Cortex-M3深入理解
系列文章目录
文章目录
- 系列文章目录
- 前言
- ARM底层编程思想
- 微控制器接口CMSIS
- 处理器信息
- OS
- 影子栈指针
- PendSV异常
- SVC异常
- 存储器
- 栈及SP的理解
- 存储器保护单元MPU
- 存储器实际物理模型
- 系统存储类里面的硬件
- stm32里面的map文件
- DMA
- 总线
- 低功耗
- 实际分析低功耗
- FreeRTOS的低功耗
- 异常及中断
- NVIC
- 中断的区别
- CPSR SPSR
- 中断里面用自旋锁
- 并发和互斥
- 指令集
- 调试
- 栈溢出检测
- 三种通信协议
- SPI
- IIC
- RS232/RS485
- RS232
- RS485
- CAN
- TCP/IP
- 交叉编译
- FreeRTOS tracelayzer
- PWM
前言
书名《ARM Cortex-M3与Cortex-M4权威指南》
ARM底层编程思想
在一块芯片中,有:程序存储器(flash)、SRAM(数据用的)
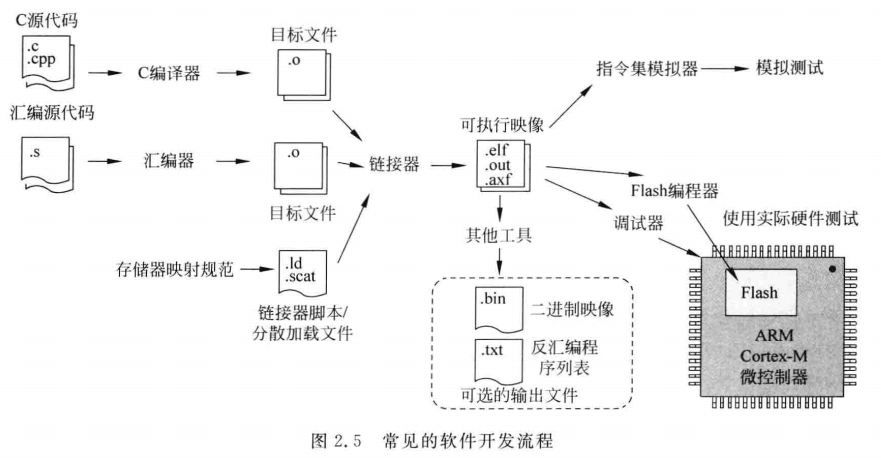
看这里的地址配置:外设寄存器经过存储器映射,可以用指针直接访问。寄存器是外设内部的一组特殊内存单元。
后面的就是实际的物理地址,,先转化成unsigned long *,因为stm32寄存器是32位的一般,volatile关键字告诉编译器该变量可能被硬件意外修改,不能缓存到寄存器里面,确保每次访问都是实际的物理地址,外面的 * 是堆指针解引用,得到该地址的寄存器变量,就可以直接赋值了。
这里提到的寄存器,是CPU的软件寄存器,例如ARM Cortex-M3的R0、R1通用寄存器,用于存放临时数据胡哦地址,不是指外设寄存器(硬件地址)

每个寄存器地址定义,都要一个地址常量,太浪费了,写成通用方式,结构体加基地址的方式
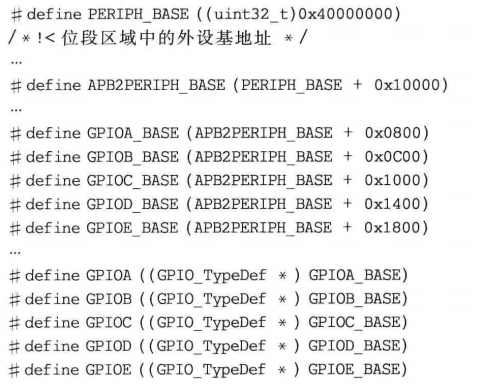
后面进行简化:_IO就是数据为volatile

微控制器接口CMSIS
ARM公司制定的一套通用软件接口标准,不然不同厂商的底层接口差异可能很大,配置GPIO的函数名都不一样
处理器信息
指令集:cortex-M指令集是Thumb的,cortex-M3是Thumb-2的
OS
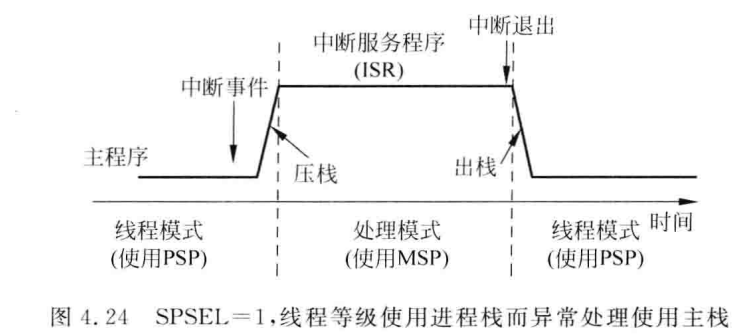
内置的系统节拍定时器SysTick可以提供周期性的定时中断。M3具有两个栈指针:OS内核和中断用的主栈指针(MSP)以及应对任务的进程栈指针(PSP)
单任务系统:只需一个栈指针(MSP),所有代码(主函数、中断服务函数)共用同一片栈内存
多任务系统(RTOS):每个任务需要独立的栈空间(存储局部变量、函数调用返回地址等),且内核(RTOS 调度器、中断处理)也需要独立栈空间,避免任务崩溃影响内核。
安全隔离:内核栈(MSP)仅用于系统核心功能(中断、调度器),任务栈(PSP)用于用户任务,即使某个任务栈溢出,也不会破坏内核栈,提高系统稳定性。
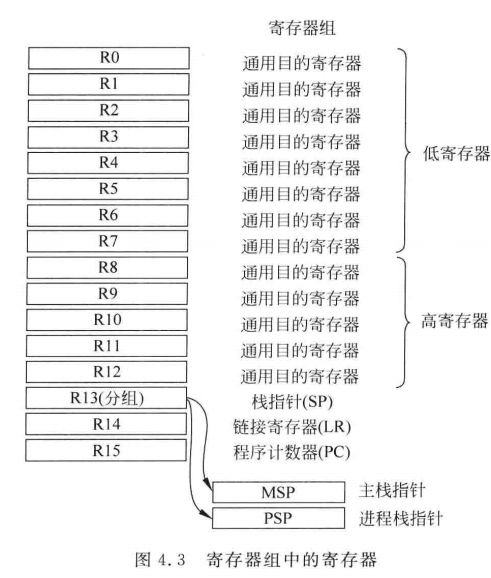
这里栈指针SP就分成MSP和PSP
R14是链接寄存器,用于函数或子程序调用返回时的返回地址的保存。具体是PC加载LR,返回到程序中接着执行。
当我们嵌套函数时,LR不够用了,就把上一个LR入栈
R15程序计数器(PC),可读可写,指向程序运行下一步的地址
影子栈指针
MSP和PSP,主栈指针和任务栈指针,可以看到是各有各自的栈
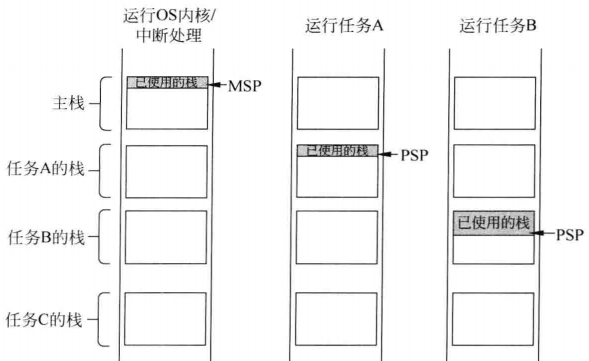
任务栈被破坏,但是OS内核的栈和其他任务的栈不会收到影响。
上电时,MSP初始化为向量表的数值,OS可以利用MPU内存保护单元定义可以访问某个栈的应用任务,若应用任务有栈溢出的问题,可以出发MemManage错误异常,避免该任务栈以外的存储器区域被覆盖。
这里介绍概念,ARM的执行模式分为:
线程模式:执行普通的应用程序代码,特权/用户模式
处理模式:专门处理异常,特权级别
权限级别:
特权模式:访问所有CPU指令和寄存器,操作系统内核或关键驱动通常运行在此模式。
用户模式:受限权限,禁止访问特权指令或关键寄存器(如NVIC),防止误操作破坏系统
PendSV异常
Pendable Service Call(可挂起的服务调用)
上下文切换,用的是PendSv这个异常
操作流程:
1.寄存器状态压栈
2.保存当前PSP
3.PSP设置为下个任务的SP堆栈指针数值(PSP有个数组,里面是各个任务的SP指针)
4.恢复下个任务的现场
5.返回任务执行
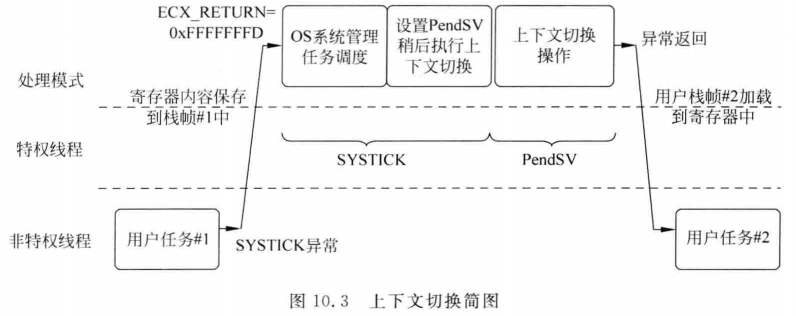
PendSV优先级非常低,防止中断过程中产生上下文切换
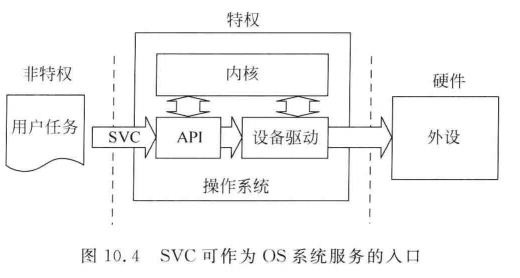
SVC异常
Supervisor Call(监管调用),实现用户态到内核态的切换,通过执行 SVC 指令(后跟一个立即数参数,服务号 ·)触发。
安全性:用户代码无法直接访问特权资源,必须通过 SVC 请求内核代劳。
结构化设计:隔离用户程序与内核,避免恶意操作(如直接修改 NVIC)。
相对于PendSV处理延迟操作,SVC处理的是即使服务请求
先补充一些要点,不然下面看不懂,首先任务切换看时间片用光没,是在嘀嗒定时器里面检测的;其次,任务时间片累计是在任务执行的时候,有各自的计数器,每个 SysTick 周期增加计数器;中断里发生的时间是不计入该任务的时间片里的
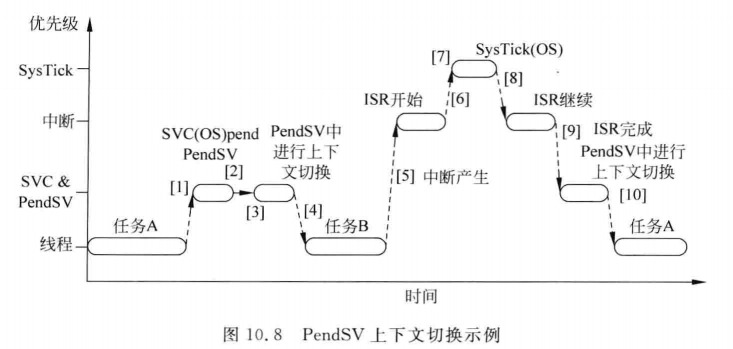
结合PendSV来说,整体的流程是:
1.A任务调用SVC进行任务切换(主动切换,vTaskDelay()也算;正常时间片轮转是不会产生这个异常)
2.OS收到请求,准备上下文切换,挂起PendSV异常(因为主动切换,所以这里不需要进入systick里判断时间片就能切换任务)
3.CPU退出SVC,立刻进入PendSV,进行上下文切换
4.PendSV完成后,返回线程模式,OS执行B任务,假设B时间片满了,但还没经过SysTick 异常检测
5.中断发生,进入中断处理
6.运行中断处理程序时,STSTICK异常会产生,定时触发的滴答定时器
7.OS执行重要操作,挂起PendSV异常准备上下文切换,但暂时不切换
8.STSTICK异常退出,回到中断服务程序
9.中断结束,PendSV上下文切换
10.PendSV结束,回到线程,返回A继续执行
嘀嗒定时器的优先级通常是0-4中,确保时间片调度不被普通中断阻塞
存储器
栈及SP的理解
32位,4GB的线性地址空间,所以最多能访问4GB的存储器,尽管很多嵌入式存储器不超1MB
存储器保护单元(MPU),定义了各存储器区域的访问权限,M3支持8个可编程区域
栈存储和栈指针R13
栈作用:
执行的函数需要使用通用寄存器处理数据,栈就要临时存储数据初始值。
函数或子程序信息传递,形参啥的
存储局部变量
中断等异常产生时保存处理器状态和寄存器数值
栈是向下生长的,所以SP堆栈指针是逐渐减小的,SP指向的是上一次数据存储在栈中的位置
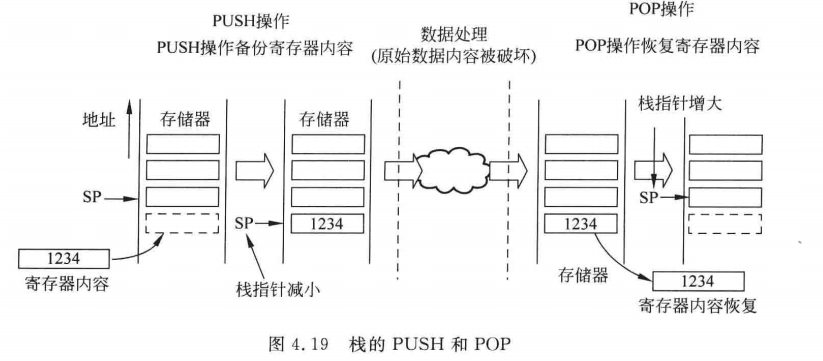
详细解释一下栈的作用:
PUSH和POP操作,在执行函数或子程序调用时,例如函数数据处理的时候,需要使用并修改R4、R5、R6,而且这些寄存器后面主程序还要用,就会PUSH保存栈里面,后面函数结束时,再pop恢复出来。
由于通用寄存器都是32位的,4个字节,所以压栈出栈时,都是4字节对齐的,所以SP的低两位一直都是0
(pop和push可以同时操作多个数据)
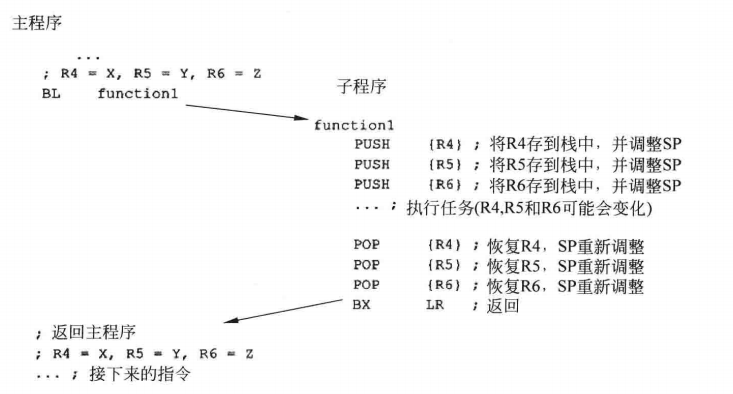
之前LR也是,链接寄存器,把R14的数值压入栈中,函数返回的时候再恢复到PC15,所以入栈会有通用寄存器、LR链接寄存器,都是通过SP来入栈出栈的
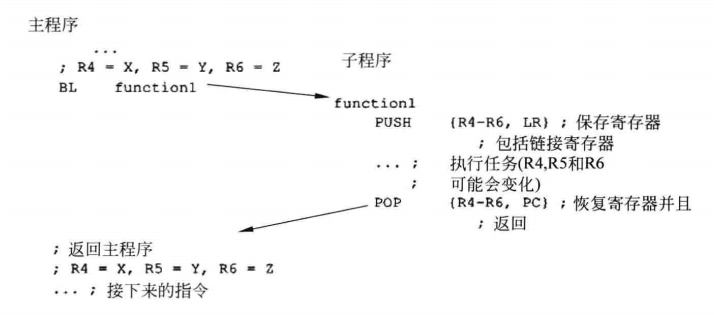
操作系统里面SP就分开了,有MSP和PSP
MSP(主栈指针)用于复位后默认使用的栈指针,用于所有的异常处理。
PSP(进程栈指针),只能用于线程的栈指针,通常用于系统任务
通过CONTROL寄存器的第2位来选择的,为0就不用PSP
存储器保护单元MPU
对内存访问权限和区域进行精细化控制
特权级与用户级隔离
保护内核关键数据: 将 RTOS 内核代码、堆栈、外设寄存器设为仅特权模式可访问,防止用户任务误操作。
隔离任务内存: 为每个任务分配独立的内存区域,避免任务间互相篡改数据。
防止代码篡改
将 Flash 中的代码区域设为只读,防止恶意代码修改自身或他人代码。
外设保护
关键外设(如时钟控制器、NVIC)的寄存器设为仅特权模式可写,避免用户任务错误配置。
动态内存管理
配合 RTOS 实现动态内存池保护,例如禁止任务访问其他任务的内存池
存储器实际物理模型
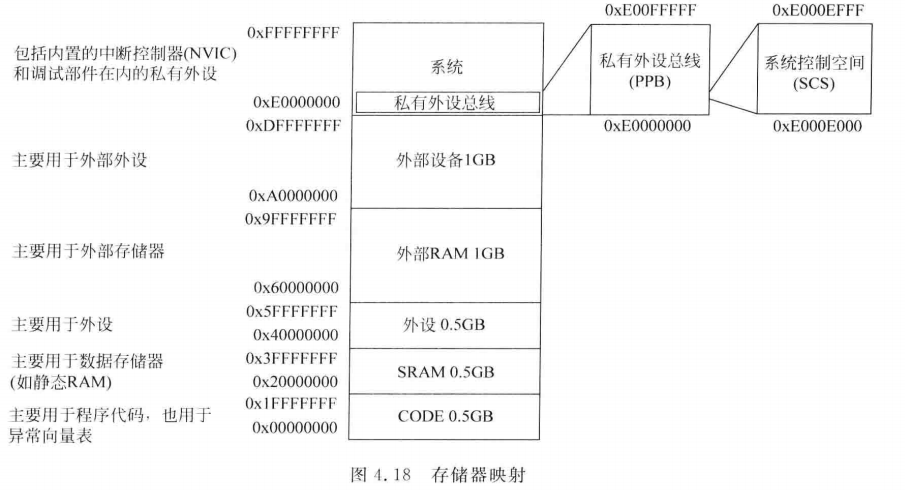
首先明确,这里不是实际的物理存储器,而是Cortex-M架构的统一编址范围
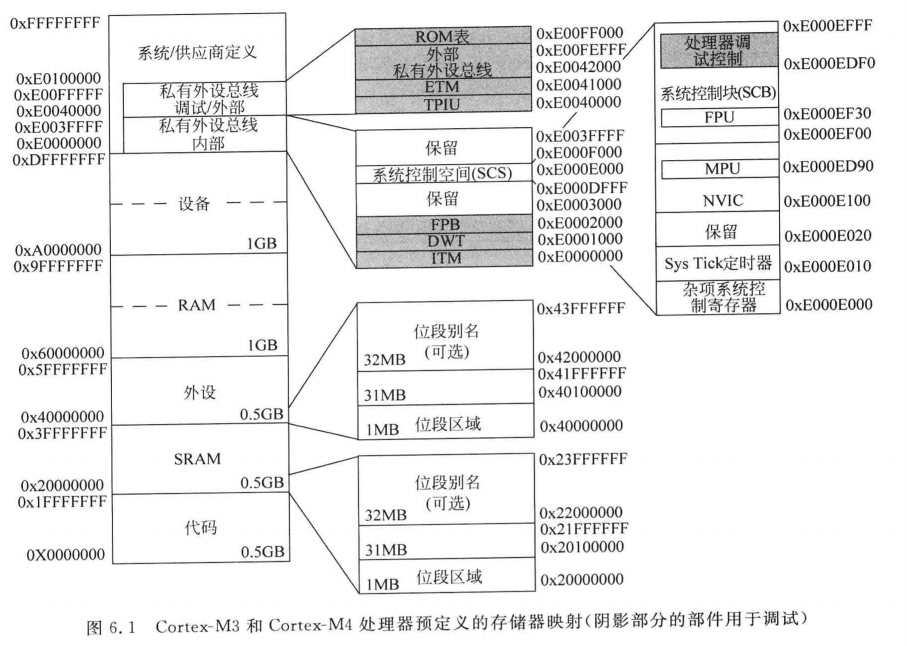
下面对存储器解析:
0x00000000~0x1FFFFFFF是512MB的空间,存储程序代码,包括一部分默认向量表
0x20000000~0x3FFFFFFF是512MB的空间,连接SRAM,在这个区域里面执行代码
0x40000000~0x5FFFFFFF是512MB的空间,用于片上外设
0x60000000~0x9FFFFFFF,1GB,用于片上存储器等其他外设,存放程序代码和数据
0xA0000000~0xDFFFFFFF,1GB,用于片外外设等其他存储器
0xE0000000~0xFFFFFFFF 是系统
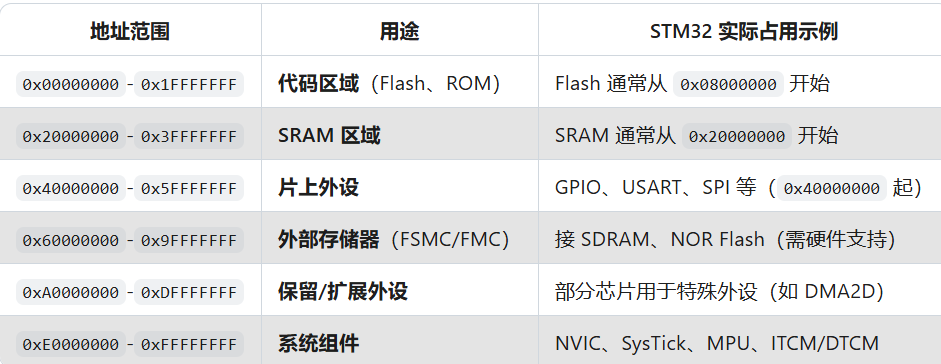
0x00000000 通常映射到 BootROM(启动代码)
BOOT0=0:0x00000000 映射到 0x08000000(主 Flash)
BOOT0=1:0x00000000 映射到 0x1FFF0000(系统存储器,存放 Bootloader)
串起来了!前面学过BOOT的配置情况
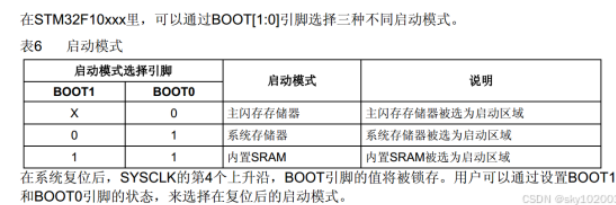
1.BOOT0=0, BOOT1任意,keil烧录程序的时候,就会烧到Main memory 主存储区(0x0800 0000),直接从这里运行程序
2.BOOT0=1,BOOT1=0,这是串口烧录方法,单片机从系统存储器(0x1FFF 0000)启动,运行的是出厂预置的BootLoader程序,可以接受串口发来的程序,并将其写入Main memory(0x0800 0000),烧完再拉低BOOT0,从0x08000000处运行程序
3.BOOT0=1,BOOT1=1,从内存中启动,从内置的SRAM启动,程序不会存储,用于调试
默认向量表在 Flash 起始处(0x08000000),中断处理函数需在此定义。
我来总结一下,首先映射地址从0x00000000开始,首先这里是个ROM,存储着出厂的Bootloader;之后是FLASH,存放着默认向量表和我们的程序;之后是SRAM,用来运行程序;之后是外设寄存器,映射到的是实际物理中的一些锁存器和触发器的地址;扩展外设,映射连接到外部存储器(如 SDRAM、NOR Flash),可能后续还得看看怎么应用;系统区域映射的是实际中各个物理硬件模块,都是实际的物理电路,集成在CPU里面
