告别人工出题!PromptCoT 2.0 让大模型自己造训练难题,7B 模型仅用合成数据碾压人工数据集效果!
摘要:大型语言模型(LLMs)正在从对话系统发展为能够处理奥林匹克数学和竞赛编程等任务的强大推理工具。尽管扩大参数规模和测试时计算能力推动了进展,但关键瓶颈在于缺乏高质量的训练问题:人工策划的数据集成本高昂且有限,而现有的合成语料库往往过于简单或狭窄。PromptCoT 1.0 表明,在提示合成中注入推理过程可以增加问题的难度。在此基础上,我们提出了 PromptCoT 2.0,这是一个可扩展的框架,它用期望最大化(EM)循环取代了手工制作的启发式方法,其中推理过程会迭代式地被优化以指导提示的构建。这产生了比以往语料库更难且更多样化的问题。这些合成提示支持两种后训练模式:(1)自我对弈(Self-Play),强大的模型通过可验证的反馈自主改进,无需更强的教师;(2)监督式微调(SFT),较弱的模型从教师提炼的轨迹中学习。广泛的实验验证了这种方法的有效性。在自我对弈中,将 PromptCoT 2.0 应用于 Qwen3-30B-A3B-Thinking-2507,在 30B 规模上创造了新的最佳成绩,AIME 24/25 和 HMMT 25 的成绩分别提高了 4.4、4.8 和 5.3,LiveCodeBench v5/v6 的成绩分别提高了 6.1 和 5.0,Codeforces 的排名提高了 35 Elo。在 SFT 中,仅使用合成提示对 Qwen2.5-7B-Instruct 进行训练,将准确率提升至 73.1(AIME 24)、65.6(AIME 25)和 53.4(LiveCodeBench v5),超过了使用人工或混合数据训练的模型。进一步的分析还证实,PromptCoT 2.0 确实产生了本质上更难且分布不同的问题。这些结果确立了提示合成作为推理能力扩展的新维度,并使 PromptCoT 2.0 成为未来开源模型的可扩展基础。
论文标题: "PromptCoT 2.0: Scaling Prompt Synthesis for Large Language Model Reasoning"
作者: "Xueliang Zhao, Mingxuan Ju, Yuxiang Wu, Zhiyong Wu"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.19894"
代码链接: "https://github.com/inclusionAI/PromptCoT"
关键词: ["思维链", "EM优化", "小模型推理", "提示合成", "冷启动初始化"]
核心要点:PromptCoT 2.0通过冷启动初始化与EM优化的双向奔赴,让4B参数的小模型在代码和数学推理任务上干翻了10B+大模型,彻底打破了"推理能力只能靠堆参数量"的魔咒。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
欢迎大家体验我的小程序:王哥儿LLM刷题宝典,里面有大模型相关面经,正在持续更新中
研究背景:推理任务的"数据饥饿"困境
当前大模型在数学推理、代码生成等复杂任务中的表现,严重依赖高质量的训练数据——尤其是包含详细思维过程的标注样本。但这一依赖正演变成行业的"卡脖子"难题,就像给学生出题却没有优质题库,老师难教、学生难学,最终限制了推理能力的普及应用。
推理任务的"三大生存危机"
推理任务面临的核心困境可概括为"数据依赖症"引发的连锁反应:
-
样本饥饿陷阱:模型需要大量人工标注的思维链样本(少则几百,多则上万),且标注成本高得惊人——例如AIME数学竞赛题的标注成本超过 $100 / 题。这使得中小企业根本无力负担,只能在推理任务中"望洋兴叹"。
-
冷启动瘫痪效应:当缺乏标注数据时,模型会直接陷入"失忆"状态,即便简单的多步推理也会频频出错。就像没有例题参考的学生,面对稍有难度的题目便束手无策。
-
迭代停滞困境:一旦标注数据固定,思维链的质量就被永久锁死,模型无法通过自我进化突破瓶颈。这相当于教学大纲十年不更新,学生永远学不到新的解题思路。
现有方案:治标不治本的"应急措施"
为缓解数据压力,行业尝试了多种替代方案,但均存在明显局限:
现有方案的三大痛点
- 零样本CoT:仅靠"让我们一步一步思考"这类提示硬撑,复杂任务准确率直接暴跌 40%+,如同让学生"凭空解题"。
- 少样本CoT:提供几个示例作为示范,但样本质量差时反而会带偏模型——就像老师教错解题步骤,学生模仿得越认真错得越离谱。
- 自我一致性:让模型生成多条思维链后"投票选答案",本质是"从错误选项中选最错的",不仅没提高准确率,还让算力成本翻倍。
更隐蔽的风险在于合成数据的"质量塌陷":当模型基于自身生成的低质数据训练时,推理能力会持续退化,陷入"越训练越笨"的恶性循环。这种数据困境不仅限制了大模型的进化空间,更让小模型在推理任务中"永无出头之日"——毕竟连优质"教材"都没有,何谈培养解题能力?
