AI驱动的软件质量保障:未来已来
在软件工程飞速迭代的今天,传统的软件测试方法正面临前所未有的挑战。业务逻辑日益复杂、应用形态(Web、移动端、小程序、IoT)层出不穷、发布周期从“月”缩短到“天”甚至“小时”。在这样的背景下,单纯依靠人力进行测试,不仅效率低下、成本高昂,更难以覆盖所有场景,导致线上缺陷频发。
人工智能(AI)的崛起,为软件测试领域带来了革命性的曙光。AI不再是遥不可及的概念,而是已经深度融入测试流程的强大工具。它将测试从“劳动密集型”推向“智力密集型”,实现了测试的自动化、智能化和前瞻性。本文将深入探讨AI在测试领域的三大核心应用:AI驱动的自动化测试框架、智能缺陷检测和A/B测试优化,并结合代码、流程图和实际案例,揭示其背后的技术原理与实践价值。
一、 AI驱动的自动化测试框架:会“思考”的测试机器人
传统的自动化测试框架(如Selenium, Cypress, Playwright)极大地提升了回归测试的效率,但它们本质上是“死板”的。测试脚本严重依赖稳定的页面元素定位器(ID, CSS Selector, XPath)。一旦前端代码重构、UI组件库升级,哪怕只是修改了一个元素的class名,都可能导致大量测试脚本失效,维护成本极高。
AI驱动的自动化测试框架旨在解决这一“脆弱性”问题,它赋予了测试脚本自我修复和智能决策的能力。
1.1 核心能力:自愈与智能元素定位
自愈是AI自动化框架最核心的能力。当脚本因元素无法找到而失败时,AI引擎不会立即报错,而是启动“自愈”流程:
- 分析上下文:AI会分析失败步骤周围的DOM结构、文本内容、元素属性(如
aria-label,placeholder)等。 - 多策略定位:它会尝试多种定位策略,例如:
- 如果
id找不到,就尝试class名。 - 如果
class名变了,就尝试根据元素上的文本内容(如“登录”按钮)进行定位。 - 如果文本是动态的,就尝试通过其相对于其他稳定元素的位置关系(如“密码输入框右边的按钮”)来定位。
- 如果
- 机器学习模型:更先进的框架会利用预训练的机器学习模型,该模型学习过大量网页的结构。它能像人一样“理解”页面布局,即使元素属性发生变化,也能根据视觉相似性和语义信息,高概率地找到目标元素。
- 学习与固化:一旦AI成功找到替代定位器,它可以将这个新的、更鲁棒的定位策略记录下来,用于未来的测试,实现持续学习。
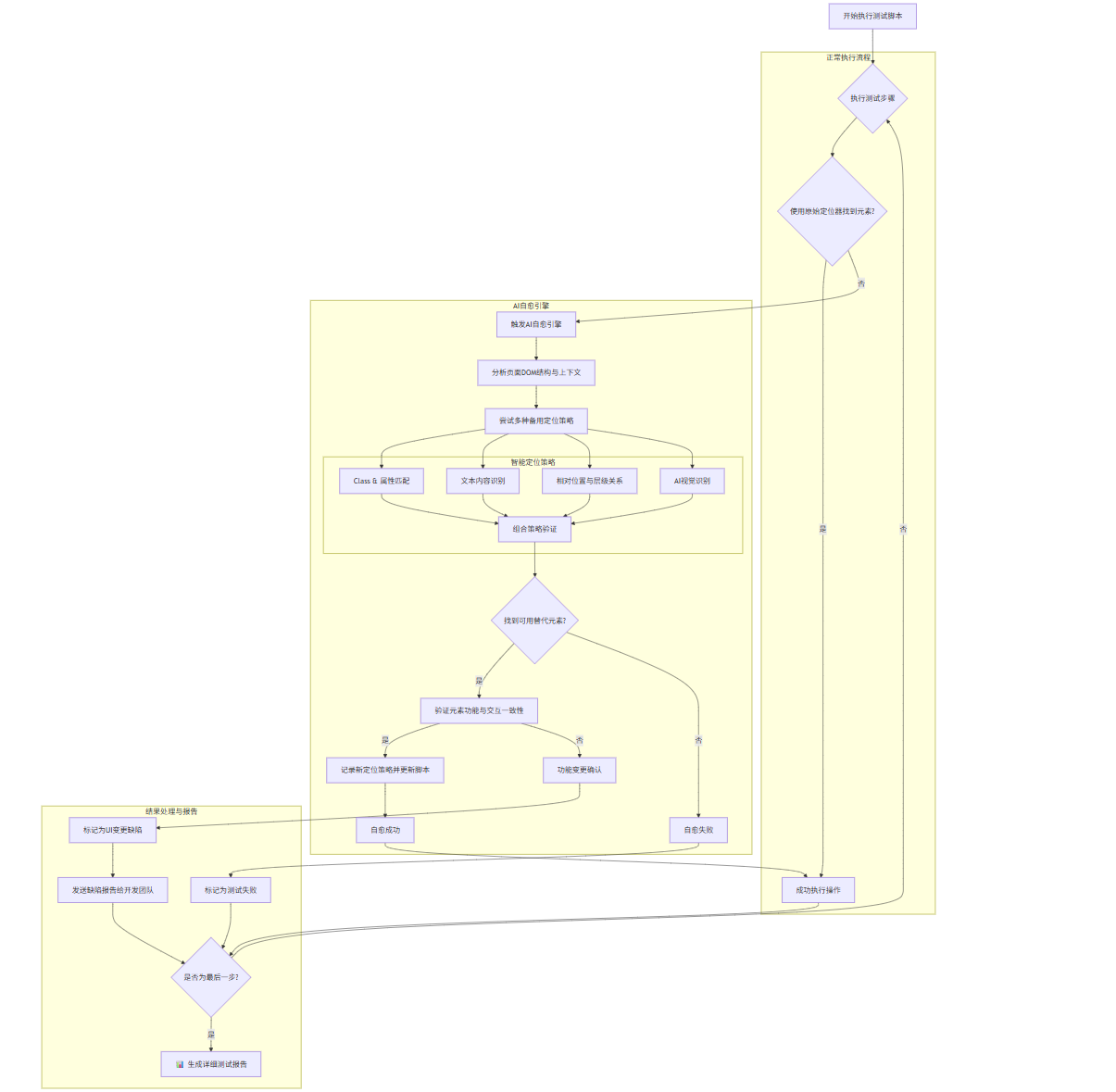
1.2 Mermaid流程图:AI自动化测试执行与自愈流程
下图清晰地展示了AI自动化测试框架在执行过程中的智能决策路径。
graph TD
A[开始执行测试脚本] --> B{执行测试步骤};
subgraph "正常执行流程"
B --> C{使用原始定位器找到元素?};
C -- 是 --> D[成功执行操作];
end
subgraph "AI自愈引擎"
C -- 否 --> E[触发AI自愈引擎];
E --> F[分析页面DOM结构与上下文];
F --> G[尝试多种备用定位策略];
subgraph "智能定位策略"
G1[Class & 属性匹配]
