LLM 笔记 —— 01 大型语言模型修炼史(Self-supervised Learning、Supervised Learning、RLHF)
01 文字接龙游戏
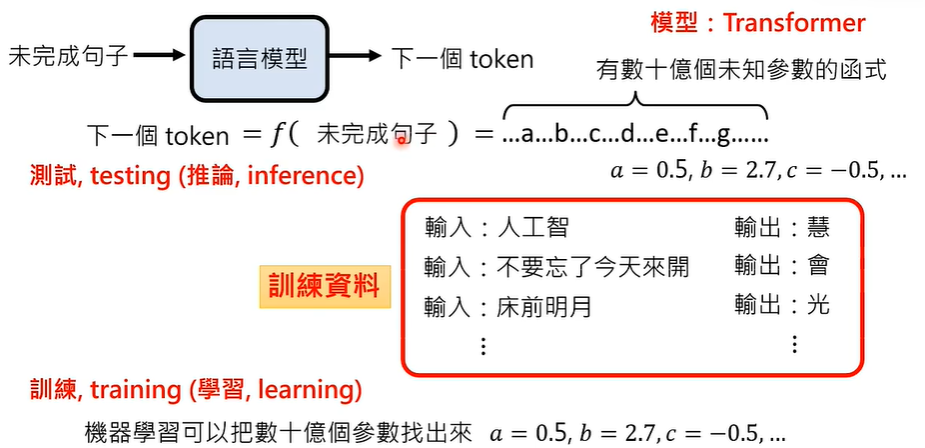
大型语言模型在训练的过程中,需要不断调整超参数以实现效果的最佳化,因为训练可能会失败,需要更换一组超参数重新训练,超参数的数量是上亿级的,需要大量的算力支持。



GPT-3 中存在 1750 亿个参数,组成了将近 28000 个矩阵,细分为八大类别,即 Embedding、Key、Query、Value、Output、Up-projection、Down-projection、Unembedding。

也存在一种情况,训练成功了,测试失败了,这也是一种过拟合现象。
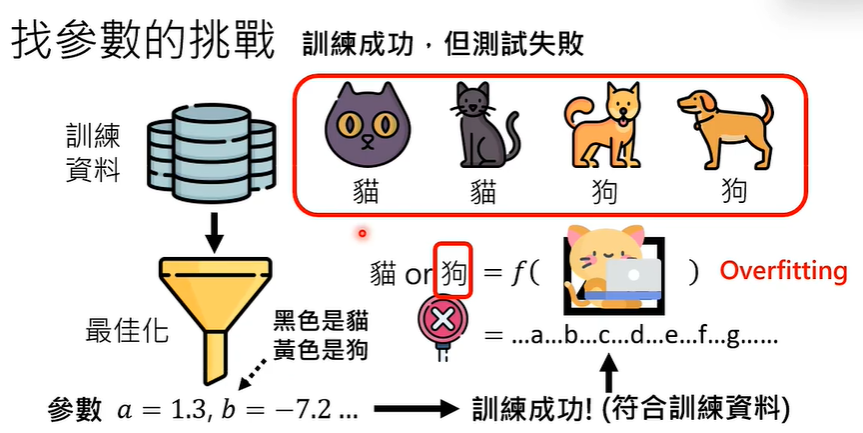
无论怎样,无论我们人类是否能看懂训练出来的参数数值,机器学习的唯一目的是找到的参数有没有【符合】训练资料,而不是有没有道理。
那么,如何让机器找到比较【合理】的参数呢?
- 增加训练资料的多样性
- 设定随机初始参数
- 提供先验知识
02 第一阶段:自我学习,积累实力
需要多少文字才能够学习文字接龙呢?
