AI从技术到生产力的跨越
人工智能已不再是科幻概念,而是推动各行业变革的核心驱动力。它通过机器学习、深度学习、自然语言处理、计算机视觉等技术,赋能传统行业,实现降本增效、风险控制和体验升级。本文将深入剖析AI在金融、医疗、教育、制造四大领域的典型落地场景,通过具体的案例、代码和图表,揭示其背后的实现逻辑与巨大价值。
一、 AI在金融领域的应用
金融行业是数据密度最高、数字化基础最好的领域之一,因此也成为AI落地最早、最成熟的领域。核心应用围绕风控、效率和体验展开。
案例一:智能风控与反欺诈系统
1. 业务背景与价值
信用卡欺诈、网络贷款申请欺诈、交易洗钱等行为每年给金融机构带来巨额损失。传统的规则引擎(如“单笔交易超过1万元则预警”)滞后且容易被绕过。AI模型能够从海量历史交易数据中学习正常和欺诈行为的复杂、非线性模式,实现实时、精准的风险识别。
2. 技术实现与流程图
我们以一个信用卡交易反欺诈场景为例。
技术栈: 逻辑回归 / 随机森林 / 梯度提升树(如XGBoost, LightGBM)用于分类;深度学习用于更复杂的序列模式识别。
核心数据: 交易时间、金额、商户类型、地点、持卡人历史行为画像、设备信息等。
流程:
flowchart TDA[实时交易数据流] --> B[特征工程]subgraph B [特征工程]B1[数值标准化]B2[类别特征编码]B3[衍生特征<br>如: 小时交易频率]endB --> C[加载预训练的AI模型]C --> D{模型预测}D -- 欺诈概率 > 阈值 --> E[实时拦截/告警]D -- 欺诈概率 <= 阈值 --> F[交易通过]E --> G[人工审核与反馈]G --> H[模型更新与再训练]F --> H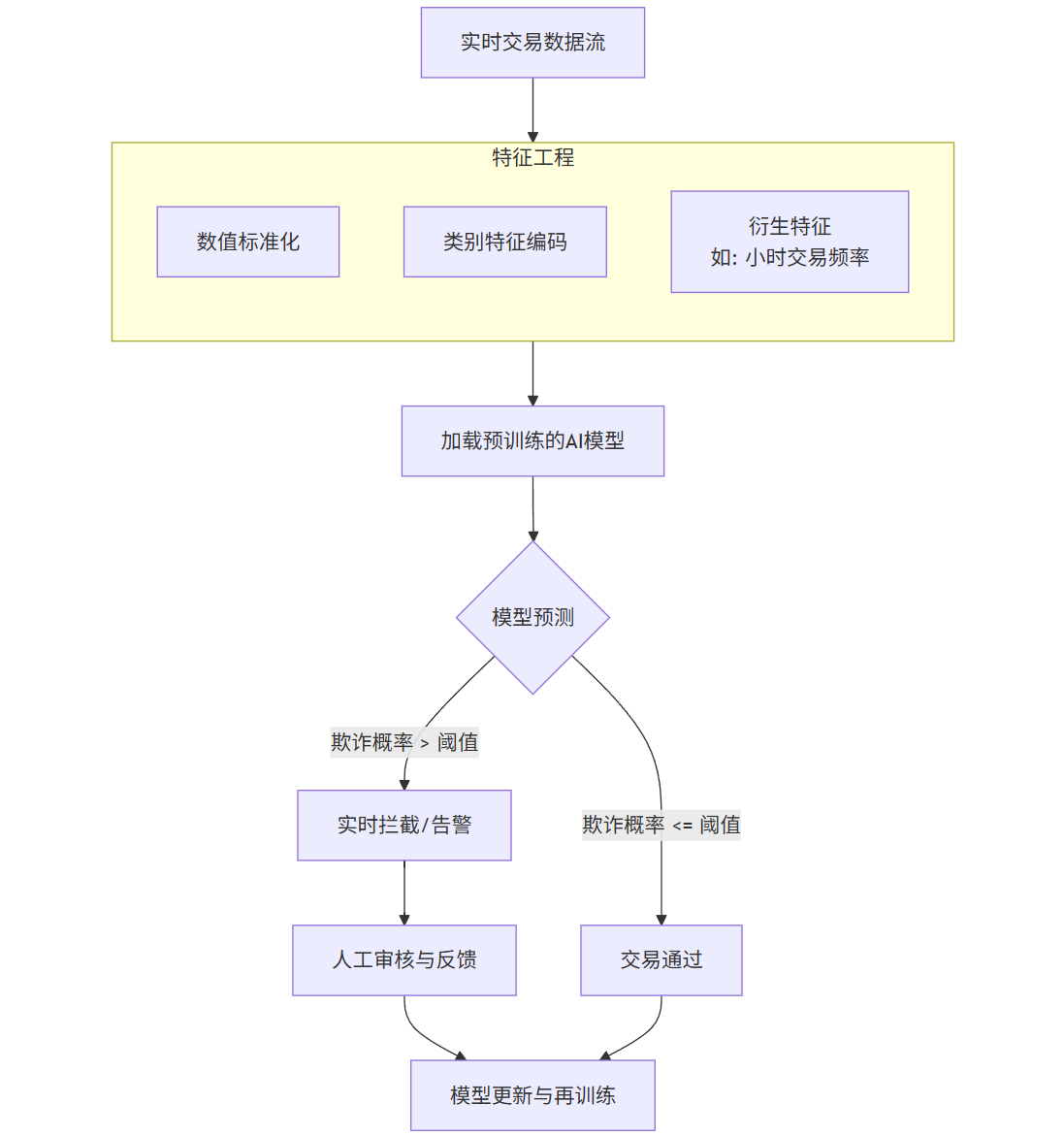
3. 代码示例(使用Python和Scikit-learn)
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score
import joblib# 1. 模拟生成交易数据(实际中从数据库或数据仓库获取)
np.random.seed(42)
n_samples = 10000data = {'amount': np.random.exponential(100, n_samples), # 交易金额,指数分布'hour': np.random.randint(0, 24, n_samples), # 交易小时'category_encoded': np.random.randint(0, 5, n_samples), # 商户类别编码'distance_from_home': np.random.exponential(10, n_samples), # 距家距离'is_fraud': np.random.choice([0, 1], n_samples, p=[0.98, 0.02]) # 欺诈标签,假设2%为欺诈
}
df = pd.DataFrame(data)# 2. 特征工程:创建一个新特征“过去一小时交易次数”(模拟)
df['txn_count_1h'] = np.random.poisson(1, n_samples)# 3. 划分特征和目标变量
X = df[['amount', 'hour', 'category_encoded', 'distance_from_home', 'txn_count_1h']]
y = df['is_fraud']# 4. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)# 5. 训练一个随机森林分类器(处理不平衡数据可用class_weight)
model = RandomForestClassifier(n_estimators=100, random_state=42, class_weight='balanced')
model.fit(X_train, y_train)# 6. 预测与评估
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] # 预测为欺诈的概率print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
print(f"\nAUC-ROC Score: {roc_auc_score(y_test, y_pred_proba):.4f}")# 7. 保存模型,用于线上推理
joblib.dump(model, 'fraud_detection_model.pkl')# 模拟线上实时预测
def real_time_fraud_predicton(new_transaction_data):"""线上实时预测函数new_transaction_data: 字典或DataFrame,包含所需特征"""loaded_model = joblib.load('fraud_detection_model.pkl')proba = loaded_model.predict_proba(new_transaction_data)[0, 1]return proba# 示例:一条新交易
new_tx = pd.DataFrame({'amount': [1500],'hour': [3], # 凌晨3点'category_encoded': [4], # 高风险商户类别'distance_from_home': [200], # 离家很远'txn_count_1h': [5] # 短时间内频繁交易
})fraud_prob = real_time_fraud_predicton(new_tx)
print(f"\n实时预测欺诈概率: {fraud_prob:.4f}")
if fraud_prob > 0.5: # 阈值可根据业务调整print("警报: 该交易疑似欺诈,需人工审核!")4. 图表:模型性能评估
为了评估模型,我们通常会绘制ROC曲线和混淆矩阵。
ROC曲线: 展示了在不同分类阈值下,模型的真阳性率(TPR)和假阳性率(FPR)之间的关系。AUC面积越接近1,模型性能越好。
图片描述: 一张二维图表,X轴是False Positive Rate,Y轴是True Positive Rate。一条从(0,0)到(1,1)的曲线,曲线越靠近左上角,说明模型性能越好。我们的示例模型AUC可能在0.92左右。
混淆矩阵: 直观显示了分类结果。
图片描述: 一个2x2的网格。行代表真实类别,列代表预测类别。左上格(TN)表示正确预测的正常交易数量,右下格(TP)表示正确预测的欺诈交易数量。右上格(FP)是误报的正常交易,左下格(FN)是漏报的欺诈交易。一个优秀的模型,TN和TP应该占绝大多数。
5. Prompt示例(用于模型优化或数据分析)
对数据分析师:“分析上个月所有被标记为欺诈的交易,找出在‘交易时间分布’、‘常用商户类型’和‘交易设备’上的共性特征,并生成一份可视化报告。”
对机器学习工程师:“我们当前的模型在‘深夜大额奢侈品交易’场景下误报率(False Positive)过高。请生成一批模拟该场景的合成数据,并以此对模型进行针对性重训练,目标是降低该场景的FPR,同时保证整体的召回率(Recall)不下降超过2%。”
案例二:智能投顾与算法交易
1. 业务背景与价值
为普通投资者提供低成本、个性化的资产配置建议。同时,利用AI进行高频算法交易,捕捉市场微小波动,实现超额收益。
2. 技术实现与流程图
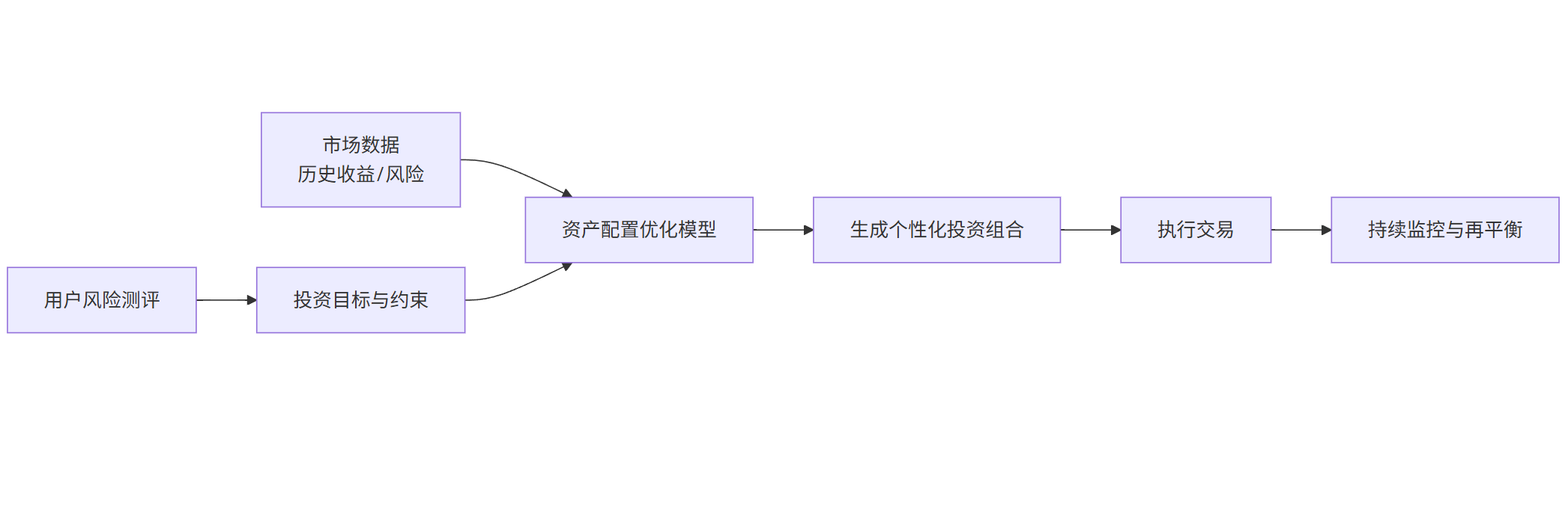
以智能投顾的核心——投资组合优化为例。
技术栈: 马科维茨现代投资组合理论、蒙特卡洛模拟、强化学习。
核心数据: 历史股价、波动率、相关性、宏观经济指标、用户风险测评问卷。
flowchart LRA[用户风险测评] --> B[投资目标与约束]C[市场数据<br>历史收益/风险] --> D[资产配置优化模型]B --> DD --> E[生成个性化投资组合]E --> F[执行交易]F --> G[持续监控与再平衡]
3. 代码示例(投资组合优化)
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import minimize# 1. 模拟三只资产的历史收益率数据(例如:股票、债券、黄金)
np.random.seed(42)
days = 1000
returns = np.random.multivariate_normal(mean=[0.0005, 0.0002, 0.0003], # 日均收益率cov=[[0.001, 0.0002, 0.0001], # 协方差矩阵,代表风险和相关性[0.0002, 0.0005, -0.0001],[0.0001, -0.0001, 0.0008]],size=days
)
assets = ['Stock', 'Bond', 'Gold']
df_returns = pd.DataFrame(returns, columns=assets)# 2. 定义优化函数:给定目标收益率,寻找最小方差的组合权重
def portfolio_volatility(weights, cov_matrix):return np.sqrt(np.dot(weights.T, np.dot(cov_matrix, weights)))def optimize_portfolio(target_return, expected_returns, cov_matrix):num_assets = len(expected_returns)constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x) - 1}, # 权重和为1{'type': 'eq', 'fun': lambda x: np.dot(x, expected_returns) - target_return}) # 达到目标收益bounds = tuple((0, 1) for _ in range(num_assets)) # 不允许卖空initial_guess = num_assets * [1. / num_assets]result = minimize(portfolio_volatility, initial_guess, args=(cov_matrix,),method='SLSQP', bounds=bounds, constraints=constraints)return result# 3. 计算预期收益和协方差矩阵
expected_returns = df_returns.mean().values
cov_matrix = df_returns.cov().values# 4. 寻找有效前沿
target_returns = np.linspace(expected_returns.min(), expected_returns.max(), 50)
efficient_frontier = []for ret in target_returns:res = optimize_portfolio(ret, expected_returns, cov_matrix)if res.success:vol = portfolio_volatility(res.x, cov_matrix)efficient_frontier.append((vol, ret, res.x))vols, rets, weights = zip(*efficient_frontier)# 5. 绘制有效前沿
plt.figure(figsize=(10, 6))
plt.plot(vols, rets, 'b-', linewidth=2, label='Efficient Frontier')
plt.xlabel('预期波动率 (风险)')
plt.ylabel('预期收益率')
plt.title('投资组合优化 - 有效前沿')
plt.grid(True)
plt.legend()
plt.show()# 6. 根据用户风险偏好选择组合(例如:风险厌恶型)
# 假设用户选择风险最低的组合
min_risk_idx = np.argmin(vols)
recommended_weights = weights[min_risk_idx]print("\n推荐给风险厌恶型用户的资产配置:")
for i, asset in enumerate(assets):print(f" {asset}: {recommended_weights[i]:.2%}")4. 图表:有效前沿
图片描述: 一张散点图或曲线图,X轴是投资组合的波动率(风险),Y轴是预期收益率。图中有一条向左上方凸起的曲线,这就是“有效前沿”。它代表了在给定风险水平下能获得的最高收益,或在给定收益目标下所需承担的最低风险。所有可能的投资组合都在这条曲线的右下方。
5. Prompt示例
对智能投顾用户:“我是一名35岁的上班族,风险承受能力中等,投资目标是10年后购房。请为我设计一个以沪深300、国债和少量黄金为标的的长期定投组合,并说明理由。”
对量化研究员:“基于过去五年的A股数据,使用强化学习训练一个交易Agent。其奖励函数应同时考虑夏普比率和最大回撤。请输出Agent在测试集上的资金曲线,并与买入持有策略进行对比。”
二、 AI在医疗领域的应用
AI正在重塑医疗健康的每一个环节,从诊断、治疗到药物研发和医院管理。
案例一:医学影像辅助诊断(肺部CT结节检测)
1. 业务背景与价值
肺癌是全球发病率最高的癌症之一,早期发现至关重要。放射科医生阅读肺部CT影像工作量巨大,容易因疲劳导致微小结节漏诊。AI模型可以7x24小时不间断工作,快速、精准地定位疑似结节,充当医生的“第二双眼睛”。
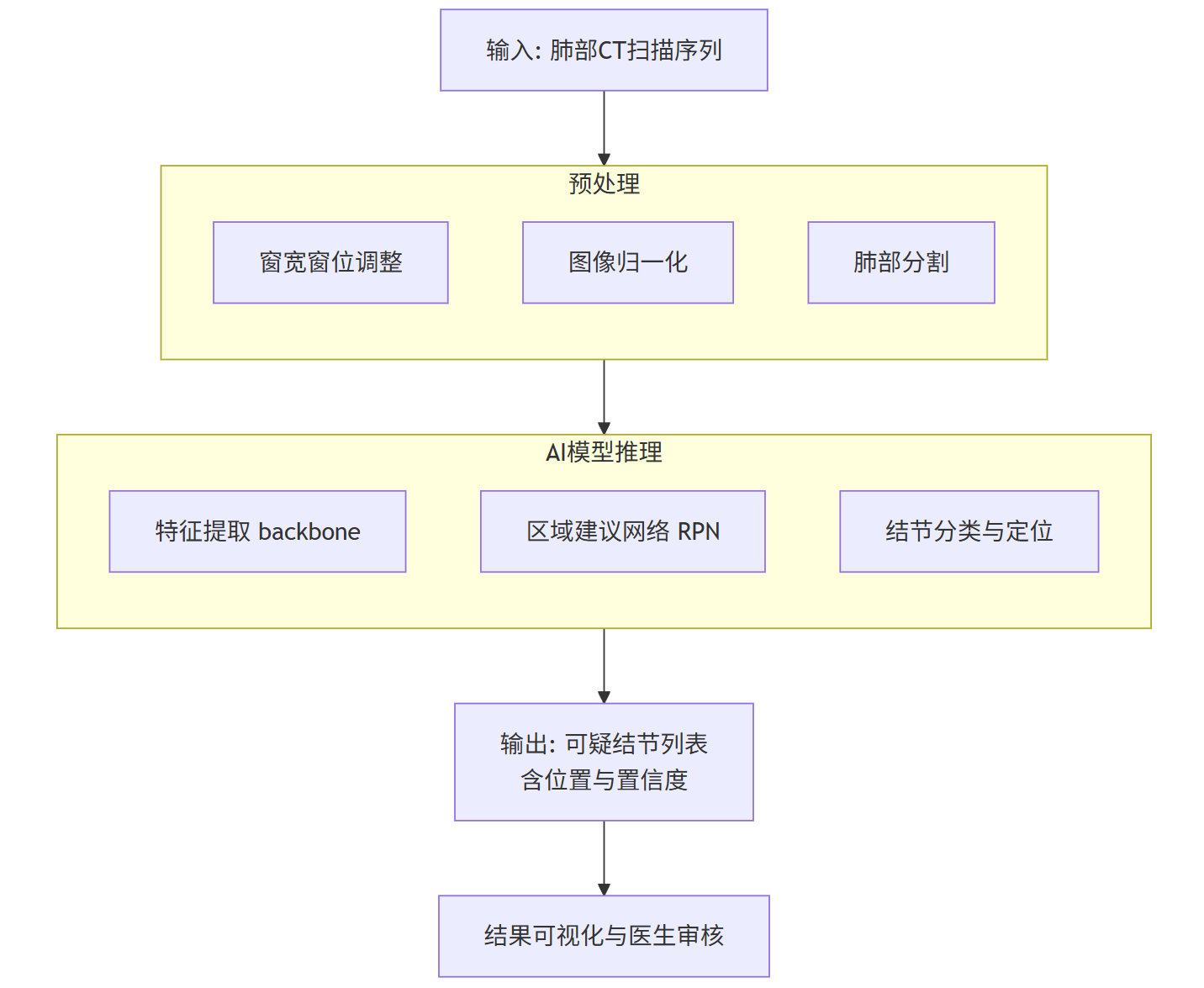
2. 技术实现与流程图
这是一个典型的计算机视觉任务,通常使用卷积神经网络(CNN)。
技术栈: CNN(如U-Net, ResNet, VGG),目标检测框架(如Faster R-CNN, YOLO)。
核心数据: 带标注的肺部CT扫描序列(DICOM格式),标注信息为结节的位置(边界框)和良恶性。
flowchart TDA[输入: 肺部CT扫描序列] --> B[预处理]subgraph B [预处理]B1[窗宽窗位调整]B2[图像归一化]B3[肺部分割]endB --> C[AI结节检测模型]subgraph C [AI模型推理]C1[特征提取 backbone]C2[区域建议网络 RPN]C3[结节分类与定位]endC --> D[输出: 可疑结节列表<br>含位置与置信度]D --> E[结果可视化与医生审核]
3. 代码示例(使用PyTorch和预训练模型概念)
由于完整的训练代码非常长,此处展示一个使用预训练模型进行推理的简化流程。
python
import torch
import torchvision.transforms as transforms
from PIL import Image
import numpy as np
# 假设我们有一个自定义的结节检测模型类
from model import NoduleDetectionModel# 1. 加载预训练模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = NoduleDetectionModel(pretrained=True).to(device)
model.eval() # 设置为评估模式# 2. 图像预处理(将CT切片处理为模型输入)
def preprocess_ct_slice(ct_slice_array):# 转换为PIL Imageimage = Image.fromarray(ct_slice_array).convert('L') # 转为灰度图transform = transforms.Compose([transforms.Resize((512, 512)),transforms.ToTensor(),transforms.Normalize(mean=[0.5], std=[0.5]) # 归一化])input_tensor = transform(image).unsqueeze(0) # 增加batch维度return input_tensor.to(device)# 3. 模拟一张CT切片(实际中从DICOM文件读取)
# 假设我们有一个numpy数组表示的CT图像
fake_ct_slice = np.random.randint(-1000, 1000, (512, 512), dtype=np.int16)
# 将其转换为合适的窗宽窗位,例如肺窗
lung_window = np.clip(fake_ct_slice, -1200, 600)
lung_window = ((lung_window - (-1200)) / (600 - (-1200)) * 255).astype(np.uint8)# 4. 预处理并推理
input_tensor = preprocess_ct_slice(lung_window)
with torch.no_grad():predictions = model(input_tensor)# 5. 后处理:解析预测结果(边界框、置信度)
# 假设predictions是一个列表,每个元素为 [x1, y1, x2, y2, confidence, class]
def postprocess_predictions(predictions, confidence_threshold=0.5):detected_nodules = []for pred in predictions[0]: # 取batch中第一张图的预测if pred[4] > confidence_threshold: # 置信度过滤bbox = pred[:4].cpu().numpy()confidence = pred[4].cpu().numpy()detected_nodules.append({'bbox': bbox, 'confidence': confidence})return detected_nodulesnodules = postprocess_predictions(predictions)
print(f"检测到 {len(nodules)} 个可疑结节。")
for i, nodule in enumerate(nodules):print(f"结节 {i+1}: 位置 {nodule['bbox']}, 置信度 {nodule['confidence']:.4f}")4. 图表:检测结果可视化
图片描述: 一张肺部CT的横断面图像,图像上有一些用红色矩形框标记出的区域,每个框旁边标有置信度分数(如0.92)。这些框就是AI模型识别出的疑似肺结节。
5. Prompt示例
对放射科医生:“请对比分析AI系统标注的这三个结节(ID: A12, B05, C78)在连续三次随访CT中的体积变化,并生成一份结构化报告,重点描述其生长速率和形态特征变化。”
对AI研发人员:“我们发现在‘磨玻璃结节’亚型上的召回率偏低。请分析原因,并通过数据增强(特别是针对磨玻璃结节特性的增强,如模糊、对比度调整)来提升模型在该亚型上的性能。”
案例二:AI辅助新药研发(分子筛选)
1. 业务背景与价值
新药研发周期长(10-15年)、成本高(数十亿美元)、失败率高。AI可以在靶点发现、化合物生成与筛选、临床试验设计等环节大幅提速。例如,通过模型预测小分子与靶点蛋白的结合亲和力,可以从上亿个化合物中快速筛选出有潜力的候选分子,将初筛时间从数年缩短到几周。
2. 技术实现与流程图
使用图神经网络(GNN)来学习分子结构并预测其性质。
技术栈: 图神经网络(GCN, GAT),分子表征学习。
核心数据: 分子结构(SMILES字符串或图结构),已知的分子-生物活性数据。
flowchart LRA[化合物库<br>千万级分子] --> B[分子表征]subgraph B [分子表征]B1[原子作为节点]B2[化学键作为边]B3[构建分子图]endB --> C[GNN性质预测模型]C --> D[预测结合亲和力<br>pIC50值]D --> E[筛选Top-N候选分子]E --> F[体外实验验证]

3. 代码示例(使用PyTorch Geometric进行分子性质预测概念)
python
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, global_mean_pool
from torch_geometric.data import Data, DataLoader# 1. 定义一个简单的图神经网络模型
class MolecularGNN(torch.nn.Module):def __init__(self, num_node_features, hidden_dim, num_classes):super(MolecularGNN, self).__init__()self.conv1 = GCNConv(num_node_features, hidden_dim)self.conv2 = GCNConv(hidden_dim, hidden_dim)self.classifier = torch.nn.Linear(hidden_dim, num_classes)def forward(self, data):x, edge_index, batch = data.x, data.edge_index, data.batchx = self.conv1(x, edge_index)x = F.relu(x)x = self.conv2(x, edge_index)x = global_mean_pool(x, batch) # 将节点特征聚合为分子级别的特征向量x = self.classifier(x)return x# 2. 模拟创建分子图数据(实际中使用RDKit从SMILES生成)
# 假设一个分子图:节点特征为原子类型(one-hot),边为化学键
# 这里我们创建两个假分子
num_node_features = 10 # 假设有10种原子类型
dataset = []
# 分子1: 3个原子,2条边
x1 = torch.tensor([[1,0,0,0,0,0,0,0,0,0], # 原子类型1[0,1,0,0,0,0,0,0,0,0], # 原子类型2[0,0,1,0,0,0,0,0,0,0]], dtype=torch.float)
edge_index1 = torch.tensor([[0, 1], [1, 0], [1, 2], [2, 1]], dtype=torch.long).t().contiguous() # 边 0-1, 1-2
y1 = torch.tensor([0.8]) # 假设的结合亲和力pIC50值# 分子2: 4个原子,3条边
x2 = torch.tensor([[1,0,0,0,0,0,0,0,0,0],[0,1,0,0,0,0,0,0,0,0],[0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,1,0,0,0,0]], dtype=torch.float)
edge_index2 = torch.tensor([[0,1], [1,0], [1,2], [2,1], [2,3], [3,2]], dtype=torch.long).t().contiguous()
y2 = torch.tensor([0.2])data1 = Data(x=x1, edge_index=edge_index1, y=y1)
data2 = Data(x=x2, edge_index=edge_index2, y=y2)
dataset = [data1, data2]
loader = DataLoader(dataset, batch_size=2)# 3. 初始化模型和优化器
model = MolecularGNN(num_node_features=num_node_features, hidden_dim=16, num_classes=1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()# 4. 训练循环(简化版,仅一个epoch)
model.train()
for data in loader:optimizer.zero_grad()out = model(data)loss = criterion(out, data.y)loss.backward()optimizer.step()print(f"Training Loss: {loss.item()}")# 5. 预测新分子
model.eval()
new_molecule = data1 # 用分子1作为新分子示例
with torch.no_grad():predicted_activity = model(new_molecule)print(f"预测的结合亲和力 (pIC50): {predicted_activity.item():.4f}")4. 图表:分子结构与预测活性关系图
图片描述: 一个散点图,X轴是实验测得的真实生物活性(pIC50),Y轴是AI模型预测的生物活性。理想情况下,所有点应该分布在一条斜率为1的直线上。该图用于评估模型预测的准确性。旁边可以配一个分子结构式,高亮显示模型认为对结合贡献最大的原子或化学键。
5. Prompt示例
对药物化学家:“针对‘KRAS G12C’这个靶点,基于我们已有的活性化合物数据集,请使用生成式AI设计100个具有新颖骨架的分子,要求其预测的pIC50 > 8.0,且类药性(QED)得分 > 0.6。”
对AI科学家:“当前的GNN模型对于大环类化合物的活性预测偏差较大。请分析是否是消息传递的层数不足导致无法捕获长程相互作用,并提出改进方案,例如加入注意力机制或相对位置编码。”
三、 AI在教育领域的应用
AI正在推动教育走向个性化、规模化和智能化,实现“因材施教”的千年理想。
案例一:自适应学习与知识追踪
1. 业务背景与价值
传统教育是“一刀切”的,无法顾及每个学生的知识掌握状态和学习速度。自适应学习系统通过AI动态评估每个学生的知识状态,推荐最适合其当前能力的练习内容,从而实现个性化学习路径,提升学习效率。
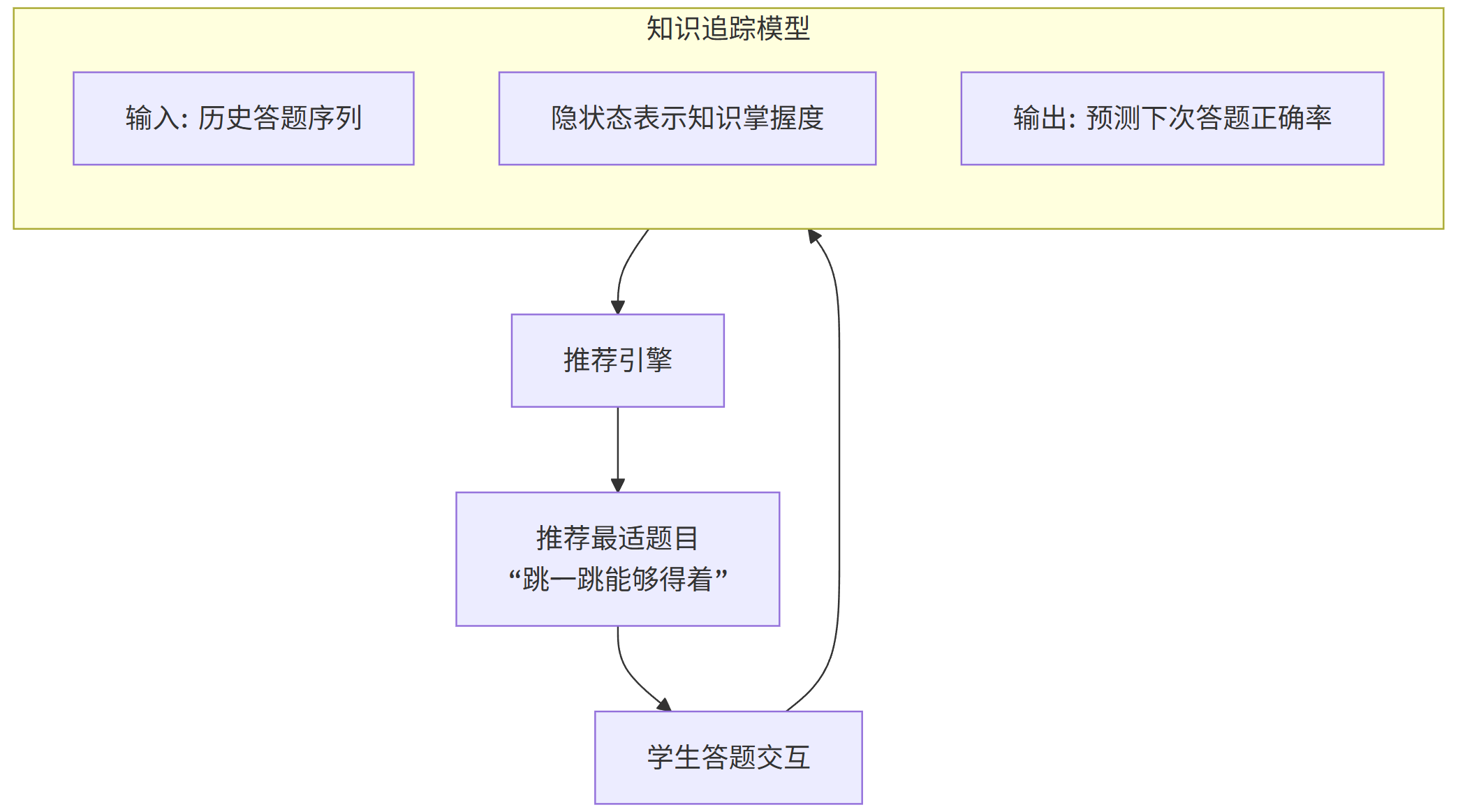
2. 技术实现与流程图
核心是知识追踪(Knowledge Tracing, KT)模型,它试图模拟学生大脑中知识点的掌握状态随时间的变化。
技术栈: 逻辑回归、贝叶斯知识追踪(BKT)、深度知识追踪(DKT)使用RNN/LSTM。
核心数据: 学生的答题序列,包括题目涉及的知识点、答题正误、答题时间等。
flowchart TDA[学生答题交互] --> B[更新知识状态模型]subgraph B [知识追踪模型]B1[输入: 历史答题序列]B2[隐状态表示知识掌握度]B3[输出: 预测下次答题正确率]endB --> C[推荐引擎]C --> D[推荐最适题目<br>“跳一跳能够得着”]D --> A
3. 代码示例(深度知识追踪DKT的简化实现)
python
import torch
import torch.nn as nn
import numpy as np# 1. 定义DKT模型
class DKTModel(nn.Module):def __init__(self, num_skills, hidden_dim):super(DKTModel, self).__init__()self.num_skills = num_skills# 输入: (技能ID, 是否正确) 的联合编码,所以输入维度是 2 * num_skillsself.input_dim = 2 * num_skillsself.hidden_dim = hidden_dimself.lstm = nn.LSTM(self.input_dim, self.hidden_dim, batch_first=True)self.output_layer = nn.Linear(self.hidden_dim, num_skills) # 预测每个知识点的掌握概率def forward(self, x, hidden=None):lstm_out, hidden = self.lstm(x, hidden)output = torch.sigmoid(self.output_layer(lstm_out))return output, hidden# 2. 模拟数据
# 假设有3个知识点 (0, 1, 2), 我们模拟一个学生的答题序列
# 输入需要被编码为 one-hot: 例如,回答知识点1,正确 -> [0,0,0, 0,1,0]? 更常见的做法是:
# 一种编码方式:对于每个时间步,创建一个长度为 2 * num_skills 的向量。
# 前半部分表示考察的技能,后半部分表示回答是否正确。
# 例如,回答技能0,正确: [1,0,0, 1,0,0]
# 回答技能0,错误: [1,0,0, 0,0,0]
# 回答技能1,正确: [0,1,0, 0,1,0]num_skills = 3
# 模拟一个序列: 答对技能0, 答错技能1, 答对技能2
skill_seq = [0, 1, 2]
correct_seq = [1, 0, 1]def encode_input(skill_id, correct, num_skills):encoding = np.zeros(2 * num_skills)encoding[skill_id] = 1 # 设置技能ID位置为1encoding[num_skills + skill_id] = correct # 在“正确性”部分设置return encoding# 构建输入序列
input_sequence = []
for s, c in zip(skill_seq, correct_seq):input_sequence.append(encode_input(s, c, num_skills))input_tensor = torch.FloatTensor([input_sequence]) # shape: (1, seq_len, input_dim)# 3. 初始化模型并进行预测
model = DKTModel(num_skills=num_skills, hidden_dim=16)
model.eval()with torch.no_grad():output, hidden = model(input_tensor)# output shape: (1, seq_len, num_skills)print("模型预测的下一次回答各知识点的正确概率:")# 通常我们取最后一个时间步的输出,作为对下一个题目的预测next_prediction = output[0, -1, :]for skill_id, prob in enumerate(next_prediction):print(f" 知识点 {skill_id}: {prob:.4f}")# 根据预测,推荐学生最需要练习的知识点(预测正确率最低的)recommended_skill = torch.argmin(next_prediction).item()print(f"\n推荐学生接下来练习知识点: {recommended_skill}")4. 图表:学生知识状态变化图
