第十二届全国社会媒体处理大会笔记
会议主题:大模型时代的AI+
会议时间:2024.10.12-13
会议地点:河南新乡
核心表达内容:大模型时代:AI+智能算网与未来融合
2024年10月12日上午
开场白
唐杰 中国中文信息学会社会媒体处理专业委员会主任
发展趋势:多模态
智能三脑与智能算网
蒋昌俊 中国工程院院士 同济大学讲席教授
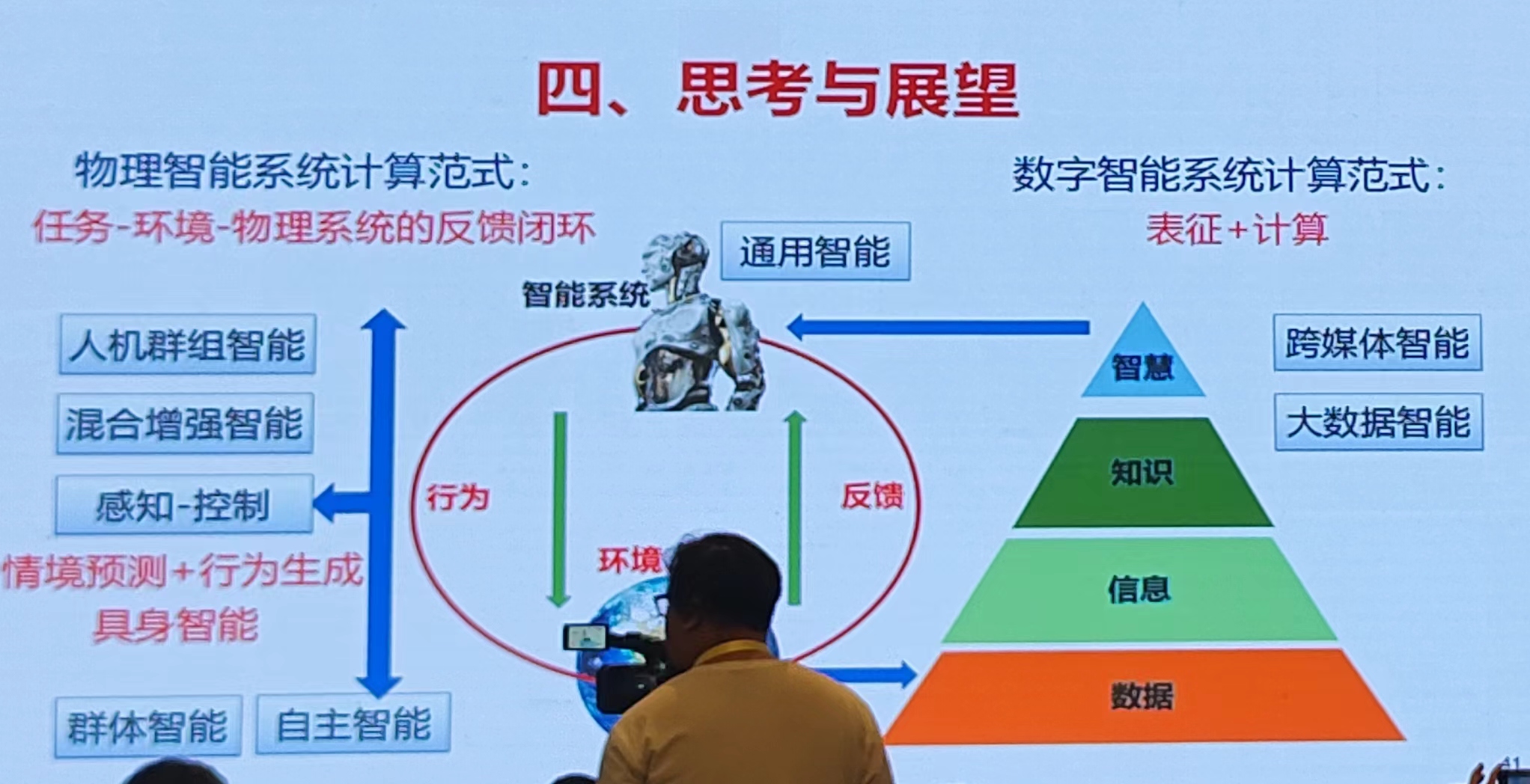
一、智能三脑:
1)电脑智能
- 基础知识:电脑(逻辑推理、形式化表示、符号操作)
- 应用:专家系统(例如医疗诊断、金融分析)、定理证明、智能控制(智能家居、自动化控制与优化)
- 缺点:处理复杂、非线性问题能力有限;需要大量专业知识与经验
2)数脑智能
- 基础知识:统计学习、深度学习、强化学习
- 应用:智能推荐(根据用户历史行为与偏好为用户推荐个性化内容与服务)、自动驾驶(利用深度学习计算对道路环境进行感知与理解,自动导航与无人驾驶)、交易风控(利用人工智能与大数据技术对交易行为进行分析与预测)
- 挑战与机遇:数据质量与标注问题(高度依赖数据的质量与标注的准确性);模型可解释性问题(深度模型复杂且难以解释)、隐私和安全问题;跨领域应用与迁移学习。
3)人脑智能
- 基础知识:人脑神经元、M-P神经元模型【简单带过】
- 特点:依靠经验模仿教育、计算速度相对较慢、低能耗、天然并行处理、高度灵活
对比了三种智能的异同点【我们现在的研究阶段处于第二阶段;数脑计算】
相同点:都能处理和分析信息、具备一定的学习和适应能力、为特定的目标进行优化和执行任务
人脑:生物智能——经验、模仿、教育
电脑:逻辑计算机智能——编程、算法
数脑:数据驱动大模型智能——大数据、机器学习
智能的融合与发展
逻辑与数据在人工智能中的结合:数据驱动的逻辑推理、逻辑指导的数据挖掘、逻辑与数据的相互验证
未来智能系统的发展:智能水平化持续提升、多模态交互能力增强、自主学习与进化能力的拓展、情感智能的发展

二、算网
国家战略背景:东数西算(2022年2月17日正式全面启动项目)
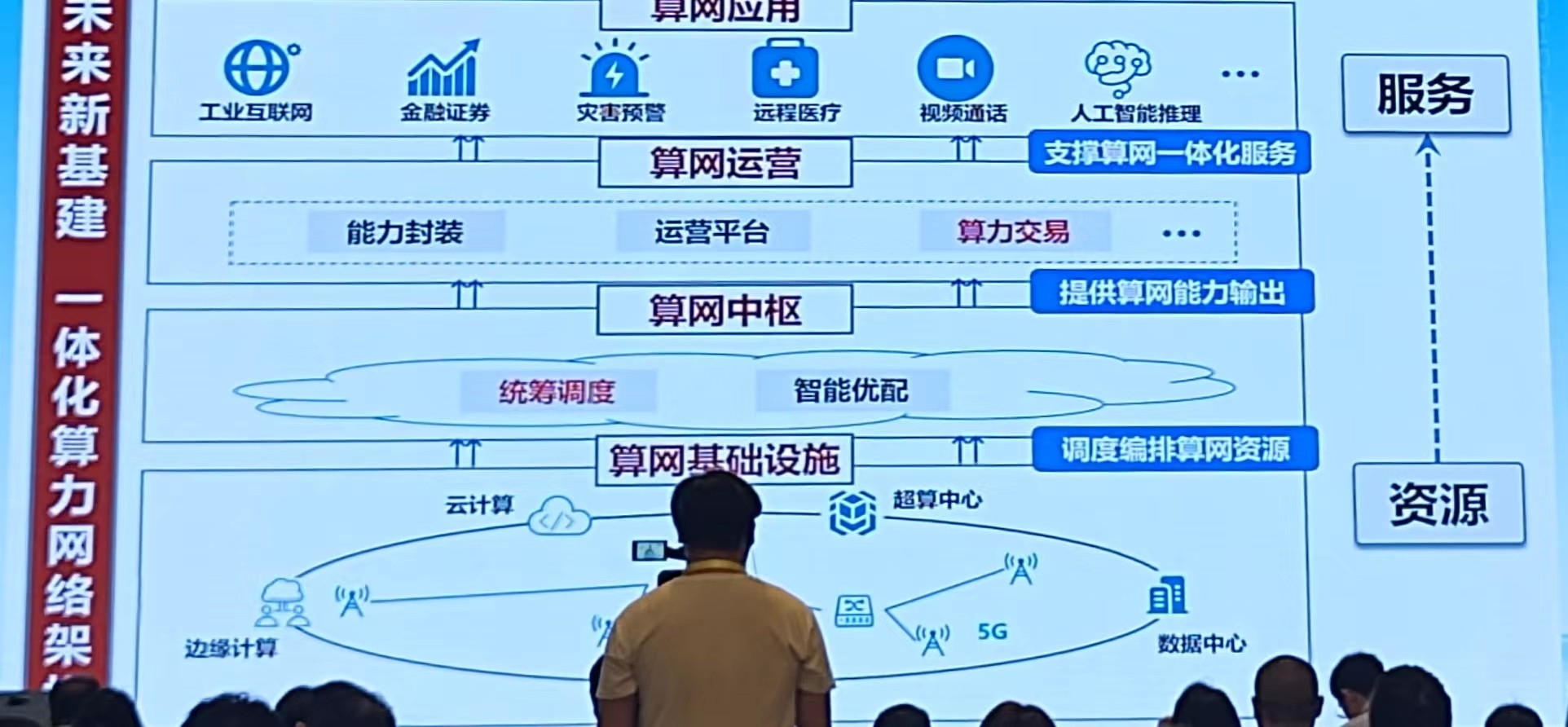
算力资源及需求分布情况特点:分布不均、运行低效、急需优配
国家一体化算网建设:资源优配——支撑算网一体化服务、提供算网能力输出、调度编排算网资源
建议:算力交易、算力优配、算力调度【功能相辅相成】
上海做国家级算力调度中心——原因:海量数据催生算力交易平台形成、金融中心完善算力交易平台建设、先进技术赋能算力交易平台构建
研究内容架构:两中心一体系
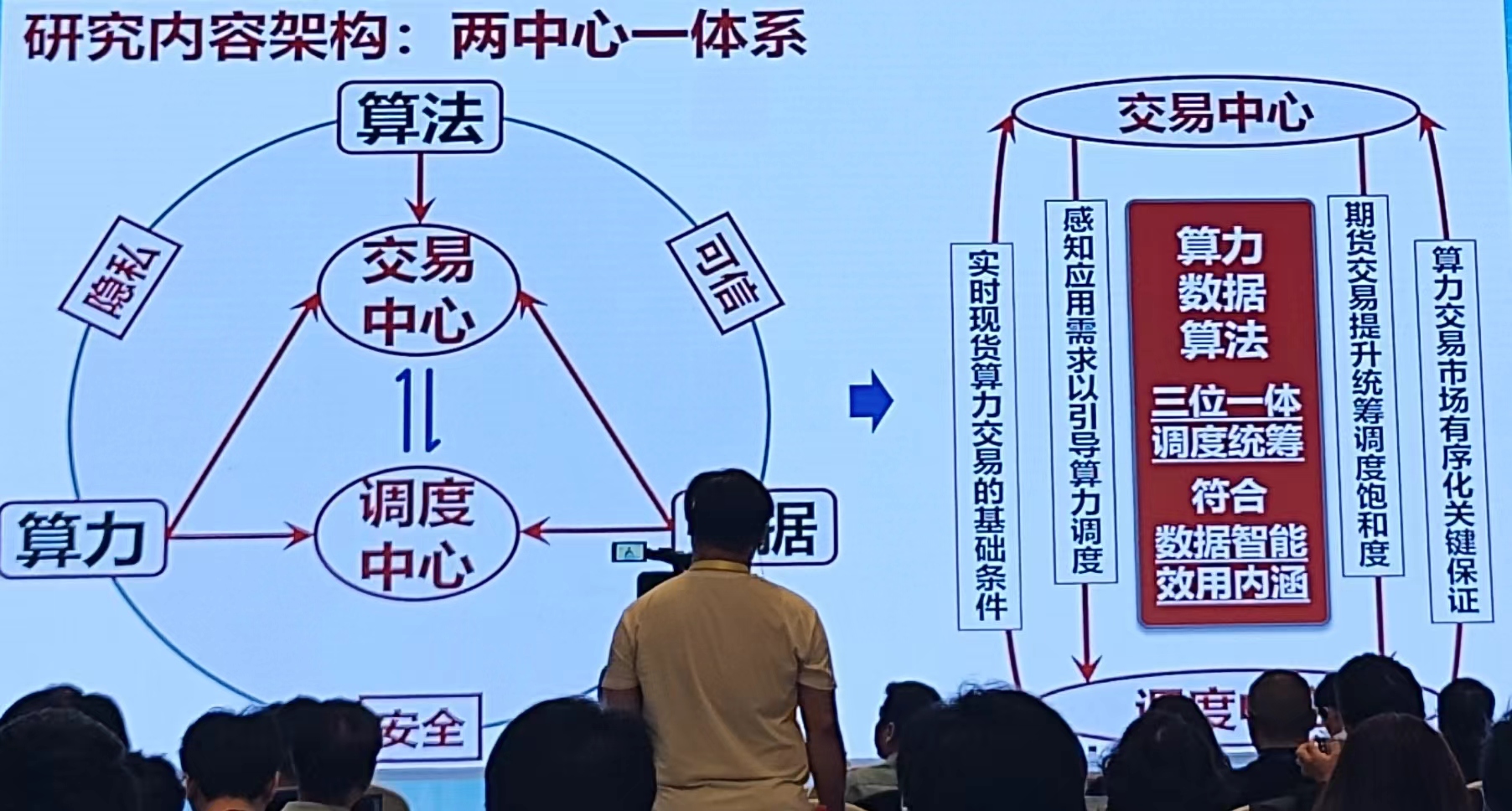
方舱计算——开发了算力网页【同济算网运营中心】智能算网、协同同济(优势:具有伸缩、机动、业务相关、数据相关、资源相关的性质)【研究要快,算力没出来多久,现在算力网就一堆了】
技术框架如下:
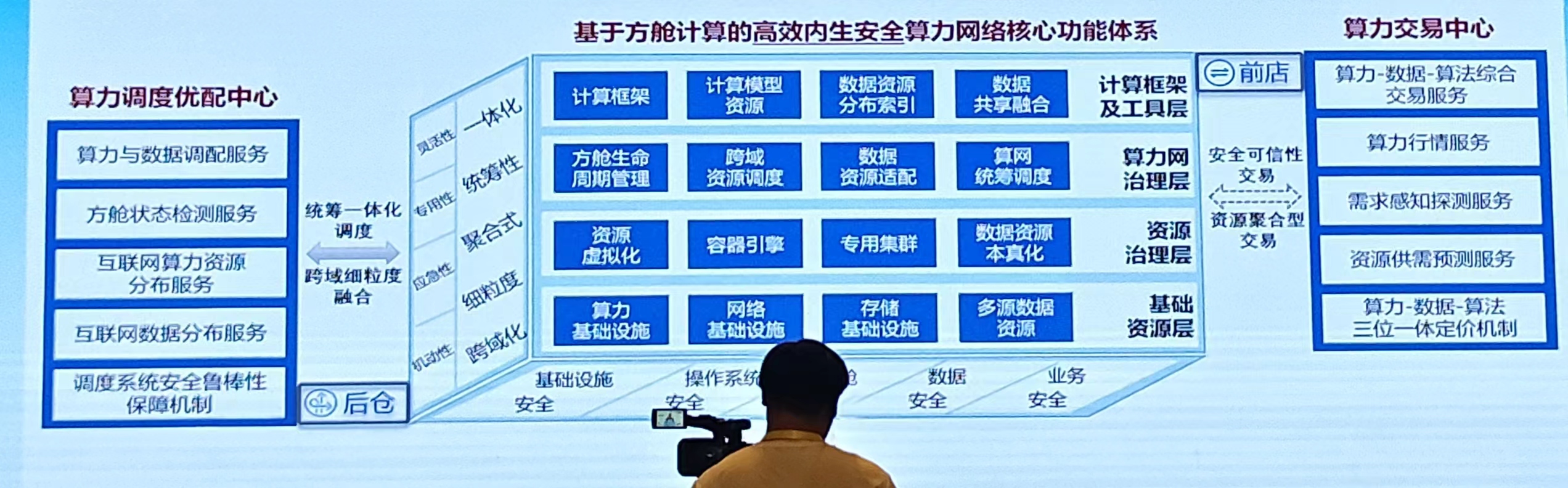
算力网络安全体系:数据-模型-系统 三层保障一体化
市场分析:
- 市场前景:2025年我国算力网络市场规模将有望超过900亿元,在2022-2025年期间,年平均增长率达到14.3%。到2030年,通用算力将增长10倍、人工智能算力将增长500倍,云服务占企业应用古出比例将达至到到87%
