融合:迈向 “一台计算机” 的终极架构
🚀 欢迎来到「数据中心网络与异构计算」专栏!
在这个算力定义未来的时代,我们正见证一场从底层网络到计算架构的深刻变革。本专栏将带您穿越技术迷雾,从当前困境出发,历经三次关键技术跃迁,最终抵达「数据中心即计算机」的终极愿景。
专栏导航:《数据中心网络与异构计算:从瓶颈突破到架构革命》![]() https://blog.csdn.net/apple_53311083/article/details/152372997?sharetype=blogdetail&sharerId=152372997&sharerefer=PC&sharesource=apple_53311083&spm=1011.2480.3001.8118
https://blog.csdn.net/apple_53311083/article/details/152372997?sharetype=blogdetail&sharerId=152372997&sharerefer=PC&sharesource=apple_53311083&spm=1011.2480.3001.8118
目录
一、RDMA 落地后的现实困境:物理连通≠逻辑统一
1.1 异构设备的 “缓存割裂” 痛点
1.2 内存资源的 “孤岛困境”
1.3 存储架构的 “层级瓶颈”
二、CXL 的破局之路:主机与存储的形态重构与资源池化设想
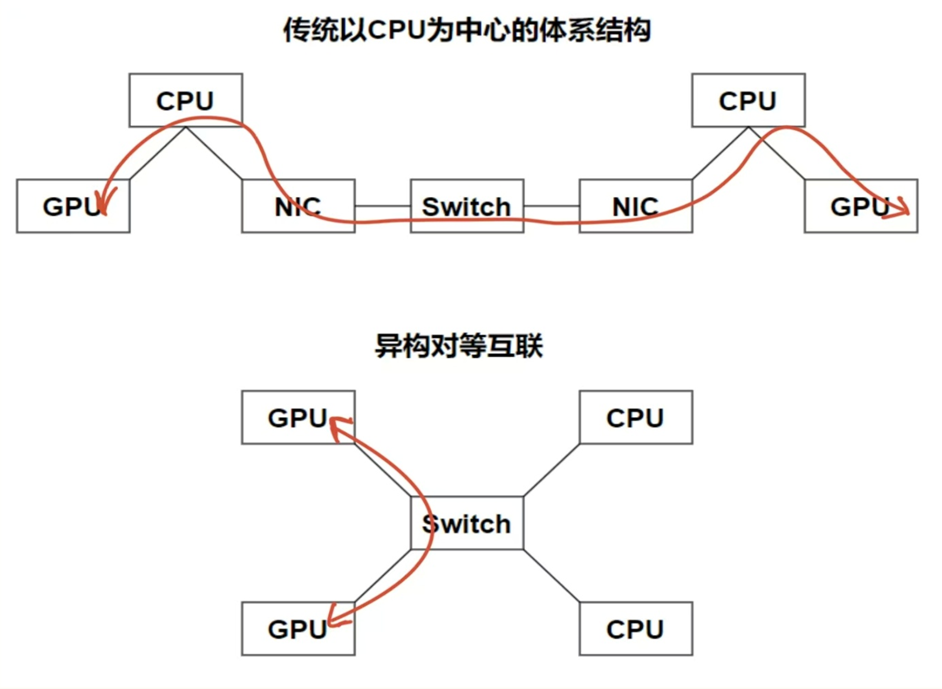
2.1 主机形态重构:从 “CPU 中心的封闭单元” 到 “异构对等的开放节点”
2.2 存储架构重构:从 “分离层级” 到 “存储 - 内存融合池”
三、“超级 PCB”:数据中心的逻辑一体化终极形态
3.1 打破 “物理连通≠逻辑统一” 的鸿沟
3.2 填补 “缓存一致性缺失” 的短板
3.3 突破 “性能与易用性瓶颈”
四、从 “一群计算机” 到 “一台计算机”:演进的必然与未来的图景
五、结语:技术演进的终点,是 “计算本质” 的回归
上一篇文章中,我们见证了 RDMA 技术的革命性突破 —— 它以 “远程内存直接访问” 的范式,彻底绕开远程 CPU,将数据中心通信延迟从毫秒级压至微秒级,为 AI 训练、HPC 等场景注入关键性能动力。但当 RDMA 大规模落地后,数据中心仍未跳出 “物理分散、逻辑割裂” 的困境:异构设备(CPU、GPU、DPU)的缓存无法同步,内存与存储仍是 “私有孤岛”,资源池化仅停留在 “物理连通” 层面,未实现 “逻辑统一”。正是这道 “最后一公里” 的鸿沟,让 CXL(Compute Express Link)成为从 “RDMA 革命” 迈向 “一体化融合” 的核心桥梁 —— 它不仅要解决 RDMA 留下的痛点,更要推动主机与存储的形态重构,最终让数据中心走向 “一台计算机” 的终极目标。
