2020年美国新冠肺炎疫情数据分析与可视化
数据分析与可视化
做实验之前,请先安装Hadoop和Spark环境
本文以Python为编程语言,涉及Spark数据分析,HDFS存储文件,以及pyecharts数据可视化。
一:实验环境
(1)Linux:Ubuntu 16.04
(2)Hadoop3.1.3
(3)Python: 3.8
(4)Spark: 2.4.0
(5)Jupyter Notebook
此实验运行在伪分布式的Hadoop环境中,并使用Spark local模式提交作业
二:数据集下载
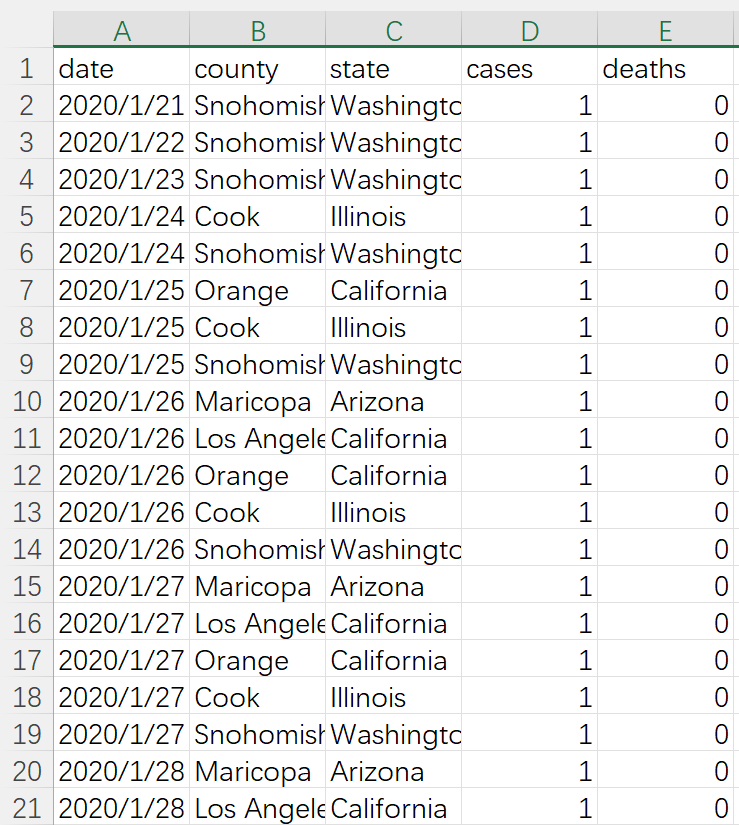
数据集来自数据网站Kaggle的美国新冠肺炎疫情数据集,该数据集以数据表us-counties.csv组织,其中包含了美国(2020-01-21 ~ 2020-05-19)的相关数据158981万条。
数据包含以下字段:
字段名称 字段含义 例子
date 日期 2020/1/21,2020/1/22 …
county 区县(州的下一级单位)Snohomish
state 州 Washington,California
cases 截止该日期该区县的累计确诊人数 1,2,3…
deaths 截止该日期该区县的累计确诊人数 1,2,3…
为了使spark方便读入数据,这里先将数据转化为.txt文件在上传到Hadoop的HDFS文件系统上
转换代码如下:
import pandas as pd
#.csv->.txt
data = pd.read_csv('us-counties.csv')
