框架系统在自然语言处理深度语义分析中的作用、挑战与未来展望
引言
随着人工智能(AI)技术的飞速发展,自然语言处理(NLP)已成为其核心驱动力之一。其中,深度语义分析——即让机器不仅理解文本的字面含义,更能洞察其深层逻辑、意图、上下文关系和隐含知识——是实现真正人工智能的关键瓶颈。在这一进程中,以TensorFlow和PyTorch为代表的深度学习框架系统,扮演了至关重要的角色。它们不仅是实现复杂算法的工具,更在深层次上影响和塑造了深度语义分析技术的发展路径、研究范式乃至未来的演进方向。
本报告旨在深入剖析框架系统对NLP深度语义分析的赋能作用、带来的内在局限与挑战,并结合截至2025年的技术发展趋势,展望未来的创新方向与启示。报告将严格依据提供的研究资料,进行深入的逻辑推理与分析。
第一章:框架系统的核心作用:深度语义分析的基石与加速器
深度学习框架的出现,极大地降低了NLP研究与应用的门槛,它们通过提供高级抽象、自动化工具和庞大的生态系统,构成了现代深度语义分析研究不可或缺的基础设施。
1.1 抽象化与自动化:简化复杂模型的构建
深度语义分析模型,尤其是基于Transformer架构的大型语言模型(LLMs),其内部结构极其复杂 。深度学习框架的核心贡献在于将底层的数学运算、梯度计算和硬件交互进行了高度封装。功能如 自动微分(Automatic Differentiation) 是TensorFlow和PyTorch等框架的基石 它将研究人员从繁琐的手动求导中解放出来,使其能够专注于模型架构的设计与创新。这种抽象化使得研究者可以快速试验新的网络结构,从而加速了从递归神经网络(RNN)到长短期记忆网络(LSTM),再到注意力机制和Transformer的演进过程 。
1.2 计算资源的统一调度与优化
现代深度语义分析依赖于海量数据的训练,这对计算资源提出了极高要求 。框架系统提供了在CPU、GPU和TPU等异构硬件上进行高效计算的统一接口 。例如,PyTorch和TensorFlow都能与NVIDIA的cuDNN等库无缝集成,以最大化利用GPU的并行计算能力 。此外,对于需要超大规模计算资源的预训练模型(如BERT、GPT系列),框架内置的分布式训练能力至关重要 。没有这些框架提供的强大计算支持,训练动辄拥有数百亿甚至数千亿参数的模型是无法想象的。
1.3 生态系统的构建与知识共享
TensorFlow和PyTorch不仅仅是软件库,它们已经发展成为庞大的生态系统。这些生态系统包括了预训练模型的存储库(如Hugging Face Transformers,虽然未直接提及,但其模式是框架生态的典型代表)、专门用于NLP数据处理的辅助库(如PyTorch的TorchText和TensorFlow的TF-Text)以及丰富的社区教程和研究实现。这种生态极大地促进了知识的共享和技术的普及。研究人员可以直接在一个框架内加载并微调如BERT这样的预训练模型,以适应特定的语义分析任务 这种迁移学习的范式已成为NLP领域的标准做法,其基础正是由框架及其生态系统所奠定的。
第二章:框架对深度语义分析的赋能与塑造
框架不仅是工具,其设计哲学和技术特性也深刻地塑造了深度语义分析的研究方向和实现路径。
2.1 动态图与静态图:影响研究与部署的范式
PyTorch以其 动态计算图(Define-by-Run) 的特性,在研究界备受欢迎 。这种模式允许研究人员在模型运行时进行更灵活的控制和调试,更符合Pythonic的编程直觉,对于探索需要处理可变数据结构或复杂控制流的深度语义解析任务(如生成逻辑形式或代码)尤为有利。