一、RDMA 落地后的现实困境:物理连通≠逻辑统一
RDMA 的出现,确实打破了 “消息传递” 的传统通信枷锁,但在实际部署中,它更像 “高性能的物理连接线”,未能解决数据中心 “资源协同” 的深层矛盾:
1.1 异构设备的 “缓存割裂” 痛点
RDMA 虽能让 GPU 直接访问远程 CPU 的内存,却无法同步二者的缓存 —— 当 GPU 通过 RDMA 将更新后的数据写入远程内存时,远程 CPU 的缓存中可能仍留存该数据的旧副本,若 CPU 后续读取缓存数据,会导致 “计算结果失准”。为避免这一问题,工程师需在 RDMA 操作后手动插入 “缓存刷新指令”(如 CPU 的clflush指令),这不仅引入 1-2 微秒的额外延迟,更让应用开发复杂度陡增。本质上,RDMA 只解决了 “数据传输” 问题,未解决 “数据一致性” 问题,异构设备仍像 “用高速线连接的独立计算器”,无法像单机内 CPU 与 GPU 那样 “无缝协同”。
1.2 内存资源的 “孤岛困境”
RDMA 支持远程内存访问,但不同节点的内存仍是 “私有资源”——CPU 的 DDR 内存、GPU 的 HBM 内存、DPU 的本地内存,各自拥有独立的地址空间,无法形成 “全局统一视图”。例如,AI 训练集群中,某节点的 GPU 内存不足时,虽能通过 RDMA 读取其他节点的 DDR 内存,但需手动处理 “内存地址映射”“数据分片传输” 等逻辑,无法像使用本地内存那样 “无感知调用”;更关键的是,当多台设备同时访问同一远程内存时,需通过软件锁机制避免冲突,这又会引入新的性能开销,让 RDMA 的优势打折扣。
1.3 存储架构的 “层级瓶颈”
RDMA 虽优化了存储节点与计算节点的通信延迟,但传统 “计算 - 存储分离” 的层级架构未被打破:计算节点需先通过 RDMA 向存储节点发送 IO 请求,存储节点的 CPU 处理请求后,再将数据从 SSD 读取到本地内存,最后通过 RDMA 传输给计算节点。这一过程仍涉及 “存储介质→存储内存→计算内存” 的多轮拷贝,存储节点的 CPU 易成为瓶颈;同时,存储资源分配仍是 “静态绑定”—— 为某计算节点分配的存储容量,即使该节点空闲,也无法被其他节点调用,资源利用率长期停留在 30%-40%。
二、CXL 的破局之路:主机与存储的形态重构与资源池化设想
RDMA 留下的 “逻辑割裂” 痛点,本质是缺乏 “一致性互联协议” 来统合异构资源。而 CXL 通过三大子协议(CXL.io、CXL.cache、CXL.mem),从 “主机形态” 与 “存储架构” 两大维度推动重构,让 “全局资源池化” 从设想变为现实。
2.1 主机形态重构:从 “CPU 中心的封闭单元” 到 “异构对等的开放节点”
