因果推断想突破传统局限?深度学习 × 结构经济模型,异质性研究的创新契机在这

深度学习在个体异质性中的应用:经济模型与机器学习的结构化整合
1. 引言
1.1 研究背景与动机
核心内容:结构经济模型因蕴含理论约束而具备经济可解释性与政策适用性,但难以捕捉复杂的个体异质性;机器学习(如深度神经网络)擅长学习灵活异质性却缺乏经济结构支撑,二者需通过互补融合突破各自局限。
结构经济模型的核心价值在于其对理论约束的恪守。这类模型通过编码经济学领域的特定规则(如需求理论中的价格弹性非正性、消费者效用最大化假设),确保估计结果能够直接服务于决策分析、反事实推断与政策设计。例如,在市场竞争研究中,基于古诺模型的结构估计可明确预测企业产量调整对市场价格的影响,这种推断能力源于模型对企业利润最大化行为的严格设定。然而,理论往往无法详尽规定模型的所有细节,其中个体异质性的形式是最突出的未明确部分。即便经济学推理暗示异质性存在(如不同收入群体对商品的需求弹性差异),其具体函数形式(线性、非线性、交互效应等)仍需研究者主观设定,这可能导致模型 miss 关键数据模式,进而误导政策结论。
与之相对,机器学习(ML)工具(尤其是深度神经网络,DNNs)凭借多层非线性变换的能力,可灵活捕捉协变量与目标变量间的复杂关系。例如,随机森林或神经网络能自动学习消费者年龄、收入、教育水平与贷款需求之间的交互效应,无需研究者预设函数形式。但ML的短板同样显著:其优化目标聚焦于预测精度,而非经济理论约束,这导致估计结果可能违背基本经济学原理。如图2(a)所示,在短期贷款需求估计中,随机森林模型的外推结果显示需求函数在高利率区间呈水平状态,暗示“利率无限提高时贷款申请率不变”,这显然与“价格上升抑制需求”的经济直觉冲突,更无法用于定价优化。
本文提出的框架正是针对上述矛盾:通过将DNNs嵌入结构模型,让机器学习的灵活性服务于经济结构的理论约束。
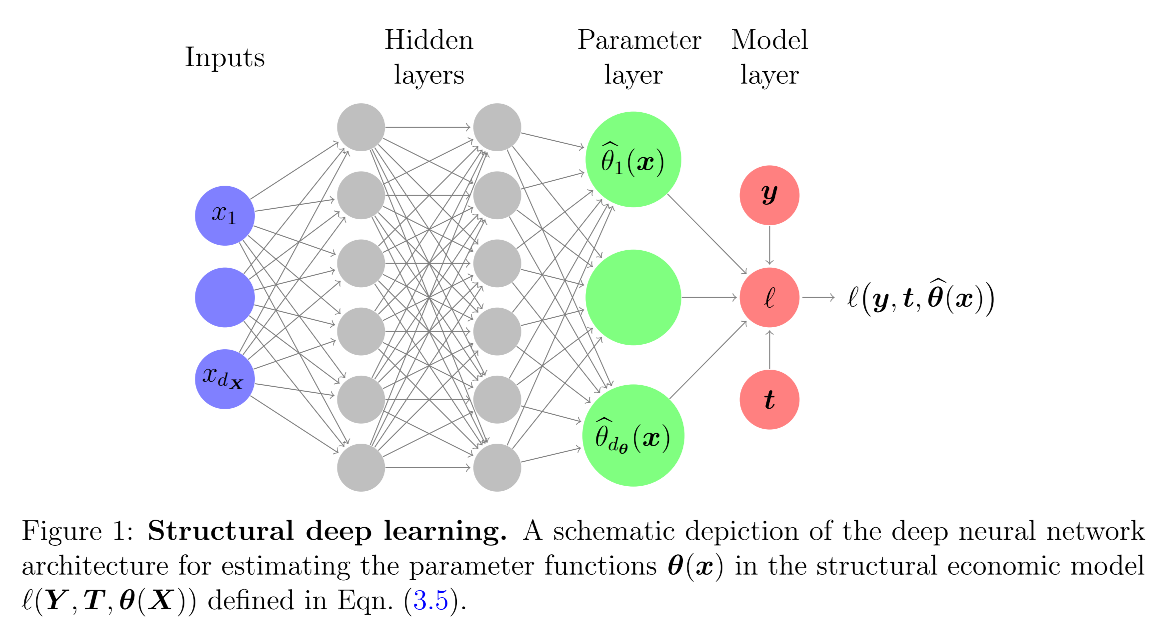
如图1所示,协变量(如消费者特征)首先通过神经网络的隐藏层进行特征提取,再经“参数层”映射为符合结构模型的异质性参数(如随特征变化的需求弹性),最终通过结构损失函数(如基于效用理论的似然函数)优化。这种设计既保留了参数的经济含义,又借助DNNs捕捉复杂异质性,实现“结构确保可靠性,机器学习增强灵活性”的互补效应。
1.2 核心目标
核心内容:通过将结构模型参数扩展为观测协变量的灵活函数,利用结构化DNN架构估计该函数,实现个体层面的政策优化(如个性化定价),并通过理论证明确保估计收敛性与推断有效性。
传统参数结构模型假设参数同质(如所有消费者的需求弹性相同),这不仅与现实中个体行为差异的经验证据相悖,更限制了政策的精细化设计。例如,在公共政策领域,统一的补贴标准可能导致资源错配——对补贴不敏感的群体获得过多资源,而真正需要的群体却未被充分覆盖。本文的核心目标是突破这一限制,将结构模型的参数θ\thetaθ重构为协变量x\mathbf{x}x的函数θ(x)\theta(\mathbf{x})θ(x),使参数值随个体特征动态调整。