with open('us-counties.txt','a+',encoding='utf-8') as f:for line in data.values:f.write((str(line[0])+'\t'+str(line[1])+'\t'+str(line[2])+'\t'+str(line[3])+'\t'+str(line[4])+'\n'))
假设代码和文件在同一目录下,并使用\t作为分隔符
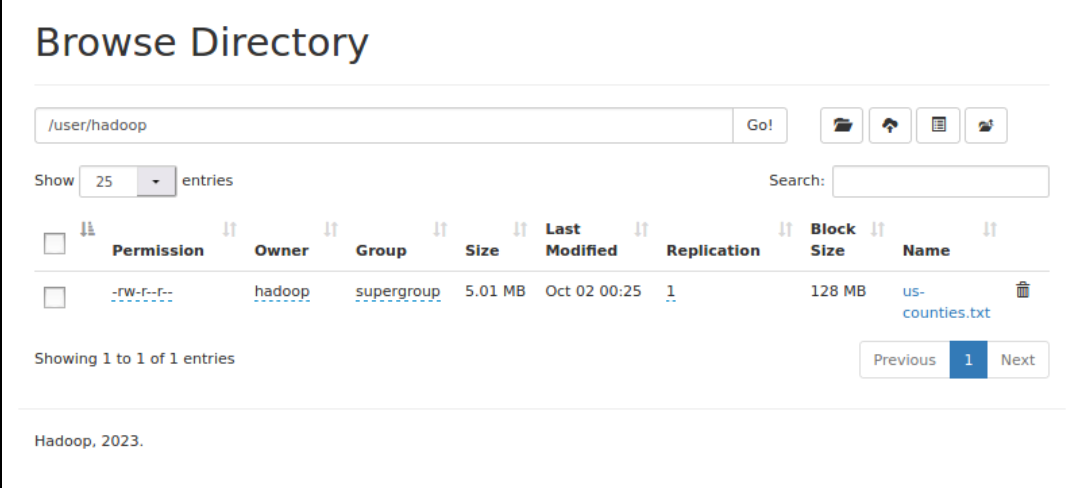
之后将文件上传到Hadoop上 /usr/hadoop/
操作命令如下:
./bin/hdfs dfs -put /home/hadoop/Downloads/us-counties.txt /user/hadoop
三:使用Spark对数据进行分析
根据数据的情况统计6个指标
- 统计美国截止每日的累计确诊人数和累计死亡人数。做法是以date作为分组字段,对cases和deaths字段进行汇总统计。
- 统计美国每日的新增确诊人数和新增死亡人数。因为新增数=今日数-昨日数,所以考虑使用自连接,连接条件是t1.date = t2.date + 1,然后使用t1.totalCases – t2.totalCases计算该日新增。
- 统计截止5.19日,美国
各州的累计确诊人数和死亡人数。首先筛选出5.19日的数据,然后以state作为分组字段,对cases和deaths字段进行汇总统计。 - 统计截止5.19日,美国
确诊人数最多的十个州。对3)的结果DataFrame注册临时表,然后按确诊人数降序排列,并取前10个州。 - 统计截止5.19日,美国
死亡人数最多的十个州。对3)的结果DataFrame注册临时表,然后按死亡人数降序排列,并取前10个州。 - 统计截止5.19日,
全美和各州的病死率。病死率 = 死亡数/确诊数,对3)的结果DataFrame注册临时表,然后按公式计算。
