大数据 Python小说数据分析平台 小说网数据爬取分析系统 Django框架 requests爬虫 Echarts图表 17k小说网 (源码)✅
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Django框架、requests爬虫、Echarts可视化、HTML、17k小说网
- 这个项目的研究背景:当前数字阅读市场中,17k小说网等平台积累了海量小说资源,但这些数据多以分散形式存在,缺乏系统的采集、整理与可视化分析。用户与从业者难以直观把握小说类型分布、热门作品趋势、新作品潜力等关键信息,传统人工分析效率低、覆盖范围有限,无法满足对小说市场数据深度挖掘的需求,因此亟需一套整合数据采集与可视化分析的系统,解锁小说数据的价值。
- 这个项目的研究意义:该项目通过requests爬虫技术从17k小说网精准采集数据,解决了数据源分散的问题;借助Echarts可视化工具,将小说类型、点击量、关键词等数据转化为直观图表,帮助用户快速理解市场趋势。基于Django框架构建的系统,搭配后台数据管理功能,保障数据有序维护与高效利用,既为用户提供数据参考,也为小说行业创作、推广提供决策支持,兼具实用价值与技术示范意义。
2、项目界面
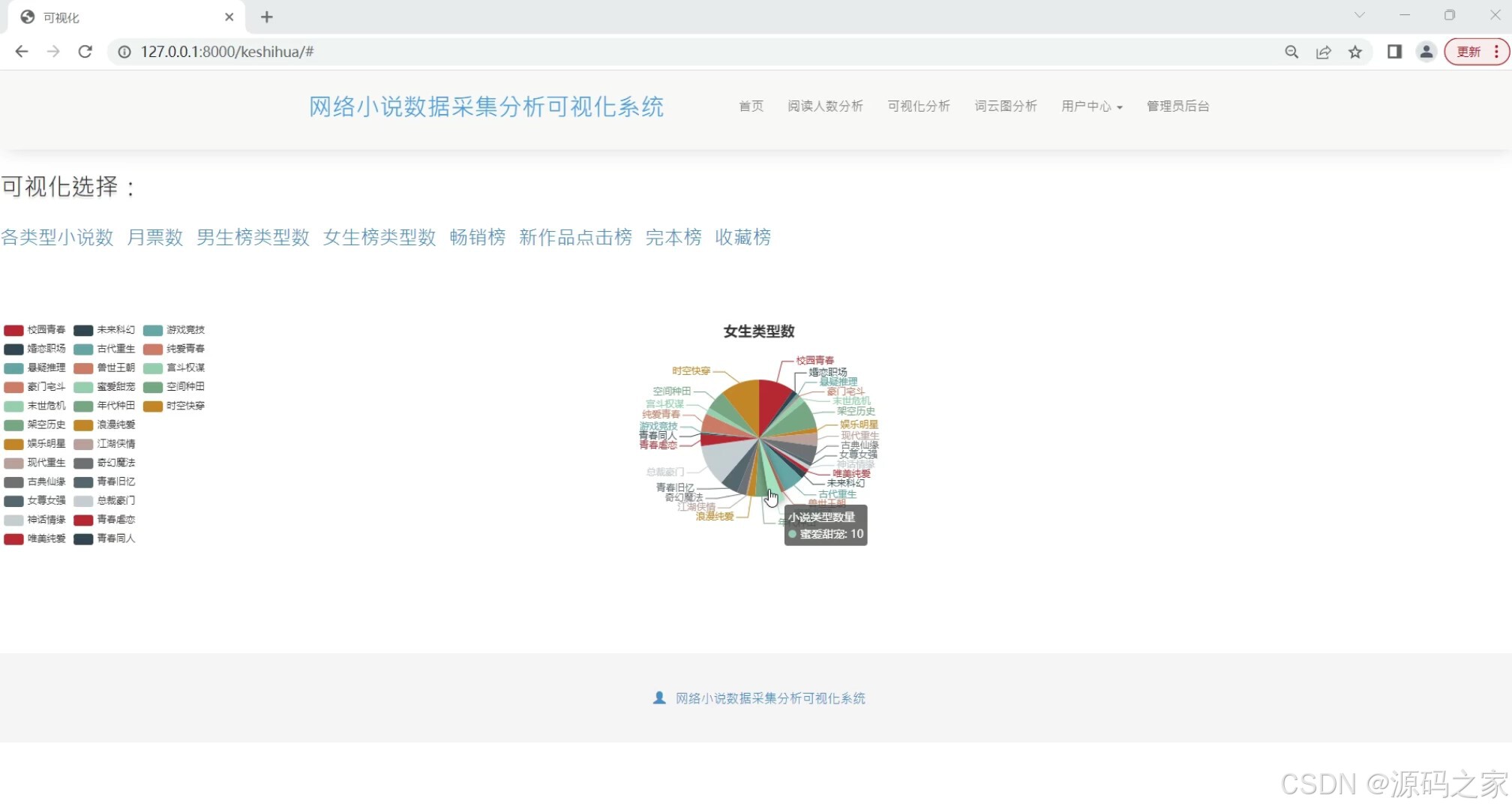
(1)各类型小说数据可视化分析
(2)月票房前20分析

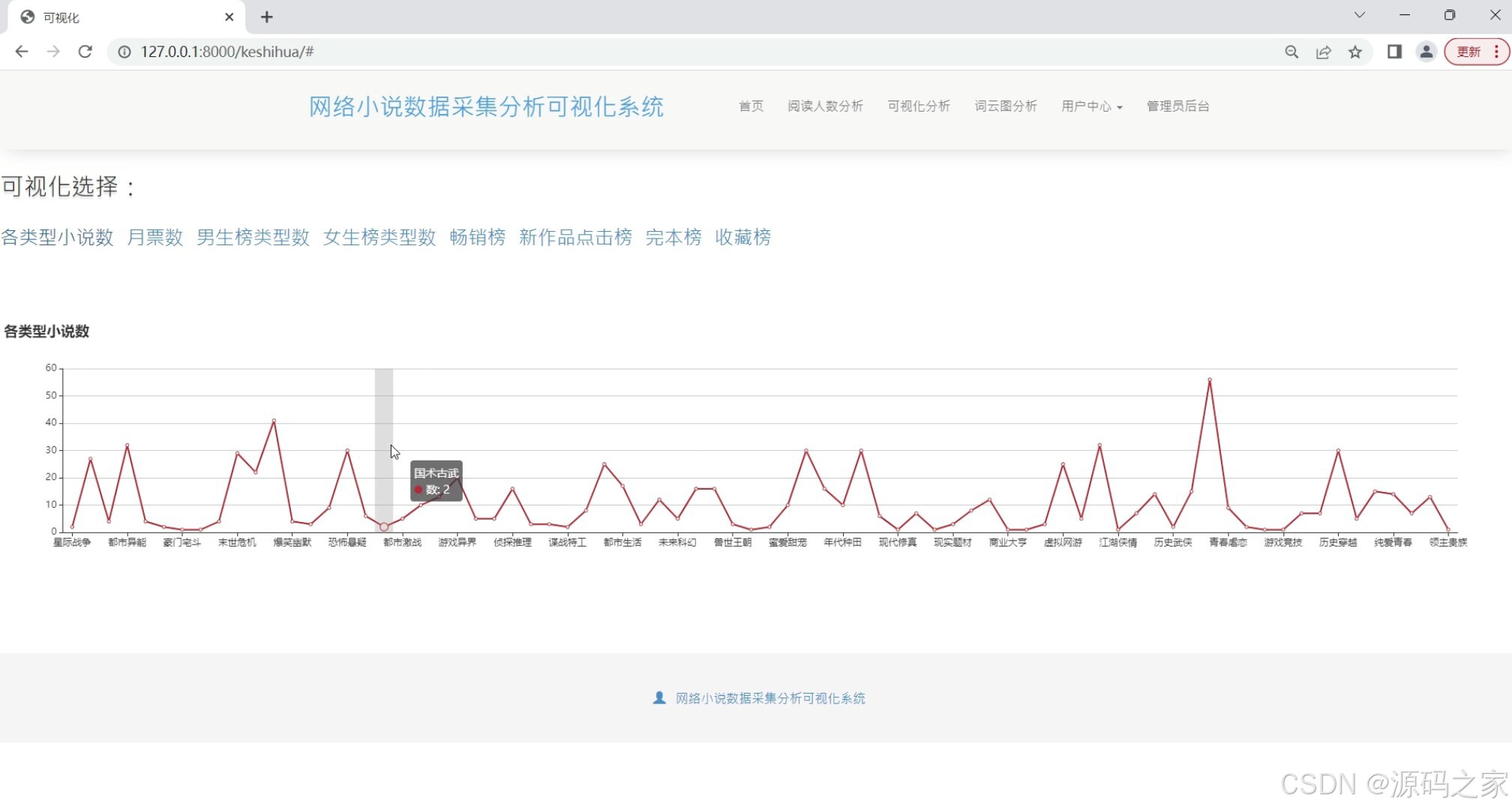
(3)各类型小说数量分析
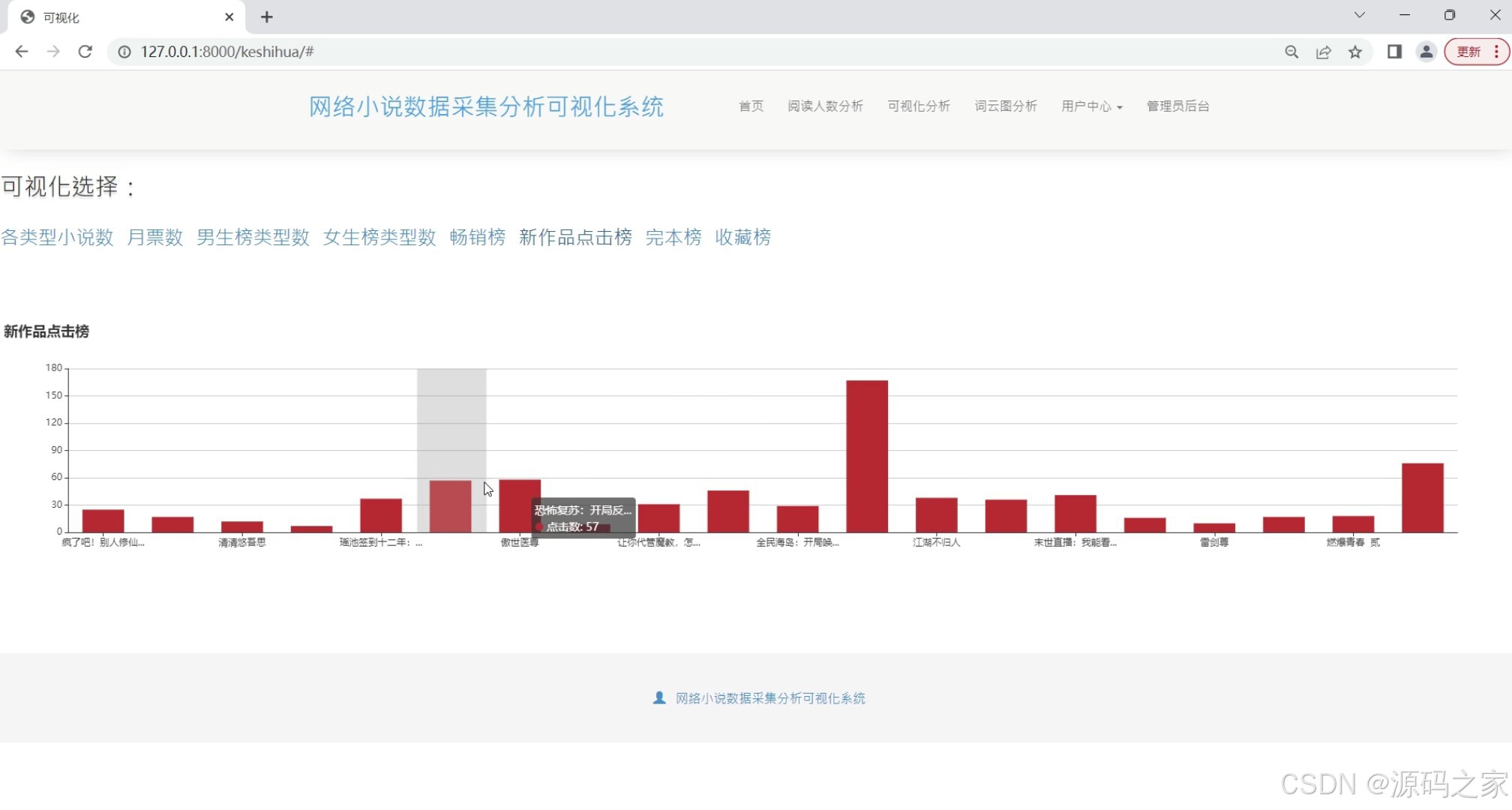
