AI应用开发新范式:从模型API到交互式网页的极速实现路径
前言:AI时代的“最后一公里”困境
我们生活在一个被AI浪潮席卷的时代。每一天,我们都能看到、听到关于大型语言模型(LLM)的突破性新闻。它们能写诗、能编程、能进行逻辑缜密的对话,其强大的能力似乎预示着一个全新的应用纪元即将到来。对于我们这些身处技术前沿的开发者、创业者和充满热情的爱好者来说,这无疑是一个激动人心的信号。我们脑中充满了各种奇思妙想:一个能自动分析财报的智能助手、一个能与用户进行深度情感交流的虚拟伙伴、一个能辅助我们进行高效编程的AI副驾驶……
然而,当激情涌上心头,我们准备将这些想法付诸实践时,一堵无形的墙却悄然立在了面前。这堵墙,我称之为AI应用的“最后一公里”困境。
第一个“痛点”是模型接入的复杂性与成本黑洞。想要调用一个顶尖的AI模型,我们首先面临的是选择。是选择像OpenAI这样成熟的商业API,还是拥抱Hugging Face上琳琅满目的开源模型?前者虽然便捷,但其高昂的费用和对数据隐私的潜在担忧,让许多初创项目和个人开发者望而却gao。后者的开源模型虽然自由度高,但随之而来的是巨大的技术负担:你需要自己处理模型的部署、优化、扩缩容,这背后是复杂的GPU服务器配置、环境依赖的调试以及持续的运维成本。对于一个核心目标是验证应用创意的团队或个人而言,这无疑是一条漫长且昂贵的弯路。
第二个“痛点”是从后端到前端的巨大鸿沟。即便我们幸运地解决了模型接入问题,我们得到的通常也只是一个API接口。一个能与用户进行交互的AI Agent,绝不仅仅是一个API。它需要一个稳定、美观、响应迅速的前端界面。这意味着我们需要投入大量时间和精力去进行网页设计、编写HTML、CSS和JavaScript代码,甚至还要学习和使用React、Vue等现代前端框架。对于许多精通后端的开发者来说,前端开发是一个完全不同的领域,这道鸿沟常常成为项目推进的巨大阻力。我们想要的是快速验证AI核心逻辑,却被迫陷入了繁琐的界面开发工作中。
第三个“痛点”是工具链的割裂与低效。在传统的开发流程中,我们需要在多个工具和平台之间不断切换。在A平台管理和测试模型API,在B工具(如Postman)中调试接口,在C代码编辑器中编写前端代码,在D终端中运行和部署……整个过程是割裂的、碎片化的。每一次上下文的切换都伴随着效率的损耗和注意力的分散。我们渴望一个能够将模型服务、API管理、前端构建乃至部署测试流畅整合在一起的平台,一个能让我们专注于“创造”而非“配置”的环境。
正是这些普遍存在的痛点,让无数优秀的AI应用创意停留在构想阶段,无法落地。我们距离那个“人人都能创造AI应用”的未来,似乎总差着那关键的“最后一公里”。
今天,我将通过一次完整的实战演练,向你展示一种全新的路径。这条路径将彻底绕开上述所有痛管,让你能在极短的时间内,将一个AI Agent的想法变为现实。我们将利用一个名为“蓝耘”的MaaS(Model-as-a-Service)平台,结合一个创新的前端构建工具,来证明:构建一个属于你自己的、功能完备的AI Agent,不再需要庞大的团队、高昂的预算和漫长的开发周期。
这不仅仅是一篇技术教程,更是一次思维的解放。准备好,让我们一起跨越这“最后一公里”。
第一章:寻找基石——MaaS平台如何重塑AI开发
在开始实际操作之前,我们必须先理解一个核心概念:MaaS,即模型即服务(Model-as-a-Service)。这个概念是我们能够快速构建AI Agent的根本前提。
在云计算发展的历程中,我们经历了IaaS(基础设施即服务)、PaaS(平台即服务)和SaaS(软件即服务)的演变。IaaS为我们提供了虚拟的计算资源(如虚拟机、存储),让我们不必再购买和维护物理服务器。PaaS则更进一步,提供了操作系统、数据库、中间件等平台级服务,让开发者可以专注于应用逻辑本身。SaaS则直接向最终用户交付完整的软件应用。
MaaS,正是这一演变在AI领域的自然延伸。它将训练好的、复杂的AI模型封装成一个标准化的、易于调用的API服务,并向开发者提供。这意味着,我们作为应用开发者,不再需要关心以下任何问题:
- 硬件基础设施:我们不需要购买、配置和维护昂贵的GPU服务器。MaaS平台已经为我们准备好了一切,并根据实际使用情况弹性伸缩。
- 模型部署与优化:我们不需要处理复杂的模型部署流程,不需要担心Python环境依赖冲突,也不需要为提升模型的推理速度而进行底层优化。所有这些工作,MaaS平台都已完成。
- 模型维护与更新:AI模型在不断迭代。MaaS平台会负责模型的更新和维护,确保我们随时都能用到最新、最强大的版本。
MaaS的出现,从根本上降低了AI技术的准入门槛。它让开发者能够像调用一个普通的函数库一样,去调用世界上最先进的AI模型的能力。这种模式的转变,将开发者的精力从繁重的底层技术工作中解放出来,使其能够完全聚焦于应用的创新和业务逻辑的实现。
在众多的MaaS平台中,我们今天选择的是“蓝耘平台”。选择它的原因很简单:它提供了一个清晰、简洁且对开发者友好的环境,并且拥有丰富的模型资源库。
现在,让我们迈出第一步:进入这个平台并完成注册。
打开浏览器,访问这个地址:https://console.lanyun.net/#/register?promoterCode=0131
这是一个非常标准的注册流程。你需要提供基本的邮箱信息,设置一个安全的密码。这个过程通常不会超过两分钟。
(此处应插入图片:注册界面截图)
完成注册并登录后,我们就进入了蓝耘平台的控制台。这是一个集成化的工作空间,所有后续的操作都将在这里完成。
第二章:选择你的“大脑”——在模型宇宙中航行
登录平台后,我们的首要任务是为我们的AI Agent选择一个“大脑”,也就是它所依赖的大型语言模型。蓝耘平台将所有与模型相关的服务都整合在了其“MaaS平台”板块中。
在控制台顶部的导航栏中,找到并点击MaaS平台。
(此处应插入图片:导航栏指向MaaS平台截图)
进入这个板块后,一个丰富的模型资源库便展现在我们眼前。这里就像一个模型的超级市场,汇集了来自世界各地顶尖AI研究机构和公司的模型。你可以看到不同规模、不同特长、不同授权协议的模型,它们被清晰地分类和陈列,等待着开发者的挑选。
(此处应插入图片:模型资源列表截图)
这种体验本身就是一种赋能。在过去,想要尝试和切换不同的开源模型,意味着数小时甚至数天的环境配置和代码调试。而在这里,切换模型的成本几乎为零。这极大地鼓励了开发者进行实验和创新,为自己的应用找到最匹配的“大脑”。
在今天的项目中,我们将选择一个非常具体且具有前沿特性的模型:DeepSeek-V3.2-Exp。
让我们深入了解一下这个选择背后的考量。
DeepSeek-V3.2-Exp 中的“Exp”代表“Experimental”,即实验性版本。这本身就很有吸引力。选择一个实验性版本,意味着我们有机会率先接触到一些可能在未来成为主流的新技术。根据平台的官方介绍,V3.2-Exp在V3.1-Terminus版本的基础上,引入了一种名为“DeepSeek Sparse Attention”(深度求索稀疏注意力)的机制。
这是一个关键的技术点。让我们用直接的方式来理解它。传统Transformer架构中的“注意力机制”,其计算量会随着输入文本长度的平方而增长。这意味着处理长文本(例如,一篇几万字的文档)时,模型的计算开销和内存占用会急剧增加,导致处理速度变慢,成本变高。
而“稀疏注意力机制”是对这一问题的直接回应。它通过一种智能的方式,让模型在计算时只关注输入文本中最重要的部分,而不是对所有部分都给予同等的注意力。这种机制可以在不显著牺牲模型性能的前提下,极大地提升处理长文本时的训练和推理效率。
选择DeepSeek-V3.2-Exp,意味着我们的AI Agent天生就具备了高效处理长上下文的潜力。这对于文档分析、知识库问答、长时间对话等应用场景至关重要。
确定了模型后,我们需要获取一个关键的标识符,以便在后续的API调用中告诉平台我们想要使用哪一个模型。在模型列表中找到DeepSeek-V3.2-Exp,点击进入其详情页面。
(此处应插入图片:DeepSeek-V3.2-Exp模型详情页截图)
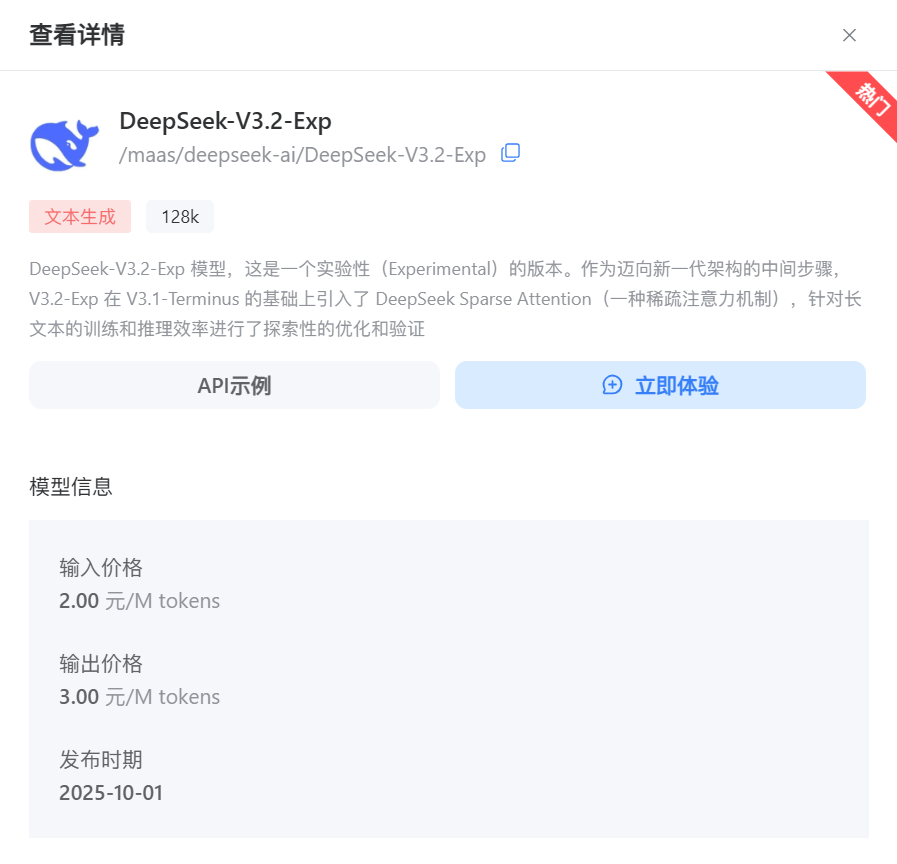
在这里,我们可以看到模型的详细介绍、参数以及最重要的信息——模型ID。对于DeepSeek-V3.2-Exp,它的模型ID是:/maas/deepseek-ai/DeepSeek-V3.2-Exp。