图片描述: 一个折线图,X轴是时间或答题次数,Y轴是知识掌握概率(0到1)。图中有多条折线,分别代表不同知识点(如“一元一次方程”、“因式分解”)。可以清晰地看到,随着学生答题,某些知识点的掌握度在波动中上升,而某些知识点始终处于低位,这为个性化推荐提供了依据。
5. Prompt示例
对学生/老师:“根据小明最近50次的数学练习数据,生成一份知识掌握度报告。指出他的优势知识点和薄弱环节,并从题库中为他精选5道针对薄弱环节的、难度适中的题目。”
对课程设计者:“分析所有学生在‘浮力’这一章的学习路径数据,找出最常见的错误概念和‘学习瓶颈’。并建议如何调整教学视频的顺序或增加新的讲解案例来突破这个瓶颈。”
案例二:AI口语老师与作文批改
1. 业务背景与价值
语言学习需要大量的练习和即时反馈,但外教资源稀缺且昂贵。AI可以通过语音识别和NLP技术,为学习者提供随时随地的口语对话练习和作文批改服务,大幅降低练习成本。
2. 技术实现与流程图
以作文批改为例。
技术栈: 语法错误纠正(GEC)、文本表征模型(如BERT)、文本生成。
核心数据: 标注了语法错误、润色建议的作文语料库。
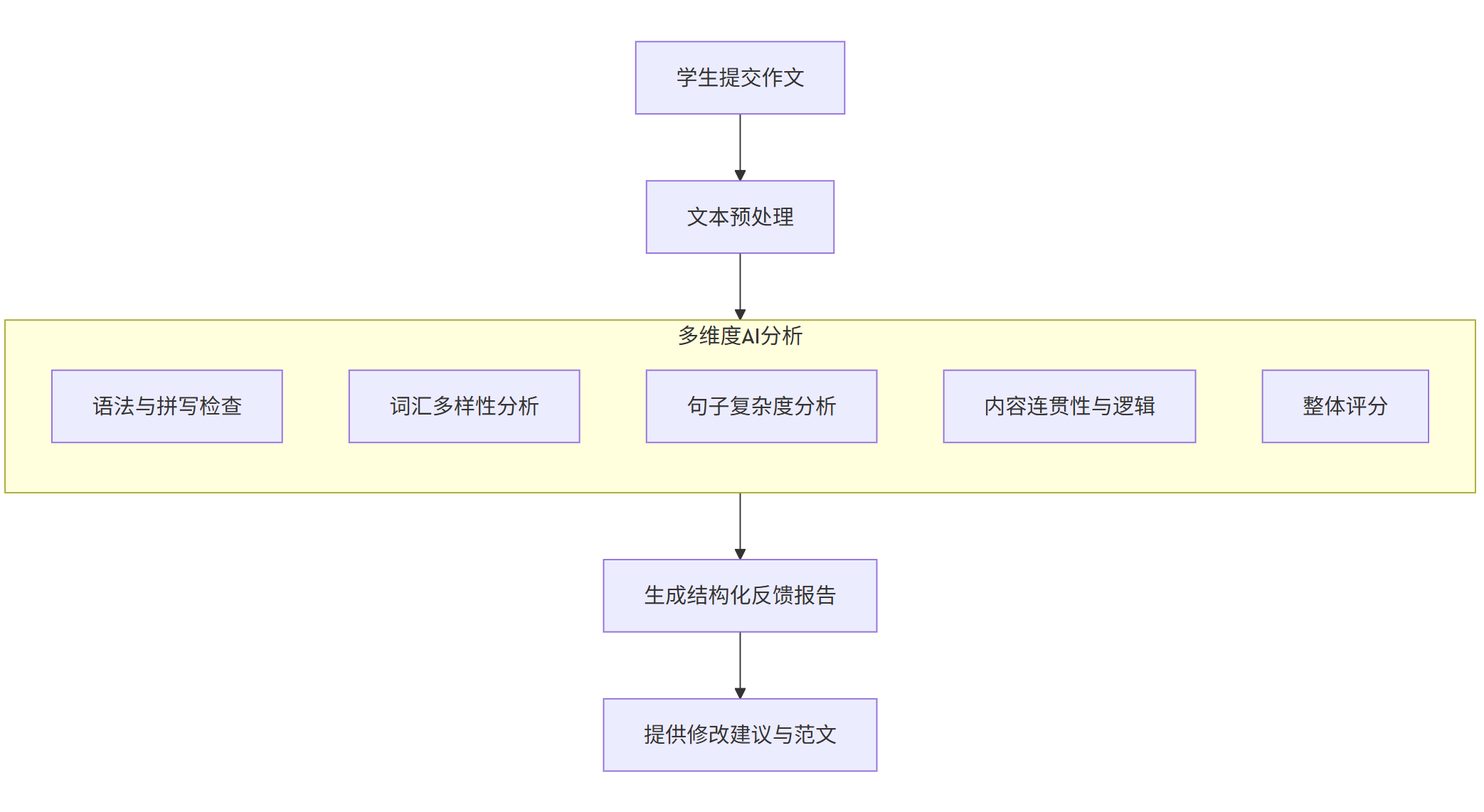
flowchart TDA[学生提交作文] --> B[文本预处理]B --> C[多维度AI分析]subgraph C [多维度AI分析]C1[语法与拼写检查]C2[词汇多样性分析]C3[句子复杂度分析]C4[内容连贯性与逻辑]C5[整体评分]endC --> D[生成结构化反馈报告]D --> E[提供修改建议与范文]
3. 代码示例(使用Transformer库进行语法纠错概念)
python
# 注意:这是一个概念性示例,实际应用需要使用专门的GEC模型和大量数据训练。
from transformers import pipeline# 1. 使用一个文本生成管道来模拟语法纠错
# 实际中,你应该使用像 'grammarly/coedit-large' 或 'vennify/t5-base-grammar-correction' 这样的专门模型
corrector = pipeline('text2text-generation', model='vennify/t5-base-grammar-correction', device=0) # 使用GPU# 2. 学生提交的有语法错误的句子
student_essay = """
I goes to school by a bus. Yesterday, I seen a beautiful bird.
She are singing very loud. Life is full with challenges.
"""# 将文章按句号分割成句子(简单的分割)
sentences = [s.strip() for s in student_essay.split('.') if s.strip()]print("原文及AI批改建议:")
print("-" * 50)for i, sentence in enumerate(sentences):if not sentence:continueprint(f"\n原句 {i+1}: {sentence}")# 构建纠正提示prompt = f"grammar: {sentence}"try:corrected_results = corrector(prompt, max_length=64, num_return_sequences=1)corrected_sentence = corrected_results[0]['generated_text']print(f"修正 {i+1}: {corrected_sentence}")except Exception as e:print(f"处理句子时出错: {e}")corrected_sentence = sentence# 3. 整体评分和反馈(模拟)
# 一个更复杂的系统会综合所有句子的纠错结果进行分析
print("\n" + "="*50)
print("AI综合反馈报告:")
print(" 总体评价: 作文基本达意,但存在较多基础语法错误,如主谓一致、动词时态和介词使用。")
print(" 建议: 1. 重点复习'主谓一致'规则。")
print(" 2. 练习不规则动词的过去式。")
print(" 3. 注意介词 'by', 'with' 的用法区别。")4. 图表:作文批改界面示意图
图片描述: 一个类似于Word的界面,学生的原文显示在左侧。AI系统在右侧有一个反馈面板,列出了“语法错误”、“词汇建议”、“逻辑连贯性”等维度的评分。在原文中,有语法错误的单词下面被划上了波浪线(如红色下划线),点击后会弹出修改建议。
5. Prompt示例
对学生:“请扮演我的英语口语陪练老师。我们来进行一场关于‘我最喜欢的电影’的对话。请在我每次说完后,首先纠正我的发音和语法错误,然后以地道的表达方式复述我的句子,最后提出一个相关的问题引导对话继续。”
对AI模型:“请分析以下这段中文作文,从‘立意深度’、‘结构布局’、‘语言表现力’三个维度进行评分(百分制),并为每个维度提供至少两条具体的修改建议。作文内容:[此处粘贴学生作文]”
四、 AI在制造业领域的应用
工业4.0的核心是智能制造,AI是其中枢大脑,致力于提升质量、效率和柔性。
案例一:工业视觉质检
1. 业务背景与价值
在生产线上,传统的人工质检效率低、易疲劳、标准不一。AOI(自动光学检测)设备结合AI视觉模型,可以7x24小时高速、高精度地检测产品表面的划痕、凹陷、污渍、装配错误等缺陷,极大提升了生产质量和效率。
2. 技术实现与流程图
这是一个图像分类或分割问题。
技术栈: CNN图像分类(如ResNet用于良/次品分类)、实例分割(如Mask R-CNN用于定位和分割缺陷区域)。
核心数据: 产线上拍摄的产品图像,标注为“良品”或“次品”,对于次品还需标注缺陷区域。
flowchart TDA[产线摄像头捕获产品图像] --> B[图像预处理]B --> C[AI缺陷检测模型]subgraph C [AI模型推理]C1[方案A: 分类模型<br>输出良品/次品]C2[方案B: 分割模型<br>输出缺陷像素级位置]endC1 --> D{是否次品?}C2 --> E[缺陷位置可视化]D -- 是 --> F[触发机械臂剔除]D -- 否 --> G[流向下一个工序]E --> H[生成质检报告]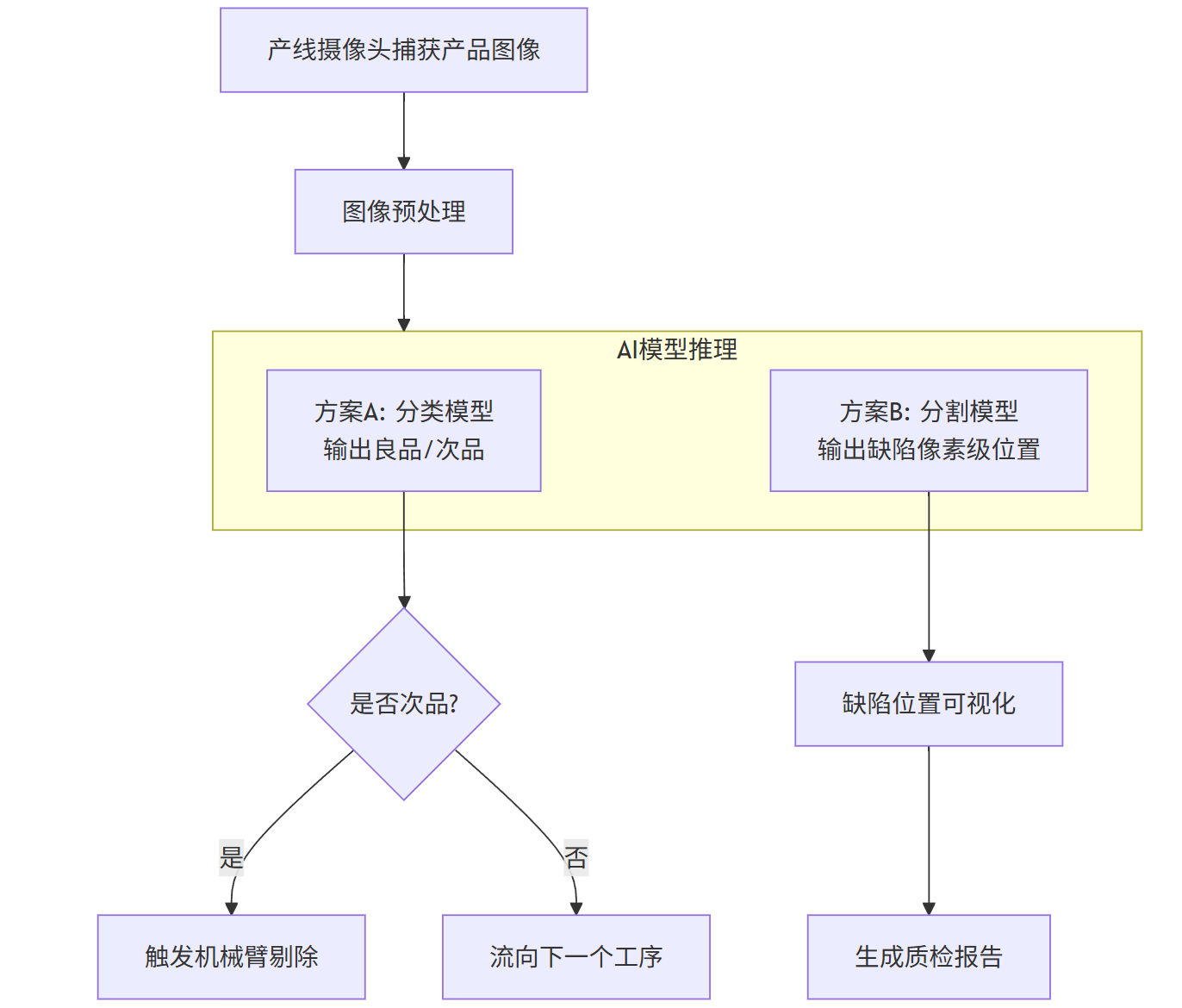
3. 代码示例(使用PyTorch和预训练ResNet进行缺陷分类)
python
import torch
import torch.nn as nn
from torchvision import models, transforms
from PIL import Image# 1. 定义一个基于预训练ResNet的分类模型
def create_model(num_classes=2):model = models.resnet18(pretrained=True)num_ftrs = model.fc.in_featuresmodel.fc = nn.Linear(num_ftrs, num_classes) # 替换最后的全连接层return model# 2. 加载训练好的模型权重(假设我们已经训练好了一个模型)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = create_model(num_classes=2)
model.load_state_dict(torch.load('defect_classification_model.pth', map_location=device))
model.to(device)
model.eval()# 3. 定义图像预处理流程(必须与训练时一致)
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])# 4. 对一张新的产品图像进行预测
def predict_image(image_path):image = Image.open(image_path).convert('RGB')input_tensor = preprocess(image)input_batch = input_tensor.unsqueeze(0).to(device) # 创建batch维度with torch.no_grad():output = model(input_batch)# output是logits,用softmax转换为概率probabilities = torch.nn.functional.softmax(output[0], dim=0)confidence, predicted_class = torch.max(probabilities, 0)class_names = ['ok', 'defect']return class_names[predicted_class], confidence.item()# 5. 测试
image_path = 'path_to_your_product_image.jpg'
prediction, confidence = predict_image(image_path)
print(f"预测结果: {prediction}")
print(f"置信度: {confidence:.4f}")if prediction == 'defect':print("警报!发现缺陷产品,请人工复检或自动剔除。")
else:print("产品合格,继续流转。")4. 图表:缺陷检测热力图
图片描述: 一张合格的产品图像旁边,是一张被检测出有缺陷的产品图像。在缺陷图像上,叠加了一个彩色的“热力图”,红色区域表示模型认为该处最可能是缺陷所在,这有助于工程师理解模型的决策并复检问题。
5. Prompt示例
对产线工程师:“分析过去一周所有被AI系统判为‘划痕’缺陷的图片,统计划痕最常出现的区域和尺寸分布,并判断是否与某个特定的机械臂工位有关。”
对AI工程师:“当前模型对于‘反光’造成的假性缺陷误报率较高。请采用‘异常检测’算法,只使用良品数据进行训练,将任何与良品模式差异过大的图像都判为异常,以期降低此类误报。”
案例二:预测性维护
1. 业务背景与价值
传统维护是定期维护(时间到了就换)或事后维护(坏了再修),成本高且可能造成非计划停机。预测性维护通过AI分析设备传感器数据(振动、温度、噪声等),预测设备在未来一段时间内发生故障的概率,从而在故障发生前、恰当地时机进行维护,最大化设备利用率和寿命。
2. 技术实现与流程图
这是一个时间序列预测和异常检测问题。
技术栈: 时间序列分析(ARIMA)、LSTM/GRU等循环神经网络、CNN1D。
核心数据: 设备历史传感器数据序列、对应的故障记录标签。
flowchart LRA[设备传感器数据流<br>振动/温度/电流] --> B[数据采集与预处理]B --> C[特征提取]subgraph C [特征提取]C1[时域特征: 均值/方差]C2[频域特征: FFT变换]endC --> D[AI健康状态评估模型]D --> E[预测剩余使用寿命 RUL<br>或故障概率]E --> F{概率 > 阈值?}F -- 是 --> G[生成维护工单]F -- 否 --> H[继续监控]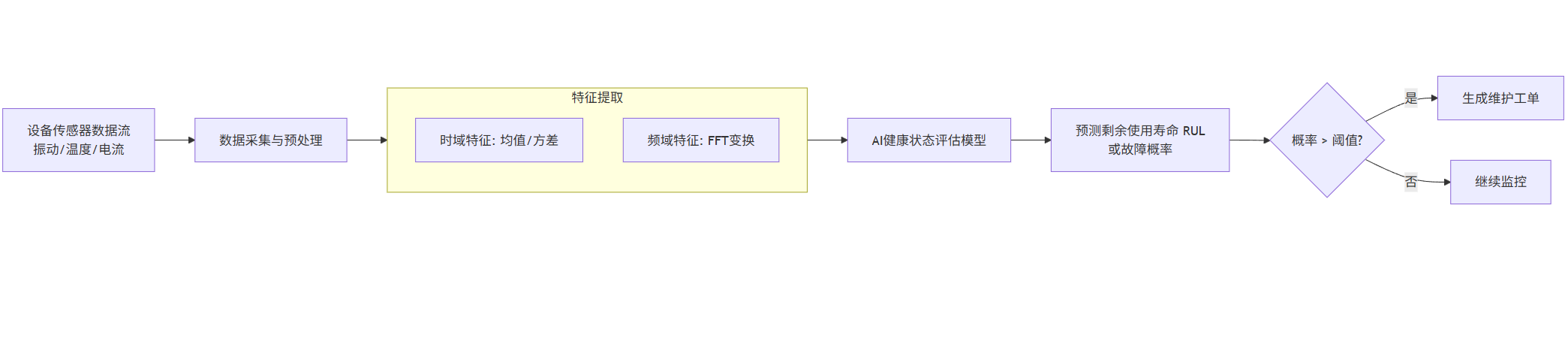
3. 代码示例(使用LSTM预测设备剩余使用寿命RUL)
python
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler# 1. 定义一个简单的LSTM模型
class RULPredictor(nn.Module):def __init__(self, input_size, hidden_size, num_layers, output_size):super(RULPredictor, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)out, _ = self.lstm(x, (h0, c0))out = self.fc(out[:, -1, :]) # 取最后一个时间步的输出return out# 2. 模拟传感器数据(实际中从SCADA系统获取)
