AI(学习笔记第九课) 使用langchain的MultiQueryRetriever和indexing
文章目录
- AI(学习笔记第九课) 使用langchain的MultiQueryRetriever和indexing
- 学习内容:
- 1.`MultiQueryRetriever`的基本概念
- 1.1 学习`embedding model url`
- 1.2 为什么引入`MultiQueryRetriever`
- 1.3 `MultiQueryRetriever`的代码
- 1.4 `MultiQueryRetriever`的代码执行结果
- 2.`Indexing`的基本概念
- 2.1 `indexing`的`langchain`说明
- 2.2 为什么要对`document`进行`indexing`
- 2.3 `vector store`的整体结构
- 2.4 对`vector store`中的文档`document`进行`indexing`的需求
- 2.5 `indexing API`提供四种模式
- 2.6 `indexing`的代码实现
- 2.6.1 下载并使用`elastic search`
- 2.6.2 实现代码
- 2.7 `indexing`的代码执行
AI(学习笔记第九课) 使用langchain的MultiQueryRetriever和indexing
- 为什么需要使用
MultiQueryRetriever - 如何使用
MultiQueryRetriever - 为什么要进行
indexing - 如何对
vector db进行indexing
学习内容:
MultiQueryRetriever的基本概念langchain中如何使用MultiQueryRetriever
1.MultiQueryRetriever的基本概念
1.1 学习embedding model url
- langchain的
MultiQueryRetriever - 整体的练习代码
- 练习文件papaer about agent
1.2 为什么引入MultiQueryRetriever
基于vector database的检索,会有一个问题,那就是当微调提示词的时候,结果会发生变化,根据AI的提示词工程(prompt engineer)会有很多变化,但是不断的调整提示词会很麻烦,有时候还没有思路。
MultiQueryRetriever自动化这个过程,进行提示词优化。
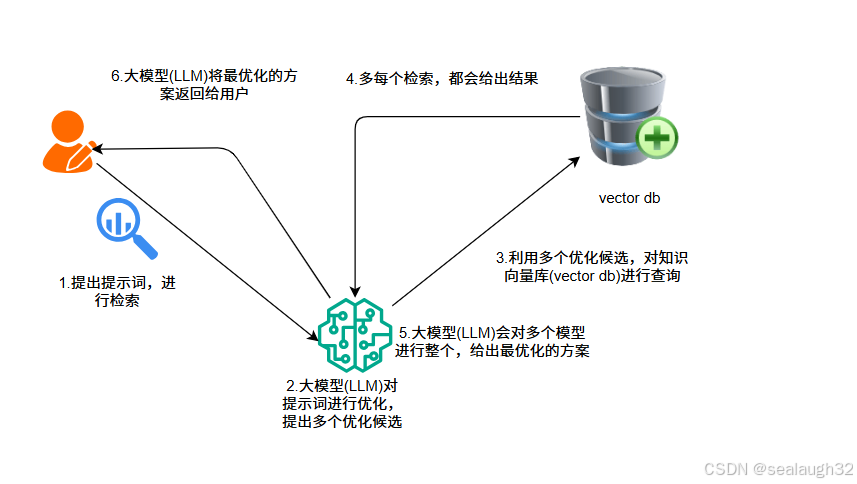
- 使用大模型
LLM,对检索提示词进行优化,产生多个提示词(query words)。 - 对每个检索词都进行对向量数据库进行检索
vector database。 - 综合每个检索结果,进行最优化。
1.3 MultiQueryRetriever的代码
# Build a sample vectorDB
from langchain.retrievers import MultiQueryRetriever
from langchain_openai import ChatOpenAI
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_ollama import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
import logging# 使用Ollama的嵌入模型
embeddings_model = OllamaEmbeddings(base_url='http://192.168.2.208:11434',model="nomic-embed-text")
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)# VectorDB
vectordb = Chroma.from_documents(documents=splits, embedding=embeddings_model)# 配置 DeepSeek API(deepseek 兼容 OpenAI)
llm = ChatOpenAI(api_key = 'sk-XXXXXX',base_url = 'https://api.deepseek.com/v1',model='deepseek-chat'# 或其他 DeepSeek 模型
)
question = "What are the approaches to Task Decomposition?"