请复制这个ID并妥善保存。这是我们与模型进行通信的第一个凭证。
第三章:获取授权——生成你的专属API-KEY
有了模型ID,我们已经确定了要和哪个“大脑”对话。但平台如何知道是我们(而不是其他任何人)在发起这个对话呢?这就需要一个身份验证机制,也就是API-KEY。
API-KEY是一个唯一的字符串,它代表了你的开发者身份。在每一次API请求中,你都需要附上这个KEY,平台通过验证KEY的有效性来确认你的身份,并对你的使用情况进行计费和监控。因此,API-KEY是极其重要的凭证,必须妥善保管,绝不能泄露给他人。
在蓝耘平台生成API-KEY的过程非常直接。
在平台控制台的左侧导航栏中,找到并点击API-KEY管理。
进入管理页面后,你会看到一个清晰的界面,用于创建和管理你的所有KEY。一个良好的实践是为每一个不同的应用创建一个独立的API-KEY,这样便于你分项目进行用量监控和权限管理。
点击页面上的创建API-KEY按钮。
系统会立即为你生成一个新的KEY。这个KEY通常以“sk-”开头,后面跟着一长串无规律的字符。
请立即复制这个新生成的KEY。由于安全原因,这个完整的KEY只会在创建时显示一次。关闭这个弹窗后,你将无法再次看到完整的KEY内容。务必将它粘贴到一个安全的地方,比如你的密码管理器或者一个受保护的本地文件中。
同时,请注意截图中的另一个有用信息:平台为每个KEY都提供了专属的监视模型使用情况的网址。这是一个非常实用的功能,你可以随时访问这个地址,查看该KEY下的模型调用次数、token消耗量等关键数据,让你的成本控制变得透明和可预测。这解决了我们在前言中提到的“成本黑洞”痛点。
至此,我们已经拥有了构建AI Agent所需的两个核心要素:
- 模型ID:
/maas/deepseek-ai/DeepSeek-V3.2-Exp - API-KEY:
sk-xxxxxxxxxxx(你自己的专属KEY)
我们已经准备好与AI模型进行第一次直接的程序化交互了。
第四章:建立连接——解构第一个API调用
我们现在要去获取与模型进行交互的具体代码。一个优秀的MaaS平台,一定会提供清晰、易懂、开箱即用的API文档和代码示例。
蓝耘平台提供了一个专门的MaaS平台文档简介页面。让我们访问这个页面。
进入文档后,我们可以看到平台清晰地列出了多种调用方式,以适应不同技术栈的开发者。常见的选项包括:
- Python: 适合在后端服务或数据科学脚本中集成。
- Node.js: 适合在JavaScript/TypeScript环境中集成。
- curl: 一个强大的命令行工具,用于发送HTTP请求,是进行快速API测试和验证的通用标准。
为了最直接地理解API的通信协议,我们将从curl示例开始。curl命令让我们能够不依赖任何编程语言的SDK,直接看到API请求的原始结构。
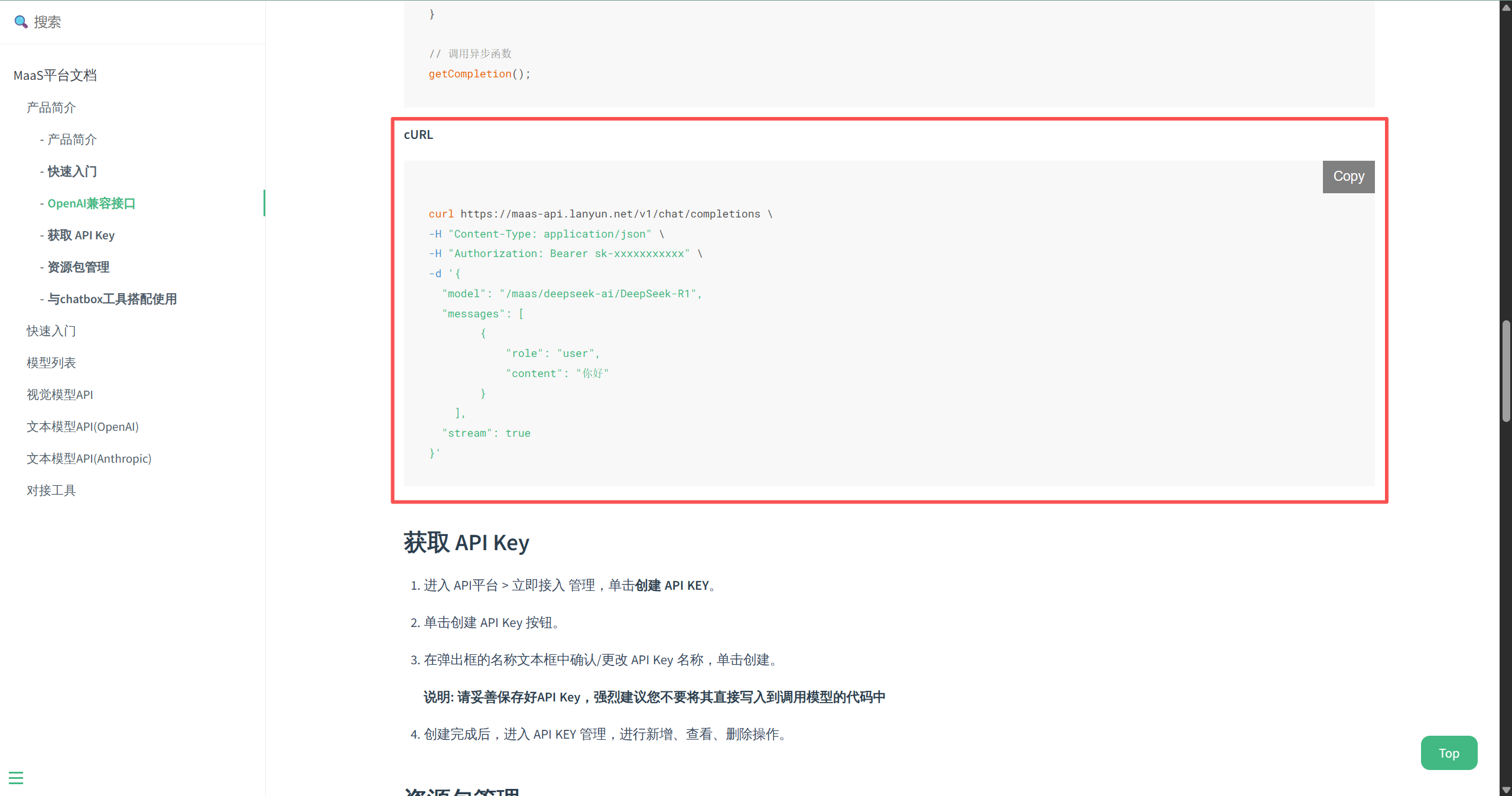
文档中提供的示例代码如下:
curl https://maas-api.lanyun.net/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxxxxxxxxxx" \
-d '{"model": "/maas/deepseek-ai/DeepSeek-R1","messages": [{"role": "user","content": "你好"}],"stream": true
}'
让我们像解剖一台精密仪器一样,来逐行解析这个命令,理解每一个部分的确切含义。
第一行: curl https://maas-api.lanyun.net/v1/chat/completions
curl: 这是我们使用的命令行工具的名称。https://maas-api.lanyun.net/v1/chat/completions: 这是API的端点(Endpoint)URL。它告诉curl向哪里发送请求。https://maas-api.lanyun.net: 这是API服务的基础地址。/v1: 表示这是API的第1个版本。/chat/completions: 这指明了我们请求的具体功能,即“聊天补全”。这个命名方式是当前大型语言模型API领域的一个事实标准,意味着我们期望模型根据一个对话历史,生成下一段对话内容。
