【Linux 系统】进程优先级
文章目录
- 前言
- 1. 进程优先级
- 2. 根据优先级进行调度
- 进程调用的其它算法
- 3. 了解进程切换
前言
本篇文章,小编会和大家分享进程的优先级部分的知识内容,同时包含简单介绍进程的调度算法以及和进程的切换等方面的知识。
如果有哪方面不够正确,希望大家能够指出。
1. 进程优先级
CPU资源是有限的,在单核场景下,CPU资源只有一份,但是一台机器上有多数的进程需要被调度。所以这就决定了进程之间存在着CPU资源的竞争。
- 而操作系统作为软硬件的管理者,就需要让进程进行良性竞争,从而需要确定进程的优先级。(如果一个进程长时间无法得到CPU资源,那么该进程的代码长时间无法推进,这就导致了进程饥饿)
Linux在解决这样的问题的时候,就给每一个进程添加了一个属性字段:优先级。Linux在描述进程的时候,采用了一个结构体:struct task_struct。或许在这个进程启动的时候,Linux操作系统就会在struct task_struct中添加进程优先级的描述字段。我们也可以通过ps命令来查看一个进程的优先级属性:
-
下面是利用
ps -l查看终端的相关信息:

-
其中有两个字段是用来描述一个进程的优先级的:
- PRI:priority 优先级(数字越小优先级越高)
- NI:nice 进程优先级的修正数据。范围是[-20, 19]
这就为我们透露出来一个信息:
-
进程的优先级是可以被修改的。一个进程最终的优先级值的范围就是[60, 99]。
PRI = 80 + NI -
但是实际上操作系统是不希望自己内部的优先级被过多进行修改的,所以但是Linux仍然提供了指令例如:
nice,renice,top可用于修改一个进程的优先级。同时,修改一个进程的优先级是需要权限的!
2. 根据优先级进行调度
- 那么Linux操作系统是如何根据进程的优先级在进行调用的呢?
操作系统的实现,只会更加复杂不会像我们说的这样简单,我们这里仅仅是谈到优先级影响调用。
- 结论:位图结构 + 哈希。实现趋近于O(1)时间复杂度的调度算法。
我们可以理解,Linux中维护了一个struct runqueue的结构体:
struct runqueue
{struct task_struct **running;struct task_struct **waiting;struct task_struct *run[140];struct task_struct *wait[140];
}
-
我们会为运行队列维护两个数组,每一个数组存放的就是
struct task_struct*的指针,这样指针指向一个进程PCB。而进程的优先级决定着这个进程的PCB的连接位置,例如,一个准备运行的进程优先级为60,那么他就被存储在下标为100的,后面同样的优先级可以采用链表的形式链入数组结构中。如果你对数据结构比较敏感,你一定会发现,这不就是哈希桶吗?
- [0, 99]的范围是被操作系统内置的一些进程使用的,一般用户的进程是不在这个区间的。
- [100, 139]的范围恰好就是一个进程nice值的修改范围[-20, 19]。恰好范围相同

run哈希桶:管理的是运行中的进程,随时准备被CPU进行调度。wait哈希桶:管理的是等待中的进程。一个刚刚启动的进程/一个刚刚被CPU切换而下的进程(这是一个细节,保证了优先级高的进程不会反复被调度!),链入这个哈希桶中。
但是这样是不够的。当run中的进程都运行结束了,那么我们怎么实现高效的将wait中的进程转化过来进行调度呢?