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectordb.as_retriever(), llm=llm
)
logging.basicConfig()
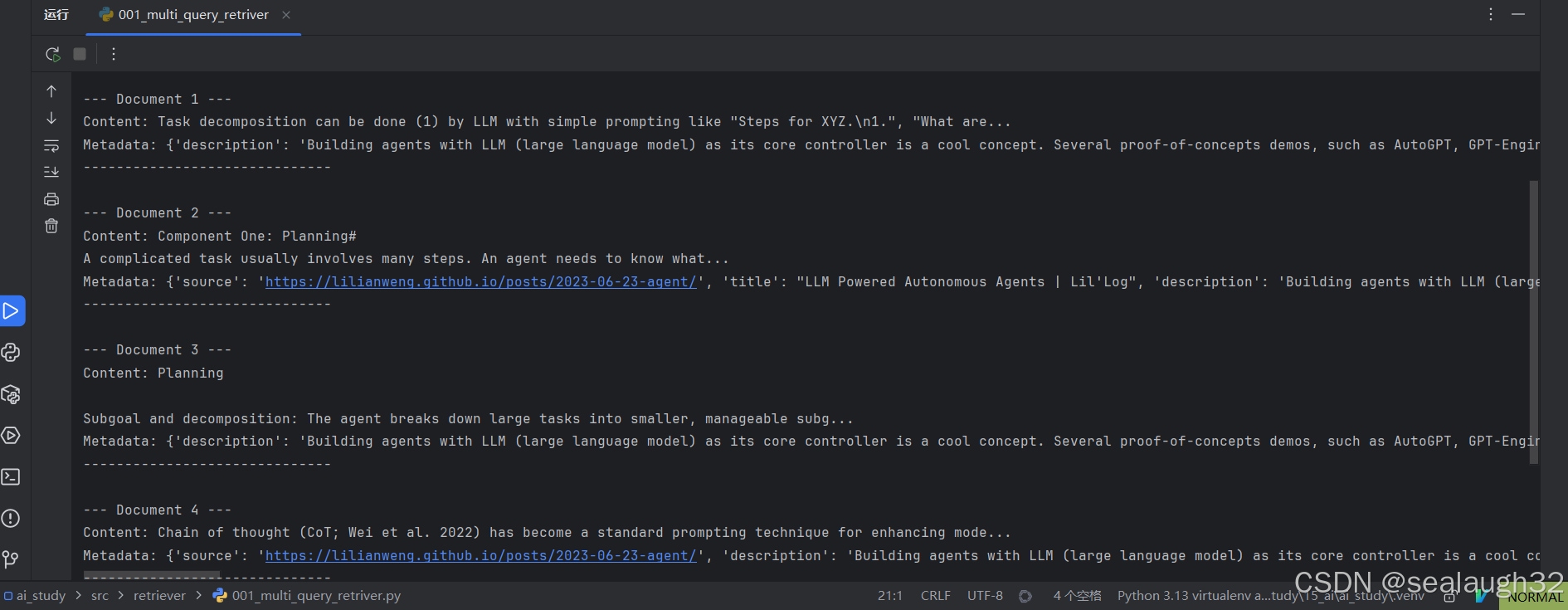
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)unique_docs = retriever_from_llm.invoke(question)
print(len(unique_docs))# 添加分隔符和详细打印
print("\n" + "="*50)
print("UNIQUE DOCUMENTS DETAILS:")
print("="*50)for i, doc in enumerate(unique_docs):print(f"\n--- Document {i+1} ---")print(f"Content: {doc.page_content[:100]}...") # 显示前100个字符if hasattr(doc, 'metadata') and doc.metadata:print(f"Metadata: {doc.metadata}")print("-" * 30)- 使用
https://lilianweng.github.io/posts/2023-06-23-agent这个内容,作为例子,构建vector db。 - 这里使用了
logging,将langchain.retrievers.multi_query,进行输出。INFO:langchain.retrievers.multi_query:Generated queries:['What are the main strategies for breaking down a complex task into smaller sub-tasks?', 'How can a large problem be decomposed into more manageable components?', 'What frameworks or methodologies exist for dividing work into smaller, actionable steps?'] - 提出的原始提示词是
What are the approaches to Task Decomposition?
