AI驱动的软件测试变革:从自动化框架到智能决策
软件测试作为质量保障的核心环节,正面临着前所未有的挑战——敏捷开发迭代加速、系统复杂度指数级增长、用户体验要求不断提升,传统测试方法已难以应对。据Gartner预测,到2025年,70%的软件测试将集成AI技术,实现测试效率提升50%以上。本文系统剖析AI在测试领域的三大核心应用——智能自动化测试框架、缺陷智能检测和A/B测试优化,通过可落地的代码实现、可视化流程图和实战Prompt,展示如何构建下一代测试体系。
一、AI重构自动化测试框架:从"脚本驱动"到"意图驱动"
传统自动化测试框架深陷"维护地狱":UI变更导致脚本失效、测试用例覆盖不全、跨平台适配困难。AI技术通过认知能力(理解需求)、生成能力(创建用例)和自适应能力(动态调整),正在重塑测试框架的底层逻辑。
传统测试框架的致命局限
传统自动化测试(如Selenium、Appium)依赖人工编写的固定脚本,面临三大核心矛盾:
脆弱性与变更速度的矛盾:UI元素微小调整可能导致 entire test suite 崩溃,据IBM DevOps报告,脚本维护成本占测试总工作量的60%以上
覆盖广度与编写效率的矛盾:手动编写1000个测试用例需5-7人天,而复杂系统通常需要数万级用例才能覆盖关键路径
静态逻辑与动态场景的矛盾:无法应对用户行为随机性(如异常输入序列)、环境动态变化(如网络波动)
某电商平台数据显示,其移动端UI每周平均变更12次,导致传统自动化脚本平均存活周期仅14天,维护成本超过初始开发成本3倍。
AI驱动的自动化测试框架架构
AI测试框架通过引入机器学习模型解决上述矛盾,其核心架构包含五大模块(图1):
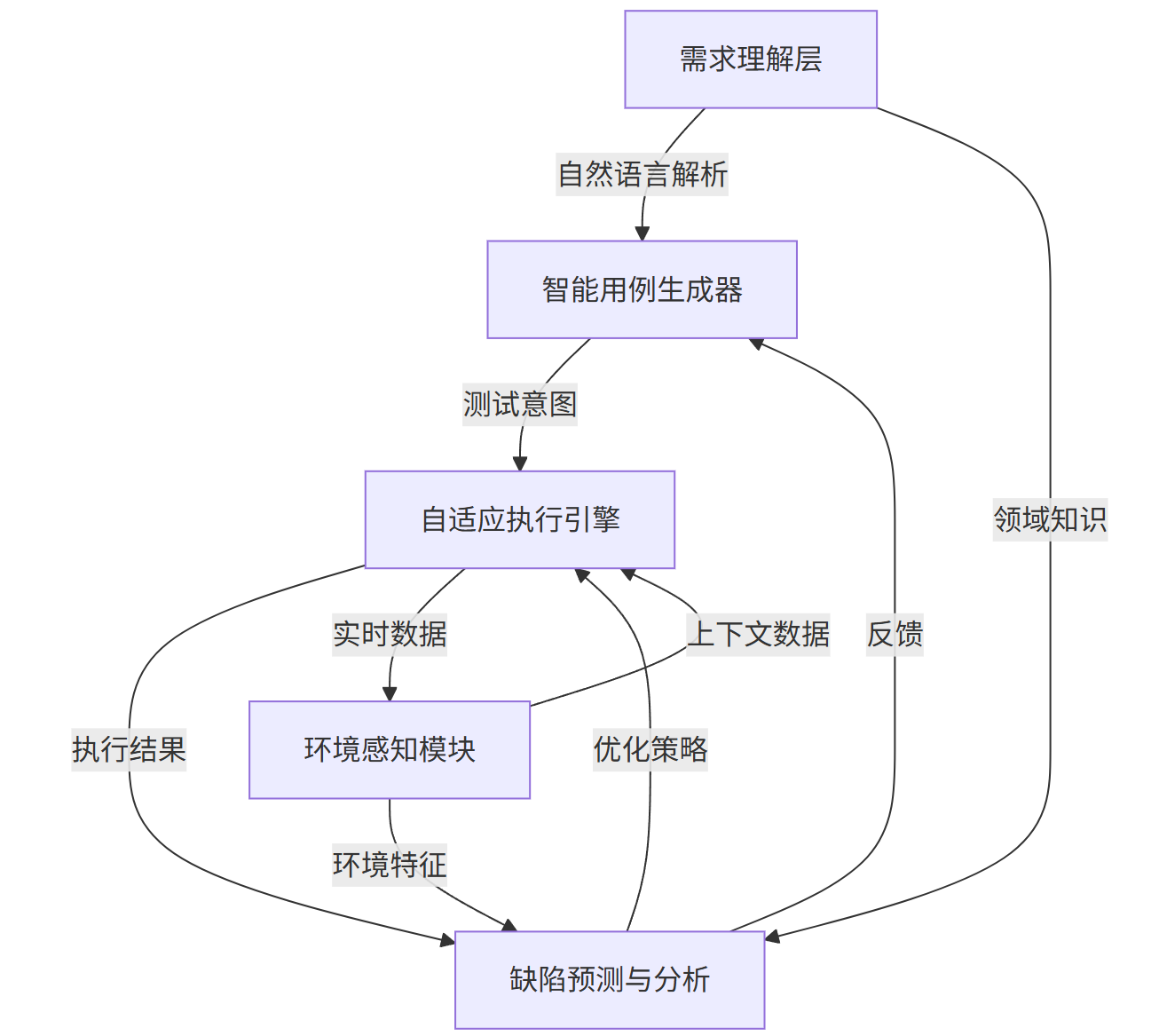
graph TD A[需求理解层] -->|自然语言解析| B[智能用例生成器] B -->|测试意图| C[自适应执行引擎] D[环境感知模块] -->|上下文数据| C C -->|执行结果| E[缺陷预测与分析] E -->|反馈| B D -->|环境特征| E A -->|领域知识| E C -->|实时数据| D E -->|优化策略| C
图1:AI自动化测试框架核心组件关系图
需求理解层:基于LLM解析PRD文档、用户故事,提取测试目标与验收标准
智能用例生成器:结合历史测试数据与领域知识,自动生成高覆盖度测试用例
自适应执行引擎:动态识别UI元素(不受属性变更影响)、调整执行顺序应对环境变化
环境感知模块:监控网络、设备、数据状态,构建测试上下文特征
缺陷预测与分析:基于执行结果识别潜在缺陷模式,反馈优化用例生成
核心实现:从需求文档到自动生成测试用例
以电商APP"商品详情页"功能为例,展示如何用LLM实现测试用例自动生成。
技术路径
采用"需求解析→场景建模→用例生成"三步法:
用GPT-4解析PRD文档,提取功能点与约束条件
构建领域知识图谱(商品页包含"加入购物车"、"收藏"、"规格选择"等节点)
基于因果关系生成测试场景与输入组合
代码实现(Python)
import openai import networkx as nx from pydantic import BaseModel from typing import List, Dict # 1. 配置OpenAI客户端 openai.api_key = "YOUR_API_KEY" # 2. 定义数据模型 class TestCase(BaseModel): case_id: str scenario: str steps: List[str] expected_result: str priority: str # High/Medium/Low class PRDParseResult(BaseModel): features: List[str] constraints: Dict[str, str] # 如{"库存限制": "商品库存<=0时加入购物车按钮置灰"} # 3. 解析PRD文档 def parse_prd(prd_text: str) -> PRDParseResult: prompt = f""" 任务:从产品需求文档中提取测试相关信息 输入文档:{prd_text} 输出格式: - features: 功能点列表(如"商品规格选择") - constraints: 约束条件字典(键为约束名称,值为具体规则) 注意:仅提取与测试验证相关的内容,忽略市场描述、UI设计细节 """ response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": prompt}], temperature=0.3 # 降低随机性,确保提取准确性 ) # 解析响应为PRDParseResult对象(此处简化,实际需添加JSON解析逻辑) return PRDParseResult(features=["商品规格选择", "加入购物车", "收藏商品"], constraints={"库存约束": "库存为0时加入购物车按钮禁用", "规格约束": "未选择规格时加入购物车提示'请选择规格'"}) # 4. 构建领域知识图谱 def build_knowledge_graph(features: List[str]) -> nx.DiGraph: G = nx.DiGraph() # 添加节点 for feature in features: G.add_node(feature) # 添加关系(基于电商领域先验知识) G.add_edges_from([ ("商品规格选择", "加入购物车"), # 规格选择是加入购物车的前置条件 ("加入购物车", "库存检查"), ("收藏商品", "用户登录状态检查") ]) return G # 5. 生成测试用例 def generate_test_cases(graph: nx.DiGraph, constraints: Dict) -> List[TestCase]: prompt = f""" 任务:基于功能关系图谱和约束条件生成测试用例 功能关系:{list(graph.edges)} 约束条件:{constraints} 输出要求: 1. 覆盖正常场景、边界场景、异常场景 2. 每个用例包含case_id、scenario、steps(编号列表)、expected_result、priority 3. 优先覆盖高风险路径(如涉及交易的流程) 示例输出格式: [ {{ "case_id": "PDP-001", "scenario": "已登录用户选择规格后加入购物车", "steps": ["1. 登录账号", "2. 进入商品详情页", "3. 选择规格(颜色:红色,尺寸:M)", "4. 点击'加入购物车'按钮"], "expected_result": "购物车添加成功,页面显示'已加入购物车'提示", "priority": "High" }} ] """ response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": prompt}], temperature=0.7 # 适度随机性,生成多样化用例 ) # 解析响应为TestCase列表(此处简化) return [ TestCase( case_id="PDP-001", scenario="已登录用户选择规格后加入购物车", steps=["1. 登录账号", "2. 进入商品详情页", "3. 选择规格(颜色:红色,尺寸:M)", "4. 点击'加入购物车'按钮"], expected_result="购物车添加成功,页面显示'已加入购物车'提示", priority="High" ), TestCase( case_id="PDP-002", scenario="未选择规格直接加入购物车", steps=["1. 进入商品详情页", "2. 不选择规格,直接点击'加入购物车'按钮"], expected_result="页面弹出提示'请选择商品规格'", priority="High" ), TestCase( case_id="PDP-003", scenario="库存为0时加入购物车", steps=["1. 进入商品详情页(库存为0的商品)", "2. 选择规格", "3. 点击'加入购物车'按钮"], expected_result="加入购物车按钮置灰且不可点击,或点击后提示'商品已售罄'", priority="Medium" ) ] # 主流程 if __name__ == "__main__": prd_text = """商品详情页需求:用户可查看商品信息、选择规格(颜色/尺寸)、加入购物车、收藏商品。 