我们可以采用两个指针:
struct runqueue
{struct task_struct **running;struct task_struct **waiting;
}
running:指向run哈希桶。所以我们找到需要运行的队列,就找到running指针即可。waiting:指向wait哈希桶。所以我们找到需要的等待队列,就找到waiting指针即可。
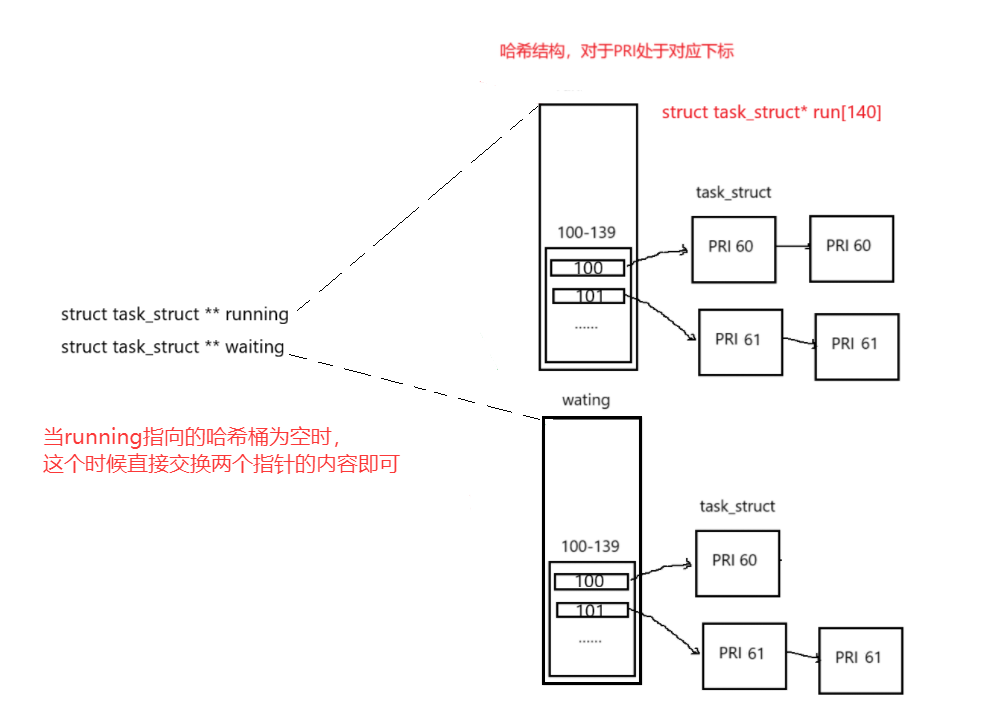
所以操作系统是通过running指针来找到需要运行的进程的。那么当执行的进程哈希桶已经为空了,这个时候我们就需要调度wait中等待的进程了。由于wait和run的结构是相同的,所以如果我们想要找到需要调用的进程,其实十分的简单:对两个指针的内容进行交换即可!即swap(&running, &waiting);交换两者的指针只会,那么此时running指针指向的就是刚刚的等待的进程哈希桶。此时,CPU又可以愉快的进行调度了!
-
那么如何得知
run哈希桶已经为空了呢?我们可以采用位图的数据结构(这里我们只考虑后面40个优先级的进程)。一个bit位又
0/1两种状态,我们利用0:表示当前桶为空;1:表示当前桶不为空。char bitset[5]结构中,5个元素(每一个元素8个bit位)的值都为0的时候,我们就可以认为这个整个run已经为空了。
进程调用的其它算法
进程调用还有一些算法。CPU 是擦欧总系统根据某种策略下选择的下一个要运行的进程,调用的基本单位可以是进程/线程,具体取决于操作系统的设计。CPU 调度的主要目标就是提高系统的效率和资源利用率
| 调度算法 | 原理 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| 先来先服务 | 按照进程就绪的队列顺序进行调度 | 简单易于实现 | 肯恩共导致进程饥饿的问题 | 简单的批处理系统 |
| 短作业优先 | 优先调度时间最短的进程。分为抢占式和非抢占式 | 平均等待时间较短 | 难于预知每一个进程的调度时间,可能造成进程饥饿 | 适用于可以准确预估作业的环节 |
| 轮转调度 | 每一个进程分配一个固定的时间片 | 公平,所有进程都能得到调度。响应时间短 | 时间片设置过长或者过短都会影响性能 | 适用于交互式系统 |
| 优先级调度 | 为每一个进程分配优先级,优先级高先执行 | 可以实现关键任务先处理 | 可能导致优先级低的进程饥饿问题 | 适用于优先级分区的系统 |
| 多级反馈队列 | 将进程按优先级分配称为多个队列,每一个队列按照不同的调度策略 | 结合多种调度算法的优点,灵活且适应性强 | 实现复杂 | 适用于多任务混合的型系统 |