可以看到LLM给补充了三个。What are the main strategies for breaking down a complex task into smaller sub-tasks?How can a large problem be decomposed into more manageable components?What frameworks or methodologies exist for dividing work into smaller, actionable steps?
1.4 MultiQueryRetriever的代码执行结果
2.Indexing的基本概念
2.1 indexing的langchain说明
How to use the LangChain indexing API
这里给出了如何对vector store的document进行indexing。
2.2 为什么要对document进行indexing
langchain的indexing API能帮助将document进行装载进vector store,能提供以下功能:
- 避免将重复的
document写入进vector store - 避免将
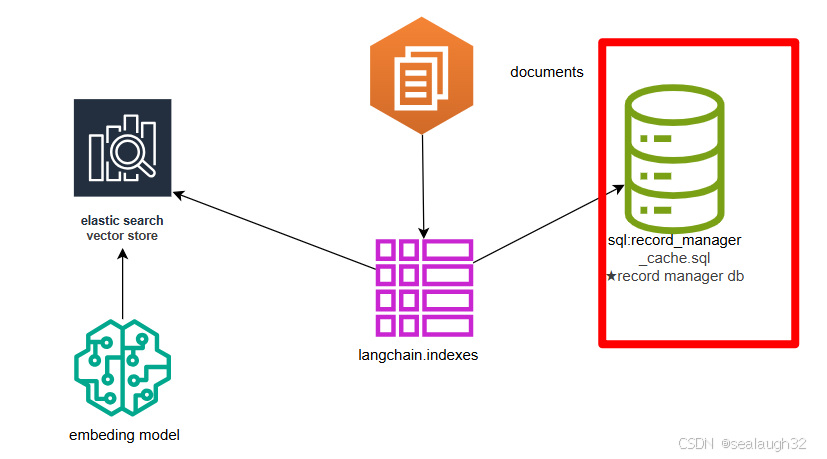
2.3 vector store的整体结构
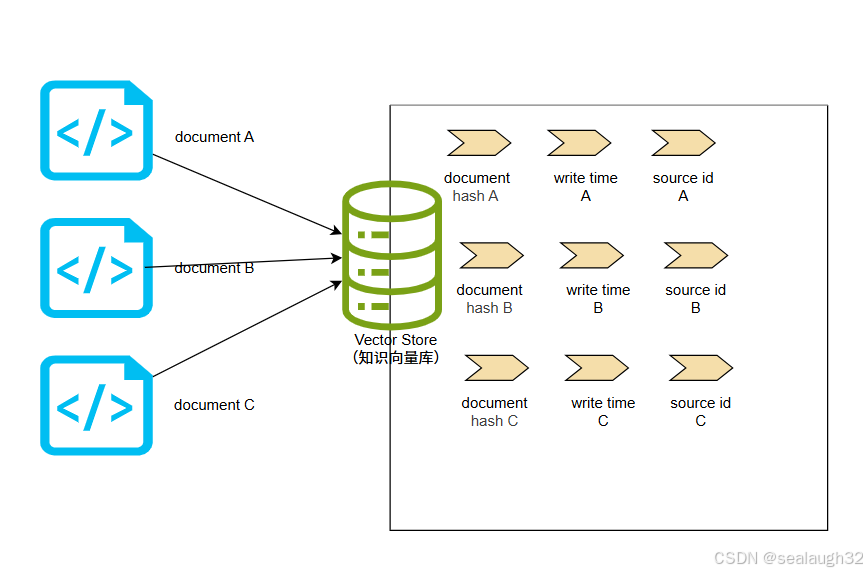
