RynnVLA-001:利用人类演示来改进机器人操作
25年9月来自阿里达摩研究院和湖畔研究院的论文“RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation”。
RynnVLA-001,是一个基于人类演示大规模视频生成预训练构建的视觉-语言-动作 (VLA) 模型。其提出一种两阶段预训练方法。第一阶段,以自我为中心的视频生成预训练,在 1200 万个以自我为中心的操作视频上训练一个图像-到-视频模型,以初始帧和语言指令为条件预测未来帧。第二阶段,以人为中心的轨迹-觉察建模,通过联合预测未来关键点轨迹来扩展此模型,从而有效地将视觉帧预测与动作预测连接起来。此外,为了增强动作表征,其提出 ActionVAE,这是一种变分自编码器,它将动作序列压缩为紧凑的潜嵌入,从而降低 VLA 输出空间的复杂度。当在相同的下游机器人数据集上进行微调时,RynnVLA-001 实现优于最先进基线的性能,这表明所提出的预训练策略为 VLA 模型提供更有效的初始化。
RynnVLA-001 的关键洞察在于,它将从以自我为中心的视频中人类演示中学习的操作技能隐迁移到机器人操作中。整体训练流程如图所示。
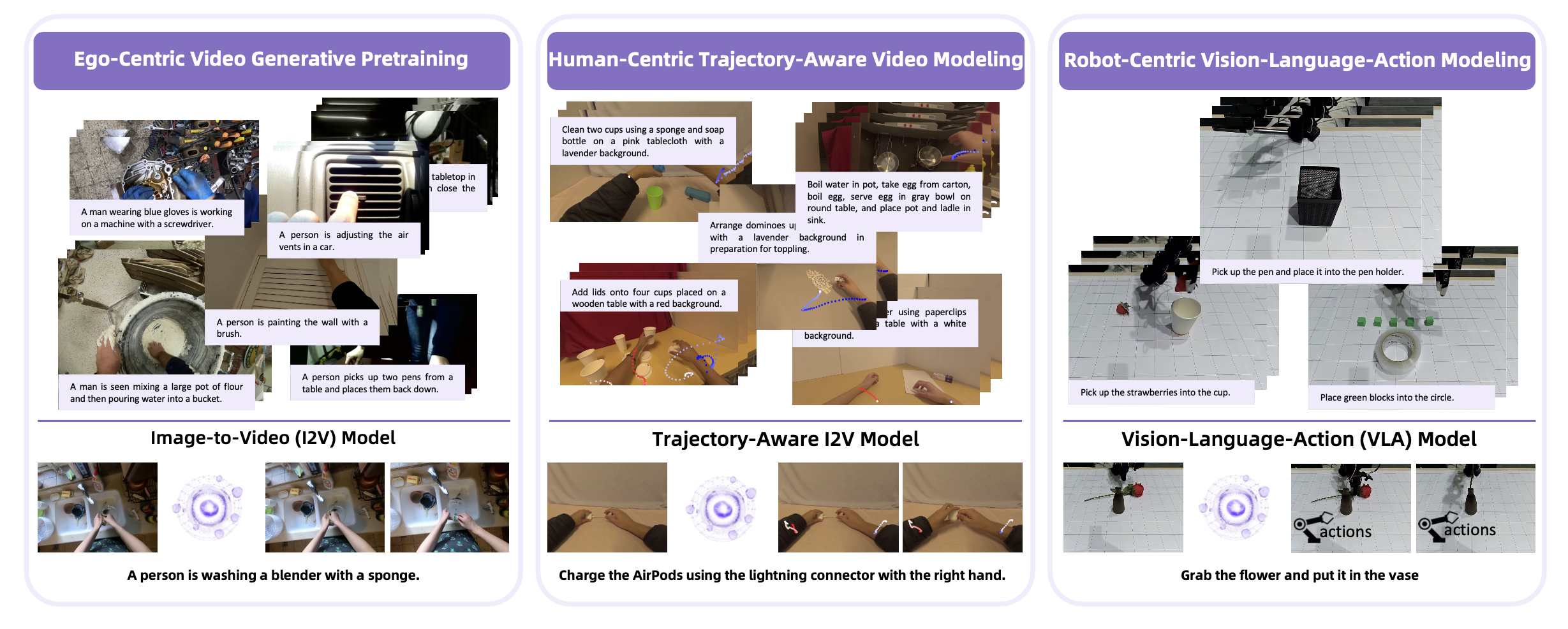
RynnVLA-001 是一个基于大规模视频生成预训练的视觉-语言-动作 (VLA) 模型。首先训练一个以自我为中心的图像-到-视频 (I2V) 模型,然后将其微调为一个具有轨迹-觉察能力的以自我为中心视频生成模型。最后,通过继承预训练的权重将模型调整为 VLA 模型。
该模型通过三个阶段逐步训练,如图所示:1)以自我为中心的视频生成预训练:使用以自我为中心的人体操作视频训练以自我为中心的图像-到-视频 (I2V) 模型。此阶段使模型能够预测未来帧。2)以人为中心的轨迹-觉察视频建模:对预训练的 I2V 模型进行进一步微调,使其能够联合预测未来的帧和人体关键点轨迹。此阶段弥合纯视觉帧预测和面向动作建模之间的差距。 3)以机器人为中心的视觉-语言-动作建模:VLA 模型继承前几个阶段的权重,并使用语言指令和当前观测值(包括双视图观测值和关节状态)作为输入,在机器人数据上进行训练。该模型经过优化,可以预测未来帧和动作嵌入,后者由预训练的 ActionVAE 解码为可执行的机器人动作。
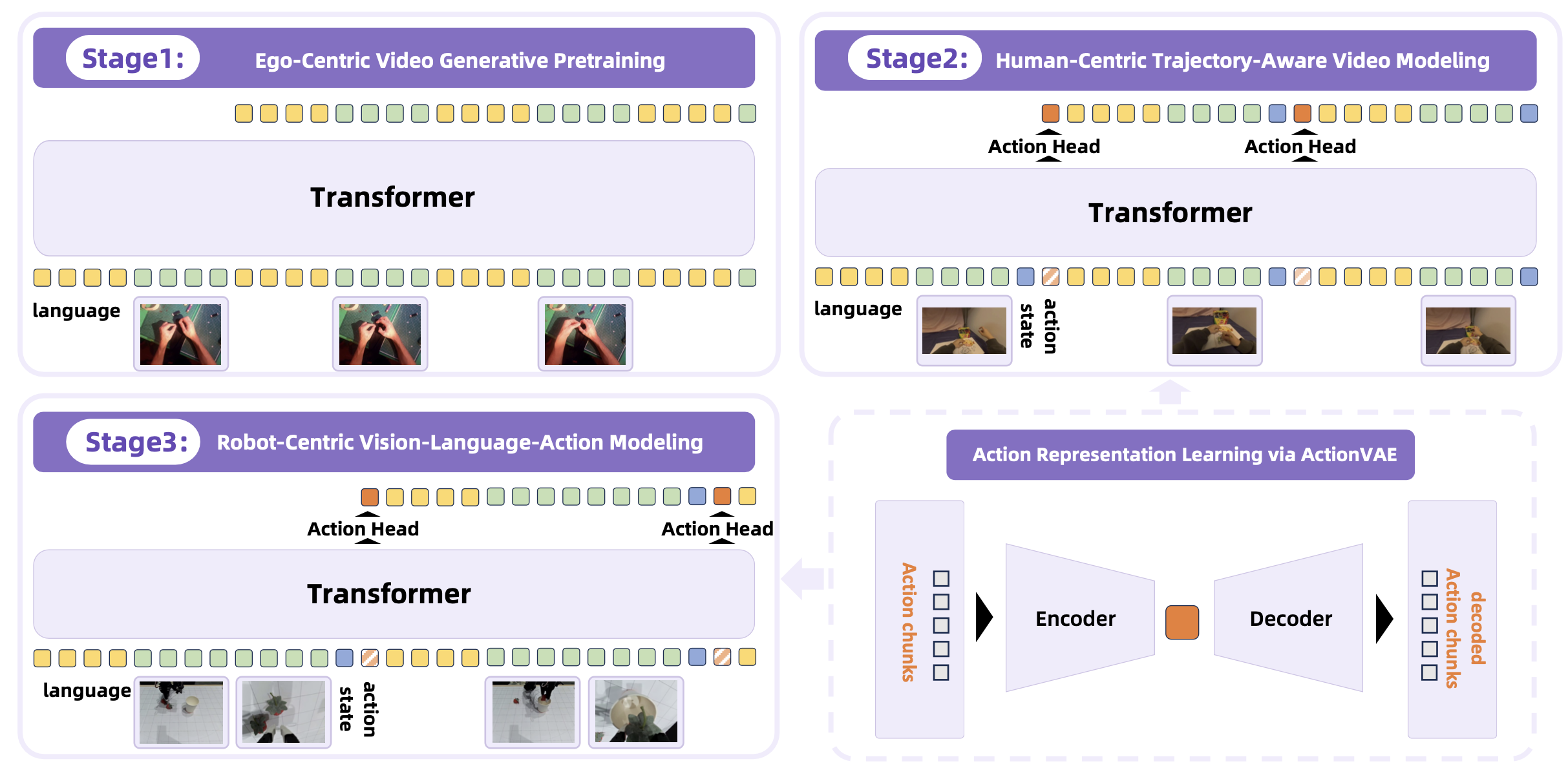
在 VLA 模型中,预测动作块(即短序列的动作)比预测单个逐步的动作更有效 (Zhao et al., 2023; Kim et al., 2025)。这种设计选择基于两个关键因素:1) 避免重复预测:单步动作执行通常只产生可忽略不计的视觉变化,这可能导致模型重复输出相同的动作并陷入停滞。预测动作块可以促进更显著的视觉变化。2) 效率:在单次前向传递中生成多个动作可以减少计算开销和推理延迟。
为了促进这种动作块级预测,同时确保生成的动作流畅连贯,在第 2 和第 3 阶段引入动作变分自编码器 (ActionVAE)。如上图所示,ActionVAE 由一个编码器和一个解码器组成,编码器将“动作块”压缩为紧凑且连续的潜嵌入,解码器从该嵌入重建原始动作序列。
由于训练流程涉及人类演示和机器人执行,并且它们的运动空间不同,因此训练两个特定领域的 ActionVAE:一个用于压缩人类轨迹(用于第 2 阶段),另一个用于压缩机器人动作(用于第 3 阶段)。这确保每个域都有定制的精确动作表示。重要的是,ActionVAE 是特定于具身的。由于它编码的块级动作通常对应于原子运动基元,因此可以直接使用训练有素的模型从同一具身的新数据中提取动作嵌入,而无需重新训练。
在最后阶段,将预训练的轨迹感知模型调整为用于机器人控制的 VLA 模型。这是通过集成特定机器人的 ActionVAE 表示并基于以机器人为中心的数据对模型进行微调来实现的。该模型的主要目标是预测下一个机器人动作块的嵌入,然后由 ActionVAE 将其解码为可执行的动作序列。