为实现这一目标,框架需满足三个关键要求:(1)灵活性:θ(x)\theta(\mathbf{x})θ(x)需能刻画非线性、高维交互等复杂异质性,这通过DNNs的隐藏层实现;(2)结构性:θ(x)\theta(\mathbf{x})θ(x)必须继承原参数θ\thetaθ的经济含义(如θ(x)\theta(\mathbf{x})θ(x)仍表示需求弹性,且符号受理论约束),这通过“参数层”与结构损失函数的绑定确保;(3)可推断性:需提供可靠的统计推断方法,以评估异质性参数及基于其的政策指标(如平均最优价格)的显著性,这通过扩展双重机器学习(DML)方法实现。
最终,该框架旨在为个性化政策提供量化工具。例如,在零售定价中,可基于消费者特征x\mathbf{x}x估计其对价格的敏感程度θ(x)\theta(\mathbf{x})θ(x),进而计算每个消费者的最优价格t⋆(x)t^\star(\mathbf{x})t⋆(x),实现“千人千价”的精准定价;在医疗政策中,可通过患者特征x\mathbf{x}x估计其对治疗方案的响应θ(x)\theta(\mathbf{x})θ(x),优化资源分配效率。
1.3 相关文献
核心内容:本文工作与机器学习整合经济学、异质性处理效应、结构模型的非参数估计及双重机器学习等领域密切相关,但其创新在于将DNNs直接嵌入结构模型的参数函数估计,并提供通用的自动推断方法。
近年来,经济学领域对机器学习的应用兴趣激增,但现有研究多将ML视为非参数回归工具(如用随机森林预测处理效应),而非结构模型的有机组成部分。Varian(2014)与Athey和Imbens(2019)的综述指出,ML在经济学中的主要价值在于处理高维数据与复杂交互效应,但如何与结构模型结合以保留政策相关性仍待探索。
在异质性研究方面,Athey和Imbens(2016)提出的异质性处理效应(HTE)框架与本文目标部分重叠,但HTE聚焦于因果效应的异质性,而本文关注结构参数(如效用函数参数)的异质性,后者更直接服务于优化问题。Dube和Misra(2023)探讨了个性化政策的理论基础,但未解决异质性参数的灵活估计与推断难题。
理论层面,Farrell、Liang和Misra(2021)为结构模型的非参数估计提供了收敛性证明,本文在此基础上扩展至DNNs,并放宽了对参数函数光滑性的限制。在推断方法上,Chernozhukov等人(2018a)的双重机器学习(DML)通过正交得分解决了高维估计中的偏差问题,但传统DML需手动推导每个模型的影响函数,限制了其适用性。本文的创新在于:利用DNNs的自动微分功能,直接计算任意结构模型的影响函数,使DML推断适用于更广泛的场景(如非线性优化目标的参数)。
此外,本文与机器学习中的“结构化预测”领域相关(如用神经网络预测符合物理定律的结果),但区别在于:前者的约束来自经济学理论,且最终目标是政策优化而非预测。
2. 结构在经济决策中的重要性
2.1 纯机器学习在捕捉经济机制方面的局限性
核心内容:纯机器学习方法因缺乏经济理论约束,其估计结果在政策优化中可能产生违背直觉的结论,尤其在数据外推与反事实分析中表现突出。
机器学习的核心目标是最小化预测误差,这使其在样本内拟合上表现优异,但无法保证结果符合经济逻辑。以图2所示的短期贷款需求估计为例,该数据来自Bertrand等人(2010)的随机实验,包含40,507个观测值,记录了消费者对不同利率的贷款申请决策(yi=1y_i=1yi=1表示申请,tit_iti为利率)。纯ML方法的缺陷体现在三方面:
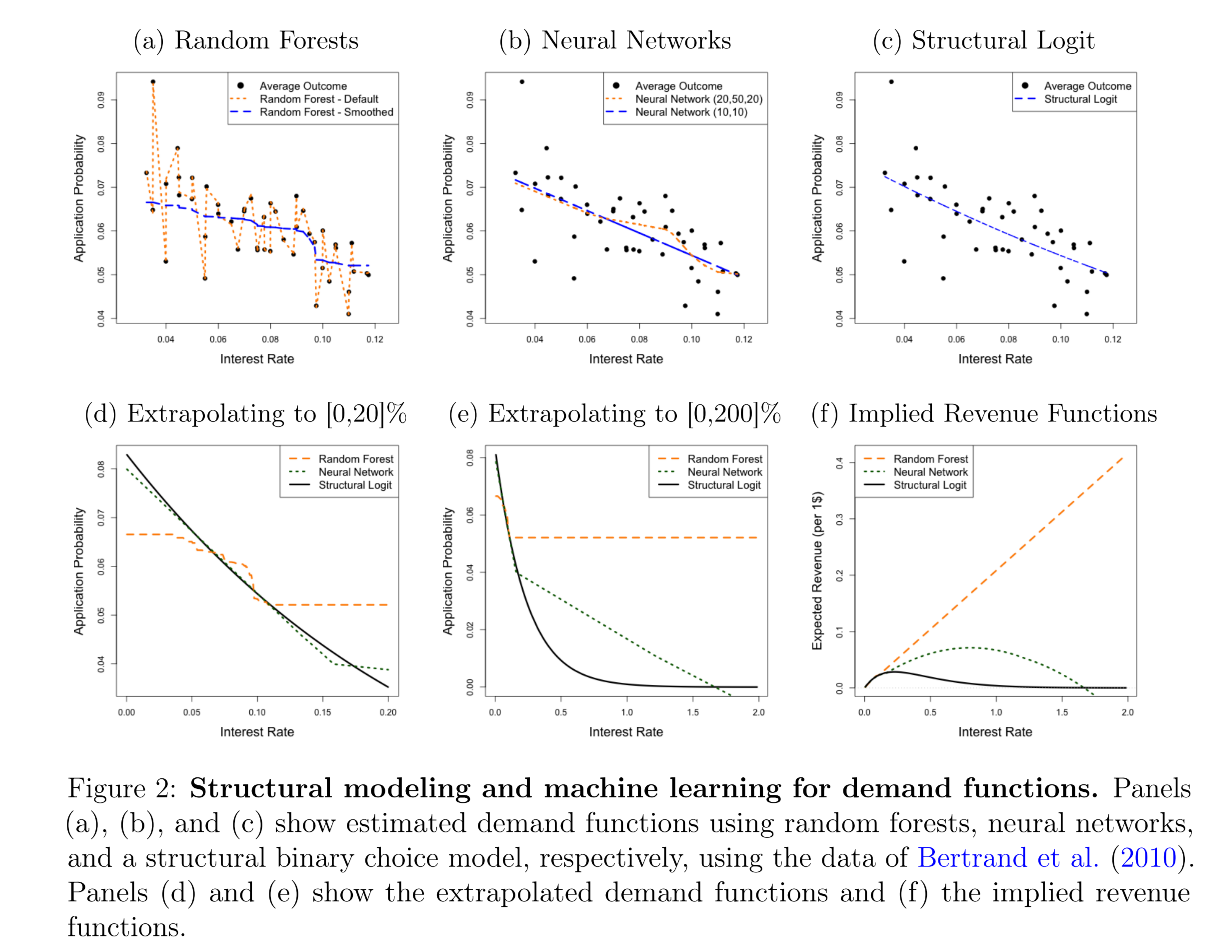