首先对数据进行加载,使用spark读取源文件生成DataFrame,并创建临时表以方便进行后续分析实现。
from pyspark import SparkConf,SparkContext
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from datetime import datetime
import pyspark.sql.functions as funcdef toDate(inputStr):newStr = ""if len(inputStr) == 8:s1 = inputStr[0:4]s2 = inputStr[5:6]s3 = inputStr[7]newStr = s1+"-"+"0"+s2+"-"+"0"+s3else:s1 = inputStr[0:4]s2 = inputStr[5:6]s3 = inputStr[7:]newStr = s1+"-"+"0"+s2+"-"+s3date = datetime.strptime(newStr, "%Y-%m-%d")return date#主程序:
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()fields = [StructField("date", DateType(),False),StructField("county", StringType(),False),StructField("state", StringType(),False),StructField("cases", IntegerType(),False),StructField("deaths", IntegerType(),False),]
schema = StructType(fields)rdd0 = spark.sparkContext.textFile("/user/hadoop/us-counties.txt")
rdd1 = rdd0.map(lambda x:x.split("\t")).map(lambda p: Row(toDate(p[0]),p[1],p[2],int(p[3]),int(p[4])))shemaUsInfo = spark.createDataFrame(rdd1,schema)shemaUsInfo.createOrReplaceTempView("usInfo")接下来对6个指标进行数据分析
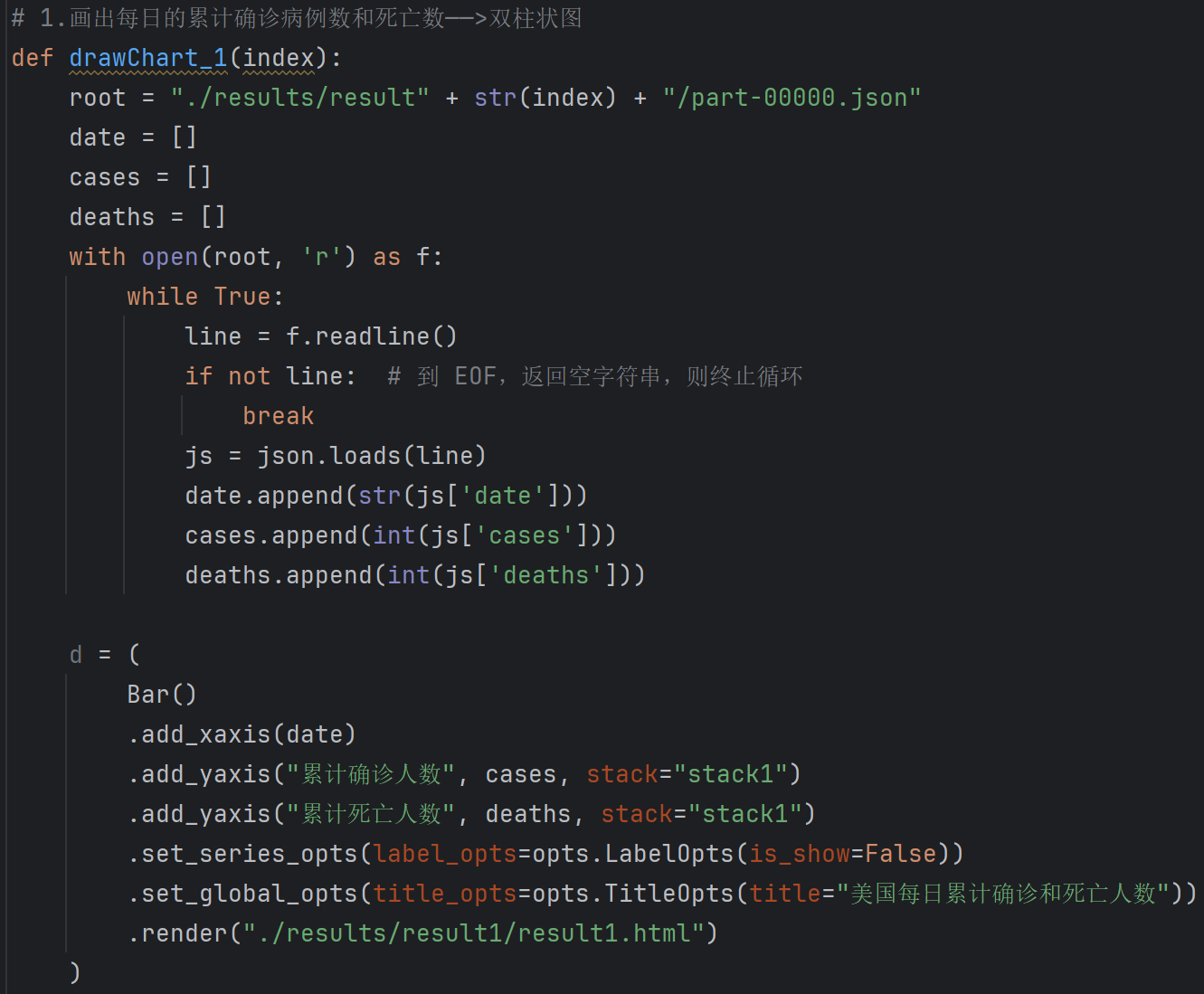
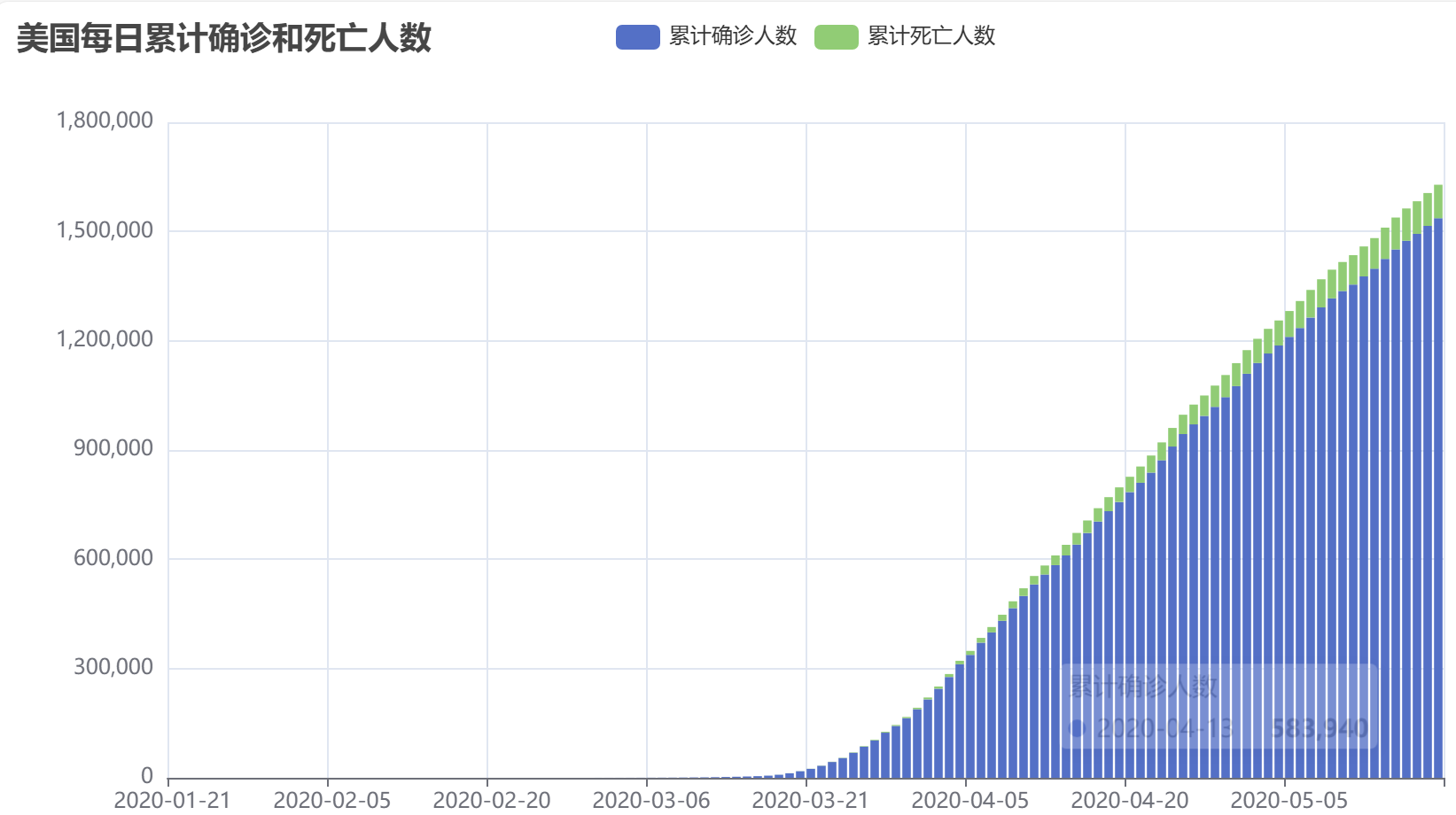
#1.计算每日的累计确诊病例数和死亡数
df = shemaUsInfo.groupBy("date").agg(func.sum("cases"),func.sum("deaths")).sort(shemaUsInfo["date"].asc())#列重命名
df1 = df.withColumnRenamed("sum(cases)","cases").withColumnRenamed("sum(deaths)","deaths")
df1.repartition(1).write.json("result1.json")#注册为临时表供下一步使用
df1.createOrReplaceTempView("ustotal")#2.计算每日较昨日的新增确诊病例数和死亡病例数