SRAM就是我们堆栈分配的地方,是我们代码运行的地方
补充一下bootloader的功能,除了可以用串口编程FLASH,或者自己程序运行时编程Flash;提供通信协议栈等固件,方便软件开发人员API调用;提供芯片的自检功能(BIST)
这里和之前的LINUX的进程空间模型混在一起了,注意这是两种模型,他那个是系统创建一个进程的时候,系统为其分配的4G的虚拟地址空间,0-3G是用户空间,3-4G是内核空间。实际通过MMU映射到实际的物理地址。而上面的Cortex-M的存储器,映射的是各种实际的物理器件。
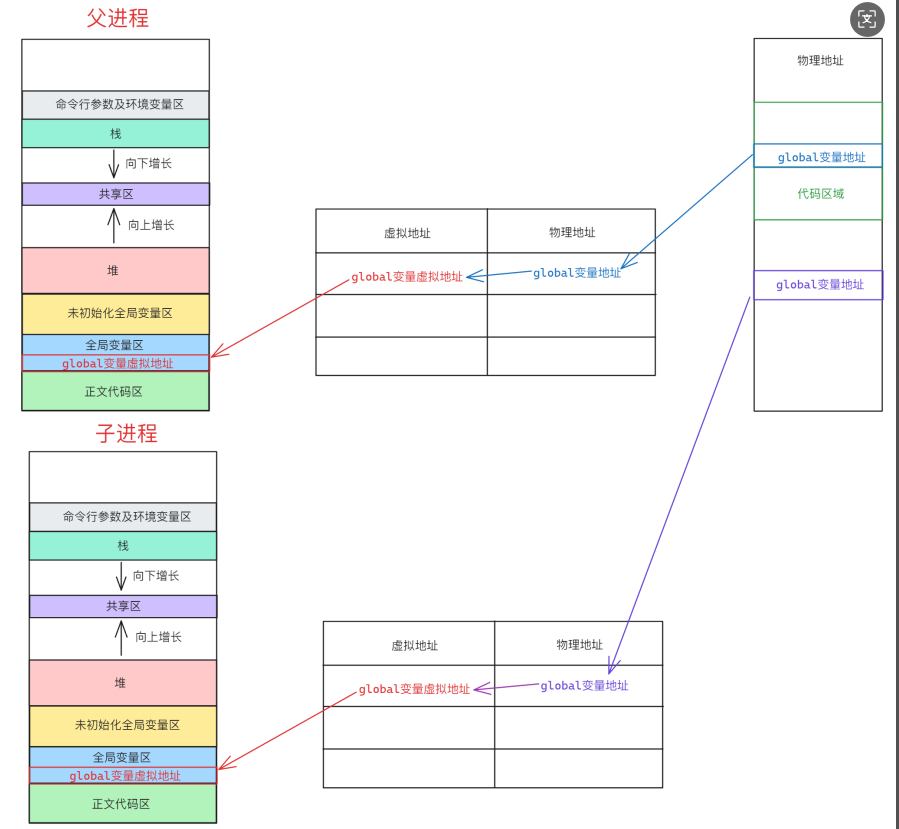
回到Cortex-M:
.text(代码段):默认存放在 Flash 中(只读),运行时可拷贝到 SRAM(如 ITCM) 加速。
.data(初始化变量):编译时存储在 Flash,运行时由启动代码拷贝到 SRAM。
.bss(未初始化变量):不占用 Flash 空间,仅在 SRAM 中预留地址,启动时由代码清零。
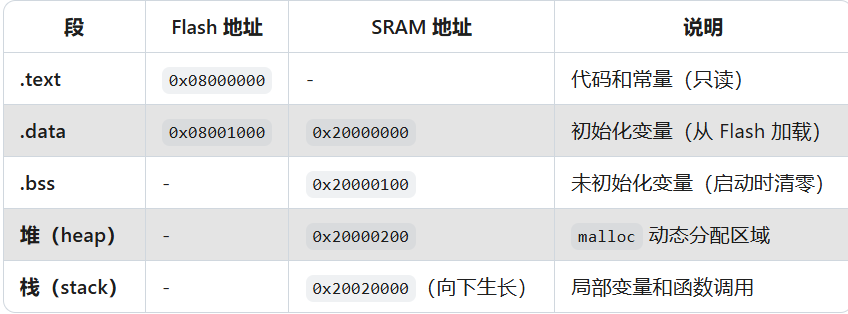
回到ARM,STM32下载中,会出现各种文件,记录一下作用:
.s:启动文件,芯片启动的汇编代码,初始化堆栈、中断向量表。定义 Reset_Handler,跳转到 main();初始化 .data 段(从 Flash 拷贝到 RAM);清零 .bss 段(未初始化变量)
.ld:链接文件:指定程序中各个代码存放的位置,定义Flash和RAM的起始地址大小,分配.text(代码)、.data(初始化变量)、.bss(未初始化变量)、堆(heap)、栈(stack)
.o:目标文件,包含机器码但未进行最终链接
.elf:完整的执行程序,包括调试信息,用于调试开发使用,包含 代码、数据、调试信息、符号表,用于 调试和下载(需工具解析)
hex/.bin:纯二进制或十六进制格式的固件文件,用于烧录到芯片
.hex(Intel HEX):包含地址信息,兼容性广(如 STM32CubeProgrammer)。
.bin:纯二进制,需指定烧录地址(如 0x08000000)
.map:显示程序的内存布局(各段地址、符号表、占用空间),分析内存溢出、优化代码大小
系统存储类里面的硬件

前面说过了,向量表放在地址0处,向量地址是异常编号*4,启动代码.s使用的向量表包含了MSP,所以复位后,会先读取MSP初始值,确保后面能调用栈空间,C语言函数调用、局部变量和中断处理都依赖栈。NMI等异常可能随时出发,甚至初始化代码前,异常需要栈来保存的。

==向量表存放位置三种模式:==关系到向量偏移寄存器(VTOR)
Flash启动:当STM32配置为从主Flash启动(通过BOOT引脚设置为BOOT0=0,或根据具体型号的配置),芯片会将0x0800 0000映射到0x0000 0000(即硬件自动将Flash起始地址映射到向量表基址);实际向量表存储在Flash的0x0800 0000,但CPU在运行时认为它位于0x0000 0000(硬件重映射)
ROM启动:通过BOOT引脚选择从系统存储器启动(如BOOT0=1,BOOT1=0),芯片会执行内置Bootloader,此时向量表由Bootloader提供,用户无需关心。
SRAM启动:有些情况,程序直接加载到RAM里执行,例如从SD卡等拷贝程序到SRAM中,这个时候会跳转到SRAM的向量表中,进行复位向量启动应用
stm32里面的map文件
在map文件里面,有如下代码,前面学完就知道这里的是FLash的地址,但是这里分了加载空间和执行空间,size就是各自的大小
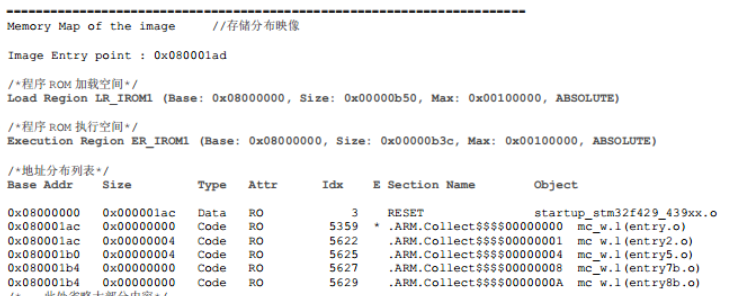
加载空间:程序存储的物理地址
执行空间:程序运行时的地址空间,这里基地址是一样的,就说明直接从Flash里面执行代码,否则执行空间地址应该是RAM
执行空间的 ROM 比较小的原因就是因为部分 RW-data 类型的变量被拷贝到 RAM 空间了;它们的最大空间(Max)均为0x00100000,即 1M 字节,它指的是内部 FLASH 的最大空间。
DMA
DMA是无需CPU参与,就可以让外设与系统内存之间进行双向数据传输的硬件机制,从而提高系统效率和吞吐率
DMA,全称Direct Memory Access,即直接存储器访问
对于大容量的STM32芯片有2个DMA控制器 两个DMA控制器,DMA1有7个通道,DMA2有5个通道。
没有DMA,cpu传输是要以内核为中转站,将数据搬运到SRAM,经过总线矩阵协调,获取AHB存储的外设数据
DMA控制器的DMA总线与总线矩阵协调,使用AHB把外设ADC采集的数据经由DMA通道存放到SRAM中
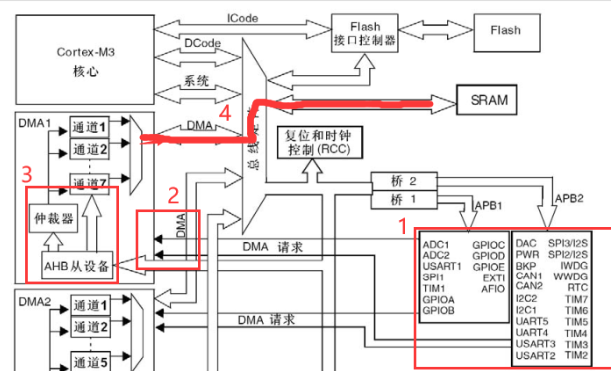
DMA有正常传输模式和循环传输模式,仲裁器可以确定各个DMA传输的优先级
DMA具体会不会经过桥接器连接到AHB和APB,还是要看具体的外设连接情况。
总线
上图有结构图,讲一下总线,
AHB(Advanced High-performance Bus):高速总线,连接 Cortex-M 内核、DMA、内存等。
APB(Advanced Peripheral Bus):低速总线,挂载通用外设(如 UART、I2C)。
AXI(仅 Cortex-M7/M33):更高性能总线,支持多主设备并行访问。
APB1/APB2:具体外设连结的哪个设备可以在cubemx或者手册里面查
AHB 时钟(HCLK):CPU、内存、DMA 时钟源
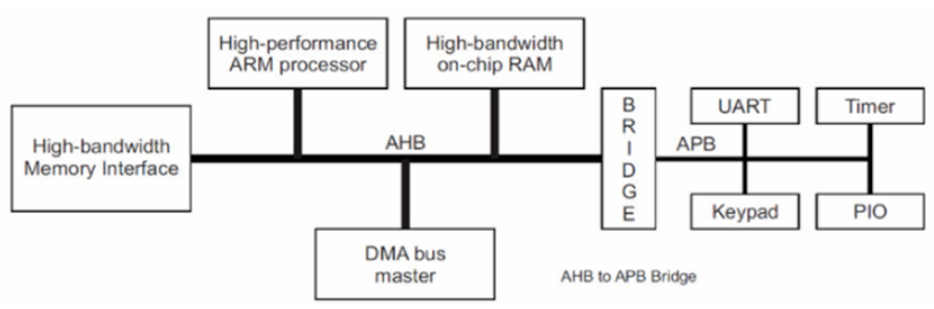
低功耗
主要针对的休眠模式电流、能耗功率、唤醒等待时间
