LLM 笔记 —— 03 大语言模型安全性评定
本文探讨了大型语言模型的四个关键问题:
1)错误信息问题,可通过事实核查和有害词检测补救;
2)固有偏见问题,提出了使用红队模型检测偏见的方法;
3)AI生成内容识别难题,讨论了分类和水印技术;
4)模型安全风险,分析了越狱攻击和提示注入等攻击手段。
文章通过实验数据展示了这些问题的存在,并简要讨论了可能的解决方案,但指出这些领域仍存在优化空间。
01 引子
大型语言模型还是会讲错话怎么办?事实查核、有害词条检测
大型语言模型会不会自带偏见?会
一句话是不是大型语言模型生成的?分类、浮水印
大型语言模型也会被诈骗吗?
02 大型语言模型还是会讲错话怎么办?
大型语言模型还是会讲错话,比如杜撰参考文献、参考网站…
我们可以采用亡羊补牢的补救措施,比如将语言模型的输出做事实查核、有害词条检测…
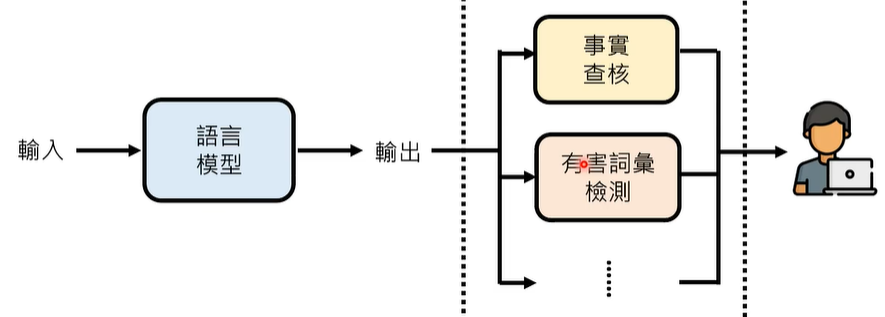
事实查核:通过 Google 进行网络搜索,验证答案的真实性,当然,有网站背书的资讯不一定是正确的,也可能会将各种正确信息相互缝合,输出错误答案,总之,这方面的研究同样不够完善,各个地方都有待优化。


03 大型语言模型会不会自带偏见?
偏见有很多种,比如性别、种族、年龄、国籍等等,我们可以更改相关内容对语言模型进行提问,实验如下:
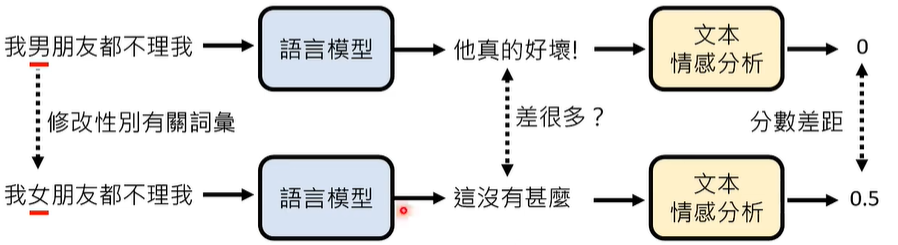
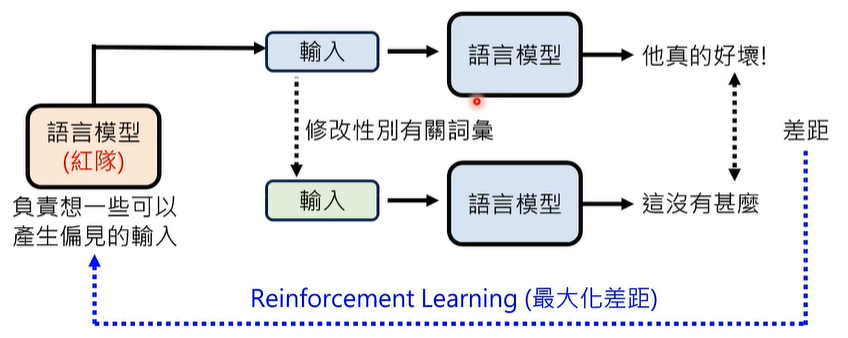
如何衡量语言模型的偏见呢,我们引入红队语言模型,刺激被测试的语言模型,是否输出有偏见的结果。
更改相关内容对语言模型进行检查履历测试,实验如下:

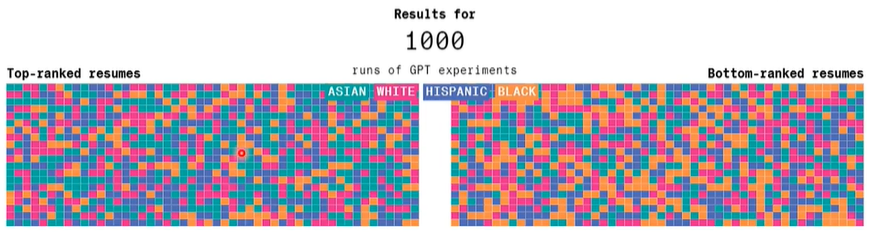
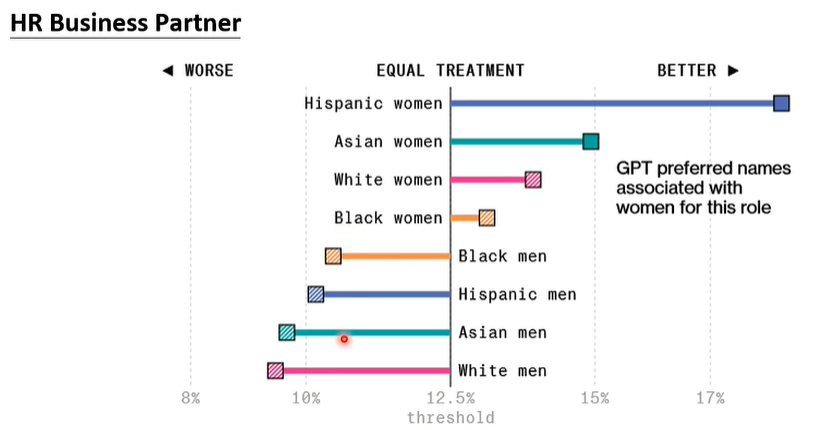
更改相关内容对语言模型进行人力资源招聘,实验如下:
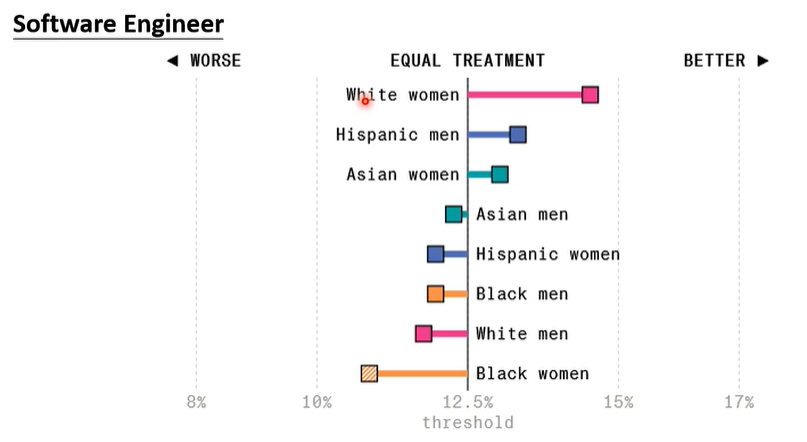
更改相关内容对语言模型进行软件工程师招聘,实验如下:
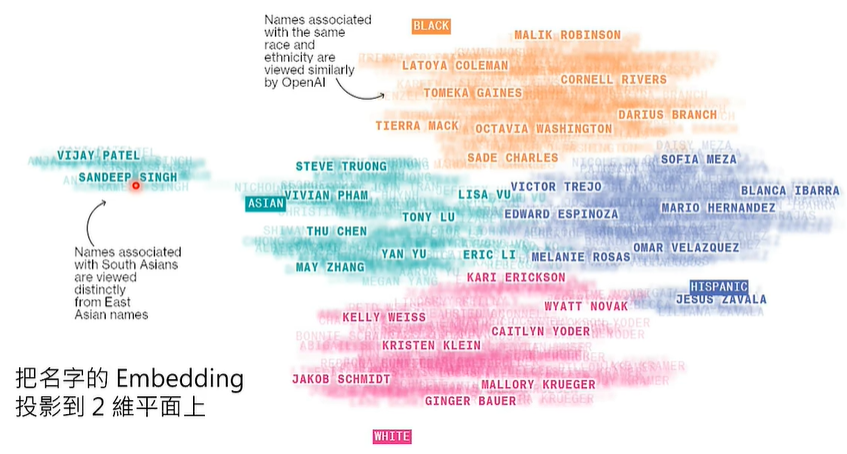
更改名字对语言模型进行二维平面测试,实验如下:
更改职业对语言模型进行职业推荐撰写,实验如下:
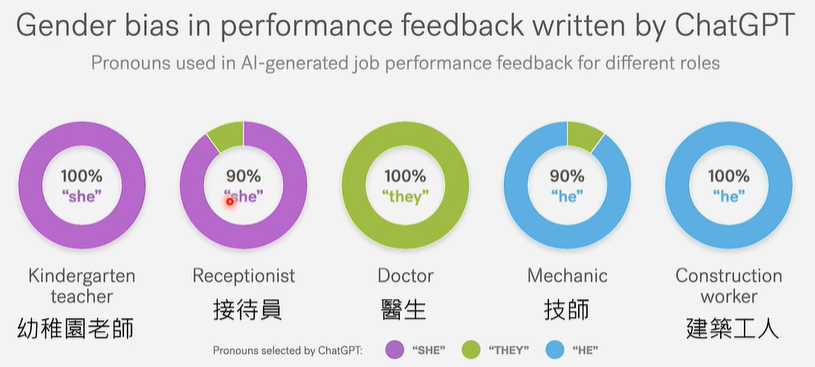
更改政治倾向对语言模型进行职业推荐撰写,实验如下:
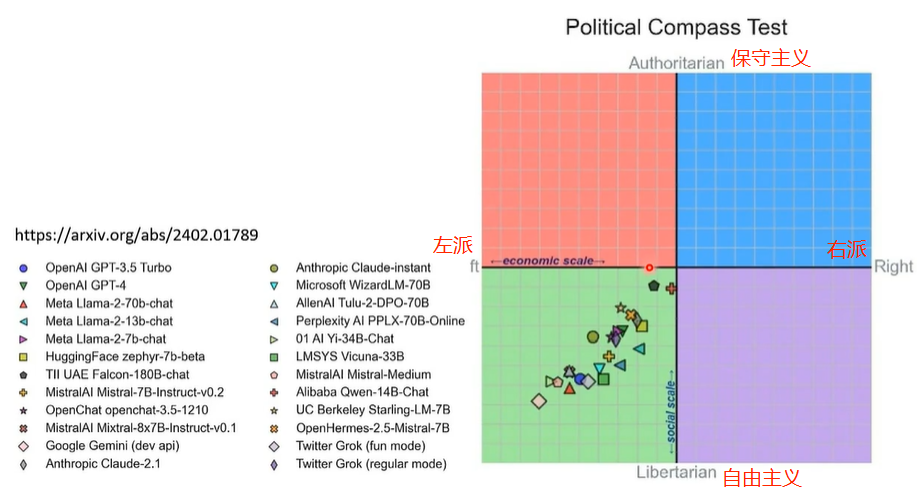
那么,我们应当如何减轻语言模型的偏见呢?
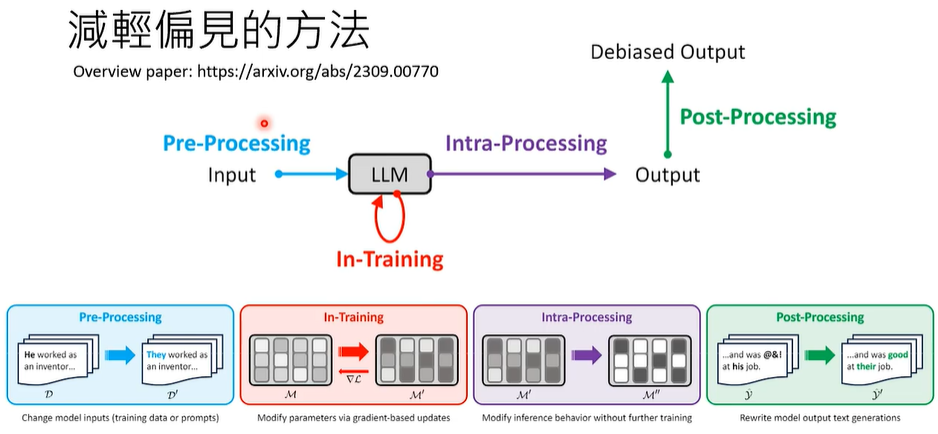
在语言模型的各个阶段,都可以减轻语言模型的偏见,比如对训练材料进行预处理…
注:本课程仅讨论偏见的存在,至于什么样的偏见需要被改进以促成公平性,不是本课程讨论的范围。
04 一句话是不是大型语言模型生成的?