df2 = spark.sql("select t1.date,t1.cases-t2.cases as caseIncrease,t1.deaths-t2.deaths as deathIncrease from ustotal t1,ustotal t2 where t1.date = date_add(t2.date,1)")df2.sort(df2["date"].asc()).repartition(1).write.json("result2.json")#3.统计截止5.19日 美国各州的累计确诊人数和死亡人数
df3 = spark.sql("select date,state,sum(cases) as totalCases,sum(deaths) as totalDeaths,round(sum(deaths)/sum(cases),4) as deathRate from usInfo where date = to_date('2020-05-19','yyyy-MM-dd') group by date,state")df3.sort(df3["totalCases"].desc()).repartition(1).write.json("result3.json")# 接下来几个分析都需要用到df3分析的结果,所以将df3也创建视图
df3.createOrReplaceTempView("eachStateInfo")#4.找出美国确诊最多的10个州
df4 = spark.sql("select date,state,totalCases from eachStateInfo order by totalCases desc limit 10")
df4.repartition(1).write.json("result4.json")#5.找出美国死亡最多的10个州
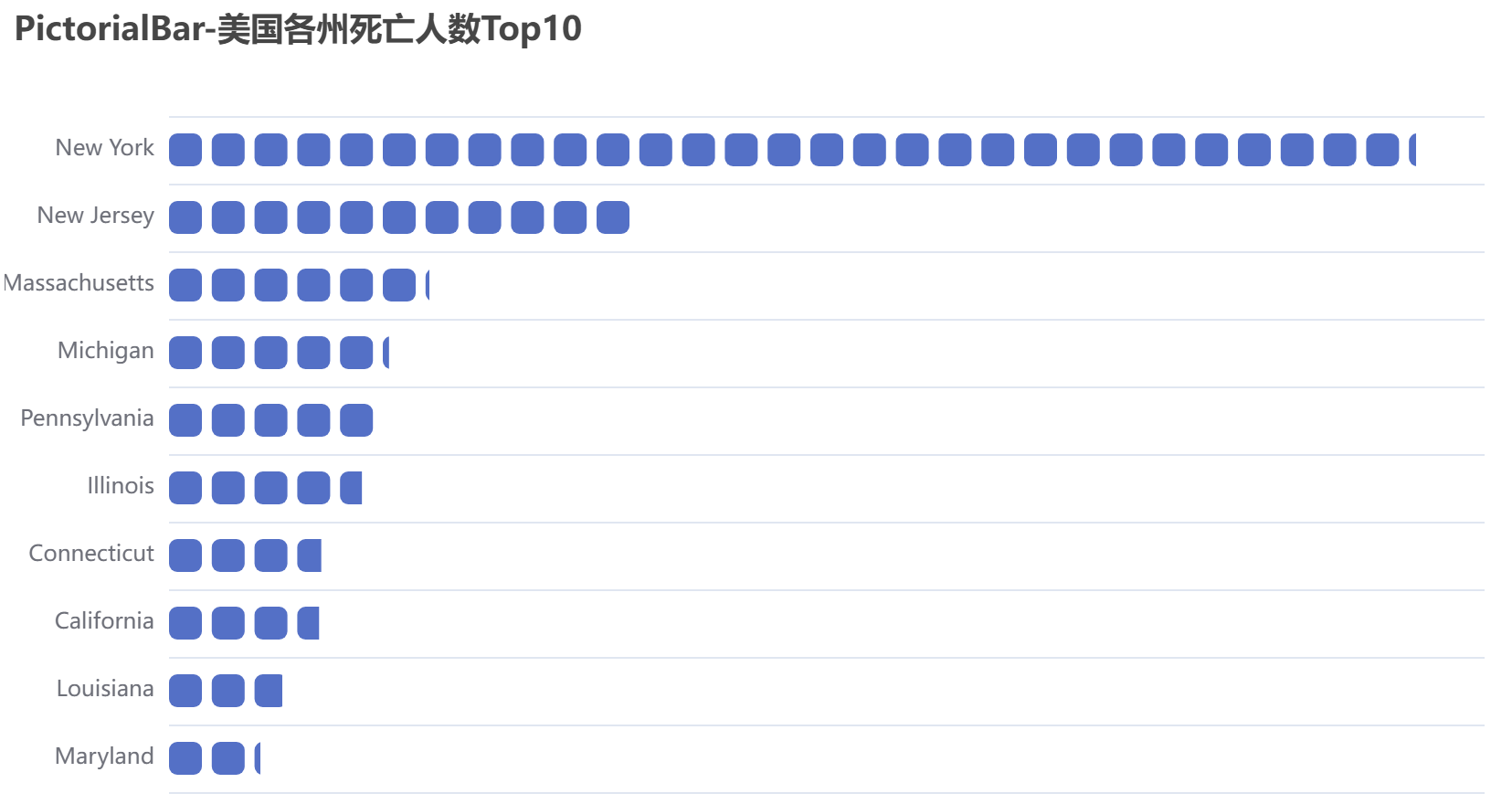
df5 = spark.sql("select date,state,totalDeaths from eachStateInfo order by totalDeaths desc limit 10")
df5.repartition(1).write.json("result5.json")#6.统计截止5.19全美和各州的病死率
df6 = spark.sql("select 1 as sign,date,'USA' as state,round(sum(totalDeaths)/sum(totalCases),4) as deathRate from eachStateInfo group by date union select 2 as sign,date,state,deathRate from eachStateInfo").cache()
df6.sort(df6["sign"].asc(),df6["deathRate"].desc()).repartition(1).write.json("result6.json")
着重对第六个分析代码进行解释
- 第一部分(计算全美整体病死率)
select 1 as sign, -- 标记为“全国数据”(用于后续排序)date, -- 日期(固定为2020-05-19)'USA' as state, -- 州名固定为'USA',代表全国-- 计算全国病死率:总死亡数/总确诊数,保留4位小数round(sum(totalDeaths)/sum(totalCases),4) as deathRate
from eachStateInfo
group by date -- 按日期分组
