Java 黑马程序员学习笔记(进阶篇16)
1. LinkedHashMap 集合
① 核心特点:
- 不重复(键唯一,基于哈希表特性);
- 无索引(无法通过索引随机访问);
- 有序性:默认按插入顺序排序;也可通过构造函数传入
accessOrder = true,改为按访问顺序(访问过的元素移到链表尾部)排序。
② 底层原理:
底层数据结构仍为哈希表,但每个键值对额外通过双链表机制记录存储顺序(类似 HashSet 的有序实现逻辑)。
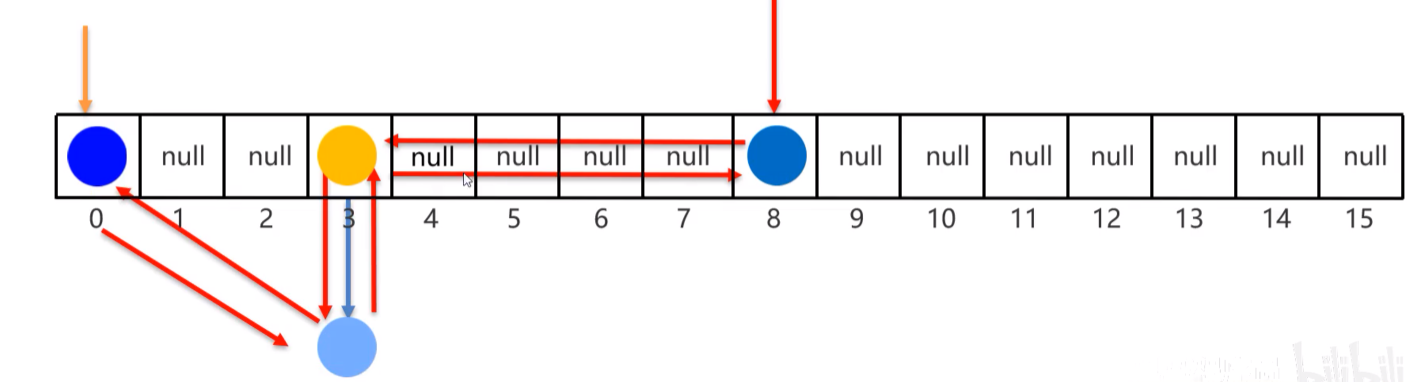
2. TreeMap 集合
① 核心特点:
- 底层是红黑树结构(平衡二叉搜索树,保证查询、插入效率);
- 依赖自然排序(键实现
Comparable接口)或比较器排序(创建TreeMap时传入Comparator)对键排序; - 若键是自定义对象,必须实现
Comparable接口或在创建TreeMap时指定比较器; - 默认按键从小到大排序,也可自定义排序规则。
② 综合练习
题目 1:学生信息管理
请设计一个 Java 程序,实现以下功能:
(1) 定义一个 Student 类,包含以下属性:
name(姓名,String 类型)age(年龄,int 类型)- 提供无参构造方法和带参构造方法
- 提供
getName()、setName()、getAge()、setAge()方法 - 重写
equals()和hashCode()方法(根据姓名和年龄判断相等) - 重写
toString()方法,格式为:Student{name = 姓名, age = 年龄} - 实现
Comparable<Student>接口,排序规则为:- 先按年龄升序排序
- 若年龄相同,按姓名的字典序升序排序
(2) 编写测试类 test,在 main 方法中完成:
- 创建一个
TreeMap<Student, String>对象(键为学生对象,值为学生的籍贯) - 添加以下三个学生信息:
- 姓名:zhangsan,年龄:23,籍贯:江苏
- 姓名:lisi,年龄:24,籍贯:天津
- 姓名:wangwu,年龄:25,籍贯:北京
- 打印输出整个
TreeMap对象
(3) 要求:
- 使用
TreeMap的默认排序(即依赖Student类的compareTo方法) - 运行结果应按照年龄从小到大输出,如果年龄相同,则按姓名字典序输出
package demo1;import java.util.Objects;public class Student implements Comparable<Student> {private String name;private int age;public Student() {}public Student(String name, int age) {this.name = name;this.age = age;}/*** 获取* @return name*/public String getName() {return name;}/*** 设置* @param name*/public void setName(String name) {this.name = name;}/*** 获取* @return age*/public int getAge() {return age;}/*** 设置* @param age*/public void setAge(int age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}public String toString() {return "Student{name = " + name + ", age = " + age + "}";}@Overridepublic int compareTo(Student o) {int i = this.getAge() - o.getAge();i = i == 0 ? this.getName().compareTo(o.getName()) : i;return i; //不太理解}
}
package demo1;import java.util.TreeMap;public class test4 {public static void main(String[] args) {TreeMap<Student, String> tm = new TreeMap<Student, String>();Student s1 = new Student("zhangsan",23);Student s2 = new Student("lisi",24);Student s3 = new Student("wangwu",25);tm.put(s1,"江苏");tm.put(s2,"天津");tm.put(s3,"北京");System.out.println(tm);}
}
关键逻辑:为什么 compareTo( ) 里不需要写 if (i > 0)、if (i < 0) 这类判断
(1) compareTo 方法的核心约定
Comparable 接口要求 compareTo 方法返回:
- 正整数:表示当前对象 > 参数对象;
- 负整数:表示当前对象 < 参数对象;
- 0:表示当前对象 = 参数对象。
(2) 代码的简洁逻辑
这段代码利用了 “整数减法的符号特性” 来简化判断:
int i = this.getAge() - o.getAge();
i = i == 0 ? this.getName().compareTo(o.getName()) : i;
