【AI论文】LongLive:实时交互式长视频生成
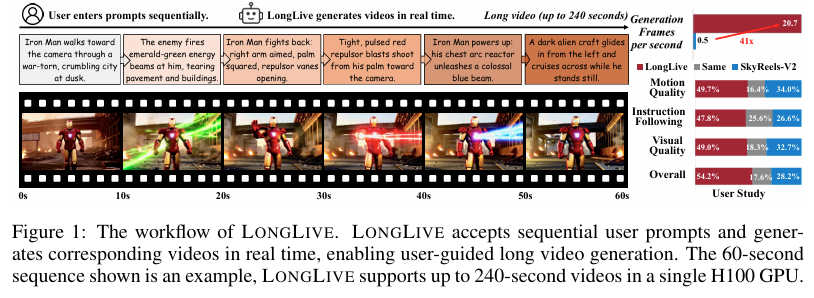
摘要:我们提出LongLive——一种用于实时交互式长视频生成的帧级自回归(AR)框架。长视频生成在效率和质量方面均面临挑战。扩散模型(Diffusion)和扩散强制模型(Diffusion-Forcing)虽能生成高质量视频,但因双向注意力机制而效率低下。因果注意力自回归模型支持键值(KV)缓存以实现更快的推理,但受限于长视频训练过程中的内存挑战,生成的长视频质量往往下降。此外,除基于静态提示词的生成外,流式提示词输入等交互功能对动态内容创作至关重要,可让用户实时引导叙事。这一交互需求大幅增加了复杂度,尤其是在提示词切换期间确保视觉一致性和语义连贯性方面。为应对这些挑战,LongLive采用了因果帧级自回归设计,并整合了KV重缓存机制——该机制通过新提示词刷新缓存状态,实现平滑且贴合的切换;采用流式长调优方法以支持长视频训练,并实现训练与推理(长时长训练-长时长测试)对齐;以及采用短窗口注意力机制与帧级注意力汇聚模块(简称帧汇聚模块)相结合的方式,在保持长程一致性的同时实现更快的生成速度。通过这些关键设计,LongLive仅用32个GPU日便将一个含13亿参数的短视频片段模型微调至可生成分钟级长视频。在推理阶段,LongLive在单块NVIDIA H100 GPU上可保持20.7帧/秒的生成速度,在短、长视频场景下的VBench基准测试中均表现出色。LongLive在单块H100 GPU上可支持生成最长240秒的视频,并进一步支持INT8量化推理,且仅造成微小的质量损失。Huggingface链接:Paper page,论文链接:2509.22622
研究背景和目的
研究背景:
随着数字内容的爆炸性增长,视频生成技术在娱乐、教育、广告等多个领域展现出巨大的应用潜力。
特别是长视频生成技术,由于其能够提供连贯的故事叙述、丰富的场景发展和复杂的时间动态,成为了研究的热点。然而,长视频生成面临两大核心挑战:效率和质量。传统的扩散模型和扩散强迫模型虽然能够生成高质量的视频,但由于依赖双向注意力机制,导致推理效率低下,难以实时生成长视频。另一方面,因果注意力自回归(AR)模型虽然支持KV缓存以实现更快的推理,但在长视频训练过程中常常因内存问题导致质量下降。
此外,传统的静态提示生成方式限制了用户在生成过程中的灵活性,用户难以在视频生成过程中实时引导叙事,这大大限制了动态内容创作的可能性。因此,开发一种既能高效生成长视频,又能支持用户实时交互引导的长视频生成框架,成为当前视频生成领域亟待解决的问题。
研究目的:
本研究旨在提出一种名为LONG LIVE的实时交互式长视频生成框架,该框架旨在解决长视频生成中的效率与质量问题,同时支持用户在视频生成过程中的实时交互引导。
具体目标包括:
- 提高长视频生成效率:通过引入因果注意力、帧级自回归设计以及KV-recache机制,实现高效的实时长视频生成。
- 保证视频生成质量:通过短窗口注意力和帧级注意力汇聚点(frame sink)技术,在加速生成的同时保持长视频的一致性和高质量。
- 支持实时交互:允许用户在视频生成过程中通过连续的提示输入实时引导叙事,增强视频生成的灵活性和可控性。
研究方法
1. 因果注意力与帧级自回归设计:
LONG LIVE采用因果注意力机制,支持KV缓存以实现快速推理。
帧级自回归设计使得模型能够逐帧生成视频,同时通过KV-recache机制在提示切换时刷新缓存状态,确保平滑且一致的过渡。具体实现中,模型在生成新帧时,会结合之前生成的帧和新的提示信息重新计算KV缓存,从而在保持视觉一致性的同时,遵循新的提示。
2. 短窗口注意力与帧级注意力汇聚点:
为了进一步提高生成效率,LONG LIVE引入了短窗口注意力机制,将注意力限制在固定的时间窗口内,减少计算量和内存占用。
同时,通过帧级注意力汇聚点(frame sink)技术,将视频的第一帧作为全局汇聚点,永久保留在KV缓存中,确保长视频生成过程中的长距离一致性。
3. 流式长调优策略:
为了解决传统AR模型在长视频训练中的质量下降问题,LONG LIVE提出了流式长调优策略。
该策略通过在训练过程中模拟推理条件,逐步扩展视频序列长度,并监督整个生成过程,从而对齐训练和推理,减少误差累积,提高长视频生成的一致性和质量。
4. 实时交互实现:
为了实现实时交互,LONG LIVE允许用户在视频生成过程中通过连续的提示输入实时引导叙事。模型在接收到新提示时,会触发KV-recache机制,重新计算KV缓存,确保新提示的有效融入,同时保持视频的平滑过渡。
研究结果
1. 高效的长视频生成:
实验结果表明,LONG LIVE能够在仅32个GPU天内微调出一个13亿参数的短片段模型,实现分钟级的长视频生成。
在单个NVIDIA H100 GPU上,LONG LIVE能够持续以20.7 FPS的速度生成视频,支持最长240秒的视频生成,展现了高效的长视频生成能力。
2. 高质量视频生成:
在VBench基准测试上,LONG LIVE在短视频和长视频设置下均表现出色,实现了高质量的视频生成。
用户研究也表明,LONG LIVE生成的视频在整体质量、运动质量和指令遵循性方面均得到高度评价。
3. 实时交互能力:
LONG LIVE成功支持了实时交互式长视频生成,允许用户在视频生成过程中通过连续的提示输入实时引导叙事。实验结果显示,LONG LIVE在交互式长视频生成中表现出强大的提示遵循性、平滑过渡性和高长距离一致性,同时保持了高吞吐量。
研究局限
尽管LONG LIVE在长视频生成和实时交互方面取得了显著成果,但仍存在以下局限:
1. 基础模型质量的限制:
LONG LIVE是基于预训练的基础模型进行微调的,因此其最终性能受到基础模型容量和质量的限制。
尽管长距离一致性和指令遵循性有所提高,但任何短片段的质量仍不太可能持续超过基础模型。
2. 自监督微调策略的局限性:
虽然自监督微调策略提高了效率和可扩展性,但也限制了模型纠正从基础模型继承的系统错误或偏差的能力。未来研究可以考虑引入监督数据以避免质量瓶颈。
3. 复杂场景下的表现:
尽管LONG LIVE在多个场景下均表现出色,但在处理极其复杂或快速变化的场景时,仍可能出现细微的质量下降或不一致性。
未来研究可以进一步探索如何提高模型在复杂场景下的表现。
未来研究方向
1. 引入监督数据:
为了进一步提高视频生成质量,未来研究可以考虑引入监督数据,以纠正基础模型中的系统错误或偏差,突破自监督微调策略的质量瓶颈。
2. 探索更复杂的交互方式:
目前,LONG LIVE主要支持通过连续提示输入实现的实时交互。未来研究可以探索更复杂的交互方式,如通过语音、手势或眼神追踪等实时引导视频生成,提高交互的自然性和灵活性。
3. 优化长距离一致性:
尽管LONG LIVE通过帧级注意力汇聚点技术提高了长距离一致性,但在处理极其复杂或快速变化的场景时,仍可能出现不一致性。未来研究可以进一步探索如何优化长距离一致性,如通过引入更复杂的注意力机制或上下文建模方法。
4. 扩展至其他视频生成任务:
目前,LONG LIVE主要专注于长视频生成任务。
未来研究可以探索将LONG LIVE框架扩展至其他视频生成任务,如视频编辑、视频超分辨率等,进一步拓展其应用范围。
5. 多模态交互与生成:
随着多模态技术的发展,未来研究可以探索将语音、文本、图像等多种模态的信息融合到视频生成过程中,实现更丰富的交互方式和更生动的视频生成效果。
例如,用户可以通过语音描述期望的视频场景,模型根据语音和文本提示生成相应的视频内容。