G2[文本内容识别]
G3[相对位置与层级关系]
G4[AI视觉识别]
G5[组合策略验证]
end
G --> G1 --> G5;
G --> G2 --> G5;
G --> G3 --> G5;
G --> G4 --> G5;
G5 --> H{找到可用替代元素?};
H -- 是 --> I[验证元素功能与交互一致性];
I -- 是 --> J[记录新定位策略并更新脚本];
J --> K[自愈成功];
H -- 否 --> L[自愈失败];
I -- 否 --> M[功能变更确认];
end
subgraph "结果处理与报告"
K --> D;
L --> N[标记为测试失败];
M --> O[标记为UI变更缺陷];
O --> P[发送缺陷报告给开发团队];
D --> Q{是否为最后一步?};
N --> Q;
P --> Q;
Q -- 否 --> B;
Q -- 是 --> R[📊 生成详细测试报告];
end
1.3 代码示例:模拟AI自愈逻辑
以下是一个使用Python和Playwright的简化示例,模拟了AI自愈的过程。当id定位失败时,它会尝试使用文本内容来定位。
from playwright.sync_api import sync_playwright, expect
import timeclass AIHealer:"""一个模拟的AI自愈引擎"""@staticmethoddef find_alternative(page, original_selector, fallback_text):"""当原始选择器失败时,尝试通过文本内容查找元素"""print(f"[AI Healer] 原始定位器 '{original_selector}' 失败,尝试通过文本 '{fallback_text}' 定位...")try:# 使用Playwright的文本定位器locator = page.get_by_text(fallback_text)if locator.count() > 0:print(f"[AI Healer] 成功找到替代元素!")return locatorexcept Exception as e:print(f"[AI Healer] 替代定位策略也失败了: {e}")return Nonedef run_test_with_ai_healing(url):with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.goto(url)# 假设我们有一个登录页面,登录按钮的ID可能会变login_button_selector = "#submit-button-id" # 这是一个可能失效的IDlogin_button_text = "登 录"try:# 1. 尝试原始定位器print(f"尝试使用原始定位器: {login_button_selector}")login_button = page.locator(login_button_selector)# 模拟ID已变更,这里直接跳过,让except捕获# login_button.click()raise Exception("Element not found") # 模拟定位失败except Exception as e:print(f"原始定位失败: {e}")# 2. 