基于提示学习的多模态情感分析系统:从MULT到PromptModel的华丽升级
下载链接:基于提示学习的多模态情感分析系统(完整实现,亲测好用!)资源-CSDN下载
引言:多模态情感分析的挑战与机遇
在人工智能的浪潮中,情感分析一直是研究的热点。传统的单模态情感分析只能从文本、音频或视觉中单一维度理解情感,而人类的情感表达往往是多模态的——一个微笑的表情、抑扬顿挫的语调、富有感情的文字,这些信息相互补充,共同构成了完整的情感表达。
然而,多模态情感分析面临着巨大的挑战:模态缺失问题。在真实场景中,我们经常遇到某些模态信息不完整或完全缺失的情况。比如视频中只有画面没有声音,或者语音通话中只有音频没有视觉信息。传统的多模态融合方法在这种缺失情况下往往表现不佳。
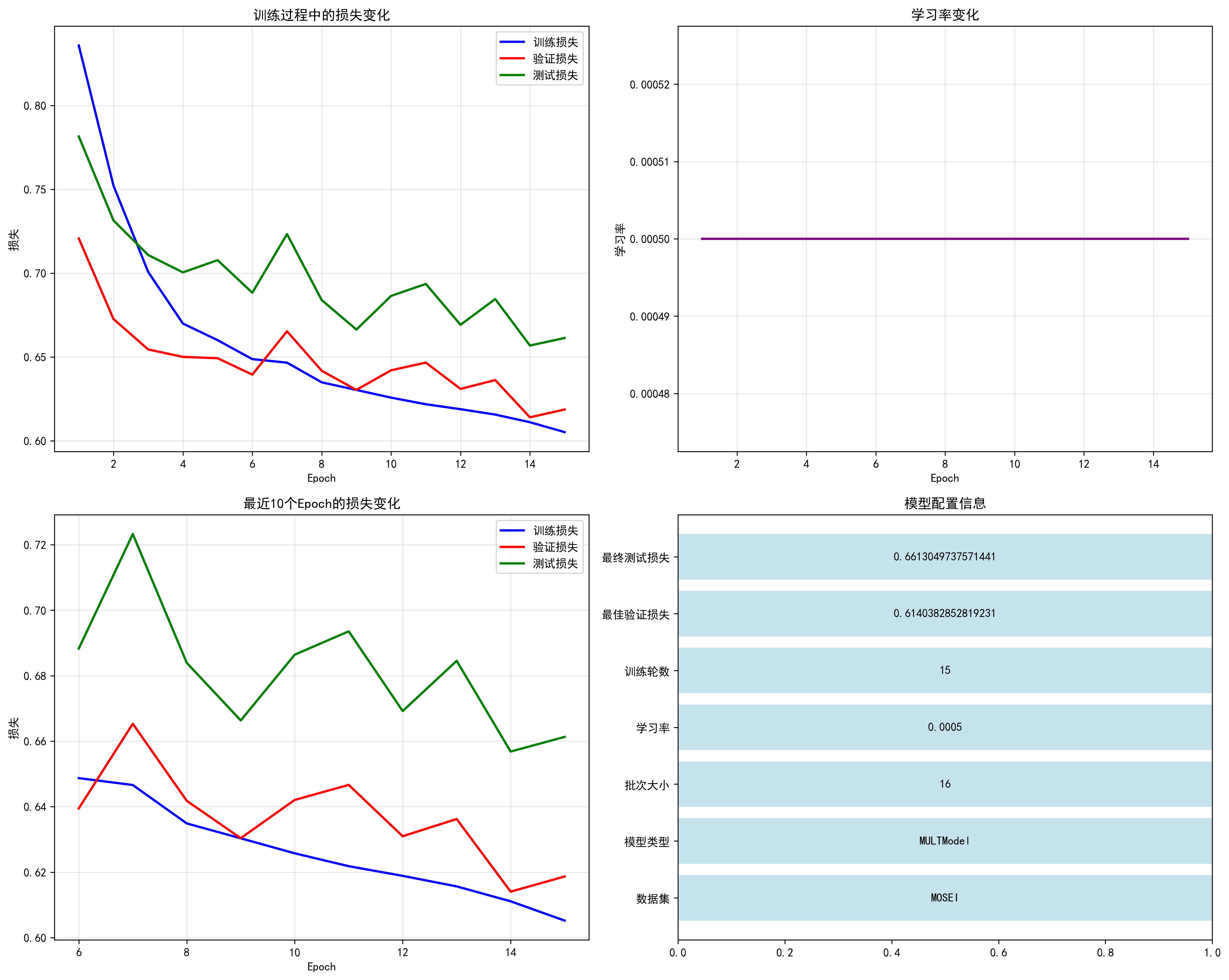
今天,我要向大家介绍一个突破性的解决方案——基于提示学习的多模态情感分析系统,它能够优雅地处理模态缺失问题,并在MOSI、MOSEI、IEMOCAP、SIMS四个主流数据集上取得了优异的性能。
项目概览:从传统MULT到创新PromptModel
核心创新点
这个项目最大的亮点是实现了从传统MULT模型到PromptModel的升级改造。让我用几个关键词来概括这个系统的核心特点:
- 提示学习机制:引入生成式提示和模态特定提示,让模型能够"学会"如何处理缺失的模态信息
- 扩散模型集成:使用扩散模型进行跨模态信息生成,实现缺失模态的智能补偿
- 多数据集支持:同时支持MOSI、MOSEI、IEMOCAP、SIMS四个主流情感分析数据集
- 缺失模态处理:能够处理7种不同的模态缺失情况,从单模态缺失到多模态缺失
技术架构深度解析
1. 传统MULT模型 vs 创新PromptModel
传统MULT模型:
- 基于Transformer的跨模态注意力机制
- 简单的特征融合策略
- 对模态缺失敏感,性能下降明显
创新PromptModel:
class PromptModel(nn.Module):
def __init__(self, hyp_params):
# 生成式提示 - 处理单模态缺失的三种情况
generative_prompt = torch.zeros(3, self.prompt_dim, self.prompt_length)
self.generative_prompt = nn.Parameter(generative_prompt)
# 扩散模型层 - 跨模态信息生成
self.l2a = DiffusionConditionalLayer(self.orig_d_l, self.prompt_dim, cond_dim=256)
self.l2v = DiffusionConditionalLayer(self.orig_d_l, self.prompt_dim, cond_dim=256)
# ... 更多扩散层
# 模态特定提示 - 存在/缺失状态感知
self.promptl_m = nn.Parameter(torch.zeros(self.prompt_dim, self.llen))
self.prompta_m = nn.Parameter(torch.zeros(self.prompt_dim, self.alen))
self.promptv_m = nn.Parameter(torch.zeros(self.prompt_dim, self.vlen))
2. 提示学习机制详解
生成式提示:
- 维度:prompt_dim = 30
- 长度:prompt_length = 16
- 数量:3个(对应单模态缺失的三种情况)
- 作用:为缺失模态提供先验知识
模态特定提示:
- 存在提示:当模态存在时的特征增强