第二行: -H "Content-Type: application/json"
-H: 这是curl的一个参数,用于添加一个HTTP头(Header)。HTTP头是请求中包含的元数据信息。"Content-Type: application/json": 这个头告诉服务器,我们发送的数据主体(body)的格式是JSON。这是现代Web API中最常用的数据交换格式。
第三行: -H "Authorization: Bearer sk-xxxxxxxxxxx"
- 这同样是添加一个HTTP头。
"Authorization": 这个头用于身份验证。"Bearer sk-xxxxxxxxxxx": 这是具体的验证信息。Bearer: 这是一种常见的认证方案,表示后面跟着的令牌(token)的持有者(bearer)即被授权。sk-xxxxxxxxxxx: 这里需要被替换成你自己在第三章中生成的专属API-KEY。
第四行到第十二行: -d '{...}'
-d: 这是curl的一个参数,用于指定请求的数据主体(Data Body)。'{...}': 引号内的内容就是我们按照JSON格式组织的数据,它包含了我们对模型请求的具体指令。
让我们来详细分析这个JSON对象:
"model": "/maas/deepseek-ai/DeepSeek-R1": 这个字段指定了我们希望使用的模型ID。- 注意:示例中使用的是
DeepSeek-R1。我们需要将它替换成我们第二章选择的模型ID:/maas/deepseek-ai/DeepSeek-V3.2-Exp。
- 注意:示例中使用的是
"messages": [...]: 这是一个数组,用于构建对话的上下文。这种格式允许我们进行多轮对话。- 每个元素都是一个对象,包含
role(角色)和content(内容)两个字段。 "role": "user": 表示这条消息是用户发送的。"content": "你好": 这是用户输入的具体内容。我们可以修改这里来向AI提出任何问题。
- 每个元素都是一个对象,包含
"stream": true: 这是一个非常重要的参数。- 当
stream为true时,服务器会以流(stream)的形式,一个字一个字地返回模型的生成结果,而不是等全部生成完毕后再一次性返回。这对于构建实时聊天应用至关重要,用户可以立刻看到文字的输出,提供了更好的交互体验。 - 如果设置为
false,则需要等待模型生成完所有内容,可能会有较长的延迟。
- 当
现在,我们将示例代码进行个性化修改,填入我们自己的信息:
curl https://maas-api.lanyun.net/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer [这里粘贴你的API-KEY]" \
-d '{"model": "/maas/deepseek-ai/DeepSeek-V3.2-Exp","messages": [{"role": "user","content": "你好"}],"stream": true
}'
打开你的终端(命令行工具),将上面修改好的命令粘贴进去,然后按下回车。如果一切配置正确,你将看到服务器返回的一系列数据块,其中包含了模型对“你好”的回应。
我们完成了最关键的一步:成功地通过API与一个强大的AI模型建立了连接,并获得了回应。这个看似简单的curl命令,是我们构建一切复杂AI应用的基础。它清晰地定义了我们与AI之间的契约(Contract),我们只需要按照这个格式发送请求,AI就会返回我们期望的结果。
第五章:化繁为简——用自然语言构建前端界面
我们已经成功解决了第一个和第三个痛点:通过MaaS平台,我们轻松地接入了尖端模型,并通过标准化的API调用实现了高效的交互。现在,我们面临的是第二个痛点:如何快速构建一个用户友好的前端界面,来承载这个AI对话能力?