触发AI自愈healed_locator = AIHealer.find_alternative(page, login_button_selector, login_button_text)if healed_locator:# 3. 使用自愈后的定位器继续执行healed_locator.click()print("测试步骤成功执行(通过AI自愈)!")# 这里可以继续后续的断言...# expect(page.locator(".welcome-message")).to_have_text("欢迎您")else:print("AI自愈失败,测试中断。")# 在真实框架中,这里会记录一个严重的缺陷time.sleep(3) # 等待观察browser.close()# 假设这是一个本地运行的测试页面
# run_test_with_ai_healing("http://localhost:8080/login")
print("这是一个代码示例,请在实际环境中运行。")
1.4 Prompt示例:让AI生成测试用例
未来的测试框架将集成大型语言模型(LLM),测试工程师只需用自然语言描述需求,AI就能自动生成、执行和维护测试脚本。
Prompt示例:
“请为我们的电商网站生成一个端到端的自动化测试脚本。
目标路径:用户从首页搜索“iPhone 15”,选择第一个商品,加入购物车,然后进入结算页面。
需要覆盖的场景:
- 正常用户,使用默认地址和支付宝支付。
- VIP用户,验证折扣是否正确应用。
- 库存不足场景,验证购物车是否给出提示。
技术栈:使用Playwright和Python。
要求:使用Page Object Model模式,并为每个步骤添加清晰的断言。”
AI将解析这个Prompt,自动生成结构化的代码,甚至可以智能地为每个元素选择最稳定的定位器。
1.5 图表:传统 vs. AI自动化框架对比
| 特性 | 传统自动化框架 | AI驱动自动化框架 |
|---|---|---|
| 维护成本 | 高,UI变更导致大量脚本修改 | 低,AI自愈大部分变更 |
| 测试覆盖率 | 有限,依赖人工设计用例 | 高,AI可探索未知路径 |
| 稳定性 | 脆弱,易受非功能性变更影响 | 鲁棒,能适应UI变化 |
| 上手门槛 | 中等,需要编程和定位器知识 | 低,自然语言即可生成用例 |
| 执行效率 | 快,但失败后需人工介入 | 略慢(因自愈过程),但整体成功率高 |
二、 智能缺陷检测:从“大海捞针”到“精准狙击”
每天,一个大型应用会产生海量的数据:用户行为日志、性能监控指标、应用商店评论、客服反馈截图。传统方法依赖人工筛查,效率低下且容易遗漏。AI,特别是计算机视觉(CV)和自然语言处理(NLP),正在将这一过程自动化。
2.1 核心能力:视觉回归测试与非结构化数据分析
1. 计算机视觉(CV)用于视觉回归测试
