怎么做淘宝客网站备案网站后台的形成
目录
一、语言中的词汇
1、词的形态学
2、词的词性
二、词语规范化
1、词语切分
2、词形还原
3、词干提取
三、中文分词
1、概述
2、基于最大匹配的中文分词
3、基于线性链条件随机场的中文分词
4、基于感知器的中文分词
词序列预测
模型参数学习
特征定义
5、基于双向长短期记忆网络的中文分词
6、中文分词评价方法
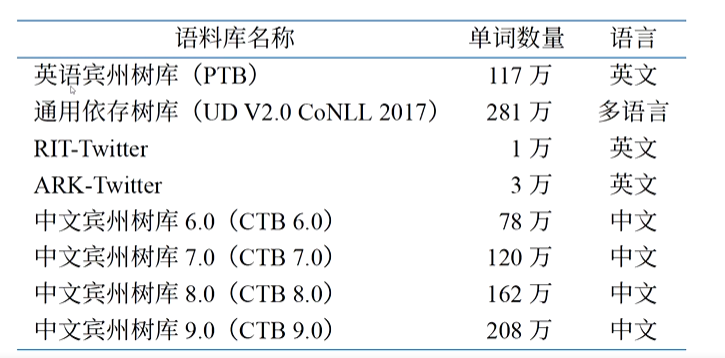
7、中文分词语料库
四、词性标注
1、基于规则的词性标注
2、基于隐马尔可夫模型的词性标注
3、基于卷积神经网络的词性标注
4、词性标注评价方法
5、词性标注语料库
自然语言处理算法中词通常也是基本单元,词的处理也是自然语言处理中重要的底层任务,是句法分析、文本分类、语言型等任务的基础。
一、语言中的词汇
词(word)是形式和意义相结合的单位,也是语言中能够独立运用的最小单位掌握一个词汇意味着知道其读音和语义。



1、词的形态学
· 词的形式具有服从于某种规则的内在结构。研究单词的内部结构和其构成方式的学科称为形态学(Morphology),又称构词学。
2、词的词性

二、词语规范化
词语规范化(Word Normalization)任务是将单词或词形转化为标准形式,针对有多种形式的单词使用一种单一的形式进行表示。
词语切分是前提,为词形还原和词干提取提供处理对象;词形还原和词干提取则是词语规范化的核心手段,目的都是将同一单词的不同形式统一为更简洁的表示
1、词语切分
将连续的文本序列按照一定规则分割成有意义的词语单元。例如:中文句子 “我爱自然语言处理” 经切分后为 “我 / 爱 / 自然 / 语言 / 处理”

word 是语言自然存在的表意单位,而 token 是为了计算需求对文本进行切分后的最小单元。token 可以是一个完整的 word,也可以是 word 的一部分(如子词、字符序列)
2、词形还原
将单词的各种变形形式(如时态、语态、单复数、词性变化等)还原为其基本形式(即 “词根” 或 “原型”),且还原后的形式需是语言中实际存在的合法单词。
- 动词 “running”“ran” 还原为原型 “run”;
- 名词 “mice” 还原为原型 “mouse”;
- 形容词 “better” 还原为原型 “good”。
3、词干提取
指通过去除单词的词缀(如前缀、后缀)等方式,提取出单词的核心部分(即 “词干”),但词干可能并非语言中实际存在的完整单词。最简单的词干提取算法可以通过查询词表的方法获得
另外一种方法是后缀剥离(Suffix-stripping),通过定义一组规则,将特定的后缀从词形中删除
- “running”“runner” 去除后缀 “-ing”“-er” 后,词干为 “run”;
- “happiness” 去除后缀 “-ness” 后,词干为 “happi”(非完整单词
三、中文分词
1、概述
中文分词(Chinese Word Segmentation,CWS)是指将连续字序列转换为对应的词序列的过程,也可以看做在输入的序列中添加空格或其他边界标记的过程。

主要困难来自以下三个方面:分词规范、歧义切分和未登录词【生词】识别。
2、基于最大匹配的中文分词
最大匹配(Maximum Matching)分词算法,核心思想是 “从词典中找出最长的词来匹配当前文本片段”,通过贪心策略确定词边界。主要包含前向最大匹配、后向最大匹配以及双向最大匹配等三类。