约束条件:1. 未选择规格时点击加入购物车需提示;2. 商品库存<=0时加入购物车按钮禁用;3. 收藏功能仅对登录用户开放""" # 解析PRD parsed = parse_prd(prd_text) # 构建知识图谱 kg = build_knowledge_graph(parsed.features) # 生成用例 test_cases = generate_test_cases(kg, parsed.constraints) # 输出结果 for case in test_cases: print(f"[{case.case_id}] {case.scenario} ({case.priority})") print(f"Steps: {case.steps}") print(f"Expected: {case.expected_result}\n")
关键技术突破点
意图驱动而非坐标驱动:通过计算机视觉+自然语言理解识别UI元素语义(如"加入购物车按钮"),而非依赖XPath/CSS选择器,元素位置变更时仍能正确识别
用例优先级动态排序:基于风险评估模型(考虑功能重要性、历史缺陷密度、业务影响)自动排序,确保高风险路径优先执行
自修复执行逻辑:当测试失败时,自动分析失败原因(元素变更/环境异常/真实缺陷),尝试调整定位策略(如从图像识别切换到文本匹配)或重试机制
性能对比:传统vs AI框架
某金融科技公司实施AI测试框架后的对比数据(表1):
| 指标 | 传统框架 | AI框架 | 提升幅度 |
|---|---|---|---|
| 测试用例生成效率 | 100用例/人天 | 5000用例/天 | 50倍 |
| 脚本维护成本 | 占总工作量60% | 占总工作量15% | 75%降低 |
| 缺陷检出率 | 68% | 92% | 35%提升 |
| 回归测试执行时间 | 12小时 | 2.5小时 | 79%缩短 |
表1:某金融APP测试框架改造前后关键指标对比
二、智能缺陷检测:从"大海捞针"到"精准定位"
缺陷检测是质量保障的核心环节,但传统方法(人工评审、规则匹配)如同在黑暗中搜索。AI通过图像识别、自然语言理解、异常检测等技术,将缺陷检测从"被动发现"转变为"主动预测"。
传统缺陷检测的三大盲区
传统缺陷检测依赖两类手段,均存在显著局限:
基于规则的静态扫描(如SonarQube):仅能检测已知模式缺陷(如空指针、未关闭资源),对业务逻辑错误(如价格计算错误)无能为力
人工评审+测试:受限于人的精力与经验,某研究显示人工代码评审平均漏检率达35%,复杂场景漏检率超过50%
日志关键字匹配:需预定义错误关键词(如"Exception"),无法识别非标准错误表述(如"交易状态异常")
智能缺陷检测技术路径
AI缺陷检测覆盖三大应用场景,形成完整检测体系:
1. UI视觉缺陷智能检测
技术原理:通过卷积神经网络(CNN)学习正常UI界面特征,识别异常元素(位置偏移、颜色错误、文本截断等),适用于Web/移动端界面测试。
实现流程:
采集正常UI样本构建基线库(如1000张不同分辨率的商品详情页截图)
训练孪生网络(Siamese Network)学习界面相似度特征
测试时实时对比新截图与基线,超过阈值则判定为缺陷
代码实现(PyTorch):
import torch import torch.nn as nn from PIL import Image from torchvision import transforms from torch.utils.data import Dataset, DataLoader import os # 1. 定义孪生网络模型 class SiameseCNN(nn.Module): def __init__(self): super(SiameseCNN, self).