- 市场特征:算网建设的重点将逐步从“基建转向“调度”,赋能算力像水电一样随取随用,使计算基础设施升级为算力资源服务
集合了四个计算中心:贵阳华为云智算中心、上海嘉定算力中心、广州天翼云边境集群、北京阿里云集群
评价指标:吞吐量、CUP利用率
核心技术:算力网络服务质量、成本效率得到显著优化,通过CNAS(上海计算机软件开发中心)第三方检测机构验证——算力资源协同调度、复杂业务环境机动生成、多方数据原位汇聚计算、应急业务需求快速解析
基于方舱计算的智能算网系统总结:实验室起步、品牌推广和影响最大化、持续优化智能算网系统建设,引领未来算网系统平台体系架构
搜索到的一篇介绍:蒋昌俊院士:智能算网一一数字经济时代的新动能 - 榆林市工业信息化推广应用中心
这个网是宏观的?没有找到具体的网站链接
社会建设与AI发展
冯仕政 中国人民大学教授
人工智能的底层逻辑还是社会计算:人工智能——社会计算——数字化——技术逻辑与社会逻辑
主要内容:数字化的过程与环节、数字化与社会本体、数字化张力与社会
一、数字化社会研究
- 技术视角:物的关系
- 社会视角:人的关系
- 效应分析多,构造分析少
- 核心是厘清数字化
介绍的内容比较偏理论
引入案例:文化震惊——Universal Service 中国街道、地方命名混乱多变、核酸采样地方混乱、停车场。。。【从现象找问题】
何为数字化:用一组可运算的参数去描述和推断自然事象和社会事象的过程
- 概念化:把无限绵延的世界切分为有明确边界的范畴、构造变量——本质上是思维解析过程
- 计算化:把不相连属的范畴关联起来形成可推演的逻辑、构造函数——经过一个函数的有限次迭代,能够得到确定且有限的解(包含:组织化、数字化、自动化、简约化)
概念化的过程:拟题(问题的抟(tuan)聚【不认识字SOS】:什么是问题)、分类(问题的定性:是什么问题)、赋格(问题的量化:问题是什么)、志名(问题的标签:问题叫什么)【举例:吃茶歇喊不进来,吃喝比听报告重要~O(∩_∩)O】——>中国文化博大精深
总结:技术性——社会性——历史性
每人每天都在想象和构造自己,数字越来越成为想象和构造自己的中介或素材:例如跑步数字化记录(不同软件的计数结果不一样)——从运动到感动(在这个一切数字化的时代,未被计量的人生,等于不存在;被错误计量的人生,简直是虚度)
社会锁闭
- 技术主义: 一切化约为技术问题甚至计算问题
- 纯净主义:流动性/模糊性 vs. 确定性/精确性
- 互联主义:遗忘权:区块链
- 反身性风险:数字秩序与社会秩序
由于时间问题,第二个部分过得很快,内容偏文科的思路对关系的思考
人在回路混合增强智能的技术路径探索与实践
薛建儒 西安交通大学教授
一、以人类智能为基准度量智能系统
背景:数字只能系统在众多类别智能任务重已超过人类、物理智能系统的行为智能水平远低于预期(例如: 无人驾驶)
莫拉维克悖(bei)论:知易行难 计算智能——> 行为智能
- 大脑产生行为的机遇:受任务牵引,在经验及知识的支持下时间自适应与认知到的外界的行为
- 物理智能系统自主行为生成:在开放、动态环境呈现出以完成任务为目标的自主行为
- 以任务为导向的行为生成:从自动到自主
