《决策树、随机森林与模型调优》
📦 1.环境准备与数据理解
在开始之前,请确保你的环境已准备好,并花点时间了解我们将要使用的数据。
- 库安装:确保你的虚拟环境中已安装以下库。如果尚未安装,请使用 安装
pip install scikit-learn numpy matplotlib- 理解鸢尾花(Iris)数据集:这是机器学习中最著名的数据集之一。它包含3种鸢尾花(Setosa, Versicolour, Virginica)各50个样本,每个样本有4个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)。我们的任务是根据这些特征预测花的种类。
📅 2.决策树(Decision Tree)
核心目标:理解并实现决策树分类器,完成鸢尾花分类任务。
2.1 导入必要的库和加载数据
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 目标标签(0, 1, 2分别代表三种花)# 查看数据集基本信息(可选,但有助于理解)
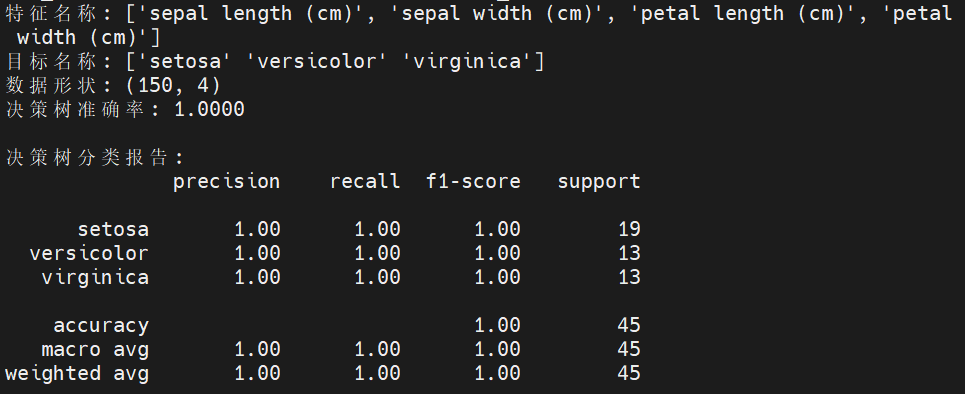
print(f"特征名称: {iris.feature_names}")
print(f"目标名称: {iris.target_names}")
print(f"数据形状: {X.shape}") # 应该是 (150, 4)2.2 划分训练集和测试集
# 将数据划分为70%训练集和30%测试集
# random_state 用于确保每次分割的结果一致,便于结果复现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)2.3 创建、训练决策树模型并进行预测
# 创建决策树分类器对象
# 先使用默认参数,后续再学习调参
dt_clf = DecisionTreeClassifier(random_state=42)# 使用训练数据拟合(训练)模型
dt_clf.fit(X_train, y_train)# 使用训练好的模型对测试集进行预测
y_pred_dt = dt_clf.predict(X_test)2.4 评估模型性能
# 计算准确率
accuracy_dt = accuracy_score(y_test, y_pred_dt)
print(f"决策树准确率: {accuracy_dt:.4f}") # 格式化输出保留4位小数# 打印更详细的分类报告
# 包括精确率(precision)、召回率(recall)、F1分数(F1-score)等
print("\n决策树分类报告:")
print(classification_report(y_test, y_pred_dt, target_names=iris.target_names))2.5 验收标准
- 成功运行:代码无报错,能成功输出决策树模型的准确率和分类报告。
- 理解输出:能读懂分类报告中的精确率、召回率等指标含义。初始准确率通常较高(可能超过0.9)。
- 关键思考:能说出决策树的一个优点(例如:易于理解和解释,可视化强)和一个缺点(例如:容易过拟合,对训练数据的小变化敏感)。
📅 3.随机森林(Random Forest)
核心目标:理解集成学习和随机森林的原理,实现随机森林分类器,并对比其与决策树的性能。
3.1 导入随机森林库
from sklearn.ensemble import RandomForestClassifier3.2 创建、训练随机森林模型并进行预测