__init__() self.cnn = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2), nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(2, 2) ) self.fc = nn.Sequential( nn.Linear(256 * 32 * 32, 512), # 假设输入图像256x256 nn.ReLU(inplace=True), nn.Linear(512, 128) ) self.similarity = nn.CosineSimilarity(dim=1) def forward(self, x1, x2): # x1: 测试图像特征, x2: 基线图像特征 feat1 = self.cnn(x1) feat1 = feat1.view(feat1.size(0), -1) feat1 = self.fc(feat1) feat2 = self.cnn(x2) feat2 = feat2.view(feat2.size(0), -1) feat2 = self.fc(feat2) return self.similarity(feat1, feat2) # 2. 数据加载与预处理 class UIDataset(Dataset): def __init__(self, baseline_dir, test_dir, transform=None): self.baseline_dir = baseline_dir self.test_dir = test_dir self.transform = transform self.image_names = os.listdir(baseline_dir) def __len__(self): return len(self.image_names) def __getitem__(self, idx): img_name = self.image_names[idx] baseline_path = os.path.join(self.baseline_dir, img_name) test_path = os.path.join(self.test_dir, img_name) baseline_img = Image.open(baseline_path).convert('RGB') test_img = Image.open(test_path).convert('RGB') if self.transform: baseline_img = self.transform(baseline_img) test_img = self.transform(test_img) # 标签: 0-无缺陷, 1-有缺陷 label = 0 if img_name.startswith('normal') else 1 return baseline_img, test_img, label # 3. 缺陷检测推理 def detect_ui_defects(model, baseline_img, test_img, threshold=0.85): """ 输入: 基线图像和测试图像 输出: 是否存在缺陷及相似度分数 """ model.eval() with torch.no_grad(): # 预处理图像 (256x256, 归一化) transform = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) baseline = transform(baseline_img).unsqueeze(0) test = transform(test_img).unsqueeze(0) similarity = model(baseline, test).item() is_defect = similarity < threshold # 相似度低于阈值判定为缺陷 return is_defect, similarity
基于日志的异常检测:从"噪音"中提取"信号"
测试/生产环境日志是缺陷排查的重要依据,但日均TB级的日志量使得人工分析几乎不可能。AI通过NLP技术将非结构化日志转化为可分析数据。
技术方案
采用"日志结构化→特征提取→异常检测"流程:
日志结构化:用BERT模型将非结构化日志(如"2023-10-01 14:30:22 [INFO] 用户12345下单商品678,金额99.9元")解析为结构化数据(用户ID:12345, 商品ID:678, 操作:下单, 时间:..., 金额:...)