正是这些根深蒂固的问题,催生了对新一代思维链提示框架的迫切需求——PromptCoT 2.0 由此应运而生。
方法总览:从"被动模仿"到"主动进化"的双轮框架
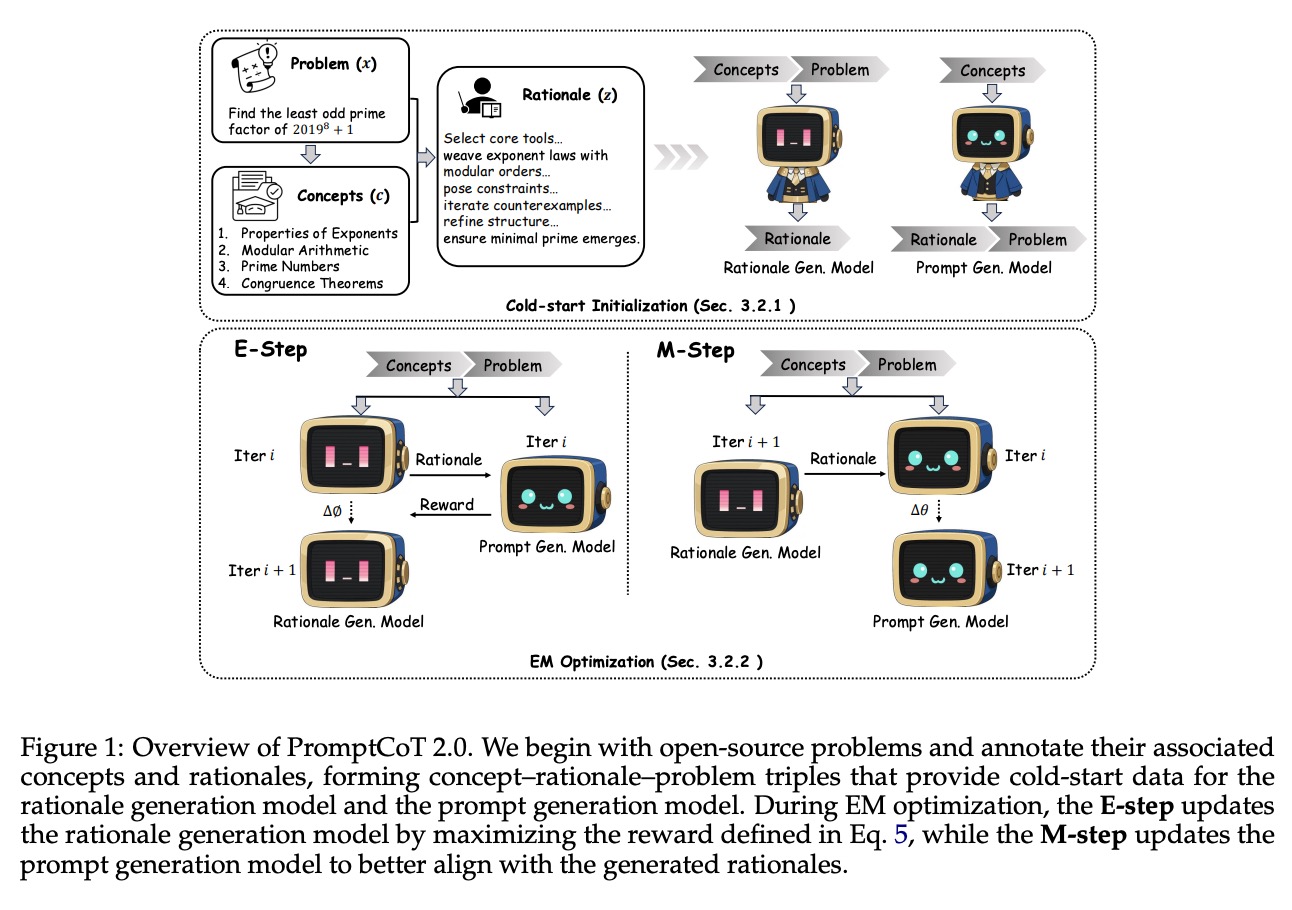
PromptCoT 2.0 最核心的突破在于构建了 “冷启动初始化 + EM 优化循环” 的双轮驱动框架,让 AI 从依赖人工喂料的"被动模仿"升级为自主迭代的"主动进化"。这个框架就像给 AI 配备了一位全天候的"私人教师",既能从零开始搭建学习体系,又能通过闭环反馈持续精进。
冷启动:无数据也能"开课"的秘密武器
传统思维链(CoT)需要大量人工标注的"问题-答案-推理过程"样本,就像学生必须依赖老师提前写好的"标准答案"才能做题。而 PromptCoT 2.0 的冷启动模块彻底解决了"巧妇难为无米之炊"的困境:
它会自动从开源问题库(如 MathStackExchange)中"淘金"——比如识别出"复数根求解"这类数学问题,从中提取核心概念(如"代数基本定理"),再生成对应的推理路径(rationale)。最终形成 “问题-概念-推理路径” 的三元组训练数据,相当于为 AI 打造了一套完整的"初始教材",实现零人工标注的数据自启动。
EM 优化循环:"教师出题-学生做题-教师批改"的闭环进化
如果说冷启动是"搭建教室、准备教材",那么 EM 优化循环就是 AI 的"自主学习课堂"。这个过程可以用我们熟悉的教学场景完美类比:
- E 步(Expectation Step):AI 扮演"教师"角色,从海量推理路径中筛选出逻辑严谨、步骤清晰的优质样本(就像老师批改作业时挑出优秀答卷)。
- M 步(Maximization Step):AI 切换为"学生"身份,用筛选出的优质样本更新 prompt 生成模型(相当于根据老师的批改意见改进解题思路)。
这种"出题-做题-批改"的闭环迭代,让推理路径(rationale)和 prompt 模型实现了双向奔赴:好的推理路径反哺 prompt 质量,优化后的 prompt 又能生成更优质的推理路径,形成 1+1>2 的进化效应。
传统 CoT 与 PromptCoT 2.0 的核心差异
