从零起步学习Redis || 第六章:Redis单线程模式的实现详解

切入点:
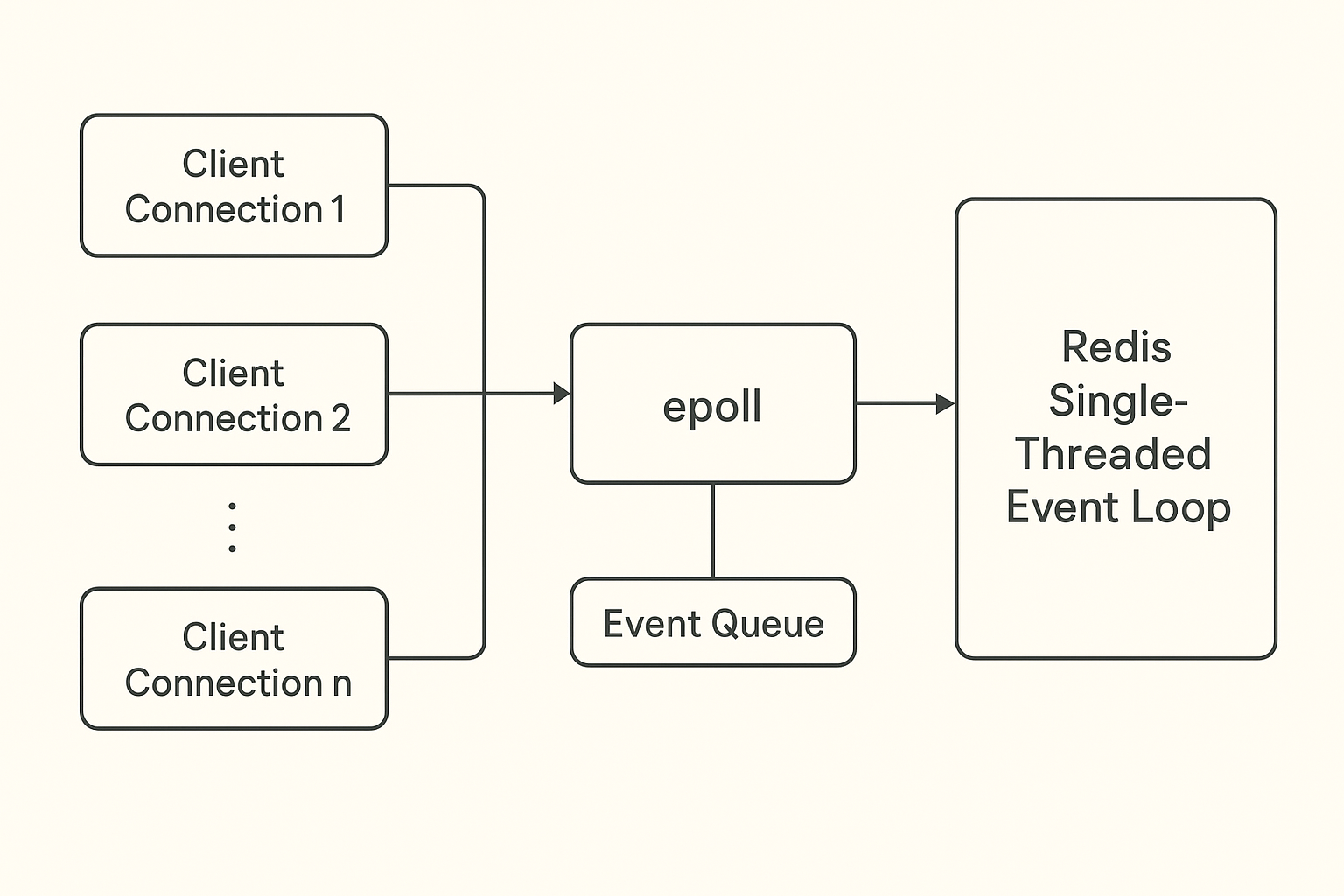
Redis 的核心是 基于事件驱动的单线程模型,它通过 I/O 多路复用(epoll/kqueue/Select) 来管理所有客户端的请求。
流程大概是这样的:
客户端请求来了(比如
SET key value)。Redis 的 事件循环 把请求放入队列。
单线程顺序地从队列里取出请求,执行对应的命令(读写内存、更新数据结构)。
把结果返回给客户端。
因为 Redis 的操作都是 内存级别 的,速度极快,加上单线程避免了多线程并发的上下文切换、加锁开销,所以性能很高。
核心机制:I/O 多路复用和事件循环
如果 Redis 是单线程的,那它怎么同时处理成千上万个客户端连接呢?