视觉回归测试确保UI在不同版本、不同浏览器、不同分辨率下看起来“正确”。AI视觉测试超越了简单的像素比对。
- 内容感知比对:AI能理解页面内容。它会忽略动态内容(如广告、时间戳)的微小变化,而专注于布局错乱、元素重叠、字体错误等真正的视觉缺陷。
- 布局差异检测:即使像素完全不同(例如,在不同DPI的屏幕上),AI也能识别出布局结构是否一致。
- OCR(光学字符识别):AI可以读取图片中的文字,用于验证显示内容是否正确,例如检查验证码图片、宣传海报上的文字等。
2. 自然语言处理(NLP)用于反馈分析
用户反馈是发现缺陷的金矿,但它们是非结构化的文本。
- 情感分析:自动判断用户评论的情绪(正面、负面、中性),快速定位有问题的版本。
- 主题建模与关键词提取:从成千上万条评论中自动聚类,提取出高频抱怨的主题,如“闪退”、“登录不上”、“支付失败”。
- 意图识别:识别用户反馈的真实意图,是报告缺陷、提出功能建议还是寻求帮助。
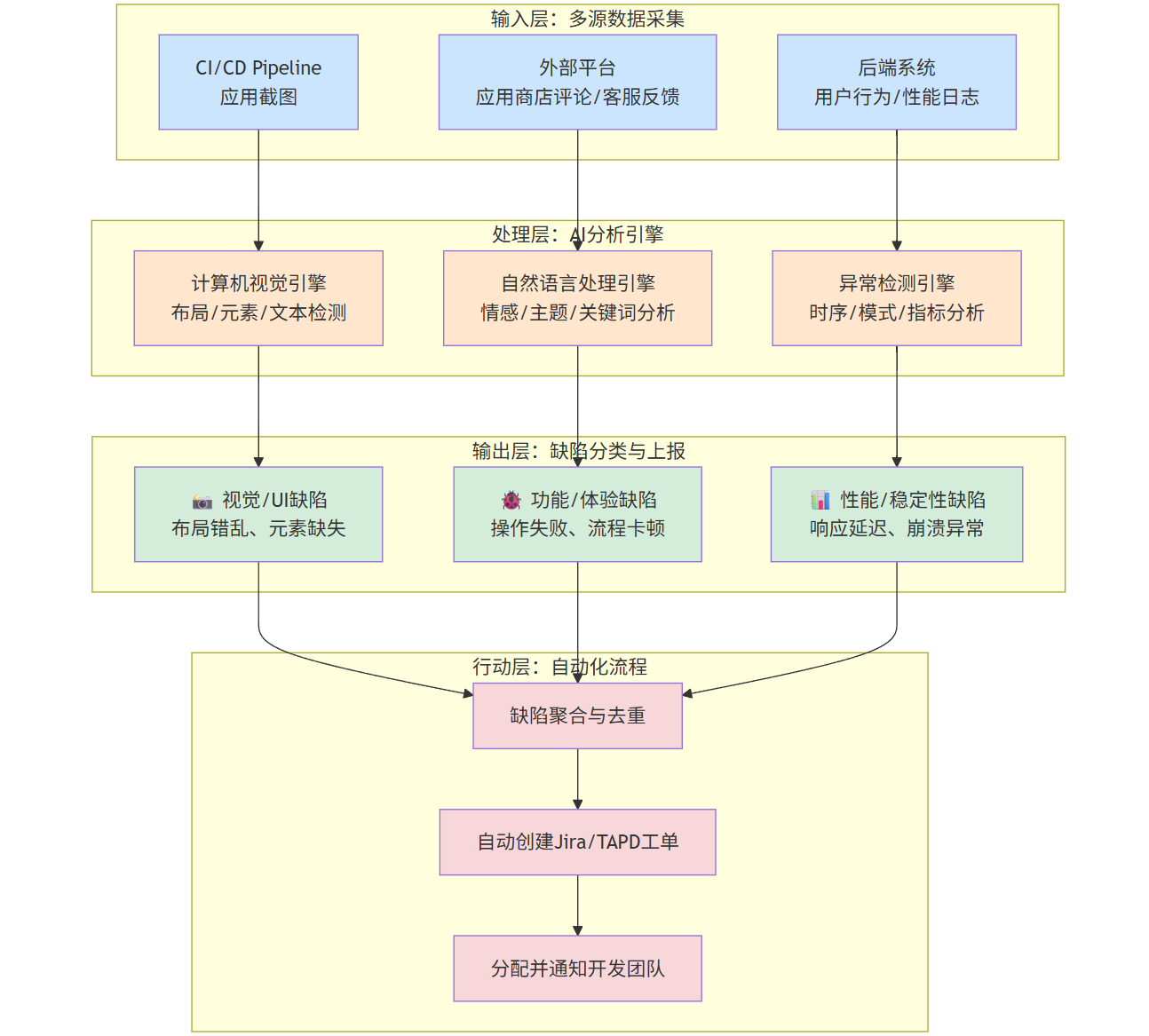
2.2 Mermaid流程图:智能缺陷检测系统工作流
graph TD
subgraph "输入层:多源数据采集"
A1[CI/CD Pipeline<br/>应用截图]
A2[后端系统<br/>用户行为/性能日志]
A3[外部平台<br/>应用商店评论/客服反馈]
end
subgraph "处理层:AI分析引擎"
B1[计算机视觉引擎<br/>布局/元素/文本检测]
B2[自然语言处理引擎<br/>情感/主题/关键词分析]
B3[异常检测引擎<br/>时序/模式/指标分析]
end
subgraph "输出层:缺陷分类与上报"
C1[📸 视觉/UI缺陷<br>布局错乱、元素缺失]
C2[🐞 功能/体验缺陷<br>操作失败、流程卡顿]
C3[📊 性能/稳定性缺陷<br>响应延迟、崩溃异常]
end
subgraph "行动层:自动化流程"
D[缺陷聚合与去重]
E[自动创建Jira/TAPD工单]
F[分配并通知开发团队]
end
2.3 代码示例:使用OpenCV进行视觉差异检测
这个Python示例展示了如何使用OpenCV库来比较两张截图,并高亮显示差异。这是AI视觉测试的基础。
import cv2
import numpy as npdef find_visual_diff(image1_path, image2_path, output_path):"""比较两张图片并高亮差异"""# 1. 读取图片img1 = cv2.imread(image1_path)img2 = cv2.imread(image2_path)# 2. 调整图片大小使其一致height, width, _ = img1.shapeimg2_resized = cv2.resize(img2, (width, height))# 3. 计算两张图片的差值diff = cv2.absdiff(img1, img2_resized)# 4. 将差值图片转换为灰度图gray_diff = cv2.cvtColor(diff, cv2.COLOR_BGR2GRAY)# 5. 