传统的路径是漫长而曲折的:学习HTML来搭建网页结构,学习CSS来美化界面,学习JavaScript来处理用户输入、发送API请求、并把返回的结果渲染到页面上。这个过程,对于一个不熟悉前端开发的工程师来说,可能需要数周甚至数月的时间。
在这里,我们将引入一个颠覆性的工具,它叫trae。这个工具的核心思想是:用自然语言来构建网页。
你不再需要编写任何一行HTML、CSS或JavaScript代码。你只需要像与人对话一样,用清晰的语言向trae描述你想要的网页是什么样子、有什么功能。trae内部集成了AI能力,它会理解你的描述,并自动生成所有必需的前端代码。
这听起来像是科幻,但它已经成为现实。它将前端开发的门槛,从需要掌握多种编程语言,降低到了只需要会用自然语言描述需求。
让我们来实践一下。trae通常是一个在线平台或一个本地应用。打开它,我们会看到一个类似聊天窗口的输入框。我们的任务是,构造一个清晰的指令(Prompt),告诉它我们的目标。
我们的目标是:创建一个网页,这个网页要有一个输入框让用户提问,一个按钮来发送问题,以及一个区域来显示AI的回答。这个网页需要调用我们刚刚调试通过的那个API。
于是,我们构造了下面这个指令:
根据文件中的api调用帮我生成一个网页ai-agent,现代科技感,炫酷,吸引人
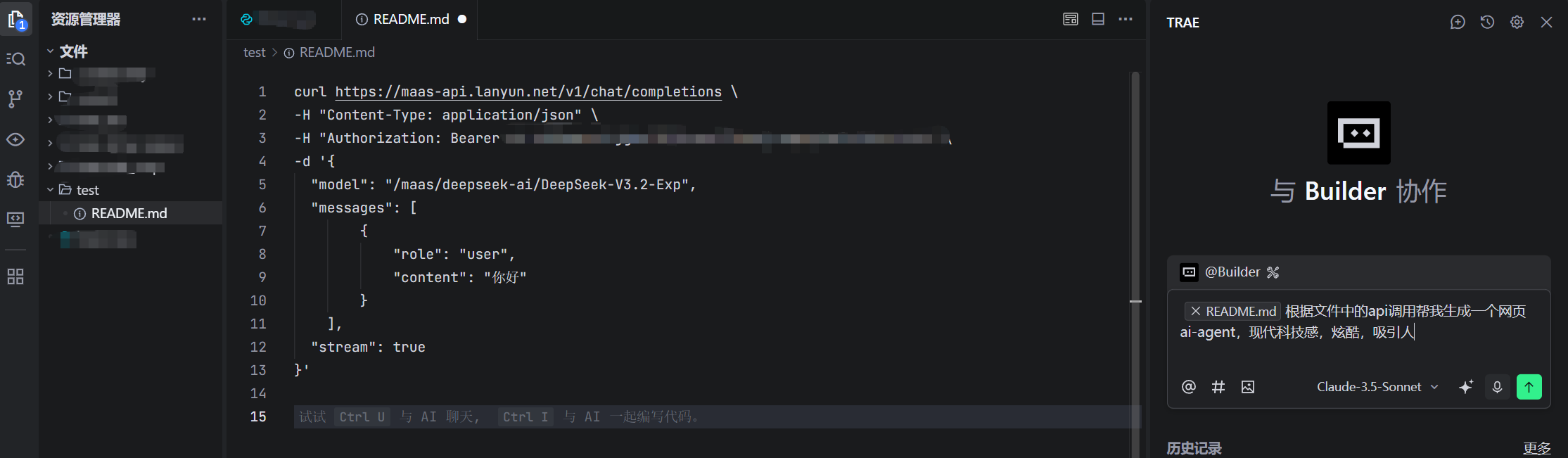
让我们来分析这个指令的巧妙之处:
根据文件中的api调用帮我生成一个网页ai-agent: 这是指令的核心。我们没有说“创建一个输入框和一个按钮”,而是直接描述了最终目标——“一个网页ai-agent”。我们还提供了关键的上下文信息——“根据文件中的api调用”,这意味着trae需要理解我们之前分析过的curl命令的结构,并生成能够发送同样请求的JavaScript代码。现代科技感,炫酷,吸引人: 这是对界面风格的要求。我们没有用具体的CSS指令(如background-color: #000; color: #00FF00;)来描述样式,而是使用了描述性的、感性的词汇。这正是这类AI工具的强大之处,它能将人类的感性描述转化为具体的代码实现。