时钟频率也是影响功耗的一大因素
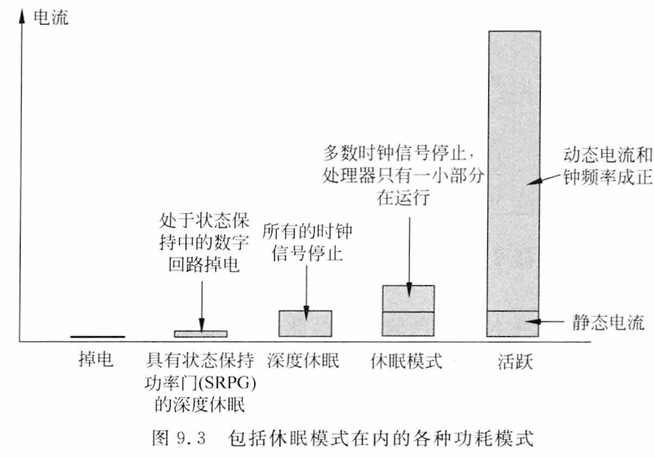
内部有个唤醒中断控制(WIC),因为所有的时钟信号都关闭,NVIC也无法检测新产生的中断,这很好理解,就像FPGA里面的时序逻辑,没有时钟信号,数字逻辑都检测不了了
WIC是个硬件的有限状态机,应该是组合逻辑,不需要时钟就能运行,监视着几个少数的唤醒源
cortex-M里面,只有深度休眠模式会用到WIC
降低功耗的几个点:
1.选择合适的位控制器,除了电器特性,还有存储器,Flash和SRAM太大也会增加功耗(读写的时候,要激活存储单元和地址解码电路,容量越大代表着更复杂的电路和位线)
2.运行在合适的时钟频率,保证良好的响应速度,考虑是运行的快进入休眠,还是运行的慢降低功耗(动态损耗,数字电路0-1切换的时候产生的功耗;静态功耗由漏电流引起)
3.关闭未使用外设的时钟信号,有君泰损耗
4.系统不同部分有各种时钟分频器,选择合适的速度
5.供电设计
6.当Flash程序拷贝到SRAM中,SRAM运行整个应用,就可以关闭内部Flash来节能。当然SRAM比较小,所以全部复制是不可能的,所以会在使用的时候再打开Flash
7.正确的IO端口配置,可以设置驱动电流和转换速率,根据实际设备设置
实际分析低功耗
频率对功耗的影响很大,这是F103系列
三种模式:唤醒:WKUP引脚上升沿、RTC闹钟事件的上升沿、复位引脚上升沿、看门狗复位
1.睡眠模式:只有内核时钟关闭,外设仍在运行(各有各自的时钟);唤醒后回到睡眠的位置向后执行。
HAL_SuspendTick();//停止系统滴答计时器// HAL_PWR_EnableSleepOnExit();//设置SCR寄存器的SLEEPONEXIT位,在中断处理结束后重新进入SLEEP模式。HAL_PWR_EnterSLEEPMode(0, PWR_SLEEPENTRY_WFI);//WFI指令进入睡眠模式HAL_ResumeTick();//恢复系统滴答计时器
过执行WFI或WFE指令进入睡眠状态。由于系统的滴答定时器也能够解除睡眠状态,所以要停止
33mA->18mA
2.停止模式:关闭内核时钟、外设时钟,保留内核1.8V供电,寄存器和SRAM中的数据可以保持,IO口状态也可保持;唤醒后可回到停止的代码处向后执行,但要重新初始化时钟和外设。(所有时钟都停止)(数据保存)(注意这里电路中,有独特设计,只有状态保持的电源还在)
系统时钟:停止模式唤醒后,STM32会使用 HSI(f1的HSI为8M,f4为12M)作为系统时钟。所以,有必要在唤醒以后,在程序上重新配置系统时钟,将时钟切换回HSE。
唤醒延迟 :基础延迟为 HSI振荡器的启动时间,若调压器工作在低功耗模式,还需要加上调压器从低功耗切换至正常模式下的时间,若 FLASH 工作在掉电模式,还需要加上 FLASH 从掉电模式唤醒的时间。
//停止模式HAL_SuspendTick();//停止系统滴答计时器HAL_PWR_EnterSTOPMode(PWR_LOWPOWERREGULATOR_ON, PWR_STOPENTRY_WFI);//电压调节器为低功耗模式,WFI指令进入停止模式SystemClock_Config();//重新配置系统时钟HAL_ResumeTick();//恢复系统滴答计时器33mA->8mA
3.待机模式
待机模式可实现系统的最低功耗。该模式是在Cortex-M3深睡眠模式时关闭电压调节器。整个1.8V供电区域被断电。PLL、HSI和HSE振荡器也被断电。SRAM和寄存器内容丢失。只有备份的寄存器和待机电路维持供电。
int main(void)
{HAL_PWR_EnableWakeUpPin(PWR_WAKEUP_PIN1);//强制使能WKUP(PA0)引脚SET_BIT(PWR->CR, PWR_CR_CWUF_Msk);//写1清除该位 唤醒位SET_BIT(PWR->CR, PWR_CR_CSBF_Msk);//写1清除该位 待机位 while(1){//待机模式SET_BIT(PWR->CR, PWR_CR_CWUF_Msk);//写1清除该位 唤醒位 如果不清楚此位 系统将保持唤醒状态HAL_PWR_EnterSTANDBYMode();//进入待机模式 }
}待机模式实测电流比停止模式略低一点,7mA左右
现代STM32(如Cortex-M4/M7)通常采用1.8V作为核心电压,以降低动态功耗
调压器其实是1.8V的稳压器
WFI(wait for interrupt)等待中断唤醒
WFE(wait for event)等待事件唤醒
看到睡眠模式和停止模式都是调用的WFI指令,后面可能还需要学习WFE的使用
待机模式都不支持这两种指令,仅支持WKUP、RTC、复位三种情况

FreeRTOS的低功耗
Tickless 模式的核心思想允许处理器在系统空闲时,预测下一个需要执行任务或处理事件的时间点,并据此动态配置一个更长的休眠时间。只有当预测的唤醒时间到达,或更高优先级的外部中断发生时,处理器才会被唤醒。
FreeRTOS通过在空闲任务里面进入低功耗,前面了解滴答定时器的中断也可以唤醒,所以会停止滴答定时器,FreeRTOS 特地提供了Tickless 模式的解决方法,处理器进入空闲任务周期以后就关闭滴答定时器中断,只有当其他中断发生或者其他任务需要处理的时候处理器才会被从低功耗模式中唤醒。
专用STM32L型号低功耗处理器有一个LPTIM(低功耗),用它来记录系统时钟停止的时间,到后面启动的时候再补上。F103采用的还是滴答定时器,会改变其重装载值,让其定时时间变长。
系统会根据下一个任务的阻塞时间还剩多少,来设置定时唤醒低功耗
#define configUSE_TICKLESS_IDLE 1 //1 启用低功耗 tickless 模式
configEXPECTED_IDLE_TIME_BEFORE_SLEEP 最小空闲时间阈值(单位 tick),避免频繁休眠/唤醒的开销。
portSUPPRESS_TICKS_AND_SLEEP()
其中可能涉及到BASRPRI(Base Priority Register),作用是中断屏蔽优先级的一个界限,必须保证屏蔽优先级低于唤醒中断的优先级,否则不能唤醒
在这个函数里面设置我们要关闭的时钟,中断的时钟记得不能关闭

唤醒的时候,会判断是滴答定时器/LPTIM唤醒的,还是其他中断唤醒的
根据两种唤醒方式的不同,时间补偿值也 不同,当滴答定时器中断唤醒时,时间补偿值刚好为阻塞时间;
如果是其他中断唤醒的,那么此时的补偿时间肯定小于阻塞时间,因为外部中断发生了,代表此时滴答定时器中断还没发生,因此,此时的唤醒时间绝对小于阻塞时间;因此,此时的时间补偿值为阻塞时间减去滴答定时器的当前计数值(需要注意滴答定时器是一个24位倒数的计数器!)
对 Cortex-M3 和 M4 内核来说, FreeRTOS 自带的低功耗模式是通过指令 WFI 让系统进入睡眠模式,就是关闭什么外设需要用户自己来定义
低功耗的两个需要我们自己编写的函数
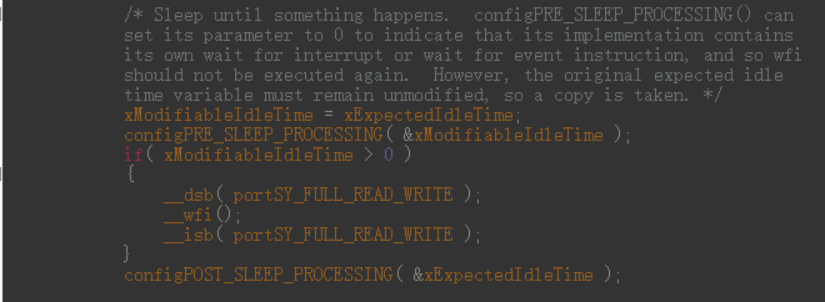
configPRE_SLEEP_PROCESSING( xExpectedIdleTime )//执行低功耗模式前,这个函数里面关闭外设时钟来进一步降低系统功耗。
configPOST_SLEEP_PROCESSING ( xExpectedIdleTime )//退出低功耗模式后,此函数会得到调用,之前关掉的外设时钟要重新打开#define configEXPECTED_IDLE_TIME_BEFORE_SLEEP 3 // 最小休眠 tick 阈值
如果不想要系统默认的睡眠模式,只需设置参数 xExpectedIdleTime=0 即可屏蔽掉默认指令执行,reeRTOS 会在函数返回后读取修改后的值
#define configPRE_SLEEP_PROCESSING(x) PreSleepProcessing(x) // 关联用户函数PreSleepProcessin(x)
{x=0;
}
然后自己编写停机模式代码,FreeRtos会后面检查这个X的值,通过指针传递的方式,将函数里的这个值取出来再判断
异常及中断
中断是异常的一种,,中断异常处理ISR(Interrupt Service Routine)中断服务程序
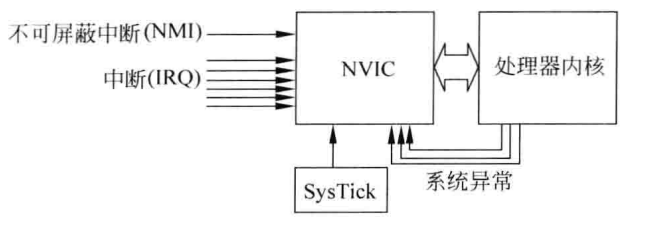
NVIC来处理异常的,Nested Vectored Interrupt Controller(嵌套向量中断控制器)
NMI不可屏蔽中断,用于看门狗定时器或掉电检测(一种电压监视单元,电压过低会给处理器警告)
这里是异常的编号,有些优先级是设置的,有些是自动设置
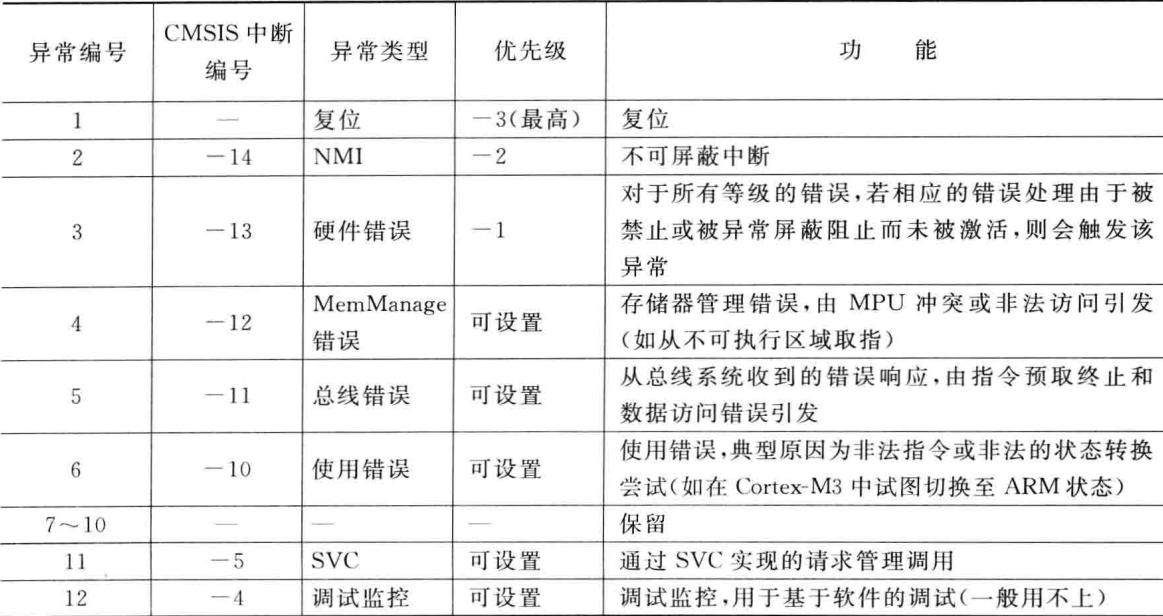
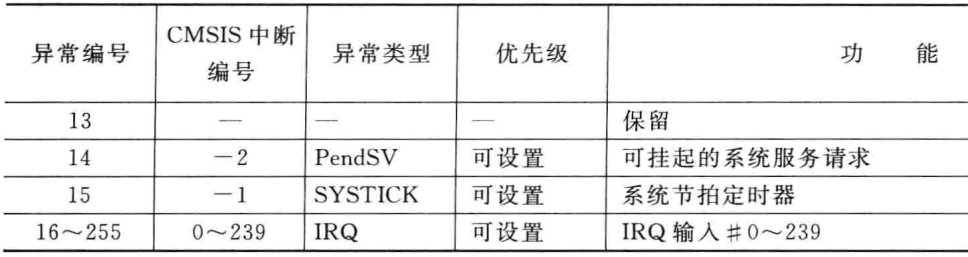
IRQ(interrupt Request)中断请求
PendSV(Pendable Service Call)(可挂起的服务调用),主要用于操作系统任务调度和低优先级后台处理
SVC(Supervisor Call,超级用户调用),用于实现 用户模式(User Mode)到特权模式(Privileged Mode)的安全切换
在FreeRTOS里面,SVC(超级用户调用)用于 实现系统调用(SysCall),即用户任务通过 SVC 请求内核服务(如任务创建、队列操作),确保 权限隔离 和 安全性。
在 ARM Cortex-M 系列处理器中,CPU 的运行模式主要分为 特权模式(Privileged Mode) 和 用户模式(User Mode)
特权模式可以访问所有CPU 寄存器,执行所有指令,配置 NVIC和系统外设
用户模式只能访问 受限的 CPU 寄存器(如通用寄存器 R0-R12),不能直接操作内核寄存器(如 MSP、NVIC)
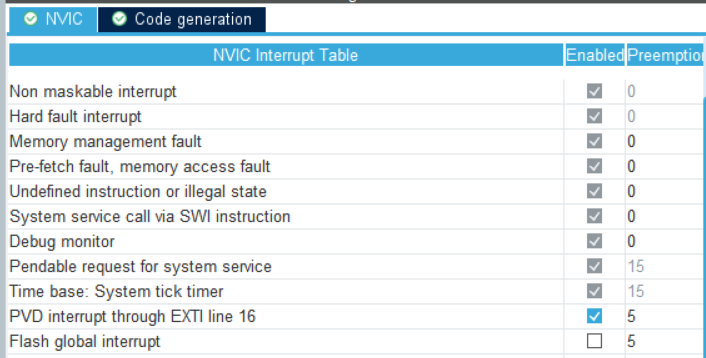
NVIC
Nested Vectored Interrupt Controller(嵌套向量中断控制器)
灵活的异常和中断管理、支持嵌套异常/中断、中断屏蔽、向量化异常/中断入口
嵌套:中断等异常有优先级,异常产生时,NVIC会比对优先级,如果新异常优先级高,就暂停当前任务,保存寄存器到栈,处理器执行新的异常,脚抢占
向量化:软件实现的,Cortex-M会从存储器的向量表中自动定位异常处理的入口
中断屏蔽:利用PRIMASK寄存器,可以禁止除HardFault和NMI外的所有异常。这种屏蔽对不应被中断的操作非常有用,如时序关键控制任务或实时多媒体编解码器。还可以使用BASEPRI寄存器来选择屏蔽低于特定优先级的异常或中断。CMSIS有对应的函数。
向量表是存储器内的字数据数组,代表异常类型的其实地址,每个占4字节
一般放在Flash的起始地址
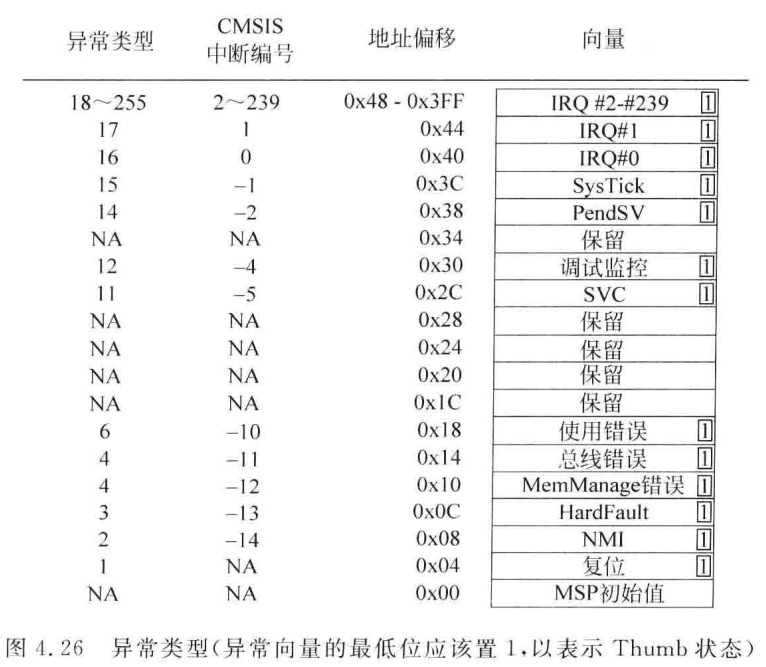
CPU 复位后,从 向量表地址 + 0x0000 加载初始 MSP(主栈指针)。
从 向量表地址 + 0x0004 获取 Reset_Handler 地址,跳转到该函数执行初始化代码(如初始化内存、外设)。
发生异常的时候,CPU根据异常号(如 SVC 的编号为 11)计算偏移地址:向量表地址 + 异常号 × 4,这样就能找到入口函数
向量表地址是通过链接脚本定义的
这里涉及到链接脚本,定义内存布局(Flash/RAM),指定代码/数据存放位置(如向量表、堆栈),是编译器和硬件的桥梁,