而 Linux
3. 了解进程切换
上面都是谈到了根据进程优先级的调度算法。我们还是很想知道,一个进程是如何被CPU切换下来的。
-
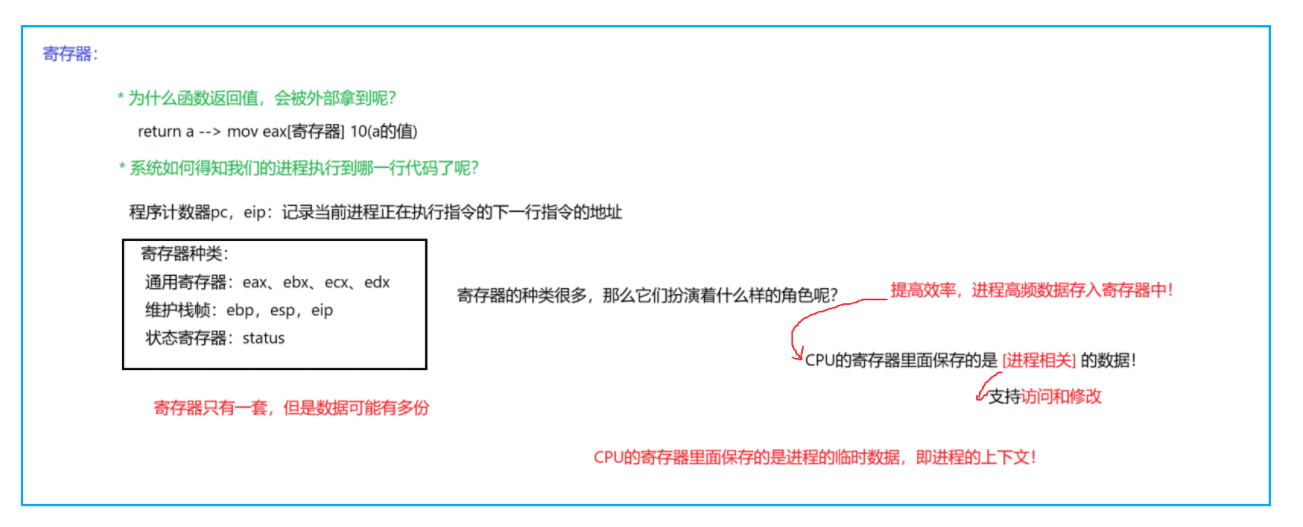
在Linux中,维护了一个进程的描述结构体:
struct task_struct这个结构体中的内容是十分丰富的。其中就包括了一个进程的上下文内容的存储部分。其中就有一个特别重要的字段,记录了进程的所有信息:struct thread_struct thread。这个thread结构体就是专门用于保存进程硬件上下文(尤其是CPU架构相关的寄存器)的。 -
在CPU中集成了许多寄存器,这些寄存器会保存当前进程的热数据。CPU在进行计算的时候,对于这些热数据就不用再去内存中取用数据而是直接使用CPU中的数据,当完成计算的时候,再写回内存即可。
进程切换通常被称为 “上下文切换”(Context Switch)
-
进程切换的过程:
-
切换页全局目录:
-
CPU有一个寄存器叫CR3(在x86架构下),它指向当前进程的页表(实现虚拟地址到物理地址的转化结构)。页表定义了进程的虚拟地址空间到物理内存的映射。(页表不了解的可以看看小编的进程地址空间)
-
切换进程时,内核首先会将CR3寄存器的值更新为下一个进程的页全局目录的物理地址(为了配合MMU实现地址转化)。这实际上就是切换了内存空间。从此以后,CPU发出的虚拟地址将由新进程的页表来解析到全新的物理地址。(实际上就将当前执行的进程的代码改变,那么CPU怎么知道刚刚切换来的进程的应该执行哪里呢?rip,rsp寄存器)这一步是进程隔离的核心,确保了进程A无法访问到进程B的内存。
-
-
切换处理器状态:
-
这包括保存(保存被切换下去的进程上下文)和恢复(恢复被切换上来的进程的上下文)所有volatile的寄存器状态。
-
保存当前状态:将当前进程的所涉及到的寄存器(通用寄存器……)的内容/值,拿到自己内核空间,并最终更新到
task_struct->thread中。(自己的进程上下文就被保存在了自己的struct task_struct中) -
恢复下一个状态:从下一个进程的
task_struct->thread中取出它上次保存的所有寄存器值,并将其加载到对应的CPU寄存器中。特别重要的是栈指针寄存器rsp和指令指针寄存器rip(能够找到CPU应该执行那一条代码)。加载rsp意味着内核栈切换到了下一个进程的内核栈(rsp指向当前栈的顶部)。加载rip意味着CPU接下来要执行的代码,就是下一个进程上次被切换出去时即将要执行的那条指令(通常是在内核态的调度器代码中)。
-
-
-
-
简单来说:

完。希望这篇文章,能够帮助你/