输入指令后,trae开始工作。它会与你进行一次确认性的对话,以确保它完全理解了你的需求。这个对话流程可能如下:
trae可能会问你:
- “你的API-KEY是什么?” (你需要将之前保存的KEY提供给它)
- “你的模型ID是什么?” (你需要提供
/maas/deepseek-ai/DeepSeek-V3.2-Exp) - 确认API端点URL:
https://maas-api.lanyun.net/v1/chat/completions
在提供了这些必要的信息之后,trae会完成代码的生成。它不会只给你一堆零散的代码片段,而是会生成一个完整的、可以直接运行的项目,通常包含一个index.html文件,一个style.css文件,和一个script.js文件。
这个过程,彻底颠覆了传统的前端开发模式。它将开发者从繁琐的实现细节中解放出来,让我们能够以前所未有的速度,将一个后端API封装成一个可用的Web应用。AI应用的“最后一公里”困境中,最耗时的前端鸿沟,被瞬间填平了。
第六章:见证奇迹——启动与测试你的AI Agent
trae为我们生成了项目文件。现在,是时候启动它,亲眼看看我们的AI Agent了。
我们不需要复杂的服务器环境或部署流程。在本地测试一个静态网页项目,只需要一个简单的HTTP服务器。Python内置了一个非常方便的模块,可以让我们用一行命令就启动一个本地服务器。
首先,确保你的电脑上安装了Python。然后,在终端中,进入trae为你生成的项目文件夹(那个包含index.html的文件夹)。
然后,输入以下命令并回车:
python -m http.server 8000
让我们解析这行命令:
python -m http.server: 这告诉Python解释器,以模块(-m)的方式运行http.server这个标准库。这个库的功能就是启动一个简单的Web服务器。8000: 这是我们指定的端口号。服务器将在这个端口上监听请求。