# 创建随机森林分类器对象
# n_estimators参数指定森林中树的数量,先设为100
rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)# 使用训练数据拟合模型
rf_clf.fit(X_train, y_train)# 使用训练好的模型对测试集进行预测
y_pred_rf = rf_clf.predict(X_test)3.3 评估模型性能并与决策树对比
# 计算随机森林的准确率
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f"随机森林准确率: {accuracy_rf:.4f}")# 与第14天的决策树准确率进行对比
print(f"\n模型对比:")
print(f"- 决策树准确率: {accuracy_dt:.4f}")
print(f"- 随机森林准确率: {accuracy_rf:.4f}")# (可选)查看随机森林中特征的重要性
print("\n特征重要性:")
for name, importance in zip(iris.feature_names, rf_clf.feature_importances_):print(f"- {name}: {importance:.4f}")3.4 验收标准
- 成功运行:代码无报错,能成功输出随机森林模型的准确率,并能与决策树结果进行对比。
- 性能对比:能观察到随机森林的准确率通常不低于甚至高于单棵决策树。
- 理解优势:能说出随机森林相比决策树的一个主要优势,即通过集成多棵树和特征随机性,有效降低过拟合风险,泛化能力更强。这是集成学习的核心思想
📅 4.模型调优(GridSearchCV)
核心目标:学习使用交叉验证和网格搜索(GridSearchCV)为随机森林寻找最优超参数组合。
4.1 导入网络搜索和交叉验证工具
from sklearn.model_selection import GridSearchCV4.2 定义参数网络
# 指定想要优化的参数及其候选值范围
param_grid = {'n_estimators': [50, 100, 200], # 树的数量'max_depth': [None, 5, 10], # 树的最大深度,None表示不限制'min_samples_split': [2, 5, 10], # 内部节点分裂所需最小样本数'max_features': ['sqrt', 'log2'] # 每次分裂时考虑的最大特征数
}4.3 执行网格搜索
# 创建GridSearchCV对象
# 传入模型、参数网格、交叉验证折数(cv=5)和评分标准(scoring='accuracy')
grid_search = GridSearchCV(estimator=RandomForestClassifier(random_state=42),param_grid=param_grid,cv=5, # 使用5折交叉验证scoring='accuracy',n_jobs=-1 # 使用所有可用的CPU核心并行计算,加快速度
)# 在训练数据上拟合网格搜索对象,它会尝试所有参数组合
grid_search.fit(X_train, y_train)# 输出最佳参数组合和对应的交叉验证准确率
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳交叉验证准确率: {grid_search.best_score_:.4f}")4.4 使用最佳参数模型进行最终评估
