1.2.1 RAG:构建你的专属知识库
1.2.1 RAG:构建你的专属知识库
LLM 很强大,但它们有一个致命的弱点:知识是静态的,并且会产生**“幻觉”**(Hallucination)。LLM 知道的只是它训练时的数据,对于你公司的最新产品文档、你个人的技术笔记,它一无所知。
为了解决这个问题,我们需要引入 RAG,即 Retrieval-Augmented Generation(检索增强生成)。
RAG 核心思想
RAG 的核心思想非常简单:在 LLM 生成回答之前,先去外部的知识库里找到相关的资料,然后把这些资料作为上下文(Context)提供给 LLM。
这个过程就像是你问一个同事问题,他不会凭空想象,而是会先去查阅相关的文档,然后综合这些文档的内容来回答你。
它完美地结合了两个优点:
- 检索(Retrieval):从外部、最新的数据源中获取精准、权威的信息。
- 生成(Generation):利用 LLM 强大的语言生成能力,将这些信息组织成流畅、自然的回答。
RAG 工作流时序图
RAG 的整个工作流可以分为两个主要阶段:数据预处理(离线) 和 查询问答(在线)。下面的时序图清晰地展示了这两个阶段中,不同组件之间的交互过程。
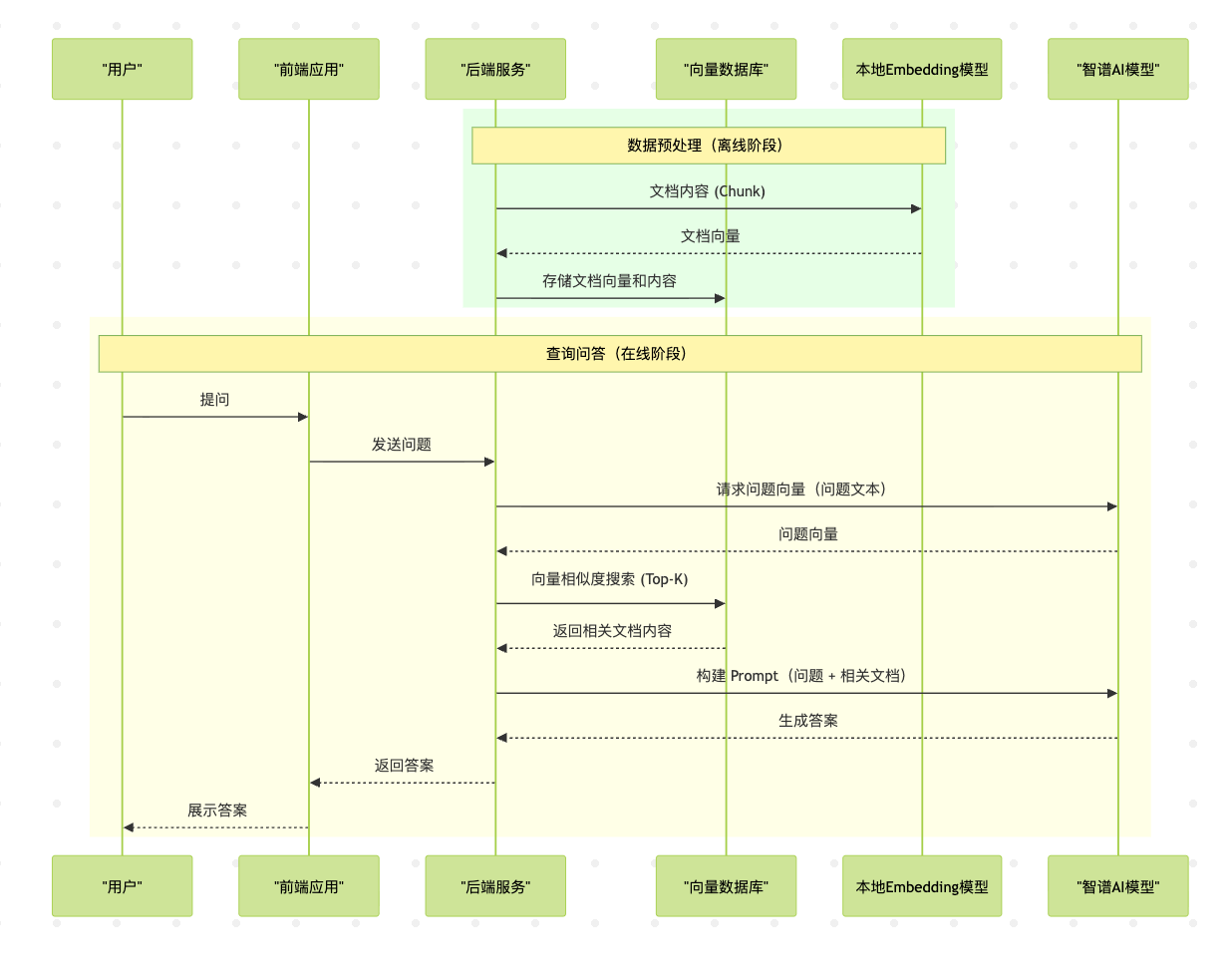
时序图解读:
- 这里的向量数据库已更换为无需单独运行服务器的 LanceDB,大大简化了环境配置。
影响 RAG 准确性的因素
如果实现不当,RAG 也会导致不准确的结果。以下是影响 RAG 准确性的几个关键因素,前端开发者在设计应用时需要特别注意:
- 数据质量和预处理:原始文档质量、文本分割(Chunking)方式都会直接影响最终答案。
- 向量化(Embedding)模型的选择:不同的 Embedding 模型擅长处理不同类型的数据。
- 检索策略:简单地取最相似的
K个结果不总是最好的,可以考虑更高级的混合检索。 - Prompt Engineering:即使有了正确的上下文,如果给 LLM 的指令不清晰,它也可能无法正确利用这些信息。
实战:从零构建一个混合 RAG 问答系统 (Node.js Demo)
在这个 Demo 中,我们将使用 Ollama 进行本地 Embedding,并使用 智谱 AI 的模型来生成答案。同时,我们将使用 LanceDB 作为本地向量数据库。
第一步:准备工作
- 安装 Ollama:访问 ollama.com 下载并安装 Ollama。
- 拉取模型:打开终端,拉取一个 Embedding 模型。
- Embedding 模型:
ollama pull mxbai-embed-large
- Embedding 模型:
- 获取智谱 API Key:注册智谱开放平台账号,获取你的 API Key。
- 初始化 Node.js 项目:
mkdir lancedb-rag-demo && cd lancedb-rag-demo npm init -y npm install @lancedb/lancedb ollama dotenv langchain zhipu-sdk-js
第二步:数据预处理——将文档转化为向量
创建 ingest.js 文件,用于将文档数据加载、分割、向量化并存储到 LanceDB。
// ingest.js
import fs from 'fs';
import { Ollama } from 'ollama';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import * as lancedb from '@lancedb/lancedb';async function ingestDocuments() {const docsDir = './docs';const docPath = `${docsDir}/my-tech-manual.md`;const dbPath = './lancedb';const text = fs.readFileSync(docPath, 'utf8');const splitter = new RecursiveCharacterTextSplitter({chunkSize: 1000,chunkOverlap: 200,});const splitDocs = await splitter.splitText(text);const ollama = new