在训练过程中,模型会同时优化两个目标:1)机器人动作预测:将与 <ACTION_PLACEHOLDER> token 输出对应的隐状态输入到新初始化的动作头中。该动作头将隐状态回归为表示下一个机器人动作块的连续嵌入。该动作头的训练由机器人专用 ActionVAE 的预测嵌入与真实嵌入之间的 L1 损失函数监督。2)未来视觉预测:模型继续对下一帧的视觉 tokens 进行自回归预测,并由交叉熵损失函数监督。这项辅助任务可以规范训练,并保持模型对世界动态的理解。
至关重要的是,为了优化效率,在推理阶段进行修改。该模型仅预测动作嵌入,并舍弃未来视觉 token 的生成。虽然预测未来帧在训练过程中可以作为正则化的一项有价值的辅助任务,但它计算成本高昂,且对于控制而言并非必要。舍弃此过程可显著提升推理速度,使模型更适用于实时应用。
预测的动作嵌入会立即传递给 ActionVAE 的解码器。解码器会根据这单个嵌入重建一个连贯的低级机器人动作序列(或动作块)。机器人会执行整个动作块。完成后,会捕获新的观察结果,并将其与语言指令一起反馈到模型中,从而启动下一个循环。此过程重复进行,直到任务成功完成。
为了基于相关的人体操作演示对模型进行预训练,构建一个大规模的以自我为中心操作视频数据集,这些视频来自网络资源(Wang,2024b;Grauman,2022;Miech,2019;Damen,2022、2018、2021;Goyal,2017;Mahdisoltani,2018)。由于原始视频数据噪声较大且高度多样化,设计一个多阶段数据整理流程,用于筛选和注释适合预训练阶段的视频。该流程包含以下步骤:
关键点检测。对于视频中的每一帧,应用姿势估计模型(Yang,2023)提取人体关键点,包括面部关键点、躯干关节以及手部相关关键点(例如手腕、肘部、手指)。
