大模型Agent五大工作模式深度解析
前言
在人工智能快速发展的当下,大模型(LLM)已经从单纯的文本生成器,逐渐演化为具备一定“智能行为”的 Agent(智能体)。相比传统的问答交互,Agent能够结合环境反馈、工具调用和自主规划,展现出更强的执行力和适应性

在此背景下,越来越多企业开始探索 多智能体系统,试图找到能覆盖所有代理任务的“通用解法”。例如,两年前研究人员提出的 ChatDev 系统,便是一个虚拟软件公司,内部由多个智能代理协作运作:从首席执行官、首席产品官,到设计师、程序员、测试员与审稿人,各司其职,如同现实的软件工程团队一般。这类案例不仅展示了代理在复杂任务中的潜力,也为未来的 智能化工作流程与组织形态 提供了启示。

为什么(代理)模式很重要
- 模式提供了一种结构化的方式来思考和设计系统。
- 模式使我们能够构建和发展复杂的人工智能应用程序,并适应不断变化的需求。基于模式的模块化设计更容易修改和扩展。
- 模式通过提供经过验证的可重用模板来帮助管理协调多个代理、工具和工作流程的复杂性。它们促进最佳实践和开发人员之间的共同理解。
何时使用代理或者不使用代理?
- 始终首先寻求最简单的解决方案。如果您知道解决问题所需的确切步骤,那么固定的工作流程甚至简单的脚本可能比代理更高效、更可靠。
- 代理系统通常会以增加的延迟和计算成本来换取复杂、模糊或动态任务上潜在的更好性能。确保收益大于这些成本。
- 在处理已知步骤的明确定义的任务时,使用工作流实现可预测性和一致性
- 当需要灵活性、适应性和模型驱动的决策时,使用代理 。
- 保持简单(静止):即使在构建代理系统时,也要努力实现最简单有效的设计。过于复杂的代理可能会变得难以调试和管理。
- 代理引入了固有的不可预测性和潜在错误。代理系统必须包含强大的错误日志记录、异常处理和重试机制,让系统(或底层 LLM)有机会自我纠正。
模式概述
要理解一个大模型Agent如何工作,核心在于它背后所依赖的 工作模式。
目前主流的Agent大多围绕五种关键模式:
-
反射模式(Reflection pattern ):让模型通过自我检视和修正提升推理能力;
-
工具使用模式( Tool use pattern):赋予模型调用外部工具与系统的能力;
-
ReAct模式(Reason and Act):在推理与行动之间动态切换,实现更高效的决策;
-
规划模式(Planning pattern):让模型具备长期目标分解与任务执行的能力;
-
多智能体模式(Multi-agent pattern):通过协作与分工,形成复杂任务的群体智能;
Reflection pattern(反射模式)
Reflection 设计模式是让 Agent 审视并修正自己的输出。
因为 LLM 的不确定性,AI 初次输出往往无法达到理想的效果,如果我们此时提供一些关键信息反馈,帮助 LLM 改正其响应, 此时我们获得理想输出的概率就能大幅提升。
如果能够自动执行「关键反馈」的步骤, 让 LLM 自动校正自己的输出并改进其响应,结果会怎样?这就是 Reflection 设计模式的出发点。
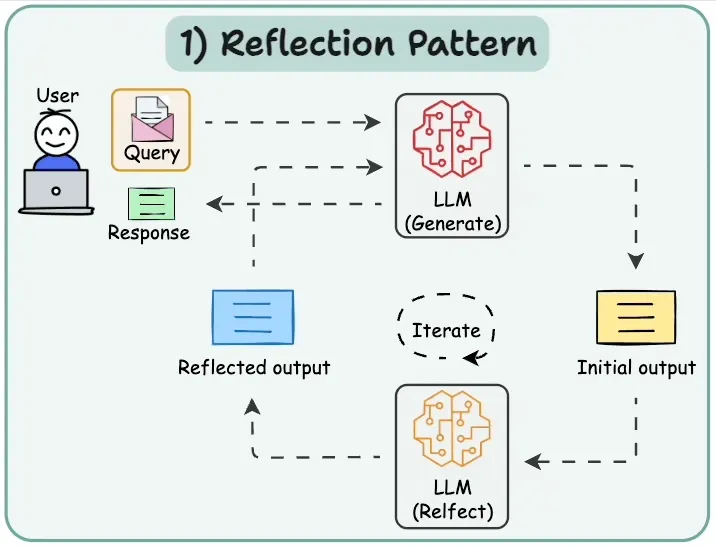
该模式的工作流程如下:
-
用户输入查询:用户通过界面或 API 向 Agent 发起查询请求。
-
LLM 生成初始输出:大型语言模型(LLM)接收查询后,生成一个初步响应。
-
用户反馈:用户对该响应进行评估,并提供反馈意见。
-
LLM 反思与调整:LLM 基于用户反馈,对初步响应进行反思和优化,生成改进后的输出。
-
迭代优化:上述过程可多次循环,直至用户对结果满意,得到最终响应。
使用案例:
- 代码生成:编写代码、执行代码,使用错误消息或测试结果作为反馈来修复错误。
- 写作和完善:生成草稿,反思其清晰度和语气,然后对其进行修改。
- 解决复杂问题:制定计划,评估其可行性,并根据评估进行完善。
- 信息检索:在提供答案之前搜索信息并使用评估器 LLM 检查是否找到了所有必需的详细信息。
import os
import json
from google import genai
from pydantic import BaseModel
import enum# Configure the client (ensure GEMINI_API_KEY is set in your environment)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])class EvaluationStatus(enum.Enum):PASS = "PASS"FAIL = "FAIL"class Evaluation(BaseModel):evaluation: EvaluationStatusfeedback: strreasoning: str# --- Initial Generation Function ---