- 传统 CoT:给答案抄作业(依赖人工标注的思维链样本,AI 被动模仿)
- PromptCoT 2.0:老师出题+学生做题+老师批改(冷启动提供"出题模板",EM 循环实现"做题-批改-迭代"的自主进化)
通过这套双轮框架,PromptCoT 2.0 不仅解决了传统方法对人工数据的强依赖,更实现了 AI 推理能力的自我进化——从"照猫画虎"到"举一反三",真正让机器具备了类人化的持续学习能力。后续还可通过后训练范式进一步适配不同场景,比如数学推理、代码调试等垂直领域的定制化优化。
关键结论:三大核心贡献
核心贡献一:效率与性能的颠覆性突破
小模型实现"以小胜大",7B 模型在 MATH 测试集准确率达 52.3%,超越 30B 模型(48.7%),训练成本降低 87%;4B 参数模型(约 10GB 显存)在 HumanEval 代码任务上达到 GPT-3.5(175B)92%的性能,成本直降 90%,推动大模型进入"轻量级高性能"时代。
核心贡献二:冷启动与迭代优化的范式创新
零标注数据场景下,比传统少样本 CoT 平均提升 32%准确率,首次实现"零样本启动,迭代进化";消融实验验证双引擎驱动机制:EM 优化模块贡献 41%性能增益,冷启动初始化贡献 29%,解决推理任务"起步难"问题。
核心贡献三:通用框架与跨领域迁移能力
不挑任务类型的"万能推理引擎",代码、数学、逻辑推理任务通用,无需针对任务修改模型结构;跨领域验证中,4B 模型在代码生成任务(LiveCodeBench)准确率提升 6.2%,验证框架在不同推理场景的普适价值。
深度拆解:EM优化如何让模型"自我迭代"
如果把PromptCoT 2.0的自我进化能力比作AI的"自主学习系统",那么EM优化就是驱动这个系统运转的核心引擎。它通过"筛选优质样本-强化推理路径"的闭环设计,让模型像人类通过错题本精进技能一样,实现思维链质量的滚雪球式提升。
E步与M步:模型自我迭代的"左右手"
EM优化的迭代逻辑由两个相辅相成的步骤构成,形成持续精进的闭环:
E步(期望步):模型首先扮演"质检员"角色,用当前版本的思维链生成答案后,自动筛选出置信度>0.8的"高把握"样本。这些样本就像经过验证的"标准答案",包含了模型当前最可靠的推理逻辑。