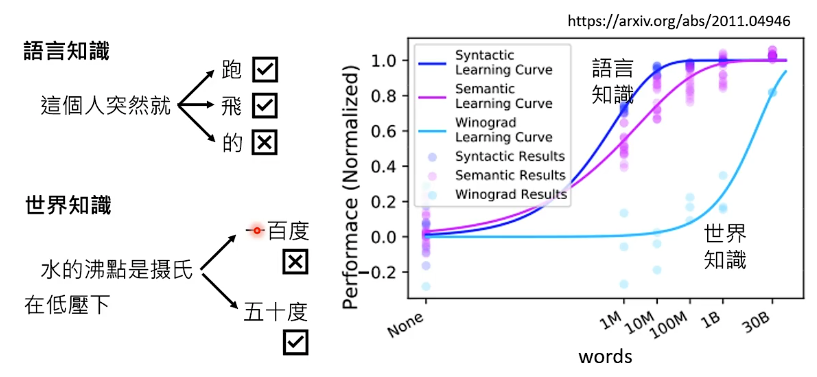
模型需要知道语言知识和世界知识,对于语言知识,是一些基本的拼音、字形、语法,对于世界知识,几乎所有的网络内容都可以作为世界知识拿来训练模型,该方法叫做自督导式学习。
有时,还是需要一些人为干预,比如筛选黄赌毒内容、去除项目符号、去除重复资料等等。
所有的文字资料都能拿来学文字接龙吗?
见仁见智。
为什么模型不能够好好回答问题呢?
因为你没有好好教它回答呀…
03 第二阶段:名师指点,发挥潜力
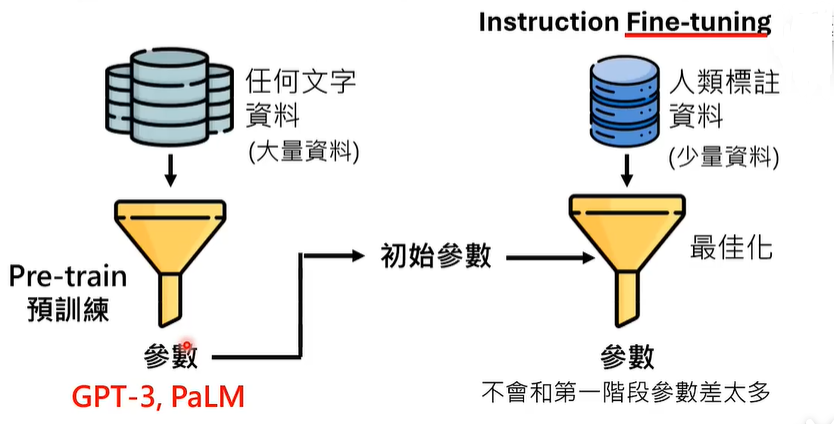
① 人类老师教导(督导式学习、预训练)

但是,我们不能以人类的视角来揣度模型的思路,来推断参数的生成,仅仅依靠人类老师教导,无法使模型获得很强的能力。
② 第一阶段的训练参数作为第二阶段的初始参数(微调)
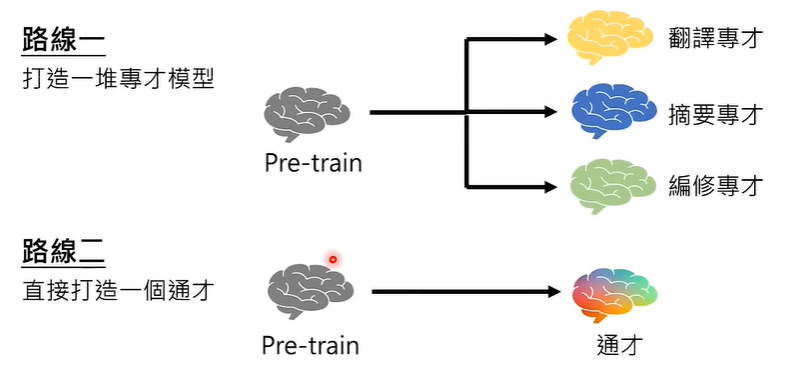
模型在经过大量的参数训练之后,可能获得很强的举一反三能力,有多夸张呢,你只要交给一个模型一个语言的学习,它会自动学会其他语言的学习!!