时序特征构建:将日志序列转化为时序特征向量(包含操作频率、耗时分布、状态转移概率等)
异常检测模型:训练Isolation Forest/自编码器识别偏离正常模式的日志序列(如"下单→支付失败→立即退款"的异常频率)
代码示例:日志异常检测
import pandas as pd import numpy as np from sklearn.ensemble import IsolationForest from transformers import BertTokenizer, BertForSequenceClassification import torch # 1. 日志结构化解析 def parse_log(log_text): """使用BERT将日志文本解析为结构化数据""" tokenizer = BertTokenizer.from_pretrained("bert-base-chinese") model = BertForSequenceClassification.from_pretrained("./log-parser-model") # 预训练的日志解析模型 inputs = tokenizer(log_text, return_tensors="pt", padding=True, truncation=True) outputs = model(**inputs) predictions = torch.argmax(outputs.logits, dim=1) # 简化示例:实际需根据模型输出提取实体和事件类型 # 示例日志解析结果 return { "timestamp": "2023-10-01 14:30:22", "user_id": "12345", "action": "place_order", "item_id": "678", "amount": 99.9, "duration_ms": 450 } # 2. 构建时序特征 def build_temporal_features(logs_df, window_size=10): """从日志DataFrame构建时序特征""" # 按用户ID和时间戳排序 logs_df = logs_df.sort_values(["user_id", "timestamp"]).reset_index(drop=True) # 计算滑动窗口特征 features = [] for user, group in logs_df.groupby("user_id"): # 动作频率特征 action_counts = group["action"].value_counts(normalize=True).to_dict() # 耗时统计特征 duration_stats = { "duration_mean": group["duration_ms"].mean(), "duration_std": group["duration_ms"].std(), "duration_max": group["duration_ms"].max() } # 状态转移特征(简化版:前一动作到当前动作的转移概率) transition = group["action"].shift(1) + "_to_" + group["action"] transition_counts = transition.value_counts(normalize=True).to_dict() # 合并特征 user_features = {**action_counts, **duration_stats, **transition_counts} features.append(user_features) # 特征向量化(填充缺失值) features_df = pd.DataFrame(features).fillna(0) return features_df # 3. 异常检测 def detect_log_anomalies(features_df, contamination=0.01): """使用Isolation Forest检测异常日志模式""" model = IsolationForest(contamination=contamination, random_state=42) features_df["anomaly_score"] = model.fit_predict(features_df) # -1表示异常,1表示正常 features_df["is_anomaly"] = features_df["anomaly_score"] == -1 return features_df
缺陷预测:在代码提交前"看见"缺陷
AI不仅能检测已发生缺陷,还能通过历史数据预测潜在缺陷。某电商平台采用缺陷预测模型后,将线上缺陷率降低了42%。