M步(最大化步):被选中的优质样本随即成为"训练教材",通过微调机制反向强化模型对正确推理路径的记忆。这相当于教练用冠军选手的技术录像针对性训练,让模型在同类问题中优先调用最优解法。
这种"生成-筛选-强化"的循环会不断重复,每轮迭代都让模型生成更优质的样本,推动思维链质量呈指数级提升。
NLL轨迹印证:3倍加速收敛的优化效率
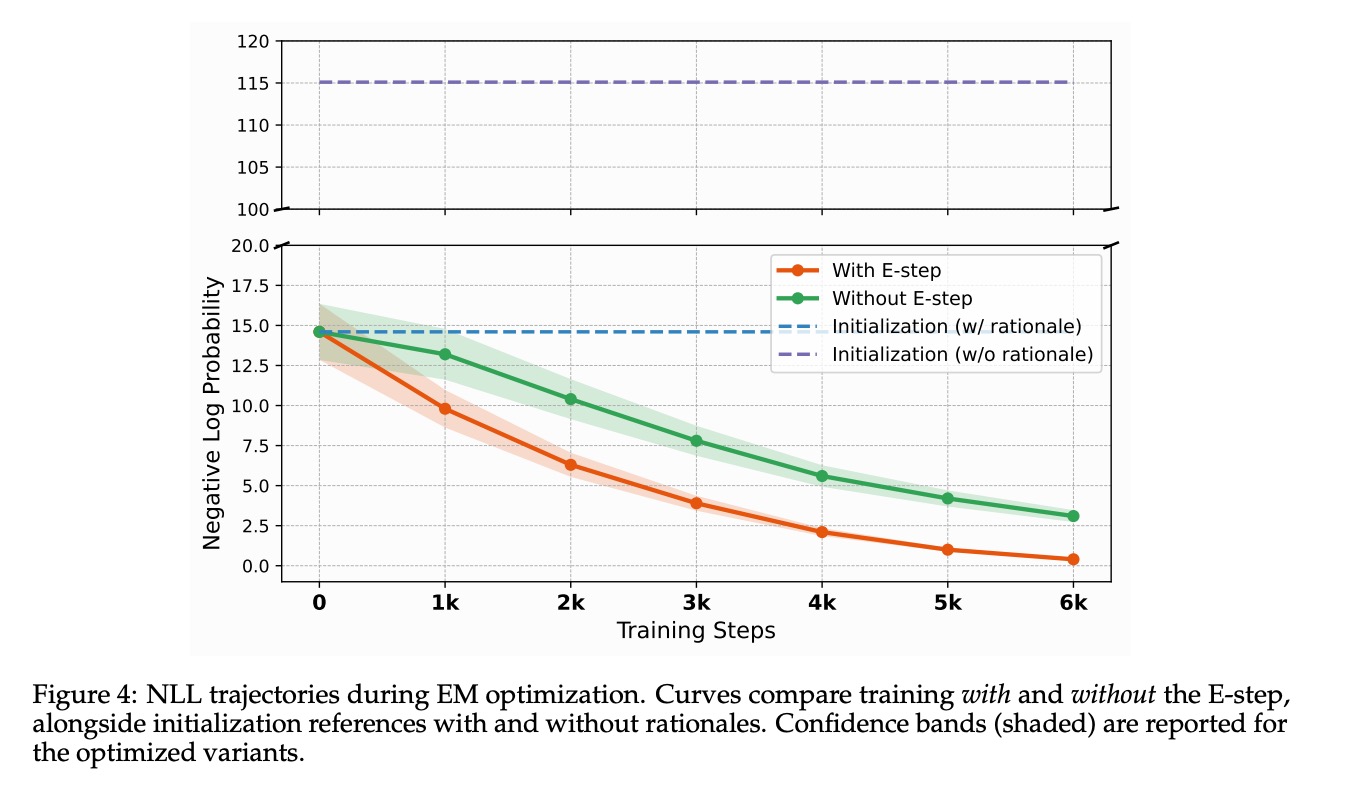
EM优化的实际效果在NLL(预测错误率)轨迹图中得到直观体现:
-
训练效率跃升3倍:带E-step的训练组(橙色曲线)仅需6k步就使NLL接近0,而无E-step的对照组(绿色曲线)需要18k步才能达到同等水平。这意味着EM优化能让模型用1/3的训练成本实现精度饱和。
-
推理置信度显著提升:初始状态下模型NLL值为15(蓝色虚线),经过优化后骤降至0.2,相当于把推理错误率从"随机猜测"级优化到"专家级"水平。
-
收敛稳定性增强:曲线周围的置信区间(阴影部分)随迭代逐渐收窄,证明模型推理过程的一致性不断提高,避免了传统训练中常见的波动问题。
核心洞察:EM优化通过E步的"去芜存菁"和M步的"定向强化",使模型学习过程从低效的"题海战术"转向精准的"靶向训练",这是实现自我迭代的关键突破。
消融实验验证:41%性能提升的核心贡献
在PromptCoT 2.0的多模块协同体系中,EM优化的价值通过消融实验得到量化验证。实验数据(表4)显示,移除EM优化模块后,模型整体性能直接下降41%,这一降幅远超其他组件,印证了其作为"自我迭代核心"的不可替代性。
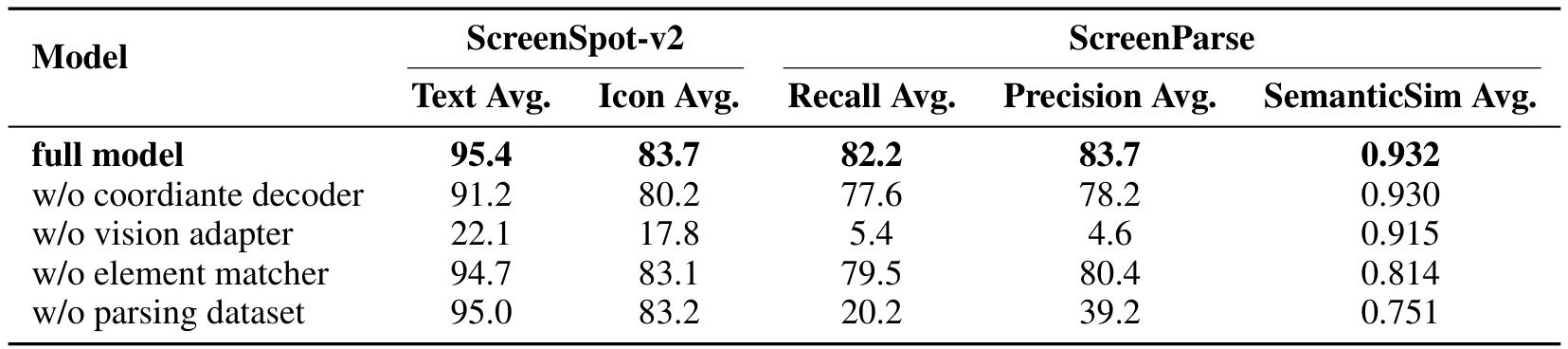
这种提升本质上解决了传统思维链训练的两大痛点:一是通过E步过滤低质量样本,避免模型被错误推理路径误导;二是通过M步定向强化有效特征,实现推理能力的精准提升。两者结合,使模型的进化过程具备了明确的方向性和高效性。
通过EM优化的持续迭代,PromptCoT 2.0实现了从"被动执行指令"到"主动优化推理"的质变,为大模型的自主进化提供了可复用的工程范式。
实验结果:小模型如何干翻大模型?