构建一个vector store, 会以document作为单位,讲每个文档进行embed indexing的同时,vector store会对文档的
hashwrite time,source id
进行管理。
2.4 对vector store中的文档document进行indexing的需求
有两种可能,需要对vector store中的文档document进行删除。
- 如果对一个存在在
vector store中的document文档,进行再次indexing,那么需要删除该document。 - 或者就想删除一个在
vector store中的document文档。
2.5 indexing API提供四种模式
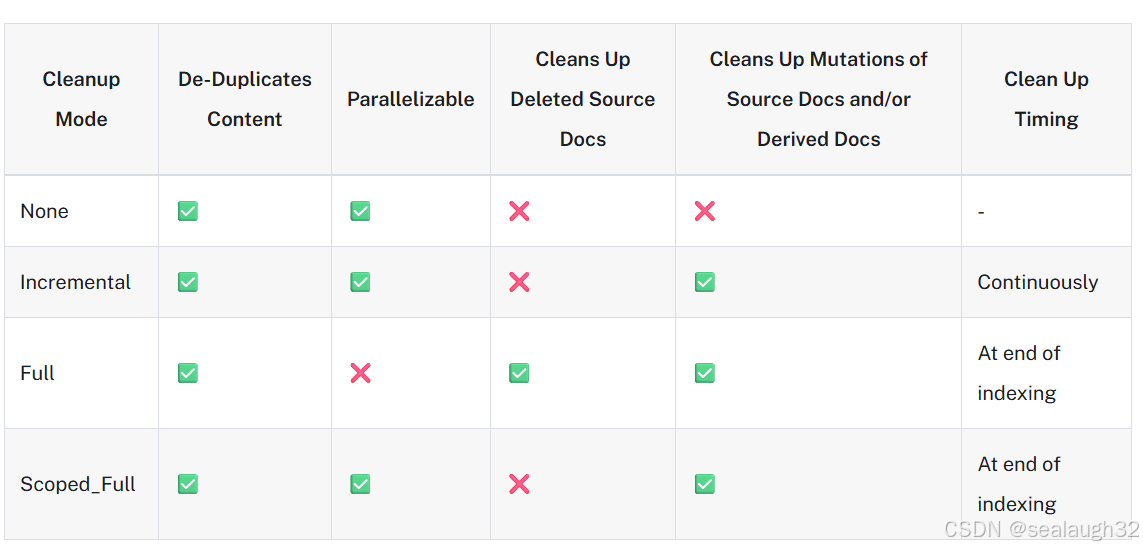
none不能自动删除indexing的document。这种模式完全是汽车的"手动挡"。- 如果文档或者派生文档的内容发生变化,那么
incremental,Full和Scoped_Full模式将自动删除前一个版本的旧文档。 - 如果主动从
vector store中,删除一个文档,Full模式会自动将这个文档上对应的indexing删除,但是Incremental和Scoped_Full并不会自动删除。
2.6 indexing的代码实现
2.6.1 下载并使用elastic search