# 获取最佳估计器(模型)
best_rf_clf = grid_search.best_estimator_# 使用最佳模型对测试集进行预测
y_pred_best_rf = best_rf_clf.predict(X_test)# 计算在测试集上的准确率,评估其泛化性能
accuracy_best_rf = accuracy_score(y_test, y_pred_best_rf)
print(f"调参后模型在测试集上的准确率: {accuracy_best_rf:.4f}")# 与未调参的随机森林模型进行对比
print(f"\n随机森林调参前后对比:")
print(f"- 调参前测试集准确率: {accuracy_rf:.4f}")
print(f"- 调参后测试集准确率: {accuracy_best_rf:.4f}")4.5 验收标准
- 成功运行:代码无报错,能成功完成网格搜索过程,并输出最佳参数组合和准确率。
- 理解过程:能简要说明网格搜索(遍历给定参数组合)和交叉验证(评估每种组合的稳健性)是如何协同工作的。
- 结果分析:能观察到调参后的模型性能可能有所提升(或保持良好),并理解找到“最佳”参数的目的是为了获得泛化能力更好、更稳健的模型。
4.6 可视化决策树
如果想直观理解决策树的决策过程,可以使用 plot_tree 函数可视化一棵树(可选):给出具体操作步骤
4.6.1 环境与数据准备
1.安装库
pip install scikit-learn matplotlib2. 导入库并加载数据:我们将使用经典的鸢尾花(Iris)数据集进行演示
# 导入所需库
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 目标标签(0, 1, 2 分别代表三种鸢尾花)🌱 训练决策树模型
在可视化之前,需要先训练一个决策树模型
# 创建决策树分类器对象
# 使用 random_state 参数确保每次运行结果一致,便于复现
clf = DecisionTreeClassifier(random_state=42)# 使用数据训练模型
clf.fit(X, y)📊 使用 plot_tree 进行可视化
1.基础可视化
# 设置图形大小,确保节点信息清晰可读
plt.figure(figsize=(20, 10))
# 调用 plot_tree 函数绘制决策树
plot_tree(clf,feature_names=iris.feature_names, # 使用特征名称替代X[0],X[1]等class_names=iris.target_names, # 使用类别名称替代0,1,2filled=True) # 用颜色填充节点,不同颜色代表不同类别
plt.show()2.关键参数详解
通过调整 plot_tree 函数的参数,可以让图形更易读:
feature_names=iris.feature_names: 显示特征的实际名称(如 "sepal length (cm)")而非索引。class_names=iris.target_names: 显示类别的实际名称(如 "setosa")而非数字编码。filled=True: 用颜色填充节点,颜色越深通常表示该节点的“纯度”越高(即样本越属于同一类别)。rounded=True: 使用圆角矩形节点,让图形更美观。impurity=True: 显示节点的基尼不纯度或熵(默认通常为True)。proportion=False: 若设为True,则显示每个节点中样本的比例而非绝对数量。max_depth=None: 可以限制显示的树深度,对于深树可设为3或4以避免图形过于复杂。