return i;第一步:this.getAge() - o.getAge()
- 若
this.age > o.age,结果i是正整数(符合 “当前对象大” 的约定); - 若
this.age < o.age,结果i是负整数(符合 “当前对象小” 的约定); - 若
this.age == o.age,结果i是 0(进入下一步 “比较姓名”)。
第二步:i == 0 ? this.getName().compareTo(o.getName()) : i
- 当年龄相等时,调用
String的compareTo方法(String本身也实现了Comparable),它会返回正、负、0(对应姓名字典序的 “大、小、相等”)。
3. HashMap 源码分析
① Node 节点
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}
}- 作用:普通链表节点,存储 key、value、hash 值和指向下一个节点的引用。
- 特点:单向链表结构,用于处理哈希冲突。
② TreeNode 节点(红黑树节点)
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // 父节点TreeNode<K,V> left; // 左子节点TreeNode<K,V> right; // 右子节点TreeNode<K,V> prev; // 前一个节点(用于双向链表)boolean red; // 节点颜色(红/黑)
}(1) 作用:当红黑树化时,链表节点会被替换为 TreeNode。
(2) 特点:
- 继承自
LinkedHashMap.Entry,同时保留链表的前后指针(方便在需要时退化为链表)。 - 额外维护红黑树的父节点、左右子节点和颜色。
- 红黑树是一种自平衡二叉查找树,保证 O (log n) 的查找效率。
③ put 方法入口(JDK 1.8)
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}- hash(key):计算 key 的哈希值(扰动函数)
- putVal(...):真正执行插入的核心方法
④ putVal 核心源码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// ① 如果 table 还没初始化,或者长度为 0,先进行扩容(初始化)if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// ② 计算数组索引 i,如果该位置为空,直接放一个新 Nodeif ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// ③ 如果桶中第一个元素的 hash 和 key 相同,说明找到了目标节点if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;// ④ 如果第一个节点是红黑树节点,则调用红黑树的插入方法else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// ⑤ 否则是普通链表,进行遍历else {for (int binCount = 0; ; ++binCount) {// 遍历到链表尾部if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 如果链表长度 >= 8,考虑转红黑树if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}// 如果找到了相同 key 的节点if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// ⑥ 如果 key 已经存在,覆盖旧值if (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e); // LinkedHashMap 回调return oldValue;}}// ⑦ 修改次数 +1(用于快速失败机制)++modCount;// ⑧ 如果元素数量超过阈值,触发扩容if (++size > threshold)resize();afterNodeInsertion(evict); // LinkedHashMap 回调return null;
}步骤 ①:检查是否需要初始化
if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;tab = table:把成员变量table赋值给局部变量tab(性能优化,减少多次访问成员变量)。- 如果
table为空,调用resize()初始化(容量默认 16,阈值 12)。
步骤 ②:计算索引并判断桶是否为空
if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);i = (n - 1) & hash:利用位运算代替取模,计算数组下标。- 如果该位置为空,直接创建新的
Node放进去。
步骤 ③:桶不为空,检查头节点是否相同
- 比较 hash 值和 key(先比较 hash,再用
equals)。 - 如果相同,说明 key 已存在,用
e保存该节点,后续覆盖值。
步骤 ④:红黑树插入
- 如果桶的第一个节点是
TreeNode,说明该桶已经树化。 - 调用
putTreeVal()在红黑树中插入或覆盖节点。
步骤 ⑤:链表插入
用 for 循环遍历链表:
- 如果到尾部还没找到相同 key,就尾插法插入新节点。
- 如果链表长度达到 TREEIFY_THRESHOLD - 1(默认 7),插入后链表长度为 8,调用
treeifyBin()尝试转红黑树。 - 如果中途找到相同 key,停止遍历。
步骤 ⑥:覆盖旧值
- 如果
e != null,说明 key 已存在,根据onlyIfAbsent判断是否覆盖旧值。 afterNodeAccess(e)是给 LinkedHashMap 用的回调,用于移动节点到链表尾部(LRU 机制)。
4. TreeMap 源码分析
① 底层数据结构
static final class Entry<K,V> implements Map.Entry<K,V> {K key;V value;Entry<K,V> left; // 左子节点Entry<K,V> right; // 右子节点Entry<K,V> parent; // 父节点boolean color = BLACK; // 颜色,红黑树的重要属性
}② 核心成员变量
private final Comparator<? super K> comparator; // 比较器,可null
private transient Entry<K,V> root; // 红黑树根节点
private transient int size = 0; // 元素数量
private transient int modCount = 0; // 修改次数(用于快速失败)comparator:
- 如果为
null,使用 key 的自然排序(Comparable)。 - 如果不为
null,使用比较器定义的顺序。
③ put 方法入口
public V put(K key, V value) {Entry<K,V> t = root;if (t == null) {compare(key, key); // 检测key是否为null(会抛NPE)root = new Entry<>(key, value, null);size = 1;modCount++;return null;}int cmp;Entry<K,V> parent;Comparator<? super K> cpr = comparator;if (cpr != null) {// 使用比较器查找插入位置do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value); // key相同,覆盖value} while (t != null);} else {// 自然排序查找插入位置if (key == null)throw new NullPointerException();@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}Entry<K,V> e = new Entry<>(key, value, parent);if (cmp < 0)parent.left = e;elseparent.right = e;fixAfterInsertion(e); // 插入后修复红黑树性质size++;modCount++;return null;
}(1) 空树处理
if (t == null) {compare(key, key); // 检查key是否为null(会抛NPE)root = new Entry<>(key, value, null);size = 1;modCount++;return null;
}如果 TreeMap 是空的(root == null):
compare(key, key)会调用比较器或Comparable.compareTo(),如果 key 是null会抛出NullPointerException(TreeMap 不允许 null key)。- 创建新节点作为根节点(根节点默认为黑色)。
- size 设为 1,直接返回。
(2) 查找插入位置
如果使用比较器(Comparator):
do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left; // key小于当前节点,往左子树找else if (cmp > 0)t = t.right; // key大于当前节点,往右子树找elsereturn t.setValue(value); // key相等,覆盖旧值
} while (t != null);如果使用自然排序(Comparable):
Comparable<? super K> k = (Comparable<? super K>) key;
do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);
} while (t != null);为什么要强制转换?
原因:
key的静态类型是K(泛型参数),在编译时,编译器并不知道K是否真的实现了Comparable接口。- 虽然 TreeMap 的契约要求:如果不提供
Comparator,则K必须实现Comparable,但 Java 泛型本身不会在编译时强制这一点。 - 因此,在调用
key.compareTo(...)之前,必须把key转成Comparable类型,否则编译器会报错。
(3) 创建新节点并插入
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)parent.left = e;
elseparent.right = e;- 新建节点,颜色默认黑色(但插入后会在
fixAfterInsertion中改为红色,并可能调整)。 - 根据
cmp结果插入到左子树或右子树。
(4) 插入后修复红黑树性质
fixAfterInsertion(e);