(4)新作品点击榜分析
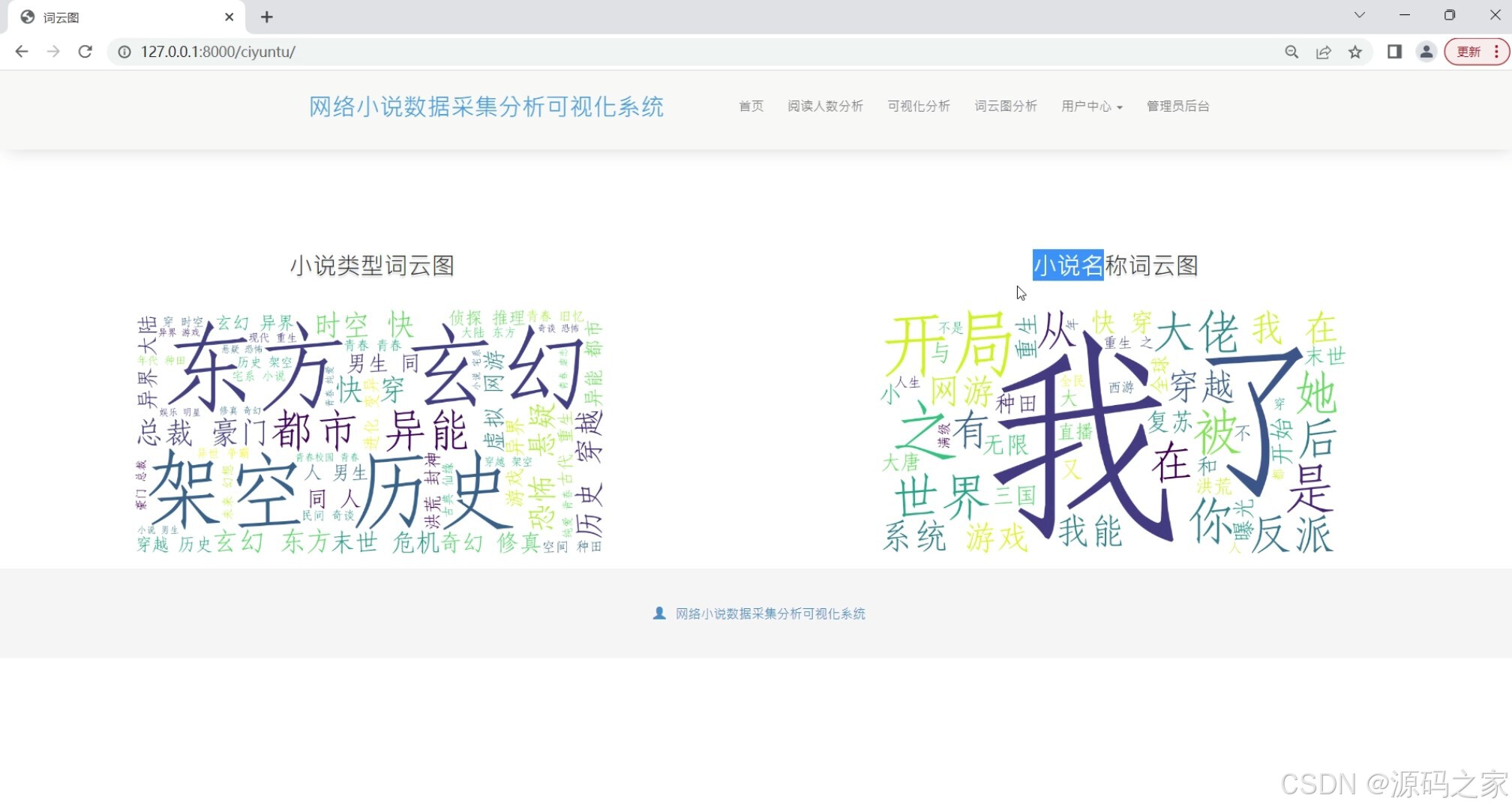
(5)词云图分析
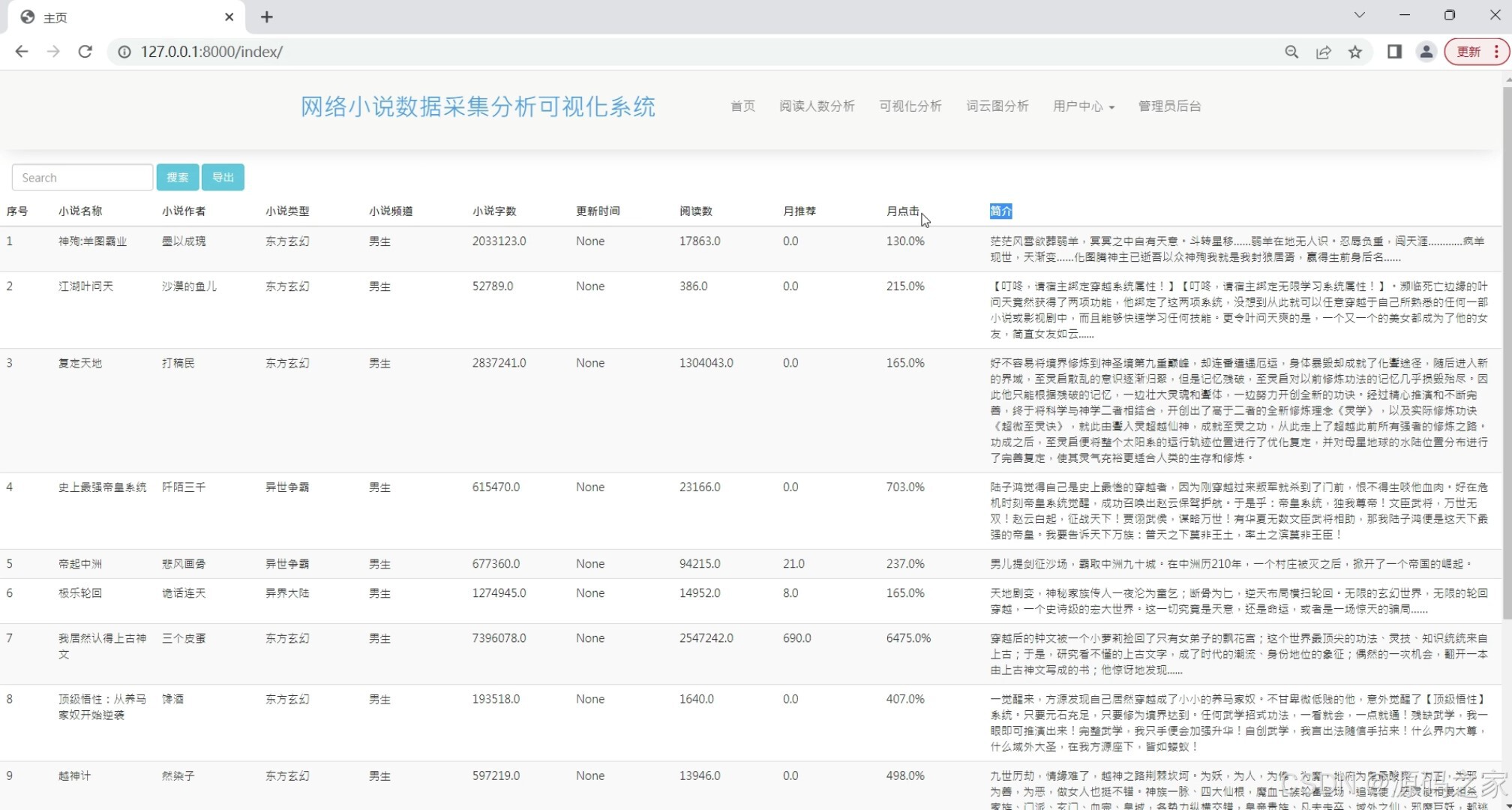
(6)小说数据列表
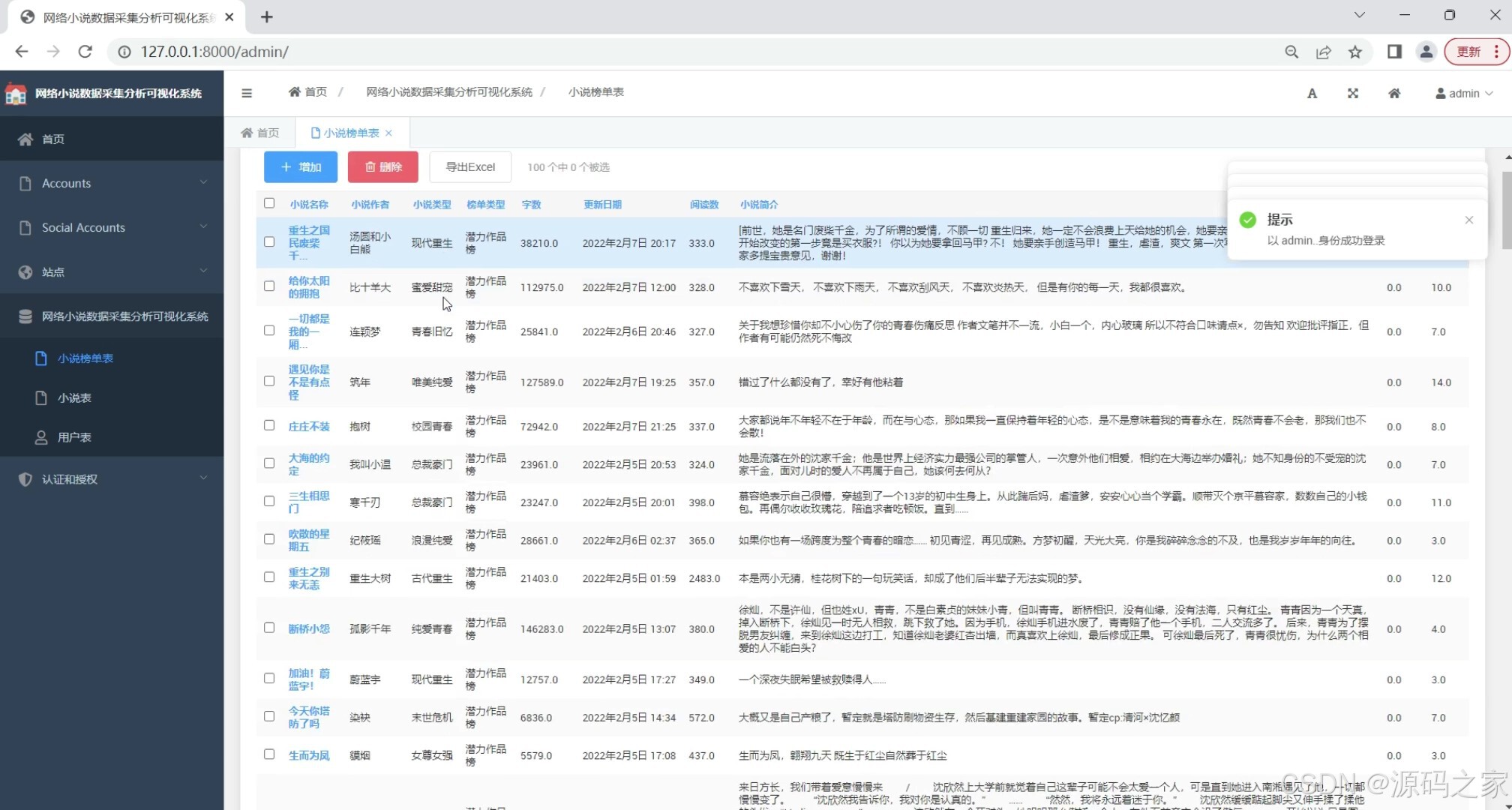
(7)后台数据管理
3、项目说明
本项目是一套基于Python与Django框架开发的小说数据分析可视化系统,核心目标是通过技术手段整合17k小说网的分散数据,以直观形式呈现小说市场关键信息,为用户与从业者提供数据参考。系统以requests爬虫技术为数据获取核心,搭配Echarts可视化工具与HTML前端界面,构建“数据采集-分析-展示-管理”的完整流程,同时依托Django框架保障系统稳定性与可扩展性。
在数据处理与展示层面,系统设计多个功能模块满足不同分析需求:“各类型小说数据可视化分析”模块通过图表呈现不同类型小说的阅读量、评分等核心指标,帮助用户快速判断各类型受欢迎程度;“各类型小说数量分析”模块统计不同类型小说的总量,揭示小说市场的类型分布趋势;“新作品点击榜分析”聚焦新发布小说,以排名形式展现其点击量表现,为评估新作品市场潜力提供依据;“词云图分析”则提取小说内容中的高频关键词,直观呈现热门小说的主题与内容特点,辅助用户把握创作趋势。此外,“小说数据列表”模块集中展示采集到的小说基础信息(名称、作者、类型、简介等),方便用户直接查询与筛选;“月票房前20分析”(虽与小说数据关联性需进一步确认,但仍作为功能模块保留)可辅助拓展数据观察维度。