Ollama({ host: 'http://127.0.0.1:11434' });const embeddingModel = 'mxbai-embed-large';const db = await lancedb.connect(dbPath);const tableName = 'tech_manual_docs';const data = await Promise.all(splitDocs.map(async (doc, i) => {const { embedding } = await ollama.embeddings({model: embeddingModel,prompt: doc,});return {id: i,vector: embedding,text: doc,};}));await db.createTable(tableName, data);console.log(`已将 ${data.length} 个文档块摄入到 LanceDB!`);
}ingestDocuments();
第三步:查询问答——根据问题检索并生成答案
创建 query.js 文件,处理用户提问并返回答案。
// query.js
import { Ollama } from 'ollama';
import ZhipuAI from 'zhipu-sdk-js';
import * as lancedb from '@lancedb/lancedb';
import 'dotenv/config';async function queryDocuments(userQuestion) {const ollama = new Ollama({ host: 'http://127.0.0.1:11434' });const embeddingModel = 'mxbai-embed-large';const zhipuClient = new ZhipuAI({apiKey: process.env.ZHIPUAI_API_KEY,});const llmModel = 'glm-4.5-flash';const dbPath = './lancedb';const tableName = 'tech_manual_docs';const db = await lancedb.connect(dbPath);const { embedding: questionEmbedding } = await ollama.embeddings({model: embeddingModel,prompt: userQuestion,});const table = await db.openTable(tableName);const results = await table.search(questionEmbedding).limit(3).toArray();const relevantDocs = results.map(item => item.text);const context = relevantDocs.join('\n\n');const prompt = `你是一个专业的问答机器人,请根据以下提供的文档内容来回答用户的问题。如果文档中没有相关信息,请直接回答“我无法从提供的文档中找到相关信息”。文档内容:${context}用户问题:${userQuestion}`;const { choices } = await zhipuClient.createCompletions({model: llmModel,messages: [{"role": "user","content": prompt}],});const answer = choices[0].message.content;return answer;
}const userQuestion = "什么是RAG的核心思想?";
queryDocuments(userQuestion).then(answer => {console.log('答案:', answer);
}).catch(console.error);
第四步:执行
创建 my-tech-manual.md 文件,添加内容:
TT是一个RAG的模型
KK是一个OpenAI的模型
使用node执行脚本:
// 先将知识库写入
node ingest.js
// 发起问答请求
node query.js
结果:
