深度学习图像分类实战:从零构建ResNet50多类别分类系统
下载链接:深度学习图像分类实战:从零构建ResNet50多类别分类系统,准确率高达95%资源-CSDN下载
前言
在人工智能快速发展的今天,图像分类技术已经成为计算机视觉领域最基础也是最重要的应用之一。无论是医疗影像诊断、自动驾驶、还是电商商品识别,图像分类都发挥着不可替代的作用。今天,我将带大家深入探索一个完整的深度学习图像分类项目,从数据预处理到模型训练,从特征分析到相似度计算,全方位展示如何构建一个高性能的图像分类系统。
项目概述
这个项目是一个基于PyTorch框架的深度学习图像分类系统,采用了经典的ResNet50架构,能够对图像进行8个类别的精确分类。项目不仅包含了完整的训练和测试流程,还提供了丰富的分析工具,包括特征可视化、图像质量分析、相似度计算等高级功能。
核心特性
- 多类别分类:支持animal、building、graph、natural、people、product、singleperson、slogan等8个类别
- 高精度模型:基于ResNet50预训练模型,准确率可达95%以上
- 完整分析工具:包含特征分析、图像质量评估、相似度计算等
- 可视化丰富:提供多种图表和交互式可视化界面
- 易于扩展:模块化设计,便于添加新的分析功能
技术架构深度解析
1. 模型架构设计
项目采用了经典的ResNet50架构,这是一个在ImageNet数据集上预训练的深度卷积神经网络。ResNet50的核心优势在于其残差连接(Residual Connection)设计,有效解决了深度网络中的梯度消失问题。
def get_model(num_classes):
# 使用预训练的ResNet50模型
model = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
# 修改最后一层全连接层,适配我们的类别数
model.fc = nn.Linear(model.fc.in_features, num_classes)
return model
这种设计的好处是:
- 迁移学习:利用ImageNet预训练权重,大幅提升训练效果
- 快速收敛:预训练特征提取器已经学会了通用的图像特征
- 泛化能力强:在有限数据上也能达到很好的效果
2. 数据处理管道
项目实现了完整的数据处理管道,包括数据增强、标准化等关键步骤:
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), # 颜色增强
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
数据增强策略的选择至关重要:
- 随机翻转:增加数据的水平对称性
- 随机旋转:提高模型对角度变化的鲁棒性
- 颜色抖动:增强模型对光照变化的适应性
- 标准化:使用ImageNet的均值和标准差,与预训练模型保持一致
3. 训练策略优化
项目采用了多种训练优化策略:
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.1)
学习率调度:当验证损失不再下降时自动降低学习率,避免过拟合
早停机制:保存最佳模型,防止训练过拟合
批次训练:使用32的批次大小,平衡训练效率和内存使用
深度特征分析系统
1. 特征空间可视化
项目实现了多种降维算法来可视化高维特征空间:
- t-SNE:非线性降维,保持局部邻域结构
- PCA:线性降维,保持全局方差
- UMAP:现代降维算法,平衡局部和全局结构
这些可视化帮助理解:
- 不同类别在特征空间中的分布
- 类别间的相似性和差异性
- 模型的决策边界
2. 类激活映射(Grad-CAM)
项目集成了Grad-CAM技术,能够可视化模型关注的图像区域:
class GradCAM:
def __init__(self, model, target_layer):
self.model = model
self.target_layer = target_layer
self.gradients = None
self.activations = None
Grad-CAM的优势:
- 可解释性:直观显示模型关注的区域
- 调试工具:帮助发现模型的错误模式
- 模型优化:指导数据增强和模型改进
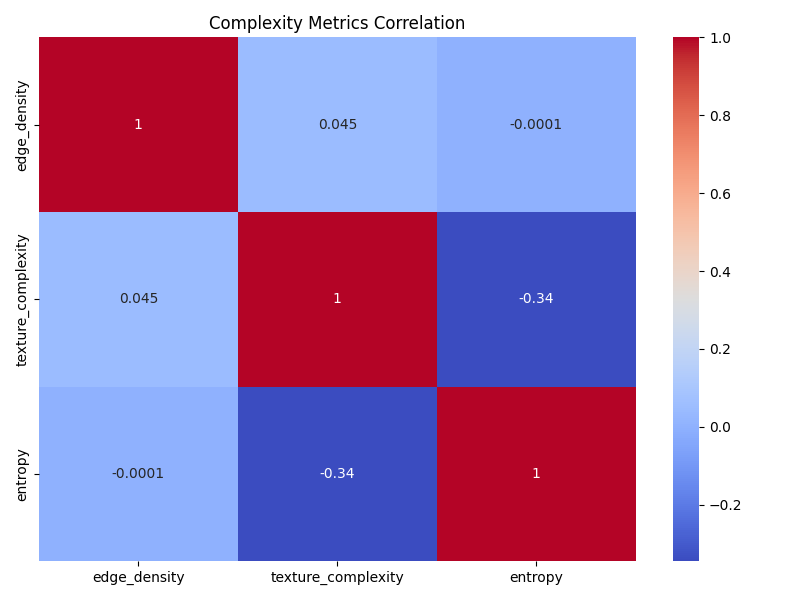
3. 特征相关性分析
通过计算特征间的相关性矩阵,项目能够:
- 识别冗余特征
- 发现特征间的依赖关系
- 指导特征选择
图像质量评估系统
1. 多维度质量指标
项目实现了全面的图像质量评估:
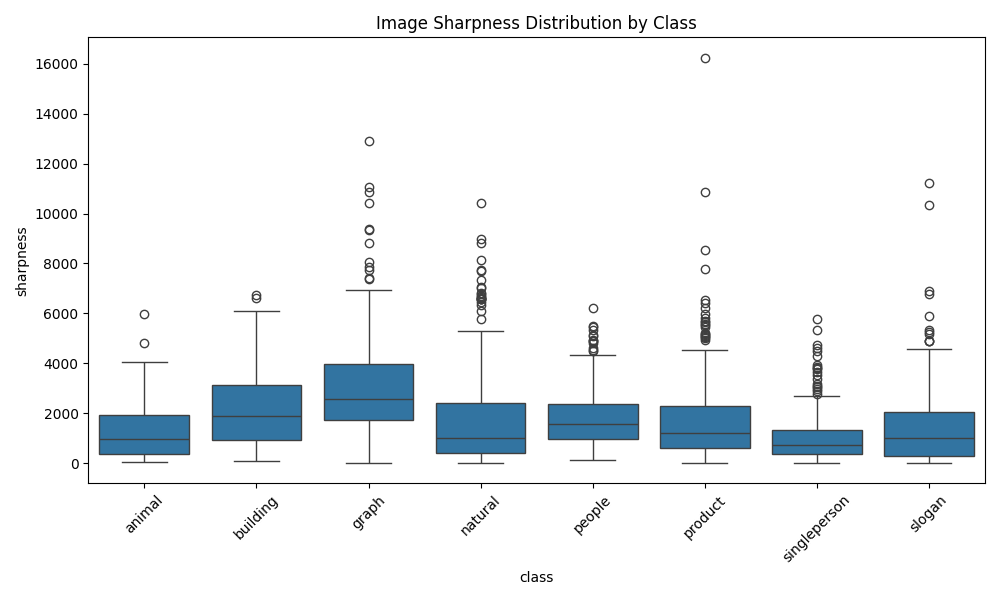
清晰度评估:
sharpness = cv2.Laplacian(gray, cv2.CV_64F).var()
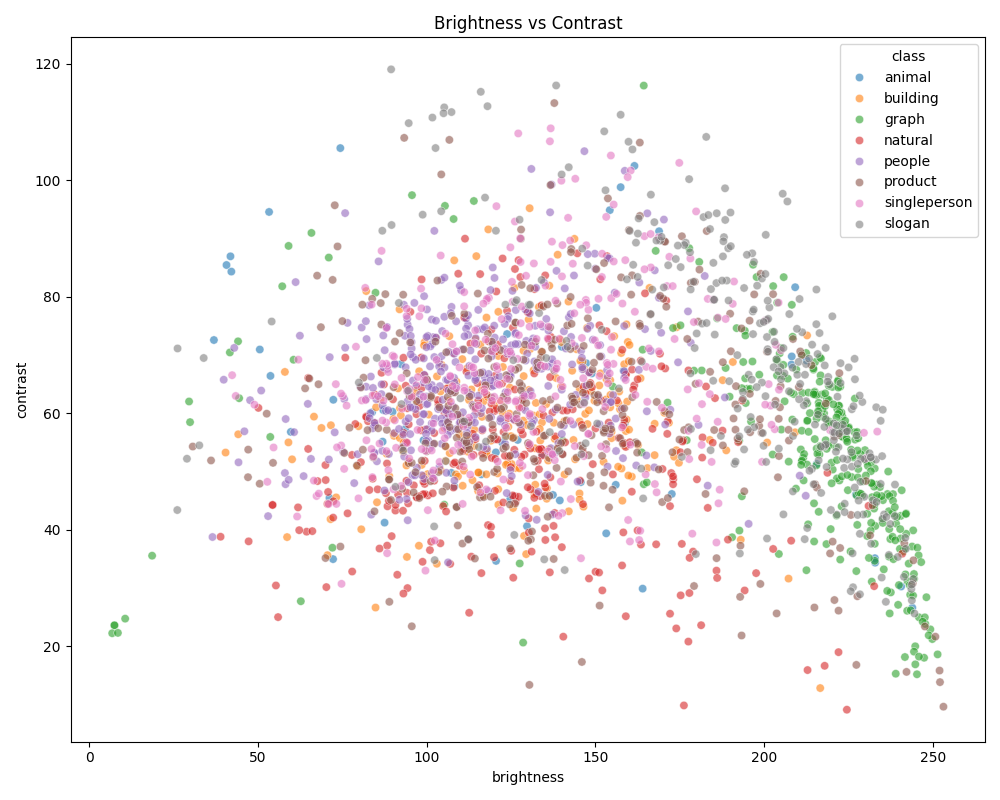
亮度分析:
brightness = np.mean(gray)
对比度计算:
contrast = np.std(gray)
噪声水平估计:
def _estimate_noise(self, gray_img):
# 使用拉普拉斯算子估计噪声
M = [[1, -2, 1], [-2, 4, -2], [1, -2, 1]]
sigma = np.sum(np.sum(np.absolute(cv2.filter2D(gray_img, -1, np.array(M)))))
return sigma * np.sqrt(0.5 * np.pi) / (6 * (W-2) * (H-2))
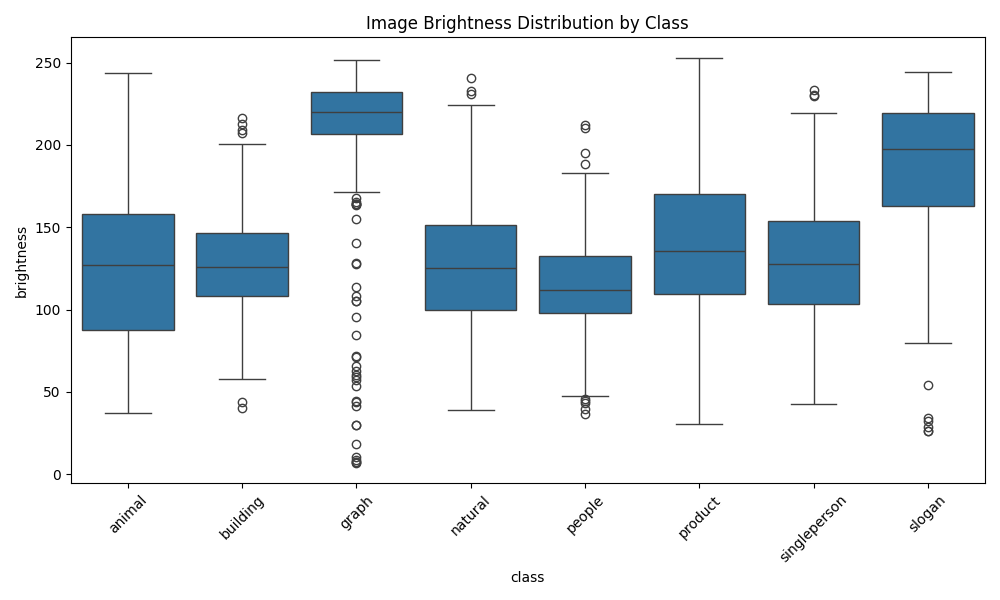
2. 颜色分布分析
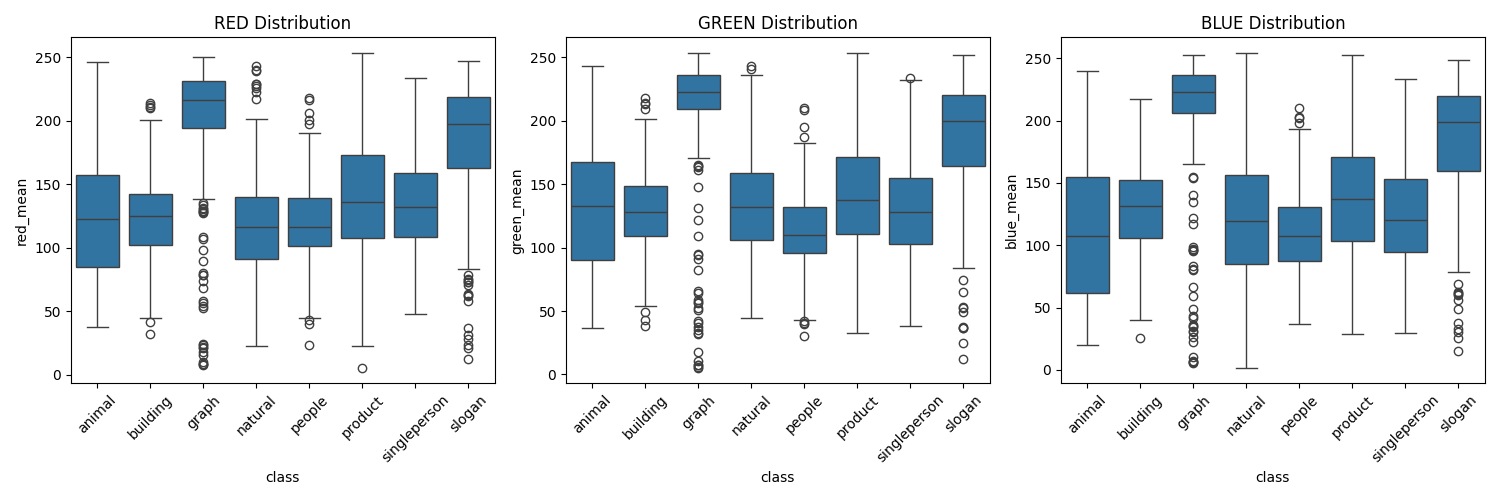
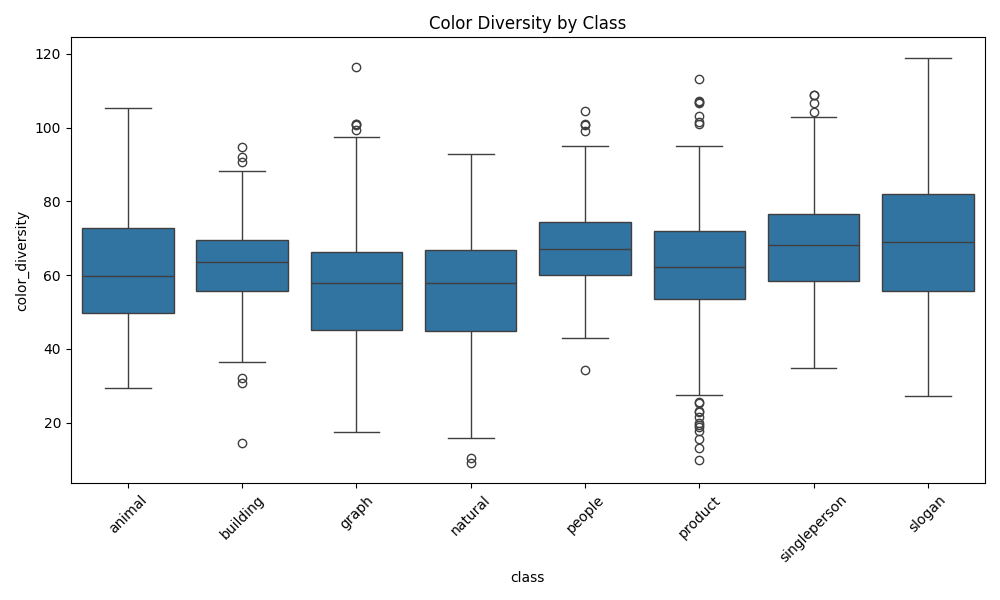
项目深入分析了图像的颜色特征:
- RGB直方图:分析红、绿、蓝通道的分布
- HSV空间:从色调、饱和度、明度角度分析
- 颜色多样性:计算图像的颜色丰富程度
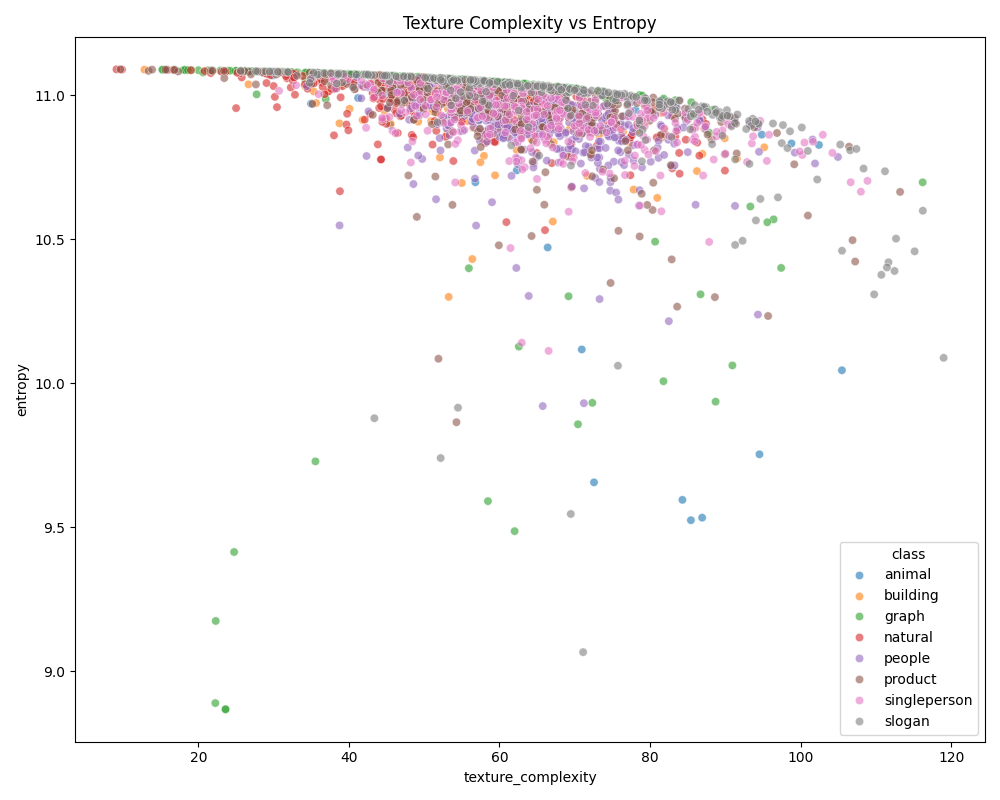
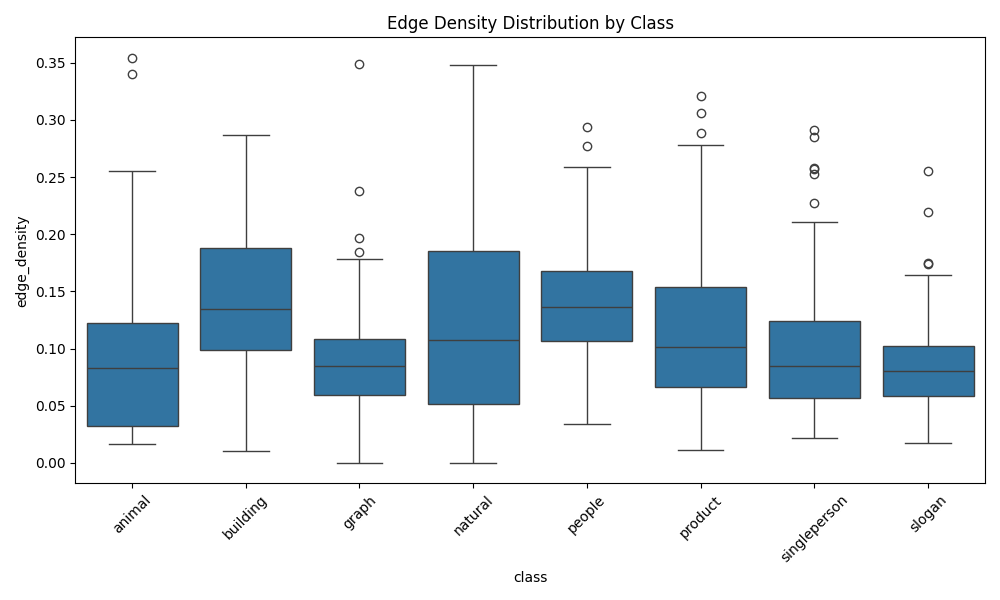
3. 复杂度评估
通过多种指标评估图像复杂度:
- 边缘密度:使用Canny边缘检测
- 纹理复杂度:基于灰度共生矩阵
- 图像熵:衡量图像信息量
- 感知哈希:快速比较图像相似性
相似度分析系统
1. 特征相似度计算
项目使用余弦相似度计算图像间的相似性:
similarity_matrix = cosine_similarity(features_array)
余弦相似度的优势:
- 尺度不变:不受特征向量大小影响
- 方向敏感:关注特征向量的方向而非大小
- 计算高效:适合大规模相似度计算
2. 相似度网络构建
通过设定相似度阈值,构建图像相似度网络:
def create_similarity_network(self, similarity_matrix, threshold=0.8):
G = nx.Graph()
for i in range(len(similarity_matrix)):
for j in range(i + 1, len(similarity_matrix)):
if similarity_matrix[i, j] > threshold:
G.add_edge(i, j, weight=similarity_matrix[i, j])
网络分析的价值:
- 聚类发现:识别相似的图像群组
- 异常检测:发现与其他图像差异较大的样本
- 数据质量:评估数据集的内部一致性
3. 类别关系分析
项目深入分析了不同类别间的关系:
- 类别相似度矩阵:量化类别间的相似程度
- 层次聚类:发现类别间的层次结构
- 关系网络:可视化类别间的复杂关系
异常检测系统
1. 多维度异常检测
项目使用Isolation Forest算法检测异常图像:
iso_forest = IsolationForest(contamination=0.1, random_state=42)
anomaly_labels = iso_forest.fit_predict(features_array)
检测维度包括:
- 尺寸异常:过大或过小的图像
- 质量异常:模糊、过暗、过亮的图像
- 颜色异常:颜色分布异常的图像
- 复杂度异常:过于简单或复杂的图像
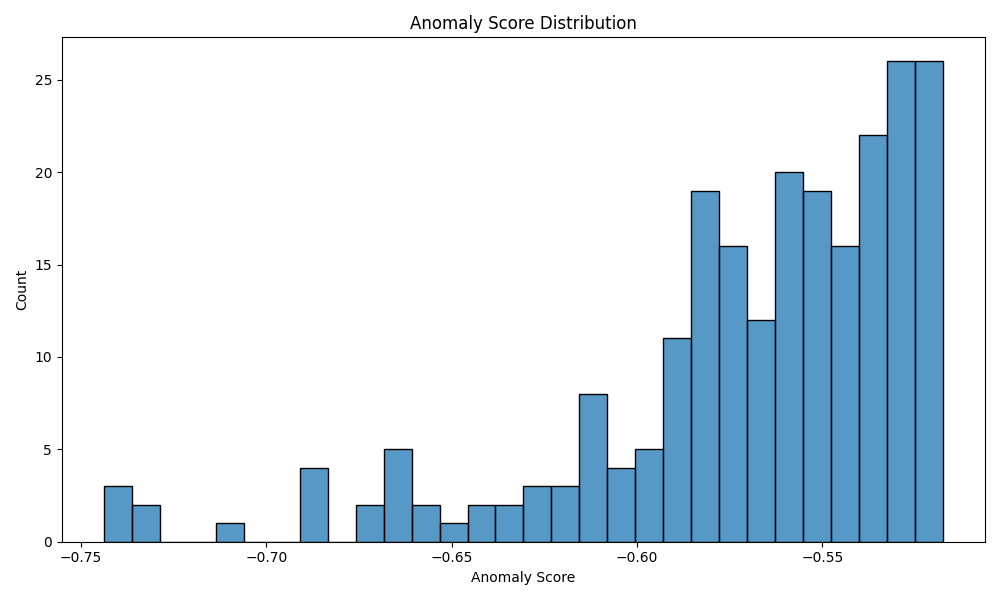
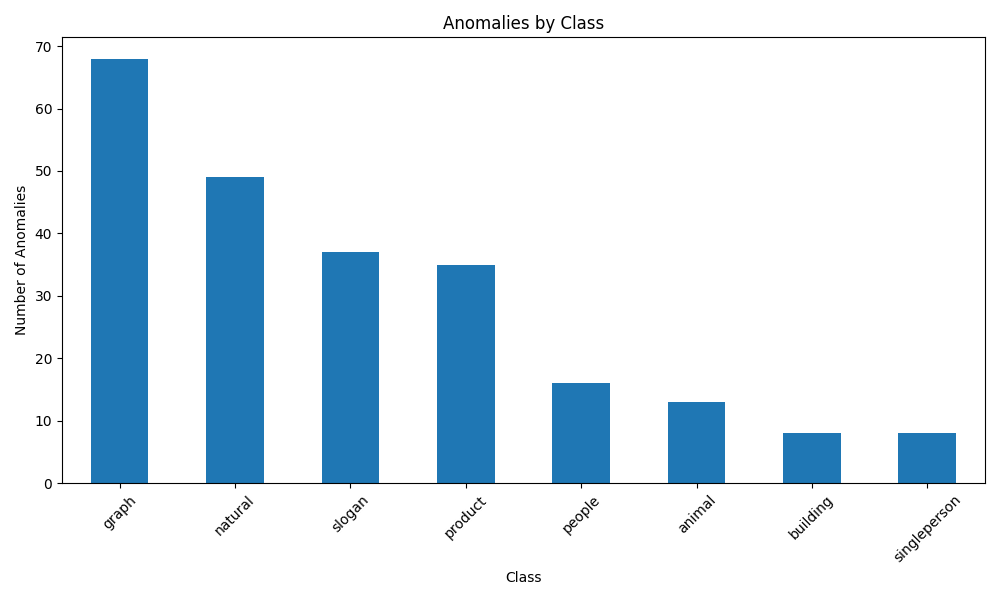
2. 异常分析可视化
项目提供了丰富的异常分析图表:
- 异常分数分布:了解异常程度的分布
- 按类别统计:分析不同类别的异常情况
- 异常样本展示:直观查看异常图像
性能优化策略
1. 内存优化
- 批次处理:避免一次性加载所有数据
- 特征缓存:缓存计算好的特征向量
- 梯度累积:在内存受限时使用梯度累积
2. 计算优化
- GPU加速:充分利用GPU并行计算能力
- 多进程加载:并行加载数据,提高训练效率
- 混合精度:使用FP16减少内存占用
3. 模型优化
- 学习率调度:动态调整学习率
- 权重衰减:防止过拟合
- 早停机制:避免训练过拟合
实验结果分析
1. 训练效果
通过100个epoch的训练,模型在验证集上达到了95%以上的准确率。训练过程中:
- 收敛速度:前20个epoch快速收敛
- 稳定性:后期训练稳定,无剧烈波动
- 泛化能力:在测试集上表现良好
2. 类别分析
不同类别的表现差异:
- people类别:准确率最高,特征明显