- 适应任务、环境的自主行为生成——从经历中学习:任务定义奖励,世界模型支撑情景预测,策略生成行为(强化学习)
策略模型:状态-动作的映射函数:无人车——无人机——无人船——服务机器人(控制动作的自由度的数量越来越多);基础模型赋能路径:语言模型、视觉-语言、多模态
自主行为生成的一体化模型:端到端模型(用神经网络整合多个子任务如预测-规划、感知-控制全栈任务)
自主行为生成的基础知识体系:在筹备出教材,年底出版——书名:《自主智能运动系统》
人机混合增强智能:将人的作用或认知模型引入物理智能系统,通过人类智能与机器智能深度融合,构建更高智能水平的物理智能形态

二、人在回路的混合增强智能
人在回路:建立人机交互通道,使人参与更高水平的智能构建
用协同行为度量人在回路混合智能系统的效能
- 协同行为:引入外部信息或额外约束自主行为,即自主行为生成式需额外考虑经交互通道输入的人的作用信息或引起的约束条件变化
- 协同行为生成的路径:共享自治、拟人化交互(建立拟人化交互范式,突破人机交互屏障)、交互学习
协同行为生成的路径:共享自治、拟人化交互
方式:1)用人在回路优化提升交互效能;2)将人的作用由控制提升至任务-运动的联合规划
典型应用场景:智能座舱/指控中心、面向飞行**任务拟人化脑机交互
人机认知负荷分配:评估人的意图与认知状态:拟人化交互的核心是在人机件合理分配认知负荷
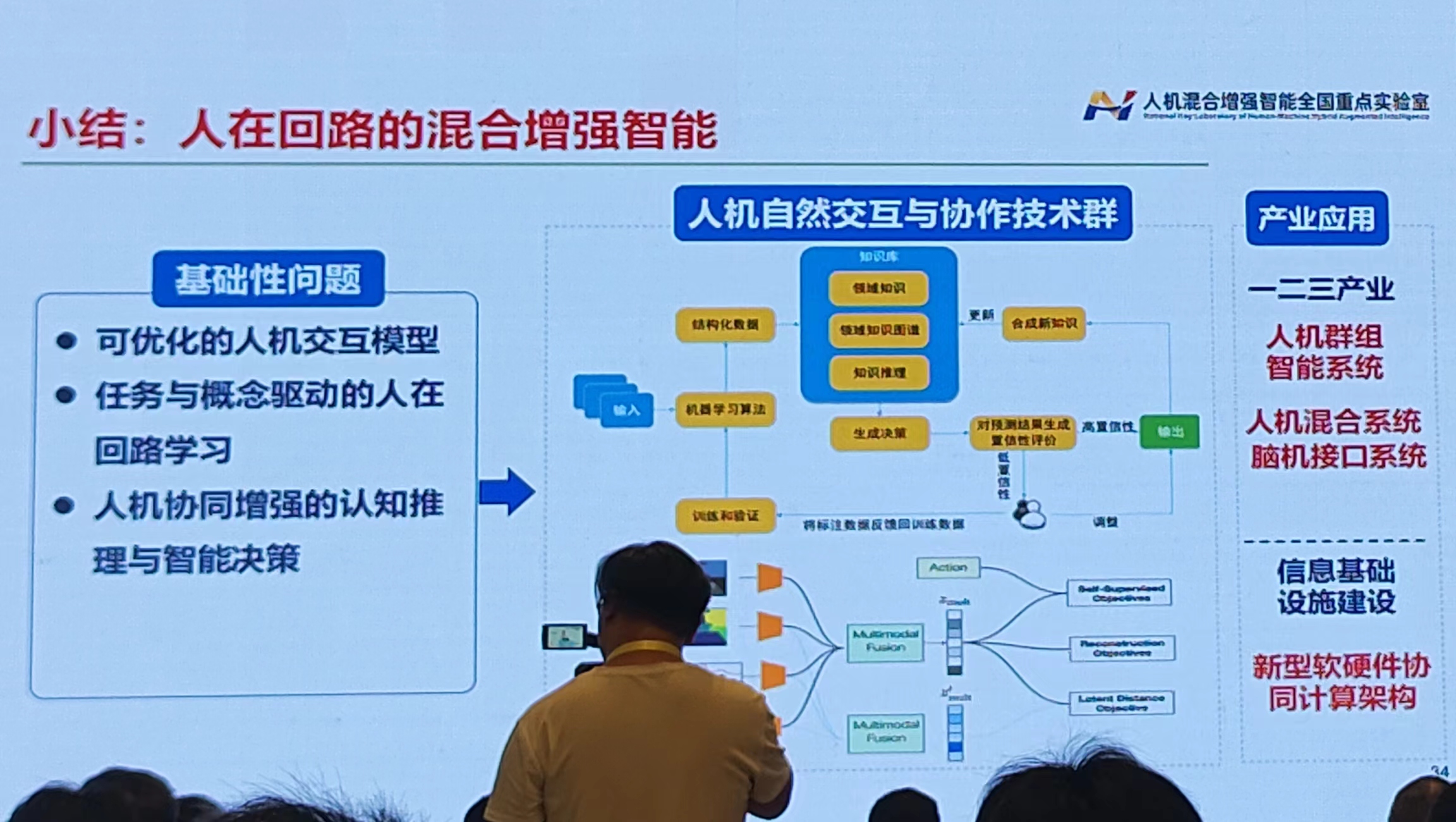
三、嵌入认知计算名的混合增强智能【这个部分过得很快】
交通情景认知计算模型——行为轨迹预测
交通风险管控
提问环节:
问题:把人的认知输送到机器?——回答:把人的作用引入到机器(没有直接地回答,害)
2024年10月12日下午
开始去的是智慧教育的,但是没有位置坐,而且一直在介绍图对抗学习相关的内容——所以俺就走了
分论坛:基础模型构架【茉莉厅】
RWKV:Next-Gen Model Aechitecture
候皓文 广东人工智能与数字经济实验室(深圳)副研究员
迭代的框架:S4、Mamba、RetNet、Mamba-2、RWKV-5.1、RWKV-5.2、RWKV-6
RWKV和Transformer的本质差异:更深刻的问题在AGI背后的记忆机制,到底应该是什么样的?
- Transformer = Addressing Memory寻址记忆(人的记忆是有限的,和这个不一样)
- RWKV= Associative Memory 联想记忆(2024年诺贝尔物理学奖)——举例:St = K0v0+...+ktvt(0+9)
评估测试
- 语言模型基准测试【多语言】
- MMLU测试(一个大模型)
- 关联记忆评测:多查询关联记忆(MQAR)——关联记忆(AR)是一项设计来模拟人类如何建立联系并提取信息的合成任务。随着任务中序列长度的延长,其难度也随之上升
- TULER测试:包含增强的大海捞针(NAH)测试,分为四个子任务,评估模型的检索能力
- LongBench测试:LongBanch 是一个针对大语言模型长文本理解能力的评测标准
- 对比Mamba2和Flash Attention
- 多模态实验结果(VisualRWKV视觉语言模型)
评估:内存消耗低、计算速度快
Transformer和Mamba紧箍咒:TC0约束——提出RWKV-7超越了TC0约束
- TC0复杂度是计算复杂度的一个类别,指的是可以通过一个固定深度的电路解决的计算问题
- Transformer和状态空间模型,无法解决本质上需要顺序处理的问题
总结:
- RWKV是新型的RNN,降低了计算的复杂度
- 能够捕捉局部性和长程依赖关系,效果超越传统的RNN(包括LSTM、GRU)
- 能够像Transformer一样并行训练,使得RWKV具有更佳的可扩展性
- 能够像RNN一样推理,让RWKV大语言模型可以运行在平民化的硬件设备上,让AGI真正走进千家万户
RWKV项目主页:https://rwkv.cn
Discord:https://discord.gg/bDSBUMeFpc
沟通群QQ号:325154699
RWKV: Receptance Weighted Key Value

基础大模型下来提升新颖方案
韩旭 清华大学
背景:从BERT 到 GPT4,大模型参数增长1.6万倍,数据增长5万倍。大模型能力增长的同时带来了严重的效率问题。
效率提升方案:小尺寸、高稀疏、存算平衡(芯片导致的问题,访存带宽)、长序列处理
一、小尺寸
增强模型知识密集度:
- 随着数据-算力-算法协同发展,模型知识密集度持续增强
- 终端算力和模型知识密集度持续增强,两条曲线交汇呈现端侧大模型的巨大潜力(配了一个图,没看懂)
方式:
- 搜索参数性价比高的训练配置:利用小模型找到下降到目标损失函数值的最快配置,可以显著提升收敛速度
- 制作学习性价比高的训练数据:微软研究工作表明高质量数据可以极大改变扩展曲线的形状
实验验证表明:大模型的知识密度平均八个月提升一倍
二、高稀疏
1)利用模型稀疏特性:大模型的前馈网络(FFN)中普遍存在激活层,存在显著的稀疏激活特性;稀疏激活的现象对于多种不同的激活函数(如ReLU、SiLU)而言均存在;丢弃LLaMA前馈网络中70%输出较小的神经元,对下游任务表现的影响很小
2)推理层面的稀疏优化:将前馈网络转换为相同参数两的MoE结构(转换后仅需20%的计算量可达到转化前98%的性能)
3)训练层面的稀疏优化:Switchable Sparse-Dense Learning(SSD)——使用稀疏结构降低计算代价、使用稠密结构强化模型学习能力、实现性能无损的训练加速
4)大模型内部的稀疏特性:
- 控制没层FFN截去未激活神经元后的输出误差(CETT)相同,给定CETT后没层自适应地确定阈值;
- 相比于传统基于阈值或保留固定神经元比例的方法(top-k),ppl-p%可以在性能和稀疏度之间达到最优的平衡
- 不同的激活函数,其激活度随训练数据的增长,呈现完全相反的趋势(ReLU激活单调递减,SiLU激活单调递增,ReLU比SiLU更为性能优秀)
- ReLU函数存在稀疏激活,但当前主流大模型均采用Swish函数激活; ReLUfication——将大模型中非ReLU的激活函数置换为ReLU函数(置换后神经元激活比例约为30%,计算量显著下降,性能相当)
- 模型的深宽比对模型也有影响:宽深比应落在一个令基线损失褒词最低水平的最优区间内,即理想的模型宽深应取为最优区间的左端点(给了一个实验的图)
- 参数量的影响:同宽深比下,模型的极限激活度与参数量的相关度较低,小模型稀疏度收敛更快。模型的稀疏激活分布对于参数量是不敏感的,增大参数量不能本质提高稀疏度。
- 不同规模模型之间几乎没有显著差距:可能原因:神经元的分工和模块化也是对模型参数量不敏感的【如果实验室设备可以跑小参数的大模型,那么是不是可以使用其来完成相关工作】
5)算子和调度层面的稀疏优化:
- Megablocks:将MoE计算转化为稀疏矩阵乘,1.3~1,4倍的推理加速
- PowerInfer-1:还有很多时间消耗放在存储的过程中——资源稀缺的情况下:只将hot neuron交GPU计算,其余用CPU计算;通过在线的Predictor提前阈值激活分布,跳过为激活神经元参与的计算。
- PowerInfer-2:采用NPU进行编码,采用CPU进行反量化和解码。(以手机拍照美颜举例)——支持在手机上进行47B模型的推理
- 通过实验验证发现:CPU环境相爱,稀疏激活模型的图例速度两倍与稠密模型
三、存算平衡
调和计算访存的平衡:
- 投机采样:用小模型为大模型打草稿,大模型进行校对,降低大模型向前计算次数;1.6~2倍的推理加速(降低大模型的推理次数 小模型推理,大模型验证)
- 前瞻采样:以并行采样为基础,痛死输入多个字符进行推理和采样;将历史上生成的N-gram装入并行采样,提高并行采样命中概率(1.3~1.8倍的推理加速)
- 美杜莎编码:通过训练额外的输出头,直接生成N-gram(2倍的推理加速)
- 衔尾蛇编码:最快较于自回归编码3.9*。。。
- 高速树状投机(EAGLE):起草模型仅用单层Transformer;树状起草多个候选,同时进行多个候选词验证;当前加速比最大的投机采样方法。
四、长序列处理
- InfLLM:通过检索机制实现块级别注意力稀疏;使短序列训练的模型具备1M tokens的捞回能力
- LOCRET:训练额外的注意力头来丢弃无用token,实现token级的cache的压缩,8B模型,单卡4090,推理1M tokens
- LLM+MapReduce:通过任务分治、结果合并两阶段方法进行长序列处理,达到效率效果的优异平衡
计算加速:
- 利用芯片缓存和分布式方法进行长序列处理加速;
- 引入量化方法降低长序列存储和计算开销;
- 混合使用上述各类方法可以实现更大程度的优化
长文本模型架构的矛盾三角经验观察与思考
吕鑫 智谱AI
一、基础回顾
为什么需要长上下文?
- 短期存储:Transformer的上下文窗口;电脑的内存RAM; 人类的短期记忆;
- 长期存储:外部向量化数据库等存储; 硬盘等持久化存储; 人类的长期记忆;
以GLM4-9b-chat-1M:开源长文本模型为例:
主要发现:1)信息捕获与推理能力在预训练阶段获得 2)短距离依赖泛化到长距离以来相对容易,无需过多的token
SFT——1)Naive Batching:速度极慢,Bubble time较大 2)sort batching:加入了先验 ,同Batch内长度相近,效果有时候更好 3)packing:将不同的数据sample合成一条长数据,基于Attention Mask来保持不同子数据的独立性
总结:
- 大模型长文本训练主要挑战:Activation显存显著增大
- 已有的3D并行:张量并行TP、数据并行DP、流水线并行PP均不适用