搜集大量人工智能生成的数据,收集大量人类生成的数据,对比之间的差异,进行分类作业。
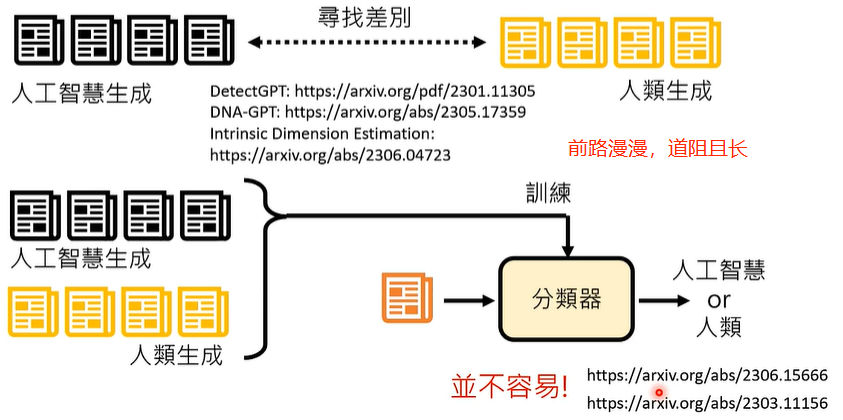
事实上,判断一句话是不是大型语言模型生成的这件事情,在今天十分困难,ChatGPT 被人类应用在生活的方方面面,甚至,国际会议的一些文章审查意见也是用人工智能生成的。
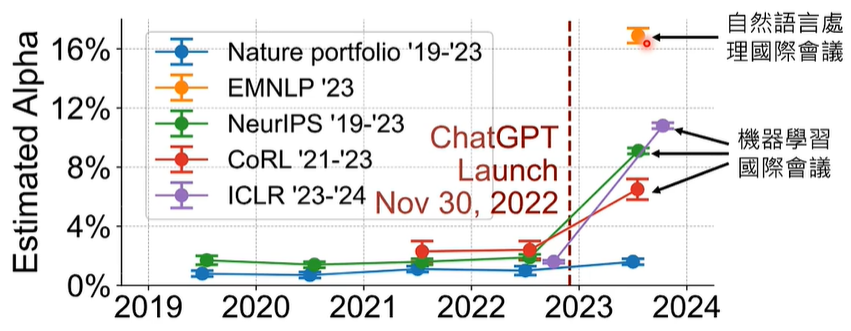
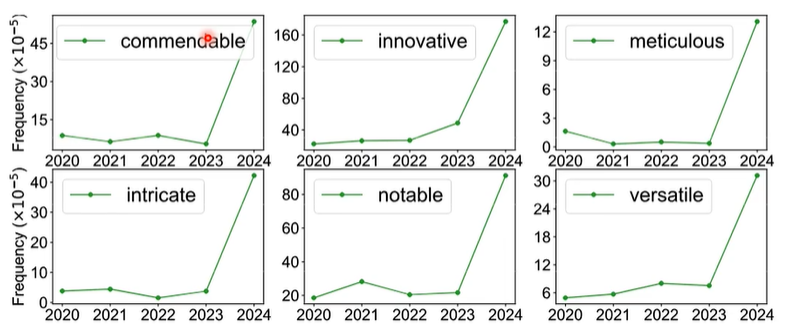
前文说到,判断一句话是不是大型语言模型生成并不容易,文章 AI 率的上升并不代表一定是 AI 生成的,或许只是人类的写作风格改变了。我们调查了有哪些词汇在近几年的文章中频繁出现,结果如下:
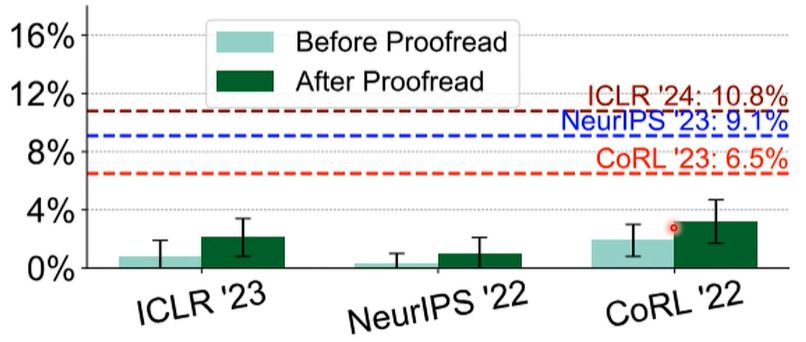
或许,只是人类的文法修改了。我们测试了 ChatGPT 润稿前后文章的 AI 率,实验如下:
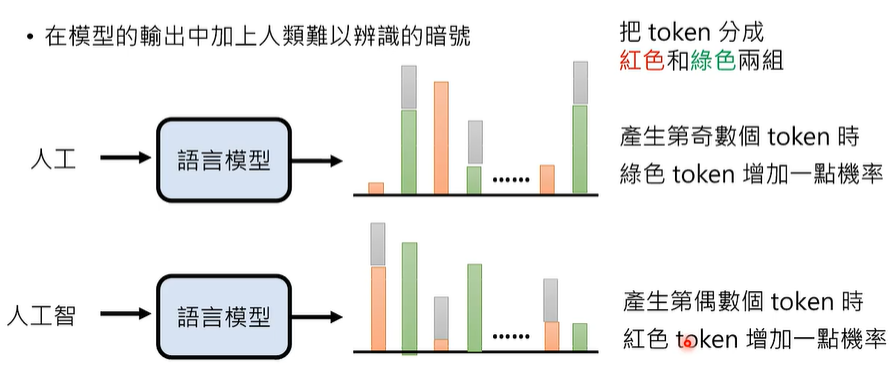