def generate_poem(topic: str, feedback: str = None) -> str:prompt = f"Write a short, four-line poem about {topic}."if feedback:prompt += f"\nIncorporate this feedback: {feedback}"response = client.models.generate_content(model='gemini-2.0-flash',contents=prompt)poem = response.text.strip()print(f"Generated Poem:\n{poem}")return poem# --- Evaluation Function ---
def evaluate(poem: str) -> Evaluation:print("\n--- Evaluating Poem ---")prompt_critique = f"""Critique the following poem. Does it rhyme well? Is it exactly four lines?
Is it creative? Respond with PASS or FAIL and provide feedback.Poem:
{poem}
"""response_critique = client.models.generate_content(model='gemini-2.0-flash',contents=prompt_critique,config={'response_mime_type': 'application/json','response_schema': Evaluation,},)critique = response_critique.parsedprint(f"Evaluation Status: {critique.evaluation}")print(f"Evaluation Feedback: {critique.feedback}")return critique# Reflection Loop
max_iterations = 3
current_iteration = 0
topic = "a robot learning to paint"# simulated poem which will not pass the evaluation
current_poem = "With circuits humming, cold and bright,\nA metal hand now holds a brush"while current_iteration < max_iterations:current_iteration += 1print(f"\n--- Iteration {current_iteration} ---")evaluation_result = evaluate(current_poem)if evaluation_result.evaluation == EvaluationStatus.PASS:print("\nFinal Poem:")print(current_poem)breakelse:current_poem = generate_poem(topic, feedback=evaluation_result.feedback)if current_iteration == max_iterations:print("\nMax iterations reached. Last attempt:")print(current_poem)Tool Use Pattern (工具使用模式)
工具使用模式是让 Agent 借助外部工具来增强自身能力。
因为 LLM 虽然在语言理解和生成上很强大,但在实时信息获取、精确计算或特定任务执行上存在局限。如果我们在合适的场景下为 LLM 提供外部工具(如计算器、数据库、搜索引擎、API 等),它就能弥补这些不足,生成更可靠、更精准的结果。
如果进一步让 LLM 自动决定何时调用工具、选择合适的工具、并对工具输出进行整合,那么它就不仅仅是“生成文本”,而是能够像人类一样主动利用资源完成复杂任务。这正是工具使用模式的核心价值。
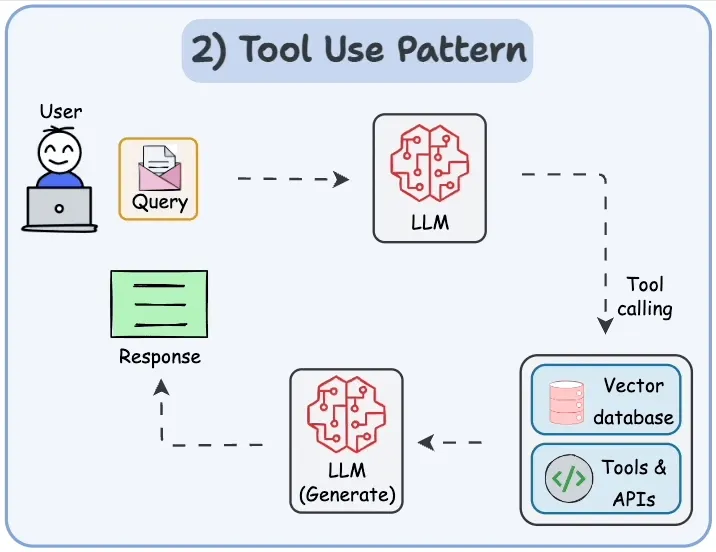
该模式的工作流程如下:
- 用户输入查询:用户通过界面或 API 向 Agent 提交查询请求。
- LLM 处理请求:Agent 内部的大型语言模型(LLM)接收并理解查询。在必要时,LLM 会判断是否需要借助外部工具或数据源。
- 工具与 API 调用:若查询涉及额外信息或计算,LLM 会调用已注册的工具或 API(可存储在向量数据库中)以获取所需数据。
- 生成响应:LLM 综合自身能力与工具返回的结果,生成最终响应。该响应形式可以是文本、表格、图表或其他数据结构。
- 返回结果:响应内容通过界面或 API 返回给用户,供其使用或进一步交互。
使用案例:
- 使用日历 API 预约约会。
- 通过金融 API 检索实时股票价格。
- 在矢量数据库中搜索相关文档 (RAG)。
- 控制智能家居设备。
- 执行代码片段。
import os
from google import genai