这里,使用elastic search构建vector store。
- 首先下载
elastic search
elastic search官方网站 - 解压并进入
elastic search的安装路径
进入%installed_path%\bin\
这里%installed_path%是D:\01_software\28_elastic_search\elasticsearch-9.1.4\
- 执行
elastic seach
在本机的9200上端口上,启动elastic search。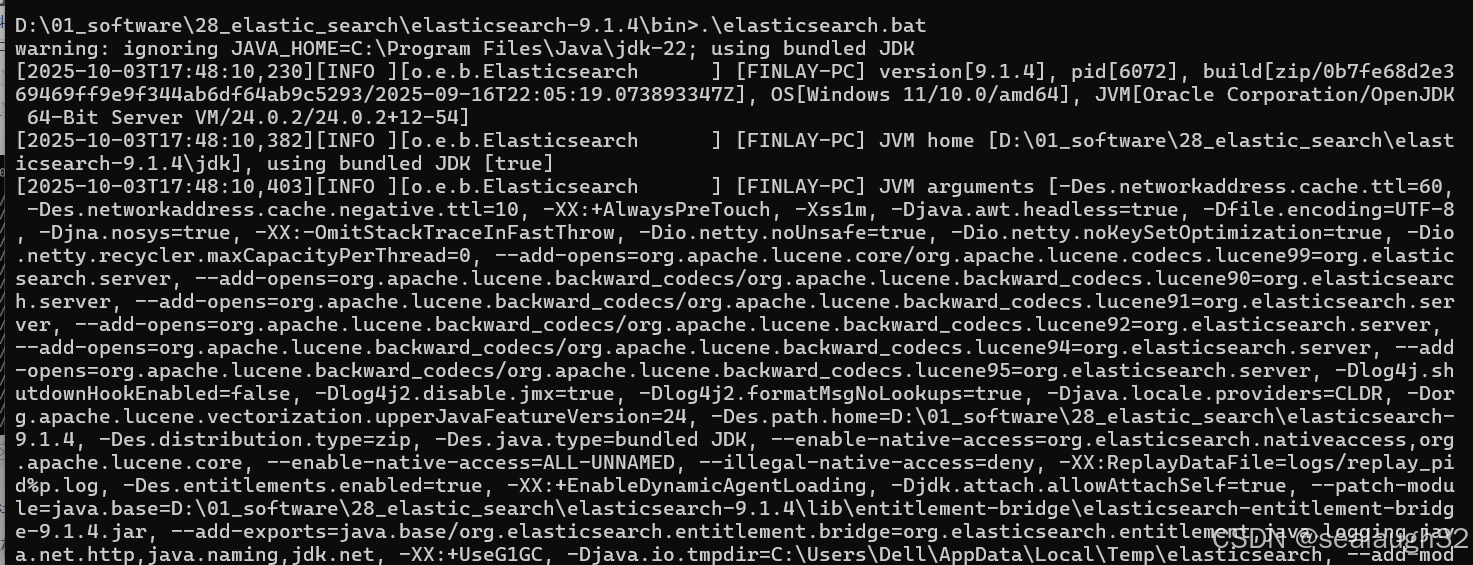
默认启动就是9200端口。
2.6.2 实现代码
- vector store indexing
- 整体架构
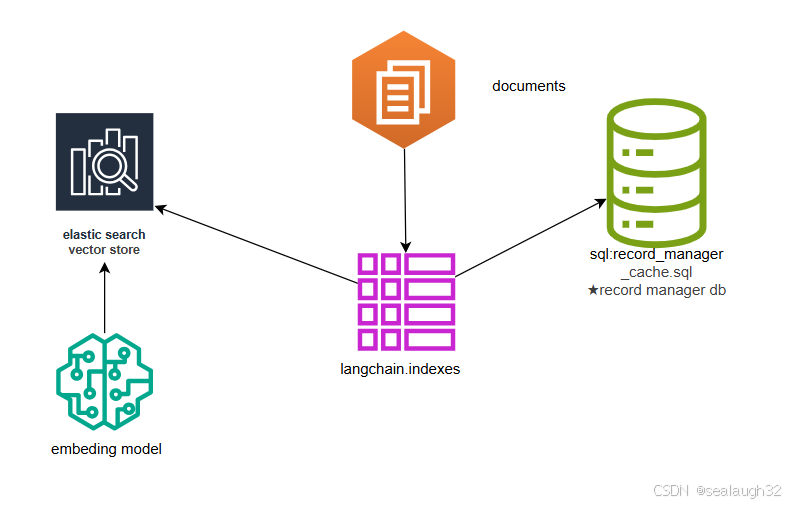
- 代码解析
- 创建
elastic store#使用Ollama的嵌入模型 embeddings_model = OllamaEmbeddings(base_url='http://192.168.1.109:11434',model="nomic-embed-text")vectorstore = ElasticsearchStore(es_url="http://127.0.0.1:9200/",index_name="test_index",embedding=embeddings_model, )