- 第二部分(引用各州已计算的病死率)
select 2 as sign, -- 标记为“州数据”(用于后续排序)date, -- 日期(固定为2020-05-19)state, -- 州名(如California、New York等)deathRate -- 各州病死率(直接复用第3步计算的deathRate)
from eachStateInfo
- union 的作用:合并结果
union 将 “全美整体数据” 和 “各州数据” 合并为一个 DataFrame,结构如下:
| sign | date | state | deathRate | |
|---|---|---|---|---|
| 1 | 2020-05-19 | USA | 0.0523 | (全美整体) |
| 2 | 2020-05-19 | NewYork | 0.0612 | (纽约州) |
| 2 | 2020-05-19 | California | 0.0389 | (加州) |
| … | … | … | … |
sign 字段的核心作用:
sign 是自定义的 “标记字段”,用于后续排序:
- sign=1 代表 “全国数据”,sign=2 代表 “州数据”。
- 后续 df8.sort(df8[“sign”].asc(),df8[“deathRate”].desc()) 会先按 sign 升序(确保全国数据排在最前面),再按 deathRate降序(各州按病死率从高到低排列),最终结果更符合阅读习惯(先看整体,再看各州排序)。
运行结果展示
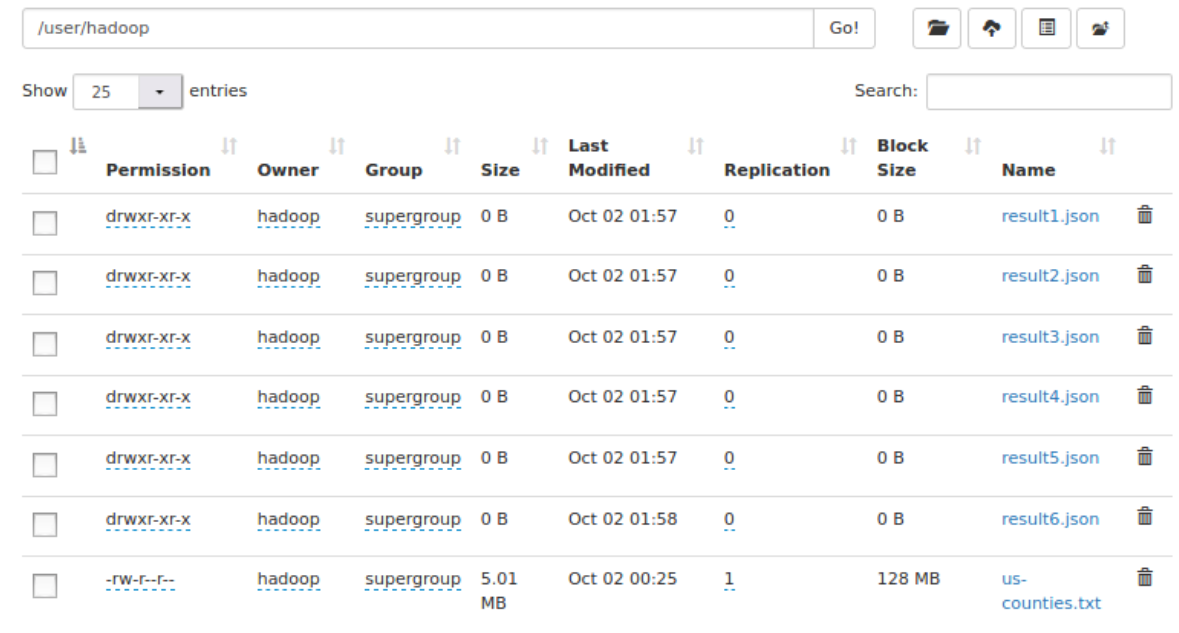
执行完成会在/user/hadoop/目录下生成六个文件夹
四:数据可视化