因此,Fine-tuning(微调) 技术划分为两条路线,一是打造一堆专才模型,二是打造一个通才。
那么,我们可以拥有自己的Instruction Fine-tunning吗,答案是不行,我们没有高质量资料,不过,可以对ChatGPT做逆向工程,获取相关资料。
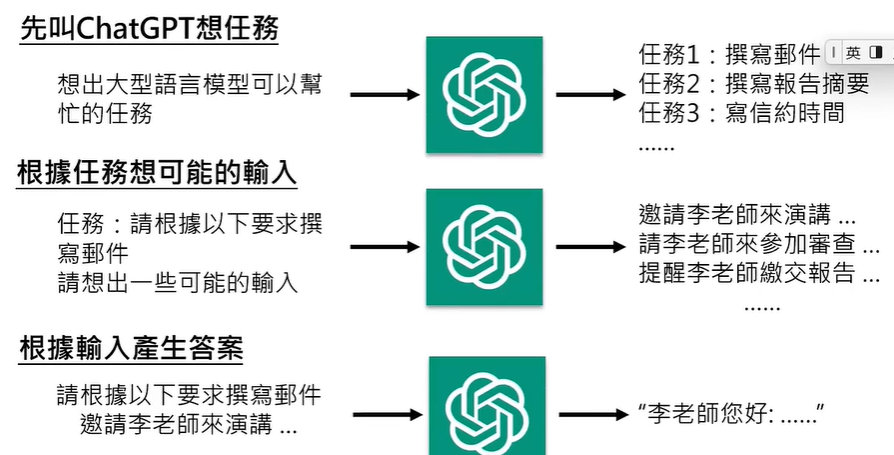
现在,我们拥有了高质量资料,可以做Instruction Fine-tunning了吗,答案还是不行,因为我们没有第一阶段生成的初始参数。嘿嘿,Meta开源了LLaMA,我们可以用它的初始参数来打造自己的大语言模型。
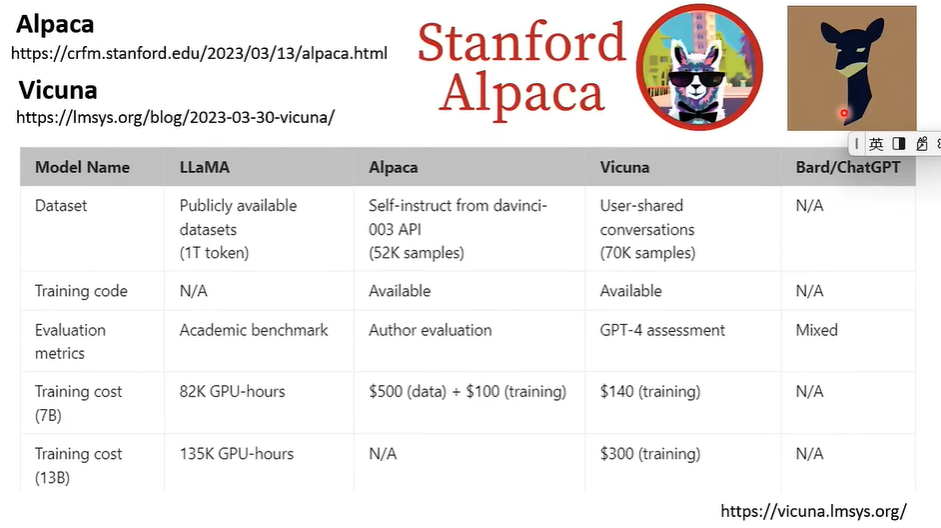
一夜之间,各式各样的大模型如雨后春笋般争相出现,世界进入了人人可以Instruction Fine-tunning大语言模型的时代。
04 第三阶段:实战演练,打磨技巧
