested Loop Join
在 Cartesian 与 Broadcast Nested Loop Join 之间,如果是内连接,或者非等值连接,则优先选择 Cartesian Join 策略;当是非等值连接并且一张表可以被广播时,会选择Broadcast Nested Loop。
条件与特点:
- 支持等值和非等值连接
- 支持所有的 JOIN 类型,主要优化点如下:
- 当右外连接时要广播左表
- 当左外连接时要广播右表
- 当内连接时,要广播左右两张表
四、一些额外补充
4.1 Sort Merge Join VS Shuffle Hash Join

4.2 Sort Merge Join VS Broadcast Join
某些场景下,”广播”的任务,效率不一定高哦。
比如:
Join两边的数据大小都是1G,spark.sql.autoBroadcastJoinThreshold的值设置为2g,程序走了广播,这个时候广播的操作就会比较耗时,网络传输成本会非常高。
这种场景更加适合Sort merge Join。
4.3 在等值数据关联中,谁的效率最高呢?
在等值数据关联中,Spark 会尝试按照 BHJ > SMJ > SHJ 的顺序,依次选择 Join 策略。在这三种策略中,执行效率最高的是 BHJ,其次是 SHJ,再次是 SMJ。BHJ 尽管效率最高,但是有两个前提条件:
- 连接类型不能是全连接(Full Outer Join)
- 基表要足够小,可以放到广播变量里面去。
那为什么 SHJ 比 SMJ 执行效率高,排名却不如 SMJ 靠前呢?
这是个非常好的问题。我们先来说结论,相比 SHJ,Spark 优先选择 SMJ 的原因在于,SMJ 的实现方式更加稳定,更不容易 OOM。
回顾 HJ 的实现机制,在 Build 阶段,算法根据内表创建哈希表。在 Probe 阶段,为了让外表能够成功“探测”(Probe)到每一个 Hash Key,哈希表要全部放进内存才行。坦白说,这个前提还是蛮苛刻的,仅这一点要求就足以让 Spark 对其望而却步。 要知道,在不同的计算场景中,数据分布的多样性很难保证内表一定能全部放进内存。
而且在 Spark 中,SHJ 策略要想被选中必须要满足两个先决条件,这两个条件都是对数据尺寸的要求:
- 首先,外表大小至少是内表的 3 倍。
- 其次,内表数据分片的平均大小要小于广播变量阈值。
第一个条件的动机很好理解,只有当内外表的尺寸悬殊到一定程度时,HJ 的优势才会比 SMJ 更显著。第二个限制的目的是,确保内表的每一个数据分片都能全部放进内存。 和 SHJ 相比,SMJ 没有这么多的附加条件,无论是单表排序,还是两表做归并关联,都可以借助磁盘来完成,内存中放不下的数据,可以临时溢出到磁盘。单表排序的过程,我们可以参考 Shuffle Map 阶段生成中间文件的过程。在做归并关联的时候,算法可以把磁盘中的有序数据用合理的粒度,依次加载进内存完成计算。这个粒度可大可小,大到以数据分片为单位,小到逐条扫描。 正是考虑到这些因素,相比 SHJ,Spark SQL 会优先选择 SMJ。
事实上,在配置项 spark.sql.join.preferSortMergeJoin 默认为 True 的情况下,Spark SQL 会用 SMJ 策略来兜底,确保作业执行的稳定性,压根就不会打算去尝试 SHJ。开发者如果想通过配置项来调整 Join 策略,需要把这个参数改为 False,这样 Spark SQL 才有可能去尝试 SHJ。