- 新的并行方式:Transformer全部的计算中只有Attention不是toKen独立的;序列并行:只对Attention部分并行,其余模块类DP
- 主要两种实现方式:Ring Attention、 DeepSpeed Ulysses
训练框架:Context Parallel:将长序列的Attention计算分在多个卡上进行; DeepSpeed Ulysses:将不同Attention Head 的计算分在多个卡上进行——共同点:可以降低每张卡上长文本训练的显存占用
二、矛盾三角
1)Lossless+ Reasoning :Transformer架构
优点:能够无损的记忆和处理上下文中的所有信息;能够基于已有的上下文做深度推理;长文本下游任务表现较好,基本上所有架构中的效果天花板;
缺点:训练时显存消耗大,需要额外的并行技术,计算量在长文本下显著增加;推理时计算量庞大,难以扩展到超长上下文本,或应用在计算机能力弱的设备上; 长度泛化性较差,难以进行无2训练的有效扩展。
2)Efficiency+Lossless: InfLLM(基于Context Memory的模型)、基于Sparse Attention 的模型——BigBird、Sliding Window KV Cache——YOCO
优点:能够精准召回上下文的信息;显著降低上下文Prefilling阶段的计算量
缺点:对于复杂的推理问题能力较差;每次生成时并不是能够看到全部的信息; 信息传播次数相比于Full Attention显著更少
3) Efficiency +Reasoning : 类SSM模型(Mamba、Retnet、S4)、循环State模型——RMT
优点:能够在隐式空间进行多次推理;显著降低长文本计算量
缺点:Token会被压缩至一个Hidden Representation,信息的召回是有损的;更适合做一些高层次的推理,涉及细节的推理有些困难
如何突破矛盾三角:
1)模型内突破:动态决定所需的上下文和计算量
2)模型间突破:根据问题的难度,选择所需模型
3)更好的权衡:选择合适的
三、经验观察
1)Sparse Attention
工作动机:并不是每个token对之间都需要Attention
Attention Pattern观察:不同层的Attention的稀疏度不一致,开始和结束的稀疏度偏低;不同Head之间的Attention稀疏度差异也比较大;针对不同层的不同Head,采用不同的稀疏度的Attention很重要
Attention存在较强的特征:Local Window特性;列特性;行特性
2)Sample Attention:
假设:key的重要性可以通过采样query计算Attention得到; 证明:采样5%的query计算和使用全部的计算,效果接近
3)Hybrid Mamba Model
Hybrid Mamb架构在短文本任务上由于Mamba和Transformer结构,具有完成复杂擦灰姑娘文本任务潜力
结论与思考:
- 在多数长文本需求场景下(128k内),Transform仍是最优选择之一
- 仍没有一个完美的架构能够在无损、高效和推理之间取得完美的统一
- 未来的架构探索需要更多的理论支持,是存在但还未被发现,还是在理论上就不存在?