传统主机以 CPU 为绝对核心,GPU、内存等均为 “附属设备”,RDMA 虽让设备间通信提速,但未改变 “CPU 主导调度” 的逻辑。CXL 则彻底打破这一格局,推动主机进化为 “接入全局资源池的开放节点”:
异构对等的 “算力协同”:CXL.cache 协议让 GPU、FPGA 等加速器可直接缓存主机内存数据,并通过硬件级一致性机制实时同步 —— 当 GPU 修改缓存数据时,CXL 硬件会自动向 CPU 发送 “缓存失效信号”,CPU 读取时直接获取最新值,无需软件干预。这让异构设备从 “附属执行者” 变为 “对等计算主体”:AI 训练中,GPU 可直接与远程 CPU 共享缓存数据,无需 CPU 中转,协同延迟从 RDMA 的 5 微秒降至纳秒级,算力利用率再提升 20%-30%。
全局统一的 “内存池化”:CXL.mem 协议支持将不同节点、不同类型的内存(DDR、HBM、持久内存)整合为 “全局内存池”,并映射到统一地址空间。例如,某节点的 CPU 可通过load/store原生指令,直接访问另一节点 GPU 的 HBM 内存,或调用远程节点的持久内存;当本地内存不足时,CXL 硬件会自动将数据 “溢出” 到全局内存池,应用无需感知 “数据位置”,仿佛拥有一块 “容量无上限的内存”。这种池化能力,让内存利用率从 RDMA 时代的 50% 提升至 80%,同时避免了 “为单节点升级内存导致的资源浪费”。
弹性扩展的 “设备互联”:CXL.io 协议继承 PCIe 5.0 + 的兼容性,传统 PCIe 设备(如 GPU、网卡)无需改造即可接入 CXL 网络,同时支持 “多设备链式互联”—— 一台主机可通过 CXL 交换机连接数十台异构设备,且带宽叠加无损失。这让主机不再是 “固定配置的封闭盒子”,而是 “按需接入资源的开放接口”:业务高峰时可临时添加 GPU 节点,低谷时释放资源,真正实现 “算力弹性伸缩”。
2.2 存储架构重构:从 “分离层级” 到 “存储 - 内存融合池”
RDMA 优化了存储与计算的通信速度,但未触及 “存储架构层级” 的核心矛盾。CXL 则通过 “存储 - 内存融合” 思路,推动存储从 “独立设备” 变为 “内存级资源”,融入全局资源池:
存储介质的 “内存化访问”:基于 CXL.mem 协议,NVMe SSD、持久内存等存储介质可直接接入 CXL 网络,计算设备无需通过存储节点 CPU,即可像访问内存一样直接读写存储数据。例如,搭载 CXL 接口的 NVMe SSD,可被映射为计算节点的 “扩展内存”——CPU 执行 “读取 0x1234 地址数据” 指令时,CXL 硬件会自动识别该地址对应 SSD,直接从 SSD 读取数据并返回,IO 延迟从 RDMA 时代的 20 微秒降至 10 微秒以内,接近内存级性能。
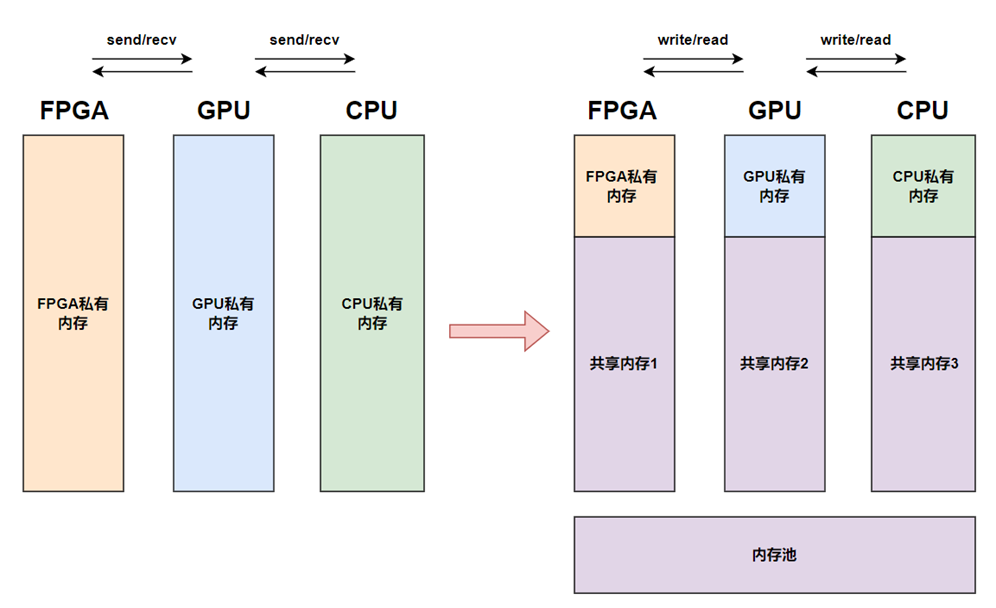
