Presto:一款免费开源的大数据SQL查询引擎
Presto 是一款免费面向现代数据分析的高性能、分布式 SQL 查询引擎,可以为数据库、大数据以及湖仓一体等存储架构提供统一的 SQL 查询接口。
Presto 项目主要基于 Java 语言开发,遵循 Apache 2.0 开源协议,代码托管在 GitHub,目前已经获得了 16.5K Stars:
https://github.com/prestodb/presto
系统架构
作为一个计算引擎,Presto 本身不存储数据,而是专门用来快速查询外部数据源。
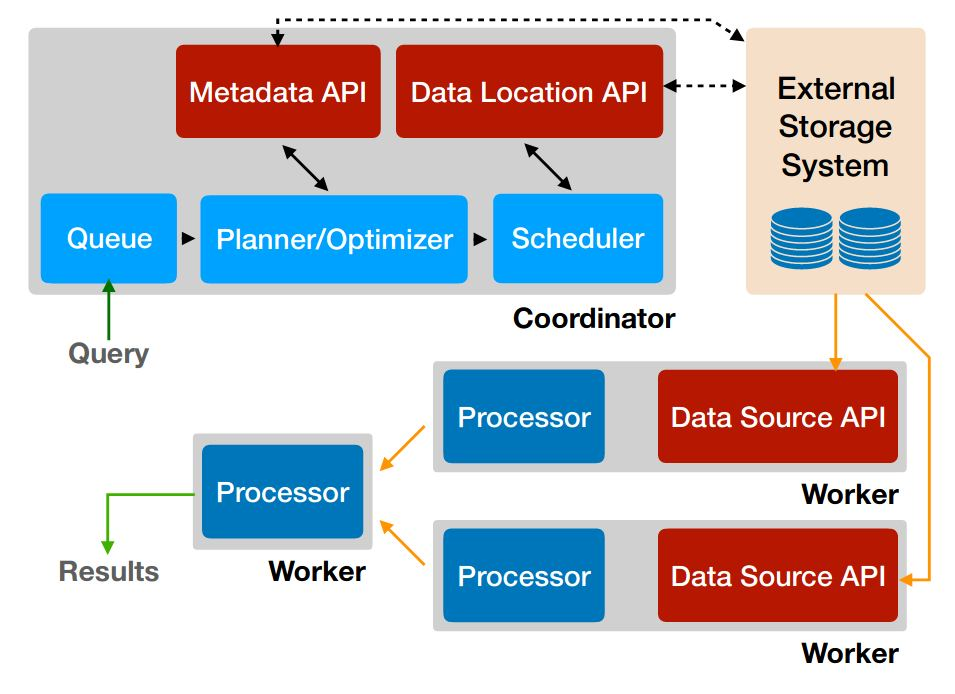
Presto 采用典型的主从(Master-Slave)架构,主要包括两个角色:Coordinator 和 Worker 。