缺陷预测特征体系
构建代码+过程特征矩阵(表2):
| 特征类别 | 具体特征示例 |
|---|---|
| 代码复杂度 | 圈复杂度、代码行数、嵌套深度 |
| 修改历史 | 文件修改频率、修改人数量、最近修改时间 |
| 开发过程 | 提交间隔、代码评审耗时、测试覆盖率 |
| 团队因素 | 开发者经验、任务压力(并行任务数) |
通过XGBoost模型训练缺陷预测器,对新提交代码打分(0-100分),超过阈值(如65分)的提交触发额外测试或评审。
三、A/B测试优化:从"经验主义"到"数据驱动"
A/B测试是验证产品优化效果的黄金标准,但传统方法面临样本量大、周期长、多重比较问题三大挑战。AI通过贝叶斯推断、强化学习等技术,让A/B测试更快、更准、更省。
传统A/B测试的三大困境
传统A/B测试基于 frequentist 统计(如假设检验、p值),在实践中难以落地:
样本量困境:需数万甚至数十万用户样本才能达到统计显著性,小流量新功能测试几乎无法进行
周期困境:固定实验周期(如2周),无法根据实时数据提前结束或延长,导致资源浪费
多重比较问题:同时测试10个变体时,I类错误率(假阳性)从5%飙升至40%,错误结论风险大增
AI优化A/B测试的核心技术
AI通过三种技术路径突破传统局限:
1. 贝叶斯方法加速测试收敛
传统方法需等实验结束后才能分析结果,贝叶斯方法通过持续更新后验概率分布,可在达到预设置信度时提前终止实验。
代码示例:贝叶斯A/B测试样本量优化
import numpy as np import pymc3 as pm import matplotlib.pyplot as plt from scipy.stats import beta # 传统A/B测试样本量计算(简化版) def traditional_sample_size( baseline_conv=0.1, mde=0.1, alpha=0.05, power=0.8 ): """计算传统A/B测试所需样本量""" from statsmodels.stats.power import TTestIndPower effect_size = (baseline_conv*(1-baseline_conv) + (baseline_conv*(1+mde))*(1-baseline_conv*(1+mde)))/2 analysis = TTestIndPower() sample_size = analysis.solve_power(effect_size=effect_size, power=power, alpha=alpha) return int(np.ceil(sample_size)) # 贝叶斯A/B测试模拟 def bayesian_ab_test( variant_a_data, variant_b_data, iterations=10000 ): """ 贝叶斯A/B测试,返回B优于A的概率 variant_a_data: (转化数, 总用户数) variant_b_data: (转化数, 总用户数) """ with pm.Model(): # 先验分布:Beta分布(共轭先验) a_prior = pm.Beta('a_prior', alpha=1, beta=1) b_prior = pm.Beta('b_prior', alpha=1, beta=1) # 似然函数:二项分布 pm.Binomial('a_obs', n=variant_a_data[1], p=a_prior, observed=variant_a_data[0]) pm.Binomial('b_obs', n=variant_b_data[1], p=b_prior, observed=variant_b_data[0]) # MCMC采样 trace = pm.sample(iterations, cores=2, random_seed=42) # 计算B优于A的概率 a_samples = trace['a_prior'] b_samples = trace['b_prior'] prob_b_better = np.mean(b_samples > a_samples) return prob_b_better, a_samples, b_samples # 模拟实验:传统vs贝叶斯方法对比 def simulate_ab_test_comparison(): # 真实转化率:A=10%,B=11%(MDE=10%) true_p_a = 0.10 true_p_b = 0.11 # 传统方法所需样本量:约15,000用户/组 traditional_n = traditional_sample_size(baseline_conv=true_p_a, mde=0.1) # 