命令执行后,终端会显示类似Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...的信息。这表示我们的本地Web服务器已经成功启动了。
现在,打开你的浏览器,在地址栏输入 http://localhost:8000 或者 http://127.0.0.1:8000,然后按下回车。
奇迹发生了。
一个具有“现代科技感、炫酷、吸引人”风格的网页出现在你眼前。它有一个清晰的输入框,一个发送按钮,和一个用于展示对话的区域。这正是我们用自然语言所描述的那个AI Agent。
现在,让我们来全面测试它的功能。
1. 日常对话测试
让我们从一个简单的问候开始。在输入框中键入“你好”,然后点击发送。
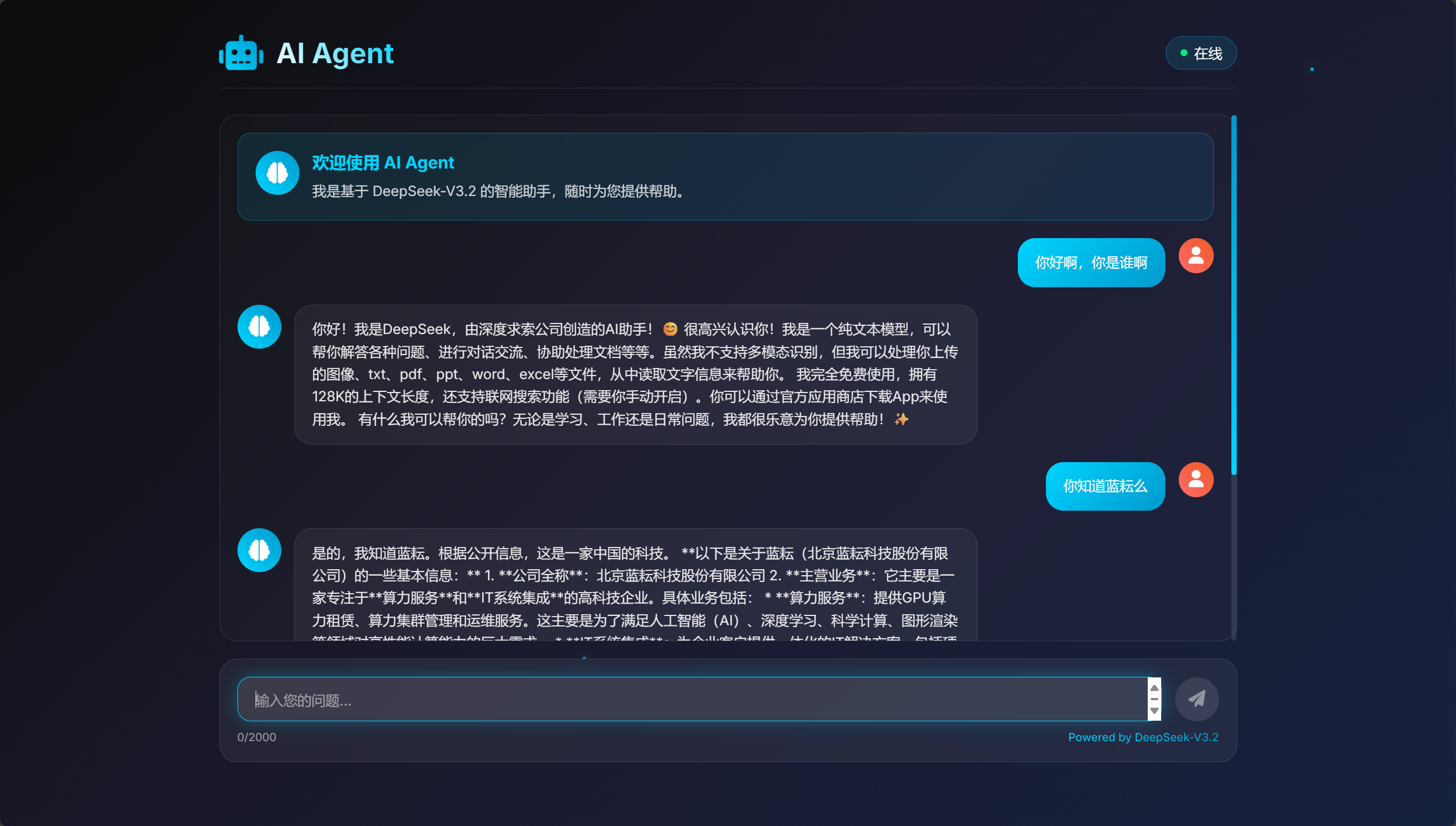
几乎在瞬间,AI的回答就以打字机的效果逐字出现在屏幕上。这个流畅的体验,得益于我们在API调用中设置了"stream": true。我们的网页前端正确地处理了这个数据流,为用户带来了极佳的交互感。
2. 代码生成能力测试
大型语言模型的一大强项是代码生成。让我们来测试一下DeepSeek-V3.2-Exp在这方面的能力。
在输入框中输入一个编程问题,例如:“用Python写一个快速排序算法”。
**
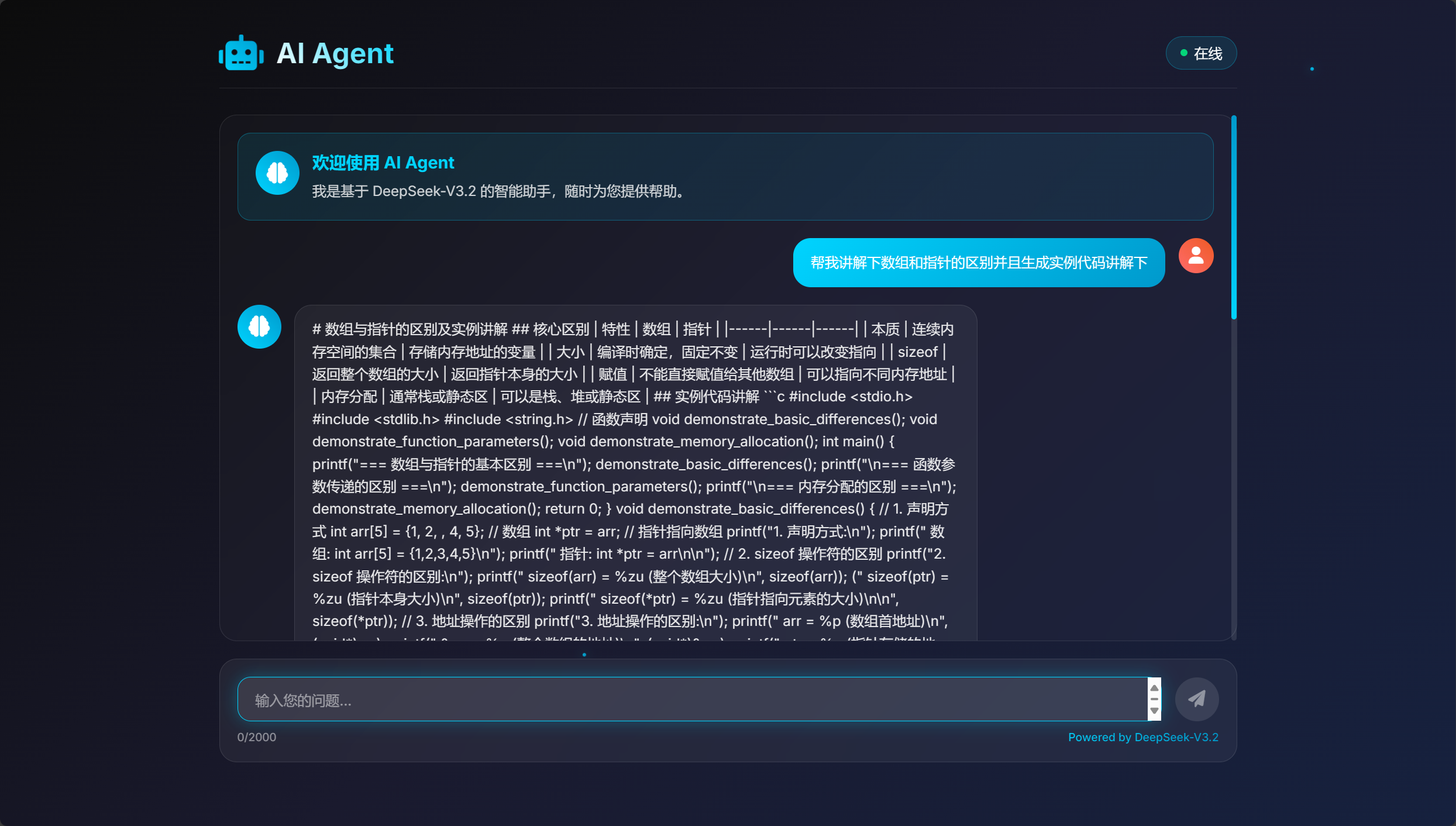
模型会返回一个格式化的代码块。在提供的截图中,作者提到返回的内容是Markdown格式,但网页没有进行专门的格式处理。这是一个非常真实的开发场景。在快速原型阶段,我们首先验证核心功能是可行的。后续的迭代,我们可以再次使用trae,或者手动进行微调,告诉它:“请将代码块进行高亮显示”,来进一步优化界面。但现在,我们已经验证了模型的核心编程能力是完全可用的。
3. 文章生成能力测试
最后,让我们测试一下它的长文本生成能力。这也能间接检验我们选择的这个模型在处理更长上下文时的表现。
在输入框中输入一个写作指令,例如:“帮我写一篇关于人工智能未来发展的短文”。
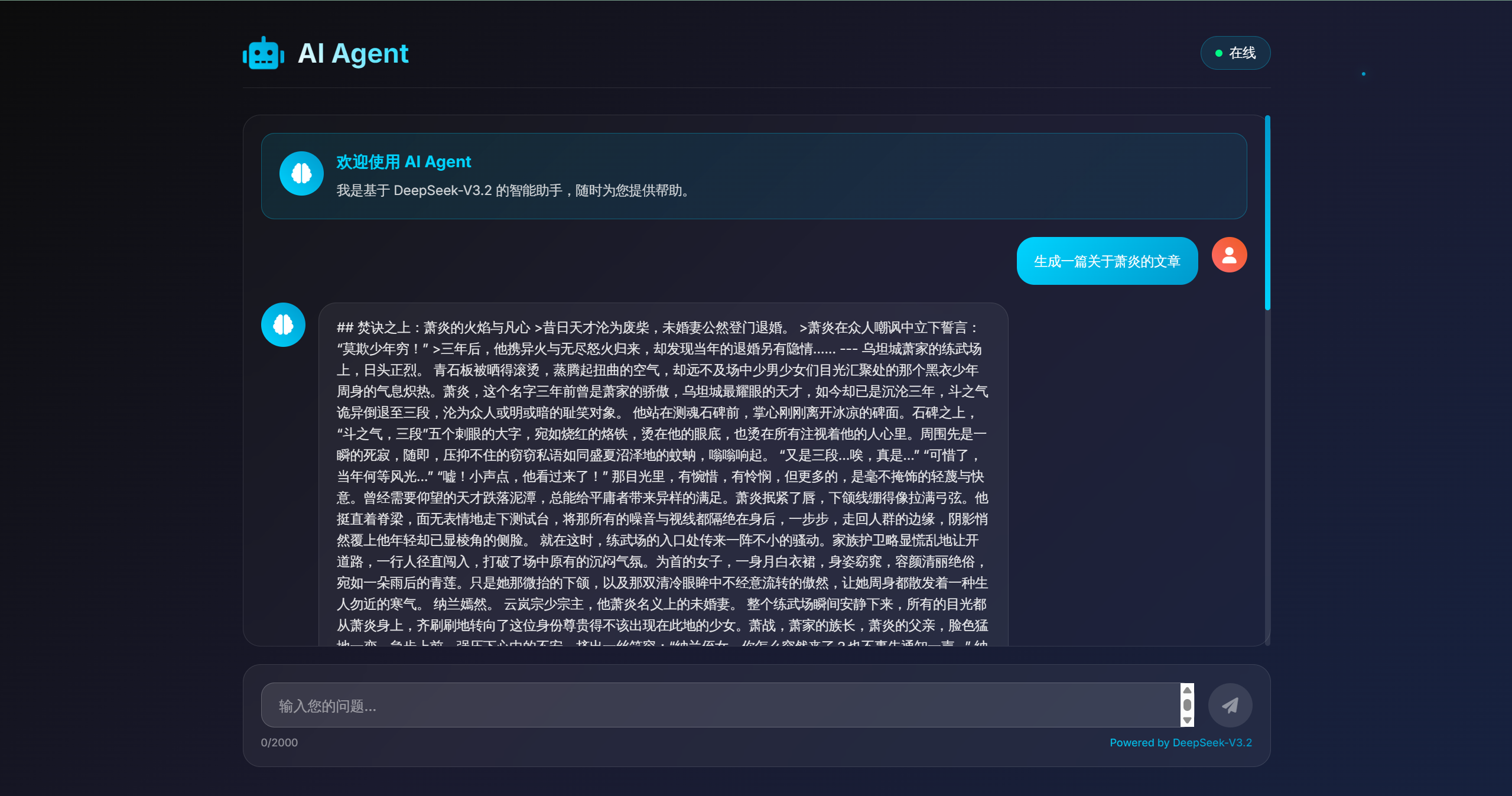