Reinforcement Learning from Human Feedback(RLHF)

增强式学习(Reinforcement Learning, RL)
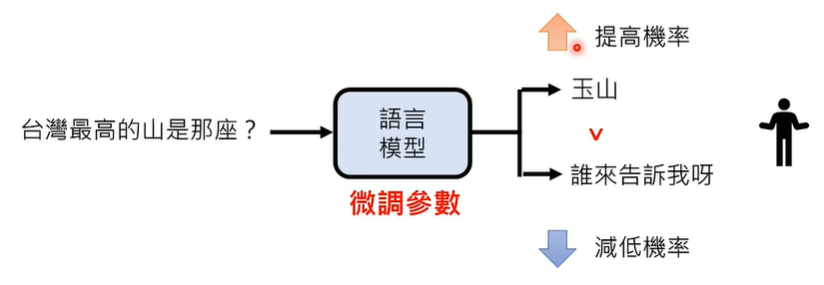
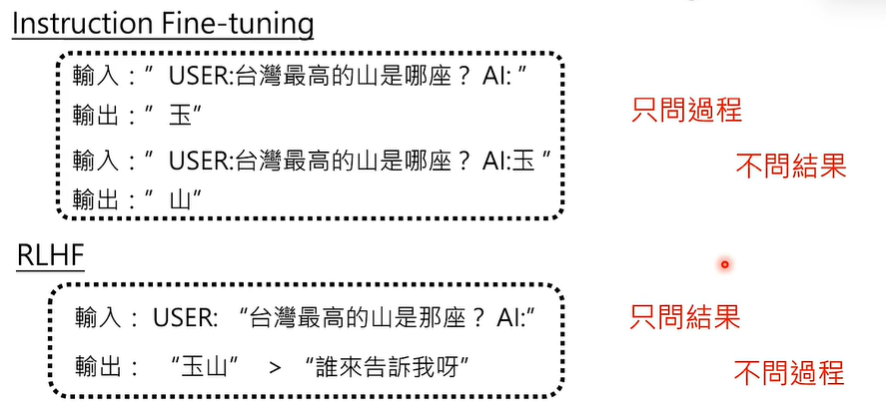
在第二个阶段,人类比较辛苦,需要收集大量的资料来告诉模型什么是对的,而到了第三阶段,人类比较轻松,模型对某个问题会给出两个答案,人类只需要判断哪个答案更好一些即可。
语言模型和AlphaGo很像,二者都是人工智能,在工作的过程中会不断迭代更新调整自己的答案,从而获得一个优秀的结果。
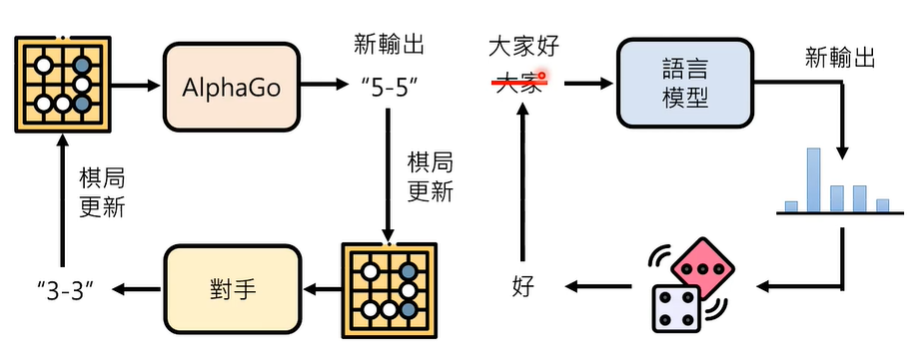
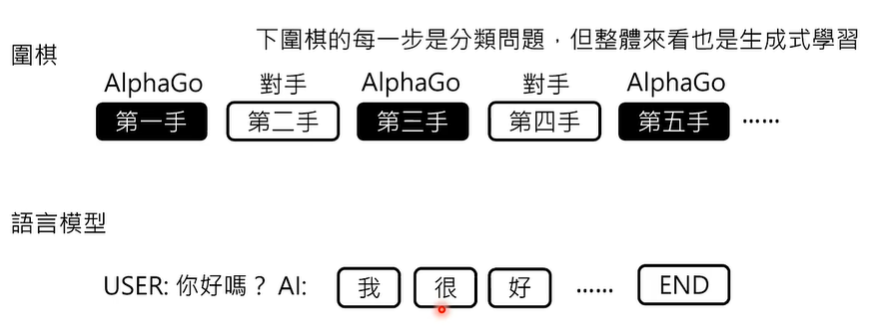
那么,AlphaGo又是如何学习的呢?