应用阈值,突出显示差异区域_, thresh = cv2.threshold(gray_diff, 30, 255, cv2.THRESH_BINARY)# 6. 查找差异区域的轮廓contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 7. 在原始图片上绘制矩形框标记差异for contour in contours:if cv2.contourArea(contour) > 10: # 忽略太小的噪点x, y, w, h = cv2.boundingRect(contour)cv2.rectangle(img1, (x, y), (x+w, y+h), (0, 0, 255), 2) # 用红色矩形框标记# 8. 保存结果cv2.imwrite(output_path, img1)print(f"视觉差异检测完成,结果已保存至 {output_path}")# 假设我们有两个版本的页面截图
# find_visual_diff('homepage_v1.png', 'homepage_v2.png', 'diff_report.png')
print("这是一个代码示例,请准备实际图片文件进行测试。")
2.4 Prompt示例:分析用户反馈
产品经理或测试工程师可以使用Prompt来快速分析用户反馈。
Prompt示例:
“分析以下100条来自Google Play的应用评论:
[此处粘贴100条评论文本]
任务:
- 总结用户抱怨最多的前5个问题。
- 提取所有与‘crash’或‘闪退’相关的评论,并按严重程度排序(例如,提及‘无法打开’的比‘偶尔闪退’更严重)。
- 识别出至少3条有价值的功能建议。
- 将分析结果以Markdown表格形式输出,包含‘问题分类’、‘提及次数’、‘典型用户原话’和‘建议优先级’四列。”
AI能够迅速完成这项耗时的工作,让团队聚焦于最关键的问题。
2.5 图片描述:智能缺陷检测平台界面
[图片:一个现代化的智能缺陷检测平台仪表盘界面]
图片描述:
界面分为三个主要区域。
- 左侧是数据源列表,显示已连接的CI/CD流水线、日志服务器和应用商店。
- 中间是一个交互式图表,展示了过去7天内通过AI检测到的缺陷趋势,按“视觉”、“功能”、“性能”三类进行颜色区分。下方是一个缺陷列表,每个缺陷都包含AI自动生成的标题、置信度分数(如98%)、来源(如“v2.5.1版本截图对比”)和AI建议的严重级别。
- 右侧是一个详细的缺陷视图。当一个视觉缺陷被选中时,右侧会并排显示基准图和当前图,并用红色高亮框自动标记出所有差异区域,下方还有AI生成的差异描述:“‘登录’按钮向下偏移了10px,导致与‘忘记密码’链接重叠。”
三、 A/B测试优化:从“静态分流”到“动态寻优”
A/B测试是产品优化的核心方法,但传统的A/B测试存在两个痛点:
- “探索”与“利用”的矛盾:在测试初期,你需要将流量均匀分配给所有版本(探索),以找到最优解。但如果你已经发现某个版本明显更好,继续给它和差的版本分配一样的流量,就是在浪费用户和收入(利用)。
- 测试周期长:需要等待足够多的样本量才能获得统计显著性,对于流量不大的产品来说,这可能需要数周甚至数月。