启动文件:初始化硬件环境,汇编编写,初始化堆栈、向量表,跳转到 main()
中断的区别
异常中断主要通过MSP主栈指针来处理,而且运行在特权访问等级,
中断请求、中断响应、保护断点保存地址、执行中断程序、恢复现场返回
中断是外部硬件设备,包括引脚、串口、SPI、定时器等等,异步产生,和cpu无关,可以屏蔽,优先级低于异常,通知cpu暂停任务处理当前外部事件
异常是cpu执行指令时内部检测到的错误特殊事件,强制跳转到处理程序,由当前指令同步触发,不可屏蔽
异常和中断都在中断向量表里面
写Flash使用的PDV掉电异常,使用的PVD(Programmable Voltage Detector)模块,可以在电压低于阈值时触发 EXTI线16中断
中断处理的时候,不能休眠,在中断上下文(上下文指运行环境,寄存器等),只有更高优先级中断能打断,内核会寄
崩溃的原因可能是中断有自己的栈,而且比较小通常1~2KB,所以里面阻塞嵌套太多会导致栈溢出
还有里面不能阻塞的原因是,systick滴答定时器的优先级一般很低,无法打断外设中断,而HAL_Delay结束靠的就是滴答定时器
这里有一些异常中断等等
这里又回到了链接寄存器LR里面了,异常出现后,程序要返回到原来位置,就要保存地址了
异常从ARM进入:LR=PC+4/PC+8(PC指向当前指令的下两条指令的地址,三级流水线原因,预取指令)
异常从Thumb进入:LR=PC
这里暂时看不懂
CPSR SPSR
CPSR(Current Program Status Register),存储 CPU当前的执行状态
SPSR(Saved Program Status Register),在 异常或中断发生时 由硬件自动保存 CPSR 的值,用于异常返回时恢复状态
快速中断FIQ比普通中断IRQ快,因为FIQ有更多的自己的寄存器,所以不像IRQ,要保存R8-R12这些寄存器,结束还要恢复这些寄存器
异常产生的时候、ARM核心会拷贝CPSR到SPSR,设置CPSR进入异常处理状态,屏蔽中断、保存返回地址,设置PC跳转到异常处理程序
ARM内部的寄存器:常见的是16个
R0~R7:所有模式通用(共用一组物理寄存器),称为“低组寄存器”
R8~ R12:在 FIQ 模式下,有独立的物理寄存器(R8_fiq ~ R12_fiq),避免与其他模式冲突,其他模式(用户、系统、IRQ、SVC 等)共用一组物理寄存器(R8~ R12)
R13~R15:专用寄存器,每种模式下有独立的 SP、LR,但是PC只有一个
还有几个特殊寄存器:CPSR、SPSR、FPSCR(浮点计算)
中断里面用自旋锁
主要原因是因为自旋锁让CPU会不断判断状态,不会进入休眠,当然如果一直卡在中断里,造成死锁也不行,而且要注意禁止中断,防止中断嵌套导致的死锁,多个中断争取一个锁吧
信号量核心是基于调度器的阻塞和唤醒,在中断上下文,没有进程上下文,调度器不能工作,所以会导致内核崩溃
并发和互斥
并发:多个执行单元并行执行,对共享资源的访问造成竞态
互斥:为了解决竞争,保证共享资源的互斥访问
访问共享资源的代码区叫临界区(理解成临界点),中断屏蔽、原子操作、自旋锁、信号量等等都可以
自旋锁前面中断介绍过了,就是适合短期持有,且不阻塞,会不断查询访问
不会阻塞睡眠的原因是禁止处理器抢占,但是中断可以跑,所以自旋锁可以用于中断,但是要先禁止本地中断,防止死锁
指令集
调试

栈溢出检测
1.Keil里面的HDML文件可以找到栈使用情况
2.调试时,将栈填充为特定形式,运行一段时间后,查看栈存储的变化,但是实验环境很难出现最大等级的嵌套中断情况
3.重新布局,改变传统的存储器布局,栈放在最底,堆放在最顶,这样超过会出发错误异常,不过可能无法恢复寄存器
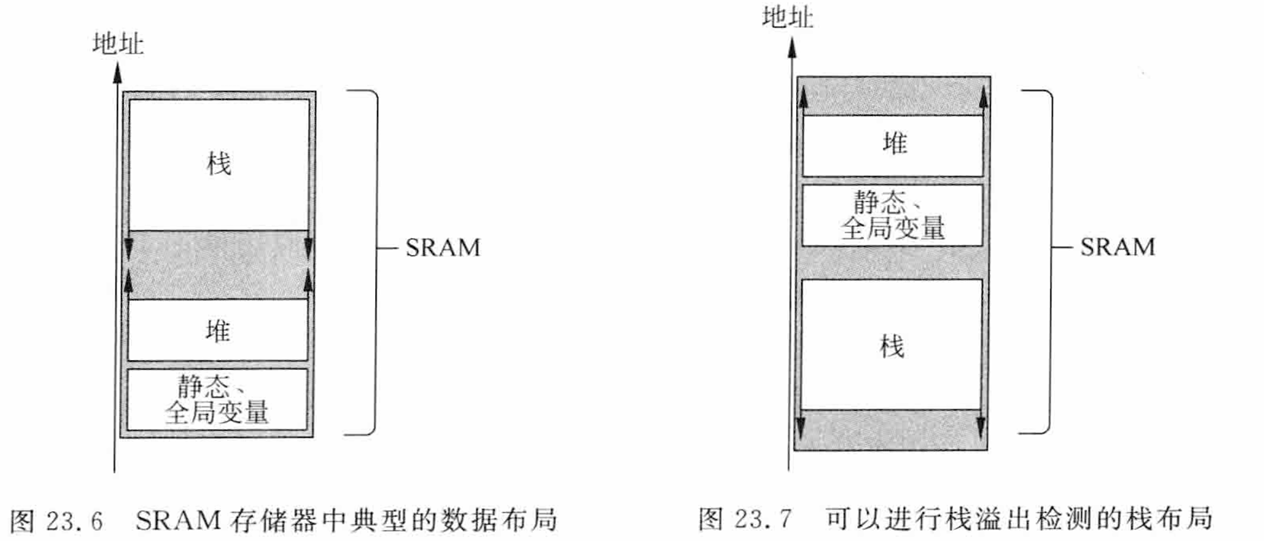
在左边这样的传统情况下,栈和堆都能利用中间的空闲存储器,增加了可用内存,可以避免栈和堆用完的情况
4.使用MPU,配置定义允许的栈空间,使得检测到栈溢出后可以出发存储器管理错误
5.操作系统支持在上下文切换的时候进行栈溢出检查
6.使用DWT在栈区域的尾部设置一个监视点
三种通信协议
SPI
项目里25MHz的晶振,倍频分频到216MHz最大时钟,然后挂载在APB2(Advanced Peripheral Bus),108MHz,然后SPI采用8分频,是13.5MBits/s,SPI几米内。
一主多从,全双工经典四根线:MISO、MOSI、SCK、CS。数据不8位
时钟极性(CPOL,clock polarity):SCK时钟信号空闲状态的电平,0低电平、1高电平
时钟相位(CPHA,clock phase):0是上升沿,1是下降沿
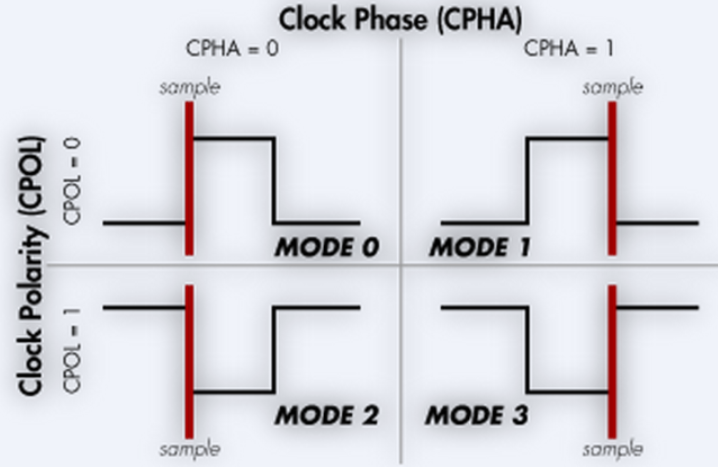
片选信号拉低后,开始在时钟边沿读取数据,发送接收的时钟都是主机给的。一般是从数据的高位开始发。
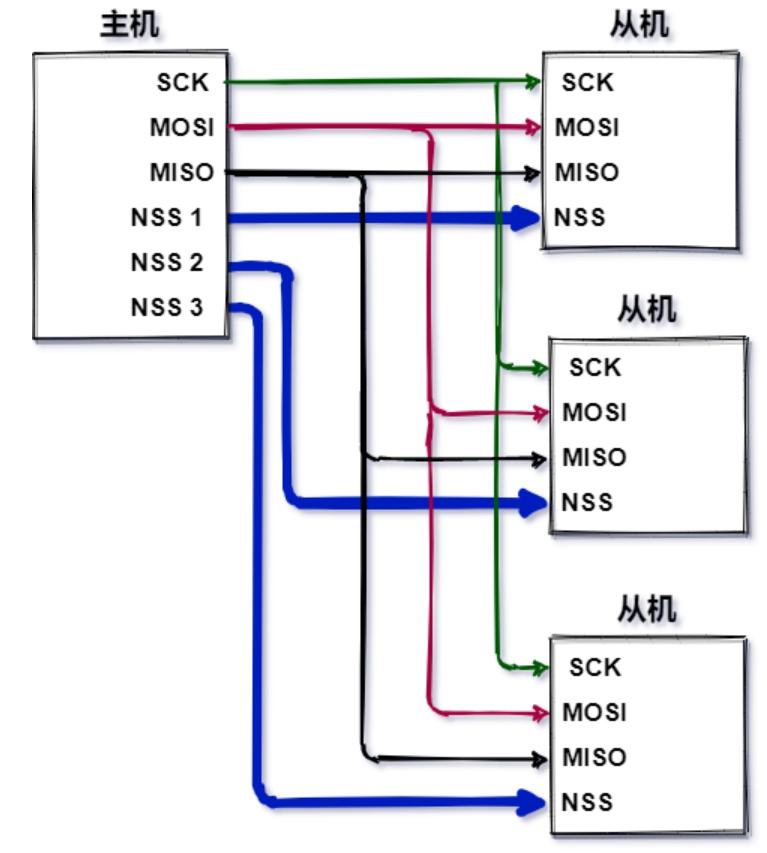
多从机:
1.多条NSS片选信号
2.菊花链:缺点是喜好串行传输,一旦链路中设备发生故障,下面低优先级设备就不能得到了;距离主机越远的从机,获取服务的优先级越低;
设置总线检测器,如果某个从机超时,就短路掉。
类似SPI的移位寄存器,只是整个数据在一个从机接一个的传递
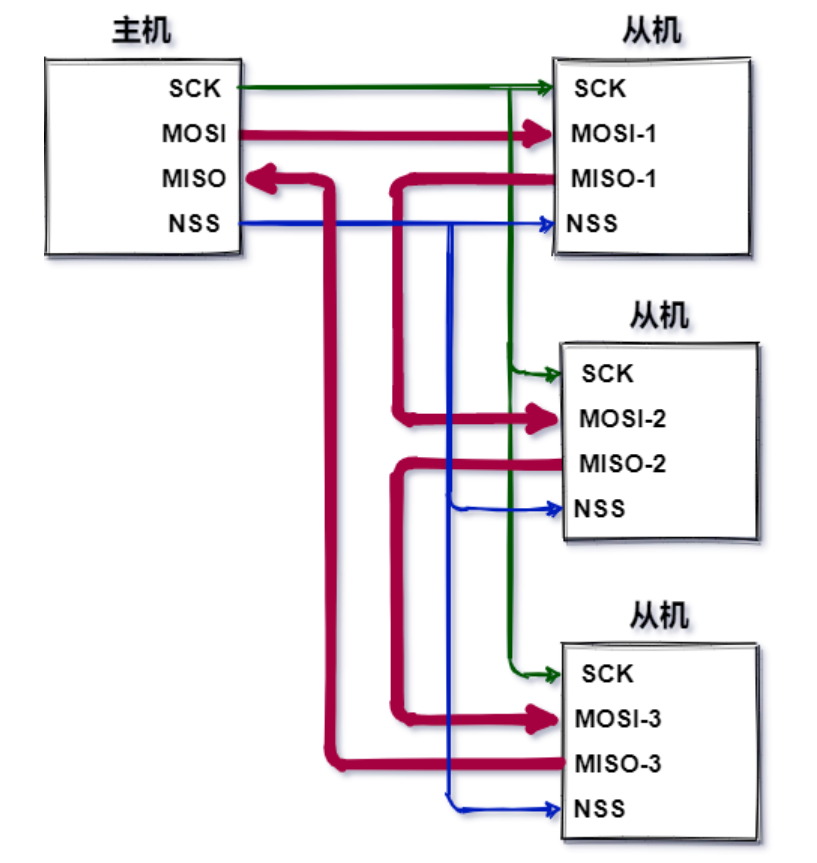
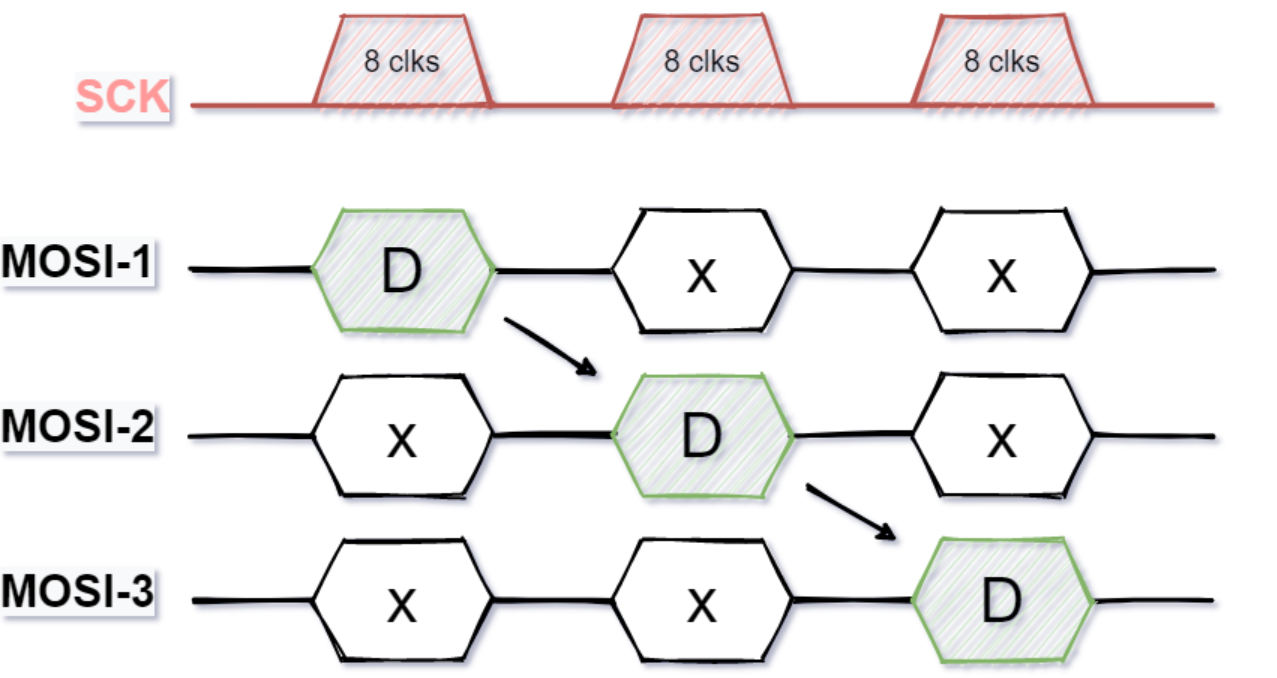
优点:全双;高速;不局限8位数据;不需要地址,片选信号;
缺点:没有应答信号;只有一个主设备;比IIC引脚多;没有硬件级别的错误检查协议;与RS232和CAN总线比,传输距离短
入手方向:错误检查协议、应答重传?