- Coordinator,负责接收客户端的 SQL 查询,主要工作包括:解析 SQL 语句,检查语法,并基于成本生成最优的分布式执行计划;将执行计划分解成多个阶段和任务,并将其分发给 Worker 节点执行;监控所有 Worker 节点的状态,并协调整个查询的执行过程。
- Worker,负责执行具体的数据处理任务,包括连接到数据源读取数据,在内存中对数据进行处理(例如过滤、聚合、关联),将中间结果传递给其他 Worker 进行下一步处理。Worker 节点是并行工作的,数据和处理任务都被分散到所有可用的 Worker,这是 Presto 高性能的基础。
客户端通过 CLI、JDBC、ODBC 等方式连接到 Coordinator 来提交查询。
功能特性
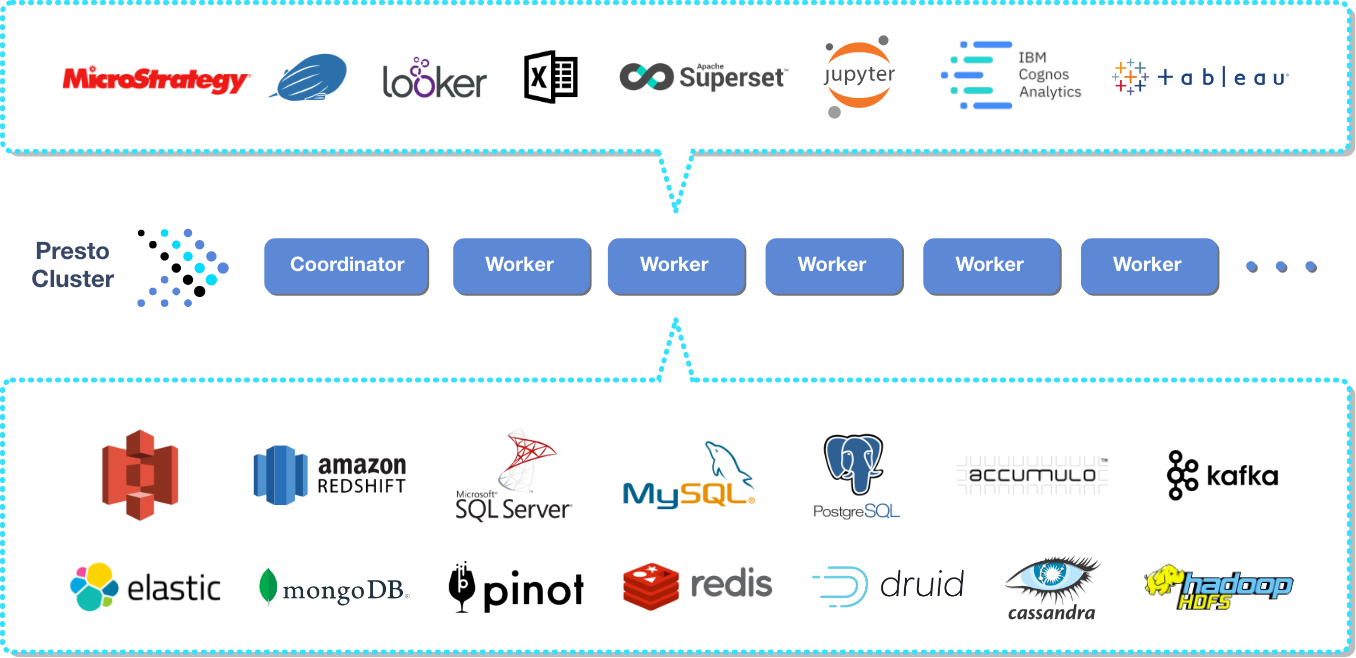
- 连接器:Presto 通过连接器(Connector)支持丰富的数据源,包括 Accumulo、Arrow Flight、BigQuery、Cassandra、ClickHouse、Delta