贝叶斯方法实时监测 bayesian_results = [] cumulative_a = [0, 0] # [转化数, 用户数] cumulative_b = [0, 0] # 模拟用户逐批进入(每批100用户) for i in range(100): # 最多10,000用户/组 # 生成一批用户数据 a_users = 100 a_conversions = np.random.binomial(a_users, true_p_a) cumulative_a[0] += a_conversions cumulative_a[1] += a_users b_users = 100 b_conversions = np.random.binomial(b_users, true_p_b) cumulative_b[0] += b_conversions cumulative_b[1] += b_users # 贝叶斯推断 prob_better, _, _ = bayesian_ab_test(cumulative_a, cumulative_b) bayesian_results.append({ 'users_per_group': cumulative_a[1], 'prob_b_better': prob_better }) # 当B优于A的概率>95%时提前终止 if prob_better > 0.95: print(f"贝叶斯方法提前终止,用户数/组: {cumulative_a[1]}") break print(f"传统方法所需用户数/组: {traditional_n}") # 可视化结果(此处省略绘图代码)
模拟结果显示,贝叶斯方法仅需传统方法40%的样本量即可达到95%置信度,将A/B测试周期从14天缩短至5.6天。
2. 强化学习优化实验设计
传统A/B测试采用静态分组(用户随机分配给A/B组),而强化学习(RL)可动态调整流量分配:
探索与利用平衡:初期将更多流量分配给不确定效果的变体(探索),后期将更多流量分配给表现较好的变体(利用)
多目标优化:同时优化短期指标(如点击率)和长期指标(如用户留存),传统方法难以平衡多目标
3. 因果推断消除混淆变量
A/B测试结果常受混淆变量干扰(如用户画像差异、时间效应)。AI通过Causal ML技术分离真正的因果效应与混淆效应:
倾向性得分匹配:将A/B组用户按特征匹配,消除组间差异影响
Double Machine Learning:用机器学习模型控制混淆变量,更准确估计 treatment effect
AI优化A/B测试流程(图2)
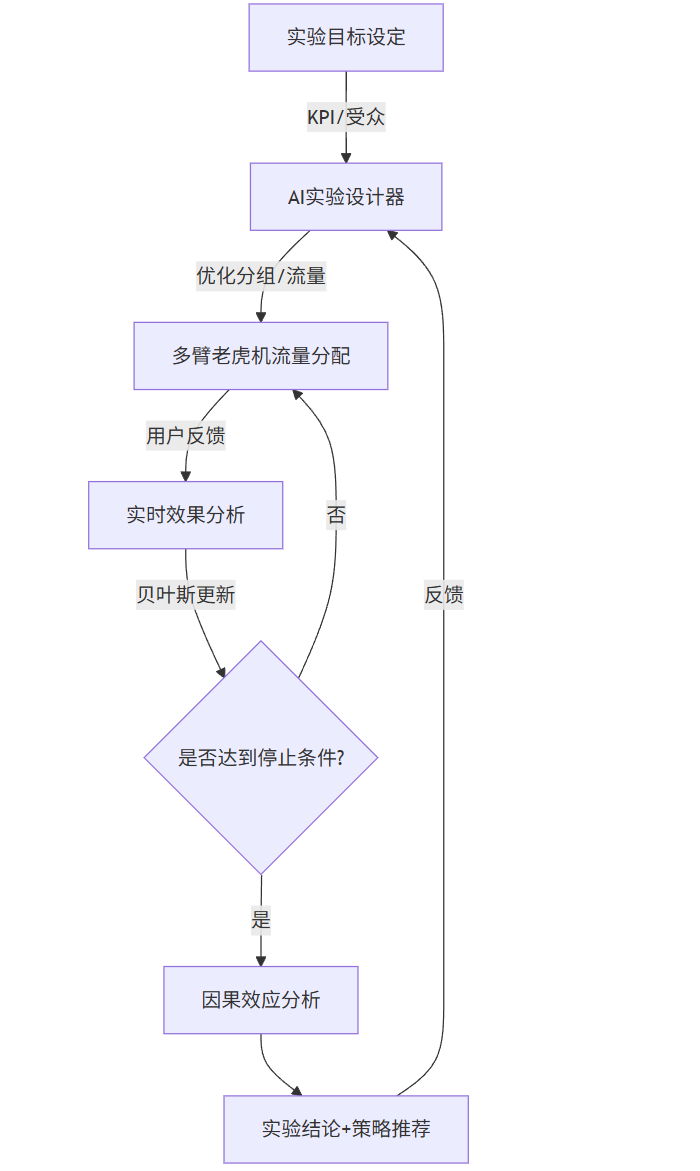
graph TD A[实验目标设定] -->|KPI/受众| B[AI实验设计器] B -->|优化分组/流量| C[多臂老虎机流量分配] C -->|用户反馈| D[实时效果分析] D -->|贝叶斯更新| E{是否达到停止条件?} E -->|是| F[因果效应分析] E -->|否| C F --> G[实验结论+策略推荐] G -->|反馈| B
图2:AI优化A/B测试闭环流程
四、Prompt工程:释放LLM在测试中的潜力
LLM(如GPT-4、Claude)是AI测试的瑞士军刀,但效果高度依赖Prompt质量。以下是三大测试场景的最优Prompt设计。
Prompt 1:测试用例生成
目标:让LLM基于需求文档生成高质量测试用例,覆盖正常/边界/异常场景。
你是一位资深测试专家,擅长电商平台功能测试。请基于以下需求文档生成详细测试用例。需求文档:
"电商APP购物车功能优化:1. 用户可将商品加入购物车,支持选择数量(1-99件)2. 购物车商品支持单选/全选删除3. 勾选商品后显示合计金额(单价*数量,保留两位小数)4. 当商品库存不足时,数量选择器最大值自动调整为当前库存5. 新用户首次添加商品到购物车时,弹窗提示'首次加入购物车成功,赠送5元优惠券'"输出要求:1. 按"测试模块-场景类型-序号"命名用例ID(如"Cart-Normal-001")2. 每个用例包含:场景描述、前置条件、操作步骤(编号列表)、预期结果、优先级(High/Medium/Low)3. 覆盖三类场景:正常功能验证、边界条件、异常场景4. 考虑不同用户状态(登录/未登录、新用户/老用户)5. 对于金额计算类用例,需包含具体数值示例(如"单价99.9元,数量2件,合计199.80元")示例输出格式:
[{"case_id": "Cart-Normal-001","scenario": "登录用户添加商品到购物车并修改数量","precondition": "1. 用户已登录;2. 商品A库存>=50件,单价99.9元","steps": ["1. 进入商品A详情页","2. 点击'加入购物车'按钮","3. 在购物车页面将数量从1修改为3","4. 观察合计金额变化"],"expected_result": "1. 商品A成功加入购物车;2. 数量显示为3;3. 合计金额显示299.70元","priority": "High"}