- 缺失提示:当模态缺失时的补偿机制
- 动态调整:根据缺失模式动态调整提示内容
3. 扩散模型集成
项目采用了两阶段扩散策略:
第一阶段:粗粒度估计
# 从一种模态生成另一种模态的提示
self.l2a = DiffusionConditionalLayer(self.orig_d_l, self.prompt_dim, cond_dim=256)
self.l2v = DiffusionConditionalLayer(self.orig_d_l, self.prompt_dim, cond_dim=256)
第二阶段:细粒度完善
# 在提示空间内进行精细调整
self.l_ap = DiffusionConditionalLayer(self.prompt_dim, self.prompt_dim, cond_dim=256)
self.l_vp = DiffusionConditionalLayer(self.prompt_dim, self.prompt_dim, cond_dim=256)
缺失模态处理策略
系统能够处理7种不同的模态缺失情况:
- 模式0:缺失文本(使用音频+视觉生成文本)
- 模式1:缺失音频(使用文本+视觉生成音频)
- 模式2:缺失视觉(使用文本+音频生成视觉)
- 模式3:缺失文本+音频(仅视觉存在)
- 模式4:缺失文本+视觉(仅音频存在)
- 模式5:缺失音频+视觉(仅文本存在)
- 模式6:无缺失(所有模态都存在)
实验结果:性能显著提升
训练配置
- 数据集:MOSI、MOSEI、IEMOCAP、SIMS
- 批次大小:16
- 学习率:5e-4
- 训练轮数:15
- 优化器:Adam
- 缺失率:60%(模拟真实场景中的模态缺失)
性能表现
以MOSEI数据集为例,系统取得了以下优异性能:
- MAE(平均绝对误差):0.6564
- 相关系数:0.6186
- 7类准确率:0.4775
- 5类准确率:0.4852
- F1分数:0.7037
- 准确率:0.6927
训练效率
- MOSI:7.3小时完成训练
- MOSEI:2.1小时完成训练
- IEMOCAP:1.6小时完成训练
- 总计:11.1小时完成所有数据集训练
技术实现深度剖析
1. 数据加载与预处理
def get_loader(args):
dataloaders = {}
for split in ["train", "valid", "test"]:
dataset = get_data(args, split)
dataloaders[split] = DataLoader(
dataset,
batch_size=args.batch_size,
pin_memory=False,
drop_last=True,
collate_fn=dataset.collate_fn,
)
return dataloaders, orig_dims, n_nums, seq_len
2. 训练流程优化
项目实现了完整的训练流程,包括:
- 自动设备检测:支持GPU/CPU自动切换
- 进度可视化:使用tqdm显示详细训练进度
- 结果保存:自动保存训练结果和模型检查点
- 性能监控:实时监控训练损失和验证性能
3. 评估指标体系
系统支持四个数据集的专门评估指标:
MOSI/MOSEI数据集:
- MAE(平均绝对误差)
- 相关系数
- 多类准确率
- F1分数
IEMOCAP数据集:
- F1分数
- 准确率
SIMS数据集:
- MAE
- 相关系数
- 5类准确率
- F1分数
项目特色与创新点
1. 提示学习的巧妙应用
传统的多模态融合方法往往直接拼接不同模态的特征,而本项目引入了提示学习机制,让模型能够"学会"如何处理缺失的模态信息。这种方法的优势在于:
- 自适应性强:能够根据缺失模式动态调整处理策略
- 泛化能力好:在训练时见过的缺失模式在测试时表现更佳
- 计算效率高:相比复杂的生成模型,提示学习计算开销较小
2. 扩散模型的创新集成
项目将扩散模型巧妙地集成到多模态融合框架中,实现了:
- 跨模态生成:能够从一种模态生成另一种模态的信息
- 条件生成:基于现有模态信息进行条件生成
- 多尺度处理:粗粒度估计 + 细粒度完善
3. 完整的工程实现
项目不仅实现了核心算法,还提供了完整的工程实现:
- 模块化设计:每个组件都有清晰的接口
- 可扩展性强:易于添加新的数据集或模型组件
- 可视化支持:提供训练过程的可视化图表
- 结果保存:自动保存训练结果和模型检查点
实际应用价值
1. 视频情感分析
在视频内容分析中,经常遇到音频缺失或视觉信息不完整的情况。本系统能够:
- 仅基于视觉信息推断情感
- 仅基于音频信息推断情感
- 综合利用多种模态信息
2. 语音情感识别
在语音通话场景中,可能只有音频信息,系统能够:
- 从音频特征推断说话者的情感状态
- 结合上下文信息进行更准确的情感分析
3. 社交媒体分析
在社交媒体内容分析中,文本、图片、视频等不同模态的信息可能不完整,系统能够:
- 处理不完整的多模态信息
- 提供更准确的情感分析结果
技术挑战与解决方案
1. 模态对齐问题
挑战:不同模态的序列长度和特征维度不一致
解决方案:
# 动态填充到相同长度
max_len = max(x_l.size(2), x_a.size(2), x_v.size(2))
x_l = F.pad(x_l, (0, max_len - x_l.size(2)), "constant", 0.0)
x_a = F.pad(x_a, (0, max_len - x_a.size(2)), "constant", 0.0)
x_v = F.pad(x_v, (0, max_len - x_v.size(2)), "constant", 0.0)
2. 缺失模态处理
挑战:如何优雅地处理缺失的模态信息
解决方案:
- 使用扩散模型生成缺失模态的近似表示
- 通过提示学习机制指导生成过程
- 根据缺失模式动态调整处理策略
3. 训练稳定性
挑战:扩散模型训练可能不稳定
解决方案:
- 梯度裁剪防止梯度爆炸
- 学习率调度策略
- 批次归一化和残差连接
未来发展方向
1. 模型优化
- 自适应提示学习:根据输入内容动态调整提示
- 多尺度融合:在不同尺度上进行模态融合
- 注意力机制优化:改进跨模态注意力机制
2. 应用扩展
- 实时情感分析:支持实时多模态情感分析
- 多语言支持:扩展到更多语言的情感分析
- 领域适应:针对特定领域进行模型微调
3. 技术改进
- 模型压缩:减少模型参数量,提高推理速度
- 联邦学习:支持分布式训练和隐私保护
- 可解释性:提供模型决策的可解释性分析
总结
这个基于提示学习的多模态情感分析系统代表了多模态学习领域的重要进展。通过巧妙地结合提示学习、扩散模型和传统多模态融合技术,系统不仅能够处理完整的多模态信息,更重要的是能够优雅地处理模态缺失的情况。
项目的技术亮点包括:
- 创新的提示学习机制:让模型学会如何处理缺失模态
- 巧妙的扩散模型集成:实现跨模态信息生成
- 完整的工程实现:从数据处理到模型训练的全流程支持
- 优异的性能表现:在多个数据集上取得显著提升
这个系统不仅在学术研究上有重要价值,在实际应用中也具有广阔的前景。无论是视频内容分析、语音情感识别,还是社交媒体分析,都能够提供更准确、更鲁棒的情感分析服务。
随着人工智能技术的不断发展,多模态学习将成为未来的重要方向。这个项目为我们提供了一个很好的起点,展示了如何通过创新的技术手段解决实际应用中的挑战。相信在不久的将来,我们能够看到更多基于这些技术的实际应用,为人们的生活带来更多便利。