Lake、Druid、Elasticsearch、Google Sheets、HANA、Hive、Hudi、Iceberg、Kafka、MongoDB、MySQL、Oracle、PostgreSQL、Prometheus、Redis、Redshift、ScyllaDB、SingleStore、SQL Server、Thrift、本地文件等。
- 高性能:采用内存计算和流水线执行模型,查询速度比 Hive 快几个数量级(从分钟级降到秒级),非常适合交互式查询和即席分析。
- 标准 SQL:支持 ANSI SQL,学习成本低,现有的 BI 工具(例如 Tableau, Superset)可以轻松地通过 JDBC/ODBC 与之集成。
- 联邦查询:采用用标准 SQL 即可实现跨源分析,打破了数据孤岛。
- 可扩展性: MPP 架构可以轻松地向集群中添加或移除 Worker 节点,实现水平扩展。
- 灵活部署:可以在本地数据中心部署,也可以在云上部署。
- REST API:Presto 提供了一套 RESTful API,允许通过 HTTP 请求直接与服务器交互,完成查询提交、状态监控和集群管理等一系列操作。
- 生态系统:Presto 托管给了 Linux 基金会,社区非常活跃,生态系统在不断扩展中。
下载安装
Presto 支持多种安装方式,使用 Docker 进行部署的命令如下:
docker run -p 8080:8080 -ti prestodb/presto:latest
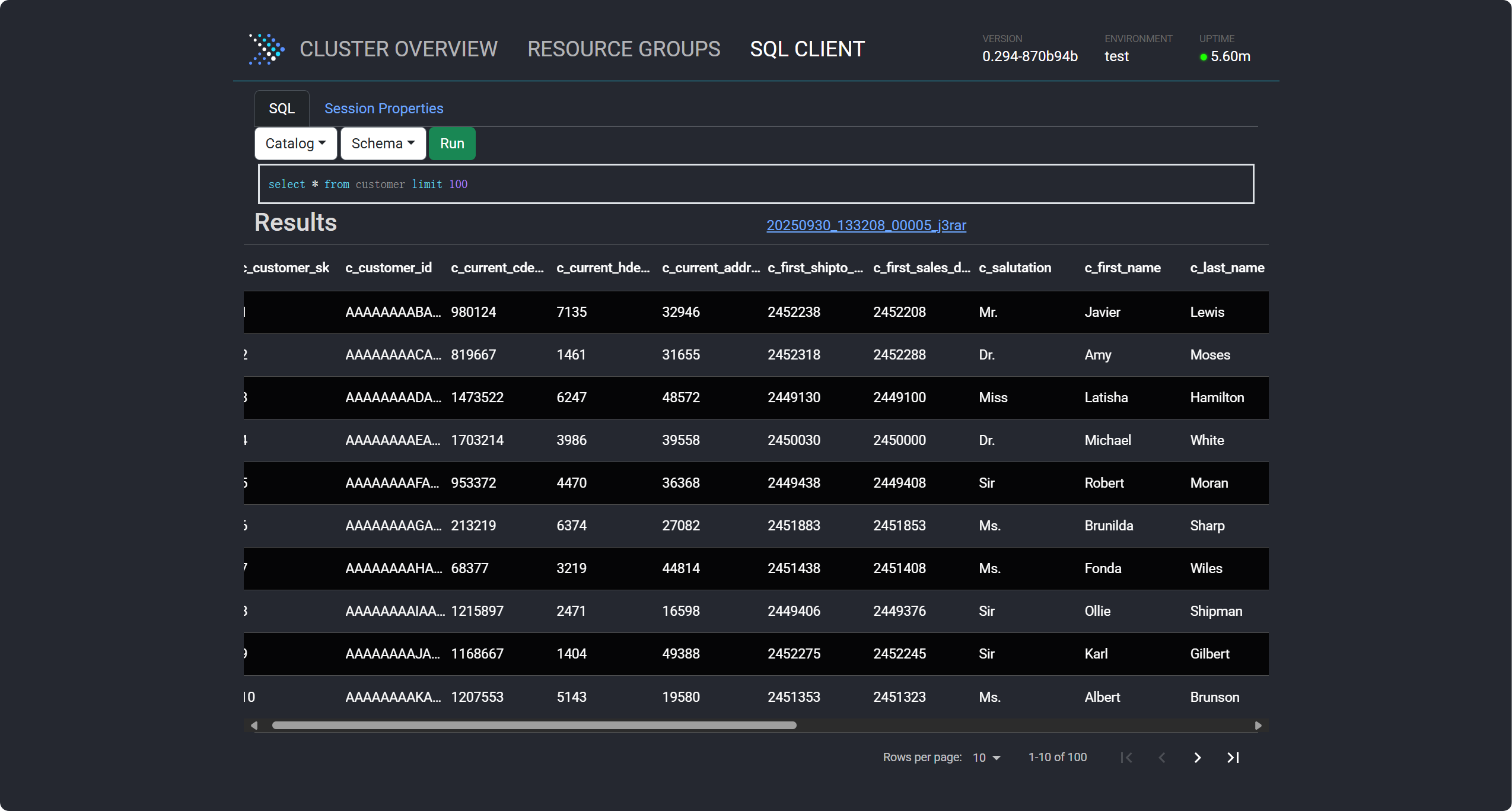
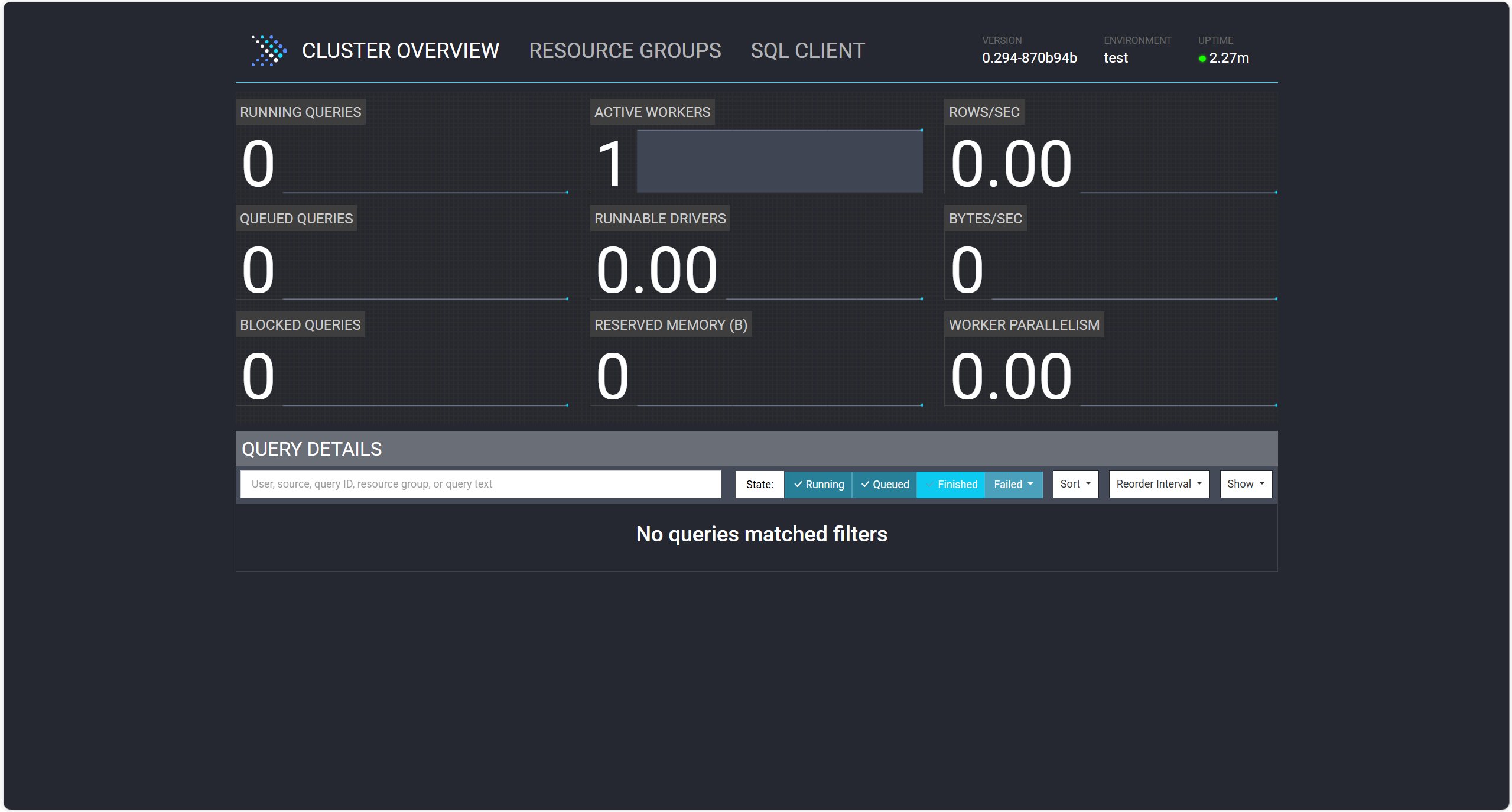
启动服务之后,在浏览器中输入以下地址进行访问:
http://localhost:8080/
官方文档:
https://prestodb.io/docs/current/index.html