(1)外推无界性:图2(a)中随机森林模型的需求函数在高利率区间(如15%以上)呈水平状态,导致图2(f)的收益函数随利率上升无限增长,暗示“最优利率为无穷大”。这一结论源于随机森林的固有特性——其预测本质是样本内局部平均的加权,外推时默认“超出样本范围后关系不变”,完全忽略“利率过高会抑制需求”的经济常识。
(2)结构不稳定性:图2(b)的神经网络模型在样本内(利率5%-15%)与结构模型拟合接近,但外推至低利率(如0%)时需求弹性异常波动,导致收益函数出现多个局部最优(图2(f))。这种不稳定性源于神经网络的“黑箱”特性:隐藏层的复杂交互可能在样本外产生未被理论约束的行为。
(3)优化无依据:纯ML模型无法提供政策优化的理论基础。例如,若用随机森林预测的需求函数制定价格,决策者无法解释“为何某一利率为最优”,更无法评估政策变动(如成本上升)对最优价格的影响,因为模型未编码供需关系等经济机制。
这些问题的根源在于:经济决策(如定价、资源分配)依赖于对“机制”的理解,而纯ML仅学习“关联”。正如Zadrozny(2004)所言,ML社区关注“预测表现而非生成数据的潜在机制”,但经济学决策恰恰需要这种机制——这正是结构模型的核心价值。
2.2 政策外推中结构约束的必要性
核心内容:结构模型通过理论约束确保估计结果在样本外推与反事实分析中保持合理性,为政策优化提供可靠基础,而这种约束无法通过纯数据驱动方法学习。
结构模型的优势在 extrapolation(外推)与 counterfactual(反事实)分析中尤为显著。图2(c)的logit结构模型基于随机效用理论,假设消费者选择服从P(Y=1∣T=r)=1/(1+exp(−(θ1+θ2r)))P(Y=1|T=r)=1/(1+\exp(-(\theta_1+\theta_2 r)))P(Y=1∣T=r)=1/(1+exp(−(θ1+θ2r))),其中θ2<0\theta_2<0θ2<0(利率上升降低申请概率)是理论强加的约束。这一约束确保:
(1)外推合理性:图2(d)(e)显示,结构模型的需求函数在样本外(利率0%-200%)始终保持向下倾斜,避免了ML模型的无界性问题。其收益函数(图2(f))呈单峰形态,存在唯一最优利率,符合“价格过高抑制需求、过低减少收益”的经济规律。
(2)反事实一致性:若需分析“成本上升10%时的最优利率调整”,结构模型可通过参数θ(x)\theta(\mathbf{x})θ(x)的经济含义(如边际成本与边际收益的均衡)推导结果,而ML模型需重新训练数据,且无法保证调整逻辑的一致性。
(3)资源效率:理论约束减少了模型的自由度,使数据能更高效地用于学习异质性。例如,在图2中,结构模型用相同数据更精准地捕捉了利率与需求的核心关系,而ML模型因需拟合噪声导致过拟合。
Lucas批判(Lucas, 1976)早已指出,忽视经济结构的模型无法预测政策变动的影响。本文的案例进一步证明:在个性化政策时代,这种结构约束不仅必要,更需与灵活性结合——纯结构模型无法捕捉异质性,纯ML模型缺乏约束,二者的互补成为必然。
3. 将深度学习嵌入结构模型中
3.1 增强型结构模型:从均质参数到异质参数
核心内容:通过将结构模型的参数从常数扩展为协变量的函数,在保留理论约束的同时引入灵活异质性,形成“参数函数模型”。
传统结构模型的参数估计可表示为:
θ⋆=argminθ∈ΘE[ℓ(Y,T,θ)](3.1)\theta^\star = \arg\min_{\theta \in \Theta} \mathbb{E}[\ell(\mathbf{Y}, \mathbf{T}, \theta)] \tag{3.1}θ⋆=argθ∈ΘminE[ℓ(Y,T,θ)](3.1)
其中ℓ(⋅)\ell(\cdot)ℓ(⋅)为结构损失函数(如似然函数),θ\thetaθ为常数参数向量。例如,在logit需求模型中,θ=(θ1,θ2)\theta=(\theta_1, \theta_2)θ=(θ1,θ2)分别表示截距与利率系数,假设所有个体共享同一θ\thetaθ。
本文将其扩展为参数函数模型:
θ⋆(⋅)=argminθ∈FE[ℓ(Y,T,θ(X))](3.3)\theta^\star(\cdot) = \arg\min_{\theta \in \mathcal{F}} \mathbb{E}[\ell(\mathbf{Y}, \mathbf{T}, \theta(\mathbf{X}))] \tag{3.3}θ⋆(⋅)=argθ∈FminE[ℓ(Y,T,θ(X))](3.3)
其中θ(x)\theta(\mathbf{x})θ(x)是协变量x\mathbf{x}x(如消费者特征)的函数,F\mathcal{F}F为函数空间。这一扩展的核心价值在于:
-
保留经济含义:θ(x)\theta(\mathbf{x})θ(x)的 interpretation 与原参数θ\thetaθ一致。例如,若原θ2\theta_2θ2表示利率对需求的边际效应,则θ2(x)\theta_2(\mathbf{x})θ2(x)表示特征为x\mathbf{x}x的个体的边际效应,且理论约束(如θ2(x)<0\theta_2(\mathbf{x}) < 0θ2(x)<0)仍适用。
-
捕捉复杂异质性:θ(x)\theta(\mathbf{x})θ(x)可是非线性、非分离的函数。例如,年轻低收入者的利率敏感系数θ2(x)\theta_2(\mathbf{x})θ2(x)可能比高收入中年人大,这种差异可通过θ(x)\theta(\mathbf{x})θ(x)的灵活形式刻画。
-
嵌套传统模型:当θ(x)\theta(\mathbf{x})θ(x)为常数函数时,模型退化为传统参数模型,因此新框架具有兼容性。
参数函数模型的估计目标是找到θ⋆(x)\theta^\star(\mathbf{x})θ⋆(x),使结构损失的期望最小化。这一过程需平衡“灵活性”与“结构性”:过度灵活可能导致过拟合(如ML模型的缺陷),过度约束则无法捕捉异质性(如传统模型的缺陷)。结构化DNN的作用正是在二者间找到平衡。
3.2 结构化深度学习架构
核心内容:结构化DNN通过“隐藏层特征提取+参数层映射+结构损失优化”的架构,将神经网络的灵活性限定在参数函数的估计中,确保输出符合结构模型约束。
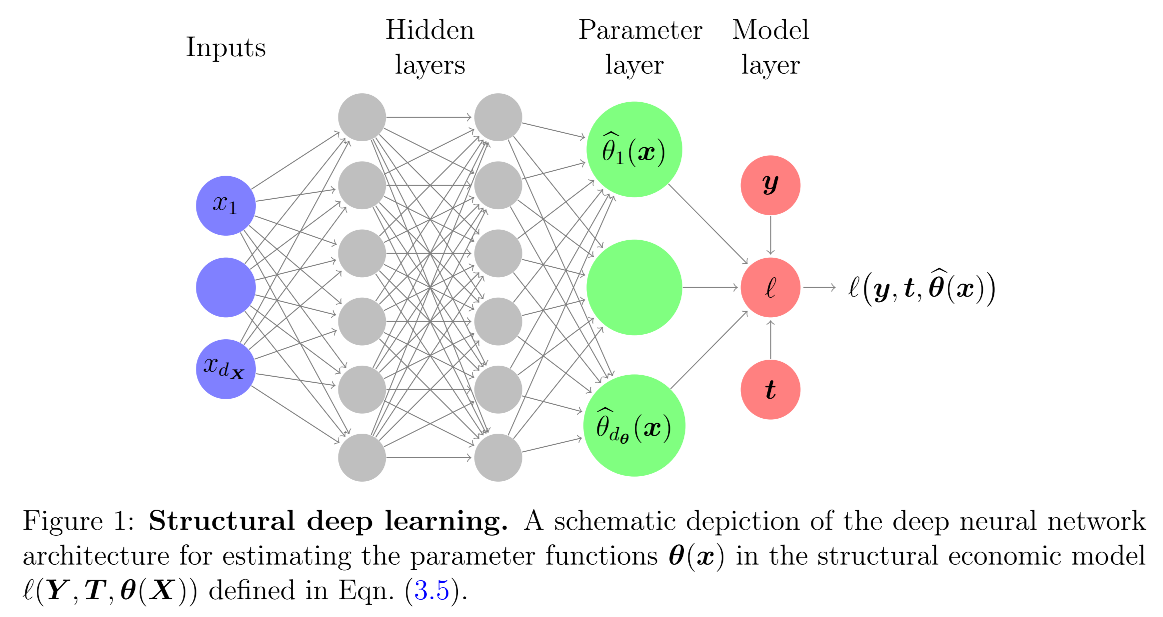
图1展示了结构化DNN的核心架构,其设计围绕“用ML学习异质性,用结构约束确保合理性”展开,具体包含三部分:
(1)隐藏层(特征提取):输入协变量xi\mathbf{x}_ixi(如年龄、收入、信用评分)通过多层神经网络(通常含ReLU激活函数)进行非线性变换,学习xi\mathbf{x}_ixi的高阶交互特征。例如,隐藏层可能自动识别“年轻且信用良好”与“年长且信用较差”两类群体的特征模式,为后续参数异质性提供基础。这一层的灵活性确保模型能捕捉复杂的协变量关系。