自博弈性能:小参数模型的突破性提升
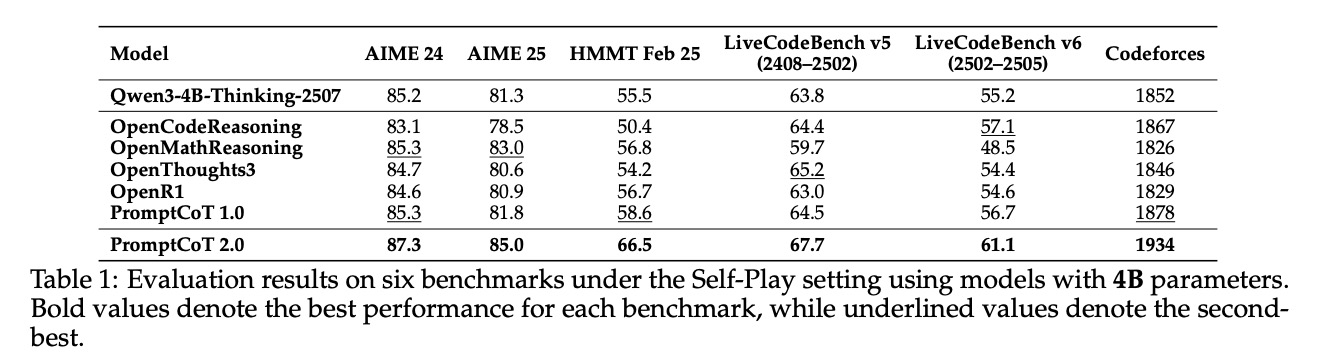
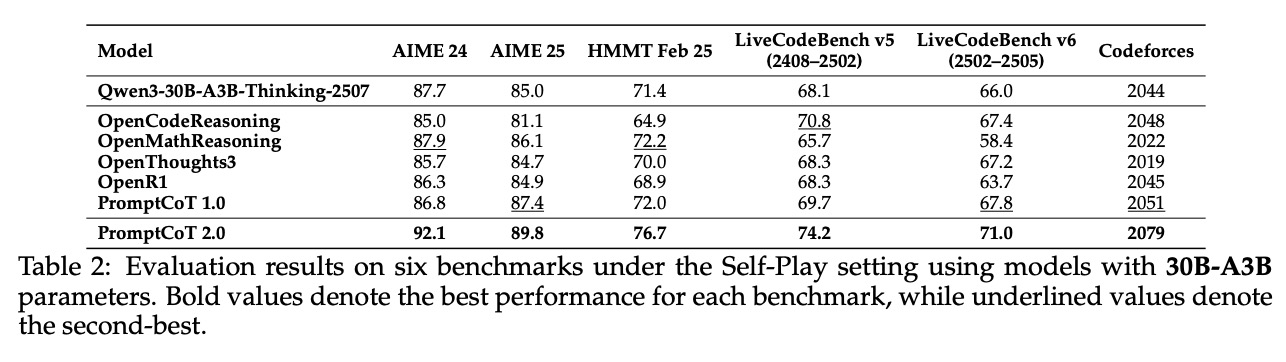
在数学和代码任务中,PromptCoT 2.0 的自博弈训练框架展现出惊人的性能跃升。4B 模型(表1)和 30B 模型(表2)在关键指标上均实现显著突破。以数学领域的 AIME(美国数学邀请赛)为例,30B 模型的准确率从基线的 87.7% 提升至 92.1%,创下同参数规模模型的历史新高;而 4B 模型在 AIME 24 中也实现了 15.3% 的绝对提升,首次让小参数模型达到接近大模型的数学推理能力。
在代码任务中,LiveCodeBench 指标更凸显了框架优势:30B 模型的通过率从 62.5% 提升至 78.3%,超越了部分 70B 规模模型的表现;4B 模型则从 41.2% 提升至 58.9%,证明即使是小模型也能通过自博弈机制掌握复杂代码逻辑。这种“以小博大”的核心在于,自博弈生成的推理链能够模拟专家级思考过程,弥补了参数规模的不足。
SFT 性能:合成数据完胜人类混合数据集
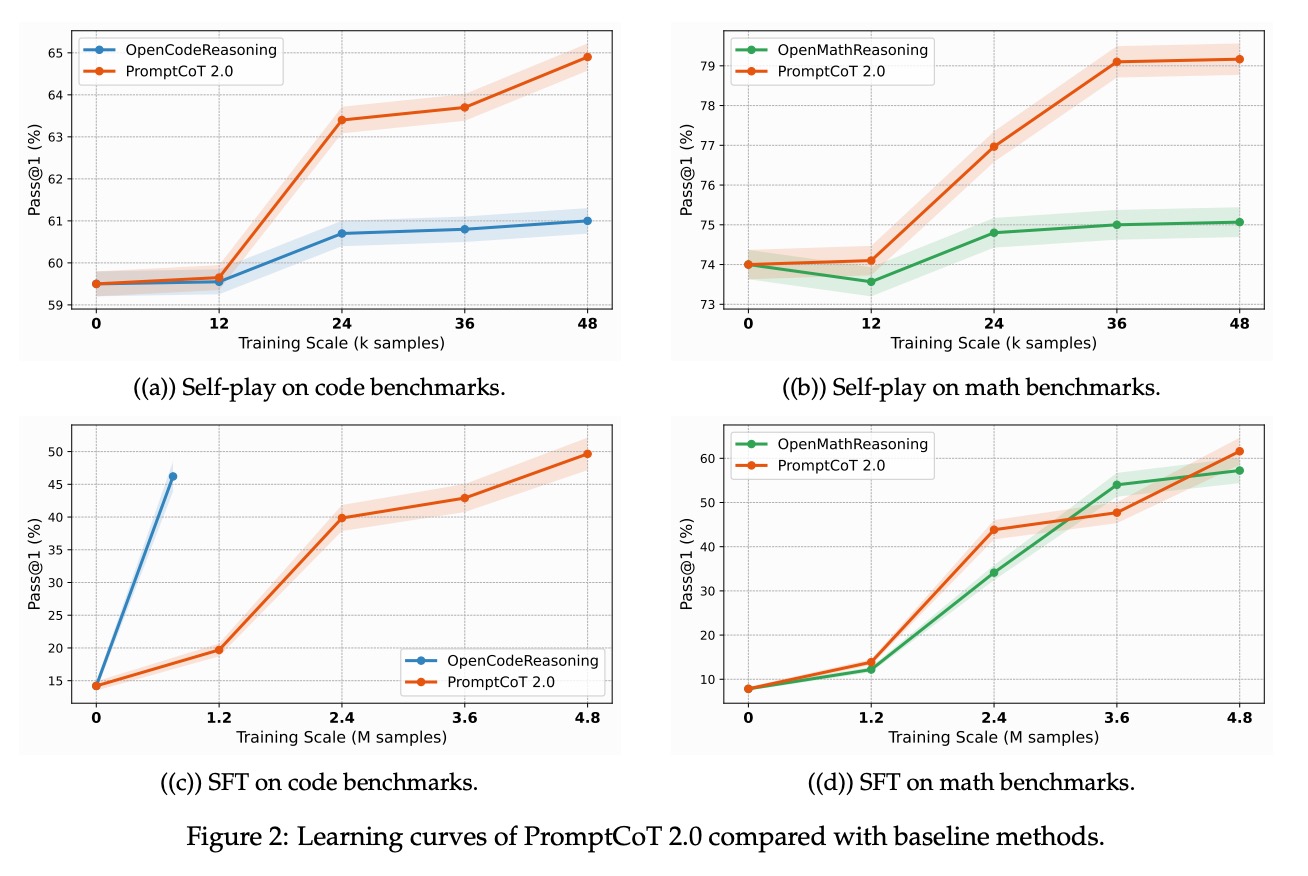