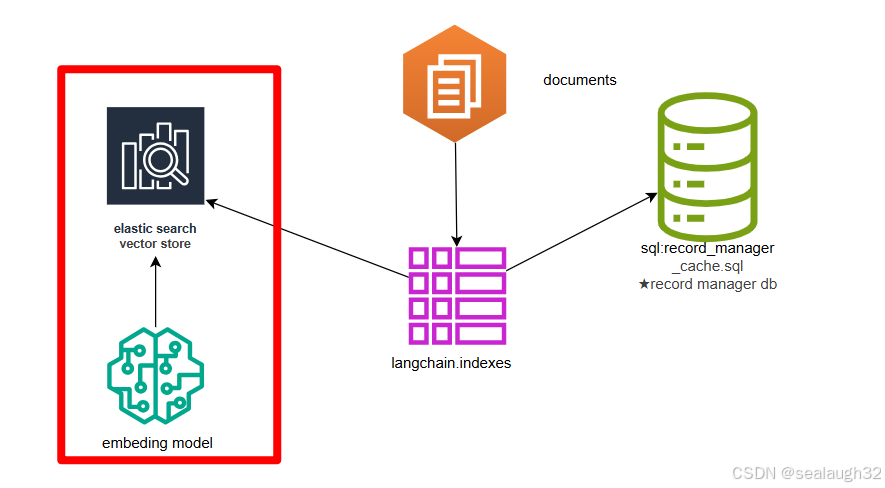
使用elastic search创建vector store,并设定embeding model(这里使用本地的ollama model)- 创建
SQLRecordManager以及namespace
创建namespace = f"elasticsearch/{collection_name}" record_manager = SQLRecordManager(namespace, db_url="sqlite:///record_manager_cache.sql" ) record_manager.create_schema()record_manager_cache.sql,用来保存records。
- 创建连个简单文档
documentdoc1 = Document(page_content="kitty", metadata={"source": "kitty.txt"}) doc2 = Document(page_content="doggy", metadata={"source": "doggy.txt"})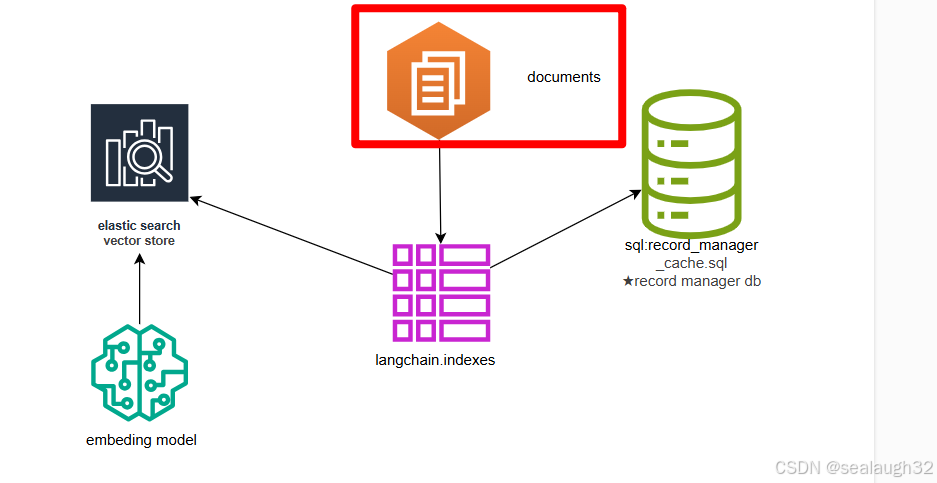
- 将文档