优化后的可视化代码示例:
plt.figure(figsize=(16, 8))
plot_tree(clf,feature_names=iris.feature_names,class_names=iris.target_names,filled=True,rounded=True,impurity=True,proportion=True, # 显示样本比例max_depth=3) # 只显示前3层,避免过于复杂
plt.title("决策树可视化示例") # 给图形加个标题
plt.show()3. 保存决策树图形
如果您想将图形保存为图片文件(如PNG或PDF),可以在 plt.show() 之前使用 plt.savefig()。
plt.figure(figsize=(16, 8))
plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True)
plt.savefig('my_decision_tree.png', dpi=300, bbox_inches='tight') # 保存为高清PNG,dpi设置分辨率
plt.show()🔍 如何解读决策树图形
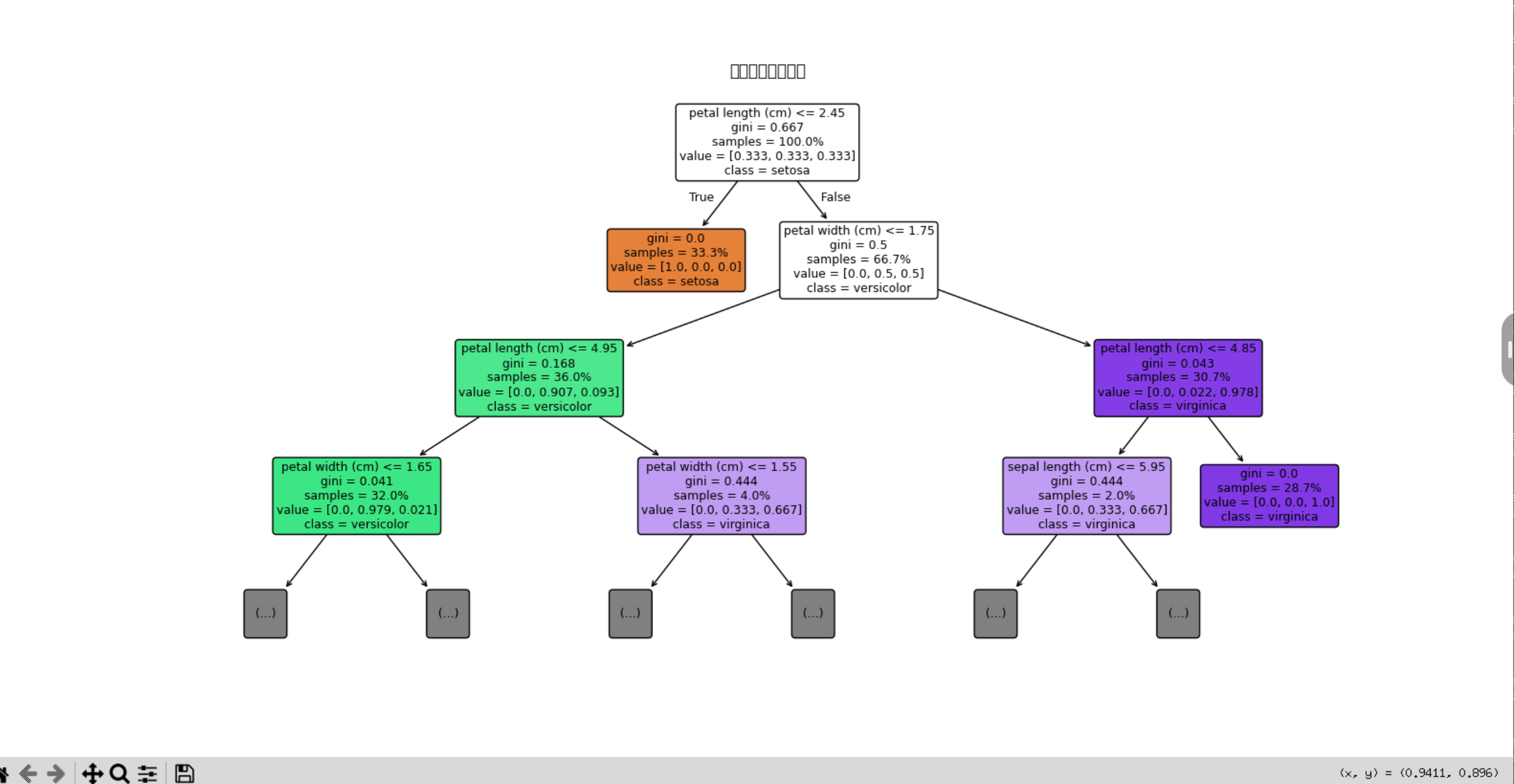
理解图形中的每个元素至关重要,下图梳理了决策树可视化中的关键信息点:
flowchart TDA[决策树节点信息解读] --> B1[根节点/内部节点]A --> B2[分支]A --> B3[叶节点]B1 --> C1["分裂特征与阈值<br>例如: petal length <= 2.45"]B1 --> C2["不纯度指标<br>基尼系数或熵"]B1 --> C3["样本数量/比例<br>samples = 100"]B1 --> C4["类别分布<br>value = [50, 50, 0]"]B2 --> C5["分支条件<br>是/否满足阈值"]B3 --> C6["预测类别<br>class = setosa"]B3 --> C7["节点纯度<br>基尼系数 = 0.0"]- 节点框内的信息:
- 第一行:显示分裂规则。例如
petal length (cm) <= 2.45。这是从根节点开始,对数据进行的第一次划分。 - 第二行:显示基尼不纯度(Gini impurity)或熵(Entropy)。衡量节点的“不纯度”,值越接近0表示该节点包含的样本越属于同一类别。
- 第三行:显示该节点包含的样本数量(
samples)或比例(如果设置了proportion=True)。 - 第四行:
value数组显示该节点中每个类别的样本数量分布。例如value = [50, 50, 0]表示有50个样本属于第一类,50个属于第二类,0个属于第三类。
- 第一行:显示分裂规则。例如
- 颜色深浅:
filled=True时,颜色越深通常表示该节点的主要类别纯度越高。 - 叶节点:树最末端的节点。其
value数组中最高的那个数字对应的类别,就是该叶节点的预测类别。
✅ 验收标准
完成以上步骤后,您可以检查:
- 成功运行:代码无报错,能弹出一个显示决策树结构的窗口。
- 正确解读:能根据节点中的信息(如分裂特征、阈值、样本数、基尼系数)说出几个简单的决策路径。例如:“当花瓣长度小于等于2.45厘米时,模型直接将样本判定为setosa。”
- 成功保存:能在当前代码目录下找到保存的PNG图片文件。