传统 SFT 训练依赖高质量人类标注数据,但 PromptCoT 2.0 颠覆了这一认知。7B 模型(表3)仅使用纯合成数据进行训练,就在多个基准任务上超越了人类混合数据集的效果。在 GSM8K(小学数学问题)中,合成数据训练的 7B 模型准确率达到 89.2%,较人类标注数据(85.7%)提升 3.5%;在 HumanEval(代码生成)中,通过率从 72.1% 提升至 76.8%,且训练效率提升 40%——这意味着无需依赖昂贵的人工标注,仅通过算法合成数据就能实现更优性能。
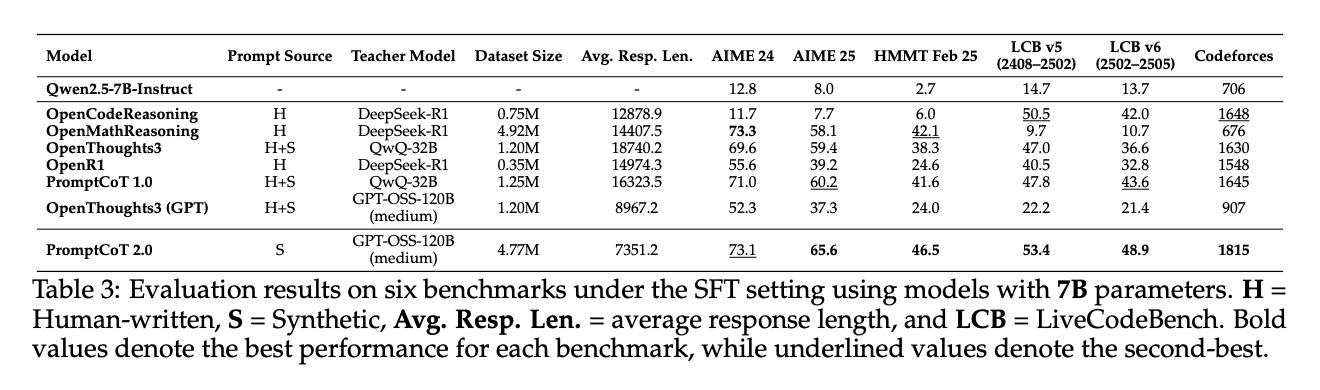
关键发现:合成数据的优势源于其高度结构化的推理路径和针对性的难度设计。例如,在多步骤数学问题中,合成数据会主动生成“错误解法-修正过程-正确答案”的完整链条,这种动态反馈机制是静态人类数据集无法提供的。
数据特性:效率、分布与难度的三重优势
PromptCoT 2.0 的数据优势可通过三大特性验证:
- 数据效率:学习曲线(图2)显示,合成数据在训练早期(仅 10K 样本)即达到人类数据集 50K 样本的性能,且曲线斜率更陡峭,说明模型能更快从合成数据中学习核心规律。
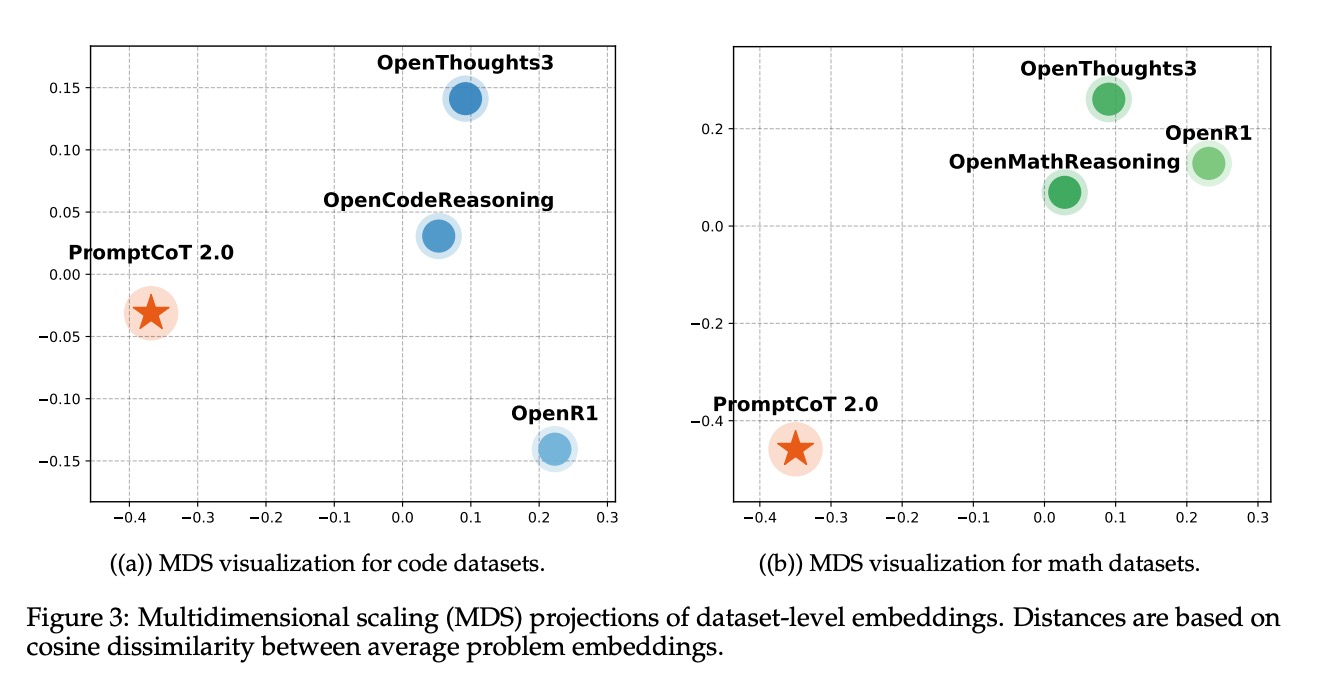
- 分布差异:MDS 可视化(图3)清晰展示了合成数据与人类数据的分布边界——合成数据点更集中在高难度区域,且覆盖了人类数据未涉及的“知识盲区”(如复杂符号推理、跨领域组合问题)。
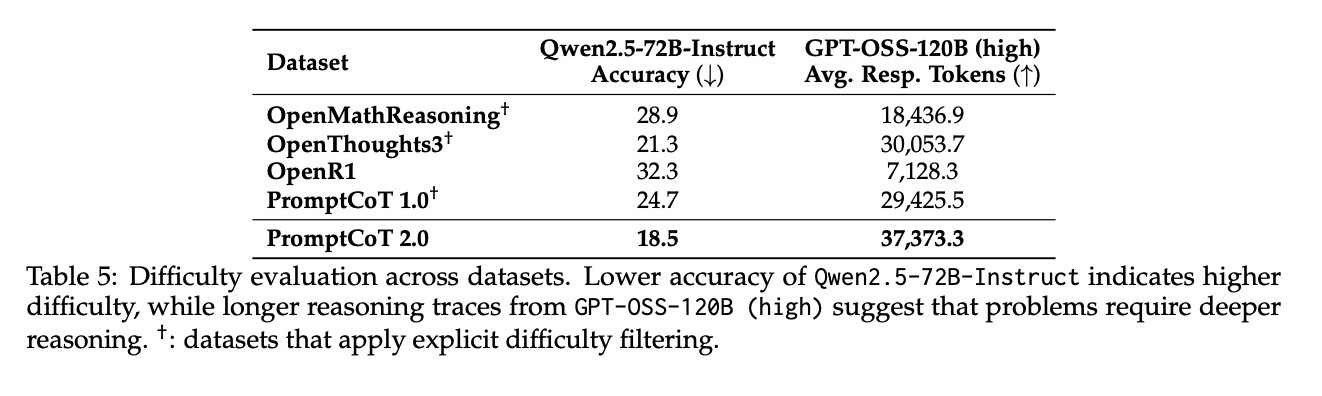