相比之下,TensorFlow早期采用的 静态计算图(Define-and-Run) 模式,虽然在灵活性上稍逊一筹,但其优势在于能够预先对整个计算图进行优化,更便于进行大规模分布式部署和在多种硬件平台上进行推理 。尽管近年来两大框架在互相借鉴(如TensorFlow引入Eager Execution,PyTorch引入TorchScript进行静态化)但它们最初的设计理念已经分别在学术研究的灵活性和工业部署的稳定性方面,对NLP社区产生了深远影响。
2.2 推动“大模型”范式成为语义分析的主流
框架对大规模分布式计算的强大支持,直接催生了以BERT、GPT为代表的“预训练-微调”范式 。这种范式改变了深度语义分析的根本方法。在此之前,研究者需要为每个具体的语义任务(如命名实体识别、关系抽取、语义角色标注)设计独特的模型架构和特征工程 。而现在,通过在一个统一的、强大的预训练语言模型基础上进行微调,可以在多个基准测试(如GLUE, SQuAD)上达到顶尖水平 。可以说,是框架的技术能力使得“大力出奇迹”的“大模型”路线成为可能,并将语义分析的研究重点从模型结构设计转向了如何更有效地利用和引导这些大规模预训练知识。
2.3 局限性:框架可能固化技术路径
框架的成功也带来了潜在的风险。由于主流框架对基于梯度下降和反向传播的深度神经网络结构支持最为成熟,这使得研究资源和人才倾向于集中在这一技术路径上。对于一些可能需要不同计算范式的方法,如纯粹的符号逻辑推理或复杂的图算法,尽管框架也在努力集成(例如PyTorch Geometric对图神经网络的支持 ,但其原生支持度和社区成熟度仍有差距。这种路径依赖可能会在一定程度上限制了对非主流、但可能对深度语义理解至关重要的颠覆性方法的探索。
第三章:框架应用中的挑战与深层瓶颈
尽管框架系统极大地推动了技术进步,但在将其应用于复杂的深度语义分析任务时,依然面临着从实现到理论的多重挑战。
3.1 数据、计算与成本的挑战
- 数据依赖性: 深度学习模型是数据驱动的,深度语义分析任务尤其需要大量高质量的标注数据,而这往往是昂贵且耗时的 。数据质量、噪声和不平衡问题会直接影响最终模型的性能 。
- 计算资源需求: 训练和部署大规模模型需要庞大的计算资源,包括高性能的GPU/TPU集群 。这不仅带来了高昂的经济成本,也引发了对能源消耗和环境影响的担忧,形成了一道阻碍学术界和中小型企业进行前沿研究的壁垒。
3.2 模型的可解释性与可靠性瓶颈
深度学习模型,尤其是通过框架构建的复杂模型,通常被视为“黑盒” 。我们很难精确理解模型为何做出某一特定语义判断。在金融、医疗、法律等高风险领域,这种不可解释性是致命的。此外,大型语言模型存在的“幻觉”(Hallucination)和知识过时问题 表明它们并未真正“理解”语义,而更多是在进行统计模式匹配。框架本身提供了构建模型的工具,但并未内在地解决这些深层的可靠性与可信度问题。
3.3 评估体系的局限性
当前用于评估NLP模型性能的指标体系,在衡量深度语义理解方面存在不足。
- 传统指标的表面性: 诸如准确率(Accuracy)、F1分数(F1-Score)、BLEU和ROUGE等指标,更多地关注词汇或句法的匹配度 。它们难以评估模型是否真正理解了文本的逻辑、意图或常识。
- 语义解析专用指标的挑战: 针对语义解析任务,虽然存在如 精确匹配(Exact Matching)、组件匹配(Component Matching)和执行准确率(Execution Accuracy) 等更专业的指标 ,但这些指标的评估同样面临挑战,尤其是在处理日益复杂的自然语言查询时。
- 评估基准的缺乏: 搜索结果多次指出,评估NLP性能缺乏公认的、能够全面反映深层语义理解能力的基准 。现有的基准如GLUE、SQuAD等虽然推动了领域发展,但也可能导致模型针对特定任务“刷分”,而非提升通用的语义理解能力。BERTScore这类基于语义相似性的新指标 是向正确方向迈出的一步,但整个评估体系仍需持续进化。