from google.genai import types# Configure the client (ensure GEMINI_API_KEY is set in your environment)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# Define the function declaration for the model
weather_function = {"name": "get_current_temperature","description": "Gets the current temperature for a given location.","parameters": {"type": "object","properties": {"location": {"type": "string","description": "The city name, e.g. San Francisco",},},"required": ["location"],},
}# Placeholder function to simulate API call
def get_current_temperature(location: str) -> dict:return {"temperature": "15", "unit": "Celsius"}# Create the config object as shown in the user's example
# Use client.models.generate_content with model, contents, and config
tools = types.Tool(function_declarations=[weather_function])
contents = ["What's the temperature in London right now?"]
response = client.models.generate_content(model='gemini-2.0-flash',contents=contents,config = types.GenerateContentConfig(tools=[tools])
)# Process the Response (Check for Function Call)
response_part = response.candidates[0].content.parts[0]
if response_part.function_call:function_call = response_part.function_callprint(f"Function to call: {function_call.name}")print(f"Arguments: {dict(function_call.args)}")# Execute the Functionif function_call.name == "get_current_temperature": # Call the actual functionapi_result = get_current_temperature(*function_call.args)# Append function call and result of the function execution to contentsfollow_up_contents = [types.Part(function_call=function_call),types.Part.from_function_response(name="get_current_temperature",response=api_result)]# Generate final responseresponse_final = client.models.generate_content(model="gemini-2.0-flash",contents=contents + follow_up_contents,config=types.GenerateContentConfig(tools=[tools]))print(response_final.text)else:print(f"Error: Unknown function call requested: {function_call.name}")
else:print("No function call found in the response.")print(response.text)
ReAct模式(Reason and Act)
ReAct 设计模式是让 Agent 在“思考(Reason)”和“行动(Act)”之间不断切换,从而更高效地解决问题。
因为 LLM 虽然擅长生成语言,但如果只停留在“思考”层面,往往难以执行具体任务;而如果只会“调用工具”,又可能缺乏全局推理的连贯性。如果我们让 LLM 既能进行推理,又能在合适时机调用工具,将两者结合,就能显著提升任务完成的质量和效率。
如果进一步实现让 LLM 在推理过程中自主决定何时推理、何时行动、何时整合结果,那么它就能像人类一样边思考边操作。这就是 ReAct 模式的核心出发点。
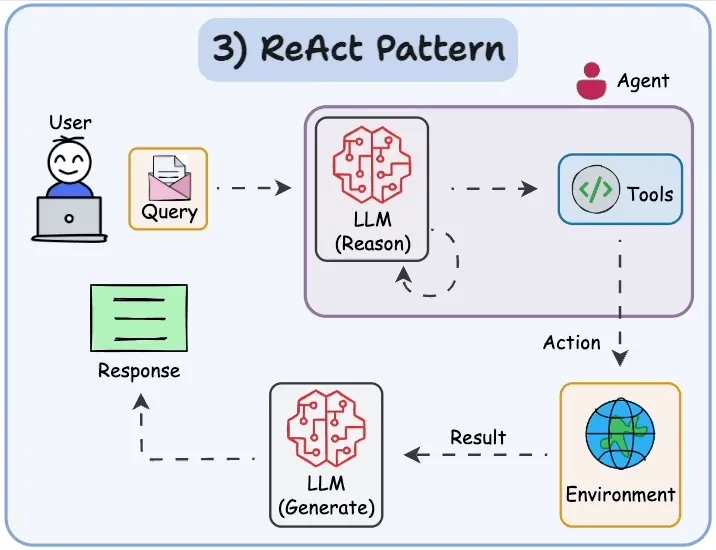
该模式的工作流程如下:
- 用户(User):用户向系统提出查询(Query),即需要解决的任务或请求。
- LLM 推理(Reason):系统中的语言模型对查询进行分析,生成解决问题的思路、策略或行动计划。
- 工具调用(Tools):根据推理过程中的需求,Agent 选择并调用合适的工具或 API 来执行具体操作。
- 环境交互(Environment):工具执行操作后,将结果返回给系统的环境层。
- LLM 生成(Generate):环境反馈的结果被输入到生成模型中,由其整合推理与执行的结果,生成最终答案。
使用案例:
- 进行问答时,先分析问题,再决定是否调用工具。
- 根据用户的输入推理需要的数据来源,例如搜索引擎或数据库。
- 遇到复杂任务时,分解问题并一步步执行(推理 + 行动)。
- 执行外部 API 查询后,对结果进行再加工并生成自然语言回答。
- 模拟“思考—行动—反馈”循环。
import os
from google import genai
from google.genai import types# 配置客户端(需设置 GEMINI_API_KEY)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# 定义工具:获取当前天气
weather_function = {"name": "get_weather_info","description": "获取指定城市的天气情况","parameters": {"type": "object","properties": {"city": {"type": "string", "description": "城市名称,例如:London"},},"required": ["city"],},
}# 模拟外部函数:返回天气数据
def get_weather_info(city: str) -> dict:if city.lower() == "london":return {"temperature": "16", "unit": "Celsius", "condition": "Cloudy"}return {"temperature": "28", "unit": "Celsius", "condition": "Sunny"}# 配置工具
tools = types.Tool(function_declarations=[weather_function])# 用户提问(触发 ReAct 流程:Reason -> Act -> Response)
contents = ["I'm planning a trip, should I bring an umbrella to London today?"]# 初次生成(Reasoning 阶段:模型分析问题,决定是否调用工具)
response = client.models.generate_content(model="gemini-2.0-flash",contents=contents,config=types.GenerateContentConfig(tools=[tools])
)# 检查模型是否选择调用函数(Action 阶段)
response_part = response.candidates[0].content.parts[0]
if response_part.function_call:function_call = response_part.function_callprint(f"模型选择调用函数: {function_call.name}")print(f"参数: {dict(function_call.args)}")if function_call.name == "get_weather_info":# 执行工具调用api_result = get_weather_info(**function_call.args)# 将调用结果反馈给模型(Feedback 阶段)follow_up_contents = [types.Part(function_call=function_call),types.Part.from_function_response(name="get_weather_info",response=api_result)]# 再次生成最终响应(Response 阶段)final_response = client.models.generate_content(model="gemini-2.0-flash",contents=contents + follow_up_contents,config=types.GenerateContentConfig(tools=[tools]))print("最终回答:", final_response.text)else:print("未知的函数调用。")
else:print("模型未调用函数,直接回答:", response.text)规划模式(Planning pattern)
规划设计模式是让 Agent 在执行任务前,先生成一个整体的计划和分解步骤。
因为 LLM 在处理复杂任务时,如果直接输出结果,往往容易遗漏关键环节或逻辑不清晰;但如果它能够先进行任务拆解,规划清晰的行动路径,再逐步执行,就能大大提升结果的准确性与可控性。
如果进一步让 LLM 自动完成“制定计划—执行步骤—验证结果”的循环,它就不仅能回答问题,还能像项目经理一样组织任务、统筹资源,确保复杂目标被逐步实现。这就是规划模式的出发点。
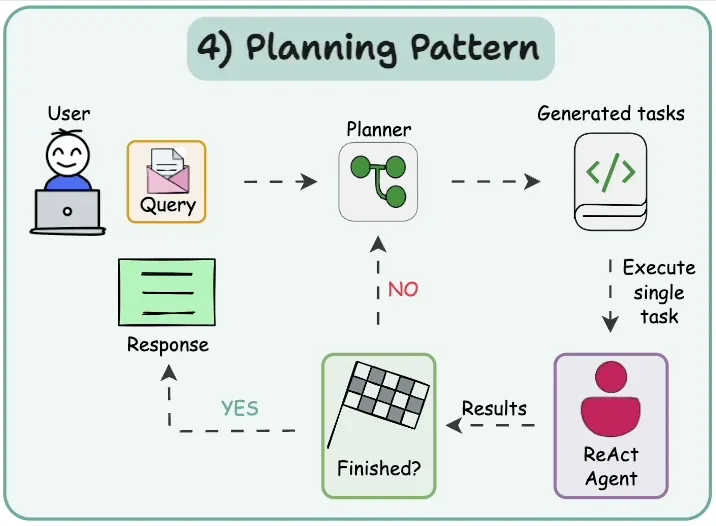
该模式的工作流程如下:
- 用户(User):用户向系统提出查询(Query),例如需要完成的任务或请求。
- 计划器(Planner):计划器接收查询后,对任务进行分析和分解,生成一系列可执行的子任务(Generated Tasks)。
- 任务分配(Task Dispatch):计划器将生成的子任务逐一分配给执行者(ReAct Agent)。
- 执行者(ReAct Agent):执行者根据计划执行具体任务,并将执行结果返回给计划器。
- 结果反馈与验证(Feedback & Verification):计划器接收结果后进行验证。如果任务尚未全部完成,则继续分配剩余任务;若所有任务已完成,则进入收尾阶段。
- 最终响应(Response):计划器整合所有任务的执行结果,生成最终响应,并返回给用户。
使用案例:
- 复杂的软件开发任务:将“构建功能”分解为规划、编码、测试和文档子任务。
- 研究和报告生成:规划文献检索、数据提取、分析和报告撰写等步骤。
- 多模态任务:规划步骤,包括图像生成、文本分析和数据集成。
- 执行复杂的用户请求,例如“计划巴黎 3 天旅行,在我的预算范围内预订航班和酒店”。
import os
from google import genai
from pydantic import BaseModel, Field
from typing import List# Configure the client (ensure GEMINI_API_KEY is set in your environment)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# Define the Plan Schema
class Task(BaseModel):task_id: intdescription: strassigned_to: str = Field(description="Which worker type should handle this? E.g., Researcher, Writer, Coder")class Plan(BaseModel):goal: strsteps: List[Task]# Step 1: Generate the Plan (Planner LLM)
user_goal = "Write a short blog post about the benefits of AI agents."prompt_planner = f"""
Create a step-by-step plan to achieve the following goal.
Assign each step to a hypothetical worker type (Researcher, Writer).Goal: {user_goal}
"""print(f"Goal: {user_goal}")
print("Generating plan...")# Use a model capable of planning and structured output
response_plan = client.models.generate_content(model='gemini-2.5-pro-preview-03-25',contents=prompt_planner,config={'response_mime_type': 'application/json','response_schema': Plan,},
)# Step 2: Execute the Plan (Orchestrator/Workers - Omitted for brevity)
for step in response_plan.parsed.steps:print(f"Step {step.task_id}: {step.description} (Assignee: {step.assigned_to})")
多智能体模式(Multi-agent pattern)
多智能体设计模式是让多个 Agent 协同工作,共同完成复杂任务。
因为单个 LLM 在处理大型或多维任务时,可能面临知识覆盖不足或能力有限的问题,如果我们能够将任务拆分,并分配给不同专长的 Agent,各自独立处理再整合结果,就能显著提升效率和准确性。