第二场 情感计算
情感计算在多模态场景中的隐式应用
宋睿华 中国人民大学副教授
Emotion-Aware Transition Networks
不标注数据:1)麻烦 2)标注的数据不准确 3)内心活动丰富,开心有很多种程度
Emotion Lexicon——数据增广——找数据的同义词,换词
使用之前详细标注好的数据
TTS stage:Transfomer TTs with tts...[使用Transformer]
评估:人工评价、Recall、accuracy
模型效果低于BERT(低了十个点)——之前看过一些情感分析的文章,BERT是比较基础的基线,所以这个模型的效果真的好吗
案例分析:生成的语音多了一些情绪
评估:rouge 与一堆通用大模型对比
俺自己浅薄的观点——现在的大模型研究:做了自己特殊训练的模型和通用大模型来对比,体现性能。人家的模型是通用的,这种特殊训练后的模型就只单在这个方面具有一定的优势,其它的基本都差于通用大模型

国家形象的色彩维度:对谷歌图书大数据的量化分析
复旦大学 官璐 新闻学传播
研究国家和色彩的关系,例如:中国——红色;爱尔兰——绿色、
统计信息:紧密中心度、度中心度、节点
研究色彩和情绪的关系
内容偏理论方面的研究,侧重于不同关系的探索
以人为中心的大模型?从 用户算法理解到平台规则冲突
张伊妍 中国人民大学新闻学院
算法的功能性:如何涉及更高效的算法
从用户视角看算法:通过感性经验或理性知识建立,与算法相关的个体或集体认识、情绪和行为
为什么要研究算法理解(理论原因、实践原因):如果用户使用过程中能够感知算法并能够有意识地与它进行交互,这将被视为一种重要的数字力量
一些相关的大模型已经提出:不是具体的方法,一种逻辑
以人为中心的大模型?大模型的透明度transparency、大模型的可靠性trustworthy、符合伦理的大模型ethial、尊重文化与价值观点大模型respectful
算法理解研究四部曲:
1)厘清定义:中英文核心文献梳理与理念框架
研究发现:算法理解的主要概念聚类、中英文研究的差异与关系、概念的泛滥与误用;
后续研究:概念的时间变迁
2)探索理解:用户是怎样构建对“信息茧房”和算法关系的理解的
采用“民间理论”在不同语境下进行了比较,帮助普通用户理解“信息茧房”等概念;
民间理论比较:与强调算法和平台作用的学术研究相反,非专业人士主要将信息同质性归因于政治行动者(美国)和小群体(中国)。本研究强调了民间理论的语境偶然性,也为提到算法素养提供了见解。
探索理解:世界各国民众是怎样感知和归因线上“信息茧房”的?
- 线上信息茧房感知:平台或算法的影响、人们的自主选择、强权。。。
- 线下信息茧房感知:人们的自主选择、虚假信息或错误信息传、强权主体的控制。。
3)探索影响:算法意识是否会颠覆媒体效果
算法的透明性,用户对算法的感知水平不同——研究不同算法设计是否会影响人们对个性化新闻推荐存在感知?
实验:中美500人(个性化推荐/非个性化推荐)——没有给出具体的细节内容
4)探索利用:用户是怎样构建算法想象并反向利用算法的
探索利用:粉丝群里是怎么构建算法想象并反向利用算法的
- 发现一:数据“通胀”(手动增加数据、基于程序或算法扩展、为数据付费买水军)和数据“通缩”(举报异常账号或者信息、不做数据)
- 发现二:平台回应
评论罗伯特——微博机器人(与其的互动有的是人主动,有的是机器主动)——出现已读乱回情况,内容不符合语境
想法构建:用户对“评论罗伯特”行为的推理与归因
行为回应:互动中的适应与抵抗
开始很多人认为推荐算法在窥探他们的隐私——也确实(电子设备除了会记录用户的各种使用信息和用户填写的私人信息,还会会偷听、偷拍。。。——目的:实现个性化推荐(增大了信息茧房))
探索利用:平台之间是否存在规则冲突? 规则可见度、内容详细度、内容主题差异
总结:
- 计算传播的核心依然是“传播”而非“计算”,人的问题是根本
- 新的弱效果时代?可能只是选择性的效果、个人化的效果
- 围绕技术的研究中将算法理解作为变量带入
【说实话,没听懂主旨想表达什么】
2024年20月13日上午
会议室被隔开一半,来听会的人也不是很多
The Checklist: What Succeeding at AGI Sagety Will Involve
Sam Bowman Research lead at Anthrople【全英文的汇报 主题是AI安全】
演讲主题:必须应对AI安全挑战,以及像Anthropic这样的大模型开发商如何应对哲学挑战
背景和预言
- 人工智能系统能力的迅速发展,正将人类推向一个人工智能可以达到甚至超越人类智能的世界
- 人工智能系统的滥用或失控可能会给人类带来严重的后果
一些风险
人工智能不能自主复制、权利、提高杀伤力、自主网络攻击、产生误解或跨越前面的红线
strategy 战略、 step by step (三个阶段:不具备自主搜索reseach能力、开始出现人类级别的reseach且低于人类、在所有的领域比人类聪明)
Technical Safety Foundations:
1) 在很大程度上解决早期TAI的对齐: 确保我们能够从人工智能系统中获得有用的工作,而不需要
灾难性故障;可扩展监管是一个主要方向。奖励黑客是一个主要的挑战。
2) 建立可靠的监控和其他外部保障措施. 额外的预防措施可能是必要的:确保模型不会造成严重的伤害,即使我们的校准失败。对抗性的健壮性和越狱是一个主要的挑战
3) 解决可解释性的基本问题:对基于网络内部的LLM推理做出声明。
以语言为核心的人工智能:探索与实践