AI,特别是多臂老虎机算法,完美地解决了这些问题。
3.1 核心能力:动态流量分配与快速收敛
MAB模型将A/B测试的每个版本看作一个“老虎机”的“臂”。你的目标是拉动哪个臂能获得最大的回报(如点击率、转化率)。
- 动态调整:MAB算法在测试开始时会分配少量流量给所有版本进行探索。一旦某个版本表现出优势,算法会动态地将更多流量分配给这个“胜出”版本,同时减少对表现差的版本的流量分配。
- 快速收敛:这种动态调整机制使得系统能够更快地收敛到最优解,最大化测试期间的总体收益,并缩短测试周期。
- 处理多变量:AI可以轻松处理更复杂的多变量测试,同时优化标题、图片、按钮颜色等多个变量,而传统A/B测试需要大量的实验组合。
常见的MAB算法包括ε-贪婪、UCB(Upper Confidence Bound)和汤普森采样。
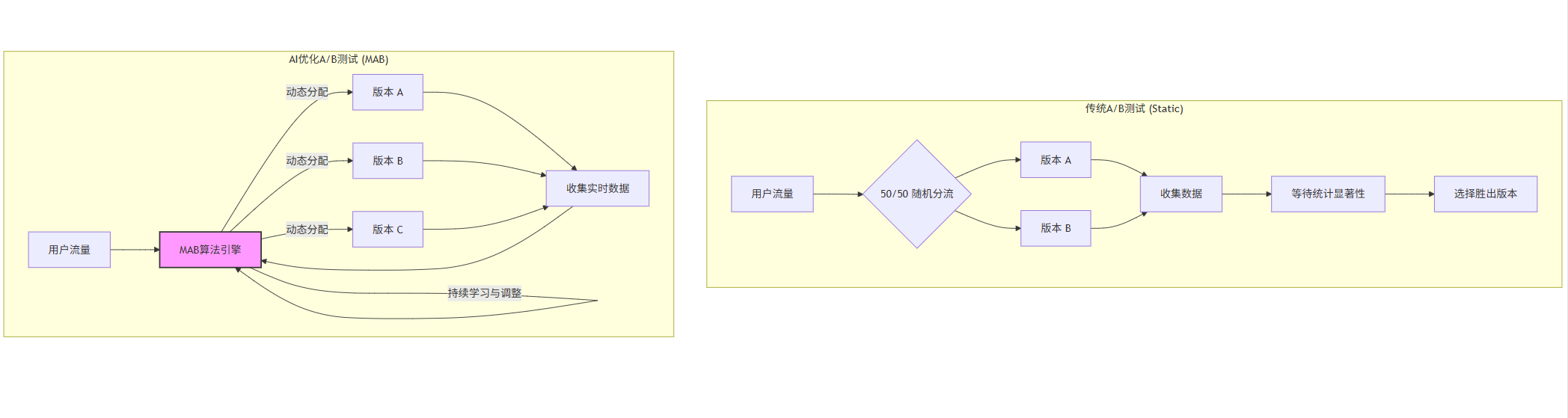
3.2 Mermaid流程图:传统A/B测试 vs. AI优化A/B测试
graph TD
subgraph "传统A/B测试 (Static)"
direction LR
S1[用户流量] --> E1{50/50 随机分流};
E1 --> V1[版本 A];
E1 --> V2[版本 B];
V1 --> C1[收集数据];
V2 --> C1;
C1 --> R1[等待统计显著性];
R1 --> D1[选择胜出版本];
end
subgraph "AI优化A/B测试 (MAB)"
direction LR
S2[用户流量] --> MAB[MAB算法引擎];
MAB -->|动态分配| V3[版本 A];
MAB -->|动态分配| V4[版本 B];
MAB -->|动态分配| V5[版本 C];
V3 --> C2[收集实时数据];
V4 --> C2;
V5 --> C2;
C2 --> MAB;
MAB -->|持续学习与调整| MAB;
style MAB fill:#f9f,stroke:#333,stroke-width:2px
end
3.3 代码示例:模拟ε-贪婪算法进行A/B测试
以下Python代码模拟了一个简单的ε-贪婪算法,用于优化一个按钮的点击率。
import numpy as np
import matplotlib.pyplot as pltclass EpsilonGreedyBandit:def __init__(self, n_arms, epsilon=0.1):self.n_arms = n_arms # 版本数量self.epsilon = epsilon # 探索概率self.counts = np.zeros(n_arms) # 每个版本的展示次数self.values = np.zeros(n_arms) # 每个版本的平均回报(点击率)def select_arm(self):"""选择一个版本(臂)进行展示"""if np.random.random() < self.epsilon:# 探索:随机选择一个版本return