分布式存储的 “池化整合”:CXL 将分散的存储节点整合为 “全局存储池”,并与 “全局内存池” 形成 “热 - 冷数据分层”:高频访问的 “热数据” 存于内存池(DDR/HBM),低频访问的 “冷数据” 存于存储池(SSD / 持久内存)。计算设备通过统一地址空间访问数据时,CXL 硬件会自动完成 “冷数据加载到内存池” 的过程,无需应用干预。例如,大数据分析任务读取历史冷数据时,CXL 会自动将数据从 SSD 加载到远程 DDR 内存,分析过程中无需等待存储 IO,效率提升 50% 以上。
存储资源的 “动态调度”:传统存储资源分配是 “静态绑定”,而 CXL 存储池支持 “按需分配”—— 管理员可通过 CXL 管理平台,实时将空闲存储资源分配给高负载的计算节点,或在负载降低时回收资源。例如,白天 AI 训练高峰时,可临时占用大数据集群的空闲存储;夜间训练结束后,存储资源自动归还,利用率从 30% 提升至 70%,大幅降低存储采购成本。
三、“超级 PCB”:数据中心的逻辑一体化终极形态
RDMA 实现了数据中心的 “物理高速互联”,而 CXL 则完成了 “逻辑统一协同”—— 二者结合,让数据中心在逻辑上成为一块 “超级 PCB(印刷电路板)”:CPU、GPU、内存、存储是 PCB 上的 “功能模块”,PCIe、InfiniBand、CXL 等互联协议是 PCB 上的 “高速铜箔走线”,所有组件以纳秒级延迟、超高带宽紧密耦合,协同工作。
CXL 在这一 “超级 PCB” 中,承担着 “时钟电路与信号协议” 的关键角色,它解决了 RDMA 未能触及的三大核心问题:
3.1 打破 “物理连通≠逻辑统一” 的鸿沟
RDMA 像 “超级 PCB 上的高速铜线”,让模块间物理连接更快;但 CXL 的一致性协议,才让这些模块能 “看见” 同一套 “电路逻辑”—— 不同节点的内存拥有统一地址空间,异构设备的缓存实时同步,不再是 “用高速线连接的独立模块”,而是 “同一 PCB 上的协同组件”。例如,CPU、GPU、DPU 访问同一数据时,无需关心数据在哪个节点,只需通过统一地址调用,CXL 硬件会自动完成数据传输与一致性维护。
3.2 填补 “缓存一致性缺失” 的短板
单机内 CPU 与 GPU 的协同,依赖 PCIe 的缓存一致性协议;而 CXL 将这一能力扩展到分布式场景 —— 通过 CXL.cache,不同节点的异构设备可共享缓存数据,且硬件级机制确保 “所有缓存副本实时同步”。这让分布式协同的 “正确性” 与 “单机内部协同” 达到同一级别:AI 训练中,多节点 GPU 修改同一参数时,CXL 会自动同步所有 GPU 的缓存,无需软件层的一致性校验,既避免计算错误,又减少性能开销。
3.3 突破 “性能与易用性瓶颈”