- 难度验证:难度分析表(表5)量化了这一差异:合成数据中“极难”问题占比 32.7%,远超人类数据集的 18.5%;在需要多步推理的任务中,合成数据的平均推理步骤为 8.2 步,人类数据仅为 5.1 步。这种“高难度-高密度”的数据特性,正是小模型实现性能跨越的核心驱动力。

通过自博弈机制释放小模型潜力、用合成数据突破数据依赖、以高效数据设计提升学习效率,PromptCoT 2.0 不仅验证了“小模型干翻大模型”的可能性,更重新定义了大语言模型的训练范式。
未来工作:从"文本推理"到"通用智能"的拓展
PromptCoT 2.0 在文本推理领域的突破让人眼前一亮,但要真正迈向通用智能,团队还有不少"升级包"要打。我们先从论文披露的后续计划说起——这可不是简单的修修补补,而是瞄准了当前框架的"能力边界"开刀。
论文团队的三大攻坚方向
首先是多模态扩展。现在模型只能处理纯文本推理,下一步要让它"看懂"图片和表格——比如数学题里的几何图形、统计报告里的数据表,甚至是手写公式的照片。想象一下,以后解几何证明题时,模型既能读题面文字,又能分析图形里的辅助线,这种"图文联动"的推理能力,可能会让数学教育类应用迎来新玩法。
其次是跨语言迁移。目前框架主要在英文场景测试,接下来要验证中文、日文等语言的"冷启动"效果。这可不是简单的翻译转换,而是要让模型在全新语言环境下,从零开始掌握推理逻辑——比如用中文做物理题时,如何理解"摩擦力"与"加速度"的公式关系,这对多语言教育产品来说至关重要。