张民 哈尔滨工业大学(深圳)、苏州大学
一、背景知识
2024诺贝尔化学奖(与AI结合——跨领域学科结合研究)
Anthropic CEO:AI将在未来10年左右消除所有疾病,人类寿命能到150岁【科技与狠活】
1956年的达特茅斯暑假研讨会提出“人工智能”的概念
AI 不等于 大模型——回归AI的本质(AI是研究、开发用于模拟、延伸和拓展人的智能和行为的理论、方法、技术及应用系统的一门新的技术科学)
AI以小时为单位的进步和人类之间想象力之间的矛盾:蒸汽机、电力、信息技术、人工智能/大数据
二、语言智能
实现高效的语言理解和人机交互,核心技术是自然语言处理
内容:数据——知识——智能——智慧
发展阶段的演变:特定文本任务的模型、通用大模型模型、以语言为核心的多模态大模型、通用智能体(具身智能)、群体智能(社会行为的自主智能)【处在2,快速实现3,逐步迈向4 5】
语言智能技术范式变迁:小规模专家知识(专家规则)、浅层统计模型(统计建模)、神经网络模型(词嵌入建模)、预训练+微调模型(自监督建模)
研究:针对不同的下游任务构建不同的模型
新范式:通过语言生成统一所有自然语言处理任务
大模型的三个特性:规模性Scaling Law、涌现性Intelligence Emergence、通用性Generality
背后的原理:数学(函数的拟合)——1)神经网络对连续函数的精准模拟 2)复杂系统的智能涌现
ChatGPT模型:给定前N个词,预测下一个词,N-gram统计语言模型
惊艳之处:神经网络可以模拟任何数学函数和数据;注意力机制完全符合NLP的理论和技术、学习人类意识——智能的涌现、大模型见多识广
三、以语言为核心的人工智能
深圳给了几个亿的研究经费(23年底调研研究)
数据很重要!!
大语言模型:基于表示与理解的语言生成模型——大数据、大参数、大算力
数据治理:建设了超过100TB的超大规模原始文本数据库,可支撑万亿参数基座大模型的训练; 开发了一套系统完整的针对多种噪音的多维度、多层次深度清洗工具
架构设计:1)语义表征和知识增强的高效网络:包含 音形义三位一体的语言表示、知识增强的高效生成 2)基于多模态信息的常识增强,语言训练产生幻觉——采用多模态数据进行训练
学习方法:内容丰富和准确的模型优化:内容丰富性增强的深度强化学习和面向大模型幻觉消除的对比学习
训练过程:基于训练动力学的大模型认知特性刻画与量化评估【目前的研究】
文本立知大模型:安全——大模型防火墙; 相关技术:剪枝、知识蒸馏、量化、低秩分解
多模态大模型要做的两件事:1)内容理解(多模态特征对齐与融合)——懂内容;2)多模态内容生成(语言语义生成视觉信息)——能创造
难度竟然变成了优化参数??
多模态大模型架构——Flamingo、InstructBLIP、LLaVA、Fuyu
四种典型生成模型:生成对抗网络(训练过程不稳定,生成缺乏多样性)、变分自编码器(生成内容模糊不真实)、流模型(必须使用专门的架构)、扩散模型(生成速度慢,但是多样性且训练过程稳定)
现有主流模型架构——潜在扩散模型:
- 特点:将图像映射到降维的潜在空间;在潜在空间中进行扩散生成
- 优势:降低资源消耗;提高训练、推理速度
多模态大模型:若愚-九天——多模态,模态覆盖面广;经典的多模态数据集;模态联系能力强;可扩展性强
统一多模态大模型:Uni-MoE——以大语言模型为核心,率先提出了多模态数据理解的多专家混合架构【2024年的一篇论文】
可信文档阅读智能体:具备多语言、多任务、多领域的文本嵌入表示能力
以大语言模型为核心,率先提出了多模态数据理解的
图论求解智能体:构建了首个多模态图论数学基准,评估多模态大模型的复杂逻辑推理能力
多智能体协作电影制作:无需人工干预,可以管控视频生成所有过程
感觉这些七七八八智能体,向大模型投喂不同领域的内容进行训练——一个领域或不同领域的内容结合——论文就出来了:关键——速度占坑
具身智能:旨在通过将只能算法与物理实体感知、行动和环境交互相结合,使机器人能够以更自主、更智能的方式与环境进行交互和完成任务
后部分内容由于时间问题,过得超快

面向司法信息处理的大语言模型探索与实践
刘奕群 清华大学教授
挑战:专业知识学习、模型幻觉消除
法律大模型评价和测试标准
L3MER:协助构建法律科技标准——评估方面分成了六成:记忆、理解、推理、辨别、生成、伦理
应用场景:
- 大模型辅助文书书写(法官集中判决的裁断,文书的书写交给大模型)
- 法律智能体——司法智能体
- 案件阅核辅助
- 案件要素式改判发回预警
- 法学研究范式革新
大模型的研究:领域知识的注入,然后模型反复训练
Panel:大模型时代的AI+
嘉宾:陈恩红(中国科学技术大学教授)、冯仕志(中国人民大学教授)、张民(哈尔滨工业大学教授)、刘奕群(清华大学教授)、邱锡鹏(复旦大学教授)
大团队、大工程、大平台、学科交叉、新范式
真正的学科交叉不是在会议室形成的,而且是学习后头脑中形成的
2024年10月13日下午
分论坛:大模型驱动的图计算
针对图数据的LLMs
黄超 香港大学助理教授
即将开源的大模型:GraphAgent
进一步探索:例如手机场景信息复杂——大小模型结合
GOFA: A Generative One-For_All Model for Joint Graph Language Modeling
大模型显式解决图算法问题
李佳 香港科技大学 助理教授
Unify the INput to GNNs
Challenge 2: Output from GNNs are Different
博士论坛
对抗攻击