# 假设我们监控三个传感器:温度、振动、电流
# 每个设备从开始运行到故障,有一个时间序列数据
def generate_synthetic_data(num_samples, sequence_length, num_sensors):# 模拟数据:传感器读数随着时间逐渐恶化(趋势性上升)data = []rul_labels = [] # 剩余使用寿命for i in range(num_samples):base = np.random.normal(0, 1, (sequence_length, num_sensors))trend = np.linspace(0, 5, sequence_length).reshape(-1, 1) # 线性恶化趋势noise = np.random.normal(0, 0.1, (sequence_length, num_sensors))sensor_data = base + trend + noisedata.append(sensor_data)# RUL假设与趋势强度相关,这里简单定义为序列长度的函数rul = sequence_length - (i % sequence_length) # 模拟每个样本处于生命周期的不同阶段rul_labels.append(rul)return np.array(data), np.array(rul_labels)# 参数
num_samples = 1000
sequence_length = 50
num_sensors = 3
hidden_size = 32
num_layers = 2
output_size = 1# 生成数据
X, y = generate_synthetic_data(num_samples, sequence_length, num_sensors)# 数据标准化
scaler_x = MinMaxScaler()
scaler_y = MinMaxScaler()
X_reshaped = X.reshape(-1, num_sensors)
X_scaled = scaler_x.fit_transform(X_reshaped).reshape(num_samples, sequence_length, num_sensors)
y_scaled = scaler_y.fit_transform(y.reshape(-1, 1))# 转换为PyTorch张量
X_tensor = torch.FloatTensor(X_scaled)
y_tensor = torch.FloatTensor(y_scaled)# 3. 初始化模型、损失函数和优化器
model = RULPredictor(num_sensors, hidden_size, num_layers, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 4. 训练模型(简化,只一个epoch)
model.train()
optimizer.zero_grad()
outputs = model(X_tensor)
loss = criterion(outputs, y_tensor)
loss.backward()
optimizer.step()
print(f'Training Loss: {loss.item():.4f}')# 5. 预测新设备的RUL
model.eval()
new_machine_data = X_tensor[0:1] # 取第一个样本作为新设备数据
with torch.no_grad():predicted_rul_scaled = model(new_machine_data)predicted_rul = scaler_y.inverse_transform(predicted_rul_scaled.numpy())actual_rul = scaler_y.inverse_transform(y_scaled[0:1])print(f"预测的剩余使用寿命 (RUL): {predicted_rul[0][0]:.2f} 周期")print(f"实际的剩余使用寿命 (RUL): {actual_rul[0][0]:.2f} 周期")4. 图表:设备健康度与RUL预测曲线
图片描述: 一个双Y轴图表。主Y轴是设备的“健康指数”(由模型计算得出,从100%逐渐下降至0%),副Y轴是预测的“剩余使用寿命(RUL)”。X轴是时间。图上有一条健康指数的平滑下降曲线,还有一条RUL的预测曲线。在某个时间点,当健康指数低于某个阈值(如20%)或RUL低于某个值时,系统会触发预警。
5. Prompt示例
对设备管理员:“汇总本季度所有空压机的预测性维护警报,按‘紧急’、‘高’、‘中’优先级排序,并关联其建议的维护措施和所需备件清单。”
对数据科学家:“我们有一批电机在没有任何传感器读数明显异常的情况下发生了突发故障。请尝试使用无监督学习算法(如隔离森林或自编码器)对这些电机故障前最后24小时的多维传感器数据进行异常检测,以期发现潜在的、未被发现的故障模式。”
总结与展望
通过以上四大领域八个典型案例的深度剖析,我们可以看到AI不再是空中楼阁,而是已经深深地嵌入到各行各业的核心业务流程中,创造了实实在在的价值:
金融: 从风控到投资,AI是效率和安全的守护神。
医疗: 从诊断到制药,AI是医生和研究员得力的超级助手。
教育: 从学习到评估,AI是实现规模化和个性化的关键路径。
制造: 从质检到维护,AI是提升质量与效率的工业大脑。
未来趋势:
多模态融合: 结合文本、图像、声音、传感器数据进行更综合的决策。
生成式AI的普及: 不仅在内容创作,在分子设计、代码生成、合成数据等领域大放异彩。
AI for Science: AI将加速科学研究,从蛋白质结构预测(如AlphaFold)到新材料发现。
可信AI与伦理: 模型可解释性、公平性、数据隐私将成为AI进一步落地的基石。
边缘AI: 模型将越来越多地部署在终端设备上,实现低延迟、高隐私的实时智能。
AI的行业应用之旅才刚刚开始,其潜力远未被完全挖掘。随着技术的不断进步与应用场景的持续深化,AI必将成为未来数十年社会与经济变革的最强大引擎。