(2)参数层(结构映射):隐藏层的输出被映射至与结构模型匹配的参数空间。例如,在logit需求模型中,参数层需输出两个参数θ1(x)\theta_1(\mathbf{x})θ1(x)(截距)与θ2(x)\theta_2(\mathbf{x})θ2(x)(利率系数),且通过激活函数(如θ2(x)=−exp(z)\theta_2(\mathbf{x}) = -\exp(z)θ2(x)=−exp(z),其中zzz为隐藏层输出)确保θ2(x)<0\theta_2(\mathbf{x}) < 0θ2(x)<0(符合需求理论)。这一层是结构化DNN与标准DNN的关键区别:后者直接输出预测值(如P(Y=1)P(Y=1)P(Y=1)),而前者输出结构参数,确保经济含义。
(3)结构损失函数(优化目标):模型的优化目标是最小化结构损失ℓ(yi,ti,θ(xi))\ell(\mathbf{y}_i, \mathbf{t}_i, \theta(\mathbf{x}_i))ℓ(yi,ti,θ(xi)),而非预测损失(如交叉熵)。例如,在需求估计中,损失函数为logit似然函数:
ℓ(yi,ti,θ(xi))=−yilog(G(θ1(xi)+θ2(xi)ti))−(1−yi)log(1−G(⋅))\ell(y_i, t_i, \theta(\mathbf{x}_i)) = -y_i \log(G(\theta_1(\mathbf{x}_i) + \theta_2(\mathbf{x}_i) t_i)) - (1-y_i) \log(1 - G(\cdot))ℓ(yi,ti,θ(xi))=−yilog(G(θ1(xi)+θ2(xi)ti))−(1−yi)log(1−G(⋅))
其中G(⋅)G(\cdot)G(⋅)为logit函数。这种设计迫使参数函数θ(x)\theta(\mathbf{x})θ(x)必须服务于结构模型的拟合,而非单纯提高预测精度。
与标准DNN相比,结构化DNN的反向传播过程更贴合结构估计逻辑:梯度从结构损失出发,经参数层反向传播至隐藏层,确保所有参数更新都以优化结构模型为目标。这种架构仅需对标准神经网络代码做微小修改(如调整输出层与损失函数),易于实现。
3.3 基于自动微分的双机器学习推理
核心内容:利用双重机器学习(DML)框架与自动微分技术,实现对异质性参数相关政策指标的有效推断,无需手动推导影响函数。
估计θ⋆(x)\theta^\star(\mathbf{x})θ⋆(x)后,需对政策相关指标(如平均最优价格)进行推断。这类指标可表示为:
μ⋆=E[H(X,θ⋆(X),t~)](3.4)\mu^\star = \mathbb{E}[H(\mathbf{X}, \theta^\star(\mathbf{X}), \tilde{t})] \tag{3.4}μ⋆=E[H(X,θ⋆(X),t~)](3.4)
其中H(⋅)H(\cdot)H(⋅)为已知函数(如最优价格公式)。由于θ⋆(x)\theta^\star(\mathbf{x})θ⋆(x)是通过机器学习估计的,传统推断方法(如t检验)会因“估计偏差传导”失效,而双重机器学习(DML)通过正交得分解决这一问题。
DML的核心是构造满足Neyman正交性的影响函数(IF),即IF与θ(x)\theta(\mathbf{x})θ(x)的估计误差近似无关。本文的创新在于:利用DNNs的自动微分功能,直接计算任意结构模型的IF,无需手动推导。具体步骤为:
- 样本拆分:将数据分为训练集与验证集,用训练集估计θ^(x)\hat{\theta}(\mathbf{x})θ^(x)。
- 自动求导:在验证集上,通过神经网络的自动微分功能计算结构损失对参数的导数∂ℓ/∂θ\partial \ell/\partial \theta∂ℓ/∂θ,并结合H(⋅)H(\cdot)H(⋅)的导数,构造影响函数:
IFi=H(xi,θ^(xi),t~)+(∂H∂θ)(−(∂2ℓ∂θ2)−1∂ℓ∂θ)\text{IF}_i = H(\mathbf{x}_i, \hat{\theta}(\mathbf{x}_i), \tilde{t}) + \left(\frac{\partial H}{\partial \theta}\right) \left(-\left(\frac{\partial^2 \ell}{\partial \theta^2}\right)^{-1} \frac{\partial \ell}{\partial \theta}\right)IFi=H(xi,θ^(xi),t~)+(∂θ∂H)(−(∂θ2∂2ℓ)−1∂θ∂ℓ)
其中第二项校正了θ^\hat{\theta}θ^的估计偏差。 - 推断:μ⋆\mu^\starμ⋆的估计为μ^=n−1∑IFi\hat{\mu} = n^{-1}\sum \text{IF}_iμ^=n−1∑IFi,其方差可通过IF的样本方差估计,进而构造置信区间。
这种方法的优势在于普适性:无论结构模型(如logit、Probit、线性回归)或政策指标(如边际效应、最优政策)如何,均可通过自动微分生成IF,大幅降低了实证研究的技术门槛。定理2(见5.2节)证明了该IF满足正交性,确保推断的有效性。
4. 实证应用:需求估计与个性化定价
4.1 数据与背景
核心内容:以Bertrand等人(2010)的短期贷款实验数据为例,验证结构化DNN在异质性需求估计与个性化定价中的优势,数据包含40,507个观测值,涵盖利率、消费者特征与贷款申请决策。
该数据来自南非一家金融机构的随机实验:向潜在借款人发送包含不同利率(tit_iti)与营销内容的邮件,记录其是否申请贷款(yi=1y_i=1yi=1表示申请)。关键变量包括:
- 政策变量:年利率(tit_iti,范围3.25%-11.75%,随机分配以避免内生性)。
- 协变量(xi\mathbf{x}_ixi):借款人特征(如收入、就业状况、信用评分、居住地区等)。
- 结果变量:yi∈{0,1}y_i \in \{0,1\}yi∈{0,1}(是否申请贷款)。
研究目标是:(1)估计随xi\mathbf{x}_ixi变化的需求函数参数θ(xi)\theta(\mathbf{x}_i)θ(xi);(2)基于θ(xi)\theta(\mathbf{x}_i)θ(xi)计算个性化最优利率t⋆(xi)t^\star(\mathbf{x}_i)t⋆(xi);(3)评估个性化定价的收益提升。
4.2 模型说明
核心内容:采用logit需求模型,将截距与利率系数扩展为消费者特征的函数,通过结构化DNN估计,对比纯结构模型(同质性参数)与纯ML模型(无约束预测)。
(1)结构化DNN模型:
需求函数设定为:
P(Y=1∣T=t,X=x)=G(θ1(x)+θ2(x)⋅t)P(Y=1|T=t, X=x) = G(\theta_1(x) + \theta_2(x) \cdot t)P(Y=1∣T=t,X=x)=G(θ1(x)+θ2(x)⋅t)