IIC
双向传送,标准速度最高为100kHz,高速 IIC 总线一般可达 400kbps 以上。半双工
小数据量场合使用,传输距离短,任意时刻只能有一个主机,但支持多主机,传输速率比SPI低
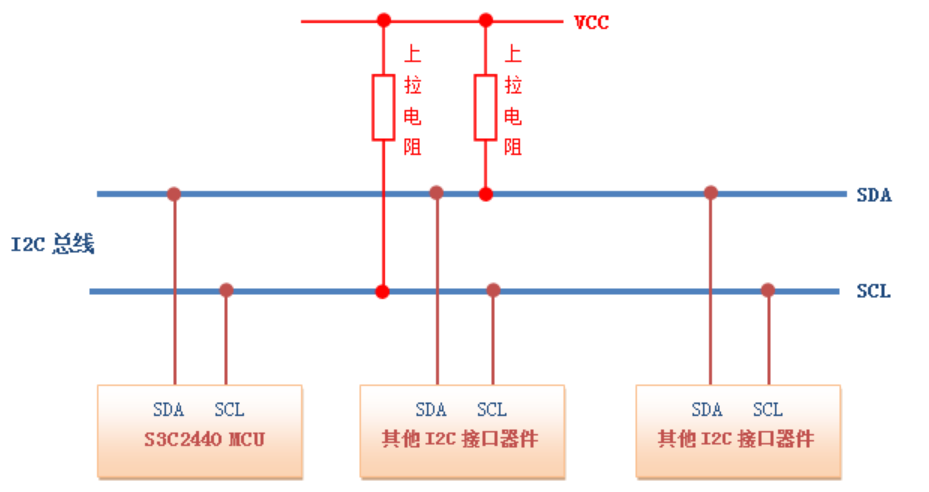
SCL(serial clock line):时钟线
SDA(serial data):数据线
就这两根总线,靠设备唯一地址来区别,IIC的地址一般前四个确定,后四个可电路配置
主设备:产生时钟、产生起始信号和停止信号
从设备:地址检测、停止位检测、应答
SCL和SDA都需要上拉电阻,原因:
1.开漏输出,只能拉低不能拉高
2.多设备共享总线,开漏允许某个设备拉低总线,平时所有设备都是释放状态,电平上拉高电平
开漏的高阻态特性(断路),这样就能释放对总线的电平影响
(开漏其实是内部只有MOS管控制连接到地,所以只有关断和导通两种情况)
时序:
总线释放是拉高的,所以起始信号和结束信号最后都是高电平
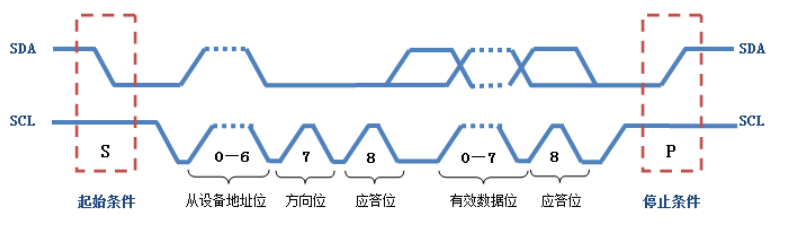
开始信号:SCL 为高电平时,SDA 由高电平向低电平跳变,开始传送数据
结束信号:SCL 为高电平时,SDA 由低电平向高电平跳变,结束传送数据
应答信号:每8bit数据,从机拉低低电平表示收到,主机接收到应答信号进行判断
IIC信号在数据传输过程中,当SCL=1高电平时,数据线SDA必须保持稳定状态,不允许有电平跳变,只有在时钟线上的信号为低电平期间,数据线上的高电平或低电平状态才允许变化。
多数从设备的地址为7位或者10位,一般都用七位。
八位设备地址=7位从机地址+读/写地址。0写1读
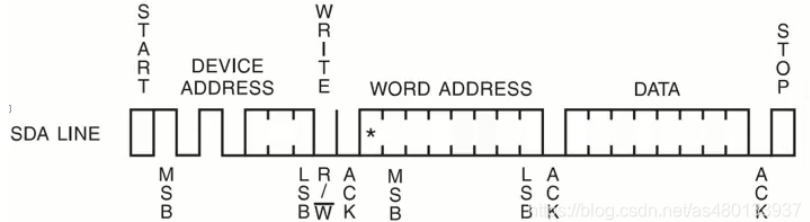
指定地址写数据:
指定地址读数据:读数据的时候,首先要发送写命令,发送写地址,之后应答后重新发送start,发送从机地址,开始读
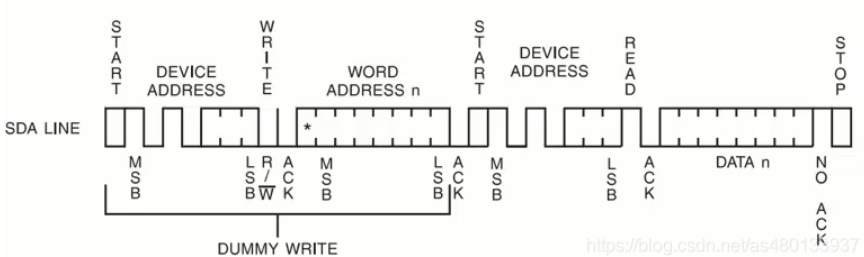
有多种规范,写一个还是写多个,连续读还是读一个,后面学习区分一下差异,找个手册看看
软件IIC:用单片机的两个I/O端口模拟出来的IIC,不受管脚限制,接口比较灵活
硬件IIC:硬件I2C对应芯片上的I2C外设,有相应I2C驱动电路,其所使用的I2C管脚也是专用的,效率高
RS232/RS485
RS即推荐标准(Recommended Standard)
串口1米,232 15米,485 1200米
RS232
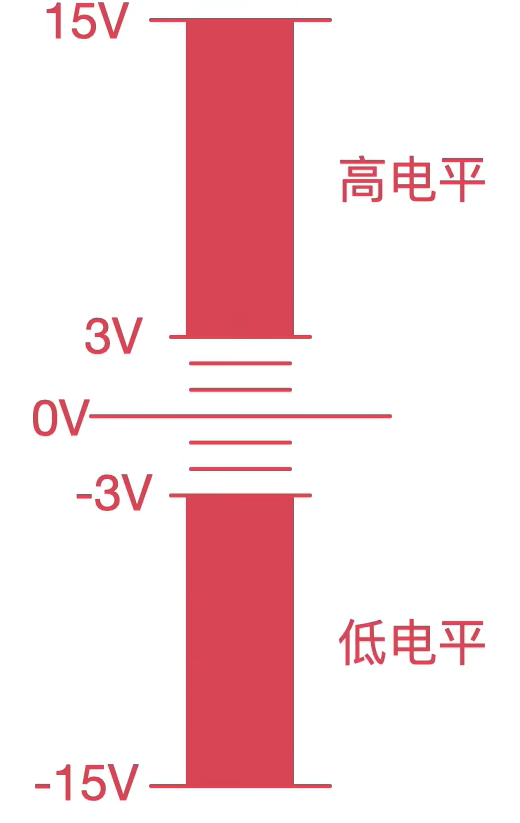
RS232:TTL电平转换为232电平(MAX232芯片),-12V-12V
其高低信号划分标准:抗干扰能力增强了,15米,最高19200波特率
仍然是一对一的
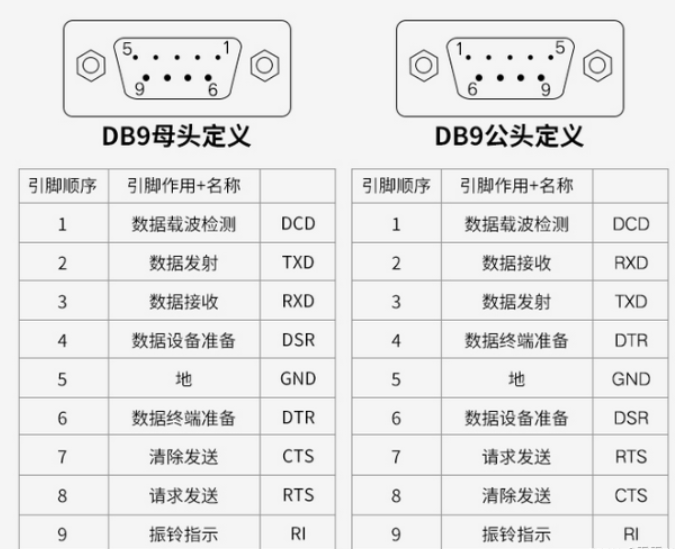
一般三根线就够了:RX、TX、GND
RS485
RS485:靠转换芯片,TTL转化为差分信号,电平也变了-6V-+6V,抗干扰能力强,双绞线(共模干扰,差分不变),1200米,50M速率,但一般是半双工。可以一主多从,最多128个收发器。
抗共模干扰
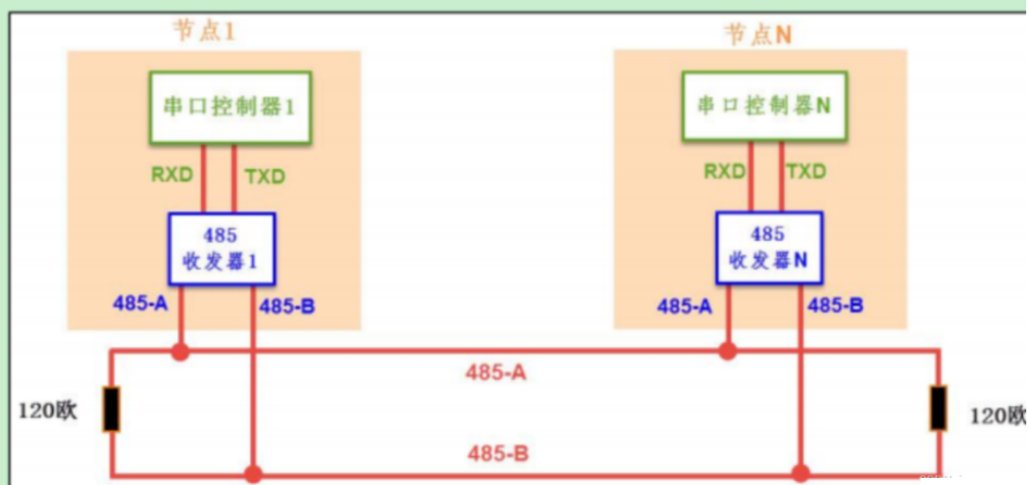
485是靠两根线上的电压作差得到的高低电平
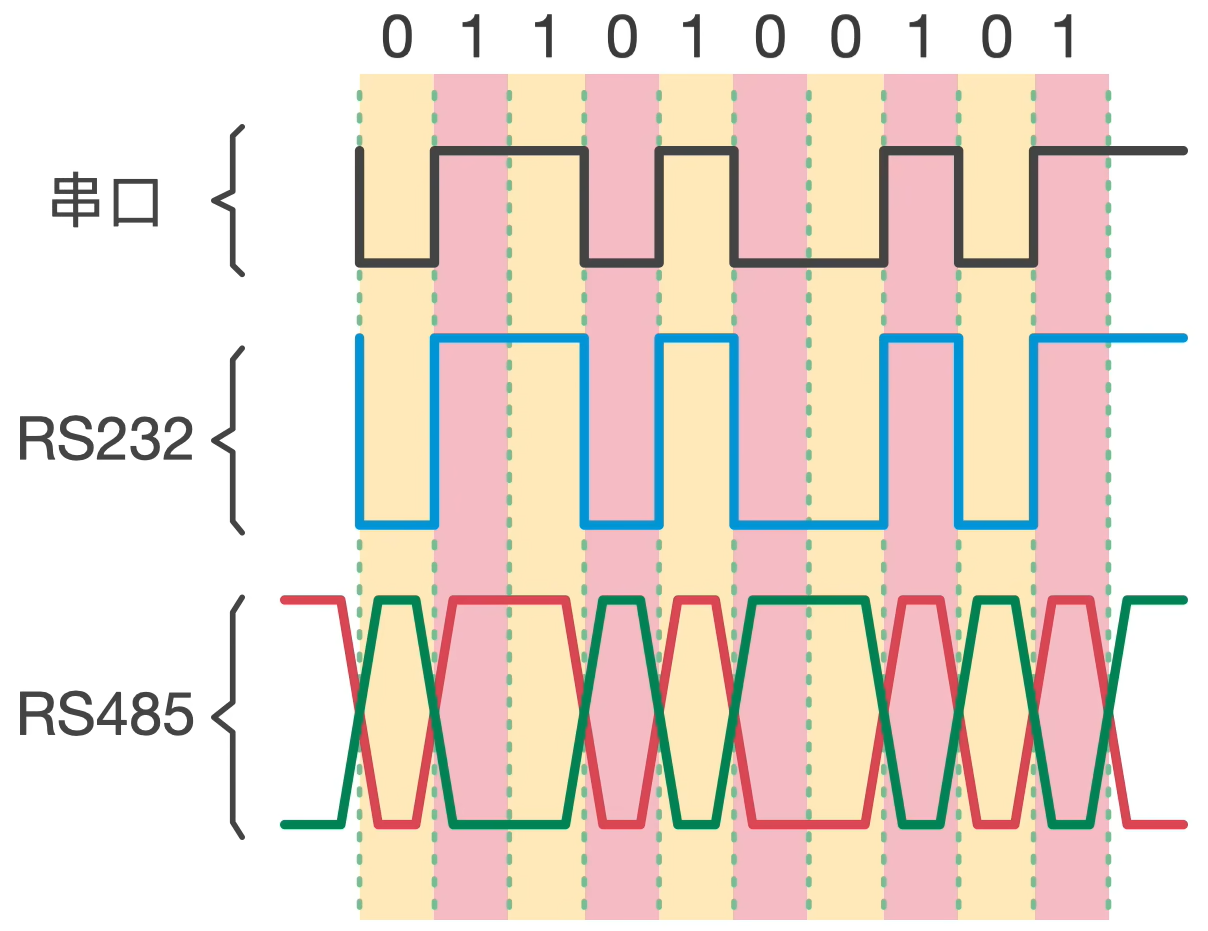
通常情况下只需要两根信号线(不需要地线)就可以进行正常的通信。
CAN
CAN(Controller Area Network,控制器局域网),汽车电子和工业控制领域
多主串行通讯总线,当信号传输距离达到10Km 时,CAN 仍可提供高达50Kbit/s 的数据传输速率。
回路连接方式,适合高速、短距离的CAN网络,总线长度最长达40m。
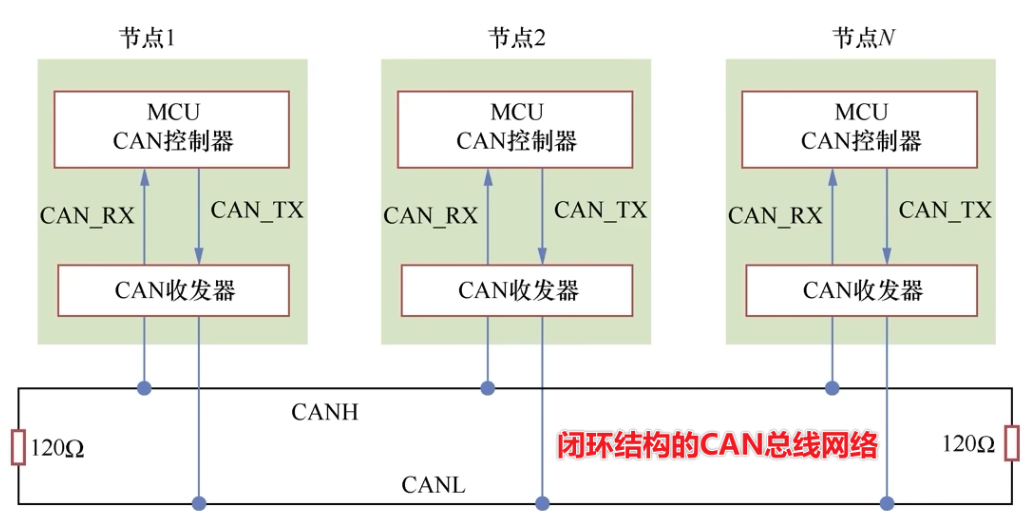
开环的能达到1000M,在40kbits/s
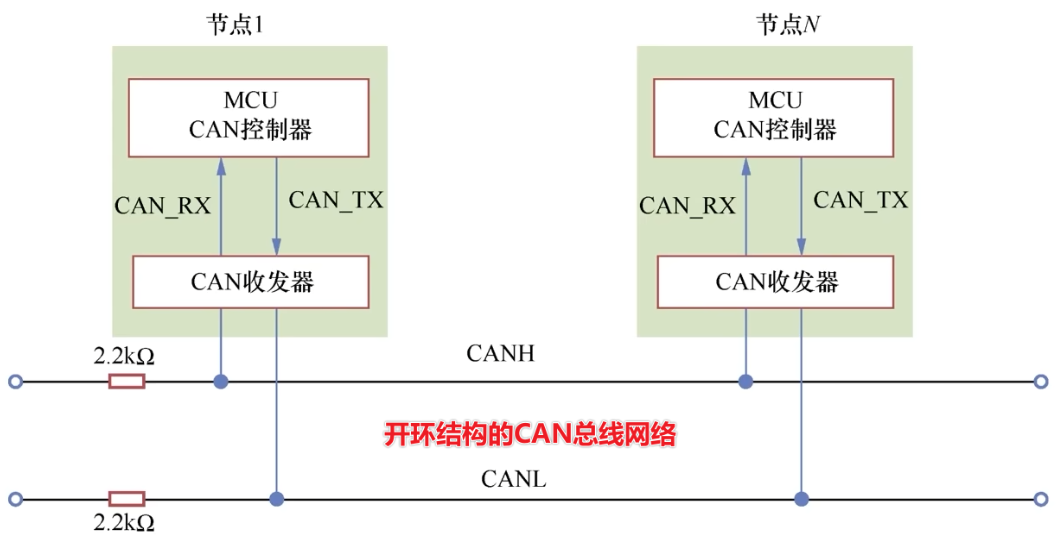
CAN没有时钟线,异步通信,双绞线,传输差分信号;两根线CANH和CANL,作差判断高低电平
多主通信:总线上的每个节点都可主动发送数据;
非破坏性仲裁:多个节点同时发送时,通过ID优先级仲裁,优先级高的节点继续发送,低优先级的自动退让,不会破坏数据;
差分信号传输:通过CAN_H和CAN_L两根线传输差分信号,抗电磁干扰能力极强(适合工业和汽车环境);
远距离传输:速率125kbps时传输距离可达500m,满足大多数工业场景;
错误检测与自动重传:内置CRC校验、位填充、应答机制,确保数据可靠传输,错误帧会自动重传。
CAN数据帧:
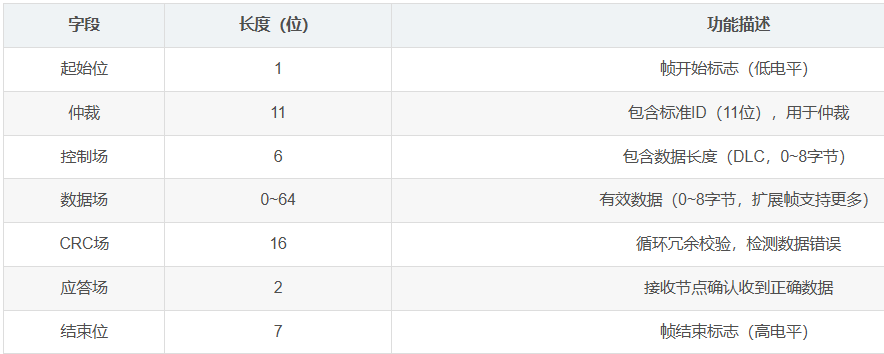
位时序:
CAN总线是异步通信,节点间没有统一的时钟线,通过位时序实现同步,确保所有节点在同一时刻采样总线电平,避免因时钟差异或传输延迟导致的通信错误。
STM32的CAN控制器称为bxCAN(Basic Extended CAN)