AlphaGo的学习分为两个阶段,第一个阶段是跟着棋谱学习,第二个阶段是干中学。
对于大语言模型训练的第三阶段,一个关键问题是,如何更有效的利用人类的回馈?
参考《葬送的芙莉莲》引入回馈模型(Reward Model)来模仿人类的偏好。
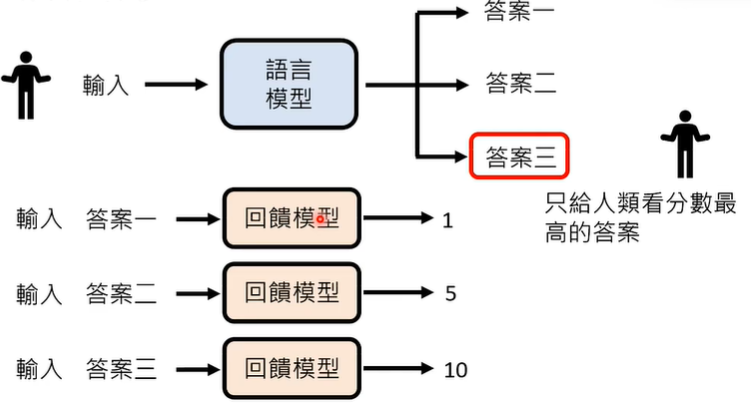
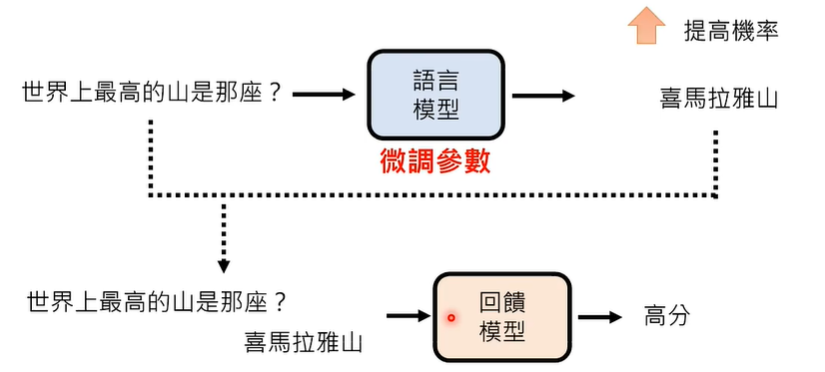
但是,过度跟虚拟人类学习,训练出来的结果也是有偏差的,今天一些大语言模型的一些不尽如人意的行为,可能就是过度跟虚拟人类学习的结果。

为了解决这一问题,有很多人目前在做各种尝试,是否有效需要时间的验证… 获取在不远的未来,新的语言模型可以代替回馈模型对原来的模型进行评价,甚至是自我迭代。
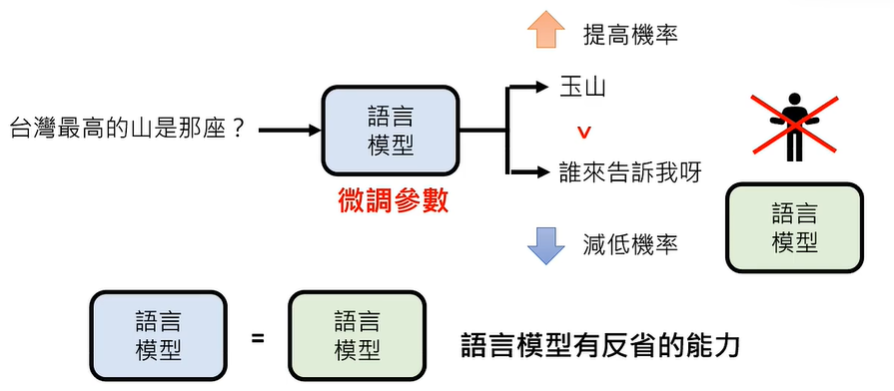
增强式学习有一个难题,什么叫做“好”的答案呢?其实,在很多中情况下,人类自己也不知道哪种选择是正确的选择,希望未来,人工智能可以代替人类做出更有利于人类发展的选择。