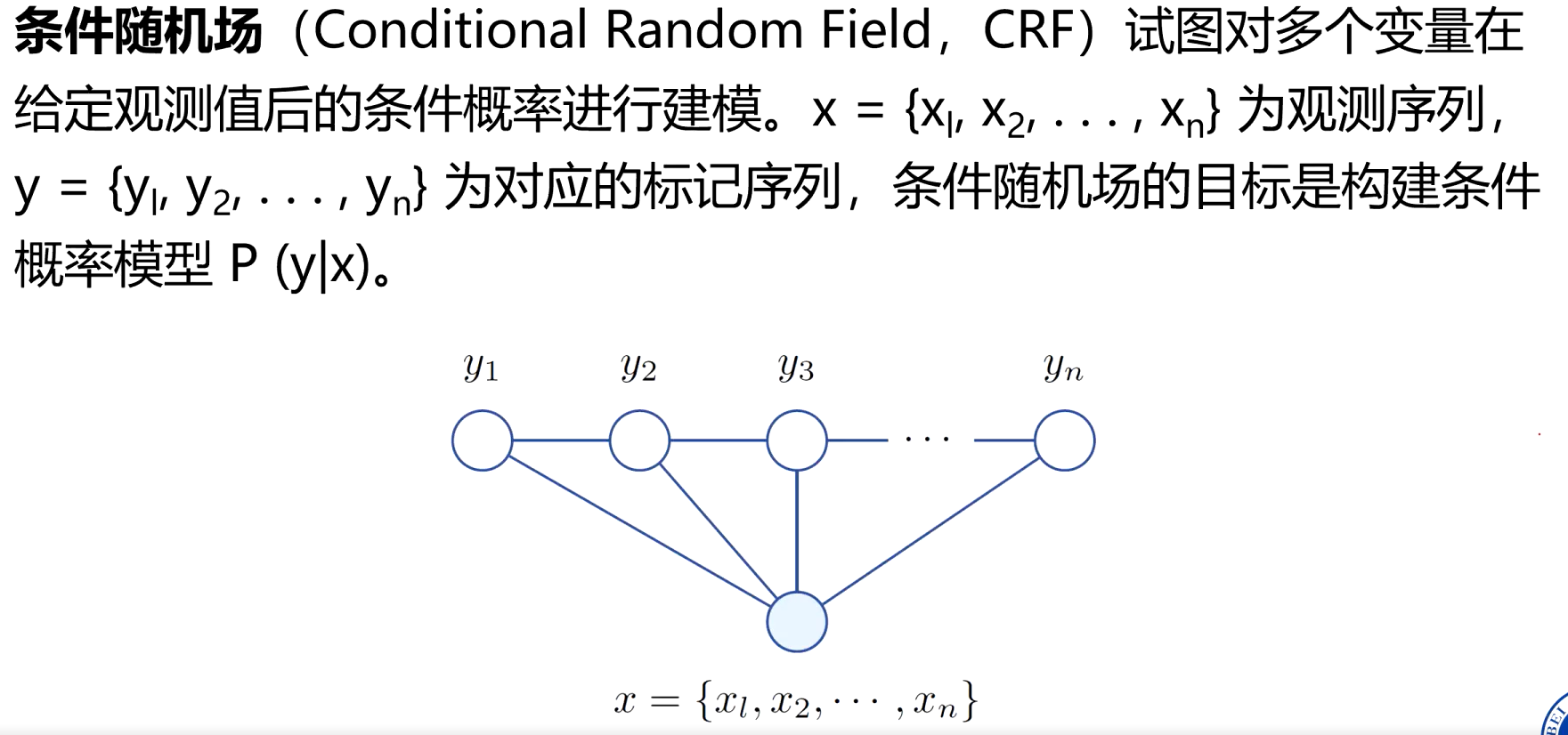
3、基于线性链条件随机场的中文分词
- 先给每个字贴标签,再按标签切分
将分词过程转换为对字的分类问题,对于输入句子中的每一个字c;,根据它在分词结果中的位置赋予不同的标签。

怎么让机器准确地给每个字贴 B/I/E/S 标签?线性链条件随机场(CRF)就是干这个的 “聪明工具”。给每个字贴标签时,不会只看单个字,而是会看这个字本身的特点、看上下文的关系、遵守标签之间的 “规矩”
- 如何学习的呢?
- 用 BIES 标签将分词转化为序列标注;
- 设计转移特征(约束标签合法性)和状态特征(捕捉汉字与标签的关联);
- 通过训练学习特征权重,使模型符合语言规律;
- 用 Viterbi 算法快速找到最优标签序列,实现分词。

4、基于感知器的中文分词


-
词序列预测


-
模型参数学习

-
特征定义

5、基于双向长短期记忆网络的中文分词
核心是利用神经网络自动学习汉字的上下文特征,将分词转化为序列标注任务
BiLSTM 是 LSTM(长短期记忆网络)的双向扩展,能同时捕捉文本的 “左→右” 和 “右→左” 上下文信息
6、中文分词评价方法
中文分词的评价核心是衡量 “系统切分结果” 与 “人工标注的标准答案(gold standard)” 的一致性,常用指标包括准确率、召回率、F1 值,辅以其他辅助指标。
7、中文分词语料库
分词语料库是人工标注了正确词边界的中文文本集合,是训练和评价分词模型的基础.
公开语料库:PKU、MSR 等可通过学术平台(如 LDC、SIGHAN 官网)免费获取
四、词性标注
词性是词语的基本属性,根据其在句子中所扮演的语法角色以及与周围词的关系进
行分类。词性标注(Part-of-speech Tagging,POs Tagging)是指在给定的语境中确定句子中各词的词性。词性标注的主要难点在于歧义性,即一个词可能在不同的上下文中具有不同的词性。也没有一个被广泛认可的统一词性划分标准。
1、基于规则的词性标注
利用词典和搭配规则针对词语和上下文进行分析,从而得到句子中每个词语词性。