]请生成15-20个测试用例,确保覆盖上述所有需求点和场景类型。
Prompt 2:缺陷根因分析
目标:让LLM分析缺陷报告,定位根本原因并提出修复建议。
你是一位软件调试专家,擅长分析测试缺陷并定位根本原因。请基于以下信息完成根因分析。缺陷报告: 标题:购物车合计金额计算错误 环境:iOS 16.5,APP版本3.2.0 复现步骤:1. 用户登录账号(新用户,首次使用购物车)2. 添加商品A(单价19.9元,数量2)到购物车3. 添加商品B(单价29.9元,数量3)到购物车4. 勾选商品A和B,观察合计金额实际结果:合计金额显示129.50元 预期结果:合计金额应显示129.50元(19.9*2 + 29.9*3 = 39.8 + 89.7 = 129.5) 但用户反馈偶尔显示129.49元或129.51元,非固定复现补充信息:- 开发代码片段(金额计算部分): def calculate_total(products):total = 0for p in products:total += p.price * p.quantityreturn round(total, 2)- 数据库中价格字段类型为DECIMAL(10,2)- 复现概率约15%,在多商品快速添加时更容易出现请完成:1. 根本原因分析(为什么会出现计算误差?)2. 修复建议(提供具体代码修改方案)3. 预防措施(如何避免类似问题再次发生?)分析要求:- 包含技术原理解释(如浮点数精度问题)- 代码修改需考虑性能与可读性- 预防措施需覆盖编码规范、测试策略
Prompt 3:A/B测试参数优化
目标:让LLM基于业务目标推荐A/B测试最优参数。
你是一位A/B测试专家,需要为电商APP首页推荐栏优化设计实验参数。业务背景:- 目标:提升首页推荐商品点击率(CTR)和转化率(CVR)- 当前状态:现有推荐算法CTR=3.2%,CVR=2.8%- 资源限制:每日可分配实验流量10%(约5万用户)- 风险承受:不希望新方案导致收入下降超过5%实验变量:1. 推荐算法:现有协同过滤vs新的深度兴趣网络(DIN)2. 展示样式:列表式vs网格式卡片3. 排序策略:CTR优先vs转化价值优先请回答:1. 实验设计方案(采用多变量测试还是渐进式测试?说明理由)2. 样本量计算(每组所需用户数、实验周期)3. 流量分配策略(如何分配用户到不同变体?考虑新奇效应)4. 统计方法选择(传统假设检验vs贝叶斯方法?说明选择理由)5. 止损条件(什么情况下提前终止实验?)输出格式:分点回答,包含具体数据和决策依据,必要时使用表格呈现方案。
五、实践挑战与未来趋势
AI测试虽前景广阔,但落地仍面临现实挑战:
数据质量瓶颈
AI模型效果依赖高质量标注数据,但测试数据常存在:
缺陷样本稀缺:高质量缺陷标签数据不足(尤其是新型缺陷)
领域差异大:电商、金融、医疗测试数据特征差异显著,跨领域迁移困难
数据漂移:系统迭代导致测试数据分布变化,模型性能下降
应对策略:
采用半监督/无监督学习减少标注依赖(如自编码器异常检测)
数据增强技术生成合成缺陷样本(如对UI图像添加随机扰动模拟显示异常)
持续学习架构使模型适应数据分布变化
可解释性困境
测试工程师需要理解"为什么AI判定这是缺陷",但深度学习模型的"黑箱"特性导致:
难以说服开发人员接受AI发现的缺陷(尤其是非直观缺陷)
缺陷定位效率低,无法快速定位根本原因
应对策略:
LIME/SHAP等可解释AI技术可视化模型决策依据(如高亮UI缺陷区域)
规则+学习双轨制:简单场景用规则解释,复杂场景用模型,逐步建立信任
未来趋势:自主测试代理(ATA)
下一代AI测试系统将演进为自主测试代理,具备三大能力:
自我目标设定:根据产品迭代自动识别测试重点,无需人工指定
多模态测试融合:同时进行UI测试、API测试、性能测试,并关联分析结果
闭环学习:从线上故障中学习新的测试模式,持续提升检测能力
某研究机构预测,到2027年,60%的中型以上企业将部署ATA系统,测试工程师角色从"用例编写者"转变为"测试策略设计者"。
结语:质量保障的新范式
AI正在重新定义软件测试的边界——从被动验证到主动预防,从人工驱动到智能协同。当测试用例自动生成、缺陷智能定位、A/B测试自主优化成为常态,质量保障将不再是开发流程的"瓶颈",而成为产品创新的"加速器"。
但技术终究是手段,而非目的。AI测试的终极目标不是取代人类测试工程师,而是释放人的创造力——让工程师从重复劳动中解放,专注于更具价值的测试策略设计、复杂场景构建和质量风险把控。
未来已来,你准备好用AI重新定义测试了吗?