利用视觉对齐的文本洞察进行医学图像分割
Harnessing Text Insights with Visual Alignment for Medical Image Segmentation
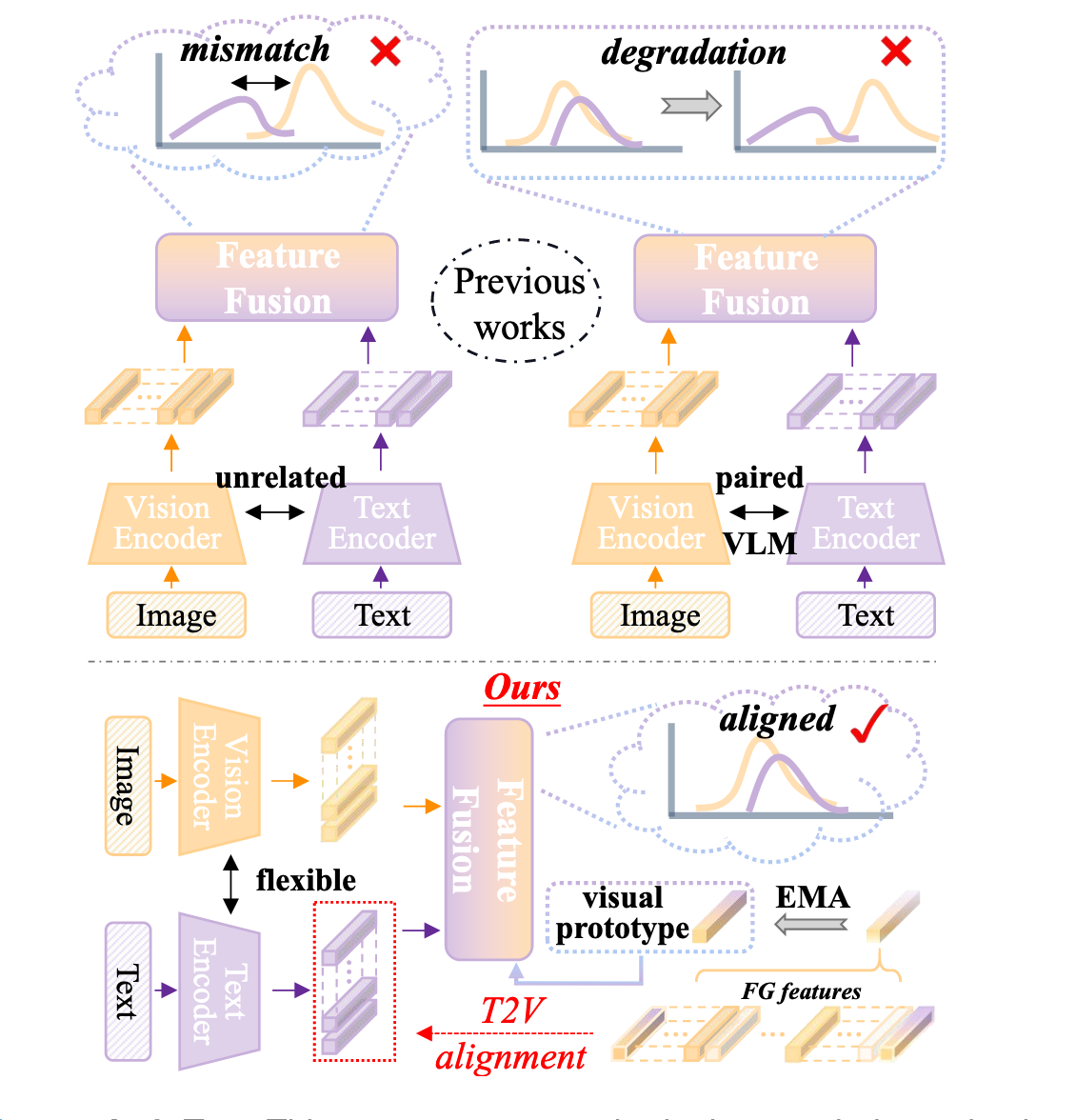
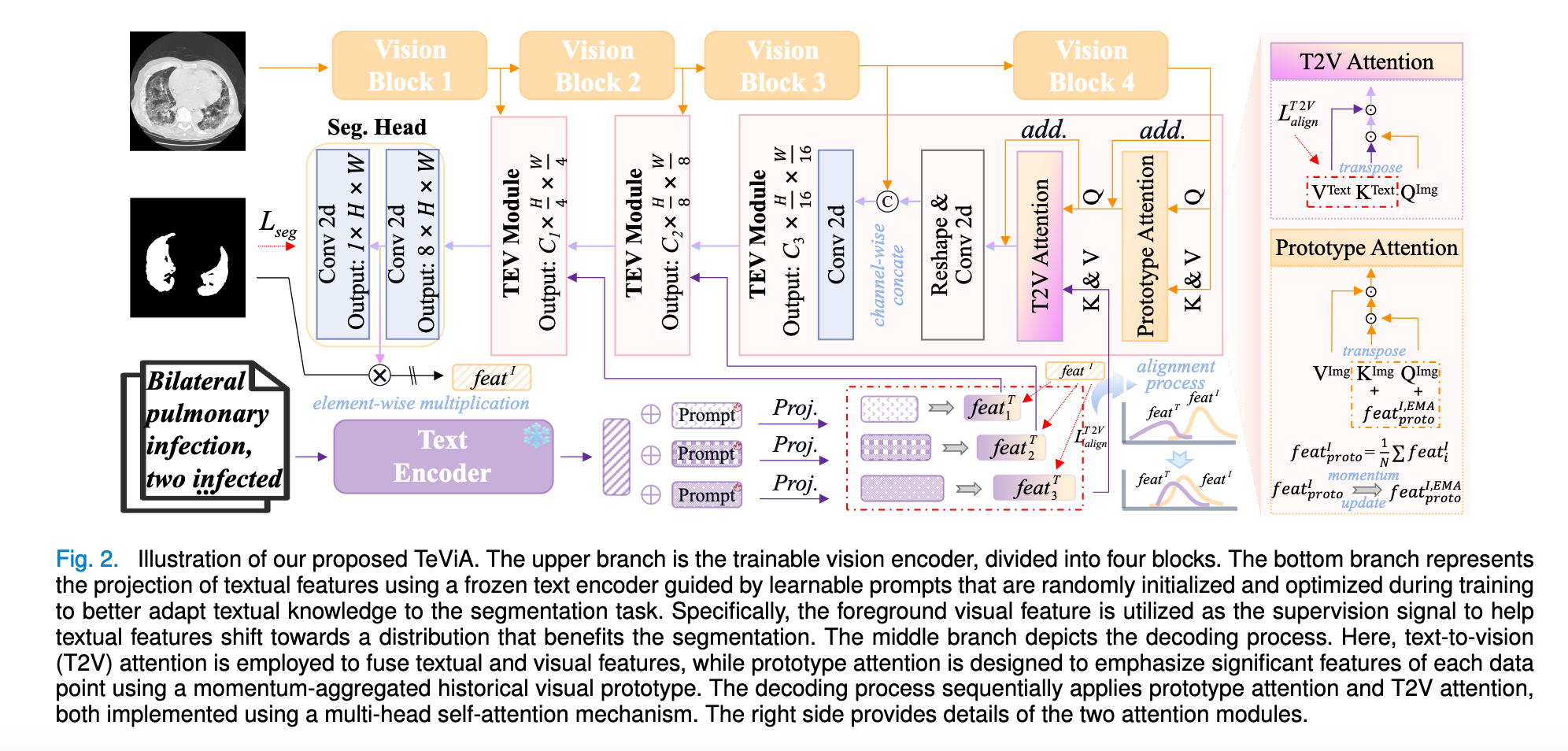
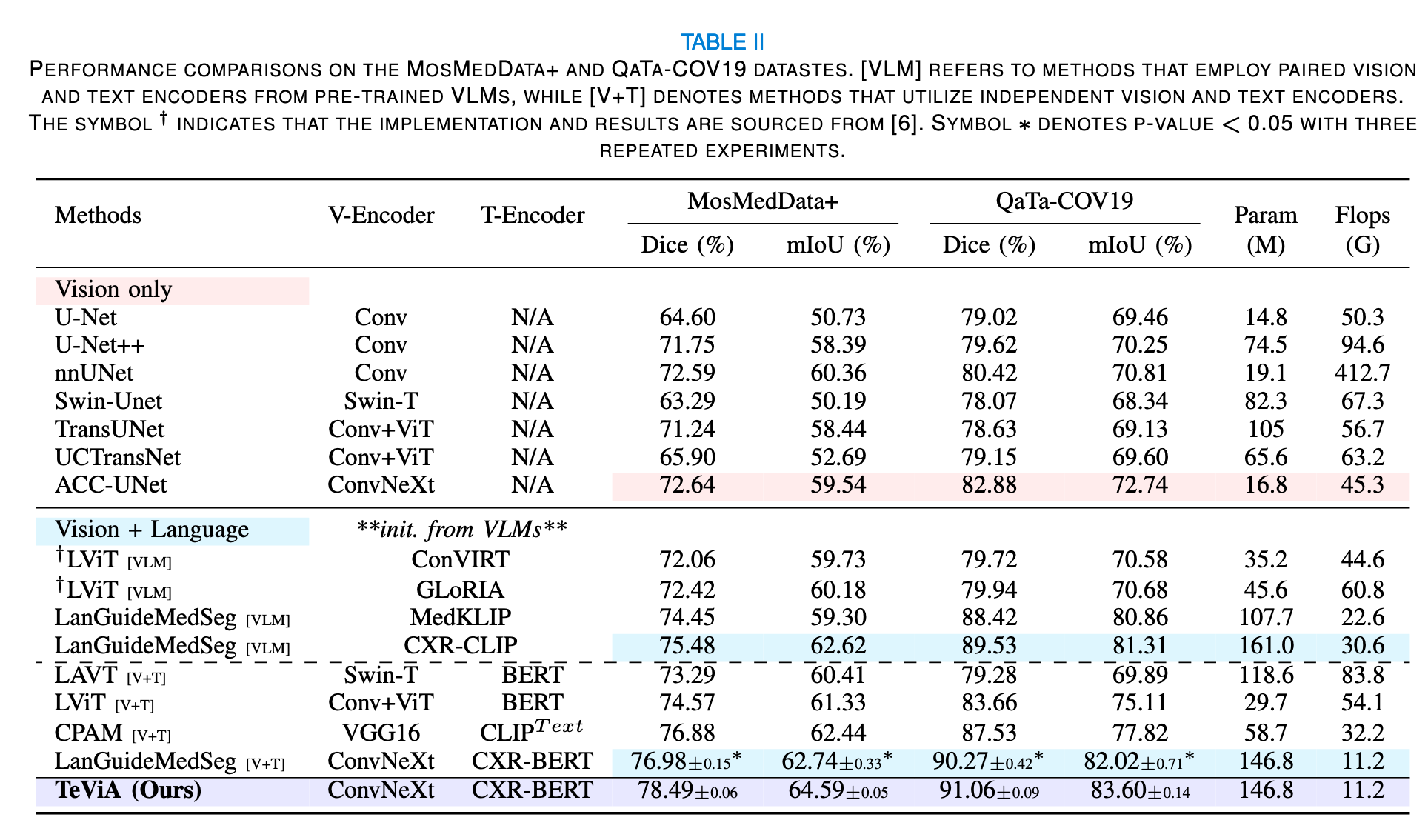