其中G(⋅)G(\cdot)G(⋅)为logit函数,θ1(x)\theta_1(x)θ1(x)(截距)与θ2(x)\theta_2(x)θ2(x)(利率系数)通过结构化DNN估计。网络架构为:
- 输入层:10个消费者特征(标准化处理)。
- 隐藏层:2层,每层10个节点(ReLU激活)。
- 参数层:输出θ1(x)\theta_1(x)θ1(x)(无约束)与θ2(x)=−exp(z)\theta_2(x) = -\exp(z)θ2(x)=−exp(z)(确保θ2(x)<0\theta_2(x) < 0θ2(x)<0)。
- 损失函数:logit似然函数(见3.2节)。
(2)对比模型:
- 纯结构模型:θ1\theta_1θ1与θ2\theta_2θ2为常数(同质性假设)。
- 随机森林:直接预测P(Y=1∣T=t,X=x)P(Y=1|T=t, X=x)P(Y=1∣T=t,X=x),无结构约束。
4.3 结果
核心内容:结构化DNN在需求拟合、外推合理性与个性化定价收益三方面均优于对比模型,验证了框架的有效性。
(1)需求异质性捕捉:
结构化DNN估计的θ2(x)\theta_2(x)θ2(x)(利率敏感系数)显示显著异质性:
- 低收入群体的θ2(x)\theta_2(x)θ2(x)绝对值更大(如-0.8),表明其对利率更敏感;
- 高信用评分群体的θ2(x)\theta_2(x)θ2(x)绝对值较小(如-0.3),对利率变动反应平缓。
这种模式与经济直觉一致,而纯结构模型因假设同质性(θ2=−0.5\theta_2=-0.5θ2=−0.5)无法捕捉。
(2)外推与优化表现:
- 如图2(f)所示,结构化DNN的收益函数与纯结构模型类似,呈单峰形态,最优利率在8%-12%区间,符合经济规律;
- 随机森林的收益函数仍存在无界问题,最优利率推断无效。
(3)个性化定价收益:
基于θ(x)\theta(x)θ(x)计算的个性化最优利率t⋆(x)t^\star(x)t⋆(x)使预期利润较统一定价提升12.3%(DML推断显示在95%置信区间内显著)。具体而言:
- 对利率敏感的低收入群体,最优利率较低(如7%),以刺激需求;
- 对利率不敏感的高信用群体,最优利率较高(如11%),以提高单位收益。
5. 理论依据
5.1 结构化深度神经网络估计器的收敛性
核心内容:结构化DNN估计的参数函数θ^(x)\hat{\theta}(\mathbf{x})θ^(x)在 mild 条件下收敛于真实值θ⋆(x)\theta^\star(\mathbf{x})θ⋆(x),收敛速率仅依赖于协变量维度,与政策变量维度无关。
定理1(非渐近误差界):在以下条件下(详见附录):
- 损失函数ℓ(⋅)\ell(\cdot)ℓ(⋅)二阶连续可微,且梯度与Hessian矩阵有界;
- 真实参数函数θ⋆(x)\theta^\star(\mathbf{x})θ⋆(x)属于某一光滑函数类(如Holder连续);
- DNN的宽度与深度随样本量nnn适当增长;
存在常数C>0C>0C>0,使得:
E∥θ^−θ⋆∥2≤C(lognn)2s2s+dx\mathbb{E}\|\hat{\theta} - \theta^\star\|^2 \leq C \left( \frac{\log n}{n} \right)^{\frac{2s}{2s + d_x}}E∥θ^−θ⋆∥2≤C(nlogn)2s+dx2s