np.random.randint(0, self.n_arms)else:# 利用:选择当前平均回报最高的版本return np.argmax(self.values)def update(self, chosen_arm, reward):"""更新所选版本的数据"""self.counts[chosen_arm] += 1n = self.counts[chosen_arm]value = self.values[chosen_arm]# 增量计算平均值new_value = ((n - 1) / n) * value + (1 / n) * rewardself.values[chosen_arm] = new_valuedef simulate_bandit(true_ctr, num_steps):bandit = EpsilonGreedyBandit(len(true_ctr))rewards = []chosen_arms = []for _ in range(num_steps):chosen_arm = bandit.select_arm()chosen_arms.append(chosen_arm)# 模拟用户点击:根据真实点击率返回1(点击)或0(未点击)reward = np.random.binomial(1, true_ctr[chosen_arm])rewards.append(reward)bandit.update(chosen_arm, reward)return bandit, rewards, chosen_arms# --- 模拟实验 ---
# 假设有3个按钮版本,它们的真实点击率分别是5%, 10%, 15%
TRUE_CTR = [0.05, 0.10, 0.15]
NUM_STEPS = 10000final_bandit, total_rewards, arm_history = simulate_bandit(TRUE_CTR, NUM_STEPS)print("--- 实验结果 ---")
print(f"真实点击率: {TRUE_CTR}")
print(f"算法学习到的点击率: {final_bandit.values.round(4)}")
print(f"各版本被展示的次数: {final_bandit.counts}")
print(f"实验期间总点击数: {sum(total_rewards)}")
print(f"实验期间平均点击率: {sum(total_rewards) / NUM_STEPS:.4f}")# --- 绘制图表 ---
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.bar(range(len(TRUE_CTR)), final_bandit.counts)
plt.xticks(range(len(TRUE_CTR)), [f'版本 {i+1}' for i in range(len(TRUE_CTR))])
plt.title('各版本最终展示次数分配')
plt.ylabel('展示次数')plt.subplot(1, 2, 2)