摘要:预训练的视觉语言模型 (VLM) 和语言模型 (LM) 近年来因其出色的文本概念表示能力而备受关注,为视觉任务开辟了新途径。在医学图像分割中,人们正在努力使用 VLM 和 LM 来整合文本和图像数据。然而,当前的文本增强方法面临着一些挑战。首先,使用单独的预训练视觉和文本模型来编码图像和文本数据可能会导致语义偏移。其次,虽然 VLM 在对成对的图像-文本数据进行预训练时可以建立视觉和文本特征之间的对应关系,但由于持续学习过程中文本和视觉成分之间的错位,这种对齐在分割任务中往往会恶化。在本文中,我们提出了一种新颖的方法 TeViA,它可以与各种视觉和文本模型无缝集成,而不受它们的预训练关系的影响。这种集成是通过特定于分割的文本到视觉对齐设计实现的,确保了信息增益和语义一致性。具体来说,对于每个训练数据,从分割头提取前景视觉表征,并将其用于监督投影层,从而调整文本特征,使其更好地完成分割任务。此外,通过聚合所有训练数据中的目标语义,创建一个历史视觉原型,并使用基于动量的方式进行更新。该原型旨在通过建立特征级连接来增强每个数据实例的视觉表征,从而细化文本特征。TeViA 的优势已在五个公共数据集上得到验证,与纯视觉方法相比,Dice 得分提升超过 6%。