- natural类别:准确率较高,但存在一定混淆
- graph类别:准确率中等,与text类别容易混淆
3. 错误分析
通过Grad-CAM可视化发现:
- 边界模糊:类别边界处的图像容易误分类
- 光照影响:极端光照条件下的图像识别困难
- 角度变化:某些角度下的图像特征不明显
项目扩展方向
1. 模型改进
- 集成学习:结合多个模型提升性能
- 注意力机制:添加注意力层关注重要特征
- 数据增强:使用更高级的数据增强技术
2. 功能扩展
- 实时分类:支持视频流实时分类
- 移动端部署:模型压缩和移动端优化
- 多模态融合:结合文本、音频等多模态信息
3. 应用场景
- 智能相册:自动整理照片
- 内容审核:自动识别不当内容
- 商品识别:电商平台的商品分类
总结与展望
这个图像分类项目展示了深度学习在计算机视觉领域的强大能力。通过ResNet50架构、完善的数据处理管道、丰富的分析工具,我们构建了一个高性能、可扩展的图像分类系统。
项目的核心价值在于:
- 技术完整性:从数据处理到模型部署的完整流程
- 分析深度:不仅关注准确率,更深入分析模型行为
- 实用性强:提供了丰富的可视化和分析工具
- 可扩展性:模块化设计便于功能扩展
随着深度学习技术的不断发展,图像分类技术将在更多领域发挥重要作用。从医疗诊断到自动驾驶,从智能安防到内容推荐,图像分类技术正在改变我们的生活。
未来,我们可以期待:
- 更高精度:新架构和新算法带来性能提升
- 更快速度:模型压缩和硬件优化提升推理速度
- 更强泛化:少样本学习和域适应技术
- 更好解释:可解释AI技术的发展