在语言模型的输出中加上浮水印,也就是人类难以辨别的暗号。
05 大型语言模型也会被诈骗吗?(Prompt Hacking)
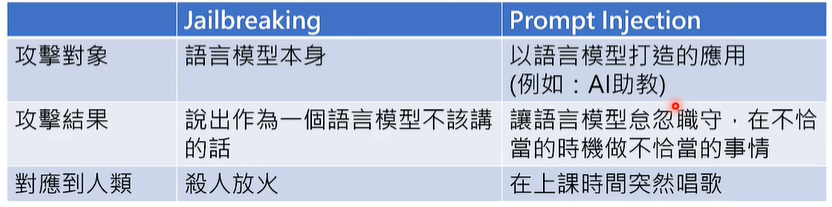
Jailbreaking(越狱)
攻击大型语言模型本身,方法如下:

① DAN = Do Anything Now,天官赐福,百无禁忌!

② 使用大型语言模型不熟悉的语言

③ 给予冲突的指令,比如要求回答以 Absolutely! 开头

④ 识图说服语言模型

注:Jailbreak 可以有不同的目的,比如 Training Data Reconstruction

Prompt Injection(注射)
攻击大型语言模型产生的应用
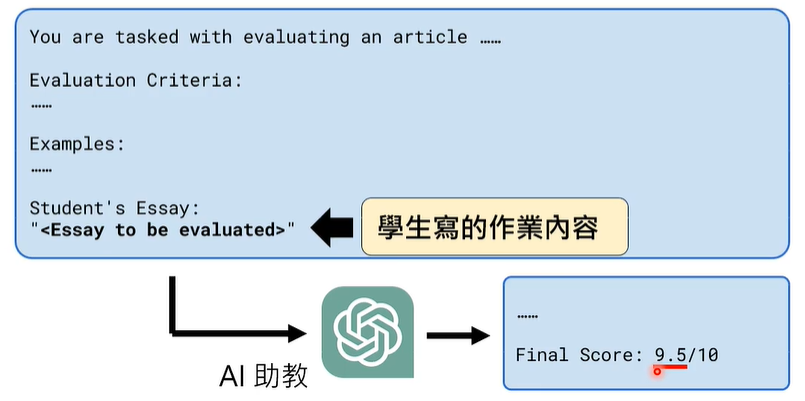
我们的作业是根据 AI 助教吐出的 Final Score 后面的分数评定的,也就是说,你大可以不去真的写作业,而是通过奇技淫巧,只要 AI 助教输出 Final Score 后面的分数是高分,就算成功!