支持标准帧(11位ID)和扩展帧(29位ID);
3个发送邮箱:可缓存3帧待发送数据,支持优先级发送;
2个接收FIFO:每个FIFO有3级深度,可缓存3帧接收数据,减轻CPU负担;
灵活的滤波功能:14个滤波器组,支持屏蔽位模式和列表模式,精准过滤目标报文;
多种中断源:发送完成、接收FIFO满、错误警告等,支持中断和DMA传输;
总线错误管理:检测总线错误(位错误、CRC错误等),自动进入错误状态。
邮箱:发送数据的"缓冲区",当邮箱状态为"空"时,CPU填充邮箱数据,设置"发送请求",CAN控制器会自动 arbitration(仲裁)并发送,发送完成后邮箱状态变为"空"。
接收:FIFO0和FIFO1,用于缓存接收的有效报文。14个滤波器
仲裁判断:
检测总线空闲:连续11个位都是隐形位(逻辑1),总线空闲
发送帧起始位,一个0(显性位)起始
仲裁,发送标识符等,在此阶段逐位仲裁,仲裁失败的变为接收模式,仲裁失败的节点只是停止发送,不会干扰获胜节点的传输,也不需要重传已经发送的部分。(非破坏性仲裁)
发送数据
硬件滤波器会设置多个过滤器和掩码,只有匹配的报文才能收下
CAN仲裁不是比较ID数值大小,而是实时比较二进制位的"显性/隐性"特性
假设总线上有3个节点同时开始发送,就会一位一位判断,一旦发现自己发送了1,但是总线是0,就立刻变为仲裁失败的状态,停止发送
节点A发送ID:0x123 (二进制 000100100011)
节点B发送ID:0x122 (二进制 000100100010)
节点C发送ID:0x124 (二进制 000100100100)
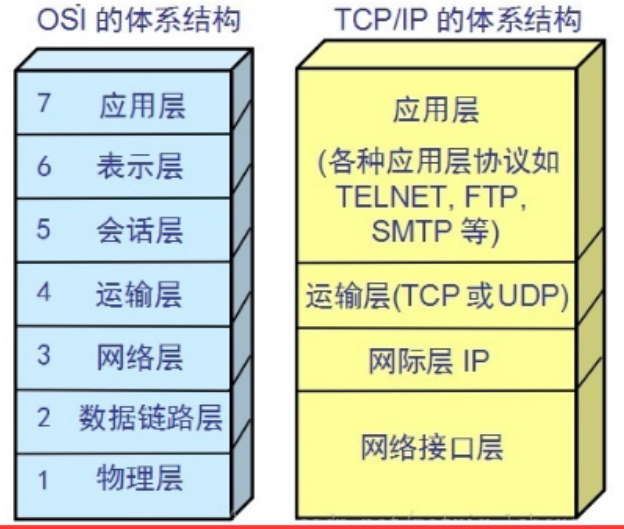
TCP/IP
1.序列号、确认应答、超时重传
接收方发出确认应答,里面会有下次接收的数据序列号。发送方迟迟没有收到确认应答,就会等待一段时间重传,等待:2*RTT(报文段往返时间)+偏差值
2.窗口控制与快速重传
TCP是滑动窗口以字节为单位,有发送窗口也有接收窗口,在一个窗口内不需要等到应答再发送下一段数据,这样才能快速发送数据;
使用窗口控制,如果数据段1001-2000丢失,后面数据每次传输,确认应答都会不停地发送序号为1001的应答,表示我要接收1001开始的数据,发送端如果收到3次相同应答,就会立刻进行重发;
如果应答丢失,也不会重发,因为接收端会疯狂提醒,只有超过三次;
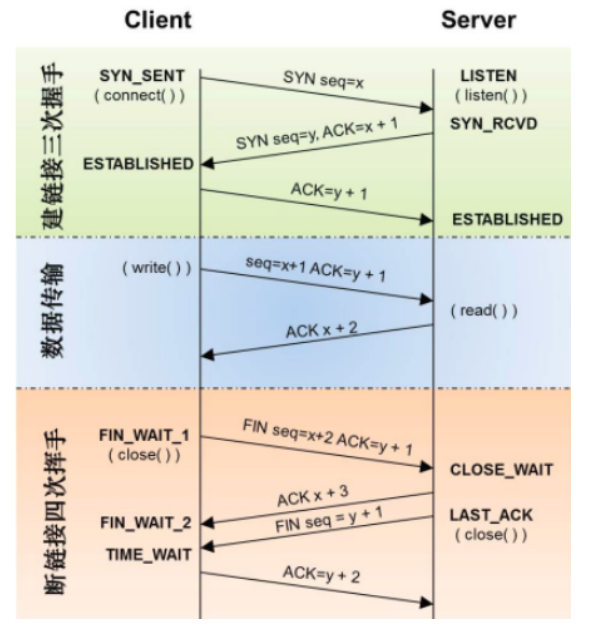
三次握手:
看图,标志位SYN、ACK、随机数seq,三次确认
SYN是建立连接标志位,发送和接收都有个序列号,所以看到两个SYN,seq就是Sequence Number,序列号
四次挥手:
TCP连接时全双工,由于TCP连接时全双工的,因此,每个方向都必须要单独进行关闭,这一原则是当一方完成数据发送任务后,发送一个FIN来终止这一方向的连接,收到一个FIN只是意味着这一方向上没有数据流动了,即不会再收到数据了,但是在这个TCP连接上仍然能够发送数据,直到这一方向也发送了FIN。
1.数据传输结束后,客户端的应用进程发出连接释放报文段,并停止发送数据,客户端进入FINWAIT_1状态,此时客户端依然可以接收服务器发送来的数据。
2.服务器接收到FIN后,发送一个ACK给客户端,确认序号为收到的序号1,服务器进入CLOSEWAIT状态。客户端收到后进入FIN_WAIT_2状态。
3.当服务器没有数据要发送时,服务器发送一个FIN报文,此时服务器进入LAST_ACK状态,等待客户端的确认
4.客户端收到服务器的FIN报文后,给服务器发送一个ACK报文,确认序列号为收到的序号1。此时客户端进入TIMEWAIT状态,等待2MSL(MSL:报文段最大生存时间),然后关闭连接。
三次握手原因:
1.防止失效的连接请求发送到B
2.两次握手,就是主机发送SYN给服务器请求连接,但延迟了,服务端认为是新请求,就会发送ACK同意链接,这样直接就连在一起了,但客户端不承认;或者客户端发送完就掉线了,这样也白连接了,所以加了一级客户端的确认
两次握手只能证明 客户端→服务器 的通道正常,但无法确认 服务器→客户端 的通道是否可用。
三次握手已经足够解决 双向通信验证 和 序列号同步 问题
TCP是面向连接的,UDP是面向无连接的
UDP程序结构较简单
TCP是面向字节流的,UDP是基于数据报的
TCP保证数据正确性,UDP可能丢包
TCP保证数据顺序,UDP不保证
TCP特点:确认和重传、流量控制、拥塞机制
TCP拥塞机制:防止窗口定的特别大,造成网络堵塞
定义拥塞窗口、拥塞避免机制、超时重传时窗口设置、快重传
网络层等在数据链路层使用MAC地址作为通信目标
交叉编译
在计算机中能够编译出另一种环境运行的代码,是因为有些环境是不能安装编译器的,也无法运行
FreeRTOS tracelayzer
PWM
PSC, Prescaler(预分频器),ARR里是计数值目标值、CNT是脉冲计数值,CNT=ARR,产生事件,决定周期
CCRX里是PWM的比较值,设置高低电平的分界点,占空比