如果进一步实现让这些 Agent 之间能够互相交流、协调行动、共享信息,形成一个动态协作的系统,那么它们就能像一个高效团队一样分工合作,解决单个 Agent 无法胜任的复杂问题。这就是多智能体模式的出发。
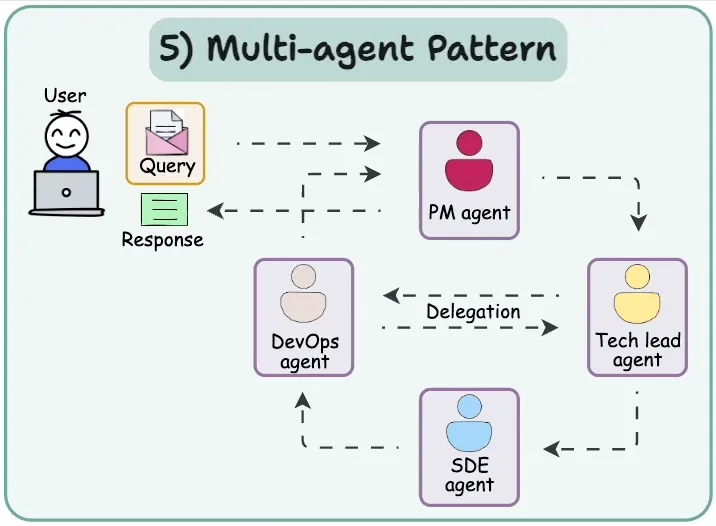
该模式的工作流程如下:
-
用户(User):用户向系统提出查询(Query),例如需要完成的任务或请求。
-
项目经理代理(PM Agent):接收用户查询后,负责分析任务并将其分配给合适的下级代理。
-
DevOps 代理(DevOps Agent):PM Agent 将任务分配给 DevOps Agent,由其处理与基础设施或部署相关的任务。
-
技术负责人代理(Tech Lead Agent):DevOps Agent 将任务进一步分配给 Tech Lead Agent,由其负责技术方案设计和任务监督。
-
软件开发工程师代理(SDE Agent):Tech Lead Agent 将具体开发任务分配给 SDE Agent,由其执行编码或实现工作。
-
任务执行与反馈(Task Execution & Feedback):每个代理根据分配的任务执行操作,并将结果反馈给上一级代理。
-
综合响应(Aggregated Response):当所有任务完成后,PM Agent 综合各代理的结果,生成最终响应并返回给用户。
使用案例:
- 模拟与不同人工智能角色的辩论或头脑风暴会议。
- 复杂的软件创建,涉及用于规划、编码、测试和部署的代理。
- 使用代表不同参与者的代理运行虚拟实验或模拟。
- 协作写作或内容创建过程。
from google import genai
from pydantic import BaseModel, Field# Configure the client (ensure GEMINI_API_KEY is set in your environment)
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# Define Structured Output Schemas
class Response(BaseModel):handoff: str = Field(default="", description="The name/role of the agent to hand off to. Available agents: 'Restaurant Agent', 'Hotel Agent'")message: str = Field(description="The response message to the user or context for the next agent")# Agent Function
def run_agent(agent_name: str, system_prompt: str, prompt: str) -> Response:response = client.models.generate_content(model='gemini-2.0-flash',contents=prompt,config = {'system_instruction': f'You are {agent_name}. {system_prompt}', 'response_mime_type': 'application/json', 'response_schema': Response})return response.parsed# Define System Prompts for the agents
hotel_system_prompt = "You are a Hotel Booking Agent. You ONLY handle hotel bookings. If the user asks about restaurants, flights, or anything else, respond with a short handoff message containing the original request and set the 'handoff' field to 'Restaurant Agent'. Otherwise, handle the hotel request and leave 'handoff' empty."
restaurant_system_prompt = "You are a Restaurant Booking Agent. You handle restaurant recommendations and bookings based on the user's request provided in the prompt."# Prompt to be about a restaurant
initial_prompt = "Can you book me a table at an Italian restaurant for 2 people tonight?"