采用脚本方式将Hadoop中HDFS上的数据保存到本地,然后进行数据可视化分析
#!/bin/bash# 定义本地根目录(最终结果会保存在这里的result1-6子目录)
LOCAL_ROOT="/home/hadoop/results"# 定义HDFS根路径(存放result1.json到result6.json的目录)
HDFS_ROOT="/user/hadoop"# 循环处理result1到result6
for i in {1..6}; do# 定义当前循环的HDFS源路径和本地目标路径HDFS_PATH="${HDFS_ROOT}/result${i}.json/*.json"LOCAL_PATH="${LOCAL_ROOT}/result${i}"echo "开始处理result${i}..."# 创建本地目录(-p确保父目录存在,已存在则不报错)mkdir -p "${LOCAL_PATH}"# 从HDFS复制文件到本地hdfs dfs -get "${HDFS_PATH}" "${LOCAL_PATH}/"# 检查命令是否执行成功if [ $? -eq 0 ]; thenecho "result${i} 成功保存到 ${LOCAL_PATH}"elseecho "警告:result${i} 复制失败,请检查HDFS路径是否存在"fi
doneecho "所有操作执行完毕"
可视化部分代码展示
可视化部分图表展示
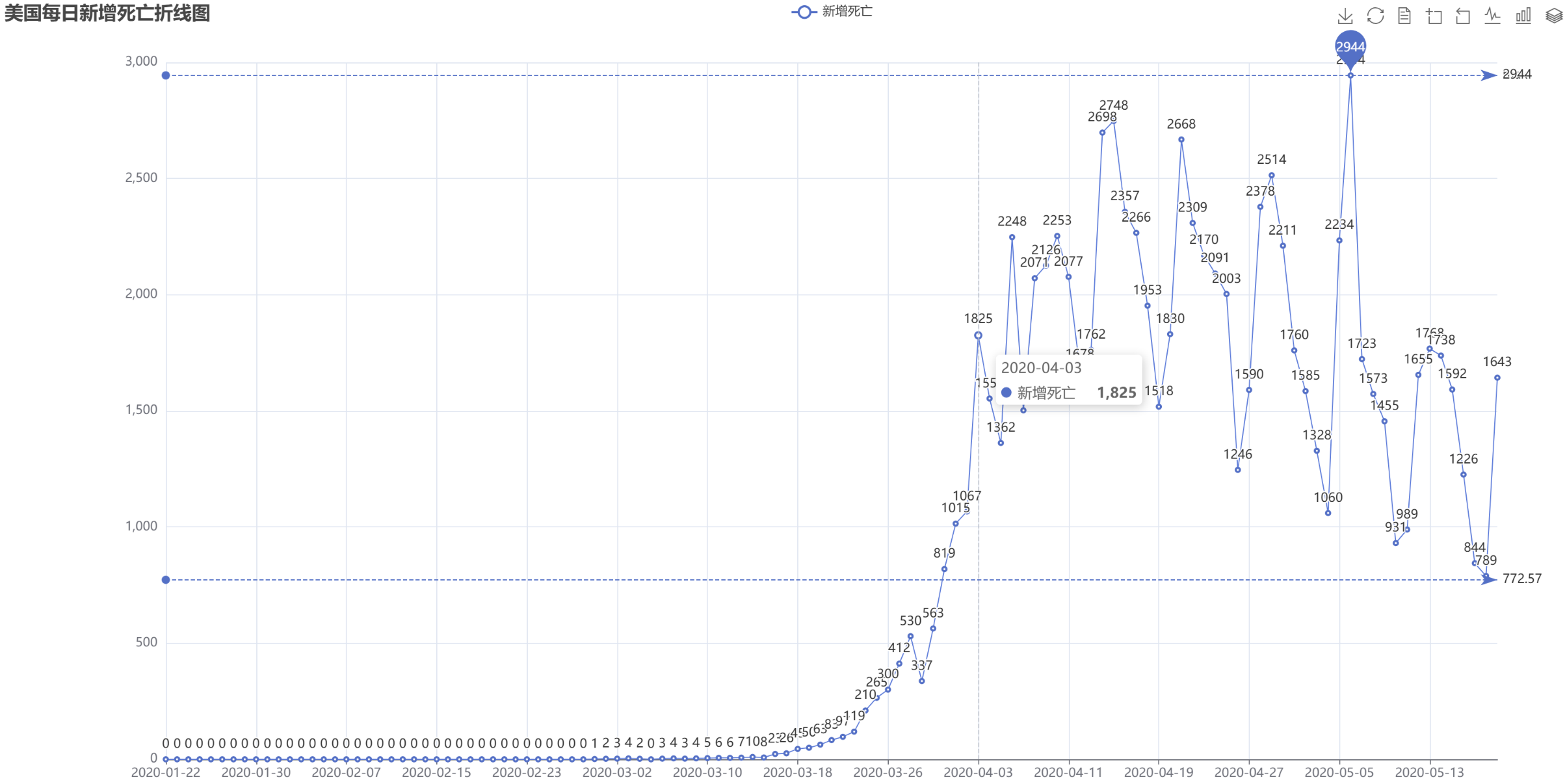
再次说明:由于条件有限,为了完成本实验,在基于伪分布的Hadoop环境,使用Spark Local模式运行代码,条件允许同学的可以搭建分布式Hadoop环境,使用standalone模式进行数据分析
实验参考:2020年美国新冠肺炎疫情数据分析