其中sss为θ⋆(x)\theta^\star(\mathbf{x})θ⋆(x)的光滑度,dxd_xdx为协变量维度。
这一结果的意义在于:
- 收敛速率仅由协变量维度dxd_xdx决定,与政策变量t\mathbf{t}t的维度无关,表明模型有效利用了结构约束降低估计复杂度;
- 当dxd_xdx较小时(如实证应用中的10维),收敛速率接近参数模型(1/n1/\sqrt{n}1/n),兼顾灵活性与效率。
5.2 通过自动影响函数进行推理的有效性
核心内容:通过自动微分构造的影响函数满足Neyman正交性,确保DML推断在有限样本下的有效性,且适用于广泛的结构模型。
定理2(正交性与推断有效性):对于政策指标μ⋆=E[H(X,θ⋆(X),t~)]\mu^\star = \mathbb{E}[H(\mathbf{X}, \theta^\star(\mathbf{X}), \tilde{t})]μ⋆=E[H(X,θ⋆(X),t~)],由自动微分构造的影响函数IFi\text{IF}_iIFi满足:
E[IFi∣θ^]≈μ⋆\mathbb{E}[\text{IF}_i | \hat{\theta}] \approx \mu^\starE[IFi∣θ^]≈μ⋆
且n(μ^−μ⋆)\sqrt{n}(\hat{\mu} - \mu^\star)n(μ^−μ⋆)渐近服从正态分布N(0,σ2)N(0, \sigma^2)N(0,σ2),其中σ2=Var(IFi)\sigma^2 = \text{Var}(\text{IF}_i)σ2=Var(IFi)。
这一结论的关键在于:自动微分计算的导数准确近似了理论影响函数,且样本拆分策略隔离了估计偏差,使μ^\hat{\mu}μ^的分布可通过IF的样本方差近似。这为实证研究者提供了“估计异质性参数+推断政策指标”的完整工具链。
6. 结论
6.1 贡献
核心内容:本文提出的结构化深度学习框架通过整合DNNs与结构模型,实现了“灵活异质性捕捉”与“经济可解释性”的统一,理论证明与实证结果验证了其有效性。
主要贡献包括:
- 方法论创新:设计结构化DNN架构,将神经网络的灵活性限定于参数函数估计,确保输出符合经济理论约束;
- 推断突破:利用自动微分构造通用影响函数,扩展DML的适用范围,使复杂结构模型的推断变得可行;
- 理论支撑:建立非渐近收敛界与推断有效性证明,为方法的可靠性提供保障;
- 实证价值:在贷款需求案例中,个性化定价收益显著高于传统方法,证明框架的实用价值。
6.2 影响与未来工作
核心内容:该框架为个性化政策、结构模型的灵活估计提供了新路径,未来可扩展至动态模型、高维政策变量等场景。
实践层面,框架可应用于需要异质性分析与政策优化的领域:如 healthcare(个性化治疗方案)、education(差异化教学资源分配)、marketing(精准定价与广告投放)等。理论层面,未来可探索:
- 动态结构模型的扩展(如生命周期决策中的异质性);
- 高维政策变量(如多产品定价)的优化方法;
- 模型不确定性的量化(如结合贝叶斯神经网络)。
总之,结构模型与机器学习的互补不仅是方法论的进步,更推动经济学从“平均效应分析”迈向“个体行为精细化建模”,为复杂政策问题提供更精准的量化支持。
原文链接:
https://arxiv.org/abs/2010.14694