第四章:面向2025年的前沿趋势与启示
站在2025年10月的时间点,我们可以观察到框架系统和深度语义分析正在朝着更加融合、智能和可靠的方向演进。以下几个趋势尤为值得关注。
4.1 混合架构与神经符号AI的兴起
为了克服纯深度学习模型在逻辑推理、可解释性和常识利用方面的短板, 神经符号AI(Neuro-symbolic AI) 正成为一个重要的研究方向 。这种方法试图将神经网络强大的模式识别能力与符号系统清晰的逻辑推理能力相结合。这对框架提出了新的要求:未来的框架需要更好地支持混合架构,能够无缝集成逻辑规则、知识图谱和概率图模型 。例如,PyTorch生态中的LogiTorch库 就代表了这一探索方向。这种趋势预示着,未来的深度语义分析将不再仅仅依赖于端到端的黑盒训练,而是走向一种更加结构化和可解释的混合智能模式。
4.2 检索增强与知识集成的原生支持
为了解决大型语言模型知识陈旧和幻觉的问题, 检索增强生成(Retrieval-Augmented Generation, RAG) 已成为一项关键技术 。它通过在生成回答前,从外部知识库(如向量数据库、文档集)中检索相关信息,来提升回答的准确性和时效性。可以预见,到2025年及以后,主流框架将提供对这类工作流的更原生、更高效的支持。这可能包括内置的向量索引和检索模块、优化的多模态数据融合接口,以及更高效地处理“检索-生成”循环的计算图机制。
4.3 “概念模型”:超越词元(Token)的语义表示
当前主流模型主要在词元(Token)级别上进行操作,这限制了它们形成和操作抽象概念的能力。有研究预测, “概念模型”(Conceptual Models, LCMs) 可能会重新定义NLP框架,推动AI从处理词元序列转向在概念层面进行推理 。这意味着未来的框架需要支持新的数据结构和计算范式,以表示和操作概念及其之间的关系。这将是实现更深层次语义理解的革命性一步,能够让模型更好地处理歧义、进行类比推理和实现真正的语境理解。
4.4 框架的持续演进:统一、高效与易用
TensorFlow和PyTorch之间的竞争与融合仍在继续。我们可以看到,它们都在努力吸取对方的优点,为开发者提供一个兼具灵活性、高性能和易部署性的统一体验 。编译器技术(如PyTorch Inductor和TensorFlow XLA 的发展,将进一步优化模型性能,降低推理延迟。对于深度语义分析而言,这意味着研究人员和工程师将能够用更少的精力关注底层优化,而将更多精力投入到模型创新本身。
结论
框架系统与NLP深度语义分析之间存在着一种共生演化的关系。框架通过提供强大的计算抽象和庞大的生态系统,极大地加速了深度学习模型(尤其是大规模预训练模型)的发展,并从根本上重塑了语义分析的研究范式。然而,它们也带来了对数据和算力的巨大依赖、模型“黑盒”问题以及评估体系滞后等一系列挑战。
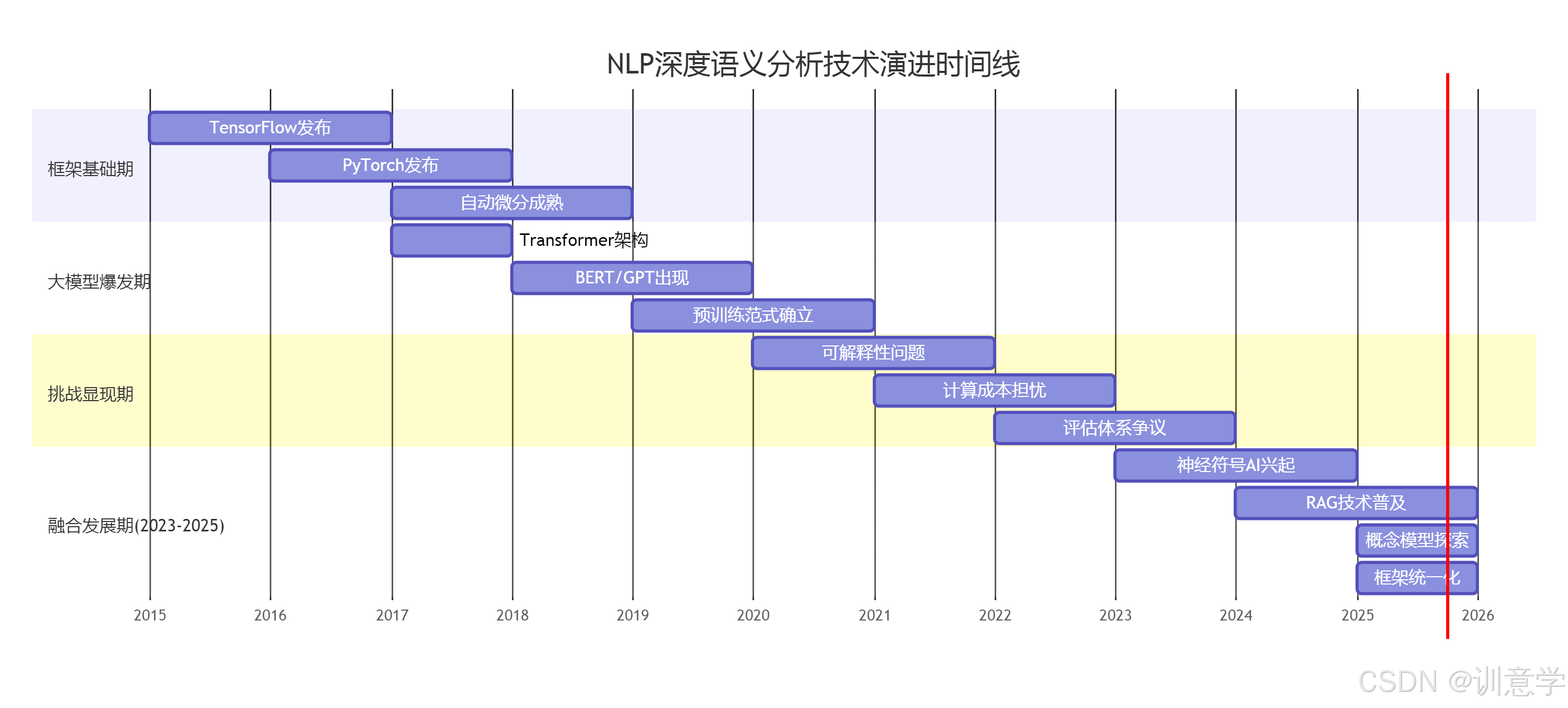
展望未来,截至2025年10月,我们看到的发展趋势清晰地表明,为了实现真正的深度语义理解,技术正从单一依赖大规模数据拟合,转向更加多元和深入的路径。未来的AI框架必须演进,以更好地支持混合架构(如神经符号AI)、外部知识集成(如RAG)、以及更高级的语义表示(如概念模型)。框架系统的创新将不再仅仅是提升计算效率,而更多地在于为构建更可解释、更可靠、更接近人类认知机理的智能系统提供基础。对于研究者和开发者而言,深刻理解当前框架的优势与局限,并积极拥抱这些新兴的技术范式,将是在通往通用人工智能的道路上取得突破的关键。