plt.plot(np.cumsum(total_rewards) / np.arange(1, NUM_STEPS + 1))
plt.title('实验期间累计平均点击率')
plt.xlabel('时间步')
plt.ylabel('平均点击率')
plt.axhline(y=max(TRUE_CTR), color='r', linestyle='--', label='最优版本真实CTR')
plt.legend()
plt.tight_layout()
plt.show()
运行这段代码,你会发现算法很快就会将大部分流量分配给版本3(真实CTR为15%),从而在整个测试期间获得了接近最优值的总回报。
3.4 Prompt示例:设计一个复杂的MAB实验
数据科学家或产品经理可以通过Prompt来配置一个复杂的实验。
Prompt示例:
“我需要为我们的App首页启动一个个性化推荐实验。
目标:最大化用户点击进入商品详情页的转化率。
实验版本(臂):
- 协同过滤推荐算法
- 基于内容的推荐算法
- 混合推荐算法
- 热销商品榜单(对照组)
算法选择:使用汤普森采样算法,因为它在处理延迟反馈和不确定性方面表现更好。
上下文信息:请将用户的‘会员等级’(新用户/普通会员/VIP会员)作为上下文特征,实现个性化多臂老虎机。
流量分配:初期总流量5%,运行3天后,如果表现稳定,自动扩大到20%。
停止条件:当某个版本的95%置信区间下限连续7天高于其他所有版本时,宣布其为胜出者并停止实验。”
3.5 图表:传统A/B测试与MAB的累计收益对比
[图表:一条折线图,X轴为时间(天),Y轴为累计转化率(%)]
图表描述:
该图包含两条线。
- 蓝色虚线(传统A/B测试):在测试初期,累计转化率增长缓慢,因为一半的流量被分配给了较差的版本。直到实验后期确定胜出版本并全量上线后,曲线才以更陡峭的斜率上升。
- 绿色实线(MAB优化测试):从第一天起,曲线就迅速攀升。因为MAB算法很快就识别出表现好的版本,并将大部分流量导向它,从而在整个测试期间都获得了更高的累计收益。两条线之间的阴影区域,代表了MAB算法带来的“增量收益”。
结论:AI重塑软件质量保障的未来
从会自我修复的自动化框架,到能洞察秋毫的智能缺陷检测,再到能持续寻优的A/B测试引擎,AI正在全方位地重塑软件质量保障(QA)的每一个环节。
在2025年的今天,AI测试已不再是少数前沿科技公司的专利,而是逐渐成为行业标配。它带来的不仅仅是效率的提升,更是质量保障理念的变革:
- 从被动到主动:AI能够预测潜在的缺陷风险,在问题发生前进行预警。
- 从局部到全局:AI打破了测试、开发、运维、产品之间的数据孤岛,实现了全链路的质量洞察。
- 从工具到伙伴:AI正成为测试工程师的智能助手,将他们从繁琐的重复劳动中解放出来,专注于更复杂的测试策略设计和质量风险分析。
未来,随着生成式AI(Generative AI)的进一步发展,我们甚至可以期待AI能够根据需求文档自动生成测试数据和测试环境,实现端到端的“测试即代码”。拥抱AI,将是每一个软件团队在激烈竞争中保持领先的关键。质量保障的未来,已然到来。