print(f"Initial User Request: {initial_prompt}")# Run the first agent (Hotel Agent) to force handoff logic
output = run_agent("Hotel Agent", hotel_system_prompt, initial_prompt)# simulate a user interaction to change the prompt and handoff
if output.handoff == "Restaurant Agent":print("Handoff Triggered: Hotel to Restaurant")output = run_agent("Restaurant Agent", restaurant_system_prompt, initial_prompt)
elif output.handoff == "Hotel Agent":print("Handoff Triggered: Restaurant to Hotel")output = run_agent("Hotel Agent", hotel_system_prompt, initial_prompt)print(output.message)
OpenAI 的Realtime API Agents (实时 API 代理)模式
项目地址:https://github.com/openai/openai-realtime-agents
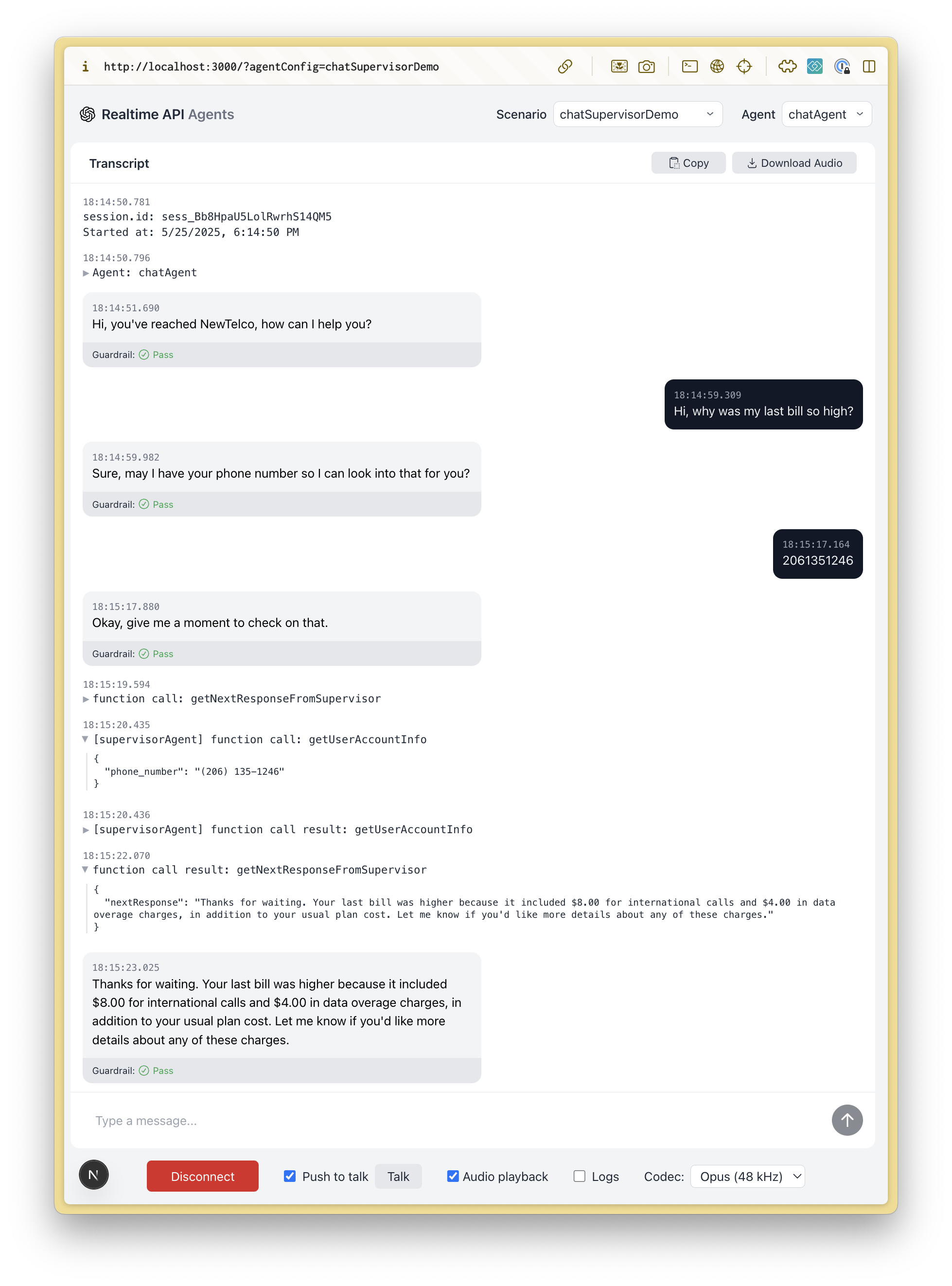
聊天主管模式
基于实时的聊天代理与用户交互并处理基本任务,而更智能的、基于文本的主管模型(例如 gpt-4.1)则广泛用于工具调用和更复杂的响应。这种方法提供了简单的入口和高质量的答案,但延迟略有增加。
顺序交接
专用代理(由实时 API 提供支持)在它们之间传输用户以处理特定的用户意图。这对于客户服务非常有用,因为用户意图可以由在特定领域表现出色的专业模型按顺序处理。这有助于避免模型在单个代理中包含所有指令和工具,从而降低性能。