如果用「一线程一连接」就会死掉,因为线程上下文切换、内存开销太大。
Redis 的解法是:一个线程,管理多个连接 → 靠 I/O 多路复用。
I/O 多路复用的思想
你可以把它想象成:
服务员(Redis 单线程) → 只有一个。
客人(客户端连接) → 可以有几万个。
服务员不可能一直守着某个客人等点单,所以用一个「呼叫器系统」(多路复用机制:
select、epoll、kqueue)。哪个客人需要点单(有事件),呼叫器就告诉服务员「这个桌子有人举手了」。
这样,一个线程就能监听很多连接。
Redis 的事件循环流程
Redis 内部有一个 事件循环(event loop),大体是这样的:
调用
epoll_wait(Linux)等待事件。如果有客户端发送请求(可读事件),就返回「哪个连接有数据」。
如果有客户端可以发送结果(可写事件),也会返回。
事件循环把这些事件放到一个队列里。
Redis 单线程依次处理这些事件:
解析客户端请求。
执行命令(对内存数据结构进行操作)。
把结果写回客户端。
处理完一批事件后,再回到
epoll_wait→ 等下一批事件
epoll是什么?
基本概念
epoll 是 Linux 提供的一种 I/O 多路复用机制,用来同时高效地监听大量文件描述符(比如 socket 连接)。
换句话说:
传统模型:一个线程处理一个连接(线程数爆炸 → 性能差)。
epoll 模型:一个线程用 epoll 监听成千上万个连接,只在有事件时才处理。
epoll 工作方式
可以分为三步:
注册事件:把要监听的 socket(客户端连接)交给 epoll,比如「这个连接可读的时候告诉我」。
等待事件:调用
epoll_wait()阻塞等待,直到有事件发生。返回事件:只返回那些「真的发生了事件」的连接,线程直接处理它们就好。
socket 的本质
socket 就是一个“通信端点”。
可以把它理解成 网络中的门口/插口:
进程要想和别的进程(可能在另一台机器)通信,得先“开个门口”。
这个门口就是 socket。
socket 工作流程
一次客户端—服务器通信,大体是这样:
服务器先在本地开一个 socket(监听端口,比如 6379 就是 Redis 的默认端口)。
客户端也开一个 socket,然后向服务器的 IP + 端口发起请求。
内核给它们牵线搭桥,两个 socket 建立连接。
以后客户端和服务器就是通过这对 socket 来 收发数据。
所以你可以把 socket 看成是 读写网络的文件描述符。
在 Linux 里,socket 甚至就是一种特殊的文件,读写它和操作文件一样。
易错点辨析:端口与socket的关系
1. 端口是什么?
端口(port)就像一栋楼里的房间号。
一台机器上可以同时跑很多服务(HTTP 80,MySQL 3306,Redis 6379)。
端口号用来区分「同一台电脑里的不同服务」。
2. socket 是什么?
socket 是通信的端点,就像插座:插上去就能通信。
在 TCP 里,一个 socket 是由 (IP 地址, 端口号) 组成的。
客户端和服务器建立连接时,其实就是在两端各创建一个 socket,然后把它们连起来。
3. 两者的关系
你可以这么记:
端口号:只是号码(告诉操作系统「数据要交给谁」)。
socket:是操作系统里真正用来收发数据的对象。
也就是说:
端口号 = 地址上的「门牌号」。
socket = 门口的「门+对讲机」,真正能收发信息。
举个 Redis 的例子:
Redis 默认监听 6379 端口。
当你用客户端连接 Redis 时:
服务器这边创建一个 socket 绑定在
(服务器IP, 6379)上。客户端也有自己的 socket,比如
(你的IP, 随机端口号)。两个 socket 建立 TCP 连接,数据就能传输。