例如:补丁规则“NN VB PREV-TAG TO”表示,如果一个单词被标注为了NN(名词并且它前面的单词标注为了TO(不定式“to”),那么将这个单词的词性转换为VB(动词)
2、基于隐马尔可夫模型的词性标注


3、基于卷积神经网络的词性标注
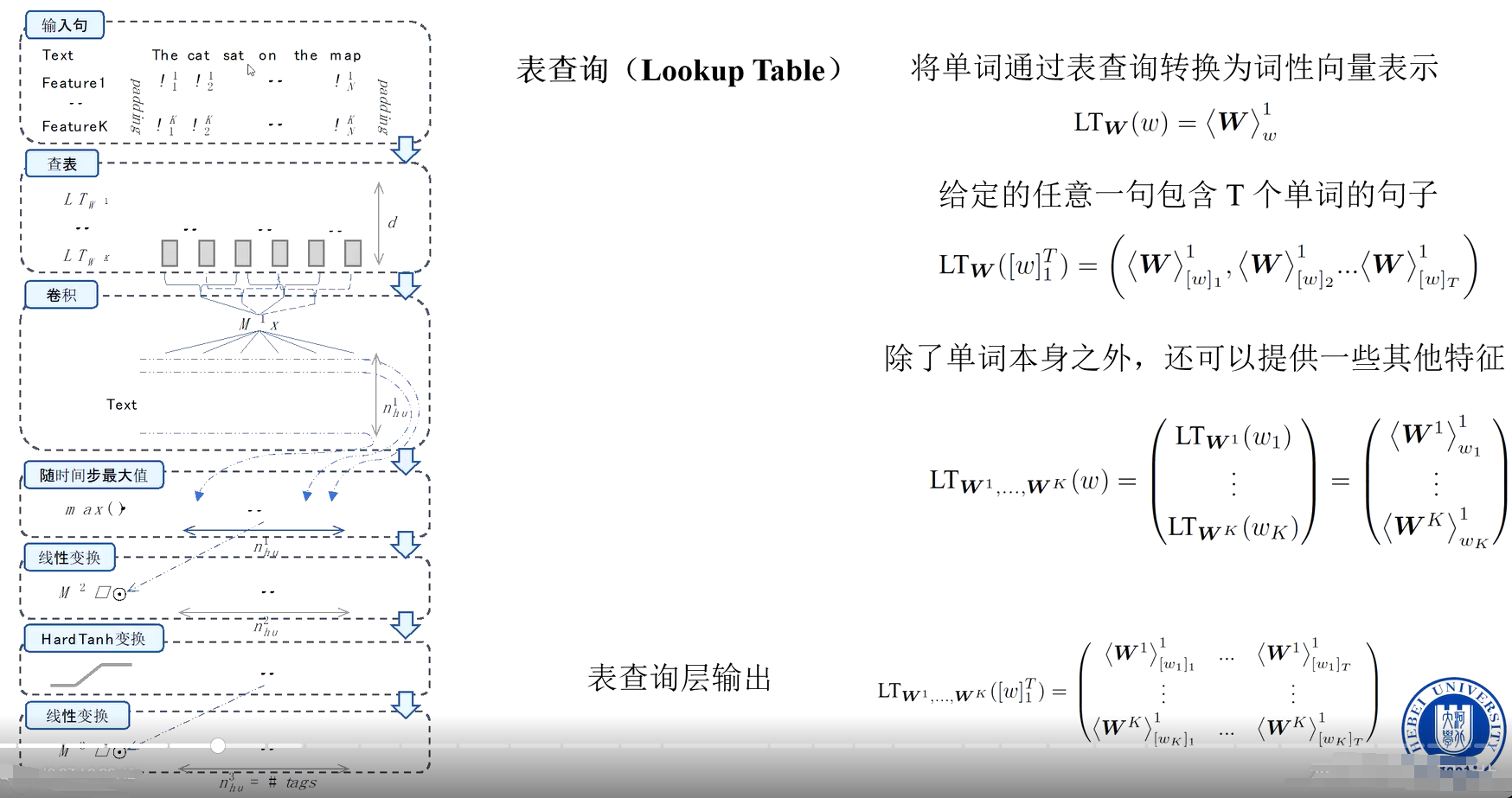
输入层:词嵌入(Word Embedding)
卷积层:提取局部上下文特征
池化层:聚合局部特征
全连接层与输出层:预测词性标签
4、词性标注评价方法