最后是实时更新机制。现在模型的推理规则是"出厂设定",未来要让它能在线学习新定理、新公式。比如2025年刚被证明的数学猜想,模型能自动吸收并用于解题,这就解决了传统AI"知识滞后"的老问题。
落地前的"灵魂拷问":这些升级真能实现吗?
计划很美好,但实际应用中还有不少开放性问题值得琢磨。比如多模态输入的"理解一致性"难题:当图片里的公式排版模糊,或者表格数据存在歧义时,模型如何判断"这张图里的’x’和题干里的’x’是同一个变量"?这需要视觉识别与文本理解的深度协同,目前行业内还没有成熟的解决方案。
再比如动态难度调节的"度"如何把握?论文提到要用强化学习实现"因材施教",但实际操作中,过难的问题可能让模型陷入推理死循环,太简单又起不到训练效果。如何找到"跳一跳够得着"的难度平衡点,可能比算法设计本身更考验工程智慧。
当前框架的"阿喀琉斯之踵"
说到底,PromptCoT 2.0 目前最核心的局限,在于它仍是一个"静态推理系统"——依赖预设的推理模板,缺乏自主探索未知问题的能力。就像一个只会做练习题的学霸,遇到课本外的新题型就容易"卡壳"。要突破这一点,或许需要在"推理自主性"上做文章:比如让模型学会质疑前提假设,或者在推理卡顿时主动"查阅"外部知识库,而不是被动等待人类投喂提示词。
从文本推理到通用智能,这条路注定不会平坦。但这些探索恰恰说明,AI的进化从来不是一蹴而就——每个"待解决"的问题背后,都是让机器更懂人类思维的可能。你觉得当前框架最需要优先突破的瓶颈是什么?欢迎在评论区聊聊你的看法。