doc1重复进行五次indexingdef _clear():"""Hacky helper method to clear content. See the `full` mode section to understand why it works."""index([], record_manager, vectorstore, cleanup="full", source_id_key="source")_clear() print (index([doc1, doc1, doc1, doc1, doc1],record_manager,vectorstore,cleanup=None,source_id_key="source", )) - 将文档
doc1和doc2分别进行indexing_clear() print(index([doc1, doc2], record_manager, vectorstore, cleanup=None, source_id_key="source") )
- 创建
2.7 indexing的代码执行
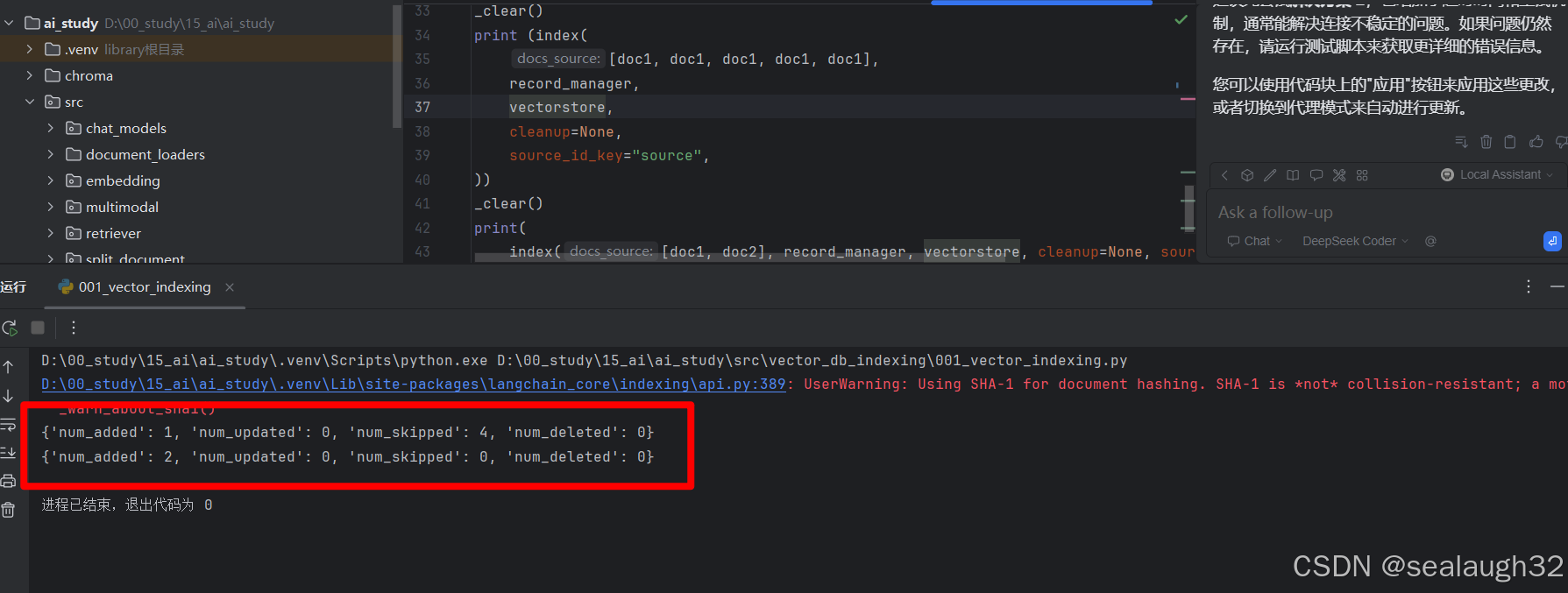
可以看出
- 第一次执行,结果
added可一个文档document,其他的四次都被忽略了。 - 第二次执行,分别给出两个不同的文档,
added了两个document。
和期待的结果一致。
有了这个langchain的indexing API,可以自由的对于document进行delete和重新indexing。