在系统管理层面,“后台数据管理”模块为管理员提供数据维护功能,支持对采集的小说数据、用户数据、操作日志等进行增删改查,同时具备数据导出、清洗功能,确保数据准确性与可用性,为后续深度分析奠定基础。
整体而言,该系统通过技术整合打破了小说数据分散的壁垒,将复杂数据转化为易懂的可视化信息,既降低了用户获取小说市场洞察的门槛,也为小说行业的创作、推广决策提供数据支撑,实现了数据价值的有效释放。
4、核心代码
from django.shortcuts import render,HttpResponse,reverse,redirect
from django.contrib.auth.decorators import login_required
from guanli import models
from django.db.models import Q
from django.shortcuts import get_object_or_404,HttpResponseRedirect# Create your views here.@login_required
def index(request):if request.method == 'GET':Search = request.GET.get('Search')if Search:datas = models.XinXi.objects.filter(book_name__icontains=Search).order_by('-id')else:datas = models.XinXi.objects.all().order_by('-id')return render(request,r"apps\book_all.html",locals())@login_required
def user_profile(request):if request.method == 'GET':return render(request,'apps/user-profile.html',locals())elif request.method == 'POST':datas = models.Users.objects.get(username=request.user.username)error = {}data = request.POSTemail = data.get('email', '')if email != '' and '@' in str(email):email = emailelse:error['email'] = '邮箱格式错误'age = data.get('age', '')try:int(age)if age != '' and 0 < int(age) and int(age) < 120:age = ageelse:raise Exception('年龄错误')except:error['age'] = '年龄错误'set = data.get('set', '')if set != '' and str(set) in ['男', '女']:set = setelse:error['set'] = '性别格式错误'mob = data.get('mob')if error != {}:return render(request, 'app/user-profile.html', context={'data': datas, 'error': error})else:models.Users.objects.filter(username=request.user.username).update(email=email, age=age, set=set,mob=mob)user = request.userreturn redirect('web:user_profile')@login_required
def yuedurenshu_all(request):if request.method == 'GET':datas = models.XinXi.objects.all()list11 = [i.types for i in datas]types = list(set(list11))type_name = []type_count = []for resu in types:type_name.append(resu)da1 = models.XinXi.objects.filter(types=resu)count = 0for da2 in da1:count += da2.yuedutype_count.append(count)return render(request,r"apps\yuedurenshu.html",locals())@login_required
def keshihua(request):if request.method == 'GET':datas = models.XinXi.objects.all()list11 = [i.types for i in datas]types = list(set(list11))type_name = []type_count = []for resu in types:type_name.append(resu)type_count.append(list11.count(resu))#月票数yuepiaoshus = models.BangDan_xinxi.objects.filter(leixing='推荐票榜').order_by('-tuijian')yuepiaoshu_name = []yuepiaoshu_count = []for resu in yuepiaoshus[:20]:yuepiaoshu_name.append(resu.book_name)yuepiaoshu_count.append(resu.tuijian)#男生类型数list22 = [i.types for i in datas if i.sets == '男生']types12 = list(set(list22))nan_count = []for resu in types12:nan_count.append({"name":resu,"value":list22.count(resu)})#女生类型数list22 = [i.types for i in datas if i.sets == '女生']types12 = list(set(list22))nv_count = []for resu in types12:nv_count.append({"name":resu,"value":list22.count(resu)})#畅销榜changxiaos = models.BangDan_xinxi.objects.filter(leixing='畅销榜').order_by('-id')changxiao_name = []changxiao_count = []for resu in changxiaos:changxiao_name.append(resu.book_name)changxiao_count.append(resu.dianji)#新作品点击榜new_zuopings = models.BangDan_xinxi.objects.filter(leixing='新作品点击榜').order_by('-id')new_zuoping_name = []new_zuoping_count = []for resu in new_zuopings[:20]:new_zuoping_name.append(resu.book_name)new_zuoping_count.append(resu.dianji)#完本榜wangbens = models.BangDan_xinxi.objects.filter(leixing='完本榜').order_by('-id')wangben_name = []wangben_count = []for resu in wangbens[:20]:wangben_name.append(resu.book_name)wangben_count.append(resu.dianji)#收藏榜shouchangs = models.BangDan_xinxi.objects.filter(leixing='完本榜').order_by('-id')shouchang_name = []shouchang_count = []for resu in shouchangs[:20]:shouchang_name.append(resu.book_name)shouchang_count.append(resu.dianji)return render(request,r"apps\keshihua.html",locals())@login_required
def ciyuntu(request):if request.method == 'GET':return render(request,r"apps\ciyuntu.html",locals())def runoob(request):context = {}context['hello'] = 'Hello World!'return render(request, 'index.html', context)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