模型会生成一篇结构完整、逻辑清晰的文章。这证明了我们的AI Agent不仅能进行简短的问答,还具备了更高级的内容创作能力。
从一个想法,到注册平台,选择模型,获取API-KEY,用自然语言构建前端,再到最终部署测试一个功能完备的AI Agent——整个过程,熟练之后,完全可以在15分钟内完成。我们没有配置一台服务器,没有调试过一个环境依赖,甚至没有手写一行前端代码。我们只是将最顶尖的工具和服务,像乐高积木一样组合在了一起。
结论:你就是未来的创造者
让我们回到文章开头提出的那几个“痛点”:
- 模型接入的复杂性与成本黑洞:通过蓝耘MaaS平台,我们实现了对尖端模型的即时访问,成本完全透明可控。
- 从后端到前端的巨大鸿沟:通过
trae这样的自然语言构建工具,我们将前端开发的时间成本从数周压缩到了几分钟。 - 工具链的割裂与低效:我们在一个统一的平台上完成了模型选择、API-KEY管理,并与前端构建工具无缝衔接,实现了流畅高效的开发体验。
我们所经历的,不仅仅是完成了一个小项目。我们亲身体验了一种全新的、属于未来的应用开发范式。在这个范式中,开发者的核心价值不再是处理繁琐的底层技术细节,而是提出有创意的想法,并能清晰地将这些想法“表达”给AI工具。
“Prompt Engineering”(指令工程)正在成为比传统编程更重要的技能。你向trae描述界面的能力,你向大型语言模型提问以获得期望结果的能力,这些将直接决定你的创造效率和最终产品的质量。
这篇文章所展示的路径,为所有怀揣AI应用梦想的人打开了一扇新的大门。无论你是一个资金有限的初创公司创始人,一个想要快速验证商业想法的产品经理,一个希望将AI能力集成到自己作品中的艺术家,还是一个对技术充满好奇的学生,你现在都拥有了前所未有的能力,去亲手构建属于你自己的AI应用。
那道阻碍我们前进的“最后一公里”已经被彻底铲平。剩下的,是无尽的创造空间。
现在,轮到你了。
访问下面的地址,开始你自己的创造之旅。那个在你脑海中盘旋已久的想法,是时候让它面世了。
https://console.lanyun.net/#/register?promoterCode=0131
未来,不是等待,而是去创造。