RDMA 的高性能依赖复杂的编程接口(如 Verbs API),开发者需手动处理内存注册、队列对管理等逻辑;而 CXL 的统一地址空间,让应用开发回归 “单机思维”—— 开发者无需关注数据在本地还是远程,无需处理数据分片、跨节点传输,只需像编写单机程序一样调用资源。例如,基于 CXL 的 AI 框架,可直接使用 “全局内存池” 存储模型参数,无需手动实现 “参数分片与同步”,开发效率提升 30%-50%。
四、从 “一群计算机” 到 “一台计算机”:演进的必然与未来的图景
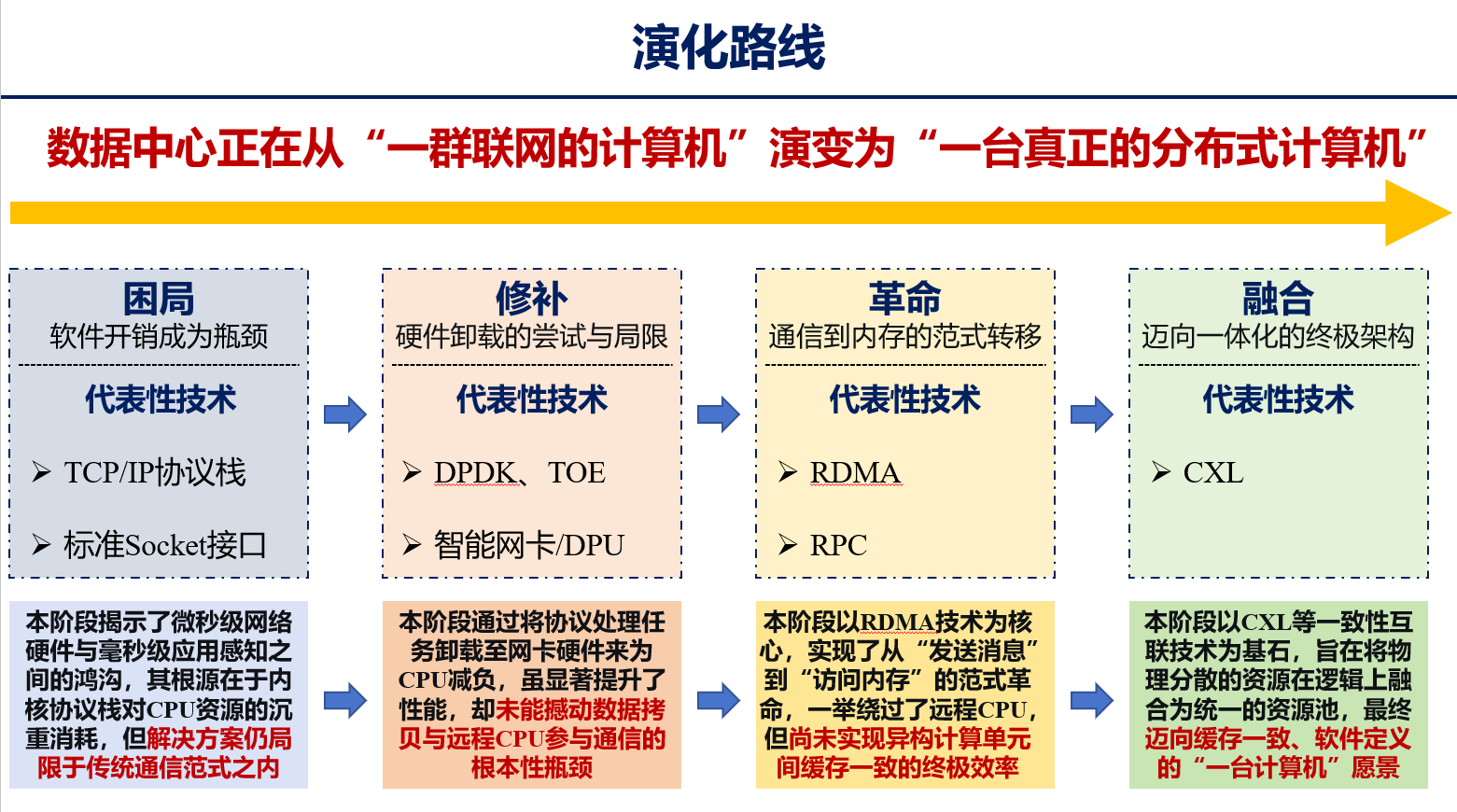
回顾数据中心的技术演进脉络,每一次突破都是对 “分散” 的超越,向 “统一” 的靠近,而 CXL 正是这一进程的 “最后一块拼图”:
- 困局阶段:TCP/IP 与 Socket 的 “软件开销” 拖累性能,数据中心困于 “消息传递” 的传统范式,计算与通信效率失衡;
- 修补阶段:DPDK、智能网卡、DPU 通过硬件卸载为 CPU 减负,缓解了协议处理的压力,却未撼动 “数据拷贝” 与 “远程 CPU 参与” 的根本瓶颈;
- 革命阶段:RDMA 实现 “从发送消息到访问内存” 的范式转移,绕开远程 CPU,将通信延迟压至微秒级,但留下 “异构缓存不一致”“资源孤岛” 的遗憾;
- 融合阶段:CXL 以一致性协议为基石,推动主机与存储的形态重构,实现 “内存 - 存储 - 计算” 的全局池化,终于让数据中心从 “一群联网的计算机”,演变为 “一台缓存一致、软件定义的分布式计算机”。
在这幅未来图景中,数据中心的运维将变得前所未有的简单:管理员无需再为 “某节点内存不足”“某存储负载过高” 烦恼 —— 全局资源池会自动调度空闲资源;开发者无需再学习复杂的分布式编程模型 —— 像开发单机程序一样调用全局算力与内存;异构设备的协同将像 “单机内 CPU 与 GPU 配合” 一样自然 ——CXL 硬件会默默完成一致性维护与数据传输。而这一切的核心,正是 CXL 定义的 “逻辑统一” 架构。
五、结语:技术演进的终点,是 “计算本质” 的回归
从 TCP/IP 的 “机械连接” 到 CXL 的 “有机协同”,数据中心的演化史,本质是对 “计算本质” 的回归 —— 计算本就该是 “资源的无缝协同”,而非 “设备的物理堆砌”。RDMA 打破了通信的速度枷锁,CXL 则消除了逻辑的割裂鸿沟,二者共同推动数据中心跳出 “群岛思维”,成为 “一块超级 PCB”、“一台超级计算机”。
当数据中心真正实现 “逻辑一体化”,我们谈论的将不再是 “跨节点通信”“分布式存储”,而是 “如何用一块‘无限扩展的计算机’解决更复杂的问题”—— 这不仅是技术的里程碑,更是人类对 “资源组织方式” 的认知跃迁。而 CXL,正是这场跃迁的关键推手,它定义的不只是一种协议,更是数据中心的未来形态。