以自我为中心的滤波。应用两个关键滤波标准,只保留高质量的以自我为中心操作视频:1)无面部关键点:包含面部关键点的视频将被丢弃。人脸的出现强烈暗示第三人称视角,这不适合以自我为中心建模。2)手部关键点的存在:只保留与手腕和手部对应的关键点可见帧。摄像头附近手部的存在是人类以自我为中心操作的有力指标,这对于建模可迁移的机器人行为至关重要。
文本描述标注。对于每个精选视频,用 Qwen2-VL-7B(Wang et al., 2024a)生成简洁的文本描述。这些描述特意保持简短,以模仿机器人学习中常用的自然语言指令(例如,“把瓶子放进盒子里”、“打开抽屉”)。由此产生的文本-视频对可作为视觉-动作对齐的有效监督信号。
实验设置
数据集。为了训练和评估 RynnVLA-001 模型,用 LeRobot SO100 机械臂 (Cadene et al., 2024) 收集一个真实世界操作数据集。该数据集包含通过人类远程操作收集的专家演示。为了确保数据集涵盖基本的操作技能,设计并收集三个代表性任务的数据,如图所示:1) 拾取和放置绿色积木:此任务侧重于基本的物体识别和抓取能力。一共收集 248 个演示。2) 拾取和放置草莓:此任务需要精确的定位和抓取点估计,重点关注模型的细粒度感知能力。一共收集 249 个演示。3) 拿起笔并将其放入笔筒:此任务需要高级的 3D 空间推理能力,特别是推断物体方向和高度以进行精确插入动作的能力。一共收集 301 个演示。为了增强数据的丰富性和复杂性,操作场景的设置从仅包含目标物体到包含其他无关干扰物体的更复杂排列不等。在遥操作过程中,人类操作员的目标是将所有目标物体移动到其目的地。此外,数据是使用三个不同的 SO100 臂在不同光照条件下的各种环境中收集的。

基线。模型与两个强大的开源基线进行比较,即 GR00T N1.5(Bjorck,2025a)和 Pi 0(Black,2024)。使用相应的预训练权重初始化这些模型,然后使用与模型相同的 SO100 数据对模型进行微调。用 GR00T N1.5 和 Pi0 的官方代码,并严格按照说明对模型进行微调。